
- 12024HVV | 护网总结报告模板与实例
- 204-ArkTS语言_基础语法之变量声明+数据类型_arkts声明数组
- 3【史上最本质】序列模型:RNN、双向 RNN、LSTM、GRU、Seq-to-Seq、束搜索、Transformer、Bert_rnn gru lstm和transformer的区别
- 4机器学习—— PU-Learning算法
- 5简述人工智能,及其三大学派:符号主义、连接主义、行为主义_人工智能行为主义
- 6一文带你弄懂Python 文本预处理_对访谈文本的预处理包括
- 7【学习3】一些NLP评价指标及其计算_cider nltk
- 8白天研究生系列:炼丹专题第三集《本地部署大语言模型保姆级教程——以ChatGLM-6B为例》_chatglm4-6b
- 9PyQt5教程(二)——PyQt5的安装(详细)_pyqt5 whl
- 10websocket 实现后端主动前端推送数据、及时通讯(vue3 + springboot)_vue3 websocket消息推送
使用 llamafiles 简化 LLM 执行_llava-v1.5-7b-q4
赞
踩
引言
运行大型语言模型一直是一个繁琐的过程。必须下载一组第三方软件来加载这些 LLM,或者下载 Python 并通过下载大量 Pytorch 和 HuggingFace 库来创建环境。如果通过 Pythonic 方法,则必须完成编写代码才能下载和运行模型的过程。本指南将介绍运行这些 LLM 的更简单方法。
学习目标
● 了解传统LLM执行的挑战
● 把握Llamafiles的创新理念
● 学习轻松下载和运行您自己的 Llamafile 可执行文件
● 学习从量化的 LLM 创建 Llamfile
● 识别此方法的局限性
本文作为数据科学博客马拉松的一部分发布。
目录
● 大型语言模型的问题
● 什么是 Llamafiles?
● One Shot 可执行文件
● 创建 Llamafiles
● OpenAI 兼容服务器
● Llamafiles的局限性
● Llamafiles对比其他方法
● 常见问题解答
大型语言模型的问题
大型语言模型 (LLM) 彻底改变了我们与计算机交互的方式,生成文本、翻译语言、编写不同类型的创意内容,甚至以信息丰富的方式回答您的问题。但是,在计算机上运行这些强大的模型通常具有挑战性。
要运行 LLM,我们必须下载 Python 和大量 AI 依赖项,最重要的是,我们甚至必须编写代码来下载和运行它们。即使在安装了现成的大型语言模型用户界面的情况下,它也涉及许多设置,这很容易出错。像可执行文件一样安装和运行它们并不是一个简单的过程。
什么是 Llamafiles?
Llamafiles 的创建是为了轻松处理流行的开源大型语言模型。这些是单文件可执行文件。这就像下载一个 LLM 并像可执行文件一样运行它。无需初始安装库。这一切都是可能的,因为 llama.cpp 和 cosmopolitan libc,这使得 LLM 在不同的操作系统上运行。
llama.cpp由Georgi Gerganov开发,用于以量化格式运行大型语言模型,因此它们可以在CPU上运行。llama.cpp 是一个 C 库,它允许我们在消费类硬件上运行量化的 LLM。另一方面,cosmopolitan libc 是另一个 C 库,它构建了一个可以在任何操作系统(Windows、Mac、Ubuntu)上运行的二进制文件,而无需解释器。因此,Llamafile 建立在这些库之上,这使得它可以创建单文件可执行的 LLM
可用模型采用 GGUF 量化格式。GGUF是由llama.cpp的创建者Georgi Gerganov开发的大型语言模型文件格式。GGUF 是一种用于在 CPU 和 GPU 上有效且高效地存储、共享和加载大型语言模型的格式。GGUF 使用量化技术将模型从原始的 16 位浮点压缩为 4 位或 8 位整数格式。此量化模型的权重可以以这种 GGUF 格式存储
