
- 1Spark-Scala语言实战(10)
- 2Oracle多用户同时修改同一记录,怎样保证该客户记录_oracle并发修改同一条数据
- 3HashCat报错_在powershell里面使用hashcat出现nvmldevicegetfanspeed(): n
- 4python基础入门——汉诺塔(hano)_python汉诺塔源于印度一个古老传说:大梵天创造世界的时候做了三根金刚石柱子,一根
- 5Centos7 防火墙开放端口,查看状态,查看开放端口_linux下报错unknown operation firewalld
- 6GitHub 入门实践_github windows客户端
- 7rp软件app流程图_AxureRP介绍
- 8plt.scatter( ) 函数的使用方法_plt.scatter()用法
- 9uni-app/vue 文字转语音朗读(附小程序语音识别和朗读)uniapp小程序使用文字转语音播报类似支付宝收款播报小程序语音识别和朗读)_uniapp 微信小程序 文字转语音
- 10微服务系统中服务注册与发现Zookeeper的使用
面试——FPGA常见问题1_某设计中使用了ddr3-1066,数据位宽32bit,fpga工程中实现的ddr3 controll
赞
踩
线网的默认值为Z(高阻),reg的默认值为X(未知)。
面积优化:资源共享、寄存器配平、串行化
速度优化:流水线设计、寄存器配平、关键路径法、乒乓操作法、树形结构法
0、DDR3
某设计中使用了DDR3-1066,数据位宽32bit,FPGA工程中实现的DDR3 controller时钟为800MHz, 应用端时钟为200MHz, 数据位宽为128bit,请问,应用端DDR3可用的理论带宽为()
解析:
DDR3-1066 理论带宽 = 1066 * 32 / 8 = 4264
FPGA内存带宽 = 800 * 32 / 8 = 3200
应用端带宽 = 200 * 128 / 8 = 3200
取瓶颈3200
0.1、设计异步FIFO时,要注意
(1)在地址信号跨时钟域时需要对其进行二进制码转格雷码的转换并进行目标时钟域的时钟打两拍同步,以防止亚稳态的产生。
(2)写满信号由读地址同步到写时钟域并与写地址进行比较产生,读空信号由写地址同步到读时钟域并与读地址进行比较产生。这样可以在第一时间得到读空与写满的信息,并对异步fifo进行操作。
(3)异步fifo的深度需要考虑到写状态的背靠背写入状态以得到最适合的深度。
(4)读写地址需要扩展一位来判断是读空还是写满,当扩展后的读写地址的格雷码相等时为读空,若其前两位不同,后面相等时为写满。
0.2、系统工作频率计算
同步电路的速度是指同步系统时钟的速度,同步时钟愈快,电路处理数据的时间间隔越短,电路在单位时间内处理的数据量就愈大。
最高运行速度:
Tco ——触发器的输入数据被时钟打入到触发器到数据到达触发器输出端的延时时间;
Tdelay——组合逻辑的延时;
Tsetup ——D触发器的建立时间
假设数据已被时钟打入D触发器,那么数据到达第一个触发器的Q输出端需要的延时时间是Tco,经过组合逻辑的延时时间为Tdelay,然后到达第二个触发器的D端,要希望时钟能在第二个触发器再次被稳定地打入触发器,则
时钟的延迟必须大于 Tco+Tdelay+Tsetup,也就是说:
最小的时钟周期 Tmin =Tco+Tdelay+ Tsetup,
即最快的时钟频率 Fmax=1/Tmin。
因为Tco和Tsetup是由具体的器件工艺决定的,故设计电路时只能改变组合逻辑的延迟时间Tdelay,所以说缩短触发器间组合逻辑的延时时间是提高同步电路速度的关键所在。由于一般同步电路都大于一级锁存,而要使电路稳定工作,时钟周期必须满足最大延时要求。故只有缩短最长延时路径,才能提高电路的工作频率。
可以将较大的组合逻辑分解为较小的N块,通过适当的方法平均分配组合逻辑,然后在中间插入触发器,并和原触发器使用相同的时钟,就可以避免在两个触发器之间出现过大的延时,消除速度瓶颈,这样可以提高电路的工作频率。这就是所谓 "流水线"技术的基本设计思想,即原设计速度受限部分用一个时钟周期实现,采用流水线技术插入触发器后,可用N个时钟周期实现,因此系统的工作速度可以加快,吞吐量加大。注意,流水线设计会在原数据通路上加入延时,另外硬件面积也会稍有增加。
1、什么是Setup 和Holdup时间?
答:Setup/hold time 是测试芯片对输入信号和时钟信号之间的时间要求。
建立时间是指触发器的时钟信号上升沿到来以前,数据稳定不变的时间。输入信号应提前时钟上升沿(如上升沿有效)T时间到达芯片,这个T就是建立时间-Setup time。如不满足setup time,这个数据就不能被这一时钟打入触发器,只有在下一个时钟上升沿,数据才能被打入触发器。
保持时间是指触发器的时钟信号上升沿到来以后,数据稳定不变的时间。如果holdtime不够,数据同样不能被打入触发器。
2、什么是竞争与冒险现象?解决办法?
