
- 1Vue3 入门笔记 ---- 利用Element Plus对页面进行布局划分以及实现左侧公共菜单_vue3布局页面分为上中下
- 2铜箔镀锡测试
- 3java中常见的限流算法详细解析_java中固定窗口算法
- 4chrome提示不安全_window 排查chrome 非安全模式
- 5功率谱密度计算公式_随机振动功率谱密度曲线的计算
- 6【ITK配准】第二期 多模态配准
- 7记录第一次使用Trtc的网页版和小程序版的已发现问题_腾讯trtc web和小程序不是同一个直播间
- 8MUMU模拟器12连logcat的方法_logcat mumu
- 9模仿dcloudio/uni-preset-vue 自定义基于uni-app的小程序框架
- 10网络编程套接字(三)之TCP服务器简单实现_tcp 服务器 简单
AI学习手册_al入门知识库
赞
踩
AI的定义:
Al,英文全称叫做Artificial lntelligence,直译过来就是人工智能。
AI的核心定义,就是由人制造出来的智能。它让机器能够模仿、学习并执行类似人类智能的任务。这种智能表现在多个方面,比如学习、推理、解决问题、知觉、语言理解等。
简单地说,Al就是让机器能够像人一样思考和行动。
Al的发展历史:
人工智能的概念可以追溯到古希腊时期,但作为一个科学领域,它是在20世纪中叶才真正开始发展。下面是Al发展的几个重要阶段:
1950年代:Al作为一个学术概念在这个时期诞生了。1956年,约翰·麦卡锡(JohnMcCarthy)等人在达特茅斯会议(Dartmouth Conference)上首次提出了“人工智能"这一术语。
1980年代:专家系统的出现,标志着Al的第一个商业成功。这些系统能模仿人类专家的决策过程,被用于医疗诊断和矿物探测等领域。
1990年代:随着互联网的兴起,大量数据的可用性增加了,机器学习开始成为AI研究的主流。
21世纪:深度学习的出现和计算能力的提升推动了Al的快速发展,出现了如AlphaGo、自动驾驶汽车等划时代的应用。
AI的分类:
人工智能可以大致分为两类:窄人工智能(Narrow Al)和通用人工智能(General Al)。
窄人工智能:也称为弱人工智能,是目前最常见的Al类型。这类Al在特定领域或任务中表现出人类般的智能。比如,语音识别软件只擅长处理语音,而不懂其他任务。这些系统通常基于大量数据的学习和模式识别。
通用人工智能:也称为强人工智能,是一种理论上的Al,它可以像人类一样执行任何智能任务。目前这类Al还未成为现实,但它是许多科幻作品中常见的主题。
在Al的发展过程中,还产生了一些子领域,如机器学习、深度学习、自然语言处理等。
- 机器学习是AI的一个分支,它让机器能够从数据中学习,而不是完全依靠预设的规则。
- 深度学习则是机器学习的子集,通过模拟人脑的神经网络结构来学习数据。
- 自然语言处理(NLP)是Al在语言理解和生成方面的应用。
AIGC:
最近非常流行一个概念,叫做AIGC。
AIGC的全称是Al Generated Content,可以直译为“人工智能生成内容”。直白地讲,AIGC就是指利用人工智能技术自动生成各种类型的内容,包括文本、图像、音乐、视频等等。
AIGC应用领域:
1.文本生成
某些AIGC应用可以生成连贯、自然的文本内容。其中,谷歌的Bard,百度的文心一言,阿里的通义千问,科大讯飞的讯飞星火,以及我们专栏要重点介绍的ChatGPT,都属于这一类应用。
2.图像生成
某些AlGC应用能够生成逼真的图像,这也就是人们常说的Al绘画。国内外有许多优秀的AI绘画平台。
3.视频生成
AIGC可以合成和编辑视频,生成具有特定场景、角色和动作的视频片段。几年前日本流行的虚拟偶像初音未来,就是AlGC在视频领域的早期尝试。
除了上述这些应用领域,AIGC还可以应用到音频合成、数据可视化、自动编程等领域。
ChatGPT是什么:
按照官方定义,ChatGPT是一款由OpenAl开发的先进人工智能助手,基于强大的GPT架构,旨在为用户提供丰富、高质量的语言理解和生成服务。
GPT架构:
GPT是一种自然语言处理模型。所谓自然语言处理模型,可以实现人与计算机之间通过自然语言进行有效通信。也就是说,你想和计算机沟通并不需要编程或是专业指令,只需要直接把人类的语言输出给计算机,计算机理解了你的意思,再用人类的语言回答你。

GPT的全称是Generative Pre-trained Transformer,这段英文又怎么来理解呢? Generative,意思是“生成式”,也就是说GPT具有生成新文本的能力。
Generative,意思是“生成式”,也就是说GPT具有生成新文本的能力。
Pre-trained,意思是预训练”,早在你使用ChatGPT之前,GPT模型就已经通过海量的文
本数据进行了预训练,学习掌握了语言结构、语法、语义等方面的知识,从而再处理你的
提问时,拥有了强大的迁移学习能力,也就是举一反三的能力。
Transformer,字面意思是“转换器”,在这里指的是一种专门的深度学习架构,叫做
Transformer架构。
Transformer架构是一种专为自然语言处理任务设计的深度学习架构,该架构的影响力非
常大,不但GPT系列以它作为底层架构,谷歌的同类产品BERT也是以Transformer架构作
为基础。
对了,像GPT和BERT这样的模型,也被归类为大语言模型(Large Language Model),
简称LLM。

好吧,这套娃实在有点深,估计大家都有点听晕了,让我们梳理一遍:
ChatGPT是一款人工智能助手产品,它基于GPT架构开发,而GPT架构是一种自然语言处理模型,又可以被细分到大语言模型这个类别。GPT的基础则是Transformer架构,Transformer架构是专为自然语言处理任务设计的深度学习架构。
在这个信息化时代,ChatGPT具有广泛的应用价值,可以帮助用户解决各种问题,提高工作效率,拓展知识面,以及获取娱乐休闲体验。
GPT-4强大在哪里?
GPT-4相对于GPT-3.5的变革,可以说是天翻地覆的。
第一,GPT-4拥有比GTP-3.5还要多得多的模型参数,这大大提升了生成文本的质量和准确。
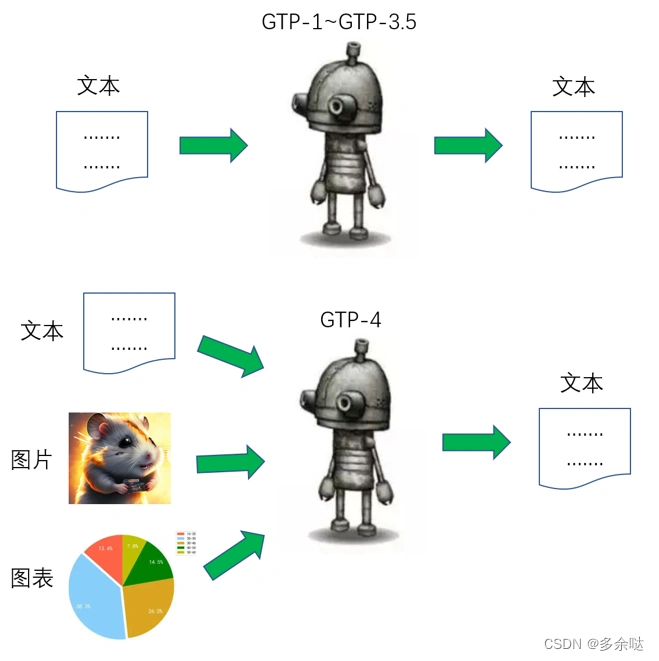
第二,GPT-4的模型架构从自然语言处理模型升级成了多模态模型。
什么是多模态呢?
所谓多模态(Multimodal),是指同时处理和理解多种类型数据的技术,这里的数据类型包括文本、图像、音频、视频等等。
在GPT-4当中,用户可以输入给ChatGPT的内容不再局限于文本,也包括图片、图表等等。同时,ChatGPT也可以用多种方式向用户输出内容,不光可以输出文字,也可以画图、生成语音。
第三,GPT-4支持了更长的文字输入。
GPT-3.5的最大文字输入长度是3000字,GTP-4的最大文字输入长度是25000字,这使得用户可以用更加充分的信息与chatGPT进行交流。
GPT-4比GPT-3.5更强大的具体的实践案例:
为了测试ChatGPT产品的智能程度,OpenAl曾经让ChatGPT参与了美国的各种主流考试
都有哪些考试呢?,包括号称"美国高考"的SAT考试、美国各大洲的统一司法考试UBE、国生物奥林匹克竞赛等等。
GPT-3.5与GPT-4都参与了这些考试,它们的成绩是怎样的呢?
SAT的数学部分(满分800分)
GPT-3.5考了590分,GPT-4考了700分。
美国司法考试
GPT-3.5成绩排名倒数10%,GPT-4排名前10%。
美国生物奥林匹克竞赛
GPT3.5成绩排名前69%,GPT-4排名前1%!
GPT-4与GPT-3.5,简直就是学霸与学渣的差距!
倒不是说GPT-3.5很弱,只是那个版本还没有很适合完成人类的考试,而GPT-4在智能上的提升,实在是太过显著了。
或许有人会问:GPT-4已经这么厉害了,那OpenAl还会推出GPT-5、GPT-6吗?
按照GPT系列以往的更新频率,我们或许会在2024年看到GPT-5的问世。那时的GPT-5,很可能会实现真正的通用人工智能!
ChatGPT的应用场景
ChatGPT能用来做什么事情?那简直不要太多了,我们这里只举出8个有代表性的例子:
第一,ChatGPT可以用于文案创作。
通过用户输入的创作要求,ChatGPT可以创作出相应的文案内容。比如媒体作者可以给ChatGPT提出要求,让ChatGPT根据某一主题生成的媒体文案。广告策划人员可以把要推广的商品信息输入给ChatGPT,让ChatGPT针对此商品生成一段广告文案。
不仅如此,ChatGPT能生成的文案是多样的,不只包括商业文案,还包括优美的诗句、有趣的小说、或者电影剧本、歌词等等;甚至可以用来写各种应用文,比如请假条,申请书,日报周报,个人简历。
第二,ChatGPT可以用于语言翻译。
我们可以把想要翻译的原文输入给ChatGPT,让ChatGPT把原文翻译成我们想要的任意一种语言。这样的能力,绝对超越了世界上最厉害的翻译专家!
第三,ChatGPT可以用于金融分析。
做金融投资的人士,可以利用ChatGPT来分析市场动态、投资策略以及金融风险。从而做出最佳的决策。
第四,ChatGPT可以用于知识搜索。
以前,人们想搜索某些知识,往往是通过谷歌、百度这样的搜索引擎。但搜索引擎得到的结果往往比较散乱,而且还充斥着大量的广告,无法确保内容的正确性。大家看看几年前的魏则西事件,就能想象到搜索引擎的结果有多么不靠谱了。
如果把问题交给ChatGPT,返回的结果工整又清晰,可以使人们获取知识更高效。
而现在使用ChatGPT去回答技术问题,答案非常精准!
第五,ChatGPT可以作为聊天工具。
ChatGPT不但可能生成严肃的文本内容,也可以进行随意的聊天,甚至是进行深度的情感交流。许多在大城市独居的人们,可以通过与ChatGPT聊天,缓解情感上的空虚。
第六,ChatGPT可以用于专业咨询。
ChatGPT通过强大的学习和微调能力,可以成为任何一个细分领域的专家。
比如,我们把大量的法律知识数据投喂给ChatGPT,可以把ChatGPT训练成一个专业的法律顾问;把大量的医学知识数据投喂给ChatGPT,可以把ChatGPT变成一个医疗咨询专家
ChatGPT通过强大的学习和微调能力,可以成为任何一个细分领域的专家。
第七,ChatGPT可以用于辅助编程。
ChatGPT可以帮助程序员生成各种程序代码,从而快速搭建起一套基础代码模板,大大提升编程效率。这对于广大程序员来说,是一大利好。
第八,ChatGPT可以用于辅助Al绘画。
只有Al才更懂Al。ChatGPT可以跟Al绘画平台(比如MidJourney))配合使用,从而得到更加精准的描述词,画出用户想要的画作。
不只是Al绘画平台,其他一些AIGC产品也可以与ChatGPT配合使用,发挥更大的价值。
ChatGPT的界面:

当使用plus账号访问ChatGPT时,可以选择两种模型,一种是GPT-3.5模式,一种是GPT-4模式:
要想体验ChatGPT最强大功能,我们这里肯定是优先选择GPT-4模式。
如果大家是免费账号,则没有这个选项。
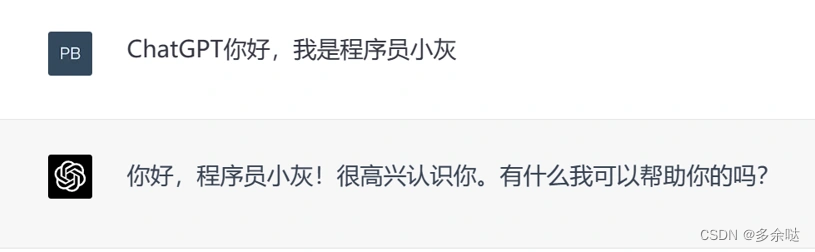
平台中下方的输入框,就是供我们提出问题的地方。我们可以先和ChatGPT打声招呼:
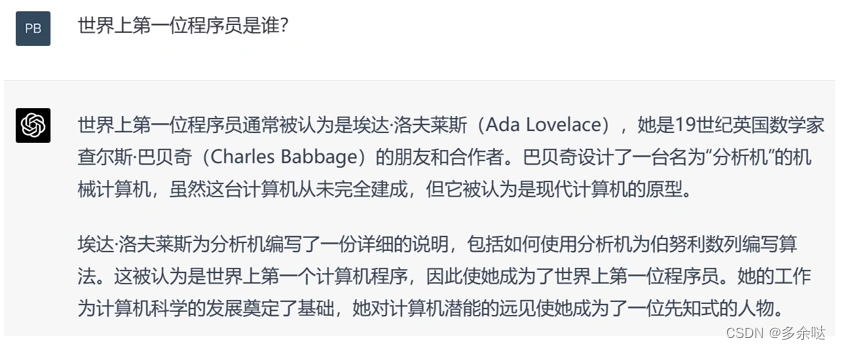
我们再来随意提出一个问题:
 接下来,我们尝试让chatGPT写一段代码:
接下来,我们尝试让chatGPT写一段代码:
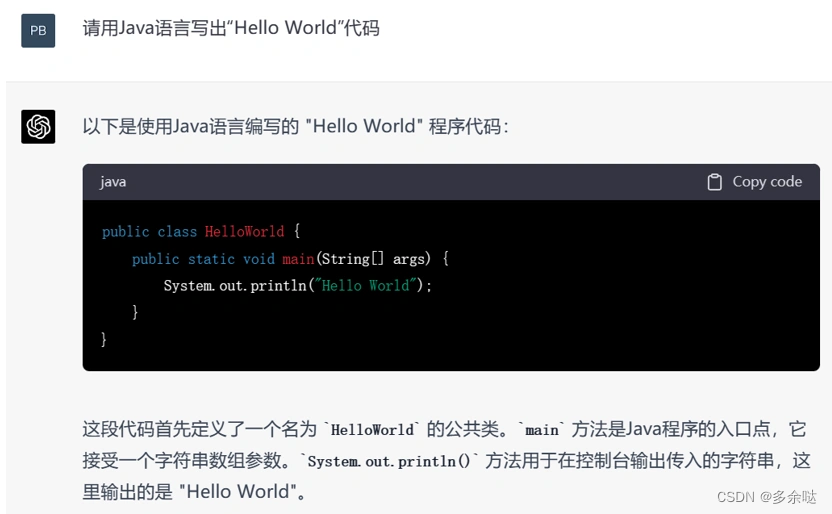
由此看出,ChatGPT的智能水平还真是不简单。
接下来我们不妨刁难一下ChatGPT,让它写一篇2022年全国统一卷的高考作文。

大家有没有发现,ChatGPT回答到中间,忽然停住了?
这是因为ChatGPT单次回答的文本长度有限,我们在对话框输入“继续"就可以了: 怎么样,ChatGPT的内容生成能力是不是很强大?
怎么样,ChatGPT的内容生成能力是不是很强大?
好了,关于如何隔使用ChatGPT提出第一个问题,我们就介绍到这里。
可能有的小伙伴会问:我还没有ChatGPT账号,该怎么办呢?
别担心,在下一讲,我会为大家介绍一个ChatGPT的替代平台。
如何更好地提问?
在初步使用ChatGPT或者替代平台的时候,大家有没有遇到过—些问题?
比如,很多时候我们问了一些问题,但ChatGPT回答给我们的,却并不是我们想要的。
这不是因为ChatGPT不够智能,而是因为提问者并没有掌握好“提问的艺术"。
提问还需要艺术吗?当然了。今天我们就来给大家讲一讲Prompt Engineering,也就是提示词工程。
提示词工程(Prompt Engineering)
提示词,是指用户向Al模型提供的输入文本,用以引导Al模型生成特定类型的文本输出。这些输入可以是问题、任务描述或场景描述。
向AI询问问题或者提出要求,就像是对人提问一样,提问者首先要把问题说得清楚明白。如果不能描述清楚你的问题,再厉害的专家也无法给出你想要的回答。
下面两个例子,就是提示词的错误示例:

写一首什么风格的诗?题材是什么?有什么格式要求?在问题里并没有表述清楚。
你和女朋友的情况分别是什么样?是什么原因促使你想要分手?在问题里也同样没有表达。
因此,我们需要一系列向AI提问题的技巧和方法,让Al模型输出更加准确的答案。这套技巧和方法就是提示词工程。
提示词工程在ChatGPT中扮演着至关重要的角色,它能将用户的需求转化为GPT模型能理解和回应的形式。通过设计合适的提示词,能够引导GPT模型生成有针对性且高质量的回复。因此,熟练运用提示词技巧能够最大限度地发挥ChatGPT的潜力,满足各种应用场景的需求。
我们怎样入门提示词工程呢?
学习提示词工程的第一步,是要了解提示词的常用种类,目前常用的提示词主要有六大类:
1.信息检索类Prompt
向ChatGPT询问某些固有的知识,比如这样输入:“乔治.华盛顿是哪一年出生的?”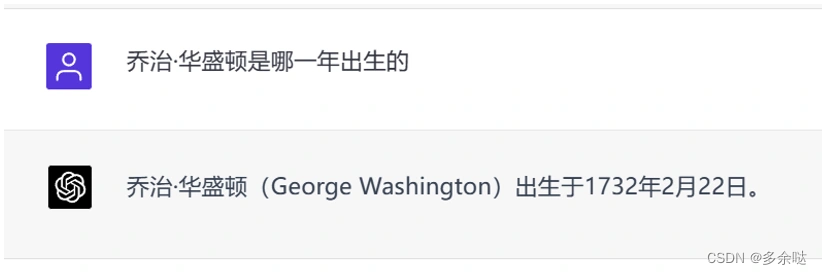
2.文本生成类Prompt
让chatGPT根据特定要求来生成文本,比如这样输入:"我今天发烧40度,无法去上班,请向我的领导写一封请假信,要求字数在300字以内"

