
- 1「云上探索实验室」直播预约开始啦,帮你一站解锁顶尖模型的无限可能
- 2mysql时间相关函数_mysql 时间函数
- 3[Mac OS X] 内核、驱动开发资料汇总_mac os 硬件驱动开发
- 4利用Nginx搭建一个apt服务器_虚拟机做代理执行apt安装
- 5springboot+mybatis-plus多租户动态切换数据源_根据租户id切换数据源
- 6手把手教你学习汇编语言——从入门到起飞_汇编学习
- 7GANs系列:CGAN(条件GAN)原理简介以及项目代码实现
- 8简单的用Python采集股票数据,保存表格后分析历史数据_python分析股票历史数据
- 9stm32与esp8266WIFI模块
- 10Docker下安装OnlyOffice文档服务_docker pull onlyoffice/documentserver
【数据开发】pyspark入门与RDD编程
赞
踩
【数据开发】pyspark入门与RDD编程
1、pyspark介绍
pyspark的用途
- 机器学习
- 专有的数据分析。
- 数据科学
- 使用Python和支持性库的大数据。
spark与pyspark的关系
- spark是一种计算引擎,类似于hadoop架构下mapreduce,与mapreduce不同的是将计算的结果存入hdfs分布式文件系统。spark则是写入内存中,像mysql一样可以实现实时的计算,包括SQL查询。
- spark不单单支持传统批量处理应用,更支持交互式查询、流式计算、机器学习、图计算等各种应用,
- spark是由scala语言开发,具备python的接口,就是pyspark。
- 简单理解,Pyspark是Spark的Python API,它允许Python开发者使用Python语言编写Spark程序,并且可以与其他Python库和工具集成。
pysql和pyspark的区别
- 不同语言的支持范围:pysql只负责提交sql,pyspark则适合sql处理不了的逻辑
- 第三方py库支持:pysql不支持依赖第三方py库,pyspark可以支持依赖
- 返回数据条数限制:pysql单节点运行py逻辑,仅支持2w条数据;pyspark用分布式集群去执行复杂的逻辑,能支持全量数据。
pyspark安装与使用
- 数据环境:
pip install pyspark - 安装环境:Anaconda+Jupyter Notebooks
- 其他:Hive/TDW库等相关的包
Spark提供了6大组件:
Spark Core
Spark SQL
Spark Streaming
Spark MLlib
Spark GraphX
SparkR
