
- 1SSE使用详解及浏览器连接限制问题解决_sseemitter连接大模型超时
- 2Unity2019+ 版本JDK配置常见问题_unity jdk
- 3js中多并发的一些处理方法
- 4Camunda工作流网关(一)-Exclusive Gateway(独占网关或排他网关)_camunda 排他网关
- 5AI时代产品经理升级之道:ChatGPT让产品经理插上翅膀_ai时代产品经理升级之道:chatgpt让产品经理插上翅膀书籍下载
- 6Unable to load io.netty.resolver.dns.macos.MacOSDnsServerAddressStreamProvider解决
- 7appium iOS 真机之坑_encountered internal error running command: error:
- 8Android 屏幕万能自适应(自定义适配)_apk自适应屏幕代码
- 9第三十六讲:神州无线AP胖AP模式配置与管理_胖ap怎么设置上网啊
- 10瞬间让你的浏览器不一样, Chrome浏览器主题美化插件 - 高级感图标精美画面流畅 iTab插件,_chrome主题插件
自动机器学习AutoML_autodl增强学习落地方案
赞
踩
【研究背景】随着深度神经网络的不断发展,各种模型和新颖模块的不断发明利用,人们逐渐意识到开发一种新的神经网络结构越来越费时费力,为什么不让机器自己在不断的学习过程中创造出新的神经网络呢?
正是出于这个构思,2017年Google推出了AutoML,一个能自主设计深度神经网络的AI网络。自此,人工智能又有了更进一步的发展,人们开始探索如何利用已有的机器学习知识和神经网络框架来让人工智能自主搭建适合业务场景的网络,从而减少人工的参与,让机器完成更复杂的工作,人工智能的另一扇大门被打开。
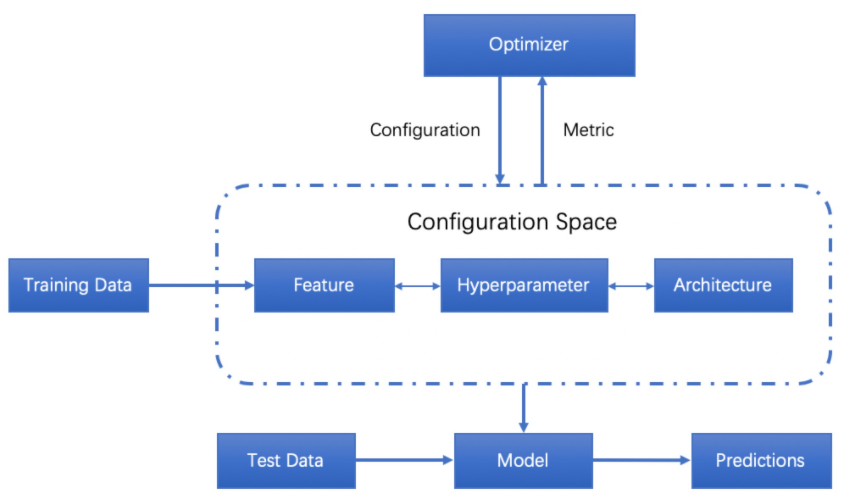
而该技术的发布主要依赖以下两个技术:
- 迁移学习(transfer learning)——运用一种神经网络,处理其他相似任务,比如一个训练的差不多的CNN,可以识别猫也可以稍加再次训练识别红绿灯,这个对模型和数据的要求都较高。
- 神经架构搜索——之前的AutoML用的是增强学习(迭代)+RNN生成的方法,实际上针对的是CNN的网络结构,用深度学习调参来训练确定网络构架。
(1)使用循环神经网络生成模型描述:用控制器生成神经网络架构的超参数,为了灵活性,控制器选择为循环神经网络。
下图为预测只具有卷积层的前馈神经网络,控制器将生成的超参数看作一系列符号,在实验中,如果网络的层数超过一定值,则生成架构会停止,该值遵循一定的策略,并随着训练过程增加。一旦控制器RNN完成了架构的生成,就开始构建并训练具有该架构的神经网络。在网络收敛之后,记录网络在验证集中的准确率,并对控制器RNN的参数进行优化,以使控制器所提出的架构的预期验证准确率最大化。
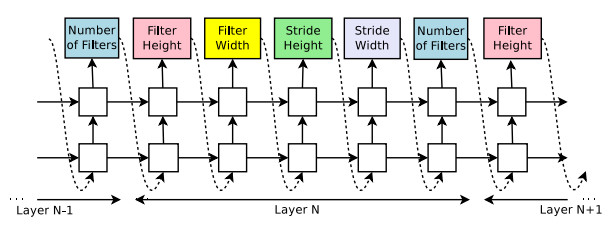
(2)使用强化学习进行训练:控制器预测的模型描述可以被看作设计子网络的一系列action。在训练子网络收敛之后,该子网络会在保留数据集上得到一个准确度R,使用该准确度R作为reward信号,并使用强化学习训练控制器。
【实现原理】
AutoML用的是神经网络搜索,(该论文也是出自李飞飞老师学生之手),有点类似于决策树,从简单单元开始,逐步堆叠网络结构——实际上用的是蒙特卡洛树搜索的思想,我们的方法类似于 A* 算法(也被称为分支限界法)。
步骤:从简单到复杂搜索模型空间,并在前进过程中剪枝处理掉没有前途的模型。这些模型(单元)按照它们所包含的模块的数量进行排序。我们从考量带有一个模块的单元开始,评估这些单元(通过训练它们并在一个验证集上计算它们的损失),然后使用观察得到的奖励来训练一个基于 RNN 的启发式函数(也被称为代理函数),可以预测任何模型的奖励。最后可以使用这个学习到的启发式函数来决定应该评估哪些带有 2 个模块的单元,在对它们进行了评估之后,再对这个启发式函数进行更新。重复这一过程,直到我们找到带有所想要的模块数量的优良单元。

用户只要提供数据,自动机器学习系统将自动的决定最佳的方案,领域专家不再需要苦恼于学习各种机器学习的算法。自动机器学习不光包括大家熟知的算法选择,超参数优化,和神经网络架构搜索,还覆盖机器学习工作流的每一步:
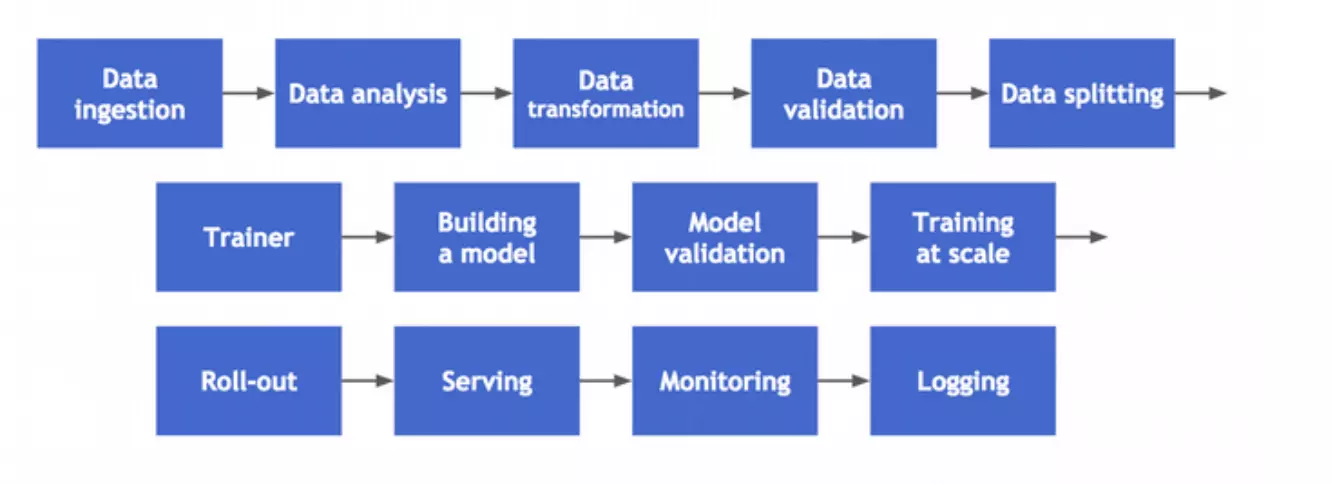
Machine learning (ML) has achieved considerable successes in recent years and an ever-growing number of disciplines rely on it. However, this success crucially relies on human machine learning experts to perform the following tasks:
- Preprocess and clean the data.
- Select and construct appropriate features.
- Select an appropriate model family.
- Optimize model hyperparameters.
- Postprocess machine learning models.
- Critically analyze the results obtained.
【技术亮点】
-
自动化程度
Jeff Dean在ICML 2019上进行了有关AutoML的演讲,并将自动化分为4个级别:
(1)手动构造预测变量,不引入学习的步骤;
(2)手工选择特征,学习预测。引入自动化超参数调优(HPO)工具,例如Hyperopt,Optuna,SMAC3,scikit-optimize等;
(3)手工构造算法,端到端学习特征和预测。除了HPO外,还有其他一些工具,例如featuretools,tsfresh,boruta等;
(4)完全自动化。端到端学习算法,特征和预测。自动化算法(模型)选择工具,例如Auto-sklearn,TPOT,H2O,auto_ml,MLBox等。 -
深度学习vs自动化深度学习
随着深度神经网络的广泛应用和不断发展,越来越强大的网络模型被构建,从AlexNet,到VGGNet,GoogleNet以及ResNet。这些模型足够灵活,但人工神经网络结构仍然需要大量的专业知识并且需要充足的时间,而且调参对于深度模型来说也是一项非常痛苦的事情,众多的超参数和网络结构参数会产生爆炸性的组合。
是否有可能使这一过程自动化,让每一个人,甚至是不了解机器学习的人可以轻松地将机器学习应用于所面临的问题,自动化深度学习(AutoDL)就是答案,AutoDL的目标是通过超参数优化的方法让机器学会自动设计网络及调参优化。
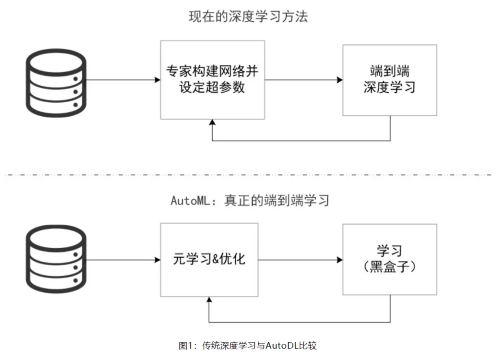
-
超参数优化(HPO,Hyper-parameter Optimization)
学习器模型中一般有两类参数,一类是可以从数据中学习估计得到,还有一类参数无法从数据中估计,只能靠人的经验进行设计指定,后者成为超参数(在机器学习的上下文中,超参数是在开始学习过程之前设置值的参数,而不是通过训练得到的参数数据。通常情况下,需要对超参数进行优化,给学习机选择一组最优超参数,以提高学习的性能和效果)。比如,支持向量机里面的C、 Kernal、game,朴素贝叶斯里面的alpha等。
最常见的超参数优化方法是黑盒优化 (black-box function optimization),所谓黑盒优化,就是将决策网络当作是一个黑盒来进行优化,仅关心输入和输出,而忽略其内部机制,决策网络通常是可以参数化的,这时候我们进行优化首先要考虑收敛性。此类算法通过采样和对采样的评价进行搜索,往往需要大量对采样的评价才能获得比较好的结果。-
网格搜索 (grid search)——一种通过遍历给定的参数组合来优化模型表现的方法,缺点是很容易发生维度灾难,优点是很容易并行;
-
随机搜索 (random search)——利用随机数求极小点而求得函数近似的最优解的方法;
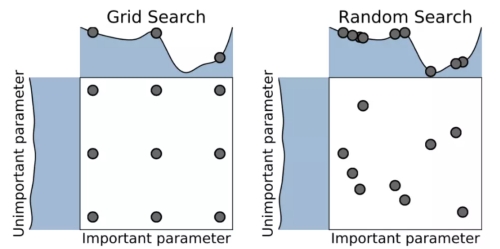
-
