
- 1Oracle物化视图(Materialized View)_oracle 物化视图
- 2基于FPGA的并行DDS设计
- 3python渗透工具编写学习笔记:9、web漏洞检测与利用脚本_python语言写网络渗透测试脚本
- 42024.5月更新大麦autojs代码,实现app端自动抢票_autojs 大麦
- 5AI辅写疑似度高风险?七招助你化险为夷!_论文ai风险高怎么解决
- 6Android Studio入门:Android应用界面详解(上)(View、布局管理器)_android studio的view
- 7腾讯后台开发一面(凉)_腾讯后端一面
- 8最新版IDEA(或Android Studio)Lombok的使用方法_android lombok
- 9Centos7防火墙与IPTABLES详解_centos7 iptables 和防火墙
- 10《动手学ROS2进阶篇》8.2RVIZ2可视化移动机器人模型_如何重装rviz2
图解 BERT 模型
赞
踩
节前,我们星球组织了一场算法岗技术&面试讨论会,邀请了一些互联网大厂朋友、参加社招和校招面试的同学.
针对算法岗技术趋势、大模型落地项目经验分享、新手如何入门算法岗、该如何准备、面试常考点分享等热门话题进行了深入的讨论。
汇总合集:《大模型面试宝典》(2024版) 发布!
《Attention is All You Need》发表于 2017 年,2018 年 Google AI Language 团队发表了论文《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》,提出了 Bert(Bidirectional Encoder Representations from Transformers)架构。
BERT 实际基于 Transformer 的编码器部分,如若大家理解了前述 Transformer 系列文章,那么再学习 BERT 会很容易理解。
