
- 1docker-compose redis_docker-compose redis
- 2MYSQL中的14个神仙功能
- 3PyTorch学习之:深入理解神经网络
- 4win11病毒和防护功能显示‘页面不可用’的解决方法_windows defender页面不可用
- 5LeetCode-994. 腐烂的橘子【广度优先搜索 数组 矩阵】
- 6365天深度学习训练营-第T6周:好莱坞明星识别_label_mode='categorical
- 7openstack运维_查看openstack各个模块服务状态nova-conductor重启不了
- 8【Flutter从入门到实战】 ⑥、Flutter的StatefulWidget的生命周期didUpdateWidget调用机制、基础的Widget-普通文本Text、富文本Rich、按钮、图片的使用_flutter didupdatewidget
- 9决策树之C4.5(详细版终结版)_决策树c4.5代码实现
- 10SpringBoot+消息队列RocketMQ(基于阿里云)_aliyun.openservices onsmessagetrace
微软AI程序员登场,10倍AI工程师真来了?996自主生成代码,性能超GPT-4 30%
赞
踩
【导读】全球首个AI程序员Devin诞生之后,让码农纷纷恐慌。没想到,微软同时也整出了一个AI程序员——AutoDev,能够自主生成、执行代码等任务。网友惊呼,AI编码发展太快了。
全球首个AI程序员Devin的横空出世,可能成为软件和AI发展史上一个重要的节点。
它掌握了全栈的技能,不仅可以写代码debug,训模型,还可以去美国最大求职网站Upwork上抢单。

一时间,网友们惊呼,「程序员不存在了」?
甚至连刚开始攻读计算机学位的人也恐慌,「10倍AI工程师」对未来的工作影响。
除了Cognition AI这种明星初创公司,美国的各个大厂也早就在想办法用AI智能体降本增效了。
就在3月14日同一天,微软团队也发布了一个「微软AI程序员」——AutoDev。

论文地址:https://arxiv.org/pdf/2403.08299.pdf
与Devin这种极致追求效率和产出结果的方向有所不同。
AutoDev专为自主规划、执行复杂的软件工程任务而设计,还能维护Docker环境中的隐私和安全。

在此之前,微软已有主打产品GitHub Copilot,帮助开发人员完成软件开发。
然而,包括GitHub Copilot在内的一些AI工具,并没有充分利用IDE中所有的潜在功能,比如构建、测试、执行代码、git操作等。
基于聊天界面的要求,它们主要侧重于建议代码片段,以及文件操作。
AutoDev的诞生,就是为了填补这一空白。

用户可以定义复杂的软件工程目标,AutoDev会将这些目标分配给自主AI智能体来实现。
然后,这些AI智能体可以对代码库执行各种操作,包括文件编辑、检索、构建过程、执行、测试和git操作。
甚至,它们还能访问文件、编译器输出、构建和测试日志、静态分析工具等。
