
- 1#map函数 #split_python把一个map切分为n份
- 2php使用RabbitMQ详解_php rabbitmq文档
- 3java区块链技术web3j_web3j介绍及基本使用
- 4AI Challenger 植物病害识别项目:利用深度学习守护绿色世界
- 5rabbitMQ配置文件_rabbitmq.config
- 6#头歌 算法 应用经典二叉树编程-Falling Leaves(中文版)
- 7C语言-字符数组_c语言字符串数组
- 8Python + Echarts + PyQt5在量化软件中实现动态刷新K线_python pyecharts k线
- 9【L1正则化与L2正则化详解及为什么L1和L2正则化可防止过拟合】_为什么有l2正则化后还要拥有l1正则化
- 10docker-compose部署RabbitMQ分布式集群_docker-compose 做rabbitmq 集群
如何在Python中使用ChatGPT API处理实时数据_github上python chatgpt
赞
踩
OpenAI公司推出的GPT如今已经成为全球最重要的人工智能工具,并精通基于其训练数据处理查询。但是,它不能回答未知话题的问题,例如:
- 2021年9月之后的近期事件
- 非公开文件
- 来自过去谈话的信息
当用户处理频繁变化的实时数据时,这项任务变得更加复杂。此外,用户不能向GPT提供大量内容,它也不能长时间保留他们的数据。在这种情况下,需要有效地构建一个自定义的大型语言模型(LLM)应用程序来为回答过程提供场景。
本文将引导人们完成使用Python中的开源LLM App库开发此类应用程序的步骤。源代码在GitHub上(链接在下面的“为销售构建ChatGPT Python API”一节中)。
学习目标
通过本文了解以下内容:
- 需要添加自定义数据到ChatGPT的原因。
- 如何使用嵌入、提示工程和ChatGPT来更好地回答问题。
- 用户使用LLM应用程序与自定义数据构建自己的ChatGPT。
- 创建一个ChatGPT Python API查找实时折扣或销售价格。
为什么为ChatGPT提供自定义知识库?
在讨论增强ChatGPT功能的方法之前,首先探索人工方法并确定它们面临的挑战。通常情况下,ChatGPT通过提示工程进行扩展。假设用户想在各种在线市场上找到实时折扣/交易/优惠券。
例如,当询问ChatGPT,“你能帮我找到阿迪达斯男鞋在本周的折扣吗?”,在没有自定义知识的情况下,可能从ChatGPT UI界面得到的标准回答是:
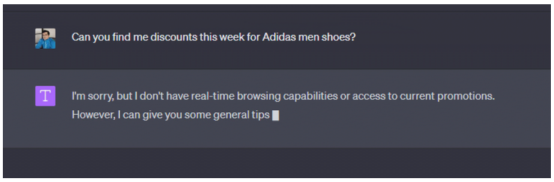
显然,ChatGPT提供了关于寻找折扣的通常建议,但缺乏关于在哪里或什么类型的折扣以及其他细节的具体信息。现在为了帮助这个模型,使用来自可靠数据源的折扣信息对其进行补充。在发布实际问题之前,必须通过添加初始文档内容来参与ChatGPT。将从Amazon产品交易数据集中收集这一示例数据,并在提示中仅插入一个JSON项:
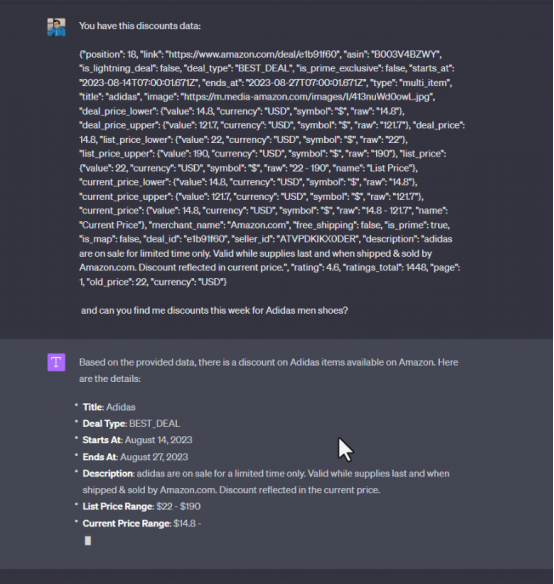
如上图所示,用户得到了预期的输出,这很容易实现,因为ChatGPT现在是场景感知的。然而,这种方法的问题是模型的场景受到限制(GPT-4的最大文本长度为8,192个令牌)。当输入数据规模非常大时,这种策略很快就会出现问题,用户可能希望在销售中发现数千种商品,而无法将如此大量的数据作为输入消息提供。此外,一旦收集了数据,可能需要对数据进行清理、格式化和预处理,以确保数据质量和相关性。
如果用户使用OpenAI聊天完成度端点或为ChatGPT构建自定义插件,它会引入以下其他问题:
- 成本—通过提供更详细的信息和示例,大型语言模型的性能可能会得到改善,尽管成本更高(对于输入10000个令牌和输出200个令牌的GPT-4,每次预测的成本为0.624美元)。重复发送相同的请求会增加成本,除非使用本地缓存系统。
- 延迟—在生产中使用ChatGPT API的一个挑战是它们的不可预测性,不能保证提供一致的服务。
- 安全性—当集成自定义插件时,每个API端点必须在OpenAPI规范中指定功能。这意味着用户正在向ChatGPT泄露其内部API设置,这是令许多企业担心的风险。