这次依然尝试使用图解的方式介绍 BERT。文章一部分及配图参考了 Rahul Agarwal 在 Medium 上的文章及原始论文,建议收藏、关注、点赞,无论实战还是面试都是常考热点。
一、BERT 概览
简单来说,BERT 是一种可用于问题解答、分类、NER 等大量 NLP 下游任务的架构。可将预训练后的 BERT 视为一个黑盒。
BERT 有两个主要版本:
-
BERT Base:12层 Transformer 编码器,隐藏层大小为768,12个自注意头,总参数量约为1.1亿。
-
BERT Large:24层 Transformer 编码器,隐藏层大小为1024,16个自注意头,总参数量约为3.4亿。
以 BERT Base 版本的 BERT 为例,它能将输入中的每个 Token 转化为一个 H = 768 的向量。与 Transformer 相同,BERT 的输入序列可以是一个单独的句子,也可以是一对由分隔符 [SEP] 标记分隔,以开始符 [CLS] 标记开始的句子。
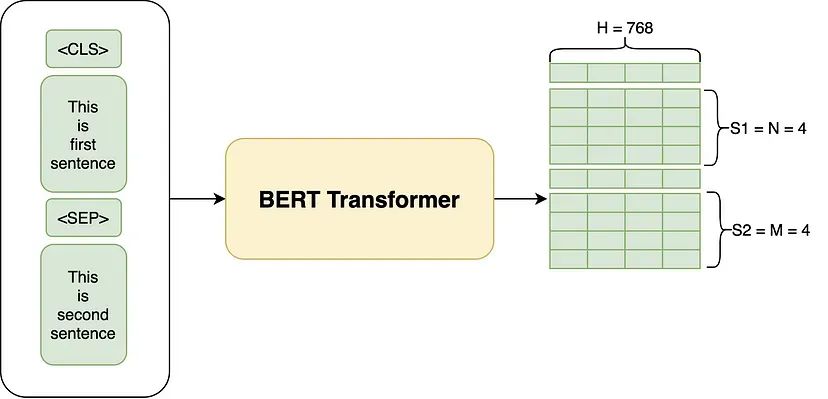
二、BERT 解决什么问题
如果各位小伙伴对 Imagenet 有所了解,那么也会很容易理解 BERT 的预训练过程。
ImageNet 是一个大型图像数据库,包含了数百万个带标签的图像。CV 模型在这个数据集上进行预训练,以学习图像特征;预训练完成后,对于具体图像任务,可以通过在较小的数据集上,微调模型最后几层来适应特定任务。前几年流行的 ResNet 和 VGG 等深度学习模型最初都是在 ImageNet 数据集上进行预训练的。
BERT 模型工作原理与使用 Imagenet 进行训练的大多数 CV 模型类似。首先,在大型语料库上训练 BERT 模型,然后通过在最后添加一些额外的层,针对具体的 NLP 任务(如分类、问题解答、NER 等)对模型进行微调。
