
- 1Vue3 入门笔记 ---- 利用Element Plus对页面进行布局划分以及实现左侧公共菜单_vue3布局页面分为上中下
- 2铜箔镀锡测试
- 3java中常见的限流算法详细解析_java中固定窗口算法
- 4chrome提示不安全_window 排查chrome 非安全模式
- 5功率谱密度计算公式_随机振动功率谱密度曲线的计算
- 6【ITK配准】第二期 多模态配准
- 7记录第一次使用Trtc的网页版和小程序版的已发现问题_腾讯trtc web和小程序不是同一个直播间
- 8MUMU模拟器12连logcat的方法_logcat mumu
- 9模仿dcloudio/uni-preset-vue 自定义基于uni-app的小程序框架
- 10网络编程套接字(三)之TCP服务器简单实现_tcp 服务器 简单
8s pod 查看 的yaml_k8s之深入解剖Pod(三)
赞
踩
目录:
Pod的调度
Pod的扩容和缩容
Pod的滚动升级
一、Pod的调度
Pod只是容器的载体,通常需要通过RC、Deployment、DaemonSet、Job等对象来完成Pod的调度和自动控制功能。
1、RC、Deployment全自动调度
RC的主要功能之一就是自动部署一个容器应用的多份副本,以及持续监控副本的数量,在集群内始终维持用户指定的副本数量。
2、NodeSelector:定向调度
Master上的Schedule负责实现Pod的调度,但无法知道Pod会调度到哪个节点上。可以通过Node的标签(Label)和Pod的nodeSelector属性相匹配,达到将Pod调度到指定的Node上。
(1)首先通过kubectl label命令给目标Node打上标签
kubectl label nodes node-name key=value例如这边给cnode-2和cnode-3添加标签

查看是否已打上标签可以使用如下命令
kubelct describe nodes node-name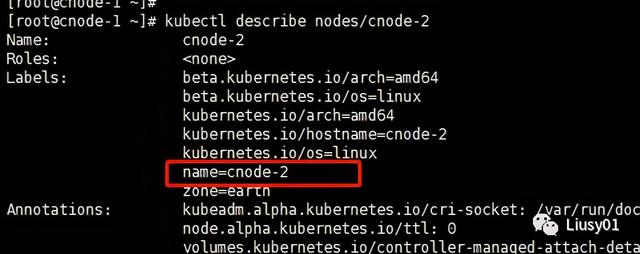
(2)在Pod定义上添加nodeSelector的设置,
apiVersion: v1kind: ReplicationControllermetadata: name: nodeselectorrc labels: name: nodeselectorrcspec: replicas: 1 template: metadata: name: nodeselectorrc labels: name: nodeselectorrc spec: containers: - name: nodeselectorrc image: nginx imagePullPolicy: IfNotPresent ports: - containerPort: 80 nodeSelector: name: cnode-2
【注】如果没有节点有这个标签,那么Pod会无法进行调度
3、NodeAffinity:亲和性调度
由于NodeSelector通过Node的label进行精确匹配,所以NodeAffinity增加了In,NotIn,Exists、DoesNotExist、Gt、Lt等操作符来选择Node,能够使调度更加灵活,同时在NodeAffinity中将增加一些信息来设置亲和性调度策略
(1)RequiredDuringSchedulingIgnoredDuringExecution:必须满足指定的规则才可以调度Pod到Node上
(2)PreferredDuringSchedulingIngoredDuringExecution:强调优选满足指定规则,调度器尝试将Pod调度到Node上,但不强求,多个优先级规则还可以设置权重,以定义执行的选后顺序。
需要在Pod的metadata.annotations中设置NodeAffinity的内容,例如
spec: affinity: nodeAffinity: preferredDuringSchedulingIngoredDuringExecution: - weight: 1 preference: matchExpressions: - key: name operator: In values: ["cnode-1","cnode-2"]上述yaml脚本是说明只有Node的label中包含key=name,并且值并非是["cnode-1","cnode-2"]中的一个,才能成为Pod的调度目标,其中操作符还有In,Exists,DoesNotExist,Gt,Lt。