- 离线评估—对代码和数据输出进行离线测试或在本地复制数据流对开发人员来说是具有挑战性的。这是因为对系统的每个请求可能产生不同的响应。
使用嵌入、提示工程和ChatGPT进行问答
人们在互联网上发现的一种很有前途的方法是利用大型语言模型(LLM)创建嵌入,然后使用这些嵌入构建应用程序,例如用于搜索和询问系统。换句话说,不是使用聊天完成端点查询ChatGPT,而是执行以下查询:
给定以下折扣数据:{input_data},回答这个查询:{user_query}。
这个概念很简单。这种方法不是直接发布问题,而是首先通过OpenAI API为每个输入文档(文本、图像、CSV、PDF或其他类型的数据)创建向量嵌入,然后对生成的嵌入进行索引以便快速检索,并将其存储到向量数据库中,并利用用户的问题从向量数据库中搜索并获得相关文档。然后将这些文档与问题一起作为提示呈现给ChatGPT。有了这个添加的场景,ChatGPT就可以像在内部数据集上训练一样进行响应。
另一方面,如果使用Pathway的LLM App,甚至不需要任何矢量数据库。它实现了实时内存数据索引,直接从任何兼容的存储中读取数据,而无需查询矢量文档数据库,而这会增加准备工作、基础设施和复杂性等成本。保持源和矢量同步是很痛苦的。此外,如果带下划线的输入数据随时间变化而需要重新索引,则会更加困难。
ChatGPT自定义数据使用LLM App
下面这些简单的步骤解释了使用LLM App为数据构建ChatGPT应用程序的数据管道方法。
- 收集:用户的应用程序从各种数据源(CSV、 JSON Lines、SQL数据库、Kafka、Redpanda、Debezium等)实时读取数据,当流模式与路径启用时或者也可以在静态模式下测试数据摄取。它还将每个数据行映射到结构化文档模式中,以便更好地管理大型数据集。
- 预处理:可以选择通过删除可能影响回答质量的重复、不相关信息和嘈杂数据,并提取需要进一步处理的数据字段,从而轻松地进行数据清理。此外,在这个阶段,可以屏蔽或隐藏隐私数据,以避免将它们发送到ChatGPT。
- 嵌入:每个文档都嵌入了OpenAI API,并检索嵌入的结果。
- 索引:在实时生成的嵌入上构建索引。
- 搜索:给定来自API友好界面的用户问题,从OpenAI API生成查询的嵌入。使用嵌入,根据与查询的相关性动态检索向量索引。
- 提问:将问题和最相关的部分插入到GPT的信息中。返回GPT的答案(聊天完成端点)。
为销售构建ChatGPT Python API
在对LLM App的工作过程有了清晰的了解之后,可以按照下面的步骤来了解如何构建折扣查找器应用程序。其项目源代码可以在GitHub上找到。如果想快速开始使用这个应用程序,可以跳过这一部分直接克隆存储库,并按照README.md文件中的说明运行代码示例。
项目目标示例
受到一篇关于企业搜索的文章的启发,这一示例应用程序应该在Python中公开一个HTTP REST API端点,通过从各种来源(CSV、Jsonlines、API、消息代理或数据库)检索最新交易来回答用户对当前销售的查询,并利用OpenAI API嵌入和聊天完成端点生成式人工智能助理响应。
步骤1:数据收集(自定义数据摄取)
为了简单起见,可以使用任何JSON行作为数据源。这个应用程序采用discounts.jsonl等JSON Lines文件,并在处理用户查询时使用这些数据。数据源希望每行都有一个文档对象。确保首先将输入数据转换为Jsonline。下面是一个带有单个raw的Jsonline文件的示例:
{"doc": "{'position': 1, 'link': 'https://www.amazon.com/deal/6123cc9f', 'asin': 'B00QVKOT0U', 'is_lightning_deal': False, 'deal_type': 'DEAL_OF_THE_DAY', 'is_prime_exclusive': False, 'starts_at': '2023-08-15T00:00:01.665Z', 'ends_at': '2023-08-17T14:55:01.665Z', 'type': 'multi_item', 'title': 'Deal on Crocs, DUNLOP REFINED(\u30c0\u30f3\u30ed\u30c3\u30d7\u30ea\u30d5\u30a1\u30a4\u30f3\u30c9)', 