
- 1【3D目标分类】PCT:Point Cloud Transformer
- 2【人工智能】NIPS2019 | 2019NIPS论文 | NeurIPS2019最新更新论文~持续更新| NIPS2019百度云下载_a tensorized transformer for language modeling代码
- 3让照片人张嘴唱 rap,阿里发布图生视频 EMO 框架,却因零代码上 GitHub 引争议!...
- 4linux下LTP的安装和配置_ltp linux
- 5关于用gradle构建spring源码环境的多次尝试_spring orm 源码 报错
- 64-LVI-SAM源码分析体会_1_lvisam
- 7基于YOLOv8/YOLOv7/YOLOv6/YOLOv5的水果新鲜程度检测系统(深度学习模型+UI界面代码+训练数据集)_基于深度学习的水果识别系统(网页版+yolov8/v7/v6/v5代码+训练数据集)
- 8用函数实现求所有(50~100)之间素数的和_python 使用函数求素数和
- 9Air724UG 4G LTE 模块AT指令连接服务器_air724ug多ip连接
- 10pytorch实现resnet50(训练+测试+模型转换)_pytorch resnet50预训练模型
CVPR:使用完全交叉Transformer的小样本目标检测
赞
踩
关注并星标
从此不迷路
计算机视觉研究院


公众号ID|ComputerVisionGzq
学习群|扫码在主页获取加入方式

论文地址:
https://openaccess.thecvf.com/content/CVPR2022/papers/Han_Few-Shot_Object_Detection_With_Fully_Cross-Transformer_CVPR_2022_paper.pdf
计算机视觉研究院专栏
作者:Edison_G
小样本目标检测 (FSOD) 旨在使用很少的训练示例检测新目标,最近在社区中引起了极大的研究兴趣。
01
概述
小样本目标检测 (FSOD) 旨在使用很少的训练示例检测新目标,最近在社区中引起了极大的研究兴趣。已经证明基于度量学习的方法使用基于双分支的孪生网络对这项任务有效,并计算图像区域和少样本示例之间的相似性以进行检测。
然而,在之前的工作中,两个分支之间的交互只限于检测头,而剩下的数百层用于单独的特征提取。受最近关于视觉转换器和视觉语言转换器的工作的启发,研究者提出了一种新颖的基于完全交叉转换器(Fully Cross-Transformer)的FSOD模型 (FCT),方法是将交叉转换器整合到特征主干和检测头中。提出了非对称批处理交叉注意来聚合来自具有不同批处理大小的两个分支的关键信息。新模型可以通过引入多级交互来改善两个分支之间的少样本相似性学习。PASCAL VOC和MSCOCO FSOD基准的综合实验证明了我们模型的有效性。
02
背景
以往小样本检测方法大致可以分为俩类:single-branch方法和two-branch方法;前者通常是基于Faster RCNN进行finetuned,需构建multi-class classifier;但该方法针对shot比较少例如1-shot时,较为容易出现过拟合情况;而后者通常时构建siamese网络,分别同时提取query特征和support特征,然后基于metric learning方法比如feature fusion,feature alignment,GCN或者non-local attention来计算俩分支的相似性,由于在Novel类别上无需构建multi-class classifier,所以泛化性更好;俩类方法大致差异如下图所示:

03
新框架
Task Definition
在小样本目标检测(FSOD)中,有两组类C=Cbase∪Cnovel和Cbase∩Cnovel=∅,其中基类Cbase每个类都有大量训练数据,而新类Cnovel(也称为支持类)只有每个类的训练示例很少(也称为支持图像)。对于K-shot(例如,K=1,5,10)目标检测,研究者为每个新类别c∈Cnovel准确地使用K个边界框注释作为训练数据。FSOD的目标是利用数据丰富的基类来协助检测少样本的新类。
Overview of Our Proposed Model (FCT)
研究者认为以往的two-branch方法只关注了detection head部分的特征交互,忽略了特征提取部分;于是这篇论文的motivation就出来了。因此研究者在Faster RCNN上提出了Fully Cross-Transformer(FCT)的小样本检测方法,在每个阶段都进行特征交互。如下图所示:
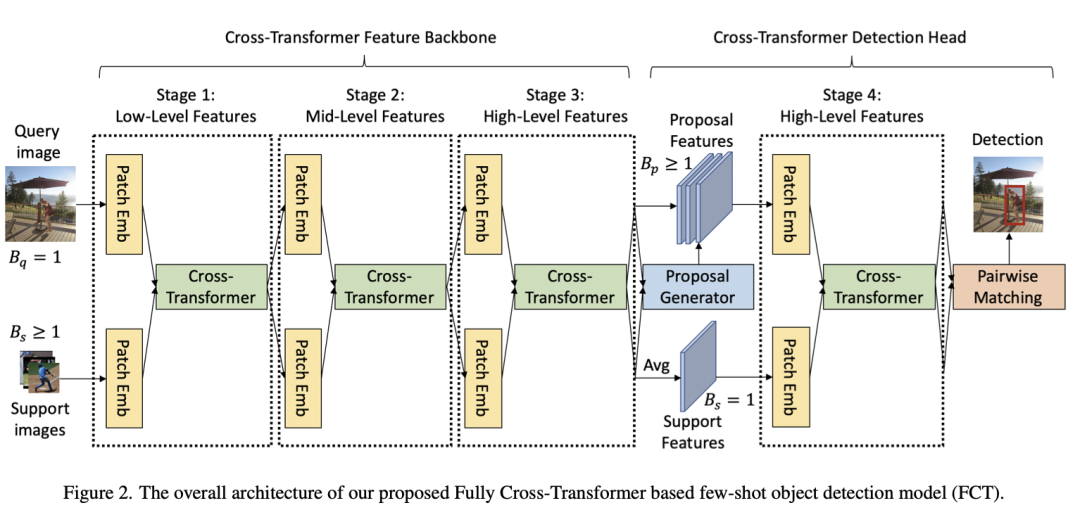
The Cross-Transformer Feature Backbone
在cross-transformer中计算Q-K-V attention时为了减少计算量,研究者采用了PVTv2的方式。上面大致介绍了query和support特征提取,在特征交互上作者提出了 Asymmetric-Batched Cross-Attention。具体做法如下图和公式所示:
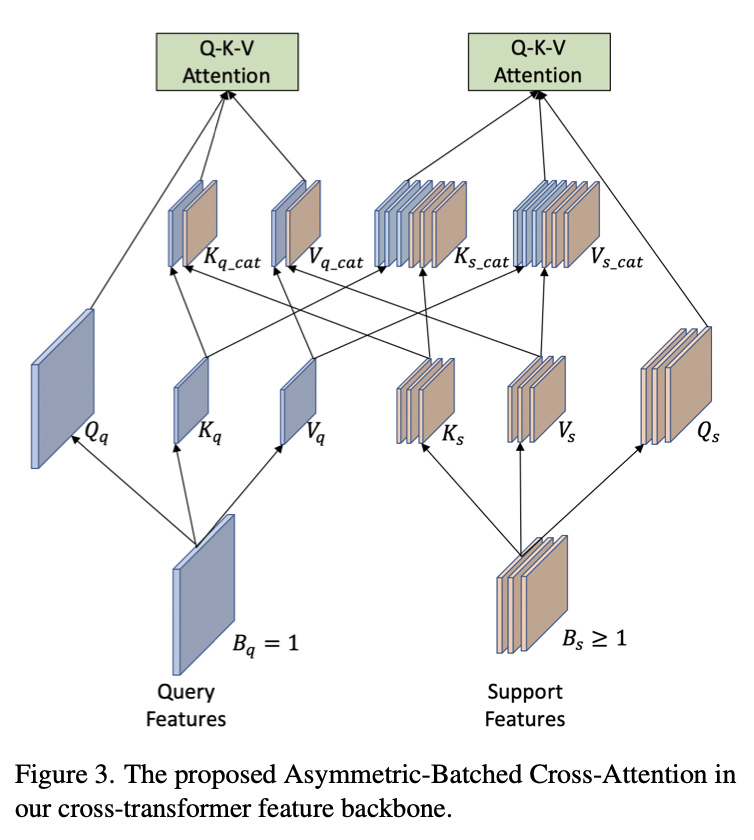
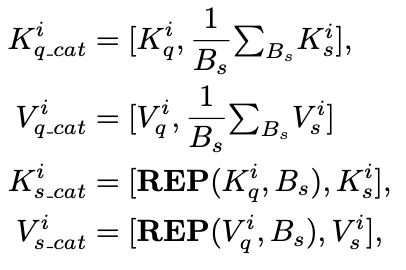