例如,先在维基百科这样的语料库上训练 BERT(屏蔽 LM 任务),然后再用特定的数据对模型进行微调,以完成分类任务,诸如通过添加一些额外的层,将评论分为负面、正面或中性等方式。实际上,我们只是使用 [CLS] 标记的输出来完成分类任务。
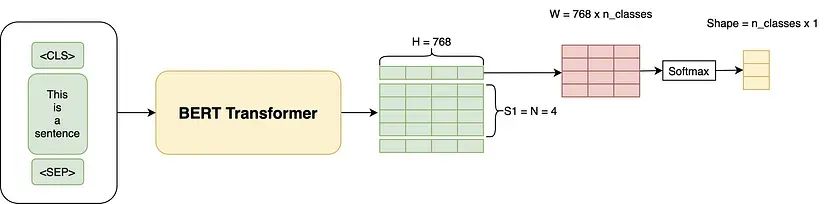
如下图所示的微调过程,通过添加线性层和 Softmax 层,对 [cls] Token 进行分类输出。
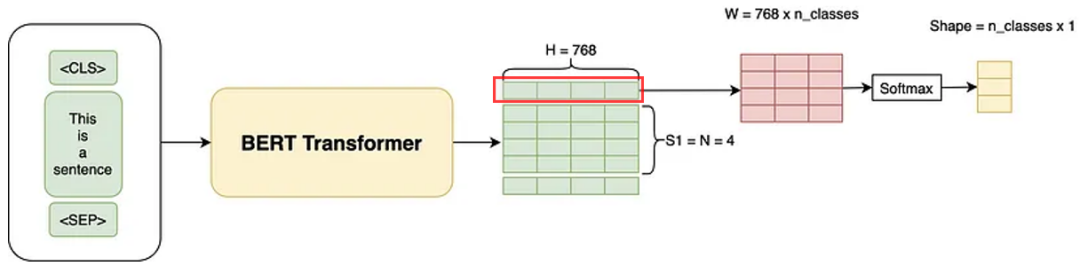
具体来说, 对 BERT 输出的 [cls] Token 使用矩阵乘法作变换。假设我们的分类数是 3,那么 [cls] Token 向量的维度是(1×768),引入的 W 矩阵的形状为( H × num_classes = 768 × 3), [cls] Token 代表的矩阵与 W 矩阵相乘,得到一个(1×3)的矩阵,这个矩阵再通过 Softmax 得到每个类别的概率,然后计算交叉熵损失。
当然,也可以通过在最后一层获取句子特征,然后再输出到 Softmax;或者可以取所有输出的平均值,然后再通过 Softmax。方式有多种,哪种最有效取决于任务的数据。
三、从嵌入的角度看 BERT
从嵌入的角度来看,BERT 的预训练为我们提供了上下文双向嵌入。
1. 上下文 Contextual:
词的嵌入不是固定的,它们依赖于周围的词语。在前序《图解 Transformer》序列文章就详细介绍过这个概念。比如,在“one bird was flying below another bird”这句话中,“bird”这个词的两个嵌入会有所不同。
2. 双向 Bi-Directional:
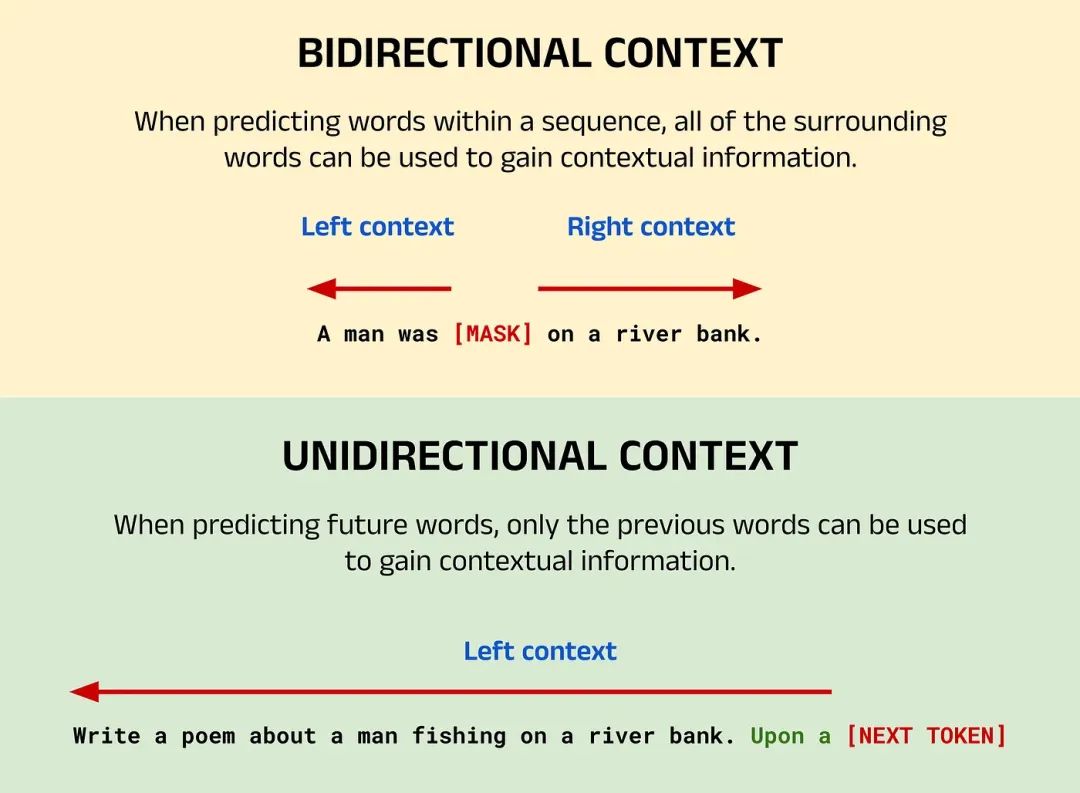
LSTM 按顺序读取文本输入(从左到右或从右到左),而 Transformer 的编码器则是一次性读取整个单词序列,因此被认为是双向的(注意,Transformer 模型的解码器部分通常是单向的)。因此,对于“BERT model is awesome.”这样的句子,“model”这个词的嵌入会包含“BERT”、“awesome”和“is”所有词的上下文。
