
- 1Python提取高频词作为话题词_python词汇话题聚类
- 2软件测试人员如何筛选目标公司?_软件测试想找甲方在哪投简历呢
- 3下载vue.js devt-tool失败,解决方案_devtools下载地址打不开
- 4python实现简单的模拟发送短信验证码_python 伪发送验证码
- 5Hive默认分隔符介绍
- 6Android中获取手机的IMEI_getimei oncompletelistener
- 7Mac免费软件下载网站推荐(最全免费,替代MacWk)_mac软件下载网站推荐
- 8R3Live系列学习(一)Loam-Livox源码阅读_r3live livox
- 9还不快收藏起来!何恺明全网最全论文合集_何恺明resnet论文
- 10AI论文速读 |【Mambda×时序预测】 时光机(TimeMachine):A Time Series is Worth 4 Mambas for Long-term Forecasting_timemachine: a time series is worth 4 mambas for l
Stable Diffusion XL(未待完续)
赞
踩
模型介绍
Stable Diffusion XL 是一种基于人工智能的图像生成模型,由Stability AI开发。它是Stable Diffusion系列模型中的一员,专门设计用来生成更高质量的图像。这个模型在原有的Stable Diffusion模型的基础上进行了扩展和改进,以支持更大的输出图像尺寸和更细致的图像细节。
先发布Stable Diffusion XL 0.9测试版本,基于用户的使用体验和图片生成的反馈情况,针对性增加数据集和使用RLHF(Reinforcement Learning from Human Feedback,基于人类反馈的强化学习)技术优化训练后,推出了Stable Diffusion XL 1.0正式版。
比起Stable Diffusion 1.x-2.x,Stable Diffusion XL的参数量增加到了66亿(Base模型35亿+Refiner模型31亿),并且先后发布了模型结构完全相同的0.9和1.0两个版本。Stable Diffusion XL 1.0在0.9版本上使用更多训练集+RLHF来优化生成图像的色彩、对比度、光线以及阴影方面,使得生成图像的构图比0.9版本更加鲜明准确。
模型结构
Stable Diffusion XL是一个二阶段的级联扩散模型(Latent Diffusion Model),包括Base模型和Refiner模型。其中Base模型的主要工作和Stable Diffusion 1.x-2.x一致,具备文生图(txt2img)、图生图(img2img)、图像inpainting等能力。在Base模型之后,级联了Refiner模型,对Base模型生成的图像Latent特征进行精细化提升,其本质上是在做图生图的工作。
