
- 1github中git clone需要username和password问题_git username password
- 2二叉树的前序遍历,中序遍历,后序遍历(Java实现)_java后续遍历
- 3WMI系列--关于WMI_wmi协议
- 4flutter从0到1构建大前端应用 pdf_这些年的体验技术部(四)· 平台前端 - 有技术,有业务,有爱与远方...
- 5Oracle:左连接、右连接、全外连接、(+)号详解_左外连接和右外连接详解
- 6DS18B20工作原理_ds18b20工作原理及电路图
- 7程序员面试时这样介绍自己的项目经验,成功率能达到98,2024年最新分享一波阿里、字节、腾讯、美团等精选大厂面试题_程序员面试怎么介绍项目
- 8ESP32+VSCode+CMake_esp32 vscode编译带调试信息的elf
- 9el-table二次封装表格组件
- 10RabbitMQ和Kafka的区别_kafaka和rabitmq的区别
13-NLP之Bert多分类实现案例(数据获取与处理)_给出文本分类的代码实现案例完整过程和注释详解
赞
踩
前言知识
一篇文章可以同时属于多个类别,而我们过去的多分类,虽然结果是多个类别,但是每个样本只能属于1个类别。

针对下图,以前,对于输出层来说,输出层有 5 个神经元。 我们认为是5个类别,通过softmax会生成5个类别的概率,我们取概率最大的那个,作为预测的结果。
但现在,针对下面的网络结构要做稍许的调整,针对最后一层,即【输出层】,每个神经元(单个神经元)有已知对应的sigmoid函数,每个神经元接入sigmoid之后,返回0或者1。如果是0.5以下,则代表当前类别不被选中。如果是0.5以上,则代表被选中。这样每个类别就有【选】和【不选】两种状态。合在一起,就是一个多分类的神经网络。


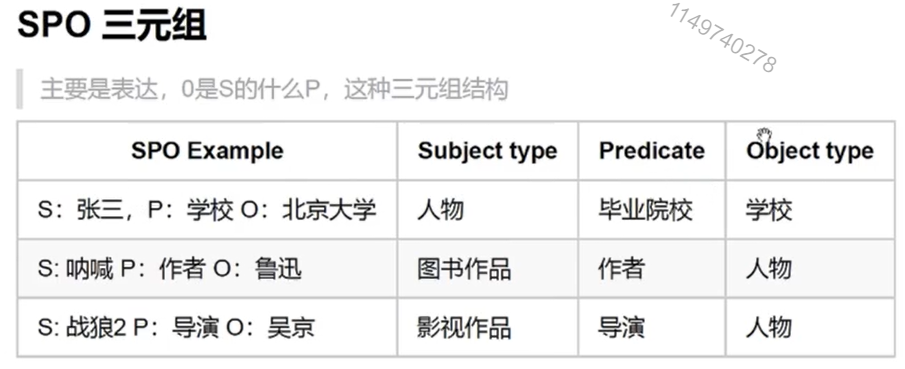
下面用知识图谱的数据做相关分析。三元组揭示了两个实体,或者实体和属性之间的关系,而这个关系,就是P的标签。
O是S的什么P,例如鲁迅是《呐喊》的导演;吴京是《战狼》的导演。
1. 代码解读
1.1 代码展示
import json
import numpy as np
from tqdm import tqdm
bert_model = "bert-base-chinese"
from transformers import AutoTokenizer
- 1
- 2
- 3
- 4
- 5
- 6
- 7
tokenizer = AutoTokenizer.from_pretrained(bert_model)
# spo中所有p的关系标签 (text --> p label)
p_entitys = ['丈夫', '上映时间', '主持人', '主演', '主角', '作曲', '作者', '作词', '出品公司', '出生地', '出生日期', '创始人', '制片人', '号', '嘉宾', '国籍',
'妻子', '字', '导演', '所属专辑', '改编自', '朝代', '歌手', '母亲', '毕业院校', '民族', '父亲', '祖籍', '编剧', '董事长', '身高', '连载网站']
max_length = 300
train_list = []
label_list = []
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
with open(file="../data/train_data.json", mode='r', encoding='UTF-8') as f:
data = json.load(f)
for line in tqdm(data):
text = tokenizer.encode(line['text'])
token = text[:max_length] + [0] * (max_length - len(text))
train_list.append(token)
# 获取当前文本的标准答案 (spo中的p)
new_spo_list = line['new_spo_list']
label = [0.] * len(p_entitys) # 确定label的标签长度
for spo in new_spo_list:
p_entity = spo['p']['entity']
label[p_entitys.index(p_entity)] = 1.0
label_list.append(label)
train_list = np.array(train_list)
label_list = np.array(label_list)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
val_train_list = [] val_label_list = [] # 加载和预处理验证集 with open('../data/valid_data.json', 'r', encoding="UTF-8") as f: data = json.load(f) for line in tqdm(data): text = line["text"] new_spo_list = line["new_spo_list"] label = [0.] * len(p_entitys) for spo in new_spo_list: p_entity = spo["p"]["entity"] label[p_entitys.index(p_entity)] = 1. token = tokenizer.encode(text) token = token[:max_length] + [0] * (max_length - len(token)) val_train_list.append((token)) val_label_list.append(label) val_train_list = np.array(val_train_list) val_label_list = np.array(val_label_list)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
1.2 流程介绍
这段代码的整体流程和目的是为了对中文文本进行自然语言处理任务的准备工作,这里似乎是为了一个文本分类或关系提取任务。具体步骤如下:
-
导入必要的库:
json:用于处理JSON数据格式。numpy:科学计算库,用于高效地处理数组操作。tqdm:用于在循环操作中显示进度条。
-
