
- 1【科学计算包NumPy】NumPy数组的基本操作_numpy库对数组的操作与运算
- 2云原生最佳实践系列 5:基于函数计算 FC 实现阿里云 Kafka 消息内容控制 MongoDB DML 操作_函数计算 fc,创建函数,这里能够配置我云服务器中自己搭建的mongodb吗
- 3码农的自我修养 - ARM编译器的区分_宏定义判断是不是mingw
- 4iptables使用limit控制新建连接速率_iptables limit
- 5turbo码_信息论-Turbo码学习
- 6【已解决】git 设置不参与合并的文件_git不合并某个文件
- 79款最新文生图模型汇总!含华为、谷歌、Stability AI等大厂创新模型(附论文和代码)_文生图大模型有哪些
- 8Java获取当前时间的几种方式_java获取当前日期
- 9二、buildroot-2015.02编译根文件系统支持Qt_buildroot 2015
- 10(附源码)SSM学生宿舍管理系统JAVA计算机毕业设计项目_宿舍管理系统怎么在其他电脑运行
RWKV论文燃爆!将RNN崛起进行到底!可扩百亿级参数,与Transformer表现相当!
赞
踩

深度学习自然语言处理 原创
作者:鸽鸽
万众期待的RWKV论文来啦!
这股RNN崛起的“清流”,由民间开源组织发起,号称是第一个可扩展到百亿级参数的非transformer架构!
RWKV结合了RNN和Transformer的优势:一方面,抛弃传统的点积自注意力、使用线性注意力,解决transformer内存和计算复杂度随序列增长呈平方缩放的瓶颈;另一方面,突破了RNN梯度消失、并行化和可扩展性等限制。
居然实现O(Td)的时间复杂度和O(d)的空间复杂度!
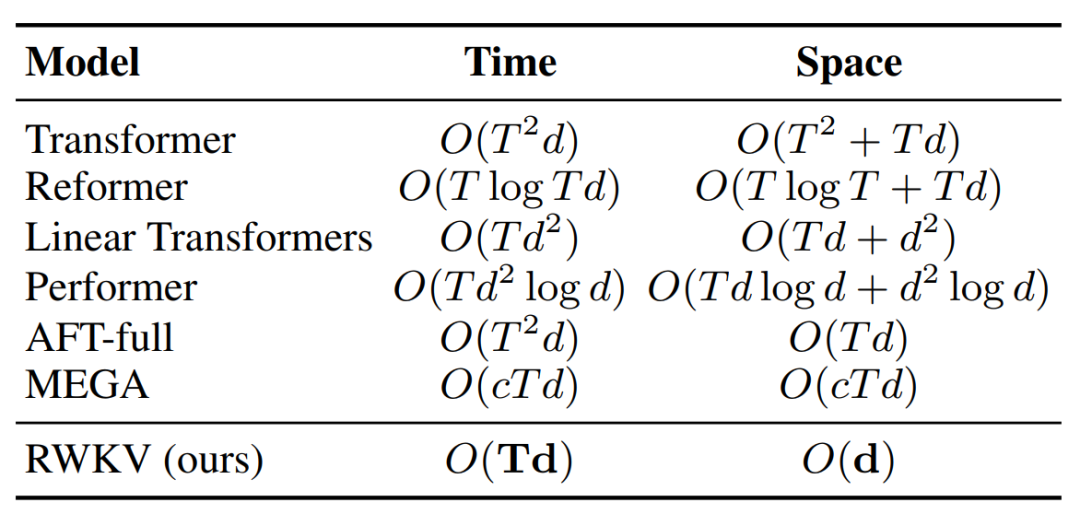
今天我们基于这篇论文,讲讲RWKV背后的注意力、时间混合和通道混合模块的原理与组成。
论文:RWKV: Reinventing RNNs for the Transformer Era
地址:https://arxiv.org/pdf/2305.13048.pdf
代码: https://github.com/BlinkDL/RWKV-LM
模型:https://huggingface.co/BlinkDL/rwkv-4-raven
回顾RNN
流行的RNN架构(如LSTM)公式如下:
下图(a)展示了RNN的数据流,尽管RNN可以分解为两个线性块(和)和一个特定于RNN的块,但对于先前时间步的数据依赖阻止了RNN的并行化。

RWKV 注意力进化史
要知道 RWKV 的线性注意力怎么来的,我们先看经典的transformer自注意力(省略multi-head和缩放因子):
其中核心的乘法是序列中每两两词元 (token) 之间成对的注意力分数的集合,对于每个时间步 t,分解为向量操作:
在Apple提出的 Attention Free Transformer (AFT) 中,引入成对位置偏差来替换点积,可以看作是每个特征维度对应一个头的多头注意力。上面的等式被写作:
其中每个是一个标量,组合成代表成对位置偏差的可学习参数矩阵.