答:在组合逻辑中,由于门的输入信号通路中经过了不同的延时,导致到达该门的时间不一致叫竞争。产生毛刺叫冒险。如果布尔式中有相反的信号则可能产生竞争和冒险现象。
解决方法:
一是添加布尔式的消去项,
二是在芯片外部加电容。
三加选通信号。
用D触发器,格雷码计数器,同步电路等优秀的设计方案可以消除。
3、如何解决亚稳态?Metastability
答:亚稳态是指触发器无法在某个规定时间段内达到一个可确认的状态。当一个触发器进入亚稳态时,既无法预测该单元的输出电平,也无法预测何时输出才能稳定在某个正确的电平上。在这个稳定期间,触发器输出一些中间级电平,或者可能处于振荡状态,并且这种无用的输出电平可以沿信号通道上的各个触发器级联式传播下去。
解决方法:
1 、降低系统时钟频率
2 、用反应更快的Flip-Flop(触发器)
3 、引入同步机制,防止亚稳态传播
异步FIFO、对于异步时钟通过异步复位同步释放(就是对异步复位时钟进行两次或者两次以上缓存。)
4 、改善时钟质量,用边沿变化快速的时钟信号
关键是器件使用比较好的工艺和时钟周期的裕量要大。
4、说说静态、动态时序模拟的优缺点
静态时序分析是采用穷尽分析方法来提取出整个电路存在的所有时序路径,计算信号在这些路径上的传播延时,检查信号的建立和保持时间是否满足时序要求,通过对最大路径延时和最小路径延时的分析,找出违背时序约束的错误.它不需要输入向量就能穷尽所有的路径,且运行速度很快、占用内存较少,不仅可以对芯片设计进行全面的时序功能检查,而且还可利用时序分析的结果来优化设计,因此静态时序分析已经越来越多地被用到数字集成电路设计的验证中。
动态时序模拟就是通常的仿真,因为不可能产生完备的测试向量,覆盖门级网表中的每一条路径.因此在动态时序分析中,无法暴露一些路径上可能存在的时序问题;
静态时序分析缺点:
1、无法识别伪路径
2、不适合异步电路
3、不能验证功能
5、用VERILOG写一段代码,实现消除一个glitch。
毛刺为高则用与门,低就或门
(1)滤掉小于1个周期glitch的原理图如下:
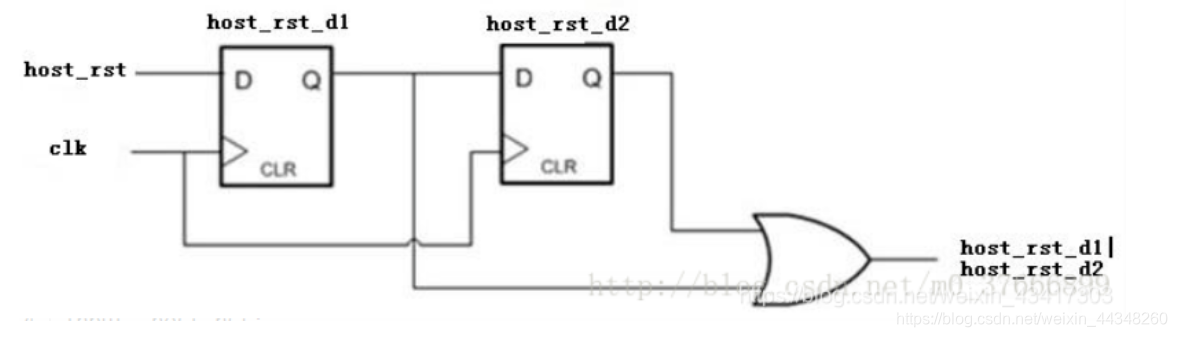
module digital_filter_(clk_in,rst,host_rst,host_rst_filter); input clk_in; input rst; input host_rst; output host_rst_filter; reg host_rst_d1; reg host_rst_d2; always@(posedge clk_in or negedge rst) begin if(!rst) begin host_rst_d1 <= 1'b1; host_rst_d2 <= 1'b1; end else begin host_rst_d1 <= host_rst; host_rst_d2 <= host_rst_d1; end end assign host_rst_filter = host_rst_d1 | host_rst_d2; endmodule

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