这使得 70 亿参数模型在具有 16GB VRAM 的计算机上运行变得更加简单。我们可以在不需要 GPU 的情况下运行大型语言模型(尽管 Llamafile 甚至允许我们在 GPU 上运行 LLM)。现在,流行的开源大型语言模型(如 LlaVa、Mistral 和 WizardCoder)的 llamafile 随时可供下载和运行
One Shot 可执行文件
在本节中,我们将下载并尝试运行多模态 LlaVa Llamafile。在这里,我们不会使用 GPU ,而是在 CPU 上运行模型。单击此处并下载 LlaVa 1.5 模型,转到官方 Llamafile GitHub 存储库。
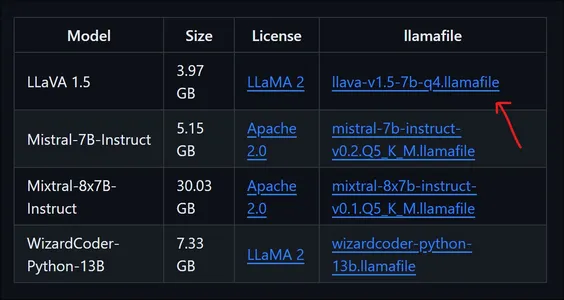
下载模型
上图显示了所有可用的模型及其名称、大小和可下载链接。LlaVa 1.5 的容量仅为 4GB 左右,是一个强大的多模型,可以理解图像。下载的模型是一个量化为到4 位的 70 亿参数模型。下载模型后,转到下载模型的文件夹。

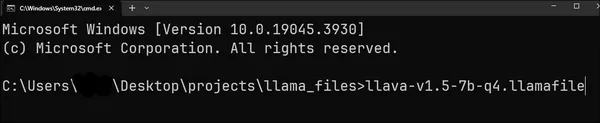
然后打开 CMD,导航到下载此模型的文件夹,键入我们下载的文件的名称,然后按 Enter。
llava-v1.5-7b-q4.llamafile
- 1
对于 Mac 和 Linux 用户
对于 Mac 和 Linux,默认情况下,此文件的执行权限处于关闭状态。因此,我们必须提供 llamafile 的执行权限,我们可以通过运行以下命令来实现。
chmod +x llava-v1.5-7b-q4.llamafile
- 1
这是为了激活 llava-v1.5-7b-q4.llama文件。此外,在文件名前添加“./”以在 Mac 和 Linux 上运行该文件。按 enter 键后,模型将被推送到系统 RAM ,并显示以下输出。

然后浏览器将弹出,模型将在 URL 上运行 http://127.0.0.1:8080/
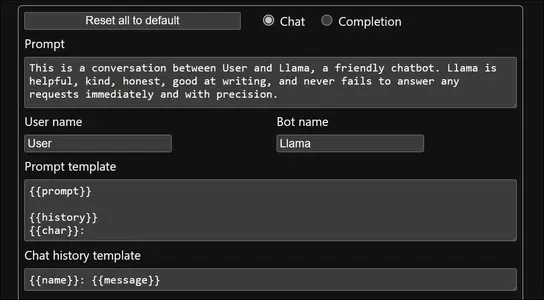
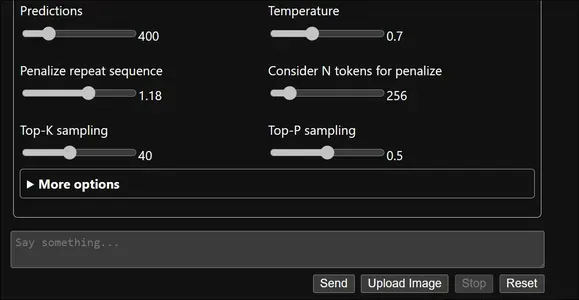
上图显示了默认的提示、用户名、LLM 名称、提示模板和聊天记录模板。这些可以配置,但现在我们将使用默认值进行。
下面,我们甚至可以检查可配置的 LLM 超参数,如 Top P、Top K、Temperature 等。即使是这些,我们暂时也会让它们成为默认的。现在让我们输入一些东西,然后单击发送。
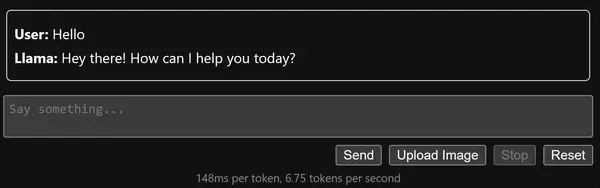
在上图中,我们可以看到我们已经输入了一条消息,甚至收到了回复。在此之下,我们可以检查我们每秒获得大约 6 个标记,考虑到我们完全在 CPU 上运行它,这是一个很好的标记/秒数。这一次,让我们用图像来尝试一下。

虽然不是 100% 正确,但该模型几乎可以从图像中获取大部分内容。现在,让我们与 LlaVa 进行多轮对话,以测试它是否记得聊天记录。

在上图中,我们可以看到 LlaVa LLM 能够很好地进行对话。它可以输入历史对话,然后生成回复。虽然生成的最后一个答案并不完全正确,但它收集了之前的对话来生成这个答案。因此,通过这种方式,我们可以下载一个 llamafile,然后像软件一样运行它,并处理那些下载的模型。
创建 Llamafiles
我们已经看到了官方 GitHub 上已经存在的 Llamafile 演示。通常,我们不想使用这些模型。相反,我们希望创建大型语言模型的单文件可执行文件。在本节中,我们将介绍创建单文件可执行文件的过程,即从量化的 LLM 的创建llama 文件的过程。
选择一个大语言模型
我们将首先选择一个大型语言模型。在本演示中,我们将选择 TinyLlama 的量化版本。在这里,我们将下载 TinyLlama 的 8 位量化 GGUF 模型(您可以点击这里前往HuggingFace 并下载模型)
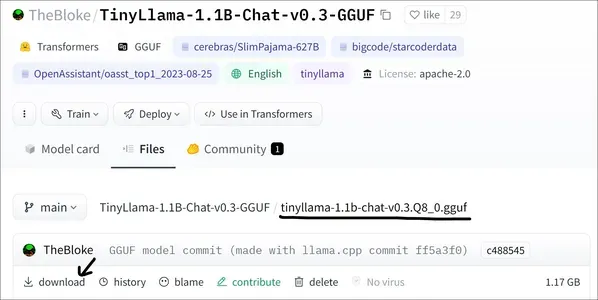