评论。研究者彻底研究了提出的模型中两个视觉分支之间的多层次交互。cross-transformer特征主干中的三个阶段使两个分支与低级、中级和高级视觉特征逐渐有效交互。
The Cross-Transformer Detection Head
在detection head部分,和以上操作相反,在每张query上提取完proposal之后经过ROI Align可以得到ROI特征fp∈RBp∗H′∗W′∗C3,其中Bp=100,为了减少计算复杂度还是对support进行ave操作fs′=1Bs∑Bsfs,fs′∈R1∗H′∗W′∗C3,然后使用Asymmetric-Batched Cross-Attention计算俩分支attention,不同的是,query分支Bp≥1 and Bs′=1 。
04
实验
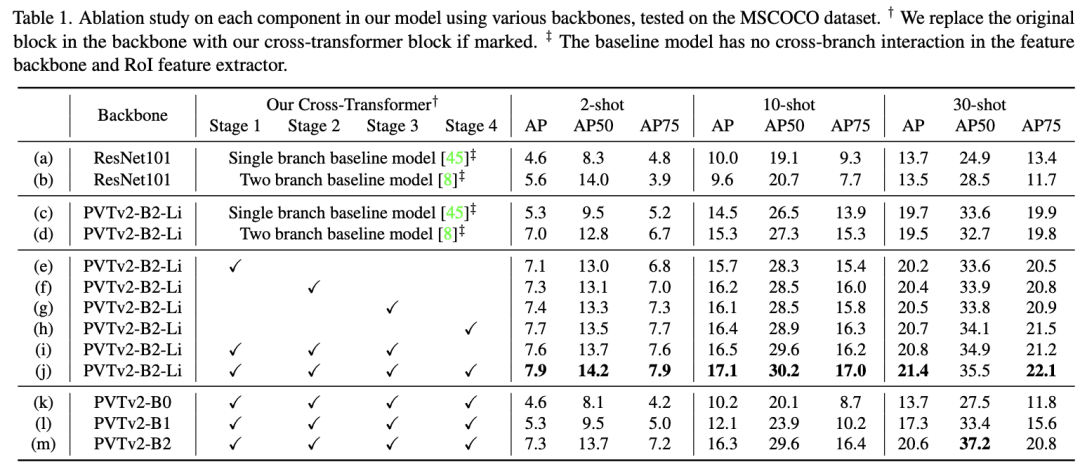
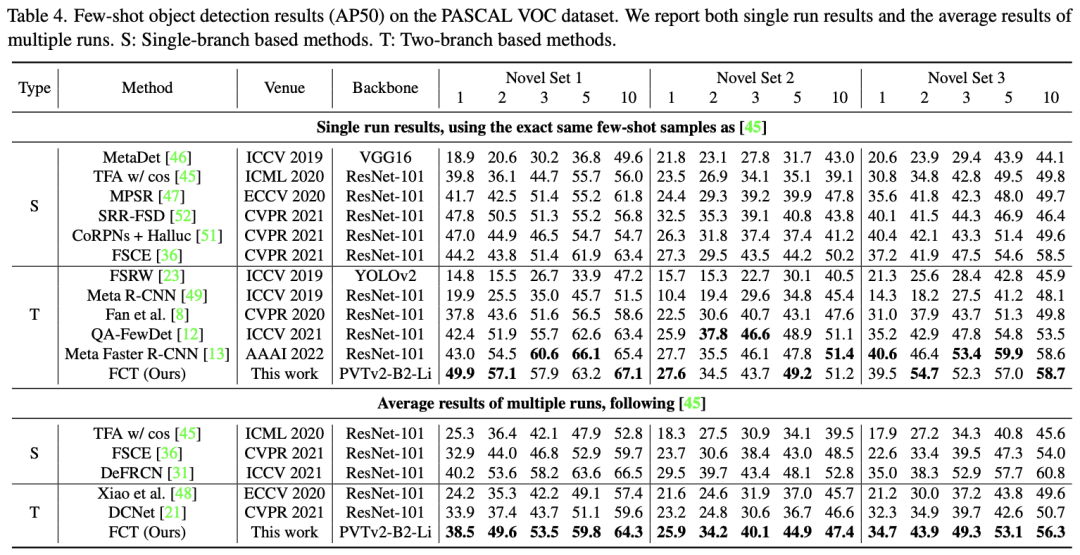
从上面表格的(c-d)俩行可以看出,使用三阶段训练在2-shot、10-shot上均有提升。

© THE END
转载请联系本公众号获得授权

计算机视觉研究院学习群等你加入!
ABOUT
计算机视觉研究院
计算机视觉研究院主要涉及深度学习领域,主要致力于人脸检测、人脸识别,多目标检测、目标跟踪、图像分割等研究方向。研究院接下来会不断分享最新的论文算法新框架,我们这次改革不同点就是,我们要着重”研究“。之后我们会针对相应领域分享实践过程,让大家真正体会摆脱理论的真实场景,培养爱动手编程爱动脑思考的习惯!
VX:2311123606

往期推荐
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