'image': 'https://m.media-amazon.com/images/I/41yFkNSlMcL.jpg', 'deal_price_lower': {'value': 35.48, 'currency': 'USD', 'symbol': '$', 'raw': '35.48'}, 'deal_price_upper': {'value': 52.14, 'currency': 'USD', 'symbol': '$', 'raw': '52.14'}, 'deal_price': 35.48, 'list_price_lower': {'value': 49.99, 'currency': 'USD', 'symbol': '$', 'raw': '49.99'}, 'list_price_upper': {'value': 59.99, 'currency': 'USD', 'symbol': '$', 'raw': '59.99'}, 'list_price': {'value': 49.99, 'currency': 'USD', 'symbol': '$', 'raw': '49.99 - 59.99', 'name': 'List Price'}, 'current_price_lower': {'value': 35.48, 'currency': 'USD', 'symbol': '$', 'raw': '35.48'}, 'current_price_upper': {'value': 52.14, 'currency': 'USD', 'symbol': '$', 'raw': '52.14'}, 'current_price': {'value': 35.48, 'currency': 'USD', 'symbol': '$', 'raw': '35.48 - 52.14', 'name': 'Current Price'}, 'merchant_name': 'Amazon Japan', 'free_shipping': False, 'is_prime': False, 'is_map': False, 'deal_id': '6123cc9f', 'seller_id': 'A3GZEOQINOCL0Y', 'description': 'Deal on Crocs, DUNLOP REFINED(\u30c0\u30f3\u30ed\u30c3\u30d7\u30ea\u30d5\u30a1\u30a4\u30f3\u30c9)', 'rating': 4.72, 'ratings_total': 6766, 'page': 1, 'old_price': 49.99, 'currency': 'USD'}"}最酷的是,这个应用程序总是能意识到数据文件夹中的更改。如果添加另一个JSON Lines文件,LLM App就会发挥神奇的作用,自动更新人工智能模型的响应。
步骤2:数据加载和映射
使用Pathway的JSON Lines输入连接器,将读取本地JSONlines文件,将数据条目映射到模式中,并创建一个路径表。可以参阅app.py中的完整源代码:
- ...
- sales_data = pw.io.jsonlines.read(
- "./examples/data",
- schema=DataInputSchema,
- mode="streaming"
- )
将每个数据行映射到结构化文档模式。可以参阅App.py中的完整源代码:
- class DataInputSchema(pw.Schema):
- doc: str
步骤3:数据嵌入
每个文档都嵌入了OpenAI API,并检索嵌入的结果。可以参阅app.py中的完整源代码:
- ...
- embedded_data = embeddings(cnotallow=sales_data, data_to_embed=sales_data.doc)
步骤4:数据索引
然后在生成的嵌入上构建一个即时索引:
index = index_embeddings(embedded_data)步骤5:用户查询处理和索引
创建一个REST端点,从API请求负载中获取用户查询,并将用户查询嵌入OpenAI API。
- ...