在 RWKV 中,参数进一步简化为一个通道级时间衰减向量,乘以相对位置 :
其中 , 是通道数(特征维度)。
RWKV 模型架构
The Receptance Weighted Key Value (RWKV) 的名字来自于时间混合 (time-mixing) 和通道混合 (channel-mixing) 块中使用的四个主要元素:
(Receptance) :接受过去信息的接受向量;
(Weight):位置权重衰减向量(可训练的模型参数);
(Key) :键是类似于传统注意力中的向量;
(Value):值是类似于传统注意力中的向量。
每个时间步,主要元素之间通过乘法进行交互。RWKV 架构如图所示:
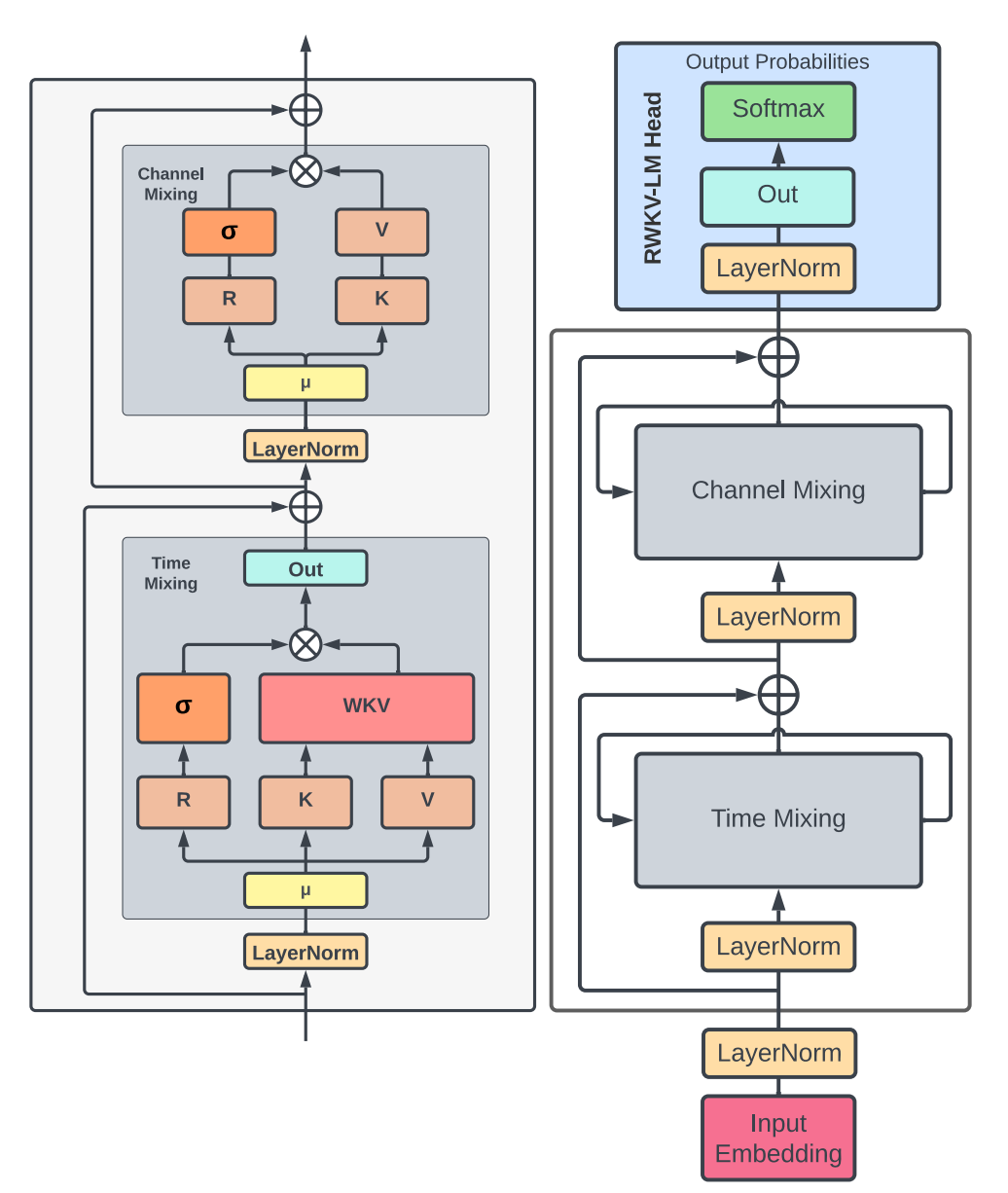