(2)滤掉大于1个周期且小于2个周期glitch的原理图如下:
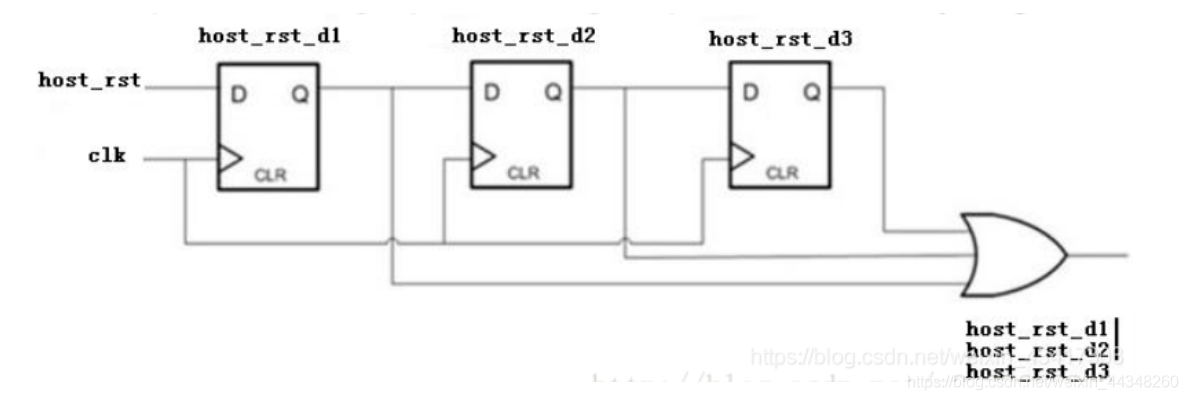
module digital_filter_(clk_in,rst,host_rst,host_rst_filter); input clk_in; input rst; input host_rst; output host_rst_filter; reg host_rst_d1; reg host_rst_d2; reg host_rst_d3; always@(posedge clk_in or negedge rst) begin if(!rst) begin host_rst_d1 <= 1'b1; host_rst_d2 <= 1'b1; host_rst_d3 <= 1'b1; end else begin host_rst_d1 <= host_rst; host_rst_d2 <= host_rst_d1; host_rst_d3 <= host_rst_d2; end end assign host_rst_filter = host_rst_d1 | host_rst_d2 | host_rst_d3; endmodule
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
6、简述建立时间和保持时间
建立时间Tsu(setup):触发器在时钟上升沿到来之前,其数据输入端的数据必须保持不变的最小时间。
保持时间Th(hold):触发器在时钟上升沿到来之后,其数据输入端的数据必须保持不变的最小时间。
7、简述触发器和锁存器之间的差别
锁存器对电平信号敏感,在输入脉冲的电平作用下改变状态。
D触发器对时钟边沿敏感,检测到上升沿或下降沿触发瞬间改变状态。
8、计算最小周期
Tco:寄存器时钟输入到数据输出的时间
Tdata:寄存器间的走线延迟
Tsu :建立时间
Tskew:时钟偏斜
最小时钟周期:
Tmin = Tco + Tdata + Tsu - Tskew。最快频率Fmax = 1/Tmin
Tskew = Tclkd – Tclks。
- 1
- 2
- 3
9、时钟抖动和时钟偏移的概念及产生原因,如何避免?
时钟抖动jitter:指时钟信号的跳变沿不确定,故是时钟频率上的不一致。
时钟偏移Skew:指全局时钟产生的各个子时钟信号到达不同触发器的时间点不同,是时钟相位的不一致。
jitter主要受外界干扰引起,通过各种抗干扰手段可以避免。而skew由数字电路内部各路径布局布线长度和负载不同导致,利用全局时钟网络可尽量将其消除。
10、同步复位和异步复位的区别
同步复位是复位信号随时钟边沿触发有效。异步复位是复位信号有效和时钟无关。
如异步复位:
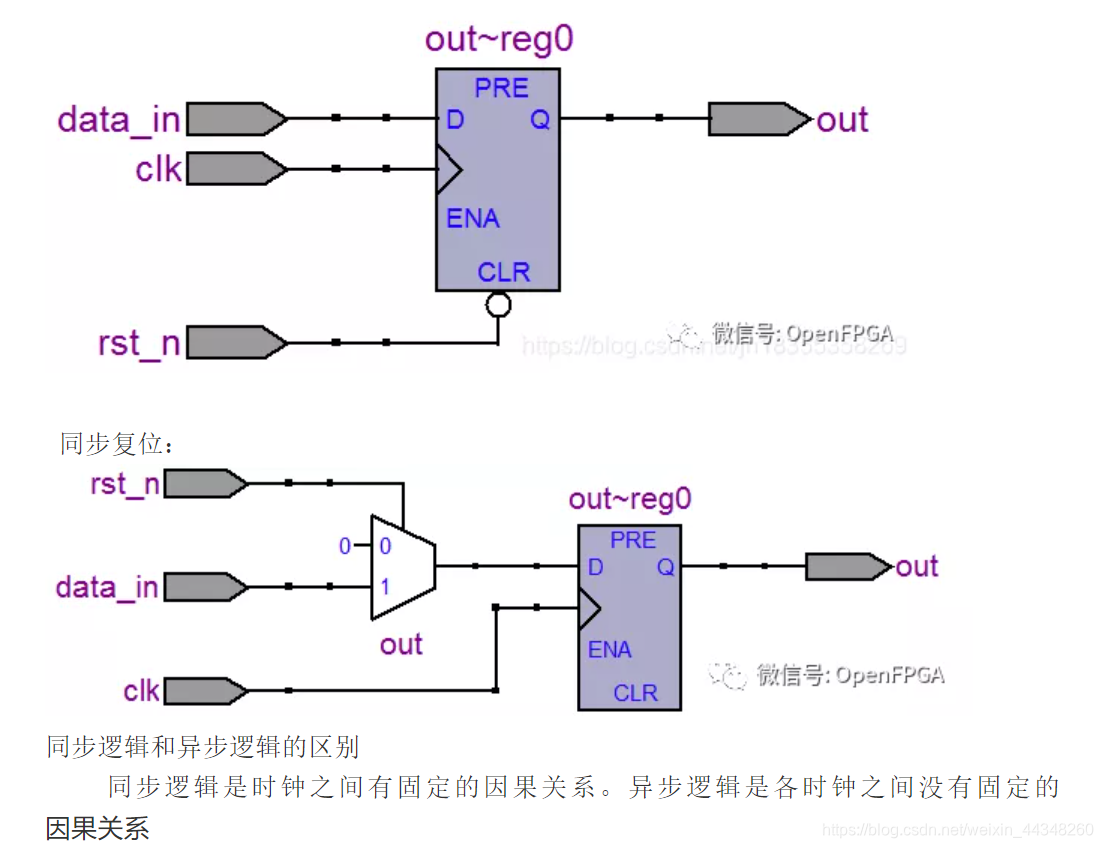
同步电路和异步电路区别:
同步电路有统一的时钟源,经过PLL分频后的时钟驱动的模块,因为是一个统一的时钟源驱动,所以还是同步电路。异步电路没有统一的时钟源。
同步复位和异步复位的优缺点:
同步复位优点:
1、有利于仿真器的仿真