四、BERT 工作的具体流程
接下来从“架构-Architecture 、输入-Input、训练-Training”三个部分介绍 BERT 的具体工作流程。
1. Architecture
如果你对 Transformers 已经有所了解,那么 BERT 的架构非常容易理解。BERT 基本上是由我们非常熟悉的Transformers 中的编码器堆栈(Encoder Stacks)组成的。
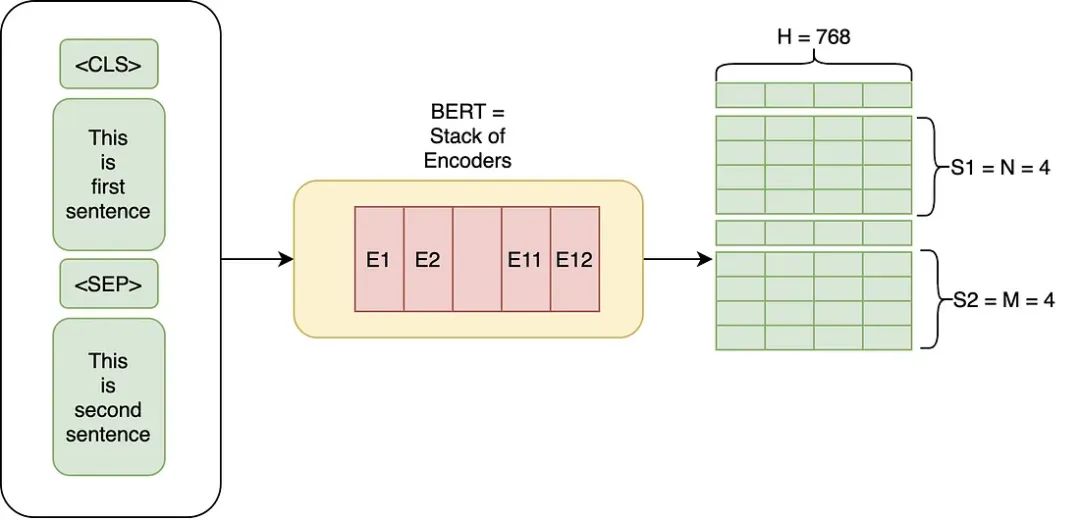
原始论文中,作者实验了两种模型,即我们在开头也提到过的 BERT Base 与 BERT Large 两种架构。
2. Training Input
我们使用下图中的输入结构向 BERT 提供输入。输入由(两个句子+两个特殊的 Token)构成。两个特殊的 token是 [CLS]和[SEP] token。
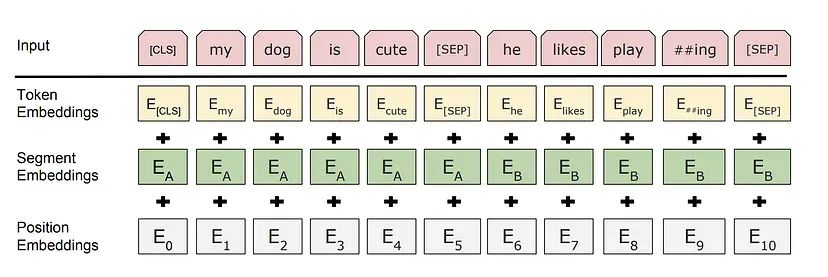
例如,对于两个句子“my dog is cute”和“he likes playing”,BERT 首先使用 WordPiece 分词将序列转换为Token,并在开头添加[CLS] Token,在第二个句子的开头和结尾添加[SEP] Token,因此输入是:

在 BERT 中使用的 WordPiece 分词方法会将单词如 playing 分解成“play”和“##ing”。对于为什么使用 WordPiece 这种方式,我们后面再详细介绍。
BERT 的每个 token 的嵌入由 Token Embeddings、Position Embeddings、Segment Embeddings 三种嵌入向量进行表示:
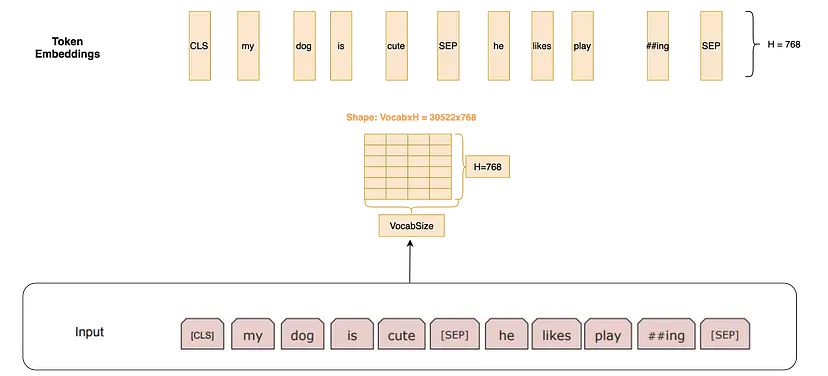