指定BERT模型的类型(
bert-base-chinese),用于中文文本。 -
使用
transformers库中的AutoTokenizer来加载指定BERT模型的分词器。 -
定义一组中文实体关系标签(
p_entitys),这些看起来是用于文本中特定实体之间关系的标签。 -
设置一个最大序列长度(
max_length)为300,以限制处理文本的长度。 -
初始化两个空列表
train_list和label_list,用于存储训练数据的特征和标签。 -
加载并处理训练数据(
train_data.json):- 使用
json.load()读取文件内容。 - 使用
tokenizer.encode()将每行文本转换为BERT词汇表中的token IDs。 - 如果文本长度短于
max_length,则用0填充。 - 解析每个文本的
new_spo_list以构建标签向量,其中如果关系存在于文本中,则相应位置为1,否则为0。
- 使用
-
将
train_list和label_list转换为NumPy数组,以便进一步处理。 -
对验证集进行与训练集相同的处理,并存储在
val_train_list和val_label_list。
代码的目的是将中文文本及其对应的实体关系标签转换为机器学习模型可以接受的数值格式。这个过程通常是自然语言处理任务中文本预处理的一部分,特别是在使用BERT这类预训练语言模型的情况下。
你需要完成的工作可能包括:
- 确保你有正确配置的环境和库来运行这段代码。
- 如果这是第一次运行,确保你下载了
bert-base-chinese模型和分词器。 - 准备
train_data.json和valid_data.json数据文件。 - 运行代码并监视进度条以确保数据正在被正确处理。
1.3 debug的方式逐行介绍
下面逐行解释代码的功能:
import json
import numpy as np
from tqdm import tqdm
- 1
- 2
- 3
这三行代码是导入模块,json用于处理JSON格式的数据,numpy是一个广泛使用的科学计算库,tqdm是一个用于显示循环进度的库,可以在长循环中给用户反馈。
bert_model = "bert-base-chinese"
- 1
这行代码定义了变量bert_model,将其设置为"bert-base-chinese",指的是BERT模型的中文预训练版本。
from transformers import AutoTokenizer
- 1
从transformers库导入AutoTokenizer,这是Hugging Face提供的一个用于自动获取和加载预训练分词器的类。
tokenizer = AutoTokenizer.from_pretrained(bert_model)
- 1
使用from_pretrained方法创建了一个tokenizer对象,这个分词器将根据bert_model变量指定的模型进行加载。
p_entitys = [...]
- 1
这里列出了所有可能的关系标签,用于将文本中的关系映射为一个固定长度的标签向量。
max_length = 300
- 1
定义了一个变量max_length,设置为300,用于后面文本序列的最大长度。
train_list = []
label_list = []
- 1
- 2
初始化两个列表train_list和label_list,分别用于存储处理后的文本数据和对应的标签数据。
with open(file="../data/train_data.json", mode='r', encoding='UTF-8') as f:
- 1
打开训练数据文件train_data.json,以只读模式('r')和UTF-8编码。
data = json.load(f)
- 1
加载整个JSON文件内容到变量data。
for line in tqdm(data):
- 1
对data中的每一项进行迭代,tqdm将为这个循环显示一个进度条。
text = tokenizer.encode(line['text'])
- 1
使用分词器将文本编码为BERT的输入ID。
token = text[:max_length] + [0] * (max_length - len(text))
- 1
这行代码截取或填充编码后的文本至max_length长度。
train_list.append(token)
- 1
将处理后的文本添加到train_list列表中。
new_spo_list = line['new_spo_list']
- 1
提取当前条目的关系列表。
label = [0.] * len(p_entitys)
- 1
创建一个与关系标签数量相同长度的零向量。
for spo in new_spo_list:
- 1
遍历当前条目的每一个关系。
p_entity = spo['p']['entity']
- 1
从关系中提取实体。
label[p_entitys.index(p_entity)] = 1.0
- 1
在标签向量中,将对应实体的索引位置设为1.0,表示该关系在文本中出现。
label_list.append(label)
- 1
将构建好的标签向量添加到label_list。
train_list = np.array(train_list)
label_list = np.array(label_list)
- 1
- 2
将列表转换为NumPy数组,便于后续处理。
接下来的代码块与之前的相似,只是针对验证数据集valid_data.json进行操作。
val_train_list = []
val_label_list = []
- 1
- 2
初始化用于验证集的两个列表。
with open('../data/valid_data.json', 'r', encoding="UTF-8") as f:
- 1
打开验证数据文件。
接下来的代码块与处理训练数据时相同,也是加载数据、对文本进行编码、生成标签向量、然后将它们添加到相应的验证集列表中。
val_train_list = np.array(val_train_list)
val_label_list = np.array(val_label_list)
- 1
- 2
最后,同样地,将验证集的列表转换为NumPy数组。
这段代码整体上是用来处理和准备数据,使其适合输入到一个神经网络模型中去。它不仅编码文本,还构造了与之相对应的标签,这在训练和验证机器学习模型时是必需的。
3. 知识点
3.2 代码疑问
1. 使用tokenizer.encode()将每行文本转换为BERT词汇表中的token IDs。包含词嵌入的内容吗?