PreferredDuringSchedulingIngoredDuringExecution使用如下:
spec: affinity: nodeAffinity: preferredDuringSchedulingIngoredDuringExecution: - weight: 1 preference: matchExpressions: - key: name operator: In values: ["cnode-1","cnode-2"]4、DaemonSet:特定场景调度
用于管理在集群中每个Node上仅运行一份Pod的副本实例
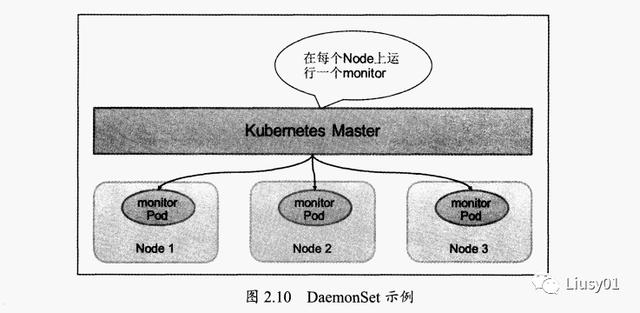
适合以下场景:
1、在每个Node上运行GlusterFS存储或者Ceph存储的daemon进程
2、每个Node上运行一个日志采集程序 ,例如fluentd或者logstach。
3、每个Node上运行一个健康程序,采集该Node的运行性能数据,例如Prometheus node Exporter
调度策略于RC类似,也可使用NodeSelector或者NodeAffinity来进行调度
例如:为每个Node上启动一个nginx
apiVersion: apps/v1kind: DaemonSetmetadata: name: ds-nginx labels: name: ds-nginxspec: selector: matchLabels: name: ds-nginx template: metadata: name: ds-nginx labels: name: ds-nginx spec: containers: - name: ds-nginx image: nginx imagePullPolicy: IfNotPresent ports: - containerPort: 80
5、Job批处理调度
可通过Job资源对象定义并启动一个批处理任务,通常并行或串行启动多个计算进程去处理一批工作任务,处理完成后,整个批处理任务结束。
按照批处理任务实现方式的不同,可分为如下几种模式 :
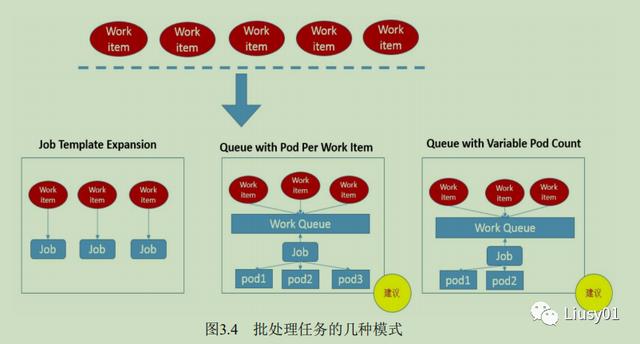
1、Job Template Expansion模式:一个Job对象对应一个待处理的Work Item,有几个Work item就产生几个独立的Job,适合Work item少,每个Work item要处理的数据量比较大的场景
例如:定义一个Job模板,job.yaml.txt
apiVersion: batch/v1kind: Jobmetadata: name: process-item-$ITEM labels: jobgroup: jobexamplespec: template: metadata: name: jobexample labels: jobgroup: jobexample spec: containers: - name: c image: busybox imagePullPolicy: IfNotPresent command: ["sh","-c","echo $Item && sleep 5"] restartPolicy: Never#使用如下命令生成yaml文件for i in a b c; do cat job.yaml.txt | sed "s/$ITEM/${i}/" > ./job-$i.yaml; done#查看运行情况kubectl get jobs -l jobgroup=jobexample2、Queue with Pod Per Work Item模式:采用一个任务队列存放Work Item,一个Job作为消费者去完成这些Work item,此模式下,Job会启动N个Pod,每个Pod对应一个WorkItem
3、Queue with Variable Pod Count模式:采用一个任务队列存放Work Item,一个Job作为消费者去完成这些Work item,Job启动的Pod数量是可变的
4、Single Job with Static Work Assignment模式:一个Job产生多个Pod,采用程序静态方式分配任务项
