
- 1字节跳动自研 OpenBMC 方案成功上线,STE 团队工程师都做了哪些事?
- 2AIML框架 & 初探_aiml官网
- 3自动驾驶软件有哪些功能?自动驾驶用到哪些AI算法?_自动驾驶算法在自动驾驶中充当什么作用
- 4教你用ChatGPT写论文(技巧干货)_如何让chatgpt写法学论文
- 5自然语言处理学习篇01——Basic Text Processing_regular expressions how can we search for any of t
- 6AI智能阅读神器,让你快速提取文献关键信息_如何通过ai快速查找制度内容
- 7【2023·CANN训练营第一季】昇腾Al计算平台CANN的逻辑架构_海光信息昇腾cann架构
- 8详解‘unicodeescape‘ codec can‘t decode bytes in position 16-17: malformed \N character escape
- 9ROS系统——部署OpenVINO版Nanodet超轻量目标检测器_ros 轻量化目标识别
- 10食品与疾病关系预测算法赛道-baseline食品与疾病关系预测算法赛道-baseline
谷歌大模型Gemma介绍、微调、量化和推理
赞
踩

谷歌的最新的Gemma模型是第一个使用与Gemini模型相同的研究和技术构建的开源LLM。这个系列的模型目前有两种尺寸,2B和7B,并且提供了聊天的基本版和指令版。
用一句话来总结Gemma就是:学习了Llama 2和Mistral 7B的优点,使用了更多的Token和单词进行了训练了一个更好的7B(8.5B)模型。所以这篇文章我们将介绍Gemma模型,然后展示如何使用Gemma模型,包括使用QLoRA、推理和量化微调。
Gemma 7B 其实是 8.5B
1、模型细节
谷歌的发布这份技术报告中提供了模型的更多细节
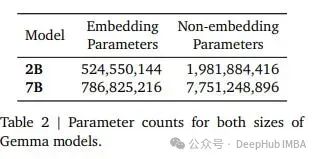
可以看到Google总结了每个模型的参数数量,并且区分了嵌入参数和非嵌入参数。对于7B模型,有7.7B个非嵌入参数。如果考虑参数总数,Gemma 7B有8.54B个参数…
相比之下Gemma更接近9B。将Gemma作为“7B”LLM发布可以算是一种误导,但这也很好理解,因为肯定希望将自己的LLM与之前发布的7B进行比较,而更多的参数往往意味着更好的性能,对吧。
为了便于比较,我们总计了其他流行的“7B”模型的参数总数:
Llama 2 7B: 6.74B
Mistral 7B: 7.24B
Qwen-1.5 7B: 7.72B
Gemma 7B: 8.54B
可以看到,其实Gemma 7B比Llama 2 7B多1.8B个参数,按照参数越多,性能越好的理论,Gemma 比其他模型好是必然的。
在google的报告中还详细介绍了模型的架构:
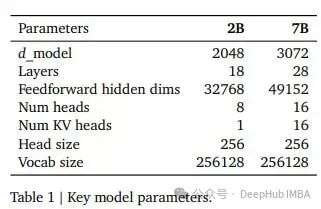
可以处理多达8k个令牌的上下文。为了高效扩展,他们使用了multi-query attention和RoPE嵌入,并且兼容FlashAttention-2。
Gemma的嵌入词表是目前开源模型中最大的,有256k个。它比Llama 2的词汇量大8倍,比Qwen-1.5的词汇量大1.7倍,而Qwen-1.5的词汇量已经被认为非常大了。除了词汇表大小之外,Gemma架构非常标准。更大的嵌入词表通常意味着模型被训练成多语言的。但是谷歌却说这些模型主要是为英语任务训练的。
但是根据目前发布的模型来看,谷歌确实在涵盖多种语言的数据上训练了模型,如果针对多语言任务进行微调应该会产生良好的性能。
2、Gemma的训练数据
Gemma 2B和7B分别接受了2万亿个和6万亿个token的训练。这意味着Gemma 7B接受的token比Llama 2多3倍。这里猜测原因如下:
由于词汇表非常大,需要对模型进行更长的训练,以便更好地学习词汇表中所有标记的嵌入。扩大训练的token后损失应该还是降低的,这也与词汇表非常大相对应。我们可以这么理解词汇表越大,可能需要的训练token就越多,当然可能表现就会越好。
对于模型的指令版本,他们对由人类和合成数据组成的指令数据集进行了监督微调,然后进行了基于人类反馈的强化学习(RLHF)。