3.机器翻译类Prompt
给定某一种语言的内容,让ChatGPT翻译成另一种语言,比如这样输入:“请将'the
secret of a happy old age is nothing else but a decent agreement with loneliness. '从英语翻译成中文。"
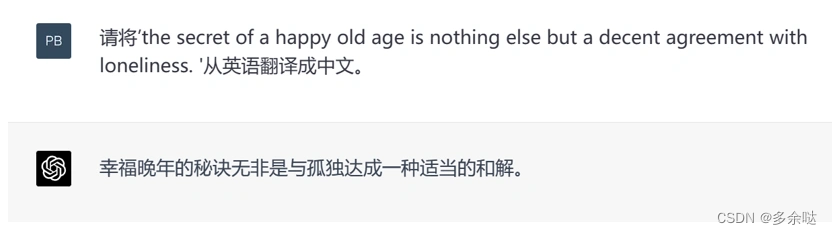 4.创意写作类Prompt
4.创意写作类Prompt
提出具有开放性的要求,让ChatGPT进行创作,比如这样输入:“写一个以美国南北战争为历史背景的短篇爱情小说,要求字数2000字以内。"
 (小说内容比较长,这里就省略了)
(小说内容比较长,这里就省略了)
5.文本摘要类Prompt
指定一篇文章,让ChatGPT提炼出文章的核心要点,比如这样输入:"请为上面的输出总结出一个50字的摘要"
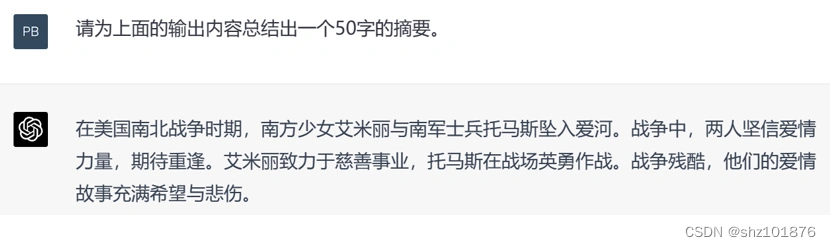 6.咨询建议类Prompt
6.咨询建议类Prompt
列举现实情况,请ChatGPT提出咨询建议,比如这样输入:“我是一个21岁的北京女大学生,我喜欢上了同班爱打篮球的男同学,我应该怎样向他表白?”
以上仅仅是提示词的常见类型。要想提出好的问题,首先要明确你的提示词种类,以此才能对症下药。
一个高质量的提示词,需要做到目标明确,有前提条件,并且限定回答格式。
想要满足这些要求,你的Prompt需要包含四大组成部分,分别是任务、上下文、指令、角色。
1.任务(Task)
所谓任务,就是用户希望模型完成的具体工作,如回答问题、提供建议等。
2.上下文(Context)
有助于模型理解任务的背景信息,如相关领域知识、具体场景等。
3.指令(Instruction)
引导模型以特定方式完成任务的具体要求,如答案格式、回答深度等。
4.角色(Role)
设定模型在互动过程中扮演的身份,如专家、助手等。
对于这四个组成部分,我们来举一个应用的例子。输入内容:
"作为一个项目组的负责人,当你遇到项目组成员因工资待遇问题发生冲突时,请给出有效的解决方法。解决方法列举5条以上,总字数在200-300字之间。"
在这个例子中:
任务部分是“给出有效的解决方法"
上下文部分是“当你遇到项目组成员因工资待遇问题发生冲突时”
指令部分是“解决方法列举5条以上,总字数在200-300字之间。”
角色:项目组的负责人
这样的提示词就是一个清晰完整的提示词,ChatGPT大概率可以给出你准确而又有价值的回答。
针对这个问题,ChatGPT的回答如下:

当然,也并非每一个问题都一定要严格包含着四大要素,只有在希望ChatGPT生成较为复杂和专业的内容时,才需要兼备这些要素。
以上是实现优质提示词的基本要求。此外针对一些特殊场景,我们也需要用到几种提示词的高级技巧。
提示词的高级技巧
Prompt Engineering有哪些高级技巧呢?
1.拆解问题
对于一个一次性很难完整回答的大问题,我们可以将其拆解成若干子问题,再将这些问题逐步输入。
我们来看下面的例子:



2.迭代改进
在进行长篇内容的创作时,很难一次就生成令人满意的内容。我们需要在与ChatGPT互动过程中,通过多轮对话和反馈不断优化生成结果,帮助用户获得更满意的输出。
我们来看下面的例子:



3.上下文引导
在提问时,我们可以在Prompt中提供额外的背景信息,帮助模型更好地理解任务,从而生成更准确的回答。
我们来看下面的例子:

4.种子词提示
ChatGPT的种子词提示,对应的英文名字是seed prompt,是一种通过提供特定的种子词或短语来控制ChatGPT输出的技术。种子词可以帮助引导模型生成特定主题或风格的文本内容。
我们来看下面的例子:

5.样本提示
样本(Sample)是机器学习领域的重要概念,GPT模型在通过大量的样本进行学习,才能像今天这样智能。
在大多数时候,我们向ChatGPT提出问题是不需要额外给出样本的,因为GPT模型已经做了充足的预训练,可以利用已经学到的海量知识来解决问题。
这样的常规提示情况被称为零样本(Zero-Shot)。
在少数情况下,一些特定领域的任务是GPT模型没有被训练到的,这时候为了保证GPT能完美回答问题,可以在问题中加上一个或多个参考样本。
我们来看下面的例子:

 使用样本提示时,我们可以使用单独一个样本,也可以用若干个样本。
使用样本提示时,我们可以使用单独一个样本,也可以用若干个样本。
使用一个样本的情况,叫做单样本(One-shot)
使用若干样本的情况,叫做小样本(Few-shot)
好了,以上就是5种提示词的高级技巧。
其实不只是向Al提问,就算我们向人类提问,我们也要讲究各种方式方法,才能得到对自己有帮助的答案。
如何使用ChatGPT的插件?
什么是插件呢?可以认为插件是一些小工具,用来扩展ChatGPT的功能,是用户在某一细分领域更方便地使用ChatGPT。
目前,插件系统还处于beta测试阶段,如果你是plus用户,可以在设置界面里开通插件功能:
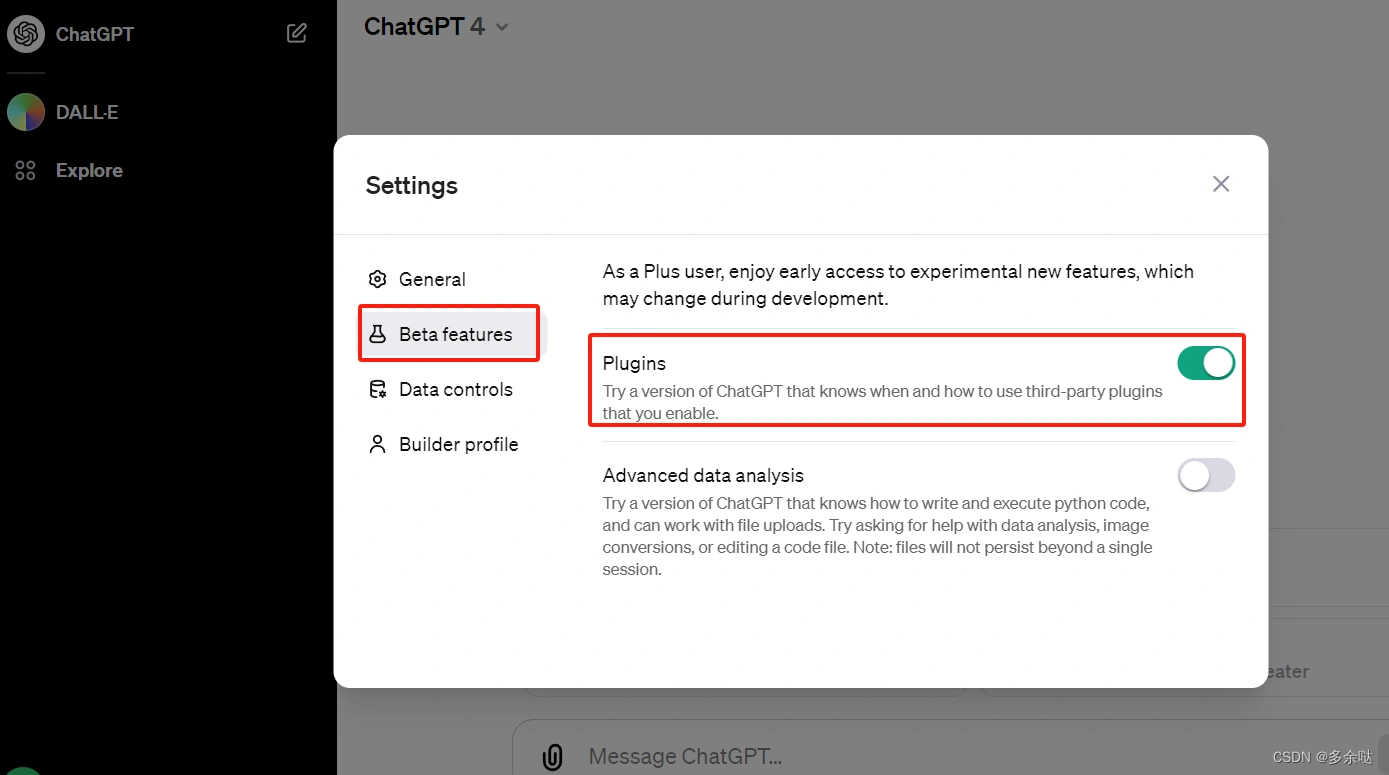
自从插件系统上线以来,许多用户研发并上传了各式各样的插件,截止到这篇文章发布时,ChatGPT的Plugins store里面已经拥有了超过1000种插件,涉及到人们的衣、食、住、行、娱乐等方方面面:
这么多插件,我们怎么来选择自己想要的插件呢?
给大家重点介绍5款比较有代表性的插件。
1.Pluginpedia
Pluginpedia插件,为其他所有插件提供了导航。就像我们访问其他网站需要先查百度查谷歌一样,我们想要查找某个功能的插件,可以先问问Pluginpedia。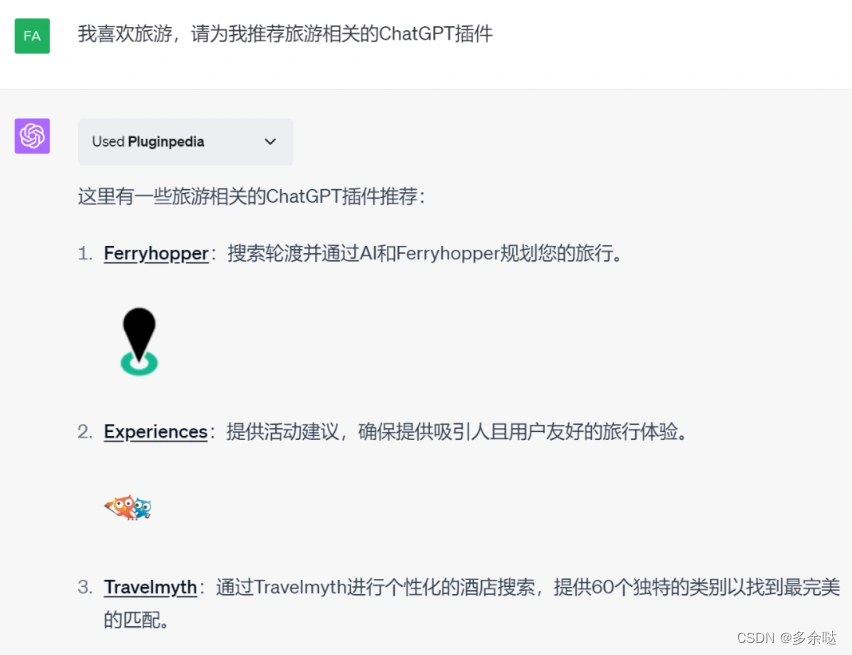
2.AskYourPdf
GPT-3.5和以前的版本,都只能读取和理解文本内容,而GPT-4采用了多模态模型,可以读取文本、图片、声音、pdf等等多种类型的数据信息。
AskYourPdf这款插件,就可以让ChatGPT读取pdf文件,并理解pdf文件的内容信息。
如何用插件来上传pdf呢?我们先来问一问: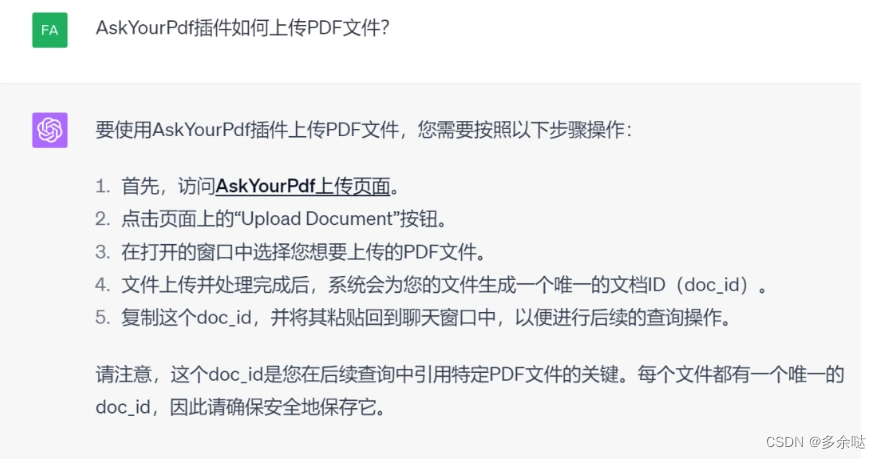
按照ChatGPT回答的步骤,我们进入AskYourPdf页面上传pdf: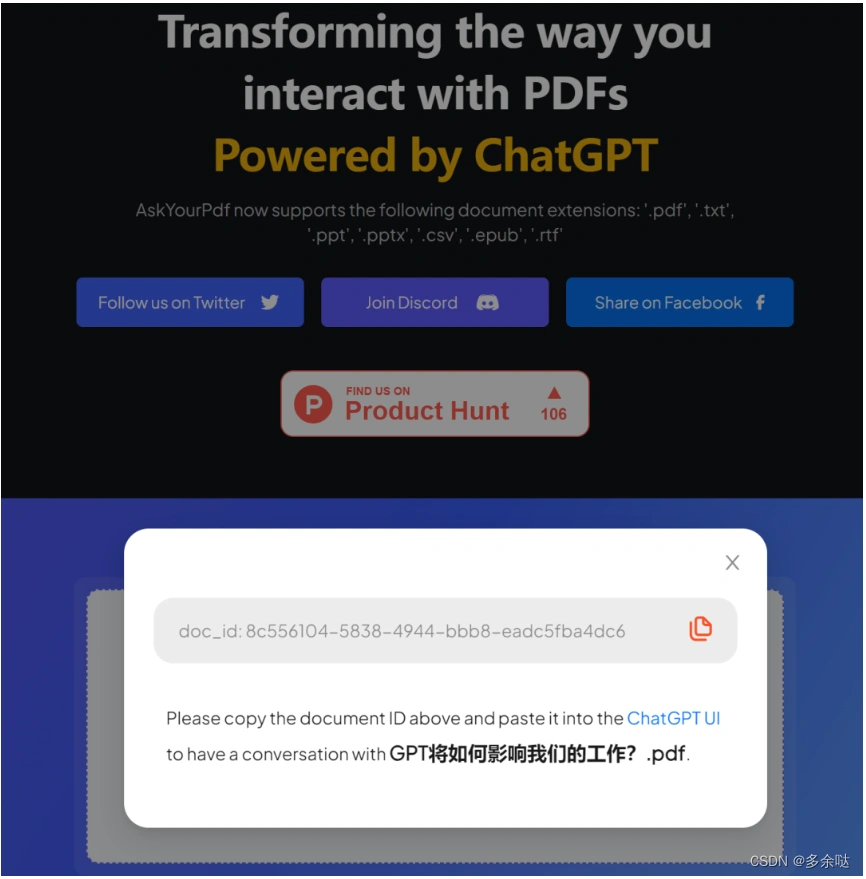 获取文件id之后,我们让ChatGPT根据这个pdf文件,为我们生成对应的摘要:
获取文件id之后,我们让ChatGPT根据这个pdf文件,为我们生成对应的摘要:
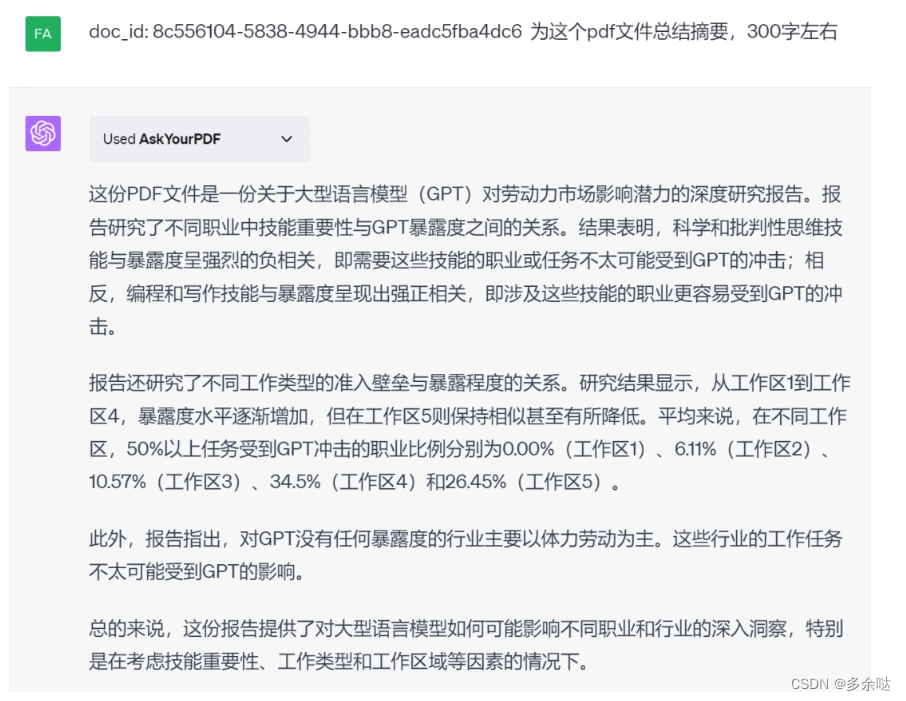
3.Export to PDF
刚才我们提到的AskYourPdf插件功能,是把PDF文件输入给ChatGPT,而Export to PDF则正相反,是让ChatGPT输出PDF格式的文件。
我们来举个例子,请ChatGPT为我们写一份个人的英文简历:

之后,我们让chatGPT把这份简历转换为pdf格式:
点击“下载简历"链接,可以看到最终生成的pdf文件。
点击“下载简历”链接,可以看到最终生成的pdf文件。
4.WebPilot

WebPilot插件可以让ChatGPT读取某个网页,提取其中的重要信息。
如何使用呢?我们以小灰公众号的一篇文章为例,让ChatGPT总结出这篇文章的摘要。
原文如下:
90后程序员回家卖羊粪,月销售额120万!
ChatGPT的摘要:
5.Speechki
speechki插件,相当于给我们的ChatGPT装上了一张嘴巴。我们可以让ChatGPT根据一段文字生成语音。
文字转语音的功能,虽然很多平台都已经有了,但大多数是收费的。Speechki转换的语音不但选择很多,而且免费,非常适合用于视频创作。
我们来看一个例子,先让ChatGPT创作一篇散文:

然后,我们让ChatGPT把这段散文转为语音: 如果我们觉得语音不是很好听,也可以换成其他声音,选项非常多∶
如果我们觉得语音不是很好听,也可以换成其他声音,选项非常多∶
以上介绍的几款插件,仅仅是ChatGPT插件系统的冰山一角,还有更多有趣又实用的插件等着我们去尝试。
另外,有些插件的功能,比如pdf的导入和生成,也可以利用多模态的方式来实现。关于多模态的新功能,我会在后续专门进行介绍。
好了,关于ChatGPT的插件系统,我们就介绍到这里。
Auto-GPT与AgentGPT
今天这一讲,我们来讲两个好用的自动化的工具,分别是Auto-GPT和AgentGPT。
ChatGPT是一个好用的Al工具,但是如果只是用原生的ChatGPT,难免会有一些局限。
是什么局限呢?
我们每次用GPT来生成内容,只能通过一问一答的形式,让GPT逐一为我们生成。如果我们有一千一万个内容想要生成,那就要询问ChatGPT一千一万次。
怎样可以像工厂流水线那样,让ChatGPT自动化地批量执行任务呢?
虽然ChatGPT本身办不到,但是全世界一些厉害的程序员基于GPT,开发了相关的开源项目,让GPT可以自动化执行各种复杂任务。
Auto-GPT
其中最具代表性的一个开源项目,叫做Auto-GPT。
Auto-GPT是一个实验性的开源应用程序,展示了GPT-4语言模型的能力。这个程序由GPT-4模型驱动,将大语言模型的“思想"串联在一起,从而自动化地实现人类设定的任何目标,成为用户的全能型Al助手。
Auto-GPT的最大特点,就是实现了“自动化"。
如同上文所说,我们在使用ChatGPT时,我们每一次都需要手动输入提示词,从而获得ChatGPT的一次回答。如果完成某个大工程需要向AI询问1000次,那我们就只能手动编写1000条提示词,再逐一输入给ChatGPT,等待回答。
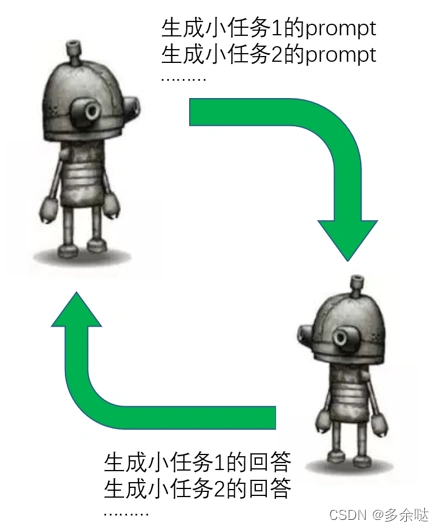
但是,Auto-GPT为我们解决了这个难题。我们只需要制定一个或多个明确清晰的大目标,Auto-GPT就会尝试理解大目标,把大目标拆解成若干小任务,再自动生成执行小任务所需要的提示词(Prompt),提交给GPT模型。
经过若干轮的循环与递归,Auto-GPT逐步完成了所有小任务,最后把实现完毕的大目标呈现给用户。
整个过程就像下图这样子:
这就是Auto-GPT的强大之处。可能小伙伴们都已经迫不及待地要使用了,Auto-GPT是一款开源应用,可以直接在Github平台找到,地址如下:
https://github.com/Significant-Gravitas/Auto-GPT
进入之后,大家可以看到项目主页:
那么,我们如何在本地部署这个项目呢?
非常简单,只需要几步即可部署:
第1步,下载项目到本地,可以使用git clone命令,也可以点击页面的download。
第2步,打开命令行工具,进入项目目录,输入命令:
pip install -r -requirements.txt
目的是安装所有项目依赖
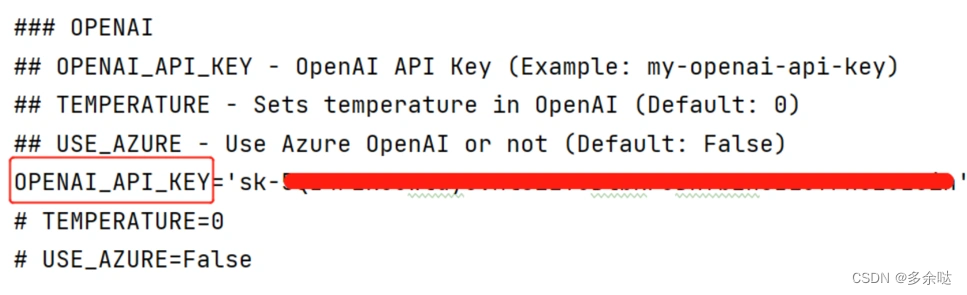
第3步,打开项目目录中的.env.template文件,在OPENAl_APl_KEY字段后面填充自己openAl账号所对应的APlKey:
第4步,把.env.template文件的EXECUTE_LOCAL_COMMANDS字段从默认的False改为True: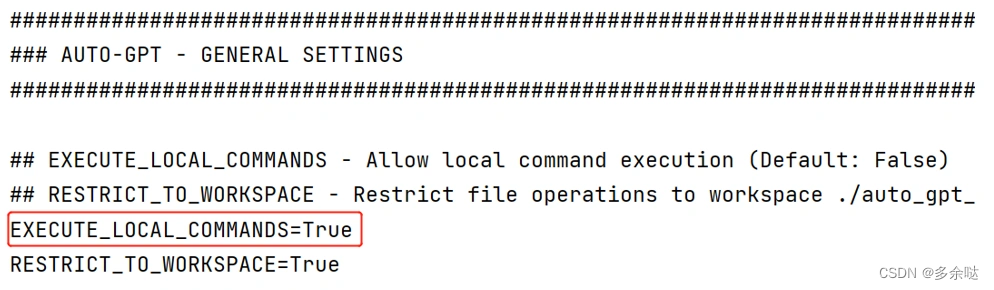 这个设置决定了Auto-GPT是否被允许执行本地命令,并非必选项。
这个设置决定了Auto-GPT是否被允许执行本地命令,并非必选项。
第5步,将.env.template文件另存到同一个目录下,新文件名为.env。
第6步,在命令行输入python -m autogpt执行项目,我们进入到了Auto-GPT的欢迎界面:

第7步,为这个Al起个名字,再确定一下AI要完成的目标:
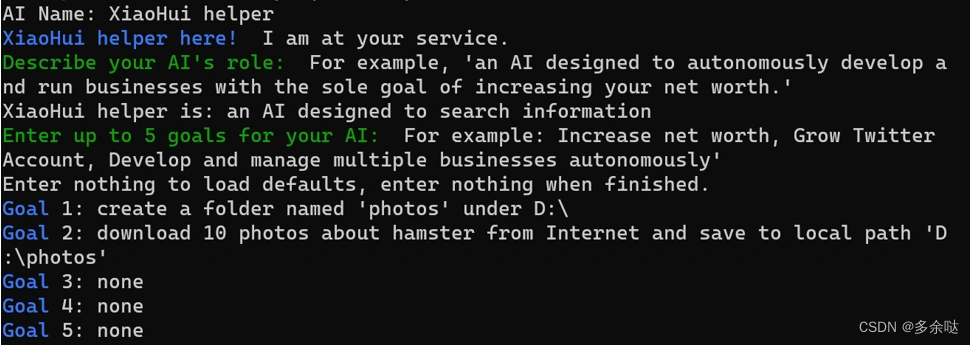 在上图的例子中,我们设置的目标是让Auto-GPT帮我在D盘创建一个名为photos的文件夹,并且下载10张仓鼠相关的照片存储到其中。
在上图的例子中,我们设置的目标是让Auto-GPT帮我在D盘创建一个名为photos的文件夹,并且下载10张仓鼠相关的照片存储到其中。
经过了一段漫长的任务执行过程,Auto-GPT终于圆满地完成了任务:
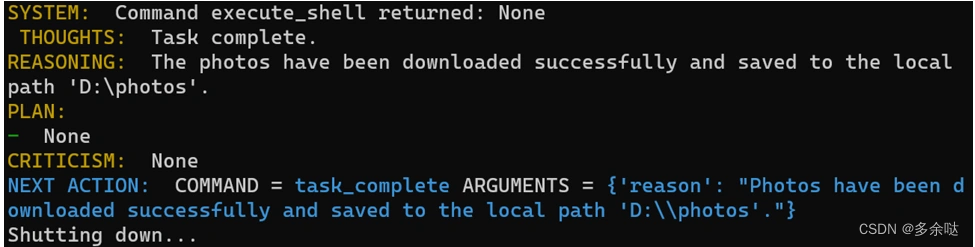
需要注意的是,Auto-GPT这个项目还在不断更新,当大家看到这一讲的时候,项目呈现出的效果可能跟上面的描述略有出入。
可能有人会说,使用Auto-GPT之前的部署过程还是有些麻烦,有没有什么更简单的办法可以用到类似的自动化Al助手呢?
AgentGPT
还真有,这里推荐另外一个开源项目,叫做AgentGPT。
AgentGPT是另一位编程高手创建的开源项目,这个项目也同样基于GPT模型,实现了自动化的Al助手功能。
不过与Auto-GPT有所不同,AgentGPT不仅在GitHub开放了源代码,同时也提供了可视化的操作页面,使得用户可以直接在页面上创建自动化目标,免去了搭建Python环境、部署项目代码的繁琐。
不过,AgentGPT虽然使用方便,却无法访问和修改用户的本地文件,而Auto-GPT是可以做到这一点的。
总而言之,Auto-GPT与AgentGPT这两大开源项目仅仅是GPT开源应用的一个开始,它们还存在诸多需要完善的点,比如执行速度较慢、耗费资源较多、有时也未必能顺利完成用户的目标。
但是不要紧,在后续一定会有更多更强大的基于GPT的应用涌现出来,呈现出百花齐放的态势,为我们的工作和生活创造了便利。
好了,关于Auto-GPT与AgentGPT,我们就介绍到这里。
使用ChatGPT创作诗词歌曲
今天我们正式进入实操环节,讲—讲用如何用ChatGPT来创作诗歌。
之前我们在讲ChatGPT使用的时候,曾经介绍过一种技巧叫做“种子词提示"。想要创作诗歌或者其他文学作品,种子词是非常重要的。
今天我们就来实践一下种子词提示,以“春雨"作为种子词,让ChatGPT创作一首古诗:
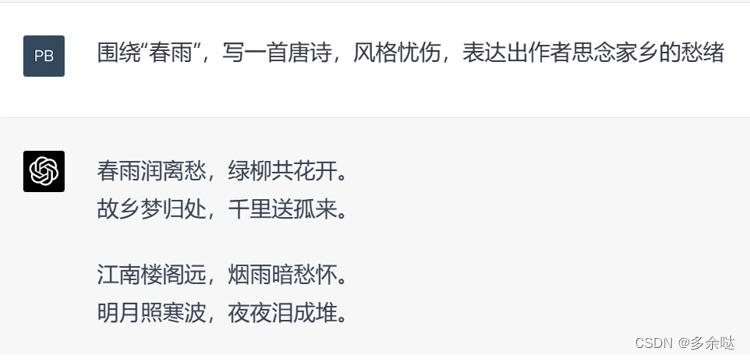
很快,ChatGPT围绕着“春雨"来展开创作的,输出了一首简单的古诗。
可能有人会觉得,这篇诗词看起来蛮工整的,就是缺少了一些意境。
没关系,我们改一下试试。
这下子,全诗的格调是不是比刚才要好多了?
创作完了古诗,我们再尝试让ChatGPT创作一首歌曲:
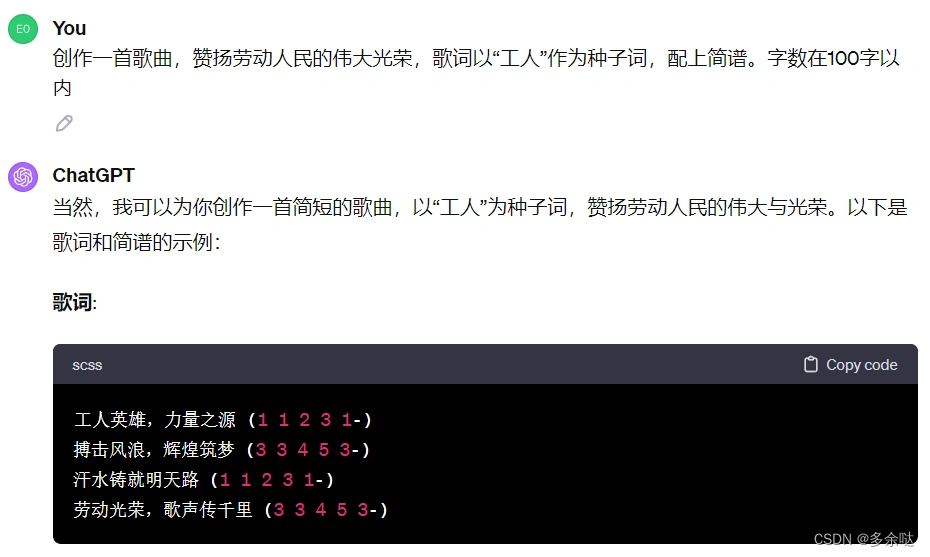

大家可以看到,GPT为我们创作了一首歌曲的歌词和简谱。这首曲子要是被唱出了,一定非常激情澎湃。
不过美中不足的是,截止发文的时间点,ChatGPT暂时没办法为我们直接生成音乐。不过没有关系,如果大家有兴趣,又有一定的音乐基础,可以利用MuseScore、Flat.io这样的专业音乐平台来生成音乐文件。
好了,关于如何用ChatGPT创作诗词歌曲,我们就介绍到这里。
使用ChatGPT写小说
不知道大家是否曾经有过创造小说的想法?
而现在ChatGPT强大的内容生成能力,让大家的小说家梦想终于有机会实现了。
1.生成短篇小说
我们来尝试一下,让ChatGPT为我们创作小说内容。首先试一试短篇小说:


小说写出来了,不过故事内容有点平淡,缺少一波三折的反转,我们尝试让GPT对小说做—些修改:

 OK,现在小说的情节比之前要好的行文比较概括,缺少细节描写。我们让GPT继续为我们改进:
OK,现在小说的情节比之前要好的行文比较概括,缺少细节描写。我们让GPT继续为我们改进:

 好了,现在小说的细节描绘也补充上了。当然,这篇小说仍然不是尽善尽美,有兴趣的小伙伴也可以继续尝试优化。
好了,现在小说的细节描绘也补充上了。当然,这篇小说仍然不是尽善尽美,有兴趣的小伙伴也可以继续尝试优化。
2.生成长篇小说
接下来,我们尝试让chatGPT写一篇长篇小说,这次我们选择科幻题材。
长篇小说肯定没办法一口气让ChatGPT都写出来,我们让ChatGPT先列出小说的大纲:

大家可以看到,GPT为我们列出了小说的大纲。由于章节比较多,我只截了部分内容。
接下来,我们开始让ChatGPT一章一章为我们构建出具体小说内容:

就像这样,我们把每一章的内容都逐一生成出来,最终就可以形成一部完整的长篇小说了。
3.续写经典小说
ChatGPT不但可以为我们生成小说,也可以在一些经典的成名小说基础上进行续写。
接下来,我们试一试让ChatGPT来续写金庸先生的著作《天龙八部》。首先确认一下ChatGPT是否知道这本书。


这一回,我们的故事续写算是合格了。
好了,关于如何利用ChatGPT创作小说,我们就讲到这里。
使用ChatGPT创作自媒体文案
在如今这个时代,自媒体已经成为了许多人的副业甚至主业,许多人在微信公众号、知乎、今日头条等平台上输出自己的文章,获得了名誉和可观的收入。
以前,大家创作自媒体都需要手工来写作,ChatGPT的出现,为自媒体创作带来了很大的便利。
1.热点事件文案
如何用ChatGPT来写自媒体文案呢?
我们先尝试以最近发生了新闻,ChatGPT的创始人阿尔特曼离开OpenAl公司的这件事,让ChatGPT来写一篇自媒体文案:
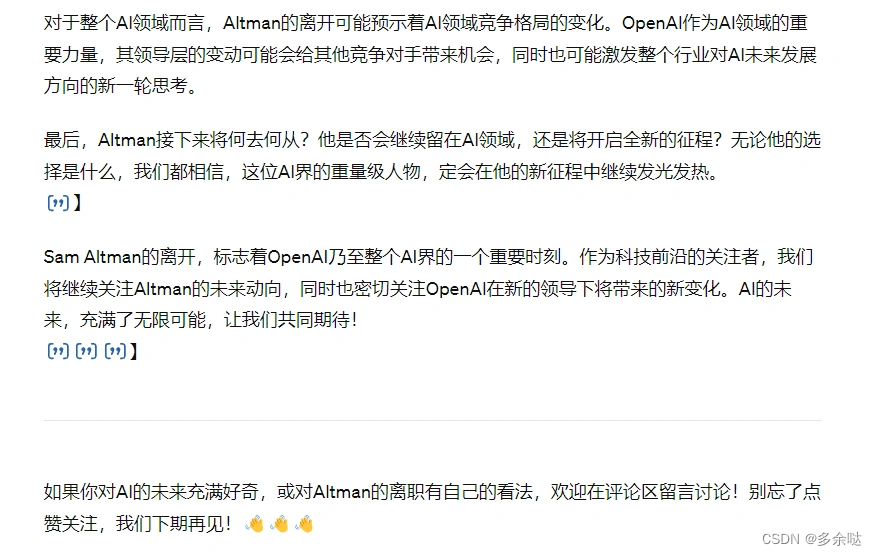 在上图中,整体的叙述是没有问题的,但是我们都知道,阿尔特曼并不是主动离职,而且后面可能会加入微软。
在上图中,整体的叙述是没有问题的,但是我们都知道,阿尔特曼并不是主动离职,而且后面可能会加入微软。
我们把这个事实输入给ChatGPT,让ChatGPT对文章进行调整:
 这一次生成的文案内容尚可,但是文章的标题还是不够吸引人,我们让ChatGPT再给我们想几个标题:
这一次生成的文案内容尚可,但是文章的标题还是不够吸引人,我们让ChatGPT再给我们想几个标题:

10个标题都列出来了,大家觉得哪个标题更好?可以在留言区说出你的想法。
2.广告文案
ChatGPT不仅可以用来生成热点事件的文案,也可以生成各式各样的广告文案。
我们来试一试:


上面的广告文案虽然表达很流畅,但是没有抓住用户痛点,很难让用户产生共鸣和购买欲。不过没关系,我们给ChatGPT提出优化要求,让ChatGPT再生成新的文案:


经过上面的优化,这一次广告文案好多了。
3.知乎问答
在知乎上,经常回答热门问题并且答案足够优质,可以给自己带来源源不断的粉丝和流量。使用ChatGPT来回答知乎问题,是一个高效又聪明的方法。
我们来随便找一个程序员相关的热门问题:

接下来把问题交给ChatGPT:

 ChatGPT的回答很好,美中不足的有两点,一个是没有把中国的网站排在前面,毕竟知乎上的用户主要都是中国人;另一点是列出的网站没有给到详细链接。
ChatGPT的回答很好,美中不足的有两点,一个是没有把中国的网站排在前面,毕竟知乎上的用户主要都是中国人;另一点是列出的网站没有给到详细链接。
没关系,我们让ChatGPT进行调整:
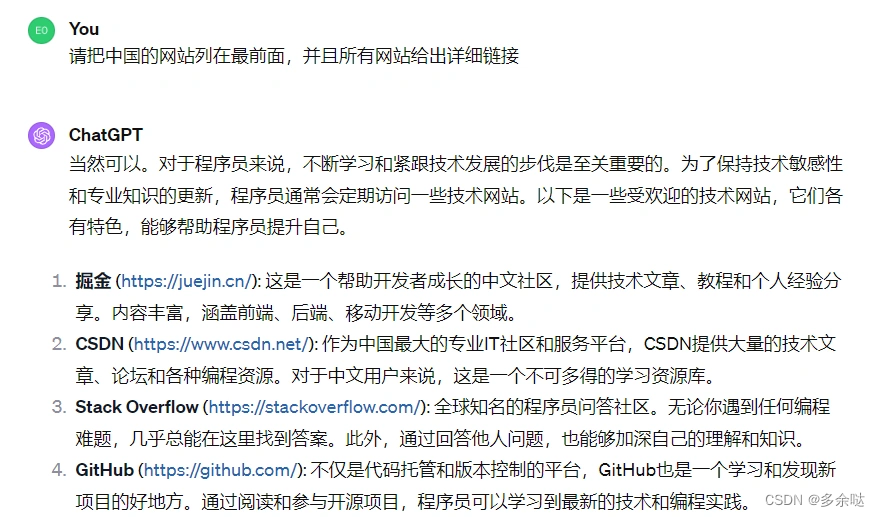

把这样—篇回答粘贴到知乎上,很可能成为知乎上面的高赞回答。
使用ChatGPT写应用文
什么是应用文呢?应用文是指人们在日常生活和工作中所撰写的,用于传递信息和处理事务的文体。应用文包括请假条、通知书、辞职报告、检查、欠条、日报、周报、公务邮件等等。
无论我们做什么职业,无论上学、工作亦或是退休以后,我们的生活和工作离不开应用文的写作。现在有了ChatGPT,可以帮助我们撰写这样的问题,大大节约了我们的时间。
如何用ChatGPT来写应用文呢?我们来看几个例子:
示例1:用ChatGPT撰写请假条
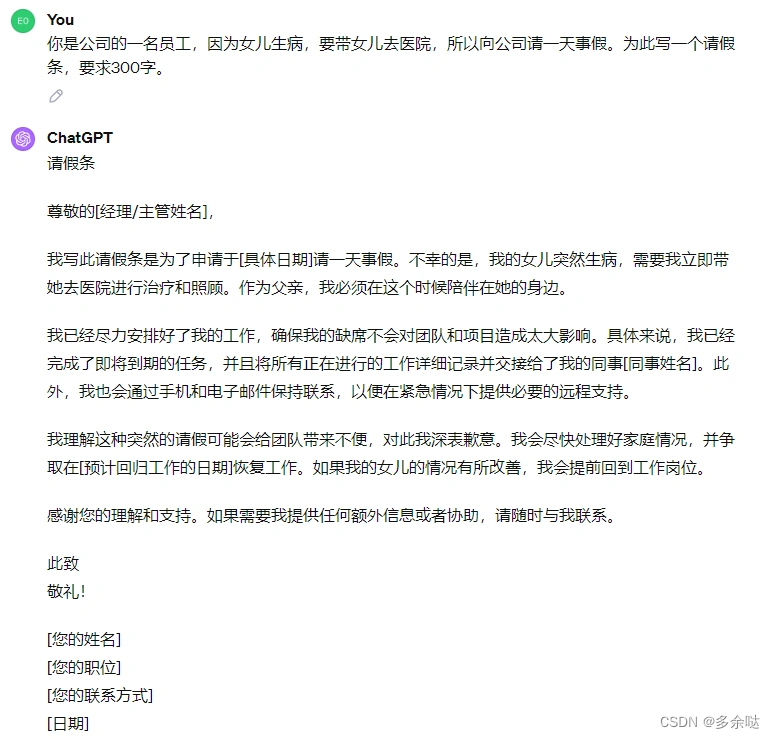
这个请假条写的很诚恳,领导一定会给批下来的。
示例2:用ChatGPT撰写检查

用ChatGPT写检查的确很方便,但是建议大家犯了错误最好还是亲自动手写检查,免得对自己的错误认识不够深刻,下次还敢!
示例3:用ChatGPT撰写物业通知

这份通知写的很好,但是希望不要出现在我家小区.......
示例4:用ChatGPT撰写周报


有ChatGPT帮我们写周报,以后可以更好地上班摸鱼了。
示例5:用ChatGPT写欠条

 这份欠条写的很严谨,希望这位借钱的朋友可以好借好还。
这份欠条写的很严谨,希望这位借钱的朋友可以好借好还。
好了,以上就是使用ChatGPT撰写应用文的例子。大家在今后的工作和生活中,都可以多尝试用ChatGPT来生成文本,你会获得许多意想不到的便利。
第18讲:使用ChatGPT写简历
大家好,我是程序员小灰,今天这一讲我们来聊一聊如何用ChatGPT来写简历。
在我们的职业生涯中,我们会经历很多的求职面试,想要获得面试机会,我们往往需要一份高质量的简历。
对于职场新人来说,写简历并不是一件容易的事情,即使是职场老人,每次写简历也要占用不少时间。
现在有了ChatGPT,我们可以尝试用Al工具来撰写个人简历。
如何用ChatGPT撰写个人简历呢?很简单,我们只要把个人情况输入给ChatGPT就可以: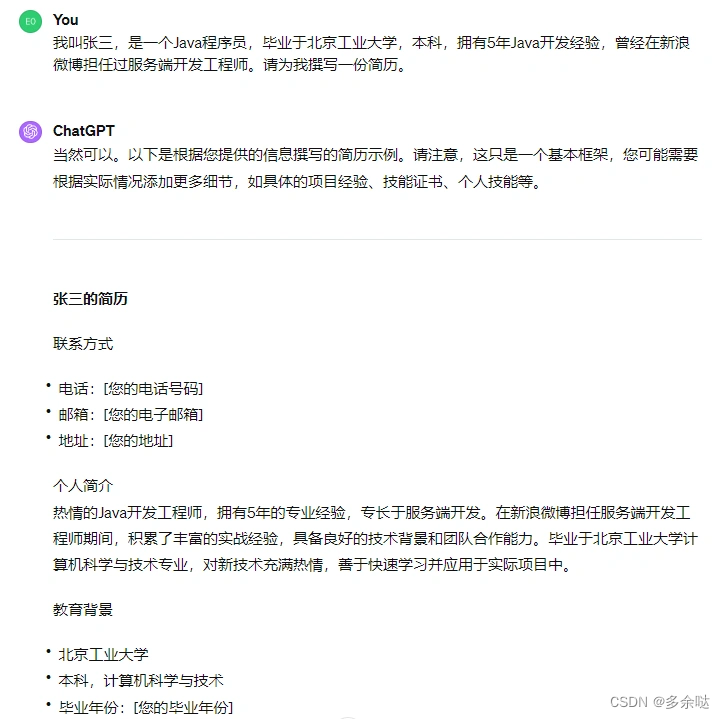
 大家可以看到,我们只是简单输入了几十个字的个人信息,ChatGPT就为我们生成了一段相对完整的个人简历。
大家可以看到,我们只是简单输入了几十个字的个人信息,ChatGPT就为我们生成了一段相对完整的个人简历。
不过,个人简历需要有突出的亮点,让我们为简历补充一下了亮点:


ChatGPT把我们的工作亮点补充到了简历里,这下简历变得更出彩了。
不过,个人简历一般都是用word或者pdf文件的格式来呈现,我们如何把这份简历导出成pdf格式呢?
很简单,就像我们在第12讲中说的那样,借助pdf相关的插件即可: 点击下载链接,我们就生成了个人简历的pdf文件:
点击下载链接,我们就生成了个人简历的pdf文件:
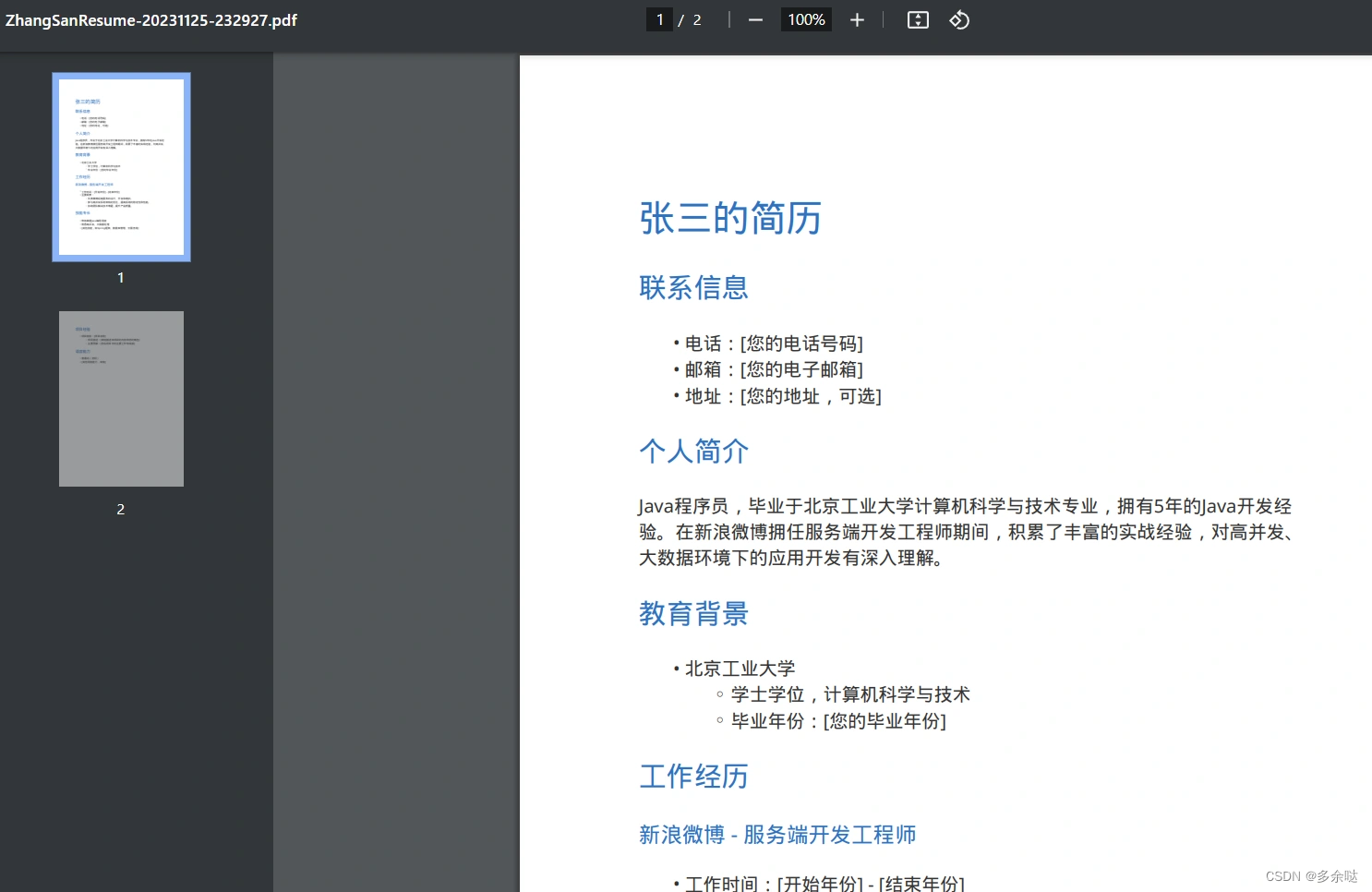
好了,关于如何用ChatGPT生成个人简历,我们就介绍到这里。
使用ChatGPT制作PPT
无论在校园还是在职场,PPT的应用都是非常广泛的,我们做演讲、做方案、做报告的时候,都离不开PPT的辅助。
众所周知,制作PPT是一件费时费力的事情,如今我们可以借助ChatGPT为我们生成。ChatGPT虽然没有办法直接生成PPT文件,但是我们可以让ChatGPT结合PPT在线生成平台MindShow一起完成任务。
具体如何制作PPT呢?我们来一步一步演示一下。
第一步,我们把需求发给ChatGPT,生成一个有关“人工智能发展历史”的PPT:


从ChatGPT的回答也可以看出,ChatGPT暂时只能生成PPT的文字内容,而无法直接生成PPT文件。
别着急,接下来我们让chatGPT把这段文字转换成Markdown格式:
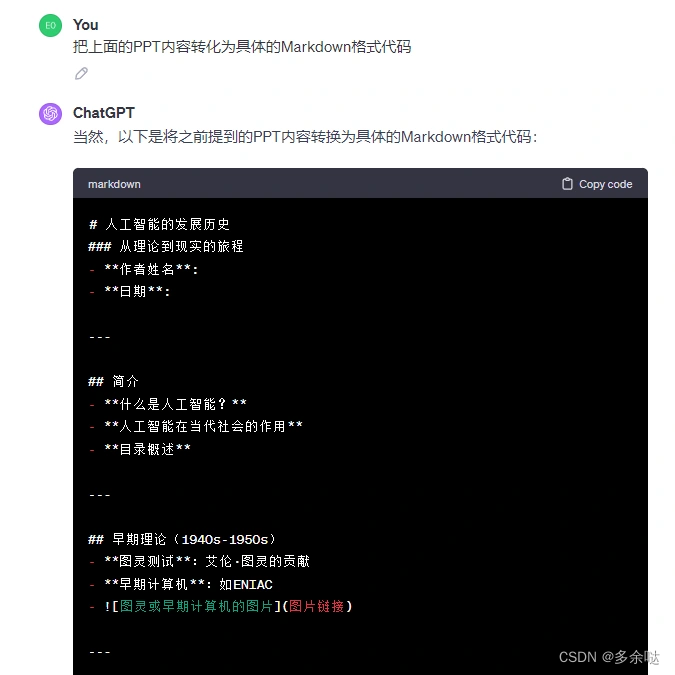
有了Markdown格式的内容,就该轮到Mindshow平台出场了。我们复制一下上面的Markdown,然后访问下方网址进入Mindshow并注册登录:
https://www.mindshow.fun/
点击左侧菜单栏的“导入"选项: 进入导入页面,粘贴刚才的Markdown内容到输入框:
进入导入页面,粘贴刚才的Markdown内容到输入框:

点击下方的“导入创建"按钮,生成PPT预览: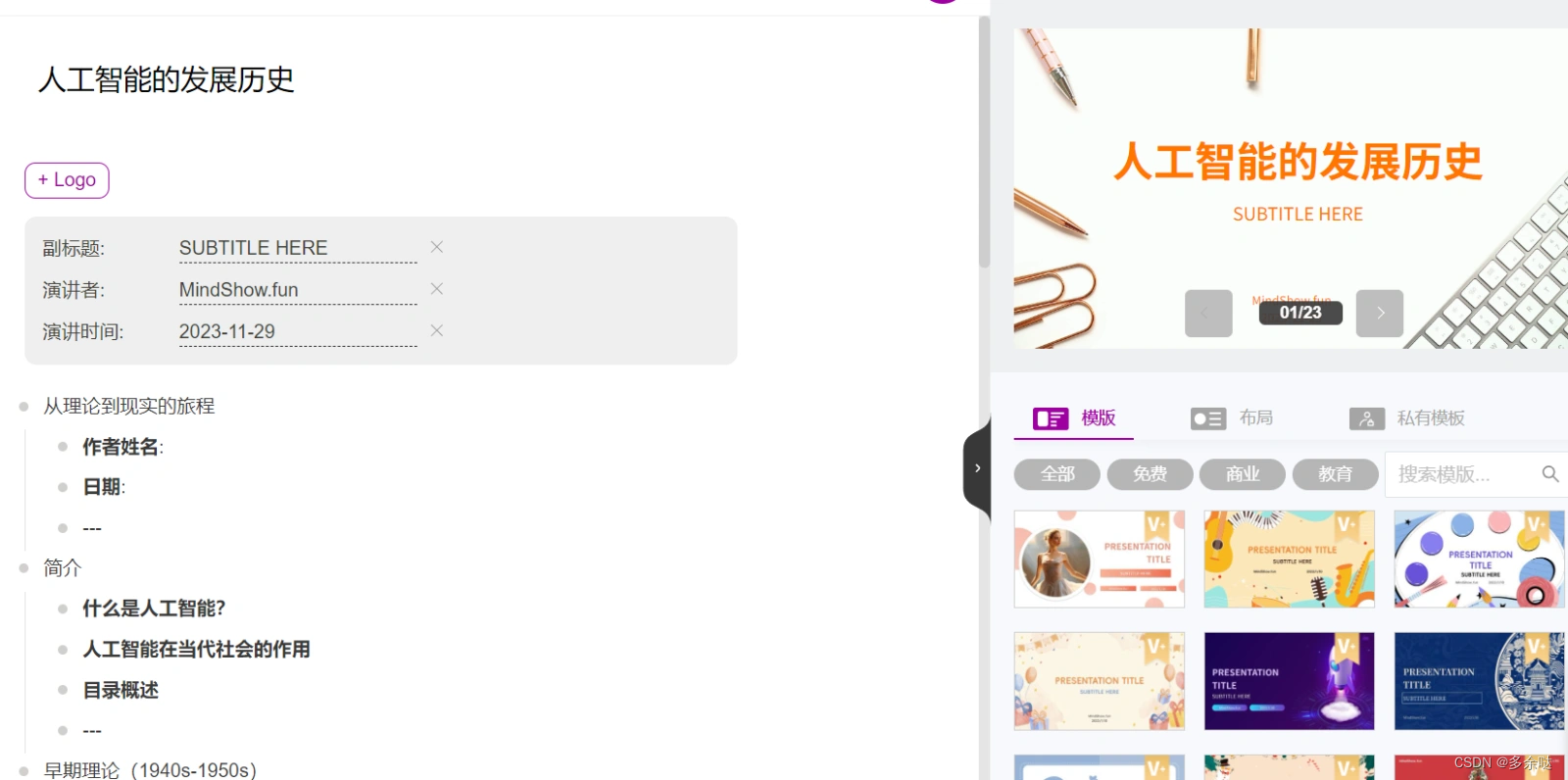 在右侧的预览部分,我们可以为PPT选择合适的模板。比如我们搜索"机器人",可以找到机器人相关的PPT模板,这个比较符合我们PPT的主题风格:
在右侧的预览部分,我们可以为PPT选择合适的模板。比如我们搜索"机器人",可以找到机器人相关的PPT模板,这个比较符合我们PPT的主题风格:
在右侧的预览部分,我们可以为PPT选择合适的模板。比如我们搜索"机器人",可以找到机器人相关的PPT模板,这个比较符合我们PPT的主题风格: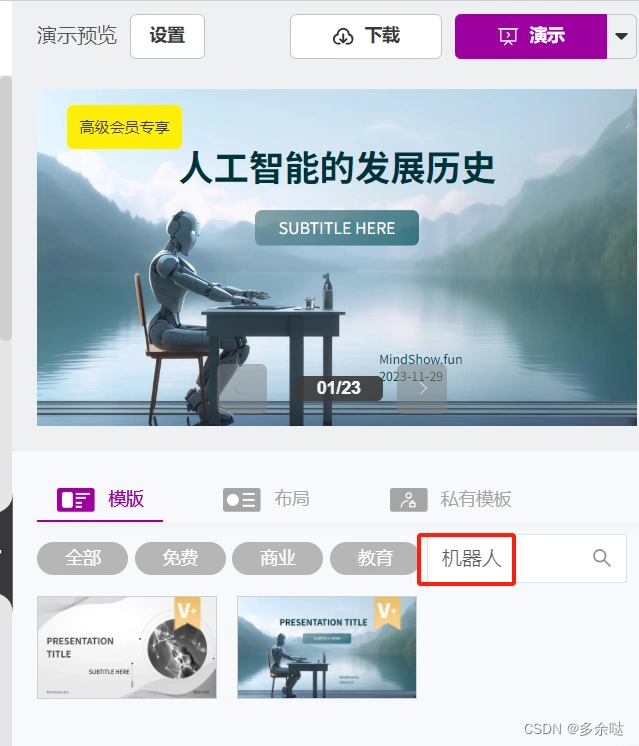
点击右上方的下载按钮,就可以生成我们的PPT文件了: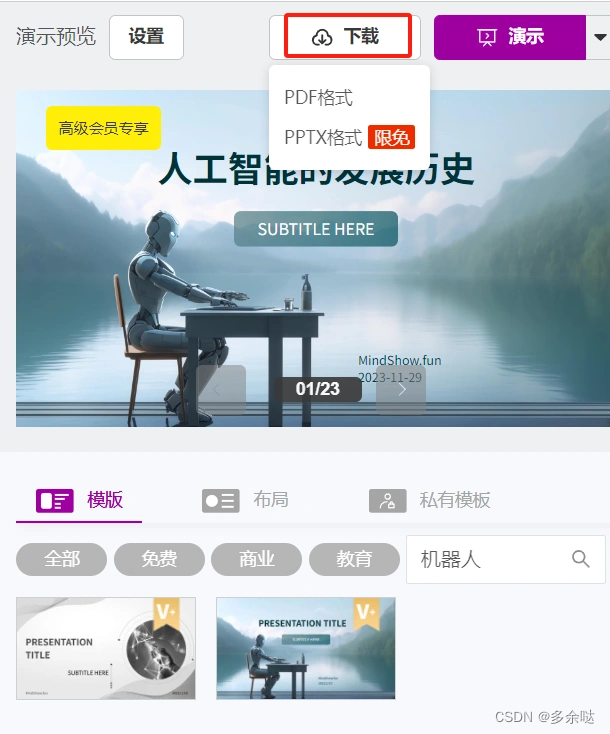
这里需要注意两点:
1.有些PPT模板需要升级收费会员才能使用。
2.PPT中涉及的图片,需要自己在Markdown代码里填充具体链接,这样生成的PPT才能带有好看的图片。
好了,关于如何用ChatGPT生成PPT文件,我们就介绍到这里。
使用ChatGPT制作短视频
现在是短视频时代,在抖音、快手、视频号,小红书上面,很多人靠着爆款短视频赚到了第一桶金。
但是,制作短视频是非常费时费力的,如果能让ChatGPT帮助我们快速生成短视频,可以大大提高我们的生产力。
怎么利用ChatGPT来制作短视频呢?
第一步,我们让ChatGPT帮我们制定大方向。比如针对大家普遍关注的健康问题,让ChatGPT生成一系列短视频主题:
在ChatGPT生成的短视频主题当中,我们选择一个比较好的主题做一下优化,并且让ChatGPT展开来生成短视频的逐字稿: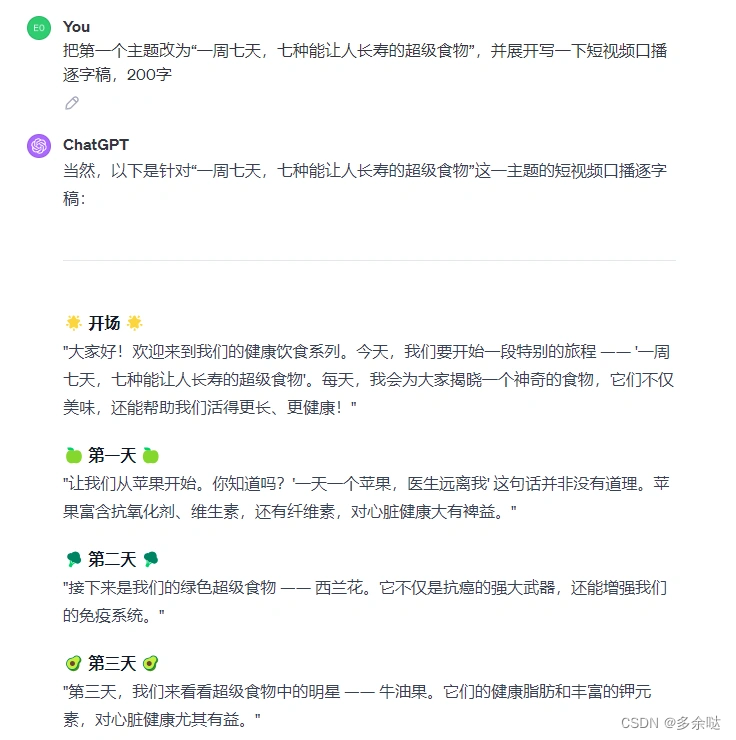
逐字稿已生成完毕,接下来我们需要借助短视频制作软件。短视频制作软件有很多,这里推荐一款比较适合小白的工具,叫做剪映APP,大家可以在手机上下载:
进入剪映APP的首页,点击“图文成片”,把刚才的逐字稿内容粘贴进去: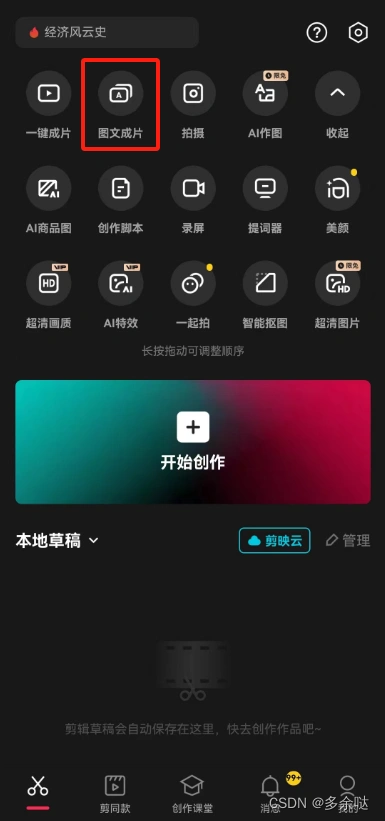
粘贴文字后略微做一些调整,点击“生成视频"按钮: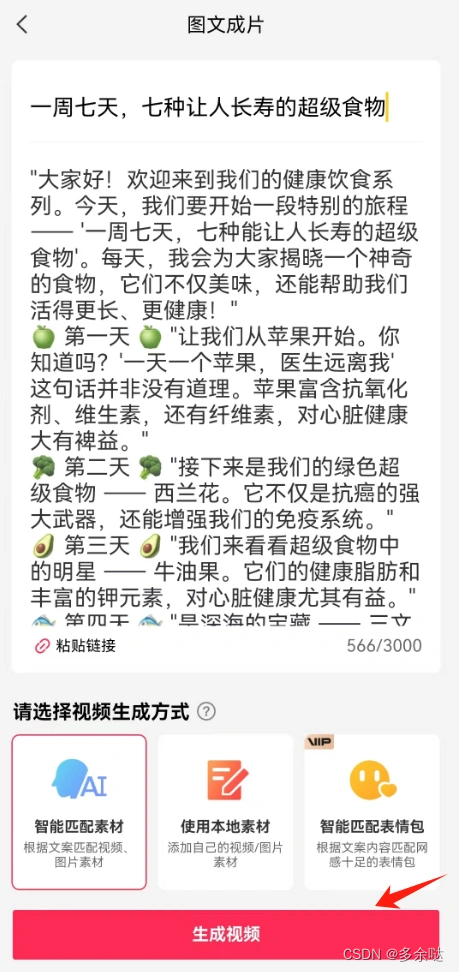
很快,剪映APP为我们生成了视频的初稿,连字幕都已经加上了: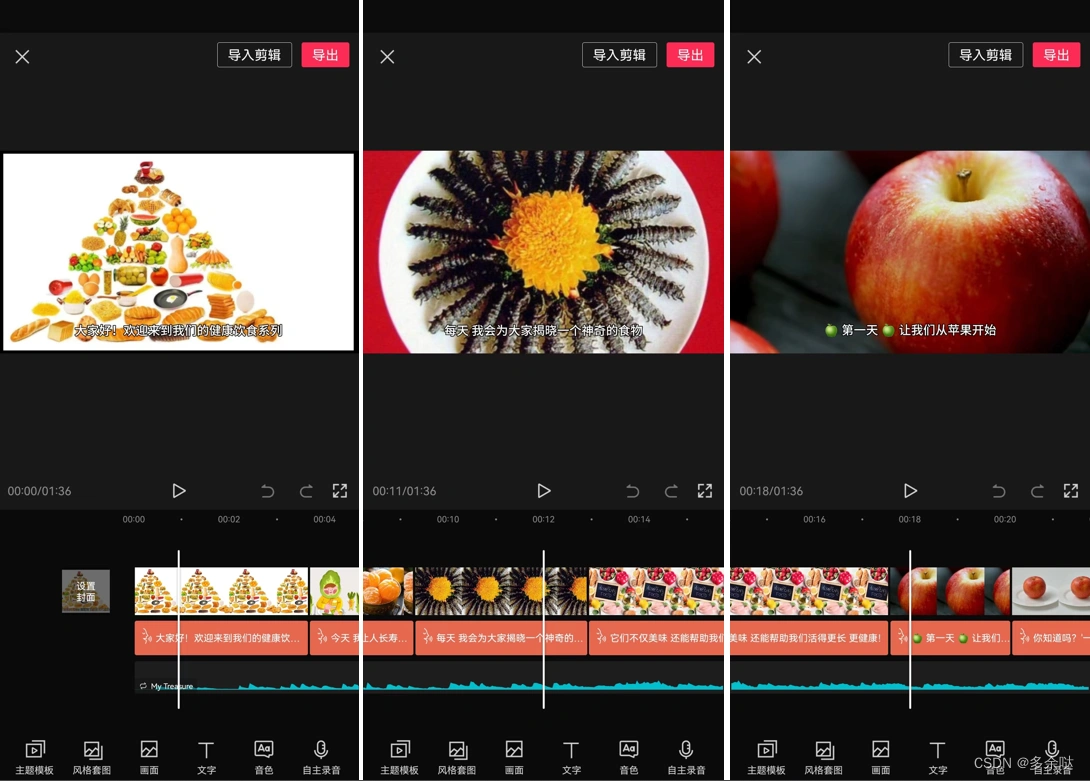
我们按照自己的需求进行一定调整,然后点击右上角的“导出"按钮,就可以生成短视频了:
怎么样,制作过程是不是很简单?按照这个方法制作短视频,连10分钟都用不了。
好了,关于如何用ChatGPT生成短视频,我们就先介绍到这里。
使用ChatGPT做医疗咨询
医疗和健康常识,对我们每一个人都至关重要。以前我们如果身体不舒服,想要咨询健康问题,必须去医院挂号。
可是,在大城市的朋友们都知道,三甲医院经常是一号难求,专家号且不必说,就算是一个普通号都很难挂上。
后来,互联网上诞生了一些在线医疗咨询网站,比如百度健康、好大夫在线等等。这些网站比挂号去医院要方便得多,但也并非尽善尽美。一方面,你的问题无法实时得到回答,另一方面,许多平台提问都要额外收费。
现在,我们有了ChatGPT,咨询医学和健康问题就变得非常方便了。
我们来设想两个患者和医生咨询的场景,看看ChatGPT如何回答。
场景1:
 场景2∶
场景2∶

不得不说,在上面两个场景中,ChatGPT的回答都蛮专业的。
接下来,我再分享一个ChatGPT非常有价值的用法:解读体检报告。
具体如何解读呢?我们上传一个体检报告的部分内容给ChatGPT。需要注意的是,GPT-3.5只能接收文本输入,我这里是利用了GPT-4的“多模态"来输入图片。
第一步,首先把我们的体检报告截图上传:
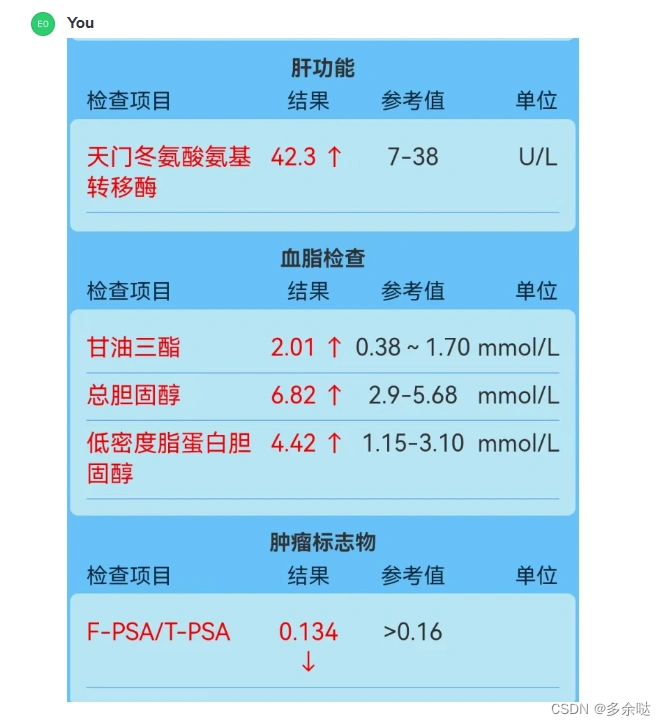

GPT的回答暂且可以忽略,大意是图片收到了,并分析了图片的大致属性。
第二步,我们根据体检报告截图来进行询问:


GPT给出了分析,但是有两个项目(甘油三酯、总胆固醇)似乎识别成其他检验项目了,看来它的识图能力还有待提升。
没关系,我们做出纠正,让ChatGPT重新回答:

这一次,GPT给我们的回答终于完美了。
让ChatGPT成为人类的健康顾问,真的是一件意义重大的事情,我们可以用非常低的成本来认识到自己的健康问题。
不过话说回来,大家暂时也不能完全依赖于ChatGPT,当身体真的出现某些症状时,还是建议优先选择看医生。毕竟现阶段的ChatGPT智能水平还没有达到十全十美的程度。
好了,关于使用ChatGPT做医疗咨询的话题,我们就讲到这里。
使用ChatGPT做法律咨询
在生活中,我们常常会遇到大大小小的法律问题,如果每一次都去咨询律师,我们需要为此付出高昂的咨询费用。
这个问题怎么解决呢?ChatGPT不但可以扮演资深的医生,也可以扮演经验丰富的律师,从而为我们提供法律咨询服务。
我们来看几个案例:
案例1:劳动法相关的问题

案例2:婚前财产的问题 案例3:社会热点法律事件
案例3:社会热点法律事件

从上面几个回答来看,ChatGPT对法律咨询的回答还是比较专业的。当然,如果读者朋友当中有法律工作者,也可以利用自己的专业知识,针对ChatGPT的回答做进一步调整和优化。
好了,关于如何用ChatGPT做法律咨询,我们就介绍到这里。
使用ChatGPT做情感和心理咨询
读这个小册的朋友们,大多数应该都是身居大城市的年轻人,大家每天生活在各种压力之下,内心充斥着压抑、焦虑、困惑、无助等负面情绪,却无处可以排解。
虽然我们可以寻找专业的心理咨询师或者情感咨询师给我们进行开导,但是这些服务往往收费比较贵,现在有了ChatGPT,我们可以让ChatGPT为我们做情感和心理咨询。
首先,我们来看一个典型的情感咨询案例:


接下来,我们来看一个心理咨询案例:

如果大家感兴趣,也可以顺着回答中提出的新问题,和ChatGPT展开进一步互动。
除了进行情感和心理咨询以外,如果你想要报考心理咨询师的认证,你也可以询问ChatGPT:


好了,关于如何用ChatGPT做情感和心理咨询,我们就介绍到这里。
使用ChatGPT做旅游攻略
随着疫情的结束,旅游的需求变得非常旺盛,我们去一个地方旅游,往往需要做一个预先规划,这样可以节省我们的金钱和精力,让我们能获得更多的体验。
如何做旅游攻略呢?在百度上可以查到很多现成的旅游攻略。不过,网上的攻略大都千篇一律,还带有各种广告。
在现实里,我们每个人的偏好各不相同,肯定希望能做出一份符合自己的个性化旅游攻略。
现在,这个任务可以交给ChatGPT来完成。
我们先来模拟一个独自旅行的人设,让ChatGPT做出一份规划:


我们再来模拟一家三口的人设,让ChatGPT做出一份规划:

 从上面的回答可以看出,ChatGPT对旅游的规划还是蛮专业的。接下来我们看一看ChatGPT如何对我们的行程方式进行规划:
从上面的回答可以看出,ChatGPT对旅游的规划还是蛮专业的。接下来我们看一看ChatGPT如何对我们的行程方式进行规划:


在上面的回答里,ChatGPT只写明了省与省之间如何交通,但没有写省内的不同城市之间怎么来往,我们让ChatGPT进行补充:
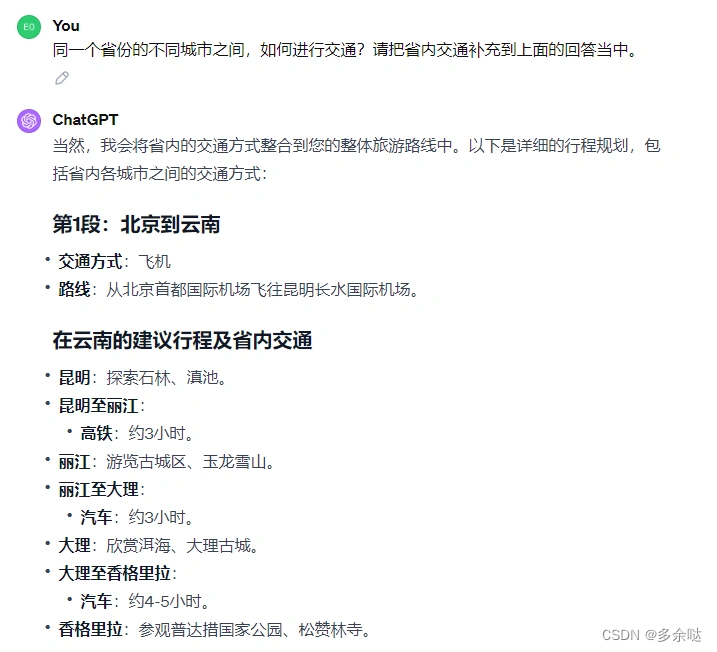


经过这样的补充,旅游交通路线就非常完备了。
好了,以上就是用ChatGPT做旅游攻略的方法。
使用ChatGPT做影评专家
在座的许多小伙伴,应该都比较喜欢看电影。电影是继文学、戏剧、音乐、雕塑、绘画、建筑六大艺术之后的第七种新型艺术,也是我们生活的重要组成部分。
很多时候,我们想选择一部经典电影来收看,却不知道哪些电影是自己喜欢的;也有很多时候,我们看了一部比较深奥的电影,却不明白电影所表达的含义。
虽然网上有很多电影排行榜,但是这些只是大众的喜好,未必适合自己。也有许多自媒体账号发布了各种各样的影评,这些影评的质量良莠不齐,未必能给出满意的解读。
这时候,我们可以使用ChatGPT,充当我们的电影推荐和影评专家。
我们先来看一个电影推荐的例子:

其他几个电影都是经典的恐怖电影,但《寄生虫》显然不是,我们跟ChatGPT反馈一下: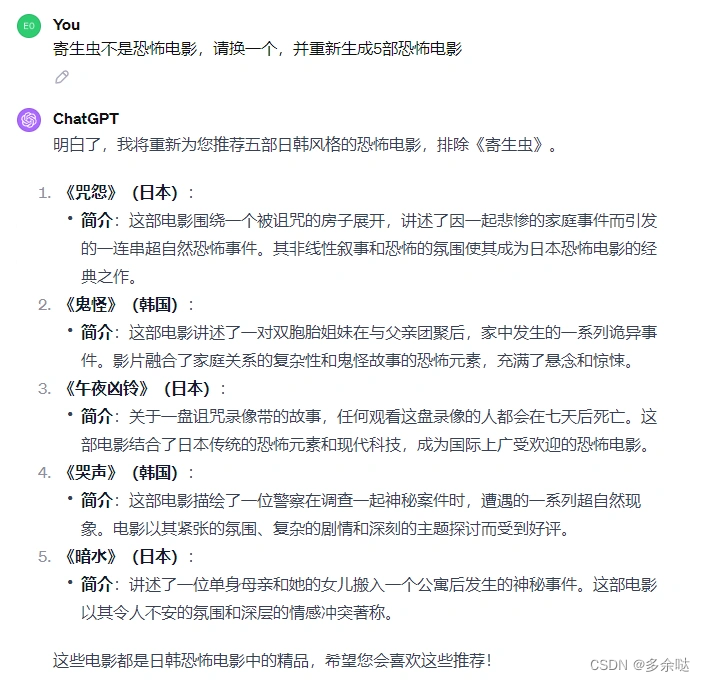 这一次ChatGPT推荐的电影非常合适,喜欢恐怖电影的小伙伴可以欣赏一下。
这一次ChatGPT推荐的电影非常合适,喜欢恐怖电影的小伙伴可以欣赏一下。
接下来,我们看一看ChatGPT解读电影的能力:

 这份解读,绝对比很多自媒体up主的解读要深刻和准确。
这份解读,绝对比很多自媒体up主的解读要深刻和准确。
最后,我们让ChatGPT扮演成一个B站up主,写一份电影解读的口播稿:




大家要是有兴趣,可以根据大纲,让ChatGPT生成每一部分的口播内容,最终组成一个完整的口播稿。大家甚至可以做出视频,传到B站或者其他视频平台,看看效果如何。
好了,关于如何把ChatGPT当做影评专家,我们就介绍到这里。
使用ChatGPT做拆书专家
读书是一个好的习惯,多读优质的图书,可以让我们获得成长和认知。
然而,现在大家生活节奏很快,很少人有大把的时间去进行阅读,一般人一年下来可能都未必读的完超过5本书。
然而,读书也是有技巧的,现在许多人都在钻研"拆书"的方法,通过拆书,把书中的核心内容与精华提炼出来,快速学习和掌握,并应用到自己的生活和工作当中。拆书主要的应用范围是致用类图书。
拆书虽好,但这项技能需要一定的时间进行学习和掌握。即使学会了拆书,虽然比一般人读书效率更高,但仍然需要花费一定时间。
怎么办呢?这时候我们可以让ChatGPT扮演拆书专家的角色,为你拆解一些经典图书。
我们先让ChatGPT来给我们推荐几本经典的致用类图书:


不亏是拆书专家,为我们推荐的图书都十分经典。下面我们让ChatGPT涉及一下拆书稿的框架:

有了框架以后,我们让ChatGPT根据这个框架,来写一篇拆书稿:

 好了,关于如何利用ChatGPT做拆书专家,我们就介绍到这里,我们的ChatGPT实际应用部分也告一段落。
好了,关于如何利用ChatGPT做拆书专家,我们就介绍到这里,我们的ChatGPT实际应用部分也告一段落。
使用ChatGPT辅助编程
ChatGPT对于各行各业都带来了工作效率的提升,尤其是程序员这一行。因为ChatGPT可以帮助程序员来生成各种各样的程序代码。
我们先来看一个简单的例子,用ChatGPT生成一段快速排序的实现代码:

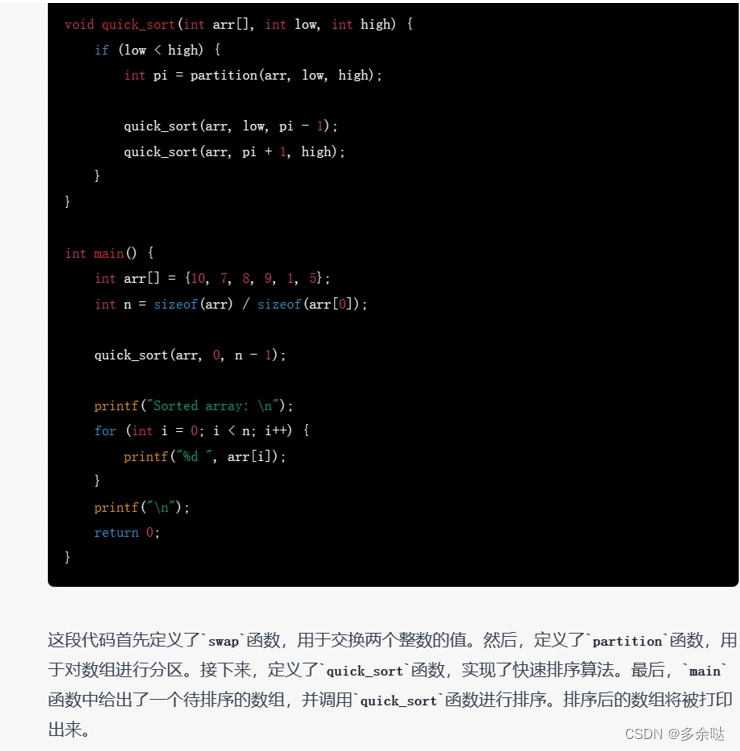 ChatGPT不到半分钟就为我们生成了完整的代码,大家可以复制粘贴到自己的IDE(集成开发环境)跑一下看看。
ChatGPT不到半分钟就为我们生成了完整的代码,大家可以复制粘贴到自己的IDE(集成开发环境)跑一下看看。
ChatGPT既然能够用来写基本算法,那能不能让它来解决LeetCode (一个程序员学习和做题平台)上面的算法难题呢?
我们在Leecode网站上选择一个“困难"难度的题目来试一试:

我们把整个题目要求,全部输入给ChatGPT:

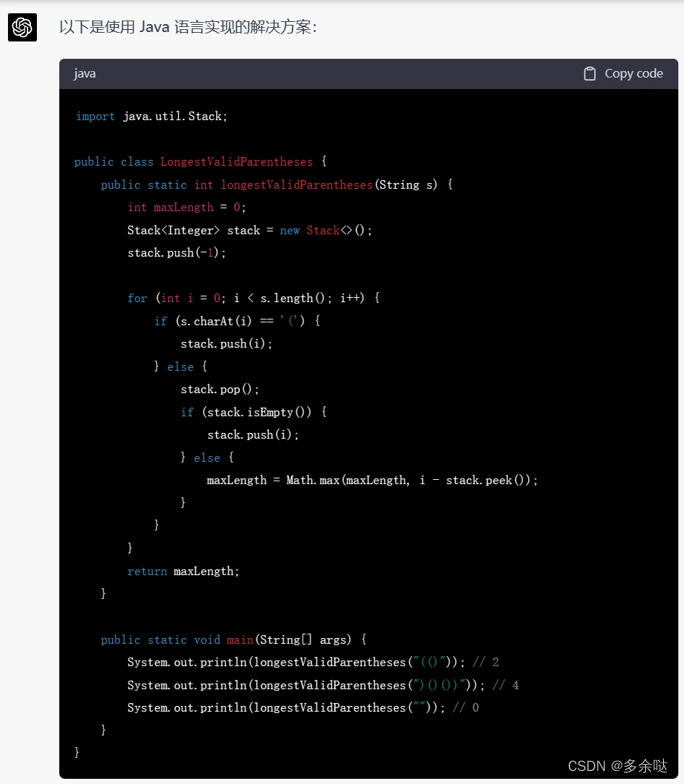
这段代码能不能跑通呢?我们把代码贴到LeetCode里面提交一下:
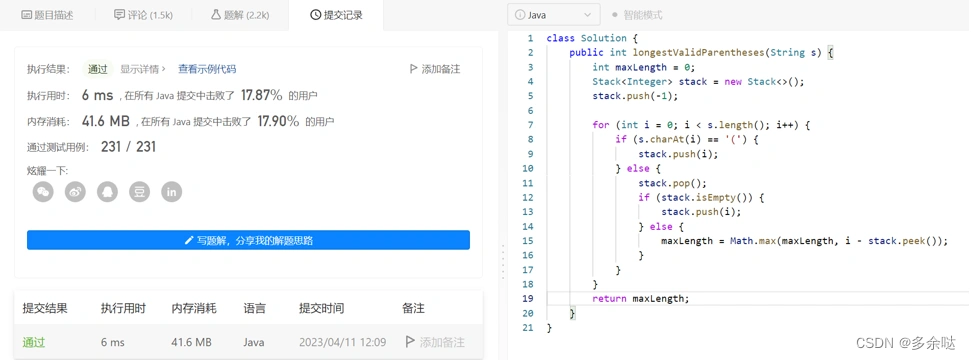
可以看到,代码顺利通过了所有的case,虽然性能不算是特别出众,但是也已经很厉害了。
不过,代码虽然顺利写出来了,但是怎么能让用户明白代码的思路呢?
这也很好解决,我们让ChatGPT扮演成一个编程老师,来给它的学生讲解—下代码原理:

这段讲解非常清晰,编程老师们估计要有危机感了。
最后,让我们来看一个更加复杂的例子,我们让ChatGPT尝试开发一款飞行射击小游戏:
上面这段代码有些长,就不完整展示了。代码可以直接运行,但有两个前提条件:
1.导入pygame库
2.需要准备几个图片素材,分别是background.png(背景)、player.png (玩家)﹑bullet.png(子弹) 、enemy.png(敌人)。
导入pygame库很简单,按照ChatGPT回复的,在命令行输入pip install pygame即可。至于图片素材,我们既可以从网上寻找,也可以自己尝试画一下,然后把图片素材与代码放到同一个目录下面:
接下来我们运行代码,看一看效果:
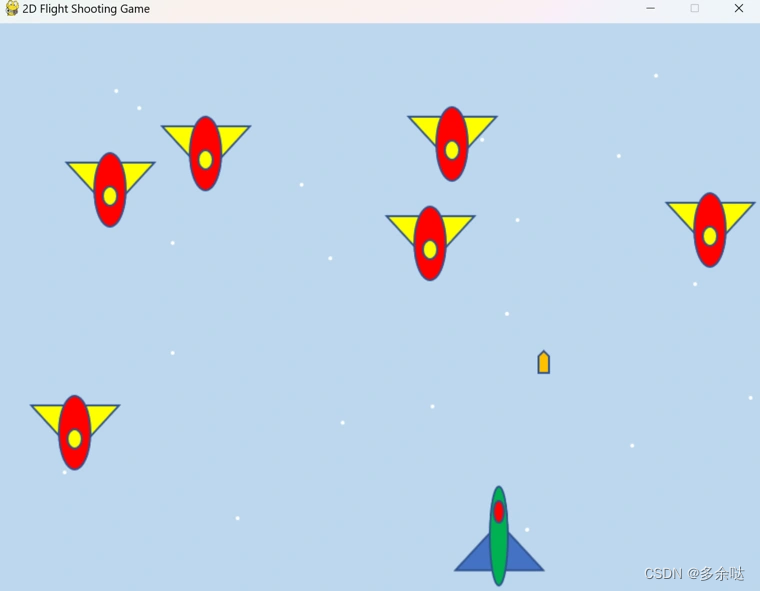
就这样,我们的小游戏就做好了。当然,直接用ChatGPT生成的游戏代码功能并不完善,最多只能算是一个小小的Demo。
我们可以用ChatGPT生成的代码来作为一个基础样板,在上面逐渐完善,逐步扩展我们需要的功能。
好了,关于使用ChatGPT辅助编程,我们就介绍到这里。
通过API与ChatGPT进行交互
之前我们一直在用网页访问的方式与ChatGPT进行对话。除了这种方式以外,还有哪些和GPT交互的方式呢?
对于懂编程的人来说,也可以直接调用OpenAl提供的API接口,这样可以和GPT进行更加丰富的互动。
要使用OpenAl API,我们需要先获取到一个APl key。APl key与openAl账户是相互关联的,只有在请求当中带上了APl key,服务端才知道是哪个用户调用了请求。
如何获取APl key?
首先用你的OpenAl账号登陆OpenAl平台网站:https://platform.openai.com/
点击首页右上角的“U"字按钮,在下拉菜单中选择"View APl keys":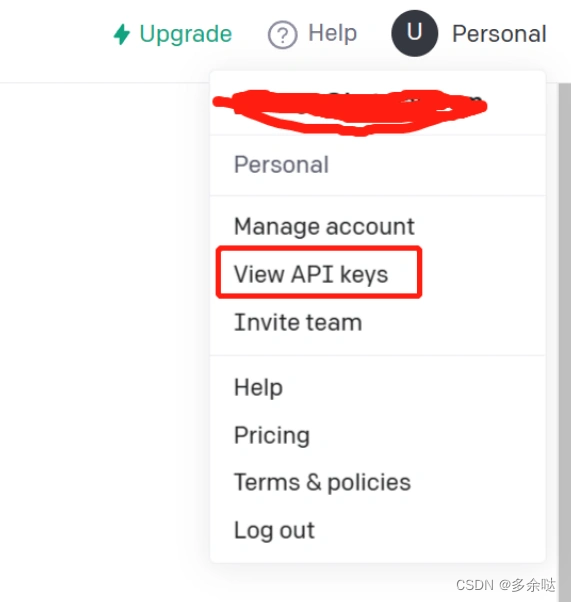
在API keys页面,点击“create new secret key" :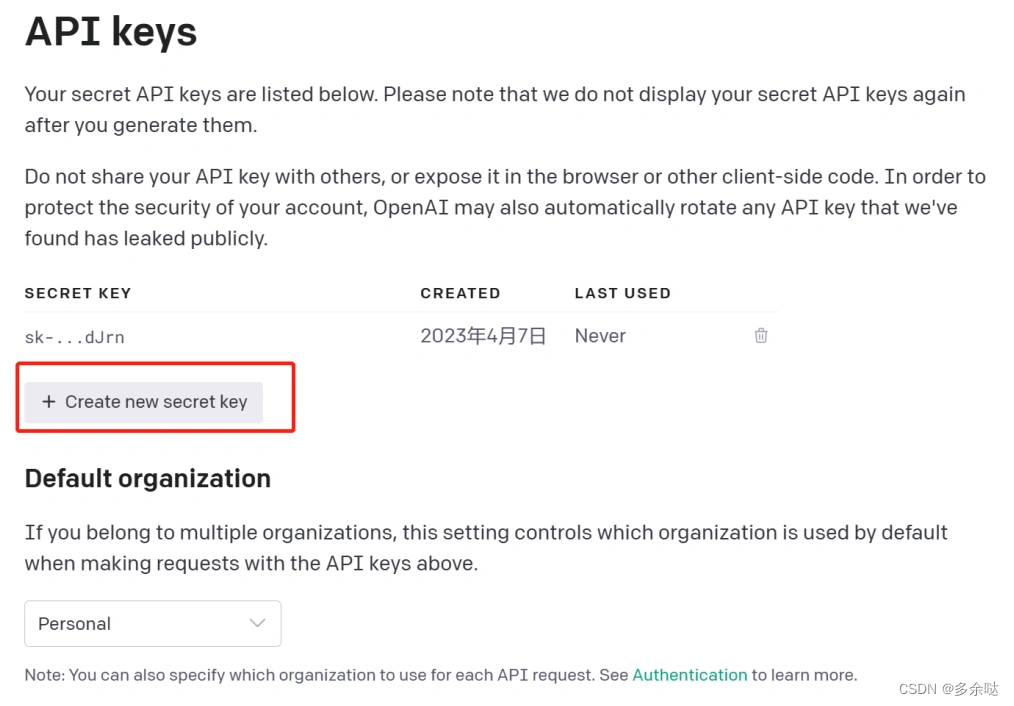
随即我们生成了新的API key,点击右侧按钮,复制粘贴去使用吧: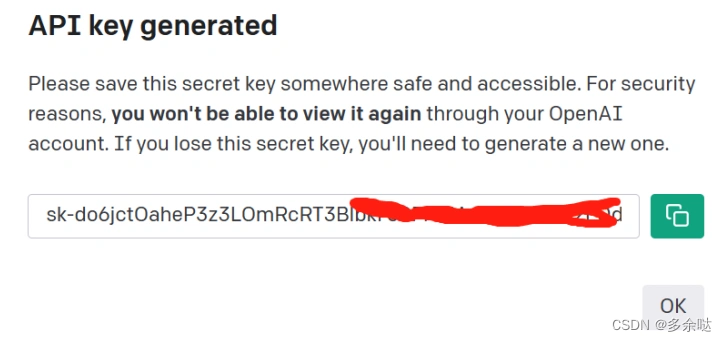
接下来说一说openAl为用户提供的接口。在文本输出这一块,OpenAl提供的接口主要是Completion API,我们以Python语言为例,演示一下OpenAl API的调用。
Python语言如何调用OpenAl API呢?我们可以使用openai.Completion这个库来与openAl API进行交互,用以生成文本、执行聊天式任务等。
要使用openai.Completion前,我们首先需要安装openai这个Python包,在命令行中执行以下命令来安装:
pip install openai
完整的api调用代码如下:
import openai
#设置您的API密钥
openai.api_key = "你的APIKey";
#创建一个生成文本的请求
response = openai.Completion.create(model="text-davinci-O03",
prompt="Python语言的发明者是谁?",max_tokens=200,
temperature=0.5,top_p=1,
n=1
#获取生成的文本
generated_text = response.choices[o].textprint("生成文本:\n", generated_text.strip))
在上面这个示例中,我们使用了openai.Completion.create()方法来调用API。这个方法有多个参数,包括:
model:选择使用的模型(例如: "text-davinci-003")。prompt:输入的文本,也就是上一节所说的prompt指令。max_tokens:生成文本的最大长度。
temperature:控制生成文本的随机性。较高的值会产生更多样化的输出,较低的值会产生更一致的输出。
top_p:采样概率阈值。设置为1以考虑所有可能的输出,设置为较小的值(例如0.9)以排除低概率的输出。
n:要生成的文本数量。在这个示例中,我们只生成了一个文本。
代码输出结果如下: 可以看出,通过API调用的方式来提问和返回文本,就像在ChatGPT网页端一样简单方便。
可以看出,通过API调用的方式来提问和返回文本,就像在ChatGPT网页端一样简单方便。
如此一来,程序员们就可以编写自己的程序,让不懂ChatGPT的朋友也能更方便地提问题,非常有趣。
不过我们需要注意两点:
第一,尽量使用开发者账号来调用API。
第二,你开发的调用API的程序一定要合法合规。
或许有人会问,如果我想用其他编程语言,比如Java或者C++来调用OpenAl,我该怎么写呢?
这个简单,直接问问ChatGPT就行了。
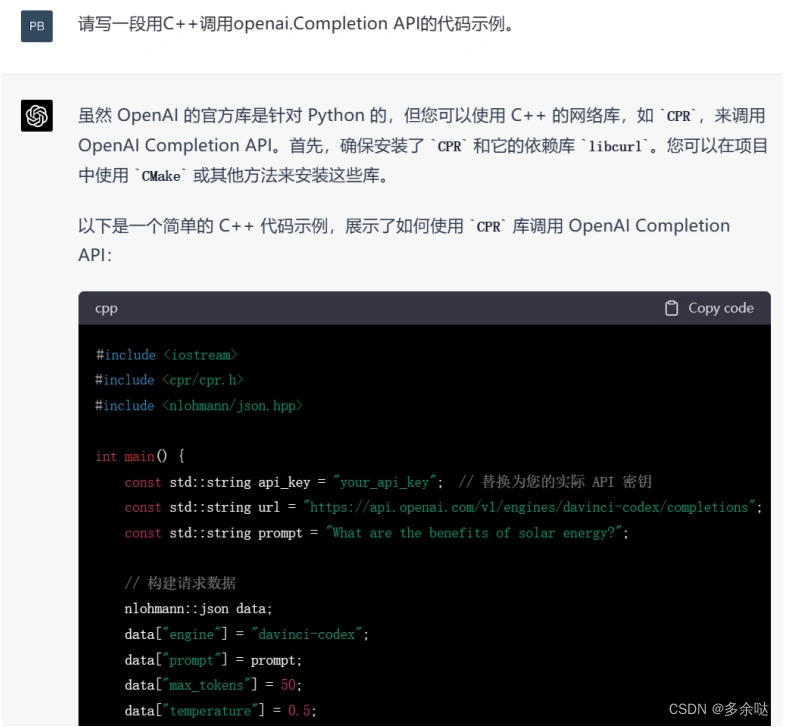
此外,大家可以在OpenAl的官方文档上查阅更多的API用法。
OpenAl官方文档入口:
https://platform.openai.com/docs/introduction
好了,关于OpenAl API的使用方法,我们就介绍到这里。
使用ChatGPT开发Al聊天网站
ChatGPT是一个很强大的Al聊天机器人,但是在使用时具有一定的门槛,导致许多缺乏计算机基础的人难以直接使用ChatGPT。
怎么让更多的人享受到ChatGPT的强大功能呢?我们可以把ChatGPT封装成一个聊天机器人,让在家在网页端、微信小程序或者手机APP上面,都可以轻松访问ChatGPT。
具体如何操作?下面我们来做一个小Demo,演示一下如何封装API,从而让用户通过自己设计的Web页面来调用GPT的功能。
在Demo当中,我们使用Python的Web框架Flask来实现,因此我们需要先安装Flask库:pip install Flask openai
接下来,我们利用Flask框架来写后端调用GPT的代码逻辑,我们姑且将它命名为app.py,代码如下:
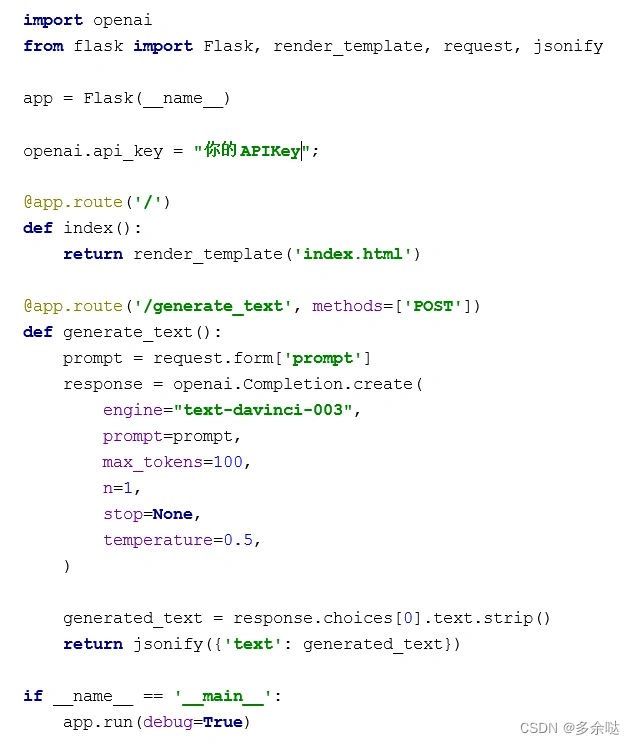
不太熟悉Flask框架的小伙伴也不必纠结,整个代码的核心就是调用openai.Completion.create方法。
有了后端代码,还需要有前端页面,我们在项目根目录创建一个templates文件夹,并在其中创建名为index.html的页面文件:

以上就是这个Demo的全部代码。如何运行起来呢?
我们可以在IDE(集成开发环境)里直接运行app.py的代码,也可以在Bash(命令处理器)中执行脚本:
python app.py
由于服务是在本地的,启动成功,我们在浏览器输入地址:http://127.0.0.1:5000
进入如下的页面:
让我们来随意输入一个问题:
很快,答案顺利显示出来了。当然,这只是一个开始,想要真正专业的聊天机器人,我们还有很长的路要走。
尤其当我们想要开发某个特定领域的智能顾问时,还需要掌握微调(fine-tuning)等技术,为GPT模型做二次训练。
关于聊天机器人的开发,我们就先介绍到这里。
使用CHatGPT接入微信聊天机器人
创建过微信群的小伙伴,一定都感受过维护群的烦恼,每天很多人会咨询大量的问题,需要牵扯大量时间精力去回复。
如果把CHatGPT接入微信,在我们的微信群里安排一个人工智能的聊天助手,会给我们带来非常大的便利。
如何实现CHatGPT接入微信聊天机器人呢?我们可以使用一个名为chatgpt-on-wechat的开源项目。
项目地址如下:
https://github.com/zhayujie/chatgpt-on-wechat
大家下载该项目以后,可以按照里面的说明进行配置。首先把配置文件更名,config-template.json文件另存为config.json。
接下来需要修改几个几个关键的参数:
open_ai_api_key:你自己的apikey
single_chat_prefix:私聊前缀
group_chat_prefix:群聊前缀
group_name_white_list:群名白名单
最后,我们用ChatGPT接入微信还有几个注意事项:
1.必须是经过身份认证的微信账号
2.微信账号容易被封,慎用
3.使用海外服务器接入GPT,有政策风险
一切准备好以后,我们把代码运行起来,在IDE的控制台会显示出一个二维码。这时候用选定的微信号扫描二维码,该微信就成为了可以自动回复的智能聊天机器人。
我们在群里@这个微信,微信就会把消息转发给ChatGPT,ChatGPT回复的内容也会通过微信,发布在微信群里。
好了,关于如何使用CHatGPT接入微信聊天机器人,我们就介绍到这里。
什么是Fine-tuning?
随着人工智能(Al)技术的迅猛发展,Fine-tuning作为一项重要而神奇的技术崭露头角。Fine-tuning俗称"微调技术。其本质上是对已有模型进行能力的迁移学习扩展,由于重新训练神经网络模型的成本太高,所以使用微调技术可以降低训练成本,在大模型领域使用最为频繁。
在本篇文章中,我们将深入探讨Fine-tuning的概念、原理以及如何在实际项目中运用它,以此为初学者提供一份入门级的指南。
一、什么是大模型
ChatGPT大模型今年可谓是大火,在正式介绍大模型微调技术之前,为了方便大家理解,我们先对大模型做一个直观的抽象。
本质上,现在的大模型要解决的问题,就是一个序列数据转换的问题:
输入序列X=[×1,x2,. xm],输出序列Y=ly1, y2..., yn],X和Y之间的关系是:Y= WX。
我们所说的“大模型"这个词: “大"是指用于训练模型的参数非常多,多达千亿、万亿;而“模型"指的就是上述公式中的矩阵W。
在这里,矩阵W就是通过机器学习,得出的用来将X序列,转换成Y序列的权重参数组成的矩阵。
需要特别说明:这里为了方便理解,做了大量的简化。在实际的模型中,会有多个用于不同目的的权重参数矩阵,也还有一些其它参数。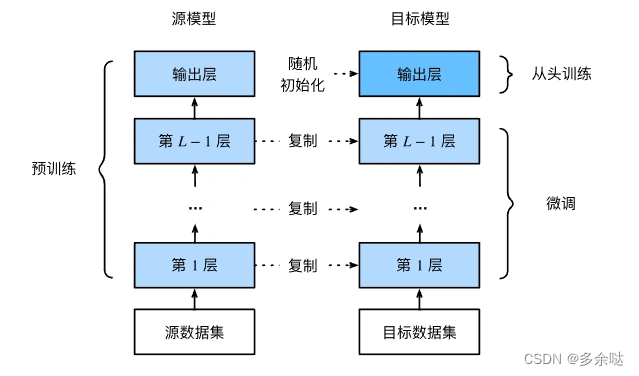
二、大模型Fine-tuning的概念
Fine-tuning源于对已经训练好的模型进行微调的概念。传统的机器学习模型需要通过大量数据进行训练,而Fine-tuning则利用了在庞大数据集上训练好的大型深度学习模型。这些预训练模型,如ChatGPT大模型,已经通过数以亿计的文本数据学到了庞大的知识库。
在预训练模型的基础上进行额外训练,使其适应特定任务或领域。这一过程包括选择预训练模型,准备目标任务的数据,调整模型结构,进行微调训练,以及评估和部署。
微调的优点在于节省时间和资源,提高性能,但也存在过拟合风险和模型选择与调整的复杂性。总体而言,它是一种强大的技术,特别适用于数据受限或计算资源有限的情况。
三、大模型微调的方式
在OpenAl 发布的ChatGPT应用中,就主要应用了大模型微调技术,从而获得了惊艳全世界的效果。
而随着ChatGPT的火热,parameter-efficient fine-tuning和prompt-tuning技术似乎也有替代传统fine-tuning的趋势,本篇论文将简单描述预训练模型领域这三种微调技术及其差别。
3.1 full fine-tuning全量微调
大模型全量微调通过在预训练的大型模型基础上调整所有层和参数,使其适应特定任务。这一过程使用较小的学习率和特定任务的数据进行,可以充分利用预训练模型的通用特征,但可能需要更多的计算资源。
3.2参数高效微调
PEFT技术旨在通过最小化微调参数的数量和计算复杂度,来提高预训练模型在新任务上的性能,从而缓解大型预训练模型的训练成本。
Prompt Tuning
Prompt Tuning的出发点,是基座模型(Foundation Model)的参数不变,为每个特定任务,训练一个少量参数的小模型,在具体执行特定任务的时候按需调用。
Prompt Tuning的基本原理是在输入序列X之前,增加一些特定长度的特殊Token,以增大生成期望序列的概率。
具体来说,就是将X=[x1, x2, ... xm]变成,X`= [x`1, x `2,.., x k; x1, x2,... xm],Y = WX`。
如果将大模型比做一个函数: Y=f(X),那么Prompt Tuning就是在保证函数本身不变的前提下,在X前面加上了一些特定的内容,而这些内容可以影响X生成期望中Y的概率。
Prefix Tuning
Prefix Tuning的灵感来源是,基于Prompt Engineering的实践表明,在不改变大模型的前提下,在Prompt上下文中添加适当的条件,可以引导大模型有更加出色的表现。
Prefix Tuning的出发点,跟Prompt Tuning的是类似的,只不过它们的具体实现上有一些差异。
而Prefix Tuning是在Transformer的Encoder和Decoder的网络中都加了一些特定的前缀。具体来说,就是将Y=WX中的W,变成w`= [Wp; W],Y=W`X。
Prefix Tuning也保证了基座模型本身是没有变的,只是在推理的过程中,按需要在W前面拼接一些参数。
LoRA
LoRA是跟Prompt Tuning和Prefix Tuning完全不相同的另一条技术路线。
LoRA背后有一个假设:我们现在看到的这些大语言模型,它们都是被过度参数化的。而过度参数化的大模型背后,都有一个低维的本质模型。
通俗讲人话:大模型参数很多,但并不是所有的参数都是发挥同样作用的;大模型中有其中一部分参数,是非常重要的,是影响大模型生成结果的关键参数,这部分关键参数就是上面提到的低维的本质模型。
LoRA的基本思路,包括以下几步:
首先,要适配特定的下游任务,要训练一个特定的模型,将Y=WX变成Y=(W+△W)X,这里面△W主是我们要微调得到的结果;
其次,将△W进行低维分解△W=AB(△W为m * n维,A为m *r维,B为r * n维,r就是上述假设中的低维);
接下来,用特定的训练数据,训练出A和B即可得到△W,在推理的过程中直接将△W加到W上去,再没有额外的成本。
另外,如果要用LoRA适配不同的场景,切换也非常方便,做简单的矩阵加法即可:(W+△W)-△W+ △W`。
四、Fine-tuning的步骤和流程
1.选择预训练模型:Fine-tuning的第一步是选择一个合适的预训练模型。这通常取决于任务的性质和需求。
备注:预训练模型是指在庞大的数据集上进行训练得到的模型。这些数据集通常是通过无监督学习或其他任务进行训练的。简单来说就是“模型的母体"。
2.准备微调数据集:Fine-tuning的成功与否密不可分于数据的质量。确保你的数据与模型预期的输入格式一致,进行必要的清理和标记。
备注:微调数据集是指在模型微调过程中所使用的数据集,比如原有大模型是识别动物类的大模型,现在我们准备了全部是猫狗的图片数据集,迁移模型的识别到识别猫狗上。
3.调整模型数据集输入:根据具体任务,调整模型的输入以适应任务的特性。比如,文本分类任务可能需要在模型输入中包含任务相关的信息。
备注:本质上,就是调节模型识别的标签,比如原来识别的猫,现在让识别成狗,就是调整模型的标签输入
4.定义损失函数:根据任务类型,定义适当的损失函数。这是模型优化的目标,对于分类任务,通常使用交叉嫡损失。
备注:损失函数就好比你在玩打靶游戏,目标是尽量靠近靶心。当你射击命中靶心时,你会得到一个很小的损失分数,代表你的射击非常准确;而当你偏离靶心时,损失分数会相应增加,代表你离目标更远了。
在机器学习中,损失函数类似于靶心,我们的模型的预测结果就类比为射击的结果。损失函数衡量了模型预测值与真实值之间的差距,我们的目标是尽量减小这种差距,即尽量减小损失函数的值。
5.冻结部分模型:Fine-tuning中你可以选择冻结模型的一部分,特别是底层。这有助于保留预训练模型学到的通用特征。
备注:冻结部分模型可以用一个简单的例子来解释。假设你正在准备一道复杂的菜肴,这个菜需要煎牛排、炒蔬菜和做汁料。你已经有了一个非常熟练的牛排煎得恰到好处的步骤,这是你多年的经验总结出来的。但是你对于炒蔬菜和做汁料的处理方法还不是很熟悉。
那么在这个情况下,你可以决定冻结(保持不变)你熟练的牛排煎的步骤,因为你已经能够很好地完成它。你只需要专注于学习和改进炒蔬菜和做汁料的步骤,以充分利用你的努力。
6.选择优化器和学习率:选择一个适当的优化器(如Adam)和学习率。预训练模型的学习率通常较小,因为它已经包含了大量的知识。
备注:优化器和学习率是机器学习中调整模型参数的重要工具。
我们可以将机器学习模型的参数调整过程类比为学生学习的过程。学习过程中,学生需要根据老师的指导不断调整学习策略,使得自己的学习效果越来越好。
优化器就像是学生的学习策略,它决定了如何根据反馈信息来更新模型的参数。不同的优化器有不同的策略,比如一些优化器会根据参数的梯度(导数)大小来调整参数的更新步长,而另一些优化器则会考虑参数的历史更新情况来调整步长。这些策略旨在使模型更好地逼近最优解,就像学生通过不断调整学习策略来提高学习效果一样。
学习率则类似于学生的学习步长,它决定了每次参数更新的幅度。如果学习率很小,那么参数更新的幅度会很小,学习过程会比较稳定但可能会收敛得比较慢;如果学习率很大,那么参数更新的幅度会很大,学习过程可能会比较震荡但可能会收敛得较快。选择合适的学习率可以帮助模型更快地找到最优解,就像选择合适的学习步长可以帮助学生更快地掌握知识一样。
7.进行微调训练:利用准备好的数据和定义好的设置,开始模型的训练。迭代多个周期,直到在验证集上表现良好。
8.评估模型性能:使用测试集来评估fine-tuned模型的性能。查看模型在任务上的表现,并根据需要进行调整。
备注:评估模型性能就好比是给学生考试一样,我们想知道学生掌握知识的程度。在考试中,我们通过评估学生的答题情况来得出一个分数,这个分数反映了学生在掌握知识方面的能力。
五、大模型微调开源项目
作者后来将各种大模型的高效微调,统一到了一个项目里:https://github.com/hiyouga/LLaMA-Factory(opens new window)
截止2023年10月29日,已经支持微调的模型型号有:
5.1 ChatGLM大模型微调
- 项目简介:基于PEFT的高效ChatGLM微调,兼容ChatGLM与ChatGLM-2模型,支持 Full Tuning、LoRA、P-Tuning V2、Freeze等微调方式。
- 备注:关于这些微调方式,我来给你通俗易懂地解释一下:
1.Full Tuning (全参数微调)︰就像你重新学习一门课程一样,这种微调方式会重新调整模型中所有参数,让模型在新的任务上学习适应最佳的参数配置。这样可以让模型更好地适应新的数据和任务,但可能需要花费更多的时间和计算资源。
2.LoRA (Layer-wise Relevance Adaption,逐层相关性适应)︰这种微调方式是针对特定层次的调整,就好比给身体的不同部位做不同的锻炼一样。通过逐层调整,模型可以更灵活地适应新的任务,而不是一刀切地调整所有参数。
3.P-Tuning v2:这是谷歌提出的一种参数微调方法,它使用了预训练的大型语言模型来进行微调,以适应特定的应用场景。这种方式类似于在预训练的基础上进行精细化调整,以获得更好的性能。
4.Freeze(冻结)︰就像冻结时间一样,这种微调方式会保持模型的某些部分不变。在微调时,你可以冻结一些不需要调整的模型参数,集中精力在需要调整的部分上,以节省时间和计算资源,同时保留已有的良好性能。
总的来说,这些微调方式都是为了让模型更好地适应新的任务或数据,但它们的策略和重点略有不同。选择合适的微调方式可以帮助我们更快地实现模型性能的提升,就好比选择合适的训练方式可以让我们更好地提高学习效果一样。
- ChatGLM项目地址:https://github.com/hiyouga/ChatGLM-Efficient-Tuning
5.2 LLaMA大模型微调
- 项目简介:基于PEFT的高效LLaMA微调,兼容LLaMA与 LLaMA-2模型。
- 项目地址: https://github.com/hiyouga/LLaMA-Efficient-Tuning
总结一下,大模型的微调技术的诞生是源于大模型进行训练的成本,因为训练一次大模型类似以上的ChatGLM大模型微调以及LLaMA大模型微调,训练主机的显存需要20GB以上,一般的公司是承受不起的。
而且数据集比较大,所以训练一次的电费都不小,因此微调技术可以快速实现能力的迁移,这就是Fine-tuning的微调技术,实现个性化Al的应用。
什么是Embedding?
在深度学习的领域,Embedding是连接符号与连续的一座桥梁。它通过将高维离散数据映射到低维连续向量空间,为大模型提供了更好的处理能力。
在这一部分,我们将深入研究Embedding的基本概念、作用以及在深度学习中的广泛应用。
一、向量Embedding与ChatGPT大模型
ChatGPT大模型是OpenAl开发的一种基于Transformer架构的预训练语言模型。它在大规模语料库上进行了训练,可以实现连贯且富有逻辑的对话生成。ChatGPT能够理解上下文,生成自然流畅的回复,并且在多轮对话中保持语境的连贯性。
而对于Embedding技术,那么,什么是向量Embedding?简单地说,向量Embedding是可以表示许多类型数据的数字列表。
向量Embedding非常灵活,包括音频、视频、文本和图像都可以表示为向量Embedding。
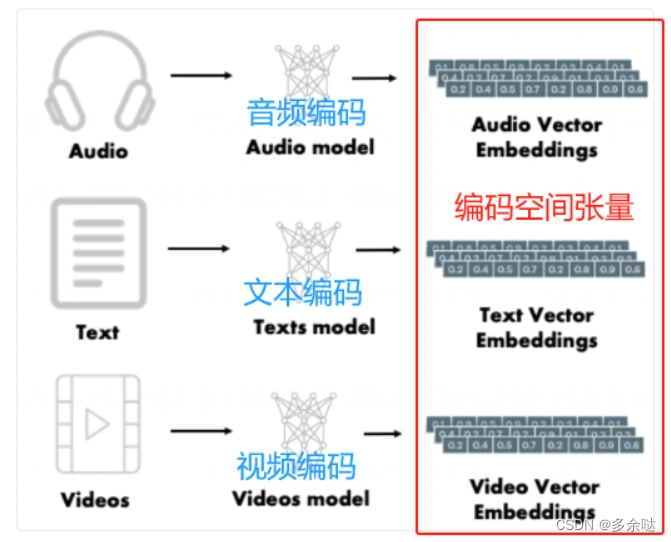
简单来说,苹果,香蕉,橘子这样的数据,是不可能直接进入到神经网络的模型,需要转化为神经网络可以接受的形式。最开始的时候,我们使用的是one-hot编码格式,one-hot编码的原理举一个简单的例子:
考虑书籍类型:"小说”、“非小说"和“"传记"。每一种体裁都可以编码成一个热向量,然而,这样的向量会非常稀疏,因为书籍通常只属于两个体裁。
下图显示了这种编码是如何工作的。注意这里0的数量是1的两倍。对于像图书类型这样的类别,随着更多的类型被添加到数据集中,这种稀疏性将会呈指数级恶化。