2、可以使所设计的系统100%成为同步电路,这有利于时序分析,而且综合出来的Fmax一般较高
3、因为它只有走有效的时钟沿到来时才有效,所有滤除了高于时钟周期频率的毛刺
缺点:
1、复位信号必须大于时钟周期,才能使其真正被系统识别并完成复位任务。同时还要考虑诸如时钟偏斜、组合逻辑路径延迟等因素。
2、由于大部分的逻辑器件库中的DFF都只有异步复位端口,所以采用同步复位的情况下,综合器就会在寄存器的数据输入端口插入组合逻辑,这样会耗费更多的逻辑资源。
异步复位的优点:
1、大部分的逻辑器件库中的DFF(触发器)都只有异步复位端口,因此采用异步复位更省资源
2、设计相对简单
3、异步复位信号识别方便,可以很方便的使用FPGA的全局复位端口GSR
缺点:
1、在异步复位释放的时候容易出问题,具体来说就是:假如复位释放时正好在时钟有效沿附近,就很容易出现亚稳态
2、复位信号容易受毛刺影响
11、什么是线与逻辑?在硬件电路上有什么要求?
线与逻辑是指两根线直接相连能够实现与的功能。在硬件上需要OC门,如果不采用OC门会会导致门电路管电流过大而烧坏逻辑门。用OC门实现线与,应在输出端口加一个上拉电阻。
知识点标记:OC门实际上只是一个NPN型三极管,并不输出某一特定电压值或电流值。OC门根据三极管基极所接的集成电路来决定(三极管发射极接地),通过三极管集电极,使其开路而输出。而输出设备若为场效应晶体管(MOSFET),则称之为漏极开路(英语:Open Drain,俗称“OD门”),工作原理相仿。通过OC门这一装置,能够让逻辑门输出端的直接并联使用。两个OC门的并联,可以实现逻辑与的关系,称为“线与”,但在输出端口应加一个上拉电阻与电源相连。
12、什么是竞争冒险?如何判断?怎么样消除?
在组合逻辑电路中,同一信号经过不同的路径到达某一汇合点的时间有先有后,这种现象称为竞争。
由于竞争而使电路发生瞬时错误的现象称为冒险。
消除方法:
1、输出端加滤波电容。在输出端和地直接接一个几十皮法的电容可以吸收掉尖峰干扰脉冲。
2、加选通脉冲
3、修改逻辑设计
4、利用格雷码每次只有一位跳变,消除了竞争冒险产生的条件。
- 1
- 2
- 3
- 4
举例:
下面这个电路,使用了两个逻辑门,一个非门和一个与门,本来在理想情况下F的输出应该是一直稳定的0输出,但是实际上每个门电路从输入到输出是一定会有时间延迟的,这个时间通常叫做电路的开关延迟。而且制作工艺、门的种类甚至制造时微小的工艺偏差,都会引起这个开关延迟时间的变化。
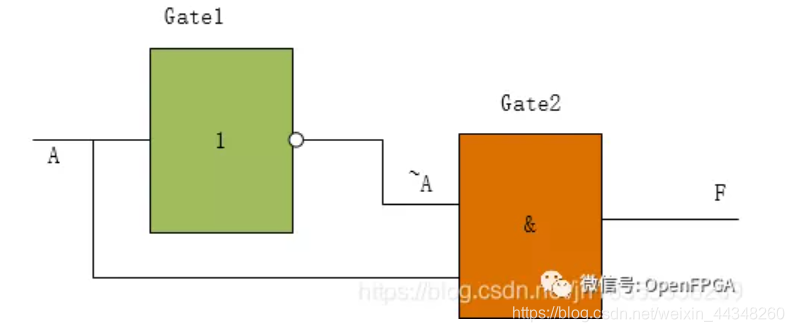

F = A & ~A
有竞争不一定产生冒险,如红线处。有冒险一定存在竞争。
13、异步FIFO深度计算
如果数据流连续不断则FIFO深度无论多少,只要读写时钟不同源同频则都会丢数;
FIFO用于缓冲块数据流,一般用在写快读慢时,
FIFO深度 / (写入速率 - 读出速率) = FIFO被填满时间 应大于 数据包传送时间= 数据量 / 写入速率
例:A/D采样率50MHz,dsp读A/D读的速率40MHz,要不丢失地将10万个采样数据送入DSP,在A/D在和DSP之间至少加多大容量(深度)的FIFO才行?