这些组件解决了使用Hadoop时碰到的特定问题。


2、RDD与基础概念
RDD模型是什么?
-
RDD ( Resilient Distributed Dataset )叫做弹性分布式数据集,是Spark的一种数据抽象集合。
-
它可以被执行在分布式的集群上进行各种操作,而且有较强的容错机制。RDD可以被分为若干个分区,每一个分区就是一个数据集片段,从而可以支持分布式计算。
-
通俗点来讲,可以将 RDD 理解为一个分布式对象集合,本质上是一个只读的分区记录集合。每个 RDD 可以分成多个分区,每个分区就是一个数据集片段。一个 RDD 的不同分区可以保存到集群中的不同结点上,从而可以在集群中的不同结点上进行并行计算。
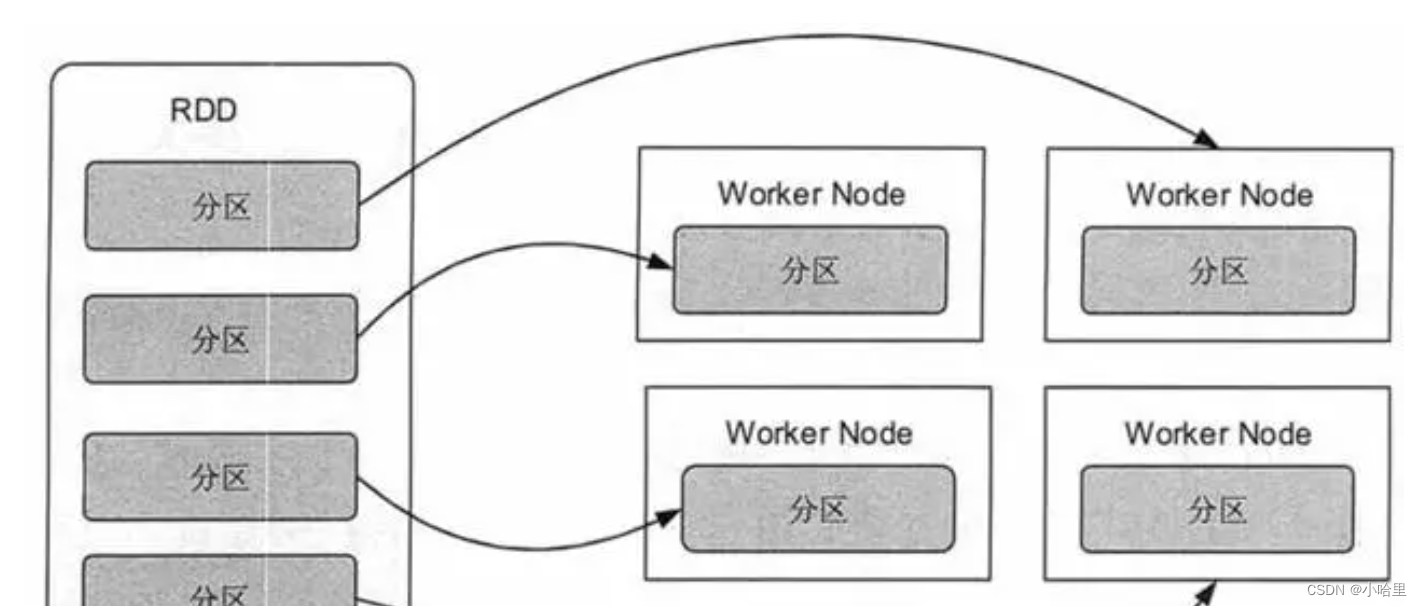
RDD运行时相关的关键名词:
- Client、Job、Master、Worker、Driver、Stage、Task以及Executor
- Client:指的是客户端进程,主要负责提交job到Master;
- Job:Job来自于我们编写的程序,Application包含一个或者多个job,job包含各种RDD操作;
- Master:指的是Standalone模式中的主控节点,负责接收来自Client的job,并管理着worker,可以给worker分配任务和资源(主要是driver和executor资源);
- Worker:指的是Standalone模式中的slave节点,负责管理本节点的资源,同时受Master管理,需要定期给Master回报heartbeat(心跳),启动Driver和Executor;
- Driver:指的是 job(作业)的主进程,一般每个Spark作业都会有一个Driver进程,负责整个作业的运行,包括了job的解析、Stage的生成、调度Task到Executor上去执行;
- Stage:中文名 阶段,是job的基本调度单位,因为每个job会分成若干组Task,每组任务就被称为 Stage;
- Task:任务,指的是直接运行在executor上的东西,是executor上的一个线程;
- Executor:指的是 执行器,顾名思义就是真正执行任务的地方了,一个集群可以被配置若干个Executor,每个Executor接收来自Driver的Task,并执行它(可同时执行多个Task)。
- 更多可以参考
RDD任务调度的原理(血缘关系)
- DAG有向无环图,Spark就是借用了DAG对RDD之间的关系进行了建模,用来描述RDD之间的因果依赖关系。因为在一个Spark作业调度中,多个作业任务之间也是相互依赖的,有些任务需要在一些任务执行完成了才可以执行的。