使用 tokenizer.encode() 将文本转换为 BERT 词汇表中的 token IDs 时,并不直接包含词嵌入(word embeddings)的内容。这个过程主要是文本的预处理步骤,涉及将文本分割成 tokens 并将这些 tokens 转换为模型能理解的数字ID。下面详细解释一下这个过程:
-
Tokenization(分词):
- 首先,
tokenizer.encode()函数将给定的文本字符串分割成 tokens。在BERT的情况下,这通常包括字词级别的分割以及子词单位(subword units)的分割。
- 首先,
-
转换为 Token IDs:
- 接着,这些 tokens 会被转换成词汇表中对应的数字ID。BERT模型有一个预先定义的词汇表,每个 token 都映射到一个唯一的ID。
-
词嵌入(Word Embeddings)的角色:
- 词嵌入是在模型的后续阶段使用的。当这些 token IDs 被输入到 BERT 模型时,模型的第一层(通常是一个嵌入层)会将这些数字ID转换成向量形式的词嵌入。
- 词嵌入是高维空间中的向量,每个向量代表着输入文本中的一个 token。这些向量是通过训练过程中学习得到的,并能够捕捉词汇的语义信息。
-
区分 Tokenization 和 Embedding:
- 重要的是要区分 tokenization(及其产生的 token IDs)和 word embeddings。Tokenization 只是将文本转换为模型可以理解的形式的预处理步骤。而 word embeddings 则是模型内部用于表示这些 tokens 语义的向量。
总结来说,tokenizer.encode() 只负责将文本转换为 token IDs,而不涉及词嵌入的创建。词嵌入是在模型内部生成的,作为模型处理这些 token IDs 的一部分。
举一个python案例,包含输入输出内容
这里有一个简单的 Python 示例,它演示了如何使用 BERT tokenizer 将文本转换为 token IDs,然后用一个基本的 BERT 模型将这些 token IDs 转换为词嵌入。请注意,这个例子需要 transformers 库,可以通过 pip install transformers 命令来安装它。
示例:使用 BERT Tokenizer 和模型
输入
文本: “Hello, how are you?”
Python 代码
from transformers import BertTokenizer, TFBertModel # 初始化 tokenizer 和模型 tokenizer = BertTokenizer.from_pretrained('bert-base-uncased') model = TFBertModel.from_pretrained('bert-base-uncased') # 文本输入 text = "Hello, how are you?" # 使用 tokenizer 将文本转换为 token IDs input_ids = tokenizer.encode(text, return_tensors='tf') # 输出 token IDs print("Token IDs:", input_ids) # 使用模型获取词嵌入 outputs = model(input_ids) last_hidden_states = outputs.last_hidden_state # 输出词嵌入的形状 print("Shape of Embeddings:", last_hidden_states.shape)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
输出
- Token IDs:一系列数字,代表每个 token 的 ID。
- Embeddings 的形状:这将展示词嵌入的维度,通常是
(batch_size, sequence_length, hidden_size)。
解释
- 这段代码首先加载 BERT tokenizer 和模型。
- 然后,它使用 tokenizer 将给定的文本字符串 “Hello, how are you?” 转换为一系列 token IDs。
- 最后,这些 token IDs 被传递到 BERT 模型中,模型返回每个 token 的词嵌入。
- 输出中包含了 token IDs 和词嵌入的形状信息。
请注意,要运行此代码,需要在 Python 环境中安装 transformers 库,并且需要网络连接以下载模型和 tokenizer。