下载最新的 Llamafile
可以从官方 GitHub 链接下载最新的 llamafile 压缩包。此外,下载并解压缩这个压缩包。根据这篇文章的最新更新,本文的当前版本是 llama file-0.6。在解压llama文件之后,bin文件夹将包含如下图所示的文件。

现在将下载的 TinyLlama 8 位量化模型移动到此 bin 文件夹。要创建单文件可执行文件,我们需要在 llamafile 的 bin 文件夹中创建一个 .args 文件。在这个文件中,我们需要添加以下内容:
-m
tinyllama-1.1b-chat-v0.3.Q8_0.gguf
--host
0.0.0.0
...
- 1
- 2
- 3
- 4
- 5
● 第一行表示 -m 标志。这告诉 llamafile 我们正在加载模型的权重。
● 在第二行中,我们指定已下载的模型名称,该名称位于 .args 文件所在的同一目录中,即 llamafile 的 bin 文件夹。
● 在第三行中,我们添加了 host 标志,表示我们运行可执行文件并希望将其托管到 Web 服务器。
● 最后,在最后一行中,我们提到了我们想要托管的地址,该地址映射到 localhost。接下来是三个点,它们指定我们可以在创建 llamafile 后将参数传递给它。
● 将这些行添加到 .args 文件并保存。
对于Windows用户
现在,下一步是针对 Windows 用户。如果在 Windows 上工作,我们需要通过 WSL 安装 Linux。如果没有,请单击此处完成通过 WSL 安装 Linux 的步骤。在 Mac 和 Linux 中,不需要其他步骤。现在在终端中打开 llamafile 文件夹的 bin 文件夹(如果在 Windows 上工作,请在 WSL 中打开此目录)并键入以下命令。
cp llamafile tinyllama-1.1b-chat-v0.3.Q8_0.llamafile
- 1
在这里,我们将创建一个名为 tinyllama-1.1b-chat-v0.3.Q3_0.llamafile 的新文件;也就是说,我们正在创建一个扩展名为 .llamafile 的文件,并将文件 llamafile 移动到这个新文件中。现在,在此之后,我们将输入下一个命令。
./zipalign -j0 tinyllama-1.1b-chat-v0.3.Q8_0.llamafile tinyllama-1.1b-chat-v0.3.Q8_0.gguf .args
- 1
在这里,我们使用从 GitHub 下载 llamafile zip 时附带的 zipalign 文件。我们使用此命令为量化的 TinyLlama 创建 llamafile。对于这个 zipalign 命令,我们传入了我们在上一步中创建的 tinyllama-1.1b-chat-v0.3.Q8_0.llama文件,然后我们传入了 bin 文件夹中的 tinyllama-1.1b-chat-v0.3.Q8_0.llamafile 模型,最后传入了我们之前创建的 .args 文件。
这将最终生成我们的单个文件可执行文件 tinyllama-1.1b-chat-v0.3.Q8_0.llama文件。为确保我们在同一页面上,bin 文件夹现在包含以下文件。

现在,我们可以像以前一样运行 tinyllama-1.1b-chat-v0.3.Q8_0.llama 文件。在 Windows 中,您甚至可以将 .llamafile 重命名为 .exe 并通过双击它来运行它。
OpenAI 兼容服务器
本节将研究如何通过 Llamfile 服务器 LLM。我们注意到,当我们运行 llama 文件时,浏览器会打开,我们可以通过 WebUI 与 LLM 进行交互。这基本上就是我们所说的托管大型语言模型。