贝叶斯优化(Bayesian Optimization)——一种迭代的优化算法,被认为是较好的超参数调优算法,相对于其它的黑盒优化算法,激活函数的计算量要少很多,包含两个主要的元素,输入数据假设的模型和一个采集函数,用来决定下一步要评估哪一个点。每一步迭代,都使用所有的观测数据fit模型,然后利用激活函数预测模型的概率分布,决定如何利用参数点,权衡是Explaoration还是Exploitation。
Sequential model-based optimization (SMBO) 是贝叶斯优化的最简形式,其算法思路如下:

Input:
f: 就是所谓的黑盒子,即输入一组超参数,得到一个输出值。
X:是超参数搜索空间等。
D:表示一个由若干对数据组成的数据集,每一对数组表示为(x,y),x是一组超参数,y表示该组超参数对应的结果。
S:是Acquisition Function(采集函数),这个函数的作用是用来选择公式(1)中的x。
M:是对数据集D进行拟合得到的模型,可以用来假设的模型有很多种,例如随机森林,Tree Parzen Estimators等。 -
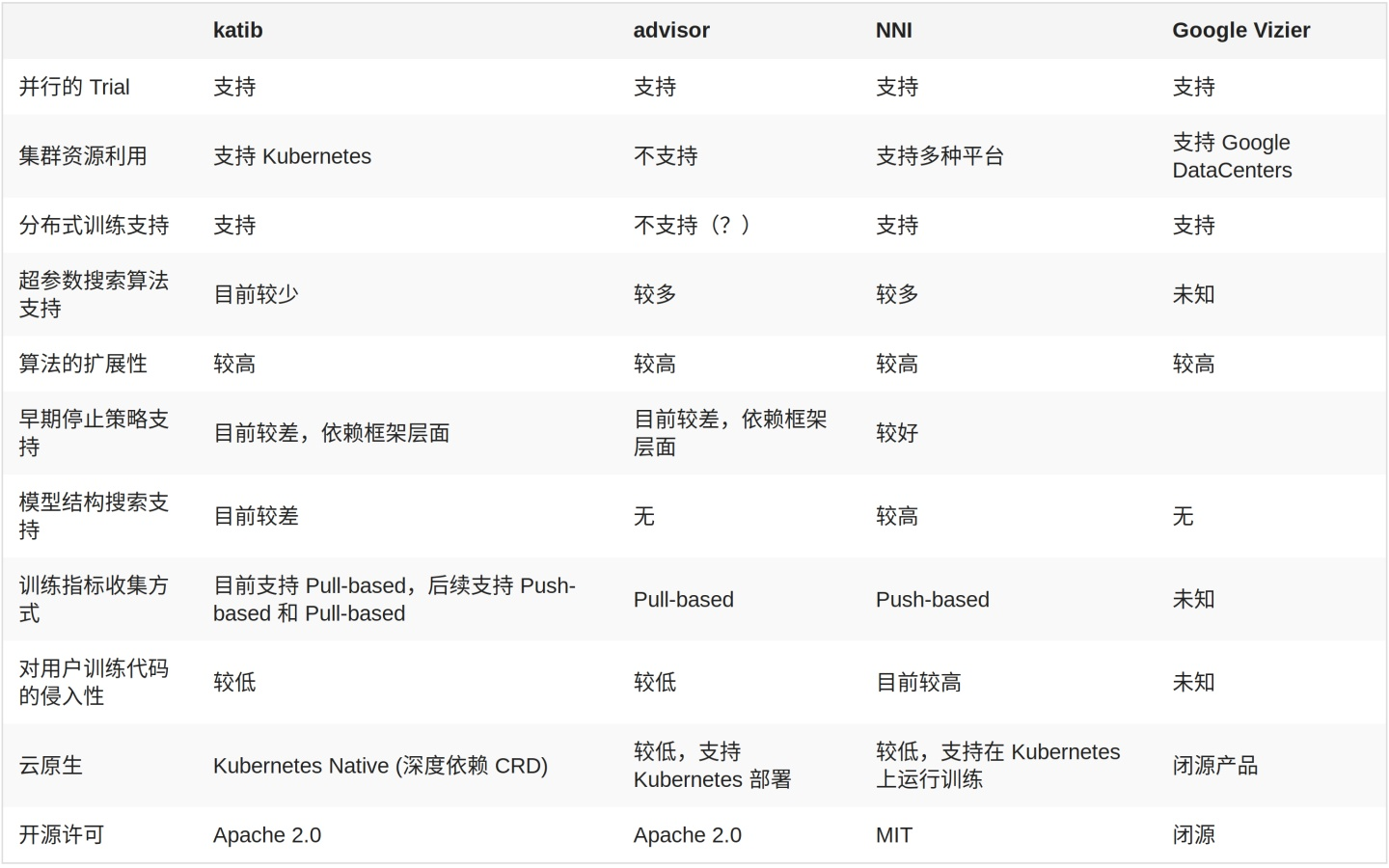
常用工具
(1)hyperopt: 是一个Python库,可以用来寻找实数,离散值,条件维度等搜索空间的最佳值,几乎可以稳定的获取比手工更加合理的调参结果
(2)Google Vizier:Google的内部机器学习系统,一款谷歌内部用于黑箱优化的服务,已经成为谷歌在调整引擎时默认使用的服务,能够利用迁移学习等技术自动优化其他机器学习系统的超参数
(3)advisor:是用于黑盒优化的超参数调整系统,Google Vizier的开源实现
(4)katib :也是对 Google Vizier 的开源实现,基于Kubernetes的超参数优化工具,Kubern,etes native 的超参数训练系统,旨在实现一个云原生的超参数搜索与模型结构搜索系统,复用 Kubernetes 对 GPU 等资源的管理能力,同时保证系统的可扩展性,云原生的实现使得维护这一系统的工作对运维工程师更加友好。
-
所面临的挑战:
(1) 对于大规模的模型或者复杂的机器学习流水线而言,需要评估的空间规模非常大
(2) 配置空间很复杂
(3) 无法或者很难利用损失函数的梯度变化
(4) 训练集合的规模太小
(5) 很容易过拟合
-
-
元学习(Meta Learning)
元学习也就是‘ 学习如何学习 ’,通过对现有的学习任务之间的性能差异进行系统的观测,然后学习已有的经验和元数据,用于更好的执行新的学习任务,这样做可以极大的改进机器学习流水线或者神经网络架构的设计,也可以用数据驱动的方式取代手工作坊似的算法工程工作。从某种意义上来说,元学习覆盖了超参数优化,因为元数据的学习包含了:超参数,流水线的构成,神经网络架构,模型构成,元特征等等。
元学习的一个很大的挑战就是如果通过很少的训练数据来学习一个复杂的模型,这就是one-shot或者few-shot的问题。像人类的学习一样,每次学习无论成功失败,我们都收获一定的经验,人类很少从头学习。在构建自动学习的时候,我们也应该充分利用已有的每一次的学习经验,逐步的改进,使得新的学习更加有效。
机器学习的算法我们又称为‘学习器’,学习器就是假定一个模型,该模型拥有很多未知参数,利用训练数据和优化算法来找到最适合这些训练数据的参数,生成一个新的算法,或者参数已知的模型,并利用该模型/算法来预测新的未知数据。如果说世界上只有一个模型,那么问题就简单了,问题是模型有很多,不同的模型拥有不同的超参数,我们往往还会把模型和算法组装在一起构成复合模型和机器学习的流水线,这个时候,我就需要知道解决不同的问题要构建那些不同的模型。元学习就在这个时候,我们可以把超参数,流水线,神经网络架构这些都看成是一个新的模型的未知参数,把不同学习任务的性能指标看成是输入数据,这样我们就可以利用优化算法来找到性能最好的那组参数。这个模式可以一直嵌套,也就是说,你可以有‘元元元学习‘。
【常用方法】
(1)通过模型评估来学习;
(2)通过任务的属性、元特征来学习;

(3)从现有的模型中学习,包括:迁移学习、利用RNN在学习过程中修改自己的权重。 -
神经架构搜索(NAS,Neural Architecture Search)
是一种针对特定数据集从头开始自动设计性能良好的模型的技术,NAS技术与超参数优化所解决的问题相同:在搜索空间中找到对目标任务表现良好的网络结构,由于神经网络的结构和连接通常可以由可变长度的字符串指定,在实际问题中,根据特定数据集生成指定的“子网络”,通过训练得到验证集的准确性。
