
- 1SpringBoot集成WebSocket,实现后台向前端推送信息_springboot整合websocket推送
- 2使用Jenkins制作镜像并上传到Harbor仓库!_jenkins如何构建镜像推送到harbor
- 3显示闰年_6、编写程序,显示从101到2100期间所有的闰年,每行显示10个。数字之间分隔开,同时
- 4粒子滤波在机器人视觉中的应用_粒子滤波算法pytorch
- 5测试计划模板——Test Plan(中英文)_easymesh testplan中文版
- 6计算机毕业设计课题题目列表信息_计算机课题项目 列表
- 7SpringBoot3.0.0-SNAPSHOT与swagger3不兼容问题解决_swagger 3.0.0不支持spring3.0.0
- 8Flink性能优化指南_flink调优指南
- 9Hbase数据库完全分布式搭建以及java中操作Hbase_hbase 开发:使用java操作hbase
- 10关于HSL和HSV颜色空间的详细论述
[zz]浅谈自然语言处理(NLP)和 自然语言理解(NLU)_知乎 自然语言理解
赞
踩
自然语言处理主要步骤包括:
1. 分词(只针对中文,英文等西方字母语言已经用空格做好分词了):将文章按词组分开
2. 词法分析:对于英文,有词头、词根、词尾的拆分,名词、动词、形容词、副词、介词的定性,多种词意的选择。比如DIAMOND,有菱形、棒球场、钻石3个含义,要根据应用选择正确的意思。
3. 语法分析:通过语法树或其他算法,分析主语、谓语、宾语、定语、状语、补语等句子元素。
4. 语义分析:通过选择词的正确含义,在正确句法的指导下,将句子的正确含义表达出来。方法主要有语义文法、格文法。
但是以上的分析,仅适用于小规模的实验室研究,远不能应用到实际语言环境中,比如说语法,我们能总结出的语法是有限的,可是日常应用的句子,绝大部分是不遵守语法的,如果让语法包罗所有可能的应用,会出现爆炸的景象。
自然语言处理的应用方向主要有:
1. 文本分类和聚类:主要是将文本按照关键字词做出统计,建造一个索引库,这样当有关键字词查询时,可以根据索引库快速地找到需要的内容。此方向是搜索引擎的基础,在早期的搜索引擎,比如北大开发的“天问系统”,采用这种先搜集资料、在后台做索引、在前台提供搜索查询服务。目前GOOGLE,百度的搜索引擎仍旧类似,但是采用了自动“蜘蛛”去采集网络上的信息,自动分类并做索引,然后再提供给用户。我曾经在我的文章中做过测试,当文章中有“十八禁”这样的字眼时,点击次数是我其他文章点击次数的几十倍,说明搜索引擎将“十八禁”这个词列为热门索引,一旦有一个“蜘蛛”发现这个词,其他“蜘蛛”也会爬过来。
2. 信息检索和过滤:这是网络瞬时检查的应用范畴,主要为网警服务,在大流量的信息中寻找关键词,找到了就要做一些其他的判断,比如报警。
3. 信息抽取:(抄书)信息抽取研究旨在为人们提供更有力的信息获取工具,以应对信息爆炸带来的严重挑战。与信息检索不同,信息抽取直接从自然语言文本中抽取事实信息。过去十多年来,信息抽取逐步发展成为自然语言处理领域的一个重要分支,其独特的发展轨迹——通过系统化、大规模地定量评测推动研究向前发展,以及某些成功启示,如部分分析技术的有效性、快速自然语言处理系统开发的必要性,都极大地推动了自然语言处理研究的发展,促进了自然语言处理研究与应用的紧密结合。回顾信息抽取研究的历史,总结信息抽取研究的现状,将有助于这方面研究工作向前发展。
4. 问答系统:目前仍局限于80年代的专家系统,就是按照LISP语言的天然特性,做逻辑递归。LISP语言是括号式的语言,比如A=(B,C,D),A=(B,E,F),提问:已知B,C,能得到什么样的结论?结论是A,D;若提问改为已知B,结论则是C,D,A或E,F,A。比如一个医疗用的专家系统,你若询问“感冒”的治疗方法,系统可能给出多种原因带来的感冒极其治疗方法,你若询问“病毒性感冒”的治疗方法,则系统会给出比较单一的、明确的治疗方法。你有没有用过AUTOCAD系统,这个就是建立在LISP语言上的括号系统,在用的时候会出现上述情况。
5. 拼音汉字转换系统:这应该是中文输入法应用范畴的东西,再多的东西我就没想过。