运行 Llamafile 后,我们可以与相应的 LLM 作为端点进行交互,因为该模型是在 PORT 8080 的本地主机上提供的。服务器遵循 OpenAI API 协议,即类似于 OpenAI GPT Endpoint,因此可以轻松地在 OpenAI GPT 模型和使用 Llamafile 运行的 LLM 之间切换。
在这里,我们将运行之前创建的 TinyLlama llamafile。现在,这必须在 localhost 8080 上运行。我们现在将在 Python 中通过 OpenAI API 本身对其进行测试
from openai import OpenAI
client = OpenAI(
base_url="http://localhost:8080/v1",
api_key = "sk-no-key-required"
)
completion = client.chat.completions.create(
model="TinyLlama",
messages=[
{"role": "system", "content": "You are a usefull AI \
Assistant who helps answering user questions"},
{"role": "user", "content": "Distance between earth to moon?"}
]
)
print(completion.choices[0].message.content)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
● 在这里,我们使用 OpenAI 库。但是,我们没有指定 OpenAI 端点,而是指定托管 TinyLlama 的 URL,并为api_key提供“sk-no–token-required”
● 然后,客户端将连接到我们的 TinyLlama 端点
● 现在,类似于我们使用 OpenAI 的方式,我们可以使用代码与我们的 TinyLlama 聊天。
● 为此,我们使用 OpenAI 的 completions 类。我们使用 .create() 对象创建新的补全,并传递模型名称和消息等详细信息。
● 消息采用字典列表的形式,我们在其中具有角色,可以是系统、用户或助手,并且我们具有内容。
● 最后,我们可以检索通过上面的 print 语句生成的信息。
上面的输出可以在下面看到。

这样,我们就可以利用 llamafile 并轻松地将 OpenAI API 替换为我们选择运行的 llamafile。
Llamafiles的局限性
虽然是革命性的,但 llamafiles 仍在开发中。一些限制包括:
● 有限的型号选择:目前,并非所有 LLM 都以 llamafiles 的形式提供。目前预构建的 Llamafiles 选择仍在增长。目前,Llamafiles 可用于 Llama 2、LlaVa、Mistral 和 Wizard Coder。
● 硬件要求:运行 LLM,即使通过 Llamafiles,仍然需要大量的计算资源。虽然它们比传统方法更易于运行,但较旧或功能较弱的计算机可能需要帮助才能顺利运行它们。
● 安全问题:从不受信任的来源下载和运行可执行文件会带来固有的风险。因此,必须有一个值得信赖的平台,我们可以在其中下载这些 llamafiles。
Llamafiles对比其他方法
在 Llamafiles 之前,有不同的方法可以运行大型语言模型。一个是通过llama_cpp_python。这是 llama.cpp 的 Python 版本,它允许我们在笔记本电脑和台式电脑等消费类硬件上运行量化的大型语言模型。但要运行它,我们必须下载并安装 Python,甚至深度学习库,如 torch、huggingface、transformers 等等。之后,它涉及编写许多行代码来运行模型。
即便如此,有时我们也可能会遇到由于依赖问题而出现的问题(即,某些库的版本低于或高于必要的版本)。还有 CTransformers 库,它允许我们运行量化的 LLM。即使这需要我们讨论过的相同过程llama_cpp_python