100,000 / 50MHz = 1/ 500 s = 2ms
(50MHz - 40MHz) * 1/500 = 20k既是FIFO深度。
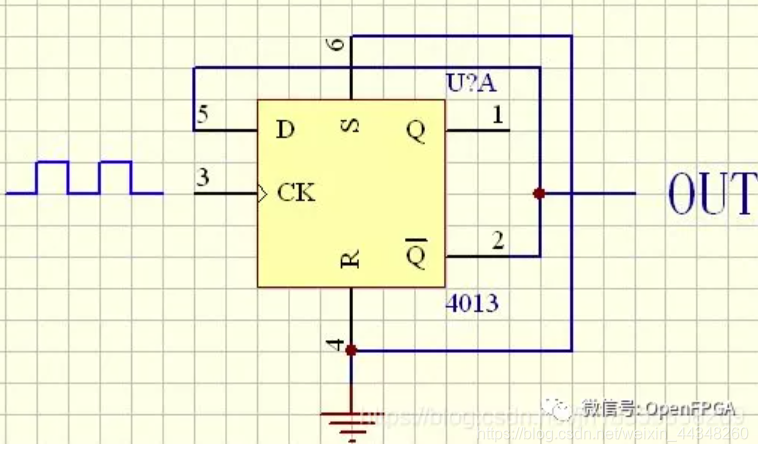
14、画出用D触发器实现2倍分频的逻辑电路
图片
将D触发器的Q非端接到数据输入端D即可实现二分频,说白了就是CLK时钟信号的一个周期Q端电平反转一次。Q和Q非输出的都是二分频电路,只不过是反相的。~Q是先高后低。
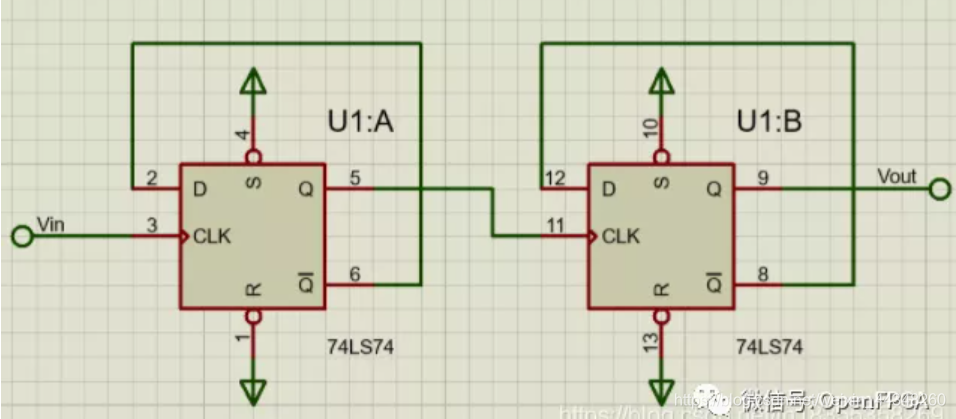
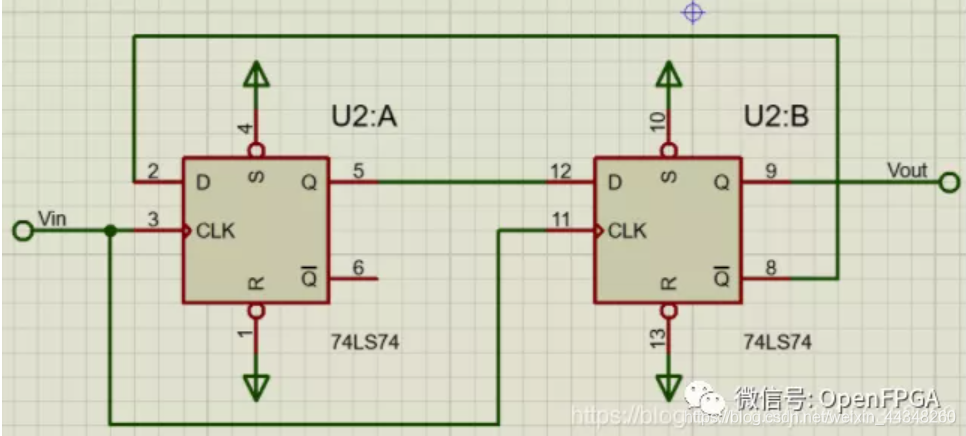
四分频电路:
15、系统最高速度计算(最快时钟频率)和流水线设计思想:
同步电路的速度是指同步系统时钟的速度,同步时钟愈快,电路处理数据的时间间隔越短,电路在单位时间内处理的数据量就愈大。
假设Tco是触发器的输入数据被时钟打入到触发器到数据到达触发器输出端的延时时间(Tco=Tsetpup+Thold);Tdelay是组合逻辑的延时;Tsetup是D触发器的建立时间。
假设数据已被时钟打入D触发器,那么数据到达第一个触发器的Q输出端需要的延时时间是Tco,经过组合逻辑的延时时间为Tdelay,然后到达第二个触发器的D端,要希望时钟能在第二个触发器再次被稳定地打入触发器,则时钟的延迟必须大于Tco+Tdelay+Tsetup,也就是说最小的时钟周期Tmin =Tco+Tdelay+Tsetup,即最快的时钟频率Fmax =1/Tmin。