- RDD 的最重要的特性之一就是血缘关系(Lineage ),它描述了一个 RDD 是如何从父 RDD 计算得来的。如果某个 RDD 丢失了,则可以根据血缘关系,从父 RDD 计算得来。
Spark的部署模式有哪些
- 主要有local模式、Standalone模式、Mesos模式、YARN模式。
- 更多可以参考
Shuffle操作是什么
- Shuffle指的是数据从Map端到Reduce端的数据传输过程,Shuffle性能的高低直接会影响程序的性能。因为Reduce task需要跨节点去拉在分布在不同节点上的Map task计算结果,这一个过程是需要有磁盘IO消耗以及数据网络传输的消耗的,所以需要根据实际数据情况进行适当调整。
- 另外,Shuffle可以分为两部分,分别是Map阶段的数据准备与Reduce阶段的数据拷贝处理,在Map端我们叫Shuffle Write,在Reduce端我们叫Shuffle Read。
RDD操作与惰性执行
-
对于 Spark 处理的大量数据而言,会将数据切分后放入RDD作为Spark 的基本数据结构,开发者可以在 RDD 上进行丰富的操作,之后 Spark 会根据操作调度集群资源进行计算。
-
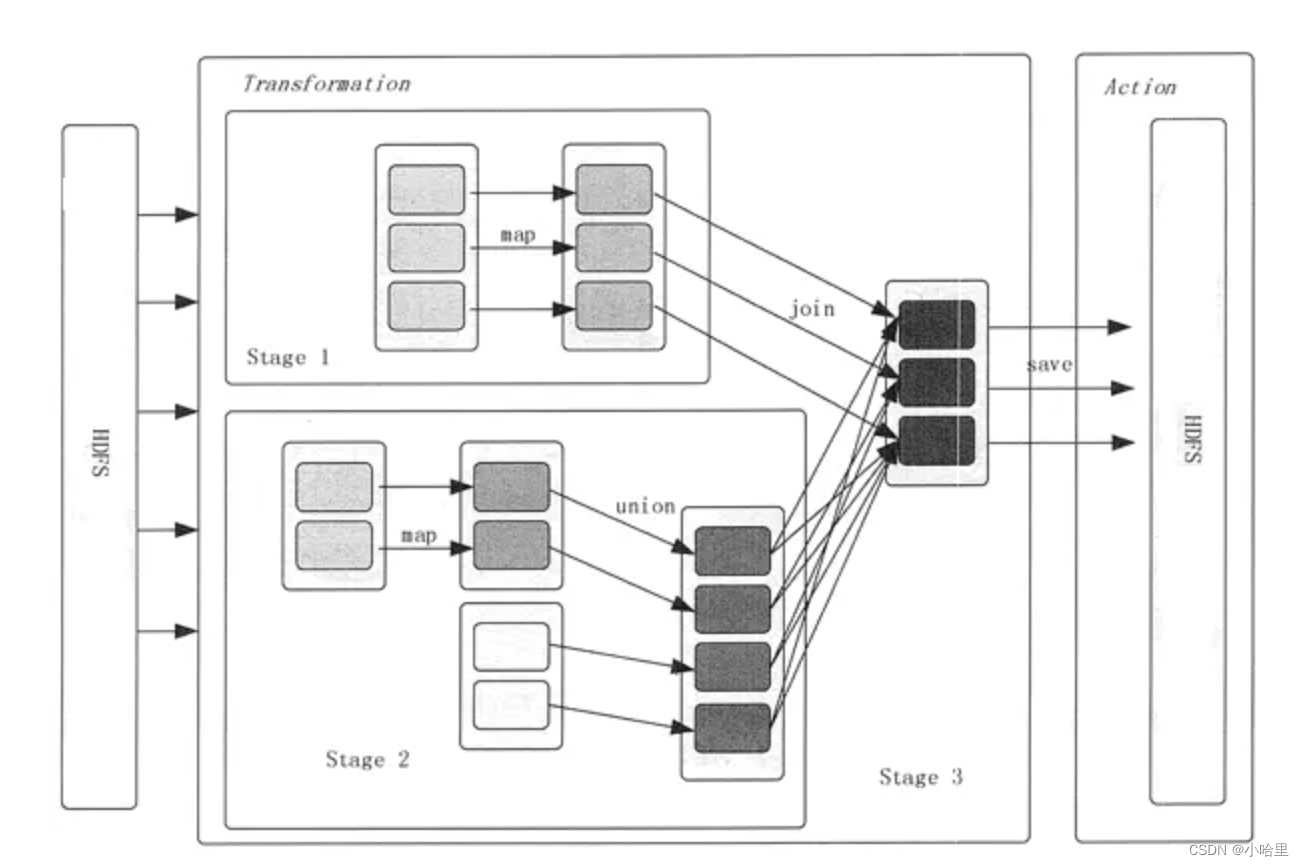
RDD 的操作分为转化(Transformation)操作和行动(Action)操作。转化操作就是从一个 RDD 产生一个新的 RDD,而行动操作就是进行实际的计算。
-
RDD 的操作是惰性的,当 RDD 执行转化操作的时候,实际计算并没有被执行,只有当 RDD 执行行动操作时才会促发计算任务提交,从而执行相应的计算操作。
RDD缓存优化
- 因为惰性求值的,而有时候希望能多次使用同一个 RDD。如果简单地对 RDD 调用行动操作,Spark 每次都会重算 RDD 及它的依赖,这样就会带来太大的消耗。为了避免多次计算同一个 RDD,可以让 Spark 对数据进行持久化。
- Spark 可以使用 persist 和 cache 方法将任意 RDD 缓存到内存、磁盘文件系统中。缓存是容错的,如果一个 RDD 分片丢失,则可以通过构建它的转换来自动重构。被缓存的 RDD 被使用时,存取速度会被大大加速。一般情况下,Executor 内存的 60% 会分配给 cache,剩下的 40% 用来执行任务。
3、RDD编程
3.1 Transformation/Action
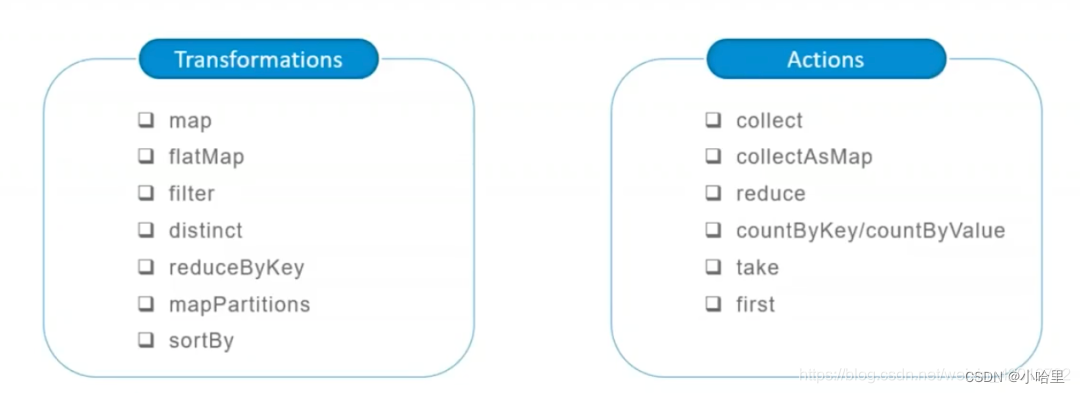
转化操作:
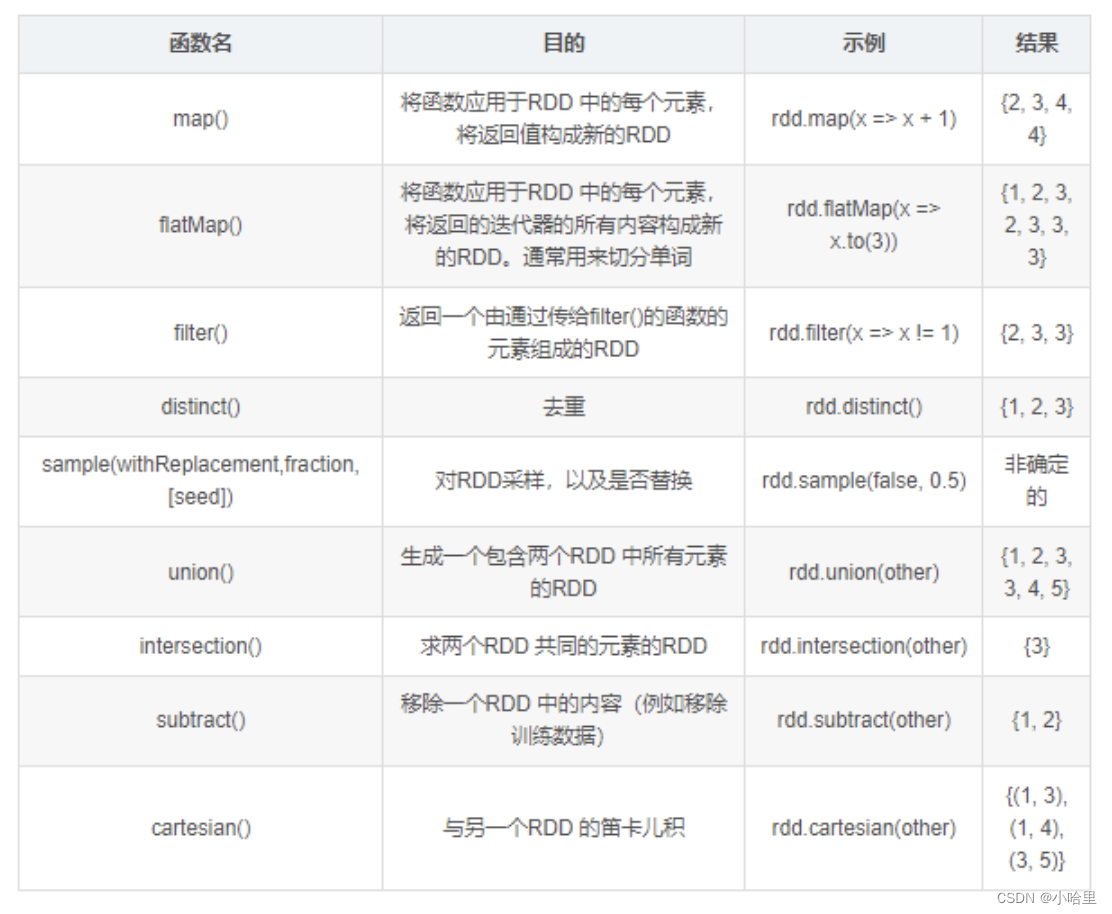
行动操作:
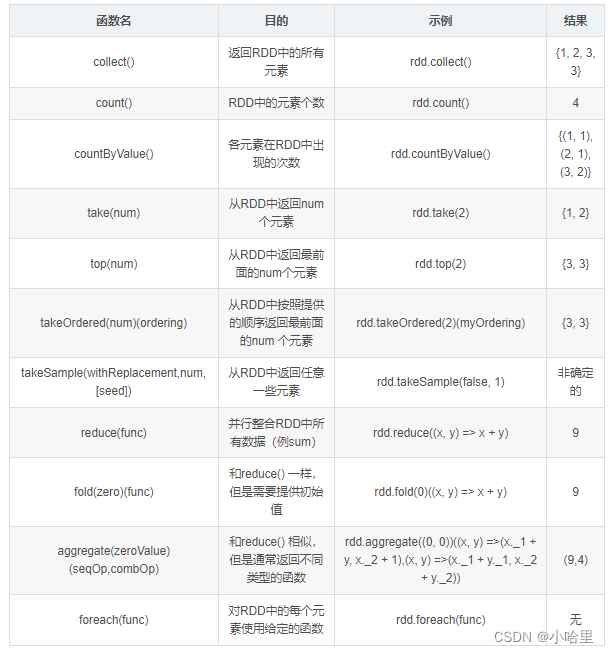
两大类示例:
import os
import pyspark
from pyspark import SparkContext, SparkConf
conf = SparkConf().setAppName("test_SamShare").setMaster("local[4]")
sc = SparkContext(conf=conf)
# 使用 parallelize方法直接实例化一个RDD
rdd = sc.parallelize(range(1,11),4) # 这里的 4 指的是分区数量
rdd.take(100)
# [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
"""
----------------------------------------------
Transform算子解析
----------------------------------------------
"""
# 以下的操作由于是Transform操作,因为我们需要在最后加上一个collect算子用来触发计算。
# 1. map: 和python差不多,map转换就是对每一个元素进行一个映射
rdd = sc.parallelize(range(1, 11), 4)
rdd_map = rdd.map(lambda x: x*2)
print("原始数据:", rdd.collect())
print("扩大2倍:", rdd_map.collect())
# 原始数据: [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# 扩大2倍: [2, 4, 6, 8, 10, 12, 14, 16, 18, 20]
# 2. flatMap: 这个相比于map多一个flat(压平)操作,顾名思义就是要把高维的数组变成一维
rdd2 = sc.parallelize(["hello SamShare", "hello PySpark"])
print("原始数据:", rdd2.collect())
print("直接split之后的map结果:", rdd2.map(lambda x: x.split(" ")).collect())
print("直接split之后的flatMap结果:", rdd2.flatMap(lambda x: x.split(" ")).collect())