然后,还有奥拉玛。Ollama 在 AI 社区中取得了巨大的成功,因为它易于使用,可以轻松加载和运行大型语言模型,尤其是量化模型。Ollama 是一种用于 LLM 的 TUI(终端用户界面)。Ollama 和 Llamafile 之间的唯一区别是可共享性。也就是说,如果需要,那么我可以与任何人共享我的 model.llama文件,他们可以在不下载任何其他软件的情况下运行它。但是在 Ollama 的情况下,我需要共享 model.gguf 文件,其他人只有在安装 Ollama 软件或通过上述 Python 库时才能运行该文件。
关于资源,它们都需要相同数量的资源,因为所有这些方法都使用下面的 llama.cpp 来运行量化模型。这只是关于它们之间存在差异的易用性。
结论
Llamafiles 标志着在使 LLM 易于运行方面迈出了关键的一步。它们的易用性和可移植性为开发人员、研究人员和临时用户开辟了一个充满可能性的世界。虽然存在局限性,但 llamafiles 使 LLM 访问民主化的潜力是显而易见的。无论您是专业开发人员还是好奇的新手,Llamafiles 都为探索 LLMs.In 世界提供了令人兴奋的可能性,在本指南中,我们了解了如何下载 Llamafiles,甚至如何使用我们的量化模型创建我们自己的 Llamafiles。我们甚至看了一下运行 Llamafiles 时创建的 OpenAI 兼容服务器。
关键要点
● Llamafile 是单文件可执行文件,使运行大型语言模型 (LLM) 更容易、更容易获得。
● 它们消除了对复杂设置和配置的需求,允许用户直接下载和运行 LLM,而无需 Python 或 GPU 要求。
● Llamafiles 现在可用于有限的开源 LLM,包括 LlaVa、Mistral 和 WizardCoder。
● 虽然方便,但 Llamafiles 仍然存在局限性,例如与从不受信任的来源下载可执行文件相关的硬件要求和安全问题。
● 尽管存在这些限制,但 Llamafiles 代表了开发人员、研究人员甚至临时用户实现 LLM 访问民主化的重要一步。
常见问题解答
问题1.使用 Llamafiles 有什么好处?
答:与传统的LLM配置方法相比,Llamafiles具有几个优点。它们使 LLM 的设置和执行更容易、更快捷,因为您不需要安装 Python 或拥有 GPU。这使得 LLM 更容易被更广泛的受众使用。此外,Llamafiles 可以跨不同的操作系统运行。
问题2.Llamafiles 的局限性是什么?
一个。虽然 Llamafiles 提供了许多好处,但它们也有一些局限性。与传统方法相比,Llamafiles 中可用的 LLM 选择有限。此外,通过 Llamafiles 运行 LLM 仍然需要大量的硬件资源,而较旧或功能较弱的计算机可能不支持它。最后,安全问题与从不受信任的来源下载和运行可执行文件有关。
问题3.如何开始使用 Llamafiles?
一个。要开始使用 Llamafiles,您可以访问官方 Llamafile GitHub 存储库。在那里,您可以下载要使用的 LLM 模型的 Llamafile。下载文件后,您可以像执行文件一样直接运行它。
问题4.我可以在 Llamafiles 中使用我自己的 LLM 模型吗?
答:不可以。目前,Llamafiles 仅支持特定的预构建模型。计划在未来的版本中创建我们自己的 Llamafile。
问题5.Llamafiles的前景如何?
一个。Llamafiles 的开发人员正在努力扩大可用 LLM 模型的选择范围,更有效地运行它们,并实施安全措施。这些进步旨在使 Llamafiles 对更多技术背景不足的人来说更加可用和安全。
本文中显示的媒体不归 Analytics Vidhya 所有,由作者自行决定使用。
文章来源:https://www.analyticsvidhya.com/blog/2024/01/using-llamafiles-to-simplify-llm-execution/