Token Embedding(词嵌入): 通过在一个大小为 30000x768(H) 的词表矩阵中查找,来获取 Token 嵌入。这里,30000 是WordPiece 分词后的词汇表长度。这个矩阵所代表的权重将在训练过程中学习。
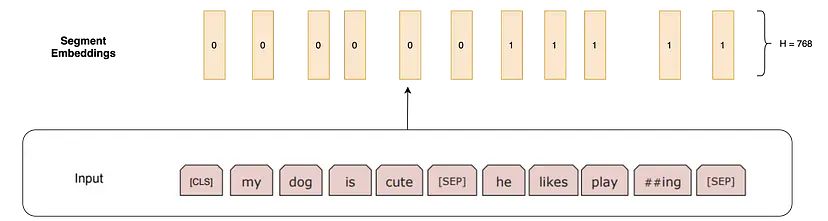
Segment Embedding(段落嵌入): 对于知识问答等任务,我们需要指定这个句子是来自哪个段落。如果嵌入来自第一个句子,这些嵌入是长度为H的全0向量;如果嵌入来自第二个句子,则为全1向量。
位置嵌入(位置嵌入):这些嵌入用于指定单词在序列中的位置,和 Transformer 中所做的一样。位置矩阵的列数为768,矩阵的第一行是[CLS] Token的嵌入,第二行是单词“my”的嵌入,第三行是单词“dog”的嵌入,以此类推。
给BERT的最终输入是 Token Embeddings、Segment Embeddings、Position Embeddings的叠加(Token Embeddings + Segment Embeddings + Position Embeddings)。
3. 训练遮蔽语言模型(Masked LM)
这部分是 BERT 最有趣的地方。我们将通过各种架构尝试并发现每种尝试的缺陷,以此来解释这些概念,并形成 BERT的最终架构。
尝试1:例如,如果我们按如下方法设置 BERT 训练,即预测输入序列的每个单词。

这种方法的问题在于学习任务过于简单。网络提前就知道它要预测什么,因此可以轻松地学习权重以达到100%的分类准确率。
注意:这里的“预测-Predict”与 Transformer 解码器中基于已经生成的单词,预测下一个单词的“预测”的含义略微不同。这里的“预测-Predict”是“生成-Generation”的意思。这里使用“Predict”这个词,是表达在 Masked LM 模型中,模型根据上下文信息推断被掩蔽 token 的过程。虽然“生成”也可以理解为一种预测,但在NLP术语中,“生成”通常指的是更广泛的内容创建,而不是特定位置 token 的推断。下面几种方法中提到的“预测”一词也是这样的含义。