3、公共测试数据上的表现
谷歌在标准基准上对Gemma进行了评估,并将结果与Llama 2(在论文中拼写为lama -2…)和Mistral 7B进行了比较。
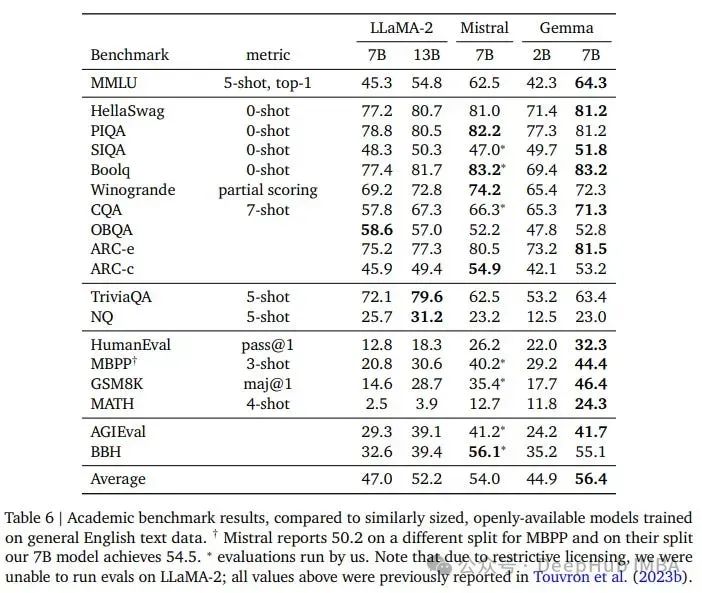
在大多数任务中,Gemma 7B比其他模型获得了更好的分数。但是这里有2个问题:
1、我们还是要对这些基准分数持保留态度。因为谷歌没有告诉我们是如何计算这些分数的。
2、还是模型参数问题,8.5B理论上应该就会比7B要好,所以分数提高是很正常的
本地运行Gemma 2B和7B
Hugging Face的Transformers和vLLM都已经支持Gemma模型,硬件的要求是18gb GPU。
我们先介绍vLLM
- import time
- from vllm import LLM, SamplingParams
- prompts = [
- "The best recipe for pasta is"
- ]
- sampling_params = SamplingParams(temperature=0.7, top_p=0.8, top_k=20, max_tokens=150)
- loading_start = time.time()
- llm = LLM(model="google/gemma-7b")
- print("--- Loading time: %s seconds ---" % (time.time() - loading_start))
- generation_time = time.time()
- outputs = llm.generate(prompts, sampling_params)
- print("--- Generation time: %s seconds ---" % (time.time() - generation_time))
- for output in outputs:
- generated_text = output.outputs[0].text
- print(generated_text)
- print('------')

然后是Transformers
- import torch
- from transformers import AutoTokenizer, AutoModelForCausalLM, set_seed
- set_seed(1234) # For reproducibility
- prompt = "The best recipe for pasta is"
- checkpoint = "google/gemma-7b"
- tokenizer = AutoTokenizer.from_pretrained(checkpoint)
- model = AutoModelForCausalLM.from_pretrained(checkpoint, torch_dtype=torch.float16, device_map="cuda")
- inputs = tokenizer(prompt, return_tensors="pt").to('cuda')
- outputs = model.generate(**inputs, do_sample=True, max_new_tokens=150)
- result = tokenizer.decode(outputs[0], skip_special_tokens=True)
- print(result)
使用起来都是很简单的,与其他的开源模型基本一样。
Gemma 7B的量化
AutoGPTQ和AutoAWQ是GPTQ和AWQ量化最常用的两个库,但在目前(2.29)它们并不支持Gemma。所有我们只能用bitsandbytes NF4量化Gemma 7B。
GGUF格式的块量化也可以用llama.cpp完成。Google在与原始版本相同的存储库中发布了Gemma的GGUF版本。
经过bitsandbytes量化Gemma 7B仍然需要7.1 GB的GPU RAM。所以还是那句话 这个“7B”的叫法是不是正确的呢?