考虑到批处理的并行问题,k8s将job分为以下三种类型:
1、Non-parallel Jobs
一个Job只启动一个Pod,除非Pod异常,才会 重启该Pod,一旦 Pod正常结束,Job将结束。
2、Parallel Jobs with a fixed completion count
并行job会 启动多个Pod,需要设定Pod的参数.spec.completions为一个正数,当正常 结束的Pod数量达到此数时,Job结束,同时此参数用于控制并行度,即同时启动几个Job来处理Work item
3、Parallel Jobs with a work queue
任务队列的并行job需要一个独立的队列,work item都在一个队列中存放,不能设置job的 .spec.completions参数,此时job有以下一些特性
(1)每个Pod能独立判断和决定是否还有任务项需要储里
(2)如果某个Pod能正常结束,则Job不会在启动新的Pod
(3)如果一个Pod成功结束,则此时应该不存在其他Pod还在干活 的情况,应该都处于即将结束 、退出的状态 。
(4)如果 所有Pod都结束了,且至少有一个Pod成功结束,则整个Job才算成功 结束。
另外,k8s从1.12版本后给job加入了ttl控制,当pod完成任务后,自动进行Pod的关闭,资源回收。
6、Cronjob:定时任务
能根据设定的定时表达式定时调度Pod
(1)Cron Job的定时表达式(与Linux的基本相同)
Minutes Hours DayOfMonth Month DayOfWeek Year其中每个域都可出现的字符如下。
◎ Minutes:可出现【,-*/】这4个字符,有效范围为0~59的整数。
◎ Hours:可出现【,-*/】这4个字符,有效范围为0~23的整 数。
◎ DayofMonth:可出现【,-*/?LWC】这8个字符,有效范围为0~31的整数。
◎ Month:可出现【,-*/】这4个字符,有效范围为1~12的整数或JAN~DEC。
◎ DayofWeek:可出现【,-*/?LC#】这8个字符,有效范围为1~7的整数或SUN~SAT。1表示星期天,2表示星期一,以此类推
◎ *:表示匹配该域的任意值,假如在Minutes域使用,则表示每分钟都会触发事件。
◎ /:表示从起始时间开始触发,然后每隔固定时间触发一次,例如在Minutes域设置为5/20,则意味着第1次触发在第5min时,接下来每20min触发一次
◎ -:指定一个整数范围。譬如,1-4 意味着整数 1、2、3、4。
◎ ,:隔开的一系列值指定一个列表。譬如3, 4, 6, 8 标明这四个指定的整数。
比如需要每分钟执行一次:
*/1 * * * * (2)创建Cron Job
使用yaml文件
apiVersion: batch/v1beta1kind: CronJobmetadata: name: hellospec: schedule: "*/1 * * * *" jobTemplate: spec: template: spec: containers: - name: hello image: busybox command: ["/bin/bash","-c","date;echo Hello"] restartPolicy: OnFailure
7、PodAffinity:Pod亲和与互斥调度策略
根据在节点上正在运行的 Pod的标签而不是节点的标签进行判断和调度,要求对节点和Pod两个条 件进行匹配。这种规则可以描述为:如果在具有标签X的Node上运行了一个或者多个符合条件Y的Pod,那么Pod应该(如果是互斥的情况,那么就变成拒绝)运行在这个Node上。
这里X指的是一个集群中的节点、机架、区域等概念,通过 Kubernetes内置节点标签中的key来进行声明。这个key的名字为 topologyKey,意为表达节点所属的topology范围。
◎ kubernetes.io/hostname
◎ failure-domain.beta.kubernetes.io/zone
◎ failure-domain.beta.kubernetes.io/region
与节点不同的是,Pod是属于某个命名空间的,所以条件Y表达的 是一个或者全部命名空间中的一个Label Selector。
