
热门标签
热门文章
- 1芋道源码 yudao-cloud 文档,开发指南如何看全部,破解_芋道商城文档
- 2git 常用命令大全(附命令注释)_git命令大全,大数据开发外包是如何转正华为的_git常用命令
- 3[油管搬运]PX4基础开发教程_px4飞控开发教程
- 4【算法】前缀和——二维前缀和模板题
- 5华为OD机试Python - 螺旋数字矩阵_疫情期间,小明隔离在家,百无聊赖,在纸上写数字玩。他发明了一种写法
- 6python用selenium打开浏览器后秒关闭浏览器的解决办法_selenium和python打开后立马就关闭了
- 7Github Actions 推送代码构建 Docker 镜像并 push 到仓库_github action docker推送
- 8联想小新笔记本外接显示屏HDMI无信号_联想小新hmdd接口的设备不显示
- 9[大数据]二、Hadoop-HDFS
- 10论文导读 | 复杂知识库问答综述:方法,挑战和解决方案_compositional generalization
当前位置: article > 正文
[完]基于Hadoop的数据仓库Hive 基础知识_hadoop 数据仓库
作者:很楠不爱3 | 2024-05-23 22:57:11
赞
踩
hadoop 数据仓库
Hive是基于Hadoop的数据仓库工具,可对存储在HDFS上的文件中的数据集进行数据整理、特殊查询和分析处理,提供了类似于SQL语言的查询语言–HiveQL,可通过HQL语句实现简单的MR统计,Hive将HQL语句转换成MR任务进行执行。
一、概述
1-1 数据仓库概念
数据仓库(Data Warehouse)是一个面向主题的(Subject Oriented)、集成的(Integrated)、相对稳定的(Non-Volatile)、反应历史变化(Time Variant)的数据集合,用于支持管理决策。
数据仓库体系结构通常含四个层次:数据源、数据存储和管理、数据服务、数据应用。
- 数据源:是数据仓库的数据来源,含外部数据、现有业务系统和文档资料等;
- 数据集成:完成数据的抽取、清洗、转换和加载任务,数据源中的数据采用ETL(Extract-Transform-Load)工具以固定的周期加载到数据仓库中。
- 数据存储和管理:此层次主要涉及对数据的存储和管理,含数据仓库、数据集市、数据仓库检测、运行与维护工具和元数据管理等。
- 数据服务:为前端和应用提供数据服务,可直接从数据仓库中获取数据供前端应用使用,也可通过OLAP(OnLine Analytical Processing,联机分析处理)服务器为前端应用提供负责的数据服务。
- 数据应用:此层次直接面向用户,含数据查询工具、自由报表工具、数据分析工具、数据挖掘工具和各类应用系统。
1-2 传统数据仓库的问题
- 无法满足快速增长的海量数据存储需求,传统数据仓库基于关系型数据库,横向扩展性较差,纵向扩展有限。
- 无法处理不同类型的数据,传统数据仓库只能存储结构化数据,企业业务发展,数据源的格式越来越丰富。
- 传统数据仓库建立在关系型数据仓库之上,计算和处理能力不足,当数据量达到TB级后基本无法获得好的性能。
1-3 Hive
Hive是建立在Hadoop之上的数据仓库,由Facebook开发,在某种程度上可以看成是用户编程接口,本身并不存储和处理数据,依赖于HDFS存储数据,依赖MR处理数据。有类SQL语言HiveQL,不完全支持SQL标准,如,不支持更新操作、索引和事务,其子查询和连接操作也存在很多限制。
Hive把HQL语句转换成MR任务后,采用批处理的方式对海量数据进行处理。数据仓库存储的是静态数据,很适合采用MR进行批处理。Hive还提供了一系列对数据进行提取、转换、加载的工具,可以存储、查询和分析存储在HDFS上的数据。
1-4 Hive与Hadoop生态系统中其他组件的关系
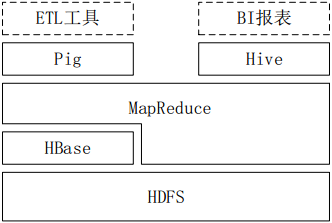
- Hive依赖于HDFS存储数据,依赖MR处理数据;
- Pig可作为Hive的替代工具,是一种数据流语言和运行环境,适合用于在Hadoop平台上查询半结构化数据集,用于与ETL过程的一部分,即将外部数据装载到Hadoop集群中,转换为用户需要的数据格式;
- HBase是一个面向列的、分布式可伸缩的数据库,可提供数据的实时访问功能,而Hive只能处理静态数据,主要是BI报表数据,Hive的初衷是为减少复杂MR应用程序的编写工作,HBase则是为了实现对数据的实时访问。
图 Hadoop生态系统中Hive与其他部分的关系
1-5 Hive与传统数据库的对比
| 对比项 | Hive | 传统数据库 |
|---|---|---|
| 数据插入 | 支持批量导入,不可单条导入 | 支持单挑和批量导入 |
| 数据更新 | 不支持 | 支持 |
| 索引 | 有限索引功能,不像RDBMS有键的概念, 可在某些列上建索引,加速一些查询操作。 创建的索引数据,会被保存在另外的表中 |
支持 |
| 分区 | 支持,Hive表示分区形式进行组织的,根据 “分区列”的值对表进行粗略划分,加快数 据的查询速度 |
支持,提供分区功能来改善大型表以及具有各 种访问模式的表的可伸缩性、可管理性,以及 提高数据库效率 |
| 执行延迟 |
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/很楠不爱3/article/detail/614738
推荐阅读
相关标签

