
热门标签
热门文章
- 1vscode 添加插件 提示 class_vscodecss提示插件
- 2【Linux】gitee仓库的注册使用以及在Linux上远程把代码上传到gitee上的方法_虚拟机怎么把代码上传到gitee上
- 3安卓玩机搞机-----第三方HyperOS 移植教程 其他机型可借鉴参考_oppo移植包修复自动亮度
- 4Charles抓包App教程_charles抓取手机端的包
- 5计算机网络2
- 6总结顺序表的几种存储方式_顺序表的存储方式
- 7渗透测试报告模板
- 8windows 配置Co-DETR踩坑笔记_co-detr 环境配置
- 9关于ROS——moveit——ABB机械臂——fanuc机械臂_abb机械臂ros
- 10【数据结构篇】线性表1 --- 顺序表、链表 (万字详解!!)_数据结构线性表
当前位置: article > 正文
30 个Python爬虫的实战项目(附源码)_爬虫实战项目
作者:羊村懒王 | 2024-04-27 12:16:25
赞
踩
爬虫实战项目
大家好,我是彭涛。
Python爬虫相关的学习资料,我们之前也为大家整理了很多,无论是思维导图,基础知识点,还是常见问题。

但是理论的知识总是比较单薄的,只有通过实战才可以真正的将掌握知识点。
所以,Python实战项目练习,它来了!


这份资源涵盖了从基础到高级的内容,旨在帮助大家逐步掌握爬虫技术。
首先,将学习如何使用Requests库发起HTTP请求,并解析HTML页面,提取关键信息,最后将数据存储到本地文件或数据库。

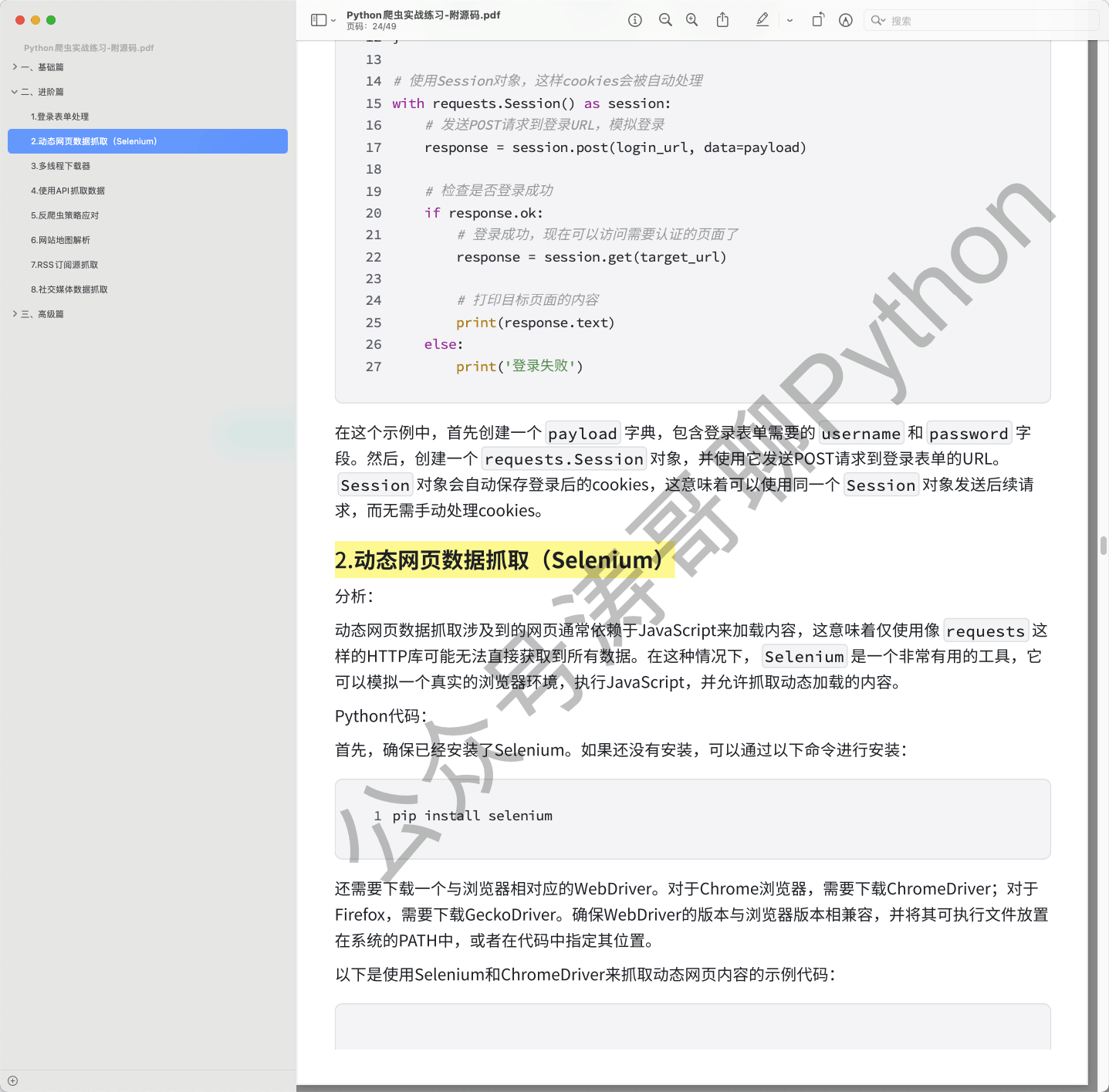
接着,将进入到动态网页数据抓取的领域。通过学习Selenium模拟浏览器操作,处理JavaScript渲染的页面,并通过XPath或CSS选择器提取数据,能够应对更加复杂的网页结构,实现进阶级的爬虫项目。
高级项目中,需要练习分布式爬虫以及处理验证码、Webhooks实现数据实时抓取等,保证爬取数据的稳定性和准确性。
同时,也将学习到数据清洗与去重的技术,此外,使用Scrapy框架可以加速爬虫开发,提高效率。

这份资源的核心在于实践。通过动手编写爬虫程序,加深对爬虫技术的理解和掌握,并能够将这些技能应用到实际项目中。
只有在实践中,才能真正掌握和应用这些知识,达到从入门到精通的水平。
领取方式
长按扫码发送:「842」

长按发送「842」
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/羊村懒王/article/detail/496695
推荐阅读

相关标签