FPGA开发软件也是通过这种方法来计算系统最高运行速度Fmax。因为Tco和Tsetup是由具体的器件工艺决定的,故设计电路时只能改变组合逻辑的延迟时间Tdelay,所以说缩短触发器间组合逻辑的延时时间是提高同步电路速度的关键所在。
由于一般同步电路都大于一级锁存,而要使电路稳定工作,时钟周期必须满足最大延时要求。故只有缩短最长延时路径,才能提高电路的工作频率。可以将较大的组合逻辑分解为较小的N块,通过适当的方法平均分配组合逻辑,然后在中间插入触发器,并和原触发器使用相同的时钟,就可以避免在两个触发器之间出现过大的延时,消除速度瓶颈,这样可以提高电路的工作频率。这就是所谓"流水线"技术的基本设计思想,即原设计速度受限部分用一个时钟周期实现,采用流水线技术插入触发器后,可用N个时钟周期实现,因此系统的工作速度可以加快,吞吐量加大。注意,流水线设计会在原数据通路上加入延时,另外硬件面积也会稍有增加。
17、异步信号同步处理
对于单bit信号:
慢时钟域到快时钟域信号的转换,用沿同步:
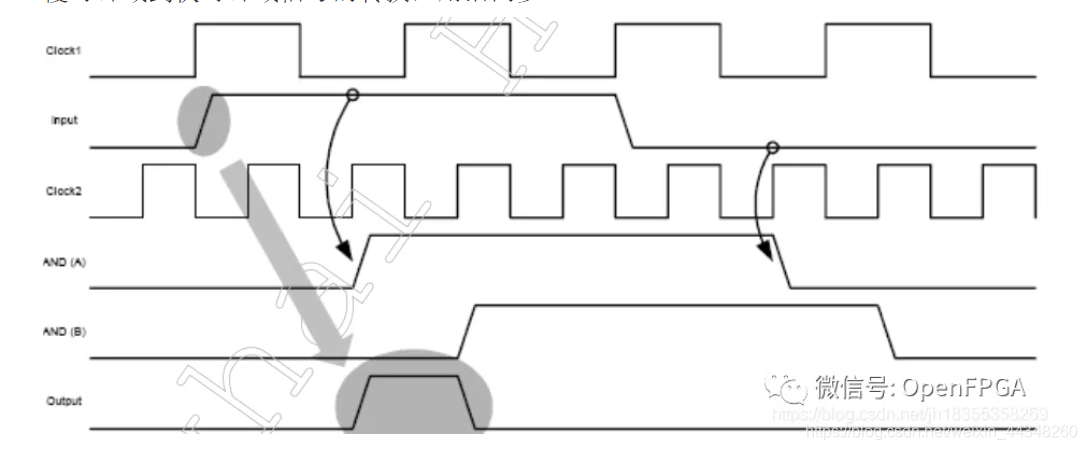
快时钟域到慢时钟域信号的转换,用脉冲同步:
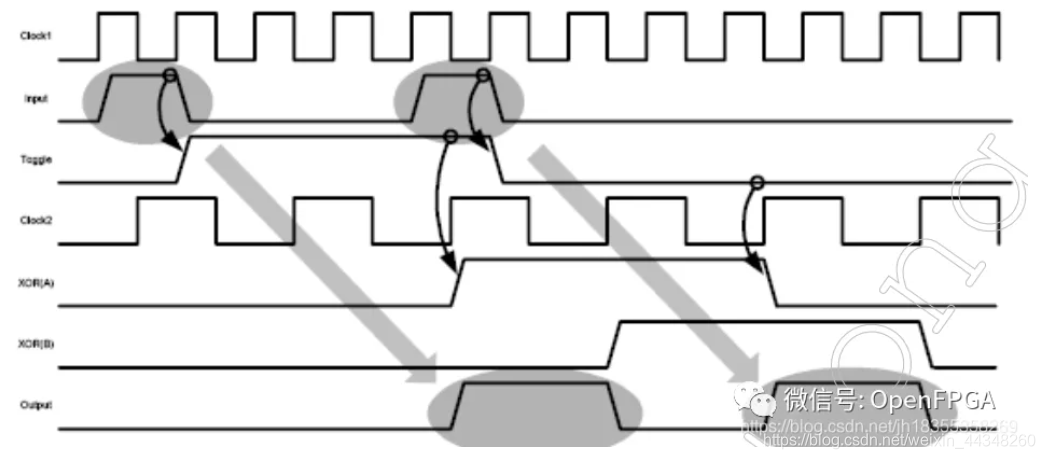
要求输入异步脉冲信号之间的间隔至少要在两个慢速时钟的时钟周期之上,如果小于这个值,两个快时钟域的单bit信号转到慢时钟域可能就变成了一个两周期宽度的信号了。
18、FPGA中可以综合实现为RAM/ROM/CAM的三种资源及其注意事项?