# 直接split之后的map结果: [['hello', 'SamShare'], ['hello', 'PySpark']]
# 直接split之后的flatMap结果: ['hello', 'SamShare', 'hello', 'PySpark']
# 3. filter: 过滤数据
rdd = sc.parallelize(range(1, 11), 4)
print("原始数据:", rdd.collect())
print("过滤奇数:", rdd.filter(lambda x: x % 2 == 0).collect())
# 原始数据: [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# 过滤奇数: [2, 4, 6, 8, 10]
# 4. distinct: 去重元素
rdd = sc.parallelize([2, 2, 4, 8, 8, 8, 8, 16, 32, 32])
print("原始数据:", rdd.collect())
print("去重数据:", rdd.distinct().collect())
# 原始数据: [2, 2, 4, 8, 8, 8, 8, 16, 32, 32]
# 去重数据: [4, 8, 16, 32, 2]
# 5. reduceByKey: 根据key来映射数据
from operator import add
rdd = sc.parallelize([("a", 1), ("b", 1), ("a", 1)])
print("原始数据:", rdd.collect())
print("原始数据:", rdd.reduceByKey(add).collect())
# 原始数据: [('a', 1), ('b', 1), ('a', 1)]
# 原始数据: [('b', 1), ('a', 2)]
# 6. mapPartitions: 根据分区内的数据进行映射操作
rdd = sc.parallelize([1, 2, 3, 4], 2)
def f(iterator):
yield sum(iterator)
print(rdd.collect())
print(rdd.mapPartitions(f).collect())
# [1, 2, 3, 4]
# [3, 7]
# 7. sortBy: 根据规则进行排序
tmp = [('a', 1), ('b', 2), ('1', 3), ('d', 4), ('2', 5)]
print(sc.parallelize(tmp).sortBy(lambda x: x[0]).collect())
print(sc.parallelize(tmp).sortBy(lambda x: x[1]).collect())
# [('1', 3), ('2', 5), ('a', 1), ('b', 2), ('d', 4)]
# [('a', 1), ('b', 2), ('1', 3), ('d', 4), ('2', 5)]
# 8. subtract: 数据集相减, Return each value in self that is not contained in other.
x = sc.parallelize([("a", 1), ("b", 4), ("b", 5), ("a", 3)])
y = sc.parallelize([("a", 3), ("c", None)])
print(sorted(x.subtract(y).collect()))
# [('a', 1), ('b', 4), ('b', 5)]
# 9. union: 合并两个RDD
rdd = sc.parallelize([1, 1, 2, 3])
print(rdd.union(rdd).collect())
# [1, 1, 2, 3, 1, 1, 2, 3]
# 10. interp: 取两个RDD的交集,同时有去重的功效
rdd1 = sc.parallelize([1, 10, 2, 3, 4, 5, 2, 3])
rdd2 = sc.parallelize([1, 6, 2, 3, 7, 8])
print(rdd1.interp(rdd2).collect())
# [1, 2, 3]
# 11. cartesian: 生成笛卡尔积
rdd = sc.parallelize([1, 2])
print(sorted(rdd.cartesian(rdd).collect()))
# [(1, 1), (1, 2), (2, 1), (2, 2)]
# 12. zip: 拉链合并,需要两个RDD具有相同的长度以及分区数量
x = sc.parallelize(range(0, 5))
y = sc.parallelize(range(1000, 1005))
print(x.collect())
print(y.collect())
print(x.zip(y).collect())
# [0, 1, 2, 3, 4]
# [1000, 1001, 1002, 1003, 1004]
# [(0, 1000), (1, 1001), (2, 1002), (3, 1003), (4, 1004)]
# 13. zipWithIndex: 将RDD和一个从0开始的递增序列按照拉链方式连接。
rdd_name = sc.parallelize(["LiLei", "Hanmeimei", "Lily", "Lucy", "Ann", "Dachui", "RuHua"])
rdd_index = rdd_name.zipWithIndex()
print(rdd_index.collect())
# [('LiLei', 0), ('Hanmeimei', 1), ('Lily', 2), ('Lucy', 3), ('Ann', 4), ('Dachui', 5), ('RuHua', 6)]
# 14. groupByKey: 按照key来聚合数据
rdd = sc.parallelize([("a", 1), ("b", 1), ("a", 1)])
print(rdd.collect())
print(sorted(rdd.groupByKey().mapValues(len).collect()))
print(sorted(rdd.groupByKey().mapValues(list).collect()))
# [('a', 1), ('b', 1), ('a', 1)]
# [('a', 2), ('b', 1)]
# [('a', [1, 1]), ('b', [1])]
# 15. sortByKey:
tmp = [('a', 1), ('b', 2), ('1', 3), ('d', 4), ('2', 5)]
print(sc.parallelize(tmp).sortByKey(True, 1).collect())
# [('1', 3), ('2', 5), ('a', 1), ('b', 2), ('d', 4)]
# 16. join:
x = sc.parallelize([("a", 1), ("b", 4)])
y = sc.parallelize([("a", 2), ("a", 3)])
print(sorted(x.join(y).collect()))
# [('a', (1, 2)), ('a', (1, 3))]
# 17. leftOuterJoin/rightOuterJoin
x = sc.parallelize([("a", 1), ("b", 4)])
y = sc.parallelize([("a", 2)])
print(sorted(x.leftOuterJoin(y).collect()))
# [('a', (1, 2)), ('b', (4, None))]
"""
----------------------------------------------
Action算子解析
----------------------------------------------
"""
# 1. collect: 指的是把数据都汇集到driver端,便于后续的操作
rdd = sc.parallelize(range(0, 5))
rdd_collect = rdd.collect()
print(rdd_collect)
# [0, 1, 2, 3, 4]
# 2. first: 取第一个元素
sc.parallelize([2, 3, 4]).first()
# 2
# 3. collectAsMap: 转换为dict,使用这个要注意了,不要对大数据用,不然全部载入到driver端会爆内存
m = sc.parallelize([(1, 2), (3, 4)]).collectAsMap()
m
# {1: 2, 3: 4}
# 4. reduce: 逐步对两个元素进行操作
rdd = sc.parallelize(range(10),5)