SDXL Base模型由U-Net、VAE以及CLIP Text Encoder(两个)三个模块组成,SDXL Refiner模型同样由U-Net、VAE和CLIP Text Encoder(一个)三个模块组成。
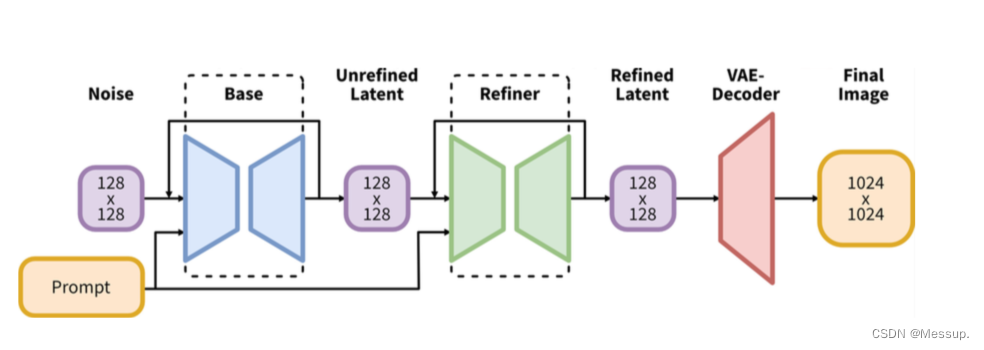
SDXL网络结构图
VAE模型
VAE模型(变分自编码器,Variational Auto-Encoder)是一个经典的生成式模型,具有简洁稳定的Encoder-Decoder架构,以及能够高效提取数据Latent特征和Latent特征像素级重建的关键能力。
当输入是图片时,Stable Diffusion XL和Stable Diffusion一样,首先会使用VAE的Encoder结构将输入图像转换为Latent特征,然后U-Net不断对Latent特征进行优化,最后使用VAE的Decoder结构将Latent特征重建出像素级图像。除了提取Latent特征和图像的像素级重建外,VAE还可以改进生成图像中的高频细节,小物体特征和整体图像色彩。
当Stable Diffusion XL的输入是文字时,这时我们不需要VAE的Encoder结构,只需要Decoder进行图像重建。VAE的灵活运用,让Stable Diffusion系列增添了几分优雅。
SDXL VAE Encoder部分包含了三个DownBlock模块、一个ResNetBlock模块以及一个MidBlock模块,将输入图像压缩到Latent空间,转换成为Gaussian Distribution。
而VAE Decoder部分正好相反,其输入Latent空间特征,并重建成为像素级图像作为输出。其包含了三个UpBlock模块、一个ResNetBlock模块以及一个MidBlock模块。
在损失函数方面,使用了久经考验的生成领域“交叉熵”—感知损失(perceptual loss)以及L1回归损失来约束VAE的训练过程。
原生Stable Diffusion XL VAE采用FP16精度时会出现数值溢出成NaNs的情况,导致重建的图像是一个黑图,所以必须使用FP32精度进行推理重建。
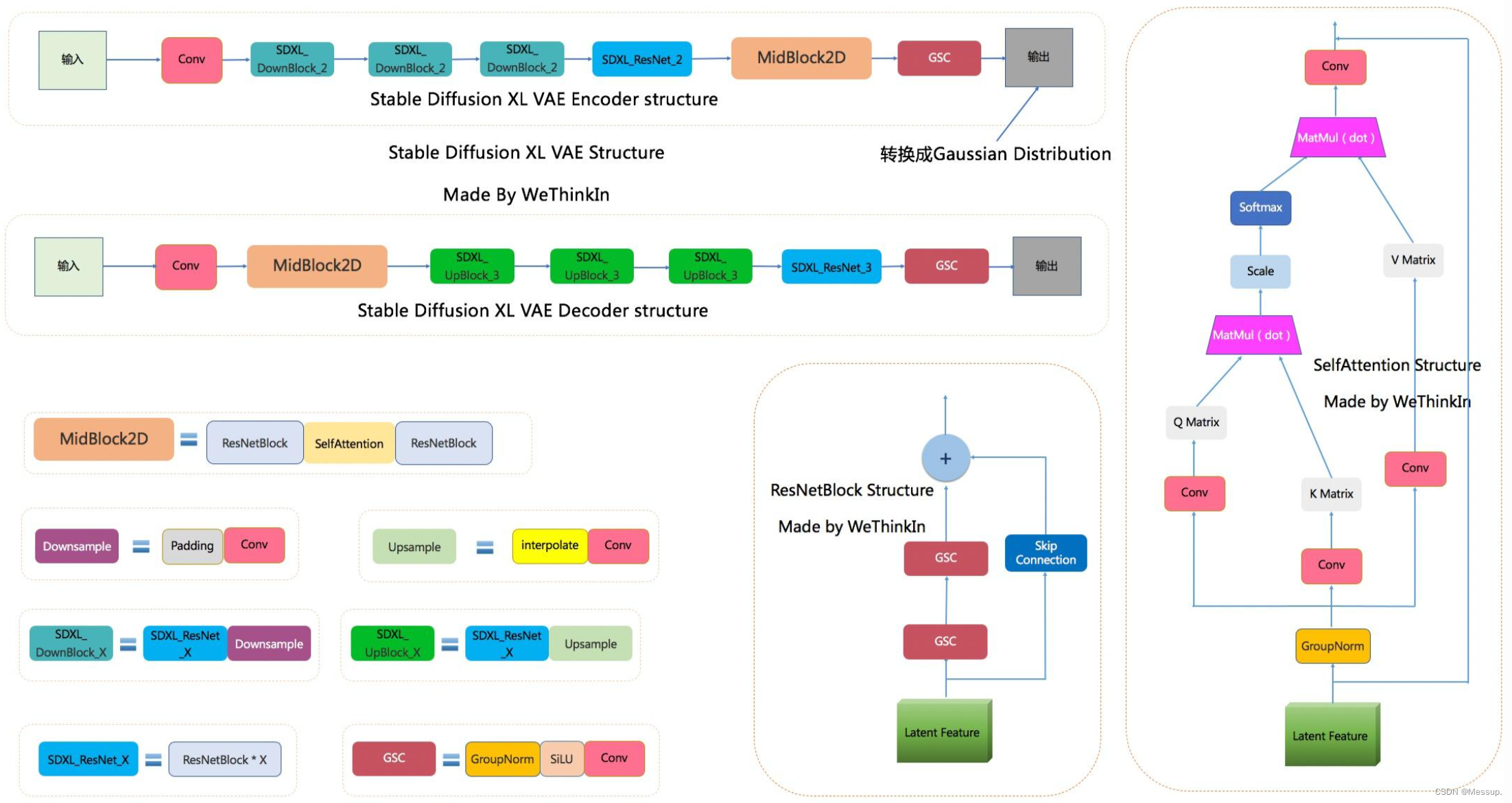
SDXL VAE结构图
U-Net
Stable Diffusion XL中的Text Condition信息由两个Text Encoder提供(OpenCLIP ViT-bigG和OpenAI CLIP ViT-L),通过Cross Attention组件嵌入,作为K Matrix和V Matrix。与此同时,图片的Latent Feature作为Q Matrix。