稀疏性会给机器学习模型带来挑战。对于每一种新的类型,编码表示的大小都会增长,因此数据集的计算成本会变得很高。
对于图书类型,或者任何具有相对较少类别的分类数据,我们可以使用简单的one-hot编码,但是,对于整个英语语言呢?对于这种规模的语料库,这种编码方法将变得不切实际。因此就进入我们的主题―—向量Embedding
Embedding在 ChatGPT中的应用:
在ChatGPT中,Embedding起到了将输入文本转换为向量表示的作用。当用户输入一段文本时,ChatGPT首先会使用Embedding嵌入层将文本中的词语转换为对应的向量表示,然后输入这些向量表示到模型中进行处理。这样做有助于模型更好地理解语义和上下文,从而生成合理的回复。
二、向量Embedding的优势与原理
向量Embedding呈现固定大小的表示,不随数据中观测值的数量而增长。由模型创建的结果向量,通常是384个浮点值,比其他编码方法(如one-hot编码)的表示密度要高得多。这意味着在更少的字节中存在更多的信息,因此在计算上的利用成本更低。以下是一个Embedding的编码示意原理图。

对于每一个字(实则是字ID)输入到Embedding组件中,输出一个表示该字的向量,如上图,“太"字对应的ID输入,输出为向量[e11,e12,e13,e14]。这个字(词)向量的每一维可以当做是隐含的主题,只不过这些主题并没有明显的现实语义。这就是Embedding的文本编码原理。
三、向量Embedding的实践应用
存在大量的预训练模型,可以很容易地用于创建向量Embedding。Huggingface ModelHub(https://huggingface.co/models)包含许多模型,可以为不同类型的数据创建Embedding。
例如,all-MiniLM-L6-v2模型是在线托管和运行的,不需要专业知识或安装。
像sentence_transformers这样的包,也来自HuggingFace,为语义相似度搜索、视觉搜索等任务提供了易于使用的模型。要使用这些模型创建Embeddings,只需要几行Python代码:
1.安装sentence_transformers编码包

2.执行编码
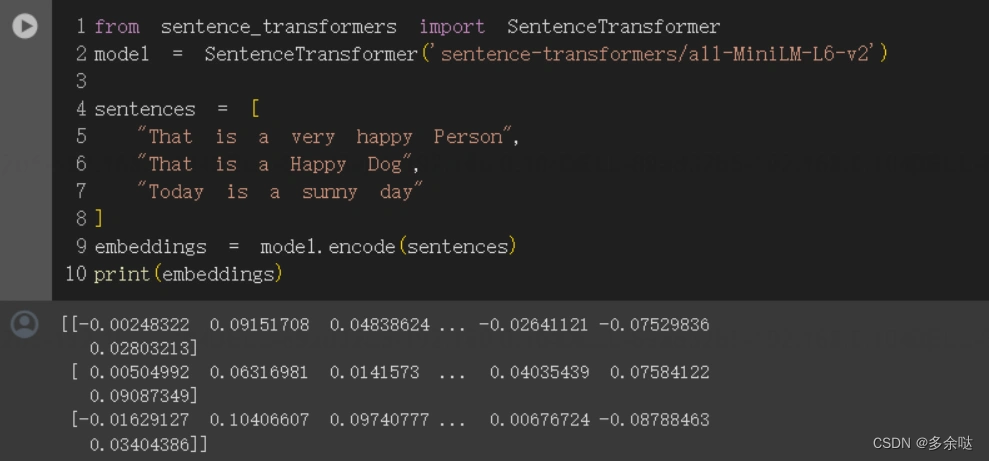
在我们的查询向量和上图中的其他三个向量之间运行这个计算,我们可以确定句子之间的相似程度。
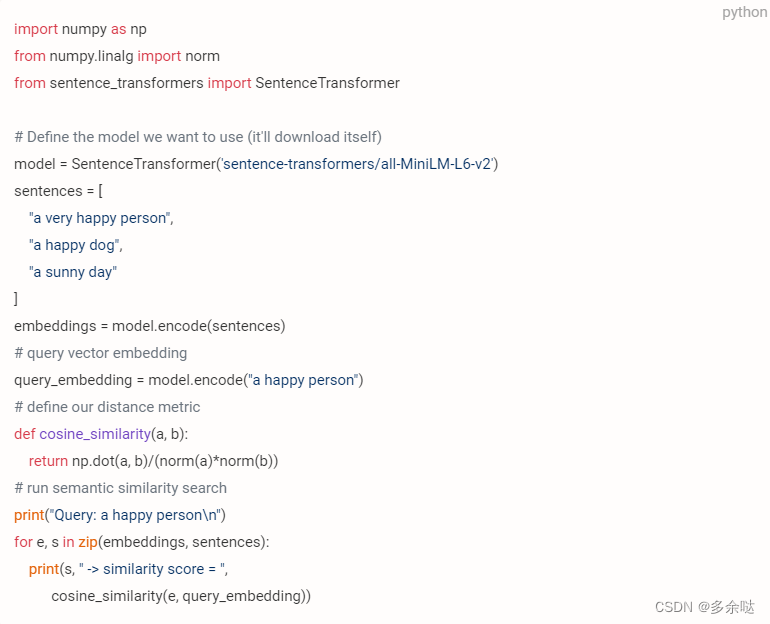
3.测试语义搜索的空间向量的判断

四、Embedding在大模型中的价值
说到Embedding在大模型中的价值,不如我们先说说目前大模型还存在哪些问题?尽管目前GPT-4或者ChatGPT的能力已经很强大,但是目前它依然有很大的缺陷:
1.知识不足或信息丢失
2.训练数据是基于2021年9月之前的数据,缺少最新的数据
3.无法访问私有的文档
4.基于历史会话中获取信息
5.对输入的内容长度有限制
因此,OpenAl发布了这样一篇文档,说明如何使用两步搜索回答来增强GPT的能力:
- 搜索:搜索您的文本库以查找相关的文本部分。
- 请求:将检索到的文本部分插入到发送给GPT的消息中,并向其提出问题。
GPT可以通过两种方式学习知识:
- 通过模型权重(即在训练集上微调模型)
- 通过模型输入(即将知识插入到输入消息中)
尽管微调可能感觉更自然--毕竟,通过数据训练是GPT学习所有其他知识的方式--但OpenAl通常不建议将其作为教授模型知识的方式。微调更适合于教授专业任务或风格,对于事实回忆来说则不太可靠。
测试代码demo:
https://github.com/openai/openai-
cookbook/blob/main/examples/Question_answering_using_embeddings.ipynb
此外,可以在大量文本数据上预训练Embedding,然后在小型数据集上进行微调,这有助于提高语言模型在各种自然语言处理应用程序中的准确性和效率。
五、Embedding让大模型解决长文本的输入
这里我们给一个案例来说明如何用Embedding来让ChatGPT回答超长文本中的问题。
如前所述,大多数大语言模型都无法处理过长的文本。除非是GPT-4-32K,否则大多数模型如ChatGPT的输入都很有限。假设此时你有一个很长的PDF,那么,你该如何让大模型“读懂"这个PDF呢?
首先,你可以基于这个PDF来创建向量embedding,并在数据库中存储(当前已经有一些很不错的向量数据库了,如Pinecone)。
接下来,假设你想问个问题“这个文档中关于xxx是如何讨论的? "。那么,此时你有2个向量embedding了,一个是你的问题embedding,一个是之前PDF的embedding。此时,你应该基于你的问题embedding,去向量数据库中搜索PDF中与问题embedding最相似的embedding。然后,把你的问题embedding和检索的得到的最相似的embedding一起给ChatGPT,然后让ChatGPT来回答。
当然,你也可以针对问题和检索得到的embedding做一些提示工程,来优化ChatGPT的回答。
六、Embedding技术的未来发展
模型的细粒度和多模态性:例如,字符级(Char-level)的嵌入、语义级的嵌入,以及结合图像、声音等多模态信息的嵌入。
更好的理解和利用上下文信息:例如,动态的、可变长度的上下文,以及更复杂的上下文结构。
模型的可解释性和可控制性:这包括模型的内部结构和嵌入空间的理解,以及对模型生成结果的更精细控制。
更大规模的模型和数据:例如,GPT-4、GPT-5等更大规模的预训练模型,以及利用全球范围的互联网文本数据。
什么是Al绘画?
这一讲我们进入到了一个全新的篇章,介绍一下Al绘画和虚拟主播。
什么是Al绘画?
Al绘画,是一种运用人工智能技术生成或辅助创作艺术作品的方法。近年来,随着深度学习和神经网络技术的飞速发展,Al绘画逐渐成为艺术和科技结合的一个新兴领域。
目前主流的Al绘画形式有两种:
第一种是文生图的形式,也就是通过文字描述(prompts),生成对应的Al图画作品。
另一种是图生图的形式,也就是通过上传的照片,生成对应的Al图画作品。
在全球市场上,活跃的Al绘画平台很多,我来列出几个比较有代表性的平台:
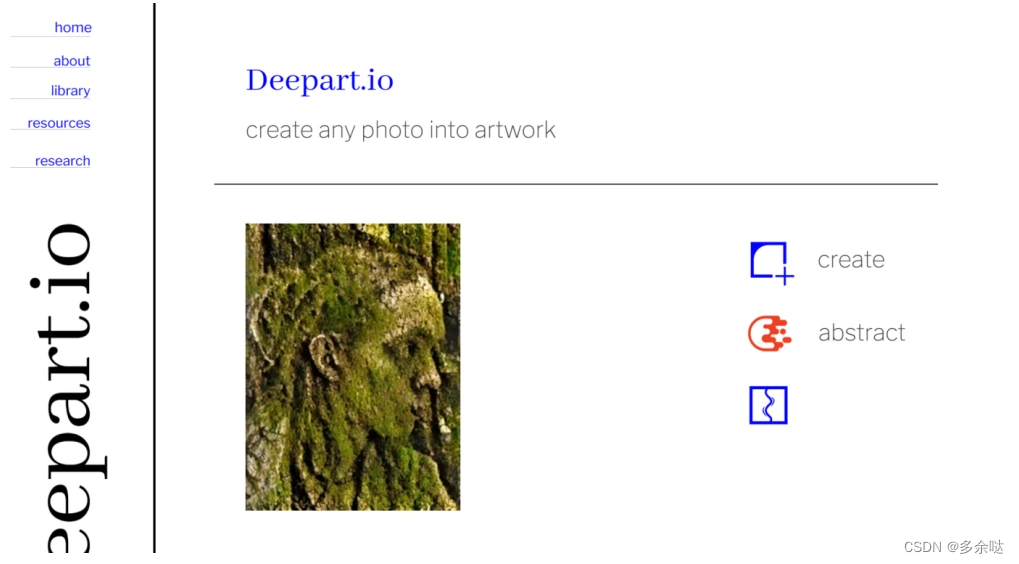
1.DeepArt.io
这是一个基于深度学习技术的在线Al绘画平台,用户可以上传自己的照片,选择一种艺术风格,然后由平台生成具有该风格的独特艺术作品。
2.DALL-E3
DALL-E系列是基于生成对抗网络技术的图像生成模型,能根据用户输入的文本描述生成相应的图像,具有很高的创意潜力。DALL-E系列与ChatGPT是一样,都是由openAl公司开发的产品。

3.MidJourney
Midjourney是一款2022年初问世的Al制图工具,搭载在Discord社区。只要输入绘画关键字,就能透过Al算法快速生成相对应的图片,只需要不到一分钟。

4.Stable Diffusion Online
Stable Diffusion是一个强大且高效的文本-图像扩散模型,能够根据任何文本输入生成逼真的照片级图像。该模型在2022年8月一经推出,就轰动了业界。
最近,Stable Diffusion也推出了自己的线上Al绘画平台,Stable Diffusion Online。
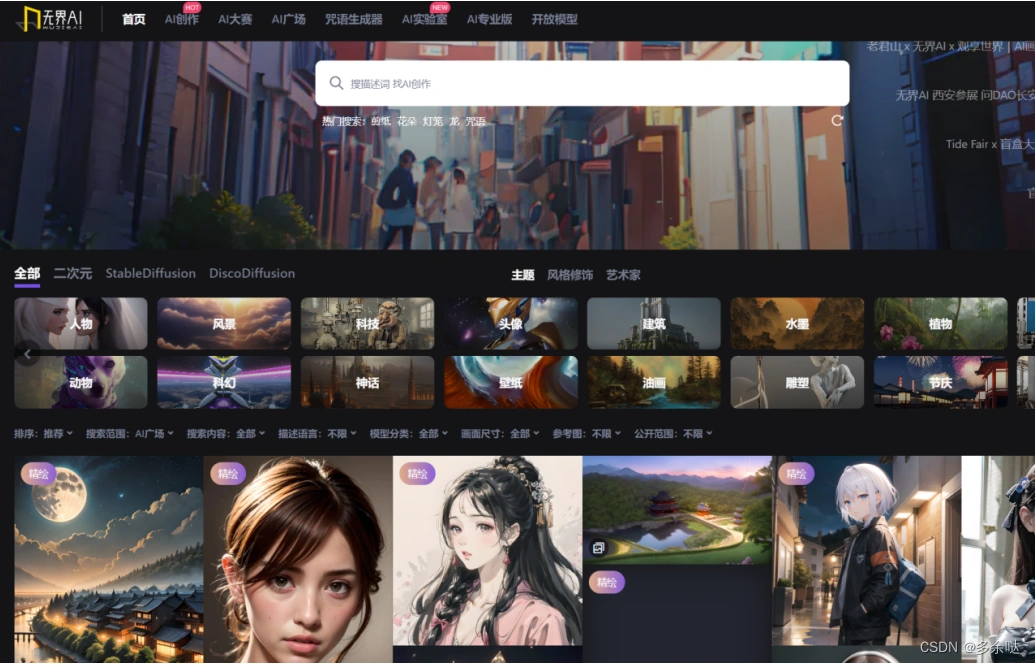
5.无界Al
无界Al是一款国产Al绘画工具,该平台原名“无界版图”,非常适合二次元绘画。
 6.文心一格
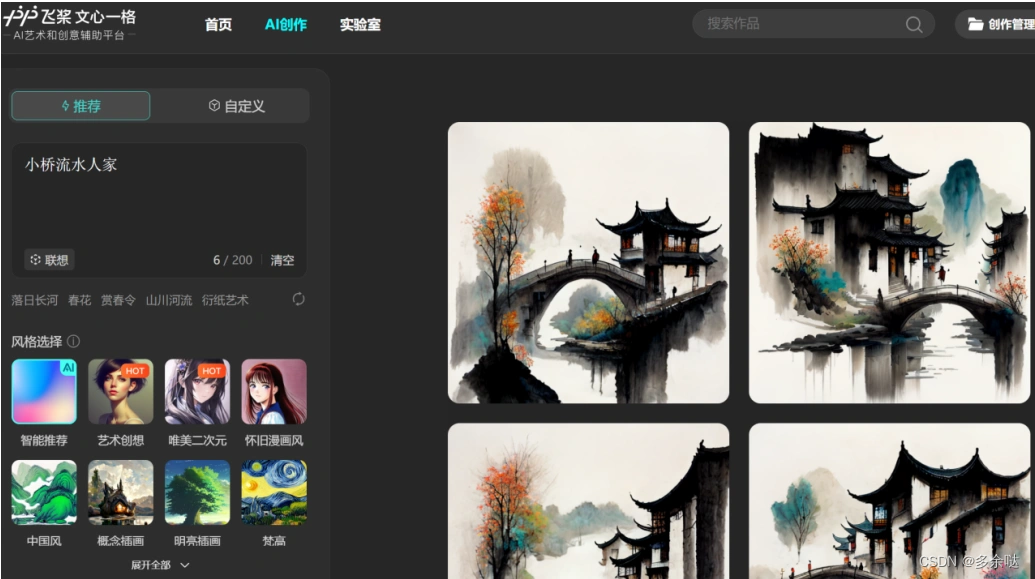
6.文心一格
文心一格是百度旗下的Al绘画平台,基于文心大模型的文生图系统实现,非常适合画中国风的作品。
面对这么多绘画平台,新手应该如何做出选择呢?建议新手首选MidJourney平台,不但强大,而且不难上手。
MidJourney平台的网址是https://www.midjourney.com。
要访问MidJourney平台,首先要注册Discord社区账号,然后用Discord账号登录进MidJourney。
进入平台主页面,我们选择一个频道,或者创建自己的独立服务器,就可以与MidJourney机器人进行对话了∶
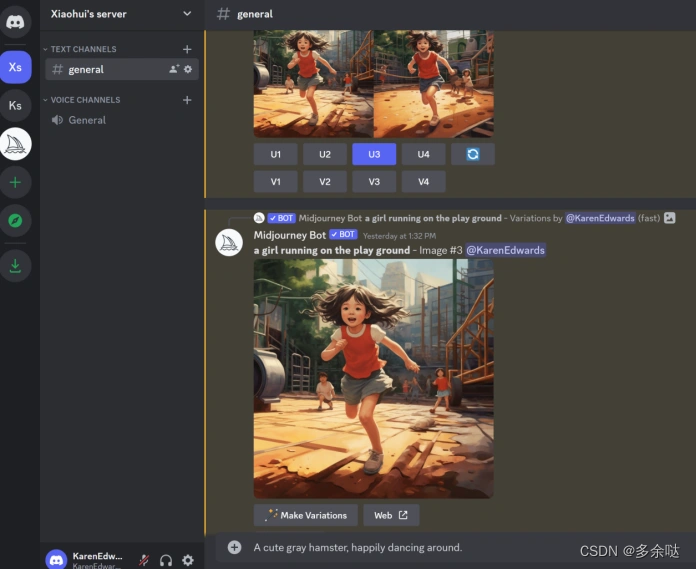
我们来尝试一个提示词: A cute gray hamster, happily dancing around.(一只可爱的灰色小仓鼠,正在开心地跳舞)
输出结果如下:

