
热门标签
热门文章
- 1手把手教你从微软官网上下载系统镜像【保持最新版】_微软系统镜像官网
- 2Git小乌龟的安装及简单使用_git小乌龟安装
- 3【纯手撸】使用PySide6 / pyqt 搭建现代化普通B端系统图形化界面_python pyside6 做资源管理器框架界面
- 4408数据结构笔记整理
- 5区块链技术的应用前景及挑战_一个企业如果要实施区块链技术有哪些挑战
- 6arkTS开发鸿蒙OS个人商城案例【2024最新 新年限定开发案例QAQ】_arkts案例
- 7uni-app 微信小程序之自定义navigationBar顶部导航栏_微信小程序自定义顶部导航栏(兼容适配所有机型)
- 8Java stringbuilder与string相互转换_stringbuilder转string
- 9大模型时代,程序员需要具备哪些技能才能胜任?
- 10HDFS 架构剖析_简述hdfs架构
当前位置: article > 正文
下载bert的预训练模型并加载训练教程_bert模型下载
作者:羊村懒王 | 2024-05-28 23:58:52
赞
踩
bert模型下载
下载bert的预训练模型并加载训练
step1: 进入网址 https://huggingface.co 搜索自己需要的模型名(下面以bert-base-uncased 为例)
step2: 在如下的界面中,找到Files and versions,下载如下三个红框中的内容即可。(这里以下载pytorch版的模型为例)
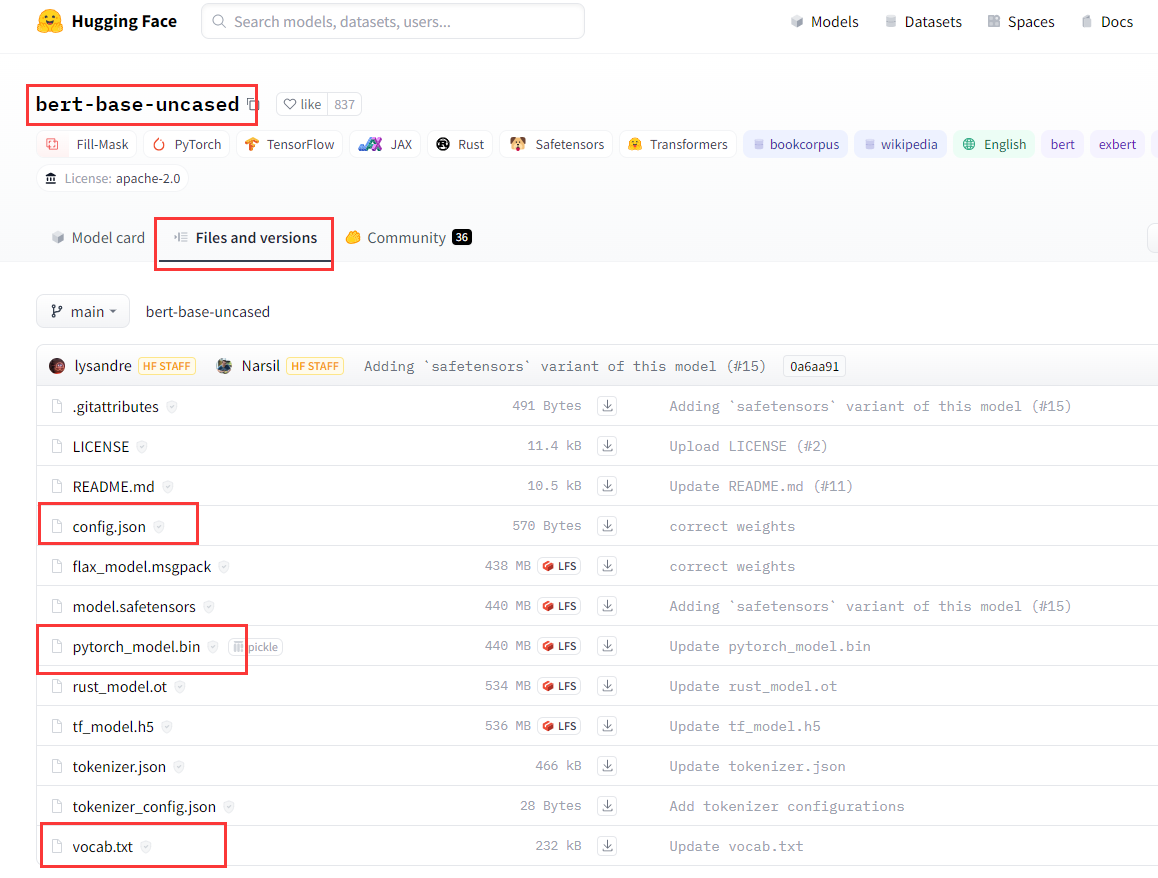
step3: 将上述下载好的内容放到/bert-base-uncased文件夹下。那么就可以在程序中这么用:
from transformers import BertModel, BertTokenizer
# 加载预训练的BERT模型和对应的分词器
model_name = 'bert-base-uncased'
tokenizer = BertTokenizer.from_pretrained(model_name)
model = BertModel.from_pretrained(model_name)
# 使用模型和分词器进行文本处理和编码
text = "Hello, how are you?"
tokens = tokenizer.tokenize(text)
input_ids = tokenizer.convert_tokens_to_ids(tokens)
print(tokens)
print(input_ids)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
输出:
['hello', ',', 'how', 'are', 'you', '?']
[7592, 1010, 2129, 2024, 2017, 1029]
- 1
- 2
在这个示例中,我们首先使用 BertTokenizer.from_pretrained() 加载了预训练的BERT模型的分词器,并将其赋值给变量 tokenizer。然后,使用 BertModel.from_pretrained() 加载预训练的BERT模型本身,并将其赋值给变量 model。
接下来,我们使用 tokenizer.tokenize() 将文本进行分词处理,得到一个标记化的单词列表。然后,使用 tokenizer.convert_tokens_to_ids() 将标记化的单词转换为对应的词汇表索引。
请注意,上述示例中的代码假设您已经安装了Hugging Face Transformers库,并已正确导入相关的包和模块。
通过这些步骤,您可以加载预训练的BERT模型,并使用它进行文本处理和编码。根据具体的任务和需求,您可以进一步调整和使用BERT模型的输出。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/羊村懒王/article/detail/639789
推荐阅读
相关标签

