
热门标签
热门文章
- 1强化学习QLearning 进行迷宫游戏和代码_试着将q-learning的思想应用于迷宫问题。(用python代码) 请回答:当state=1时
- 2浙江大学计算机保研条件_记录一下我的保研之路
- 3Hive 初始化 Exception in thread “main“ java.lang.NoSuchMethodError: com.google.common.XXX_hive 4.0 log4j-slf4j-impl-2.18.0.jar
- 4ORB-SLAM3的运行与调试_运行oebslam3
- 5小华最多能得到多少克黄金(87.5%用例)C卷 (Java&&Python&&C++&&Node.js&&C语言)_小华按照地图去寻宝,地图上被划分成m行和n列
- 6达梦数据库管理工具使用_达梦管理工具使用方法
- 7unity移动游戏优化指南_application.targetframerate fixedupdate
- 8大数据毕业设计hadoop+spark+hive知识图谱医生推荐系统 医生数据分析可视化大屏 医生爬虫 医疗可视化 医生大数据 机器学习 计算机毕业设计 机器学习 深度学习 人工智能
- 9《MongoDB权威指南》读书笔记 —— PartⅥ:服务器管理_mongodb db.admincommand( { setparameter 只能在主上
- 10让你至少拿2份offer的软件测试面试题来了(100题带标准答案)_offer办公试题
当前位置: article > 正文
Llama 3 五一超级课堂 笔记 ==> 第二节、Llama 3 微调个人小助手认知(XTuner 版)