NAS主要由三个基本问题组成,分别是搜索空间、优化方法、评估方法。
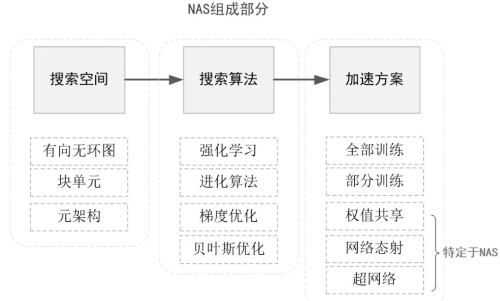
(1)搜索空间针对目标任务定义了一组可能的神经网络结构。就是可供搜索的一个网络结构集合,它的数字表示为:网络的结构(如:神经网络的深度,即隐藏层个数,和特定的隐藏层宽度)、配置(如:操作/网络间的链接类型,核的大小,过滤器的数量。(2)优化方法确定如何探索搜索空间以找到好的架构。搜索算法是一个迭代过程,用于确定以何种规则来探索搜索空间。在搜索过程的每个步骤或迭代中,一个来自于搜索空间的样本会被生成,即子网络(child network),所有的子网络在训练集上被训练,在验证集上的准确率作为目标被优化(或者是强化学习中的奖励。
搜索算法的目的是找到最佳子网络,例如最小化验证集损失或最大化奖励。主流的NAS搜索策略大致可以分为强化学习、进化算法和可微分的梯度下降算法。- 基于强化学习的方法——强化学习有三个基本要素:智能体(Agent)、环境(Environment)和奖励(Reward),智能体以 “试错”的方式进行学习,通过与环境交互获得奖励来指导行为。智能体和环境之间的交互可以被视为顺序决策过程:在每个时间t,Agent在动作集合中选择动作与环境交互并接收奖励。
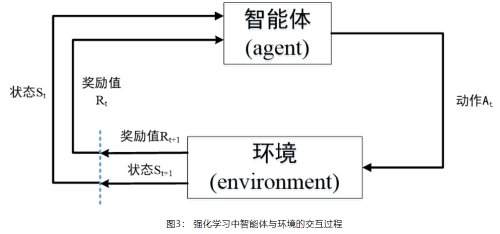
神经架构自动搜索中,强化学习把架构的生成看成一个智能体(agent)在选择动作(action)的过程,通过在测试集上测试网络性能来获取奖励值(reward),从而指导架构的生成。与传统的强化学习问题略有不同的是构建了一个RNN控制器,通过迭代的方式来更新控制器从而生成合适的架构。
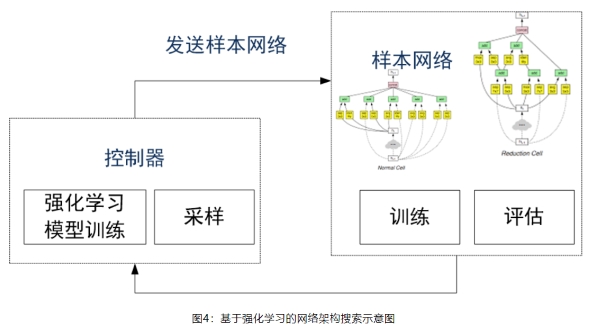
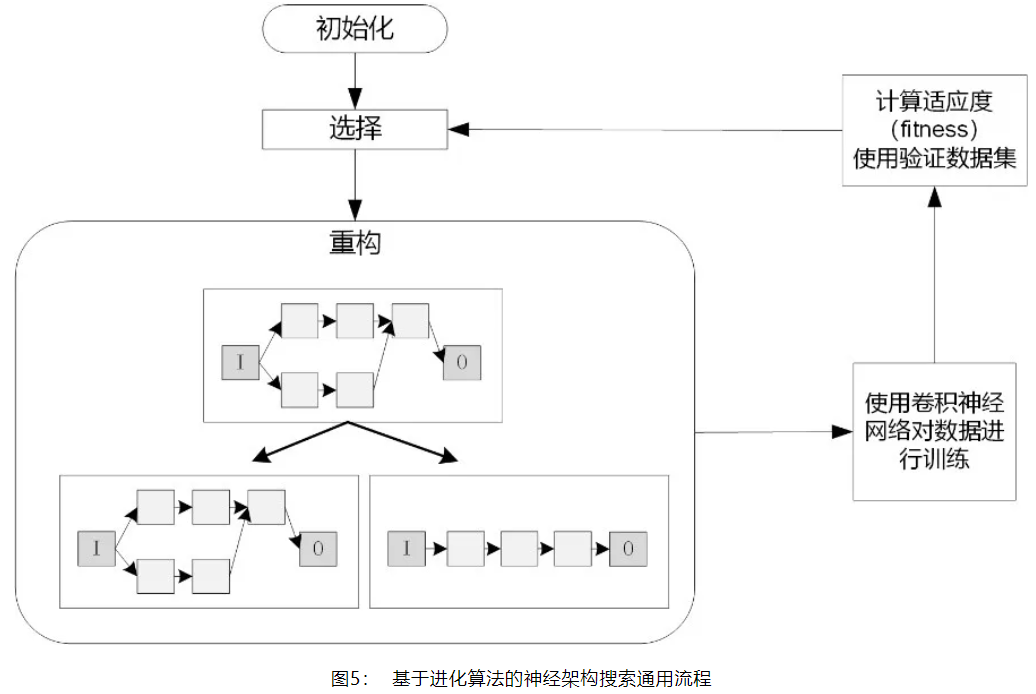
- 基于进化算法的方法——基于进化算法的神经网络结构搜索,在演化步骤中,把子模型作为种群来进化。群体中的每个模型都是训练过的网络,并被视为个体,模型在验证集上的表现(例如,准确度)作为每个个体的质量好坏。基于进化算法神经架构搜索的通用流程如下:
1、初始化操作,对现有的各个个体进行编码,把这些个体编码成种群。
2、选择操作,从种群中根据适应度挑选出优秀的个体。
3、繁殖操作,分为两种:有性繁殖操作和无性繁殖操作,无性繁殖的操作包括变异操作,有性繁殖包括交叉操作或者组合操作。
4、网络训练操作,对上一步繁殖操作得到的所有个体神经网络进行训练,训练到收敛为止。
5、适应度计算操作,使用指定的验证集对每个已训练的网络计算验证准确率,把验证准确率作为适应度。
- 基于可微分架构搜索的方法——可微分架构搜索方法很多种,其中比较出名的是卡内基梅隆大学提出的DARTS(Differentiable Architecture Search)。该方法是最早实现端到端训练的网络架构搜索方法,网络架构搜索根据搜索空间的不同可以分为离散搜索空间和连续搜索空间。
基于离散搜索空间的网络架构搜索方法常用的搜索策略有进化搜索策略的强化学习搜索策略,这类方法都是对搜索空间中的网络进行随机采样训练,缺点是内存和运算消耗十分大,很难应用。DARTS则提出了一种将离散网络搜索空间连续松弛的方法,使NAS能够在连续的空间中进行,并且能够使用基于梯度优化的搜索策略,大大减少了不必要的网络训练过程,加速了网络架构搜索的过程,效率可以比之前不可微的方法快几个数量级。
(3)评估方法评估通过优化方法考虑的每种网络结构的性能。无论是基于强化学习还是进化算法的搜索,子网络都要被训练和评估,以指导搜索过程,但是从头开始训练每个自网络需要超大的资源和时间,所以NAS的加速方案被提出,主要代表方案是改进代理模型和权值共享。
-
改进代理(Improve proxy)
代理模型的引入会带有误差,研究证明子网络的FLOPs(每秒计算的浮点数)和模型大小与最终准确度呈负相关,因此引入了一种应用于奖励计算的校正函数,通过早期停止获得子网络的精度,弥合代理与真实准确性之间的差距。