在HumanEval测试中,AutoDev分别在代码生成和测试生成方面,分别取得了91.5%和87.8% Pass@1的优秀结果。
网友表示,AI编码发展太快了,2021年GitHub Copilot能解决28.8%的HumanEval问题,到了2024年,AutoDev直接解决了91.5%的问题。

不用人类插手,AutoDev自主完成任务
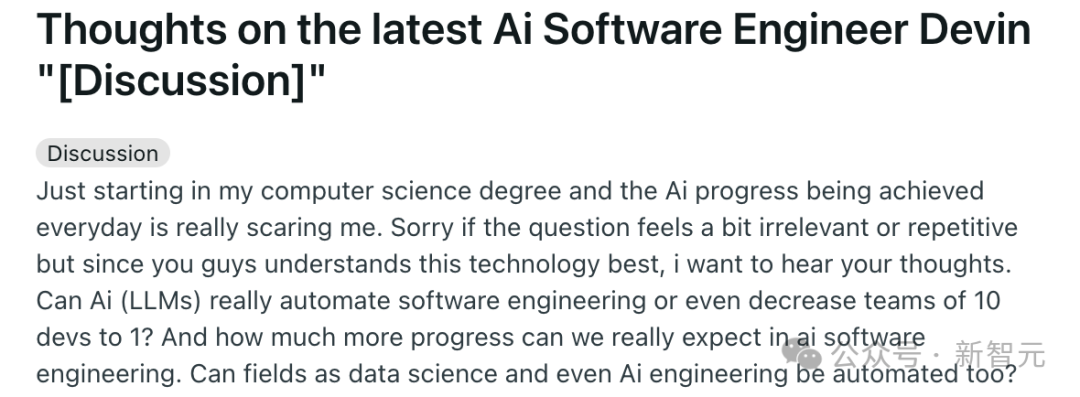
AutoDev工作流程如下图所示,用户定义一个目标,比如「测试特定方法」。
AI智能体将测试写入一个新文件,并启动测试执行命令,以上都在安全的评估环境中进行。
然后,测试执行的输出(包括失败日志)将合并到对话中。
AI智能体分析这些输出,触发检索命令,通过编辑文件合并检索到的信息,然后重新启动测试执行。
最后,Eval环境提供有关测试执行是否成功,以及用户目标完成情况的反馈。
整个过程由AutoDev自主协调,除了设定初始目标之外,无需要开发人员干预。
相比之下,如果现有的AI编码助手集成到IDE 中,开发人员必须手动执行测试(比如运行pytest)、向AI聊天界面提供失败日志、可能需要识别要合并的其他上下文信息,并重复验证操作确保AI生成修改后的代码后测试成功。
值得一提的是,AutoDev从以前许多在AI智能体领域的研究中汲取了灵感,比如AutoGen——编排语言模型工作流并推进多个智能体之间的对话。
AutoDev的能力超越了对话管理,使智能体能够直接与代码存储库交互,自动执行命令和操作,从而扩展了 AutoGen。
同样,AutoDev的研究也借鉴了Auto-GPT。这是一种用于自主任务执行的开源AI智能体,通过提供代码和IDE特定功能来支持执行复杂的软件工程任务。
AutoDev构架
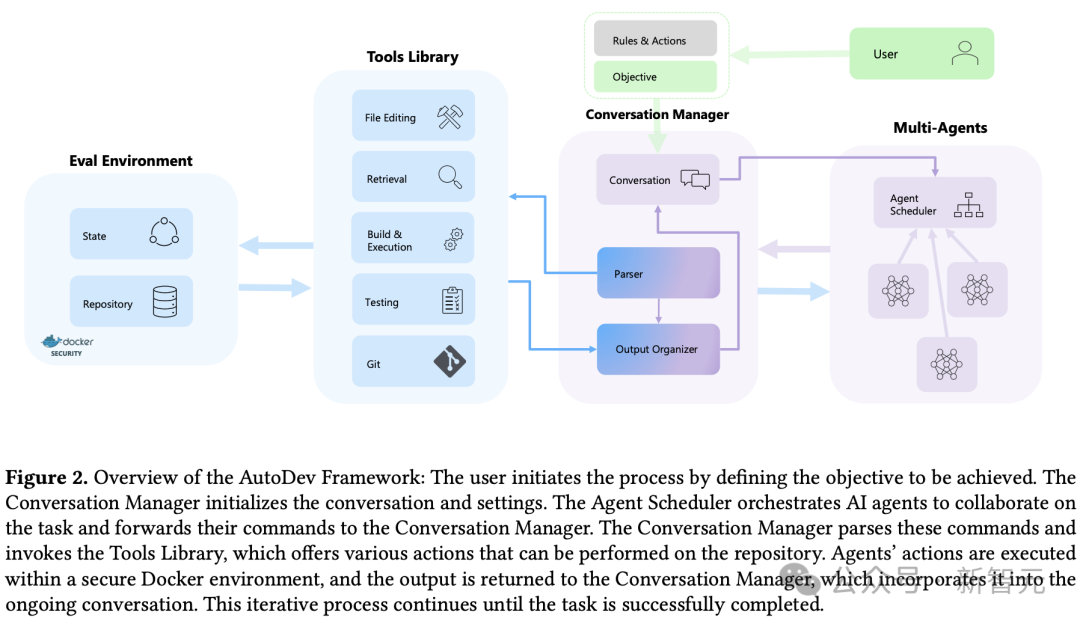
上图是AutoDev架构的简单示意图。
AutoDev主要由4个功能模块组成:
-用于跟踪和管理用户与代理对话的对话管理器(Conversation Manager);
-为代理提供各种代码和集成开发环境相关工具的工具库(Tools library);
-用于调度各种代理的代理调度器(Agents Scheduler);
-以及用于执行操作的评估环境(Evaluation Environment)。
下面就给大家详细介绍每种功能模块。
规则、行动和目标配置
用户通过yaml文件配置规则和操作来启动流程。
这些文件定义了AI代理可以执行的可用命令(操作)。
用户可以通过启用/禁用特定命令来利用默认设置或细粒度权限,从而根据自己的特定需求量身定制AutoDev。
配置步骤目的是实现对AI代理能力的精确控制。
在这一阶段,用户可以定义人工智能代理的数量和行为,分配特定的责任、权限和可用操作。
例如,用户可以定义一个 「开发者 」代理和一个 「审核者 」代理,让它们协同工作以实现目标。
根据规则和操作配置,用户可以指定AutoDev要完成的软件工程任务或流程。
例如,用户可以要求生成测试用例,并确保其语法正确、不包含错误(这涉及编辑文件、运行测试套件、执行语法检查和错误查找工具)。