6. 机器翻译:当前最热门的应用方向,这方面的文章最多。国际上已经有比较好的应用系统,美国有个AIC公司推出过著名的实时翻译系统,欧共体的SYSTRAN系统可以将英、法、德、西、意、葡六种语言实时对译,美、日、德联合开发的自动语音翻译系统,成功进行了10多分钟对话。我国军事科学院、中科院也开发过此类系统。但是这里边的问题也很多,最主要的是“满篇洋文难不住,满篇译文看不懂”,就是脱离了人类智慧的机器翻译,总会搞出让人无法理解的翻译,比如多意词选择哪个意思合适、怎么组织出通顺的语句,等等。所以目前微软、GOOGLE的新趋势是:翻译+记忆,类似机器学习,将大量以往正确的翻译存储下来,通过检索,如果碰到类似的翻译要求,将以往正确的翻译结果拿出来用。GOOGLE宣称今后几年就可以推出商业化的网页翻译系统。
7. 新信息检测:这个我不知道,没思路。
以上已经回答了自然语言发展方向的问题。我认为机器翻译是最有前途的方向,其难点在于机器翻译还不具备人类智能,虽然翻译已经达到90%以上的正确程度,然而还是不能象人类翻译那样,可以准确表达。为什么存在这样的难点?关键是自然语言处理做不到人类对自然语言的理解,“处理”和“理解”是天差地别的两个概念。“处理”好比控制眼睛、耳朵、舌头的神经,他们将接收的信息转化成大脑可以理解的内部信息,或者反过来,他们的功能就是这么多。而“理解”则是大脑皮层负责语言理解那部分,多少亿的脑细胞共同完成的功能。一个人因为其自身家庭背景、受教育程度、接触现实中长期形成的条件反射刺激、特殊的强列刺激、当时的心理状况,这么多的因素都会影响和改变“理解”的功能,比如我说“一个靓女开着BMW跑车”,有人心里会想这是二奶吧?有人心里会仇视她,联想到她会撞了人白撞;做汽车买卖的人则会去估量这部车的价值;爱攀比的人也许会想,我什么时候才能开上BWM?所以“理解”是更加深奥的东西,涉及更多神经学、心理学、逻辑学领域。
还有上下文理解问题,比如这句:“我们90平方米以后会占的分量越来越大,那么这样他的价格本身比高档低很多,所以对于整体把这个价格水平给压下来了,这个确实非常好的。” 你能理解么?估计很难或者理解出多种意思,但是我把前文写出来:“去年国家九部委联合发布了《建设部等部门关于调整住房供应结构稳定住房价格意见的通知》,对90平方米以下住房须占总面积的70%以上作出了硬性规定,深圳市经过一年的调控,目前已做到每个项目的75%都是90平方米以内。深圳市国土资源和房产管理局官员说”看了后面的你才能知道是根据国家的通知,深圳做了相应的调整。
自然语言理解
1. 语义表示
自然语言理解的结果,就是要获得一个语义表示(semantic representation):

语义表示主要有三种方式:
1. 分布语义,Distributional semantics
2. 框架语义,Frame semantics
3. 模型论语义,Model-theoretic semantics
1.1 分布语义表示(Distributional semantics)
说distributional semantics大家比较陌生,但如果说word2vec估计大家都很熟悉,word2vec的vector就是一种distributional semantics。distributional semantics就是把语义表示成一个向量,它的理论基础来自于Harris的分布假设:语义相似的词出现在相似的语境中(Semantically similar words occur in similar contexts)。具体的计算方法有多种,比如LSA(Latent Semantic Analysis)、LDA(Latent Dirichlet Allocation)及各种神经网络模型(如LSTM)等。
这种方法的优点在于,它完全是数据驱动的方法,并且能够很好的表示语义,但一个很大的缺点在于,它的表示结果是一个整体,没有进一步的子结构。
1.2 框架语义表示(Frame semantics)
顾名思义,这种方法把语义用一个frame表示出来,比如我们一开始举得例子:“订一张明天北京去杭州的机票,国航头等舱”,表示如下:

在计算方法上,典型的比如语义角色标注(Semantic Role Labeling),具体可以分为两个步骤:frame identification和argument identification,frame identification用于确定frame的类型,argument identification用于计算各个属性的具体值。这种方法和distributional semantics相比,能够表达丰富的结构。
1.3 模型论语义表示(Model-theoretic semantics)
模型轮语义表示的典型框架是把自然语言映射成逻辑表达式(logic form)。比如对于下图中的“中国面积最大的省份是哪个?”,将其表示成逻辑表达式就是图中红色字体部分,进一步那这个逻辑表达式去知识库中查询,就得到了答案。在计算方法上,典型的就是构建一个semantic parser。

模型论语义表示是对世界知识的完整表示,比前两种方法表达的语义更加完整,但是缺点是semantic parser的构建比较困难,这大大限制了该方法的应用。
1.4 目前采用的语义表示
目前常用的是frame semantics表示的一种变形:采用领域(domain)、意图(intent)和属性槽(slots)来表示语义结果。
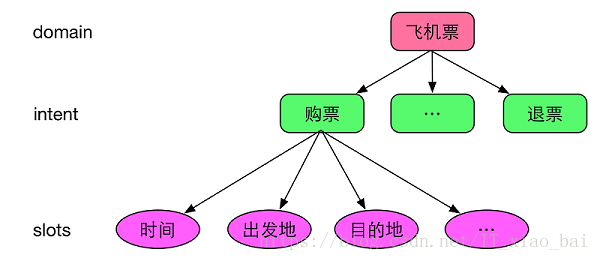
其中,领域是指同一类型的数据或者资源,以及围绕这些数据或资源提供的服务,比如“餐厅”,“酒店”,“飞机票”、“火车票”、“电话黄页”等;意图是指对于领域数据的操作,一般以动宾短语来命名,比如飞机票领域中,有“购票”、“退票”等意图;属性槽用来存放领域的属性,比如飞机票领域有“时间”“出发地”“目的地”等;
对于飞机票领域,我们的语义表示结构如下图所示:
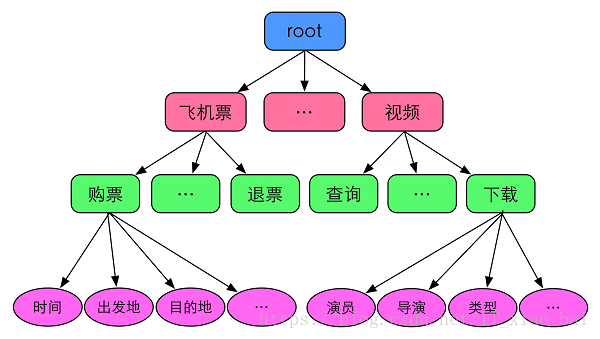
进一步,我们对于世界的语义描述(又称为domain ontology)如下:
2. 自然语言理解技术难点
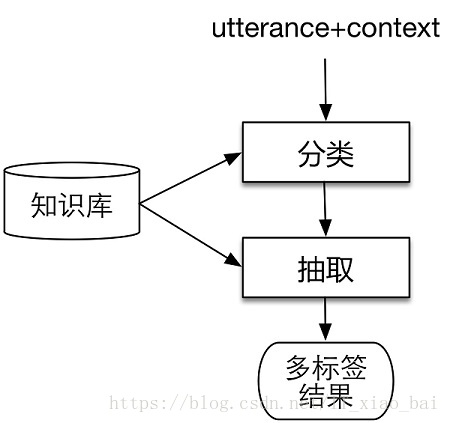
在确定了自然语言理解的语义表示方法后,我们把技术方案抽象为如下两步:
这和前文提到的语义角色标注把过程分为frame identification和argument identification类似,领域分类和意图分类对应frame identification,属性抽取对应argument identification。无论对于分类还是对于抽取来说,都需要有外部知识的支持。在实现的过程中,我们面临着如下的困难:
(1)如何构建知识库
“总参”除了表示总参谋部外,还是南京一家很火的火锅店;“中华冷面”除了是一种面条,还是一首歌名;“王菲的红豆”是指王菲唱的红豆这首歌,但如果说“韩红的红豆”就不对了,因为韩红没有唱过红豆这首歌。要想把这些知识都理解对,就需要一个庞大的知识库,这个知识库中的实体词数以千万计,怎么挖掘,怎么清洗噪音,都是很大的挑战。
(2)如何理解用户语句的意图
“东三环堵吗”这句话意图是查询路况,“下水道堵吗”就不是查路况了;“今天的天气”是想问天气状况,“今天的天气不错”则无此意;“附近哪儿可以喝咖啡”是想找咖啡馆,但“牛皮癣能喝咖啡吗”就是一个知识问答了。类似上述的例子举不胜举,更别说语言理解还受时间、位置、设备、语境等等问题的影响。
(3)如何构建可扩展的算法框架
现实世界包含众多的领域,而我们不可能一次性的把所有领域都定义清楚并且实现之,那我们就需要一个可扩展的算法框架,每当修改或者新增某个领域的时候,不会对其他领域造成干扰。
(4)如何构建数据驱动的计算流程
大数据时代,如果一个算法或者流程不是数据驱动的,不是随着数据的增加而自动提升效果,那这个算法框架就没有持续的生命力。
(5)如何融入上下文知识
在对话场景中,每句话都有对话上下文,同样的句子在不同的上下文中理解结果是不一样的,比如如下的例子,同样的一句话“今天天气好吗”在左侧图中属于天气领域,而在右侧图中则属于音乐领域。
————————————————
版权声明:本文为CSDN博主「IT_xiao_bai」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/IT_xiao_bai/article/details/81180513