但是大家知道Text Condition是三维的,而Latent Feature是四维的,那它们是怎么进行Attention机制的呢?
其实在每次进行Attention机制前,我们需要将Latent Feature从[batch_size,channels,height,width]转换到[batch_size,height*width,channels] ,这样就变成了三维特征,就能够和Text Condition做CrossAttention操作。
Text Condition如何跟latent Feature大小保持一致呢?因为latent embedding不同位置的H和W是不一样的,但是Text Condition是从文本中提取的,其H和W是固定的。这里在CorssAttention模块中有一个非常巧妙的点,那就是在不同特征做Attention操作前,使用Linear层将不同的特征的尺寸大小对齐。
Text Encoder
Stable Diffusion XL与之前的系列相比使用了两个CLIP Text Encoder,分别是OpenCLIP ViT-bigG(694M)和OpenAI CLIP ViT-L/14(123.65M),从而大大增强了Stable Diffusion XL对文本的提取和理解能力,同时提高了输入文本和生成图片的一致性。
Refiner模型
Refiner模型和Base模型一样是基于Latent的扩散模型,也采用了Encoder-Decoder结构,和U-Net兼容同一个VAE模型。不过在Text Encoder部分,Refiner模型只使用了OpenCLIP ViT-bigG的Text Encoder,同样提取了倒数第二层特征以及进行了pooled text embedding的嵌入。
Refiner模型主要做了图像生成图像(img2img)的工作,其具备很强的迁移兼容能力,可以作为Stable Diffusion、Midjourney、DALL-E、GAN、VAE等生成式模型的级联组件,成为AI绘画领域的一个强力后处理工具。
模型训练
图像尺寸条件化
Stable Diffusion XL为了在解决数据集利用率问题的同时不引入噪声伪影,将U-Net(Base)模型与原始图像分辨率相关联,核心思想是将输入图像的原始高度和宽度作为额外的条件嵌入U-Net模型中,表示为 声明:本文内容由网友自发贡献,转载请注明出处:【wpsshop博客】
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