print(rdd.reduce(lambda x,y:x+y))
# 45
# 5. countByKey/countByValue:
rdd = sc.parallelize([("a", 1), ("b", 1), ("a", 1)])
print(sorted(rdd.countByKey().items()))
print(sorted(rdd.countByValue().items()))
# [('a', 2), ('b', 1)]
# [(('a', 1), 2), (('b', 1), 1)]
# 6. take: 相当于取几个数据到driver端
rdd = sc.parallelize([("a", 1), ("b", 1), ("a", 1)])
print(rdd.take(5))
# [('a', 1), ('b', 1), ('a', 1)]
# 7. saveAsTextFile: 保存rdd成text文件到本地
text_file = "./data/rdd.txt"
rdd = sc.parallelize(range(5))
rdd.saveAsTextFile(text_file)
# 8. takeSample: 随机取数
rdd = sc.textFile("./test/data/hello_samshare.txt", 4) # 这里的 4 指的是分区数量
rdd_sample = rdd.takeSample(True, 2, 0) # withReplacement 参数1:代表是否是有放回抽样
rdd_sample
# 9. foreach: 对每一个元素执行某种操作,不生成新的RDD
rdd = sc.parallelize(range(10), 5)
accum = sc.accumulator(0)
rdd.foreach(lambda x: accum.add(x))
print(accum.value)
# 45
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
3.2 数据开发流程与环节
创建会话
import pyspark
from pyspark.sql import SparkSession
session = SparkSession.builder.appName('First App').getOrCreate()
session
spark_session = SparkSession.builder.getOrCreate()
table_data = [row.asDict() for row in spark_session.sql('''
SELECT
xxx,
id,
xxx,
xxx,
from aaa.bbb
where ds = {} and xxx != 0
'''.format(newds).collect()]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
读取数据
# 支持csv格式jdbc加载选项选项orc脚本模式表文本
data = session.read.csv('Datasets/titanic.csv')
# 检索带有标题的数据集
data = session.read.option.('header', 'true').csv('Datasets/titanic.csv')
data.show()
# 类似于pandas中使用info()
data.printSchema()
# 文本
data=sc.textFile("file://home/README.md")
data.saveAsTextFile(outputFile)
# json
import json
data=input.map(lambdax:json.loads(x))
data.filter(lambda x:x["lovesPandas"]).map(lambda x:json.dumps(x)).saveAsTextFile(outputFile)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
数据过滤
select:
用于过滤符合条件的行,返回一个新的dataframe,支持选择一个或多个列。
df.select("列名")
df.select(col("列名"))
df.select(expr("sql表达式"))
dataframe.select(column_name)
dataframe.select(column_1, column_2, .., column_N)
collect:
返回一个list,每个元素为Row。可以通过df.collect()方法将dataframe转换为可遍历的dict列表。
filter:
data = data.filter(data['Survived'] == 1)
data.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
数据清洗
# 添加一列
data = data.withColumn('Age_after_3_y', data['Age']+3)
# 删除一列
dataframe = dataframe.drop('column_name in strings')
data = data.drop('Age_after_3_y')
dataframe.show()
# 改列名
data = data.na.drop(how = 'any', thresh = 2)
data.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
多表计算
join:类似于sql的join操作
df1.join(df2, 'on的列名', 'join选项')
其中join选项默认是'inner',可以自行选择其他join方法如:left, full, right, leftouter...
- 1
- 2
- 3
- 4
- 5
- 6
- 7