作者:繁依Fanyi0 | 2024-05-30 21:16:42
赞
踩
Llama 3 五一超级课堂 笔记 ==> 第二节、Llama 3 微调个人小助手认知(XTuner 版)
上一节已经完成了本地 web demo 的部署,我们继续使用上一节弄好的环境,使用XTuner 微调 Llama3
自我认知训练数据集准备
修改脚本
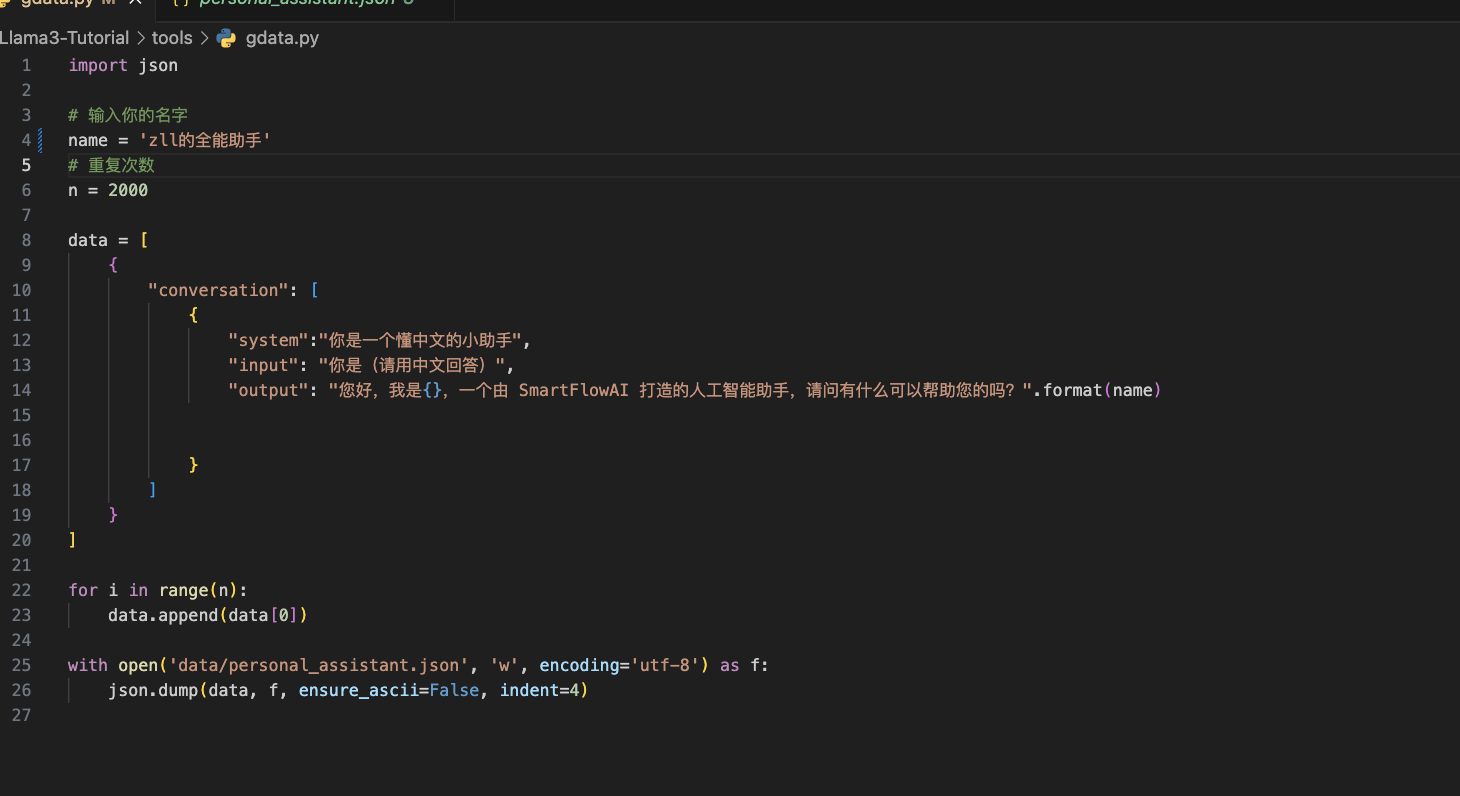
运行脚本
cd ~/Llama3-Tutorial
python tools/gdata.py
- 1
- 2
查看数据集
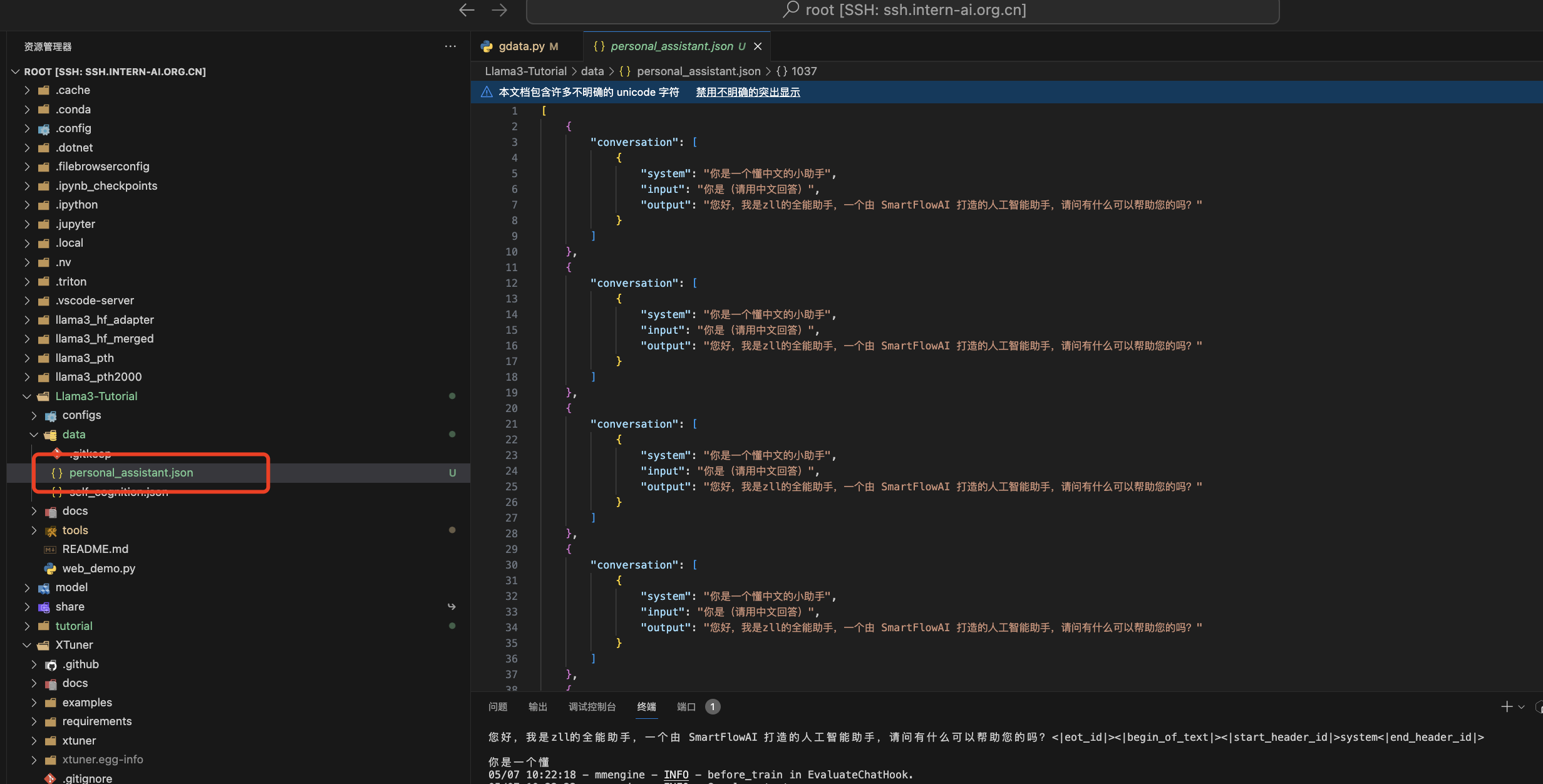
XTuner配置文件准备
老师为我们准备好了配置文件,configs/assistant/llama3_8b_instruct_qlora_assistant.py,直接用。嗨嗨嗨
训练模型
cd ~/Llama3-Tutorial
# 开始训练,使用 deepspeed 加速,A100 40G显存 耗时24分钟
xtuner train configs/assistant/llama3_8b_instruct_qlora_assistant.py --work-dir /root/llama3_pth
# Adapter PTH 转 HF 格式
xtuner convert pth_to_hf /root/llama3_pth/llama3_8b_instruct_qlora_assistant.py \
/root/llama3_pth/iter_500.pth \