对话管理器(conversation manager)
会话管理器负责初始化会话历史,在对正在进行的会话进行高级管理方面发挥着关键作用。它负责决定何时中断对话进程,并确保用户、人工智能代理和整个系统之间的无缝交流。
它维护和管理的对话对象,主要包括来自代理的信息和来自评估环境(eval environment)的操作结果。
解析器
解析器解释代理生成的响应,以预定格式提取指令和参数。它能确保指令格式正确,验证参数的数量和准确性(例如,文件编辑指令需要文件路径参数)。
如果解析失败,就会在对话中注入错误信息,阻止对资源库的进一步操作。
通过强制执行特定的代理权限和进行额外的语义检查,成功解析的命令会被进一步分析。
它能确保建议的操作符合用户指定的细粒度权限。
如果命令通过审查,对话管理器就会调用工具库中的相应操作。
输出组织器
输出组织器模块主要负责处理从评估环境接收到的输出。
它选择关键信息(如状态或错误),有选择地总结相关内容,并将结构良好的信息添加到对话历史记录中。
这可确保用户对AutoDev的操作和结果有一个清晰、有条理的记录。
对话终止器
会话管理器决定何时结束会话。这可能发生在代理发出任务完成信号(停止命令)、对话达到用户定义的最大迭代次数/token、或在进程或评估环境中检测到问题时。
AutoDev的全面设计确保了人工智能驱动开发的系统性和可控性。

代理调度程序(Multi-Agents)
代理调度器负责协调人工智能代理,以实现用户定义的目标。
配置了特定角色和可用命令集的代理协同运行,执行各种任务。调度器采用各种协作算法,如循环、基于令牌或基于优先级的算法,来决定代理参与对话的顺序和方式。
具体来说,调度算法包括但不限于以下几种:
(i)循环协作,按顺序调用每个代理,让每个代理执行预定数量的操作;
(ii)基于令牌的协作,让一个代理执行多个操作,直到它发出一个令牌,表示完成了分配的任务;
(iii)基于优先级的协作,按照代理的优先级顺序启动代理。代理调度器通过当前对话调用特定代理。
代理
由OpenAI GPT-4等大型语言模型(LLM)和为代码生成而优化的小型语言模型(SLM)组成的代理通过文本自然语言进行交流。
这些代理从代理调度程序(Agent Scheduler)接收目标和对话历史,并根据规则和行动配置指定的行动做出响应。每个代理都有其独特的配置,有助于实现用户目标的整体进展。
工具库(Tools Library)
AutoDev中的工具库提供了一系列命令,使代理能够对资源库执行各种操作。
这些命令旨在将复杂的操作、工具和实用程序封装在简单直观的命令结构中。
例如,通过build和test <test_file>这样的简单命令,就能抽象出与构建和测试执行有关的复杂问题。
-文件编辑:该类别包含用于编辑文件(包括代码、配置和文档)的命令。
-该类别中的实用程序,如写入、编辑、插入和删除,提供了不同程度的精细度。
-代理可以执行从写入整个文件到修改文件中特定行的各种操作。例如,命令 write <filepath> <start_line>-<end_line> <content> 允许代理用新内容重写一系列行。