- query, response_writer = pw.io.http.rest_connector(
- host=host,
- port=port,
- schema=QueryInputSchema,
- autocommit_duration_ms=50,
- )
- embedded_query = embeddings(cnotallow=query, data_to_embed=pw.this.query)
步骤6:相似性搜索和提示工程
通过使用索引来识别查询嵌入的最相关匹配来执行相似性搜索。然后构建一个提示,将用户的查询与获取的相关数据结果合并,并将消息发送到ChatGPT完成端点,以生成正确且详细的响应。
responses = prompt(index, embedded_query, pw.this.query)当制作提示符并在prompt.py中向ChatGPT添加内部知识时,遵循了相同的场景学习方法。
prompt = f"Given the following discounts data: \\n {docs_str} \\nanswer this query: {query}"步骤7:返回响应
最后一步就是将API响应返回给用户。
- # Build prompt using indexed data
- responses = prompt(index, embedded_query, pw.this.query)
步骤8:将把所有步骤放在一起
现在,如果将上述所有步骤放在一起,就拥有了用于自定义折扣数据的支持LLM的Python API,可以在app.py Python脚本中看到实现。
- import pathway as pw
- from common.embedder import embeddings, index_embeddings
- from common.prompt import prompt
- def run(host, port):
- # Given a user question as a query from your API
- query, response_writer = pw.io.http.rest_connector(
- host=host,
- port=port,
- schema=QueryInputSchema,
- autocommit_duration_ms=50,
- )
- # Real-time data coming from external data sources such as jsonlines file
- sales_data = pw.io.jsonlines.read(
- "./examples/data",
- schema=DataInputSchema,
- mode="streaming"
- )
- # Compute embeddings for each document using the OpenAI Embeddings API
- embedded_data = embeddings(cnotallow=sales_data, data_to_embed=sales_data.doc)
- # Construct an index on the generated embeddings in real-time
- index = index_embeddings(embedded_data)
- # Generate embeddings for the query from the OpenAI Embeddings API
- embedded_query = embeddings(cnotallow=query, data_to_embed=pw.this.query)
- # Build prompt using indexed data
- responses = prompt(index, embedded_query, pw.this.query)
- # Feed the prompt to ChatGPT and obtain the generated answer.
- response_writer(responses)
- # Run the pipeline
- pw.run()
- class DataInputSchema(pw.Schema):
- doc: str
- class QueryInputSchema(pw.Schema):
- query: str

步骤9 (可选):添加交互式UI
为了让应用程序更具互动性和用户友好性,可以使用Streamlit来构建一个前端应用。
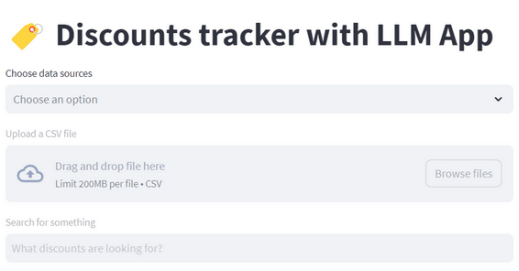
运行应用程序
按照README. Md文件中“如何运行项目”一节中的说明,可以开始询问有关折扣的问题,API将根据添加的折扣数据源做出响应。
在使用UI(应用数据源)将这些知识提供给GPT之后,看看它是如何回复的:
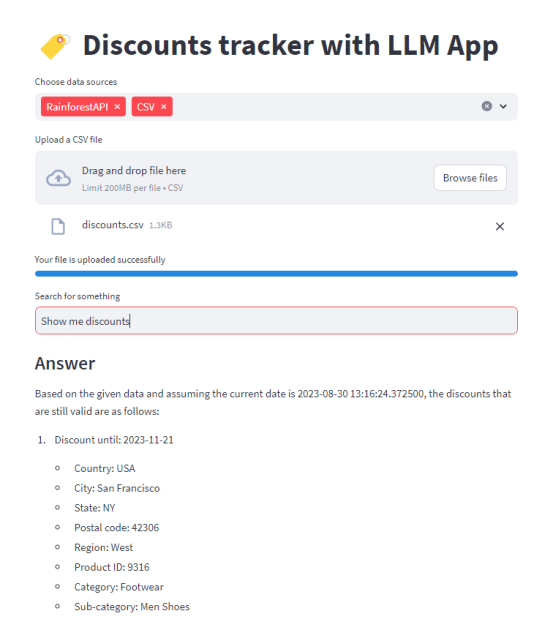
这个应用程序考虑了Rainforest API和discount .csv文件文档(立即合并来自这些来源的数据),实时对其进行索引,并在处理查询时使用这些数据。
进一步的改进
通过向ChatGPT添加折扣等领域特定知识,发现了LLM应用程序的一些功能。还可以做更多的事情:
- 整合来自外部API的额外数据,以及各种文件(例如Jsonlines、PDF、Doc、HTML或Text格式),PostgreSQL或MySQL等数据库,以及来自Kafka、Redpanda或Debedizum等平台的流数据。
- 维护数据快照以观察销售价格随时间的变化,因为Pathway提供了一个内置功能来计算两次更改之间的差异。
- 除了通过API访问数据之外,LLM App还允许用户将处理过的数据中继到其他下游连接器,例如商业智能(BI)和分析工具。例如,设置它在检测到价格变化时接收警报。