根据这一想法,研究者们提出了几种通过“预测”神经架构的精度来改进代理度量的方法,预计精确度较差的子网络将被暂停训练或直接放弃。以下是三种预测神经架构搜索的方法:
(1)根据子网络的学习曲线预测神经架构的精度。
(2)回归模型,使用基于网络设置和验证曲线的特征来预测部分训练模型的最终性能。
(3)训练代理模型,基于progressively architectural properties预测子网络的准确性。 -
权值共享(Weight sharing)
在神经网络的搜索和训练过程中,涉及到很多权值和超参数,权值共享可以实现加速,在这里列举几个权值共享的经典方法:
(1)在进化过程中,允许子网络继承父本的权重,而不是从头训练每个子模型,使用One shot 模型实现共享。
(2)设计带有辅助超网络的“主”模型,生成以模型架构为条件的主模型的权重,从超网络代表的分布中采样的权重。
(3)通过网络转换/态射来探索搜索空间,它使用诸如插入层或添加跳过连接之类的操作将训练好的神经网络修改为新的结构。由于网络转换/态射从现有的训练网络开始,因此重用权重并且仅需为数不多的训练迭代来完成新的结构的训练。

- 基于强化学习的方法——强化学习有三个基本要素:智能体(Agent)、环境(Environment)和奖励(Reward),智能体以 “试错”的方式进行学习,通过与环境交互获得奖励来指导行为。智能体和环境之间的交互可以被视为顺序决策过程:在每个时间t,Agent在动作集合中选择动作与环境交互并接收奖励。
-
自动化特征工程(Auto FE,Automated Feature Engineering)
自动化特征工程旨在从数据集中自动创建候选特征,且从中选择若干最佳特征进行训练,可以帮助数据科学家基于数据集自动创建能够最好的用于训练的特征。-
Featuretools——是一个开源库,用来实现自动化特征工程,是一个很好的工具,旨在加快特征生成的过程,从而有更多的时间专注于构建机器学习模型的其他方面。Featuretools使用一种称为深度特征合成(Deep Feature Synthesis,DFS)的算法,该算法会遍历关系数据库模式描述的关系路径,当DFS遍历这些路径时,它通过应用于数据的操作(包括和、平均值和计数)生成综合特征。

三个主要组件:
(1)实体(Entities):一个Entity可以视作是一个Pandas的数据框的表示,多个实体的集合称为Entityset
(2)深度特征综合(Deep Feature Synthesis ,DFS):DFS是一种特征工程方法,是Featuretools的主干,支持从单个或者多个数据框中构造新特征
(3)特征基元(Feature primitives):DFS通过将特征基元应用于Entityset的实体关系来构造新特征,这些特征基元是手动生成特征时常用的方法 -
Boruta——Boruta主要是用来进行特征选择,严格意义上,Boruta并不是我们所需要的自动化特征工程包。Boruta-py是Brouta特征约简策略的一种实现,在该策略中,问题以一种完全相关的方式构建,算法保留对模型有显著贡献的所有特征,这与许多特征约简算法所应用的最小最优特征集相反。
Boruta方法通过创建由目标特征的随机重排序值组成的合成特征来确定特征的重要性,然后在原始特征集的基础上训练一个简单的基于树的分类器,在这个分类器中,目标特征被合成特征所替代。
Boruta函数通过循环的方式评价各变量的重要性,在每一轮迭代中,对原始变量和影子变量进行重要性比较。如果原始变量的重要性显著高于影子变量的重要性,则认为该原始变量是重要的;如果原始变量的重要性明显低于影子变量的重要性,则认为该原始变量是不重要的。其中,原始变量就是我们输入的要进行特征选择的变量;影子变量就是根据原始变量生成的变量。
生成规则:
先向原始变量中加入随机干扰项,这样得到的是扩展后的变量,从扩展后的变量中进行抽样,得到影子变量。
步骤:
(1)首先,它通过创建混合数据的所有特征(即影子特征)为给定的数据集增加了随机性。
(2)然后,它训练一个随机森林分类的扩展数据集,并采用一个特征重要性措施(默认设定为平均减少精度),以评估每个特征的重要性,越高则意味着越重要。
(3)在每次迭代中,它检查一个真实特征是否比最好的影子特征具有更高的重要性(即该特征是否比最大的影子特征得分更高)并且不断删除它视为非常不重要的特征。