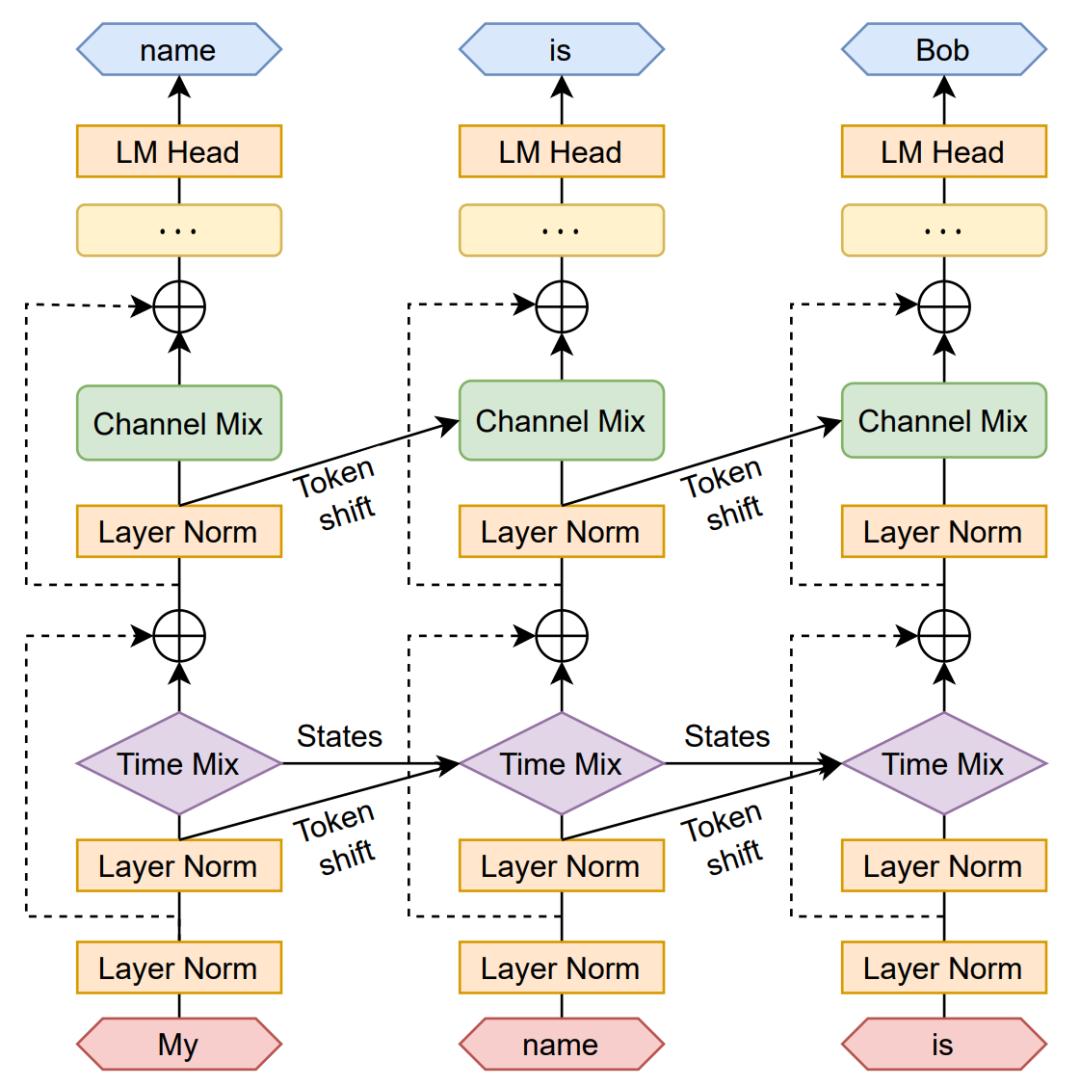
RWKV 架构由一系列堆叠的残差块组成,每个残差块由具有循环结构的时间混合和通道混合子块组成。该循环通过将当前输入和上一时间步的输入之间进行线性插值来实现(作者称为token shift),如下图中对角线所示。这个线性插值可以针对每个输入 embedding 的线性投影(例如时间混合中的和通道混合中的)独立调整。
时间混合块的公式如下:
其中,的计算扮演了Transformer中的角色,其中的时间衰减机制(方程中的)保持了对序列元素间位置关系的敏感性,逐渐减少过去信息对当前时间的影响。直观地说,随着时间的增加,向量依赖于一个长时间历史,由越来越多的项的总和所表示。对于目标位置,RWKV在位置间隔执行加权求和,然后乘以接受度。因此,交互在给定时间步内是乘法,并在不同的时间步上求和。
通道混合块采用平方ReLU激活,公式如下:
注意在时间混合和通道混合中,Receptance取sigmoid的情况下,可以直观地将其视为“遗忘门”,以消除不必要的历史信息。
在最后一个块之后,使用由LayerNorm和线性投影组成的简单输出投影头来获取在下一个token预测任务中使用的logits和计算训练期间的交叉熵损失。训练采用时间并行模式,而自回归推理和聊天则采用时间顺序模式。
评估
实验表明,与具有相同参数和训练token数量的传统transformer架构(Pythia、OPT、BLOOM、GPT-Neo)相比,RWKV在六个基准测试(Winogrande、PIQA、ARC-C、ARC-E、LAMBADA和SciQ)上均具有竞争力。RWKV甚至在四项任务中超越了Pythia和GPT-Neo.