和节点亲和相同,Pod亲和与互斥的条件设置也是requiredDuringSchedulingIgnoredDuringExecution和 preferredDuringSchedulingIgnoredDuringExecution。
Pod的亲和性被定义于PodSpec的affinity字段下的podAffinity子字段中。Pod间的互斥性则被定义于同一层次的podAntiAffinity子字段中。
例如:
参照目标Pod
apiVerison: v1kind: Podmetadata: name: pod-flag labels: security: s1 app: nginxspec: containers: - name: nginx image: nginx(1)Pod亲和性调度
apiVersion: v1kind: Podmetadata: name: pod-affinityspec: affinity: podAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: security operator: In values: ["s1"] topologyKey: kubernetes.io/hostname containers: - name: nginx image: nginx创建之后会发现两个Pod在同一个节点上

(2)Pod互斥性调度
apiVersion: v1kind: Podmetadata: name: pod-antiaffinityspec: affinity: podAntiAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: security operator: In values: ["s1"] topologyKey: kubernetes.io/hostname containers: - name: nginx image: nginx创建之后会发现这个Pod跟参照Pod不在同一个节点上

8、Pod Priority Preemption:Pod优先级调度
在中大型集群中,为了尽可能提高集群的资源利用率,会采用优先级方案,即不同类型的负载对应不同的优先级,同时允许集群中的所有负载所需的资源总量超过集群可提供的资源,在这种情况下,当发生资源不足的情况时,系统可以选择释放一些不重要的负载(优先级最低的),保障最重要的负载能够获取足够的资源稳定运行。
如果发生了需要抢占的调度,高优先级Pod就可能抢占节点N,并将其低优先级Pod驱逐出节点N。
(1)首先创建PriorityClasses
apiVersion: v1kind: scheduling.k8s.io/v1beta1metadata: name: high-priorityvalue: 10000globalDefault: false(2)然后在Pod中引用Pod优先级
apiVersion: v1kind: Podmetadata: name: nginx-priorityspec: containers: - name: nginx image: nginx priorityClassName: high-priority二、Pod的扩容和缩容
1、通过kubectl scale
通过kubectl scale进行扩容和缩容,其实就是修改控制器的副本数字段
kubectl scale rc rc-name --replicas=副本数量比如我将nodeselectorrc扩容为3
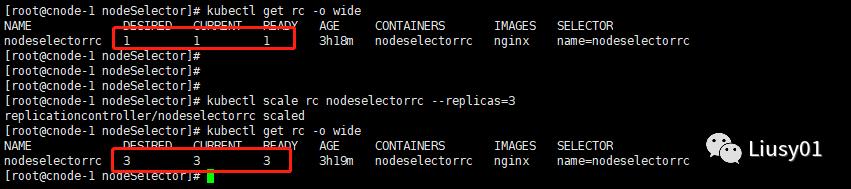
缩容也是一样,将副本数量改小就行
2、Horizontal Pod AutoScale(HPA)
实现基于cpu使用率进行自动Pod扩缩容,HPA控制器基于Master的kube-controller-manager服务启动参数
--horizontal-pod-authscaler-sync-period定义的时长(默认为30s),周期性的监测目标pod的cpu使用率,并在满足条件时对RC或Deployment中的Pod副本数量进行调整,以符合用户定义的平均Pod CPU使用率
创建HPA时可以使用kubectl autoscale命令进行快速创建或者使用yaml配置文件进行创建,在创建HPA前,需要已经存在一个RC或者Deployment对象,并且必须定义resources.requests.cpu的资源请求值,如果不设置该值,则heapster将无法采集Pod的cpu使用率