(4)最后,当所有特征得到确认或拒绝,或算法达到随机森林运行的一个规定的限制时,算法停止。 -
tsfresh——基于可伸缩假设检验的时间序列特征提取工具,该包包含多种特征提取方法和鲁棒特征选择算法。tsfresh可以自动地从时间序列中提取100多个特征,这些特征描述了时间序列的基本特征,如峰值数量、平均值或最大值,或更复杂的特征,如时间反转对称性统计量等。
这组特征可以用来在时间序列上构建统计或机器学习模型,例如在回归或分类任务中使用,时间序列通常包含噪声、冗余或无关信息,因此大部分提取出来的特征对当前的机器学习任务没有用处。为了避免提取不相关的特性,tsfresh包有一个内置的过滤过程,这个过滤过程评估每个特征对于手头的回归或分类任务的解释能力和重要性。它建立在完善的假设检验理论的基础上,采用了多种检验方法。
-
【经典框架】
-
MLBox(Machine learning Box): 是一个强大的自动机器学习python库,提供了以下几个功能:
(1) Fast reading and distributed data preprocessing/cleaning/formatting 快速读取和分布式数据预处理/清洗/格式化
(2) Highly robust feature selection and leak detection高鲁棒性选择和遗漏检测
(3) Accurate hyper-parameter optimization in high-dimensional space高维空间中精确的超参数优化
(4) State-of-the art predictive models for classification and regression (Deep Learning, Stacking, LightGBM,…)最先进的分类和回归预测模型
(5) Prediction with models interpretation模型解释预测 -
Auto Sklearn:建立在流行的scikit-learn机器学习库之上,在处理小数据集方面做得很好,使机器学习用户从算法选择和超参数调整中解放出来, 它利用了贝叶斯优化,元学习和集合构造的最新优势,可以做到:特征描述(框架的一个显著特性)、机器学习模型选型、超参数设定;
-
TPOT:其中机器学习管道是完全自动化的,为了找到最佳模型,它使用了遗传算法。像Auto Sklearn一样,此框架是scikit-learn的附加组件,但是TPOT有其自己的回归和分类算法,缺点是无法与自然语言交互等;
-
H2O:一个开源的、内存、分布式、快速和可扩展的机器学习和预测分析平台,允许在大数据上构建机器学习模型,并在企业环境中轻松实现这些模型的搭建,支持传统的机器学习模型和神经网络,特别适合那些正在寻找一种自动化深度学习方法的人;
(1) H2O的核心代码是用Java编写的。在H2O中,使用分布式的Key/Value存储来访问和引用所有节点和机器上的数据、模型、对象等。这些算法是在H2O的分布式Map / Reduce框架之上实现的,并且利用Java Fork / Join框架来实现多线程。数据是并行读取的,并分布在整个集群中,并以压缩的方式以列状格式存储在内存中。
(2) H2O的数据解析器具有内置的智能功能,可以猜测传入数据集的模式,并支持以多种格式从多个源获取数据。H2O的REST API允许外部程序或脚本通过HTTP上的JSON访问H2O的所有功能。 Rest API使用H2O的Web界面(Flow UI),R binding(H2O-R)和Python binding(H2O-Python); -
Auto Keras:遵循经典scikit-learn API的设计,但是使用了功能强大的神经网络用Keras来搜索模型参数,主要围绕Keras和PyTorch而构建,利用NAS神经架构搜索,并应用“网络态射”(在更改架构时保持网络功能)以及贝叶斯优化,以指导网络态射实现更高效的神经网络搜索;
-
Cloud AutoML:使用神经网络架构,具有用于学习和部署模型的简单用户界面, 系统是基于监督学习创建,开发者只需要通过鼠标拖拽的方式上传一组图片、导入标签,随后谷歌系统就会自动生成一个定制化的机器学习模型,几乎不需要任何人为的干预。长远来看,在商业项目中使用是非常有意义的,另一方面,出于研究目的,全年都可以免费使用有限制的Cloud AutoML;