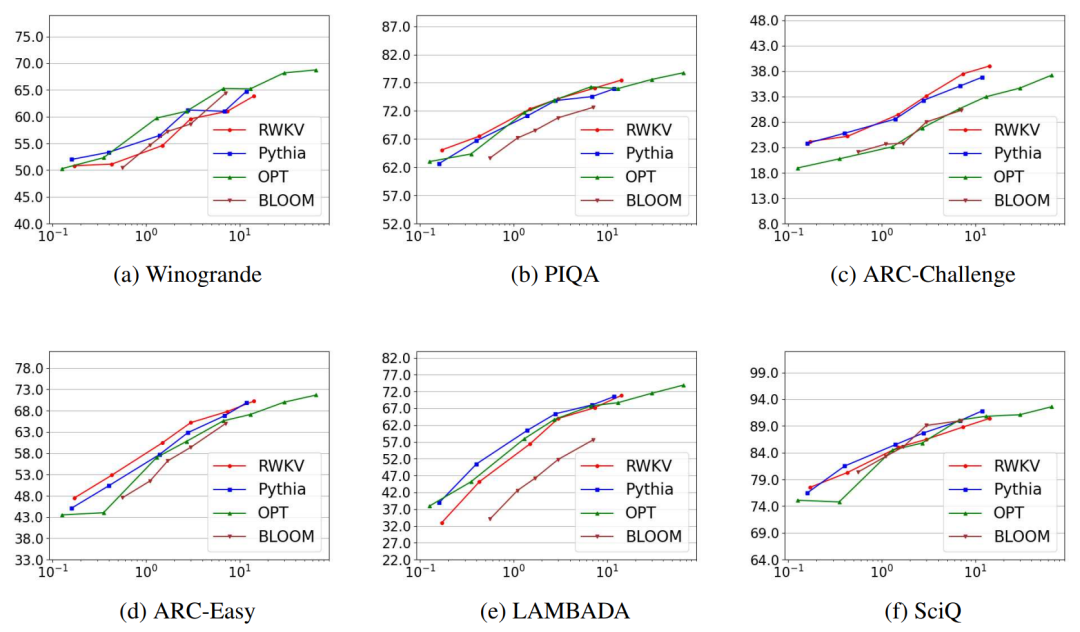
并且,增加上下文长度会导致Pile上的测试loss降低,这表明RWKV可以有效地利用长期的上下文信息。
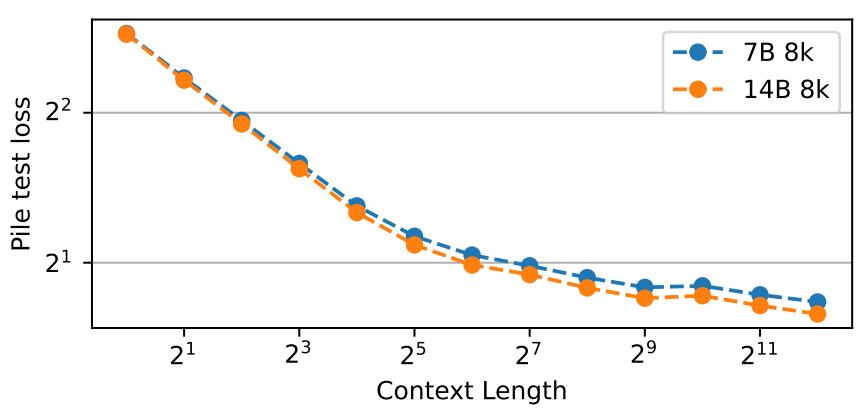
有趣的是,在RWKV-4和ChatGPT / GPT-4的比较研究显示,RWKV-4对提示工程非常敏感。当将指令风格从适合GPT调整为更适合RWKV时,RTE的F1性能甚至从44.2%增加到74.8%。作者猜想是因为RNN不能回溯处理 ( retrospective processing) 来重新调整先前信息的权重。因此为了让性能更好,期望信息应该在问题之后展示。


总结
RWKV与Transformer表现相当,且能在训练时能够并行、在推理时保持恒定的计算和内存复杂度。
但RWKV也存在局限:比起标准Transformer的平方注意力所维护的完整信息,线性注意力和递归架构使信息通过单个向量表示在多个时间步上漏斗式传递,可能限制模型回忆非常长的上下文中细节信息的能力。并且,提示工程变得更加重要。
另外,这篇论文还不是完全版本,有些地方的描述确实不太清晰具体,让我们期待完善后的版本!
进NLP群—>加入NLP交流群