三种资源:BLOCK RAM,触发器(FF),查找表(LUT);
注意事项:
1:在生成RAM等存储单元时,应该首选BLOCK RAM 资源;其原因有二:第一:使用BLOCK RAM等资源,可以节约更多的FF和4-LUT等底层可编程单元。使用BLOCK RAM可以说是“不用白不用”,是最大程度发挥器件效能,节约成本的一种体现;第二:BLOCK RAM是一种可以配置的硬件结构,其可靠性和速度与用LUT和REGISTER构建的存储器更有优势。
2:弄清FPGA的硬件结构,合理使用BLOCK RAM资源;
3:分析BLOCK RAM容量,高效使用BLOCK RAM资源;
4:分布式RAM资源(DISTRIBUTE RAM)
查找表(look-up-table)简称为LUT,LUT本质上就是一个RAM。目前FPGA中多使用4(V7和A7都是6输入)输入的LUT,所以每一个LUT可以看成一个有 4位地址线的16x1的RAM。当用户通过原理图或HDL语言描述了一个逻辑电路以后,PLD/FPGA开发软件会自动计算逻辑电路的所有可能的结果,并把结果事先写入RAM,这样,每输入一个信号进行逻辑运算就等于输入一个地址进行查表,找出地址对应的内容,然后输出即可。
19、HDL语言的层次概念?
HDL语言是分层次的、类型的,最常用的层次概念有系统与标准级、功能模块级,行为级,寄存器传输级和门级。
系统级,算法级,RTL级(行为级),门级,开关级。
21、MOORE 与 MEELEY状态机的特征?
Mealy 状态机的输出不仅与当前状态值有关, 而且与当前输入值有关。
Moore 状态机的输出仅与当前状态值有关, 且只在时钟边沿到来时才会有状态变化。
22、说说静态、动态时序模拟的优缺点?
静态时序分析是采用穷尽分析方法来提取出整个电路存在的所有时序路径,计算信号在这些路径上的传播延时,检查信号的建立和保持时间是否满足时序要求,通过对最大路径延时和最小路径延时的分析,找出违背时序约束的错误。它不需要输入向量就能穷尽所有的路径,且运行速度很快、占用内存较少,不仅可以对芯片设计进行全面的时序功能检查,而且还可利用时序分析的结果来优化设计,因此静态时序分析已经越来越多地被用到数字集成电路设计的验证中。
动态时序模拟就是通常的仿真,因为不可能产生完备的测试向量,覆盖门级网表中的每一条路径。因此在动态时序分析中,无法暴露一些路径上可能存在的时序问题;
23、FPGA内部结构及资源:
FPGA主要由可编程单元、可编程I/O单元及布线资源构成。
可编程逻辑单元(可配置逻辑单元,CLB)由两个SLICE构成,SLICE主要包括实现组合逻辑的LUT和实现时序逻辑的触发器。FPGA内部还包含专用存储单元BRAM,运算单元DSP Slice,及专用内嵌功能单元,如:PLL、Serdes等。
24、名词解释,写出下列缩写的中文(或者英文)含义:
FPGA :Field Programmable Gate Array 现场可编程门阵列
VHDL:( Very-High-Speed Integrated Circuit Hardware Description Language) 甚高速集成电路硬件描述语言
HDL :Hardware Description Language硬件描述语言
EDA:Electronic Design Automation 电子设计自动化
CPLD:Complex Programmable Logic Device 复杂可编程逻辑器件
PLD :Programmable Logic Device 可编程逻辑器件
GAL:generic array logic 通用阵列逻辑
LAB:Logic Array Block 逻辑阵列块
CLB :Configurable Logic Block 可配置逻辑模块
EAB: Embedded Array Block 嵌入式阵列块
SOPC: System-on-a-Programmable-Chip可编程片上系统
LUT :Look-Up Table 查找表
JTAG: Joint Test Action Group 联合测试行为组织
IP: Intellectual Property 知识产权
ASIC :Application Specific Integrated Circuits 专用集成电路
ISP :In System Programmable 在系统可编程
ICR :In Circuit Re-config 在电路可重构
RTL: Register Transfer Level 寄存器传输级
25、FPGA内部LUT实现组合逻辑的原理:
LUT相当于存放逻辑表达式对应真值表的RAM。软件将逻辑表达式所有可能结果列出后存放在RAM中,输入作为RAM地址,输出为逻辑运算结果。如使用LUT模拟二输入“与”逻辑。列出真值表:00 – 0,01 – 0,10 – 0,11 – 1。此时将00 01 10 11作为地址线,依次将结果0 0 0 1存放在RAM中。当输入00时及输出0&0=0.