-
Uber Ludwig:是一个基于TensorFlow的工具箱,可以训练和测试深度学习模型,无需编写代码,目标是用最少的代码实现深度学习过程的自动化,该框架仅适用于深度学习模型。
主要创新是基于数据类型的特定编码器和解码器的理念。Ludwig对支持的任何给定数据类型使用特定的编码器和解码器。与其他深度学习架构一样,编码器负责将原始数据映射到张量,而解码器则将张量映射到输出。Ludwig的架构还包括组合器的概念,它是组合来自所有输入编码器的张量,处理它们并返回用于输出解码器的张量的组件。
【论文精析】
-
[1]Xin He, Kaiyong Zhao, Xiaowen Chu∗: A Survey of the State-of-the-Art论文链接
-
[2]Jason Liang, Elliot Meyerson, et al. Evolutionary neural AutoML for deep learning论文链接
-
[3]Chengrun Yang, Jicong Fan,et al.Efficient AutoML Pipeline Search with Matrix and Tensor Factorization论文链接
-
[4]Chenxi Liu, Barret Zoph, Maxim Neumann,et al.Progressive Neural Architecture Search论文链接
-
[5]Matthias Feurer, Aaron Klein,et al.Efficient and Robust Automated Machine Learning论文链接
【技术展望】
- 从原理上来说,AutoML仍然需重度依赖人类先验知识,在处理复杂的原始数据和优化构造新特征(特征工程)的过程中仍然存在困难,暂时还必须由人类指定某类任务,进行特定结构的网络优化,离那种天马行空变出一个Dota机器人的程度尚有一定距离。
- 从商业模式来说,泛用性更强。可以根据企业需求定制模型,比如钻石分拣,特定标识及行为识别相对百度AI、腾讯AI之类的现有AI平台,实际上提供的是一个API接口,功能局限大(比如识别身份证和识别车牌就是两套服务)。Google搞定模型之后,对于有特别需求的行业客户吸引力更大。至于只需要做做数字识别,人脸辨认,语音识别等共性大,针对性低任务的中小型企业,用成本较低的接口式平台足够。
- 从发展角度来说,传统的人工智能旨在使用机器帮助人类完成特定的任务,随着人工智能的发展,在计算机领域衍生出了机器学习,机器学习旨在通过计算机程序完成对数据的分析,从而得到对世界上某件事情的预测并做出决定。当机器学习不断发展,其复杂程度也不断增加,完全依靠人为对计算机进行规定,使其按照人为设定的规则运行时,耗费了大量的人力资源。自动机器学习的出现让计算机自己去学习和训练规则,从而达到更好的效果,让AI去学习AI,减少人工的参与,让机器完成更复杂的工作,掀起下一代人工智能的浪潮。
【扩展知识】
- 迁移学习——是一种机器学习方法,把为任务 A 开发的模型作为初始点,重新使用在为任务 B 开发模型的过程中,通常这些预训练的模型在开发神经网络的时候已经消耗了巨大的时间资源和计算资源,迁移学习可以将已习得的强大技能迁移到相关的的问题上。
- RNN(Recurrent Neural Network)——是一类以序列(sequence)数据为输入,在序列的演进方向进行递归(recursion)且所有节点(循环单元)按链式连接的递归神经网络。循环神经网络具有记忆性、参数共享并且图灵完备,因此在对序列的非线性特征进行学习时具有一定优势 。循环神经网络在自然语言处理(Natural Language Processing, NLP),例如语音识别、语言建模、机器翻译等领域有应用,也被用于各类时间序列预报。引入了卷积神经网络构筑的循环神经网络可以处理包含序列输入的计算机视觉问题。
- CNN(Convoutional Neural Network)——是一类包含卷积计算且具有深度结构的前馈神经网络(Feedforward Neural Networks),是深度学习的代表算法之一,卷积神经网络具有表征学习(representation learning)能力,能够按其阶层结构对输入信息进行平移不变分类。