以下是量化加载和推理的代码
- import torch
- from transformers import AutoTokenizer, AutoModelForCausalLM, set_seed, BitsAndBytesConfig
-
- set_seed(1234) # For reproducibility
- prompt = "The best recipe for pasta is"
- checkpoint = "google/gemma-7b"
- compute_dtype = getattr(torch, "float16")
- bnb_config = BitsAndBytesConfig(
- load_in_4bit=True,
- bnb_4bit_quant_type="nf4",
- bnb_4bit_compute_dtype=compute_dtype,
- bnb_4bit_use_double_quant=True,
- )
- tokenizer = AutoTokenizer.from_pretrained(checkpoint)
- model = AutoModelForCausalLM.from_pretrained(checkpoint, quantization_config=bnb_config, device_map="cuda")
- inputs = tokenizer(prompt, return_tensors="pt").to('cuda')
- outputs = model.generate(**inputs, do_sample=True, max_new_tokens=150)
- result = tokenizer.decode(outputs[0], skip_special_tokens=True)
- print(result)
使用QLORA对Gemma 7B进行微调
bitsandbytes量化已经可以正常使用,所以我们可以用QLoRA对Gemma 7B进行微调。当然如果使用很小的训练批大小和较短的max_seq_length,也可以在消费者硬件上使用LoRA(即不进行量化)对Gemma 7B进行微调。
以下是我使用Gemma 7B测试QLoRA微调的代码:
- import torch
- from datasets import load_dataset
- from peft import LoraConfig, PeftModel, prepare_model_for_kbit_training
- from transformers import (
- AutoModelForCausalLM,
- AutoTokenizer,
- BitsAndBytesConfig,
- AutoTokenizer,
- TrainingArguments,
- )
- from trl import SFTTrainer
-
- model_name = "google/gemma-7b"
- #Tokenizer
- tokenizer = AutoTokenizer.from_pretrained(model_name, add_eos_token=True, use_fast=True)
- tokenizer.pad_token = tokenizer.eos_token
- tokenizer.pad_token_id = tokenizer.eos_token_id
- tokenizer.padding_side = 'left'
- ds = load_dataset("timdettmers/openassistant-guanaco")
- compute_dtype = getattr(torch, "float16")
- bnb_config = BitsAndBytesConfig(
- load_in_4bit=True,
- bnb_4bit_quant_type="nf4",
- bnb_4bit_compute_dtype=compute_dtype,
- bnb_4bit_use_double_quant=True,
- )
- model = AutoModelForCausalLM.from_pretrained(
- model_name, quantization_config=bnb_config, device_map={"": 0}
- )
- model = prepare_model_for_kbit_training(model)
- #Configure the pad token in the model
- model.config.pad_token_id = tokenizer.pad_token_id
- model.config.use_cache = False # Gradient checkpointing is used by default but not compatible with caching
- peft_config = LoraConfig(
- lora_alpha=16,
- lora_dropout=0.05,
- r=16,
- bias="none",
- task_type="CAUSAL_LM",
- target_modules= ['k_proj', 'q_proj', 'v_proj', 'o_proj', "gate_proj", "down_proj", "up_proj"]
- )
- training_arguments = TrainingArguments(
- output_dir="./results_qlora",
- evaluation_strategy="steps",
- do_eval=True,
- optim="paged_adamw_8bit",
- per_device_train_batch_size=4,
- per_device_eval_batch_size=4,
- log_level="debug",
- save_steps=50,
- logging_steps=50,
- learning_rate=2e-5,
- eval_steps=50,
- max_steps=300,
- warmup_steps=30,
- lr_scheduler_type="linear",
- )
- trainer = SFTTrainer(
- model=model,
- train_dataset=ds['train'],
- eval_dataset=ds['test'],
- peft_config=peft_config,
- dataset_text_field="text",
- max_seq_length=512,
- tokenizer=tokenizer,
- args=training_arguments,
- )
- trainer.train()
300个训练步(训练批大小为4个)需要不到1小时。
总结
许多框架已经很好地支持Gemma模型,GPTQ和AWQ的量化也将很快就会发布的,经过量化后可以在8gb GPU上使用Gemma 7B。
不可否认发布Gemma模型是谷歌前进的一步。Gemma 7B看起来是Mistral 7B的一个很好的竞争对手,但我们不要忘记它也比Mistral 7B多10亿个参数。另外我一直没想明白Gemma 2B的用例是什么,它的性能被其他类似尺寸的模型超越了(这个2B可能就真是2B了),并且可以看到谷歌这俩模型参数少的性能不行,性能好的参数又多很多。这种文字游戏说明谷歌在AI赛道上的确使落后并且着急了,而且目前还没有任何的办法进行超越。
这里是谷歌官方发布的gemma-report,有兴趣的可以查看
https://storage.googleapis.com/deepmind-media/gemma/gemma-report.pdf
作者:Benjamin Marie
公众号:AI蜗牛车
保持谦逊、保持自律、保持进步

发送【蜗牛】获取一份《手把手AI项目》(AI蜗牛车著)
发送【1222】获取一份不错的leetcode刷题笔记
发送【AI四大名著】获取四本经典AI电子书