26、 低功耗技术:
功耗可用公式描述:Power = KFCV^2,即功率等于常数系数工作频率负载电容值*电压的平方。
故从以下几个方面降低功耗方式:
a.控制工作频率:降低频率增大数据路径宽度,动态频率调整,门控时钟(时钟使能有效时钟才进入寄存器时钟输入引脚)
b.减少电容负载:使用几何尺寸更小的逻辑门,其电容负载较小,功率也随之减少。
c.降低工作电压:动态改变工作电压、零操作电压(直接关闭系统中一部分的电源)
27、MOS管基本概念及画图:
MOS中文意思是金属氧化物半导体场效应管,由栅极(G)、漏级(D)、源级(S)组成。分为PMOS和NMOS两种类型,区别在于G级高电平时,N型管导通,P型管截止。两者往往是成对出现的,即CMOS。只要一只导通,另一只则不导通,现代单片机主要是采用CMOS工艺制成的。
画图一般需要根据一个简单的逻辑表达式,画出CMOS电路图结构。需要掌握常用逻辑门的实现方式。
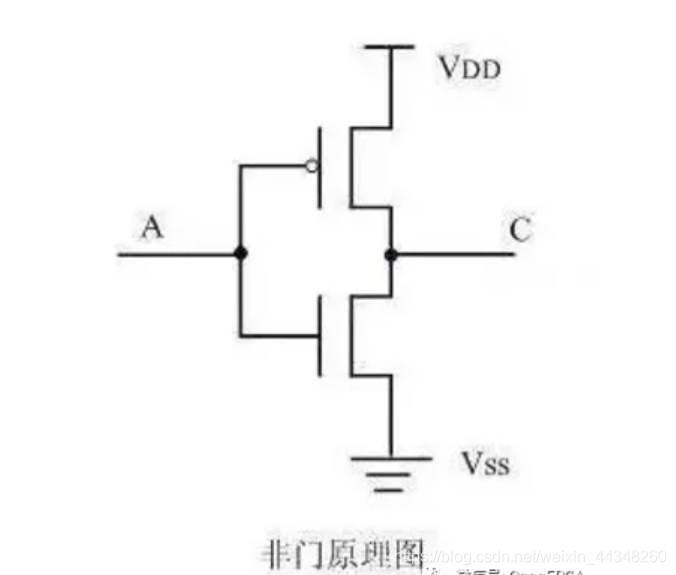
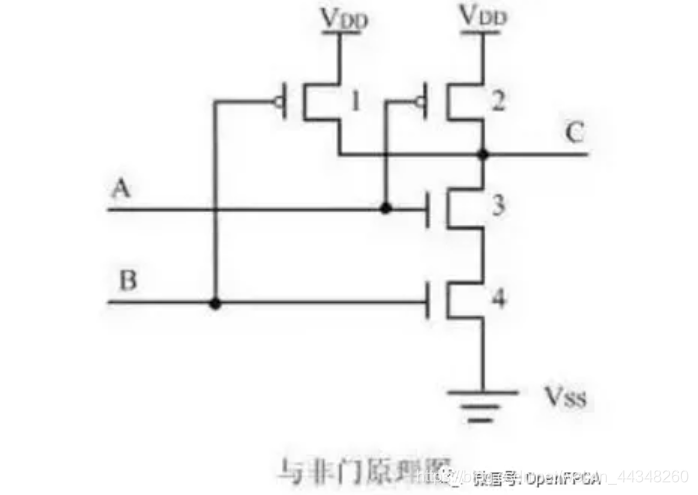
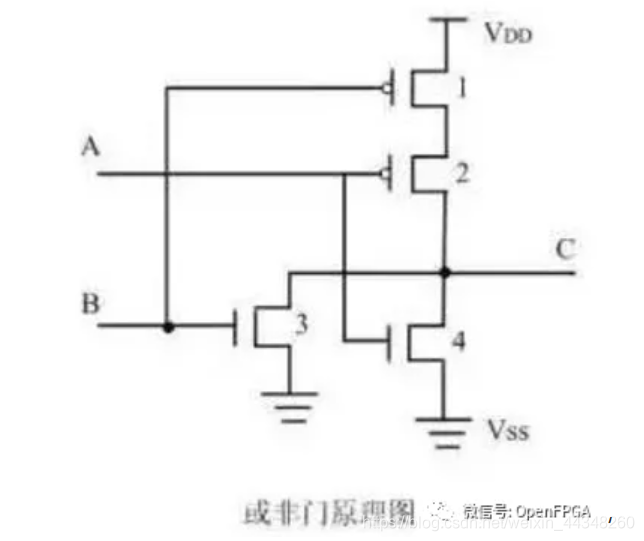
总体来看还是挺好记的,与非门和或非门都是上下各两个MOS管,且上面是PMOS,下面是NMOS。不同之处在于与非是“上并下串”,或非是“上串下并”。
28、FPGA详细设计流程(面试提问)
与数字IC设计流程类似,以xilinx vivado工具为例,主要有以下步骤:
系统设计、
RTL级设计、
RTL级仿真、
综合、
门级仿真、
布局布线、
时序仿真、
板级调试。
29、时序约束相关有哪几种时序路径:
input paths:外部引脚到内部寄存器
register-to-register paths:系统内部寄存器到寄存器路径
output paths:内部寄存器到外部引脚的路径
port to port paths:FPGA输入端口到输出端口路径(不常用)
30、创建时序约束的关键步骤:
baseline约束:create clocks define clocks interactions
I/O约束:set input and output delays
例外约束:set timing execptions(set_max_delay/set_min_delay、set_multicycle_path、set_false_path)
设计初期可先不加I/O约束,但baseline约束要尽早建立。
31、 SRAM和DRAM的区别
SRAM是静态随机访问存储器,由晶体管存储数据,无需刷新,读写速度快。DRAM是动态随机访问存储器,由电容存储数据,由于电容漏电需要动态刷新,电容充放电导致读写速度较SRAM低。但DRAM成本较低,适合做大容量片外缓存。