- 强化学习(Reinforcement Learning)——又称再励学习、评价学习或增强学习,是机器学习的范式和方法论之一,用于描述和解决智能体(agent)在与环境的交互过程中通过学习策略以达成回报最大化或实现特定目标的问题。不同于监督学习和非监督学习,强化学习不要求预先给定任何数据,而是通过接收环境对动作的奖励(反馈)获得学习信息并更新模型参数,强化学习问题在信息论、博弈论、自动控制等领域有一定应用,被用于解释有限理性条件下的平衡态、设计推荐系统和机器人交互系统 。
- 蒙特卡洛树搜索——又称随机抽样或统计试验方法,属于计算数学的一个分支,它是在上世纪四十年代中期为了适应当时原子能事业的发展而发展起来的。传统的经验方法由于不能逼近真实的物理过程,很难得到满意的结果,而蒙特卡洛树搜索方法由于能够真实地模拟实际物理过程,故解决问题与实际非常符合,可以得到很圆满的结果。这也是以概率和统计理论方法为基础的一种计算方法,是使用随机数(或更常见的伪随机数)来解决很多计算问题的方法。将所求解的问题同一定的概率模型相联系,用电子计算机实现统计模拟或抽样,以获得问题的近似解。
- A*算法——是一种静态路网中求解最短路径最有效的直接搜索方法,也是解决许多搜索问题的有效启发式算法。算法中的距离估算值与实际值越接近,最终搜索速度越快。
公式表示为: f(n)=g(n)+h(n),其中, f(n) 是从初始状态经由状态n到目标状态的代价估计,g(n) 是在状态空间中从初始状态到状态n的实际代价,h(n) 是从状态n到目标状态的最佳路径的估计代价。(对于路径搜索问题,状态就是图中的节点,代价就是距离)

- One/zero-shot learning——Zero-shot learning 指的是我们之前没有这个类别的训练样本,但是我们可以学习到一个映射X->Y,如果这个映射足够好的话,我们就可以处理没有看到的类了。 比如,我们在训练时没有看见过狮子的图像,但是我们可以用这个映射得到狮子的特征。一个好的狮子特征,可能就和猫,老虎等等比较接近,和汽车,飞机比较远离。One-shot learning 指的是我们在训练样本很少,甚至只有一个的情况下,依旧能做预测,可以在一个大数据集上学到general knowledge(具体的说,也可以是X->Y的映射),然后再到小数据上有技巧的update。
- Scikit-learn(以前称为scikits.learn,也称为sklearn)——是针对Python 编程语言的免费软件机器学习库 。它具有各种分类,回归和聚类算法,包括支持向量机,随机森林,梯度提升,k均值和DBSCAN,并且旨在与Python数值科学图书馆NumPy和SciPy。
- k 折交叉验证——将数据集等比例划分成k份,以其中的一份作为测试数据,其他的k-1份数据作为训练数据。然后,这样算是一次实验,而k折交叉验证只有实验k次才算完成完整的一次,也就是说交叉验证实际是把实验重复做了k次,每次实验都是从k个部分选取一份不同的数据部分作为测试数据(保证k个部分的数据都分别做过测试数据),剩下的k-1个当作训练数据,最后把得到的k个实验结果进行平分。
- SOTA(state-of-the-art)——通常来说state-of-the-art指的就是某一种技术、研究或者产品已经达到了这个领域的顶级,再也无法被超越,这个通常情况下是比较难的,因此现在很多时候说state-of-the-art的话,都是指在现在这个技术发展的阶段达到领域最优。SOTA model:state-of-the-art model,并不是特指某个具体的模型,而是指在该项研究任务中,目前最好/最先进的模型;SOTA result:state-of-the-art result,指的是在该项研究任务中,目前最好的模型的结果/性能/表现。
来源:
[1] 如何评价谷歌刚推出的Cloud AutoML?作者:cat cynthia
[2] 微信公众号 Datawhale : 一文讲解自动机器学习(AutoML)!你已经是个成熟的模型了,该学会自己训练了
[3] Awesome-AutoML-Papers
[4] 贝叶斯优化(Bayesian Optimization)深入理解
[5] AUTOML