【注】此方式需要安装heapster进行采集资源的cpu使用率
命令行方式:
kubectl autoscale rc rc-name --min=1 --max=10 --cpu-percent=50yaml方式:
apiVersion: autoscaling/v1kind: HorizontalPodAutoscalermetadata: name: hpa-namespec: scaleTargetRef: apiVersion: v1 kind: ReplicationController name: rc-name minReplicas: 1 maxReplicas: 10 targetCPUUtilizationPercentage: 50上述两种方式都是在cpu使用率达到50%的时候进行扩缩容,最小副本数为1,最大副本数为10
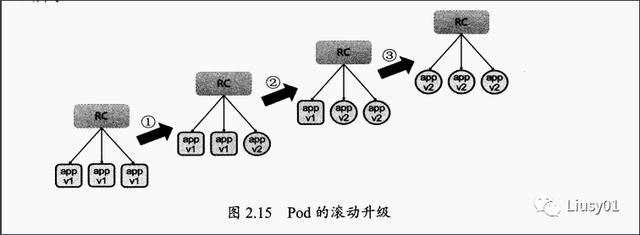
三、Pod的滚动升级
滚动升级通过kubectl rolling-update命令完成,该命令创建了一个RC,然后自动控制旧的RC中的Pod副本的数量逐渐减少至0,同时新的RC中的Pod副本的数量从0逐步增加至目标值,最终实现了Pod的升级。新旧的RC需要在同一个Namespace下。
1、使用yaml进行升级
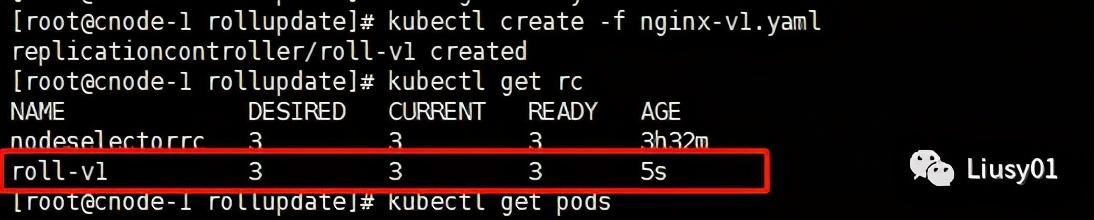
比如有一个nginx的v1版本:nginx-v1.yaml
apiVersion: v1kind: ReplicationControllermetadata: name: roll-v1 labels: name: roll-v1 version: v1spec: replicas: 3 selector: name: roll-v1 version: v1 template: metadata: name: roll-v1 labels: name: roll-v1 version: v1 spec: containers: - name: roll-v1 image: nginx imagePullPolicy: IfNotPresent ports: - containerPort: 80创建之后如下:
需要将其升级为v2版本:nginx-v2.yaml
apiVersion: v1kind: ReplicationControllermetadata: name: roll-v2 labels: name: roll-v2 version: v2spec: replicas: 3 selector: name: roll-v2 version: v2 template: metadata: name: roll-v2 labels: name: roll-v2 version: v2 spec: containers: - name: roll-v2 image: nginx imagePullPolicy: IfNotPresent ports: - containerPort: 8080使用如下命令进行升级:
kubectl rolling-update roll-v1 -f nginx-v2.yaml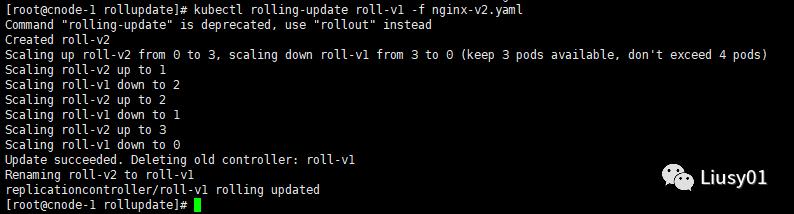
执行之后会逐步替换掉v1版本的pod
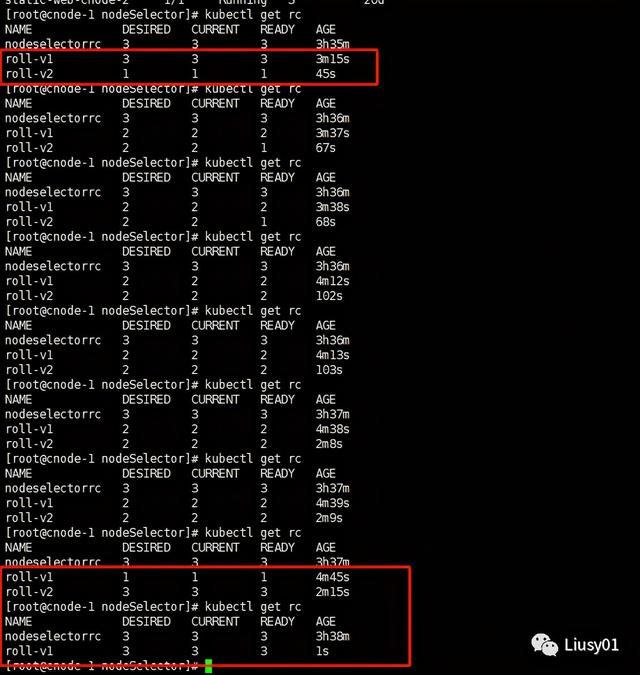
需要注意的是:
1、RC的名字不能与旧的RC相同
2、在selector中至少有一个Label与旧的不同,以表示其是新的RC。(其实是必须所有label不一样)
2、使用命令方式直接升级
也可以使用命令行直接替换掉容器的镜像
kubectl rolling-update rc-name --image=image-name:version3、回滚
当滚动更新出现问题时,可以进行回滚
kubectl rolling-update rc-name --image=image-name:version --rollback===============================
我是Liusy,一个喜欢健身的程序员。
欢迎关注微信公众号【Liusy01】,一起交流Java技术及健身,获取更多干货,领取Java进阶干货,领取最新大厂面试资料,一起成为Java大神。
来都来了,关注一波再溜呗。