检索:在这一类别中,检索工具包括grep、find和ls等基本CLI工具,以及更复杂的基于嵌入的技术。
这些技术能让代理查找类似的代码片段,从而提高他们从代码库中检索相关信息的能力。
例如,retrieve <content> 命令允许代理执行与所提供内容类似的基于嵌入的片段检索。
-构建与执行:这类命令允许代理使用简单直观的命令毫不费力地编译、构建和执行代码库。底层构建命令的复杂性已被抽象化,从而简化了评估环境基础架构中的流程。这类命令的示例包括:构建、运行 <文件>。
-测试与验证:这些命令使代理能够通过执行单个测试用例、特定测试文件或整个测试套件来测试代码库。代理可以执行这些操作,而无需依赖特定测试框架的底层命令。
这类工具还包括校验工具,如筛选器和错误查找工具。这类命令的例子包括:检查语法正确性的 syntax <file> 和运行整个测试套件的 test。
-Git:用户可以为Git操作配置细粒度权限。包括提交、推送和合并等操作。例如,可以授予代理只执行本地提交的权限,或者在必要时将更改推送到源代码库。
-通信:代理可以调用一系列旨在促进与其他代理和/或用户交流的命令。值得注意的是,talk命令可以发送自然语言信息(不解释为版本库操作命令),ask命令用于请求用户反馈,而stop命令可以中断进程,表示目标已实现或代理无法继续。
因此,AutoDev中的工具库为人工智能代理提供了一套多功能且易于使用的工具,使其能够与代码库进行交互,并在协作开发环境中进行有效交流。
评估环境(Eval Environment)
评估环境在Docker容器中运行,可以安全地执行文件编辑、检索、构建、执行和测试命令。
它抽象了底层命令的复杂性,为代理提供了一个简化的界面。评估环境会将标准输出/错误返回给输出组织器模块。
整合
用户通过指定目标和相关设置启动对话。
对话管理器初始化一个对话对象,整合来自人工智能代理和评估环境的信息。随后,对话管理器将对话分派给负责协调人工智能代理行动的代理调度器。
作为人工智能代理,语言模型(大型或小型 LM)通过文本互动提出指令建议。
命令界面包含多种功能,包括文件编辑、检索、构建和执行、测试以及 Git 操作。对话管理器会对这些建议的命令进行解析,然后将其引导至评估环境,以便在代码库中执行。
这些命令在评估环境的安全范围内执行,并封装在 Docker 容器中。
执行后,产生的操作将无缝集成到对话历史中,为后续迭代做出贡献。
这种迭代过程一直持续到代理认为任务完成、用户干预发生或达到最大迭代限制为止。
AutoDev 的设计确保了系统、安全地协调人工智能代理,以自主和用户控制的方式完成复杂的软件工程任务。
实证评估设计
在研究人员的实证评估中,评估了AutoDev在软件工程任务中的能力和有效性,研究它是否能够提升人工智能模型的性能,而不仅仅是简单的推理。
此外,研究人员还评估了AutoDev在步骤数、推理调用和token方面的成本。
主要是确定了三个实验研究问题:
-
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