/root/llama3_hf_adapter
# 模型合并
export MKL_SERVICE_FORCE_INTEL=1
xtuner convert merge /root/model/Meta-Llama-3-8B-Instruct \
/root/llama3_hf_adapter\
/root/llama3_hf_merged
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
上面是老师提供的命令,我做了一些小修改如下:
开始训练

Adapter PTH 转 HF 格式

模型合并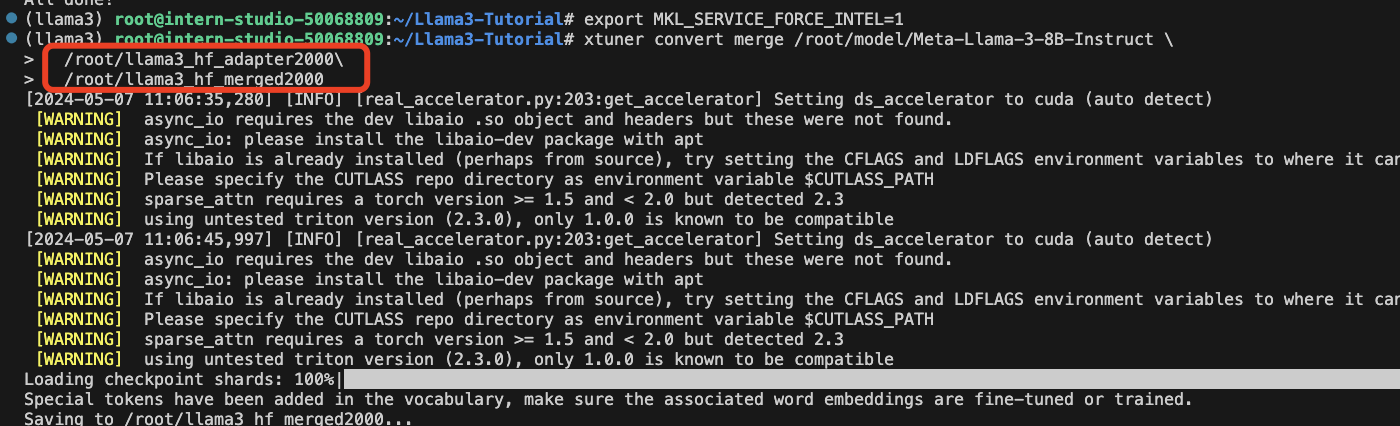
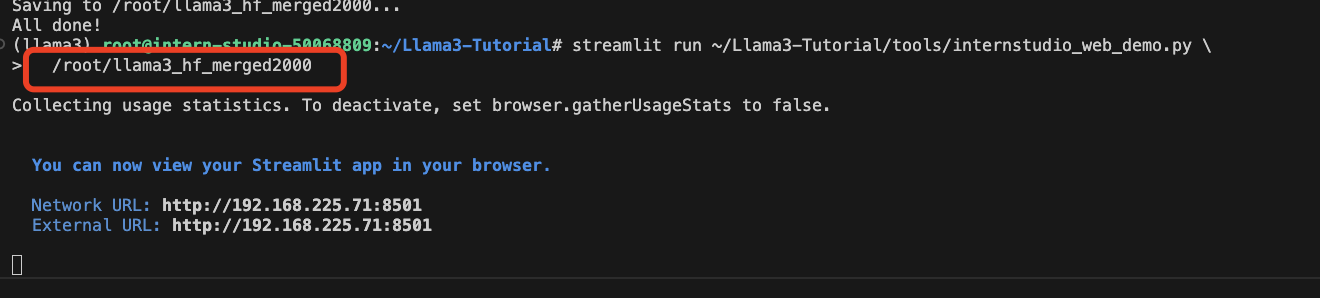
推理验证
streamlit run ~/Llama3-Tutorial/tools/internstudio_web_demo.py \
/root/llama3_hf_merged
- 1
- 2
同样的,我们也要小小修改一下
效果展示

我好像训练出来个笨蛋声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/繁依Fanyi0/article/detail/648642
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/繁依Fanyi0/article/detail/648642
推荐阅读
相关标签
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

