
- 1C语言字符集, 标识符与关键字_c语言字符大全
- 2pnpm实战教程_pnpm link
- 3星火大模型如何升级应对:一场AI巨头间的技术较量与未来展望
- 4go 针对 time类型字段,前端查询,后端返回数据格式为UTC时间
- 5【Hive】split函数(分割字符串)_hive split
- 6Llama 3 五一超级课堂 笔记 ==> 第二节、Llama 3 微调个人小助手认知(XTuner 版)
- 7HSRP配置案例_preempt delay minimum 120 reload 120
- 8java表格树_智慧树_创新创业能力解析_结课测验答案
- 9作为程序员,外包到底值不值得去呢
- 10git语言包安装_TortoiseGit的安装及使用
数据仓库基本概念_数据仓库概念
赞
踩
什么是数据仓库?
数据仓库,英文名称为Data Warehouse,数据仓库(Data Warehouse)是一个面向主题的(Subject Oriented)、集成的(Integrated)、相对稳定的(Non-Volatile)、反映历史变化(Time Variant)的数据集合,用于支持管理决策(Decision Making Support)。 ——比尔·恩门(Bill Inmon)在1991年出版的“Building the Data Warehouse”(《建立数据仓库》)
数据仓库的特点
- 主题性:数据仓库是针对某个主题来进行组织,比如滴滴出行,司机行为分析就是一个主题,所以可以将多种不同的数据源进行整合。而传统的数据库主要针对某个项目而言,数据相对分散和孤立。
- 集成性:数据仓库需要将多个数据源的数据存到一起,但是这些数据以前的存储方式不同,所以需要经过抽取、清洗、转换的过程
- 稳定性:保存的数据是一系列历史快照,不允许修改,只能分析。
- 时变性:会定期接收到新的数据,反应出最新的数据变化。
数据仓库架构
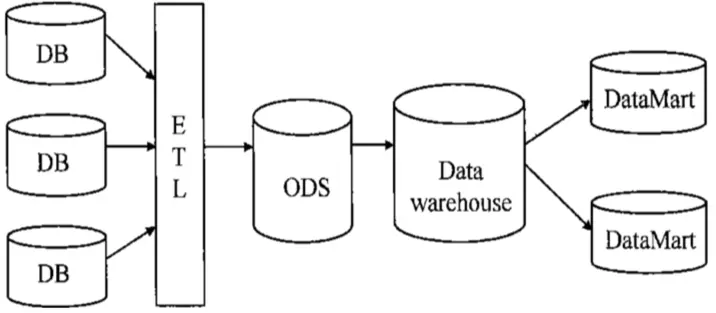

- DB:源系统数据库,如mysql、oracle、mongodb等数据库
- ETL: 抽取(extract)、交互转换(transform)、加载(load)的过程。实现方式可以是编写程序或kettle等工具
- ODS(Operation Data Store):操作型数据仓库。存储各大业务型数据库ETL后的数据,存放原始数据,直接加载原始日志、数据,数据保持原貌不做处理,目的是数据集中。
- DW(Data Warehouse):即数据仓库。
- DM(Data Mart):数据集市层。以具体某个业务应用为出发点而建设的局部dw,dw只关心自己需要的数据,不会全盘考虑企业整体的数据架构和应用。
OLAP和OLTP的区别
OLTP是传统的关系型数据库的主要应用,主要是基本的、日常的事务处理,例如银行交易。OLAP是数据仓库系统的主要应用,支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果。
OLTP 系统强调数据库内存效率,强调内存各种指标的命令率,强调绑定变量,强调并发操作;
OLAP 系统则强调数据分析,强调SQL执行市场,强调磁盘I/O,强调分区等
| 联机事务处理OLTP | 联机分析处理OLAP | |
| 用户 | 操作人员、低层管理人员 | 决策人员、高级管理人员 |
| 功能 | 简单的事务、日常操作处理 | 复杂查询、分析决策 |
| DB设计 | 面向应用、业务的数据库 | 面向主题、分析的数据仓库 |
| 数据 | 读/写数十条记录 | 读上百万条记录 |
| 实效性 | 实时性 | 对实效性要求不严格 |
| 应用 | 数据库 | 数据仓库 |
其他概念
事实:是数据仓库中的信息单元,也是多维空间中的一个单元,受分析单元的限制。事实存储于一张表中(当使用关系数据库时)或者是多维数据库中的一个单元。每个事实包括关于事实(销售额,销售量,成本,毛利,毛利率等)的基本信息,并且与维度相关。在某些情况下,当所有的必要信息都存储于维度中时,单纯的事实出现就是对于数据仓库足够的信息。
数据仓库中都会包括一个或多个事实数据表,包含在事实表中的“度量值”有两种,一种是可以累计的度量值,另一种是非累计的度量值。
从用途的不同来说,事实表可以分为三类,分别是事务事实、周期快照、累计快照。
维度:是人们观察数据的特定角度,是考虑问题时的一类属性,属性集合构成一个维,通常有日期、地区等维度。
切片:一种用来在数据仓库中将一个维度中的分析空间限制为数据子集的技术。
切块:一种用来在数据仓库中将多个维度中的分析空间限制为数据子集的技术。
星型模式:是数据仓库应用程序的最佳设计模式。它的命名是因其在物理上表现为中心实体,典型内容包括指标数据、辐射数据,通常是有助于浏览和聚集指标数据的维度。星形图模型得到的结果常常是查询式数据结构,能够为快速响应用户的查询要求提供最优的数据结构。星形图还常常产生一种包含维度数据和指标数据的两层模型。
雪花模式:指一种扩展的星形图。星形图通常生成一个两层结构,即只有维度和指标,雪花图生成了附加层。实际数据仓库系统建设过程中,通常只扩展三层:维度(维度实体)、指标(指标实体)和相关的描述数据(类目细节实体);超过三层的雪花图模型在数据仓库系统中应该避免。因为它们开始像更倾向于支持OLTP 应用程序的规格化结构,而不是为数据仓库和OLAP应用程序而优化的非格式化结构。
粒度:粒度将直接决定所构建仓库系统能够提供决策支持的细节级别。粒度越高表示仓库中的数据较粗,反之,较细。粒度是与具体指标相关的,具体表现在描述此指标的某些可分层次维的维值上。例如,时间维度,时间可以分成年、季、月、周、日等。
数据仓库模型中所存储的数据的粒度将对信息系统的多方面产生影响。事实表中以各种维度的什么层次作为最细粒度,将决定存储的数据能否满足信息分析的功能需求,而粒度的层次划分、以及聚合表中粒度的选择将直接影响查询的响应时间。
度量值:在多维数据集中,度量值是一组值,这些值基于多维数据集的事实数据表中的一列,而且通常为数字。此外,度量值是所分析的多维数据集的中心值。即,度量值是最终用户浏览多维数据集时重点查看的数字数据(如销售、毛利、成本)。