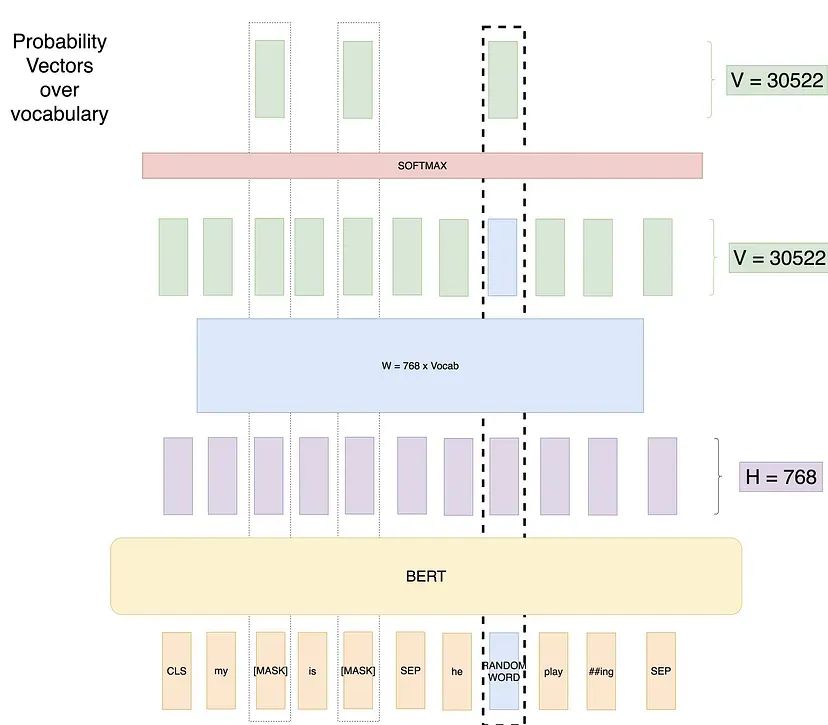
尝试2:遮蔽语言模型(Masked LM)。原论文中尝试使用此方法克服上述问题。在每个训练输入序列中随机遮蔽15%的单词,并仅预测这些单词的输出。
此种方式计算损失时只针对屏蔽的单词。模型学会了预测它未见过的单词,同时还能看到这些单词周围的上下文。(注意,图中屏蔽了 3 个单词,实际上应该只屏蔽 1 个单词,因为这个示例中,8 个单词的 15% 就是 1 个单词。)
但这种方式的造成了模型在“预训练-微调”两个过程的不匹配问题。
具体来说,在预训练阶段,模型需要根据上下文预测被遮蔽的 token,因此模型会更多地依赖上下文信息来填补空白。但在微调阶段,模型直接处理完整的句子,输入方式不同可能会导致模型的预测行为与预训练阶段存在偏差。另外,在预训练时模型通过预测被掩蔽的token来学习语言的结构和语义,但在微调阶段,模型的目标通常是根据完整输入直接进行分类或预测,这种目标上的差异可能导致模型在微调时需要重新调整。
尝试3:使用随机单词的遮蔽语言模型:
在这个尝试中,仍然会遮蔽15%的位置。但会用随机单词替换那些被遮蔽标记中的20%。这样做是为了让模型知道,即使单词不是[MASK]标记,我们仍然需要输出一些结果。因此,如果我们有一个长度为500的序列,我们将遮蔽75个标记(500的15%),在这75个标记中,有15个标记(75的20%)将被随机单词替换。示意图如下:
这种方式的优点在于,网络仍然可以处理任何单词。
但其问题在于,模型会学到一种错误模式,即看到随机替换的单词时,这些单词永远不会是正确的输出。比如对于我们的例子,将“likes”随机替换为“eats”,而我们在这个位置需要的输出为“likes”,模型会学习到“eats”的输出永远不会是“eats”。而在不同的上下文中,比如输入“he eats bread”,需要的输出中包含“eats”。
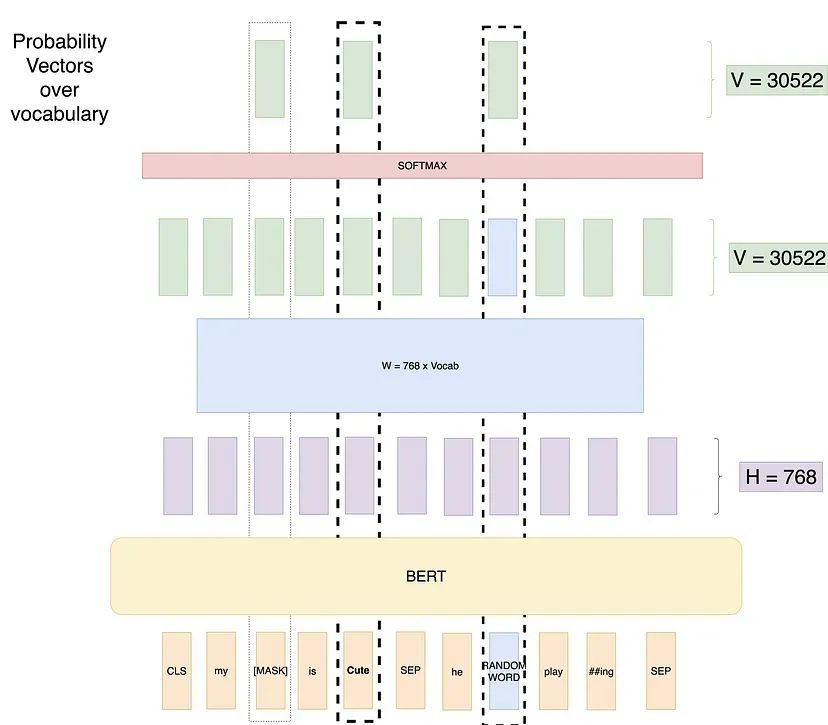
尝试4:使用随机单词和未遮蔽单词的遮蔽语言模型
为了解决这个问题,作者提出了以下训练设置。
在训练数据中随机选择 15% 的 token 位置进行预测。这些随机选择的 token 中,80%替换为[MASK]标记,10%随机替换为词汇表中的其他 token,10% 保持不变。
如果我们有一个长度为 500 的序列,我们将遮蔽75个 token(500的15%),在这75个 token中,7个 token(75的10%)将被随机 token 替换,7个 token(75的10%)保持不变。示意如下:
这样就有了最佳设置,模型不会学习到不良模式。
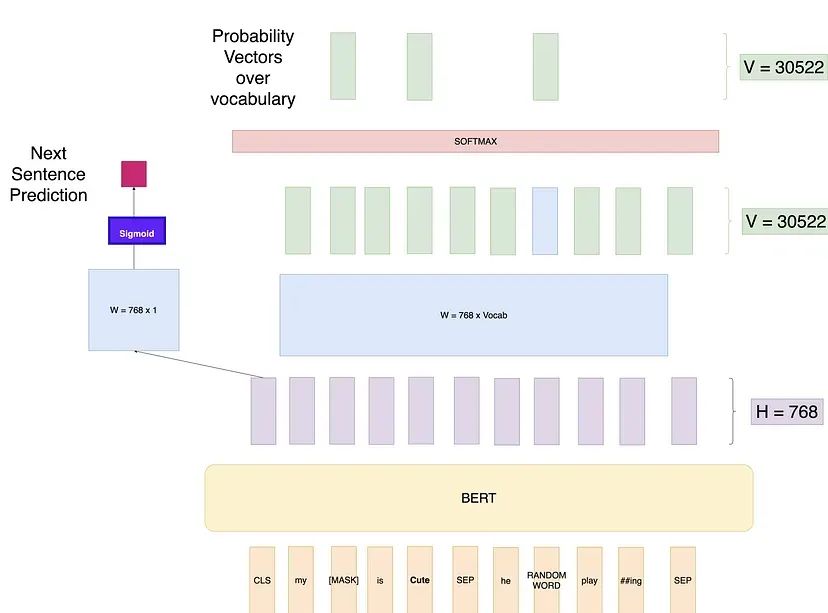
4. 训练附加的下一句预测任务(NSP)
BERT 模型在训练过程中还有另一个并行的于 Masked LM 的训练任务,这个任务称为下一句预测(Next Sentence Prediction, NSP)。在创建训练数据时,我们为每个训练样本选择句子A和B,其中50%的情况下B是实际紧跟在A后的句子(标记为IsNext),而另外50%的情况下B是语料库中的一个随机句子(标记为NotNext)。然后我们使用[CLS]标记的输出来计算损失,这个损失也会通过网络反向传播来调整权重。
摘自 BERT 论文原文:许多重要的下游任务,如问答(QA)和自然语言推理(NLI),都基于两个句子之间的关系,而这种关系不是通过语言模型直接捕捉到的。为了训练一个能够理解句子关系的模型,我们进行了一种二元化的下一句预测任务(binarized next sentence prediction task)的预训练,这个任务可以从任何单语语料库中轻松生成。
现在我们有了预训练的BERT模型,它可以为我们提供上下文嵌入。那么如何将它用于各种任务呢?
五、针对具体任务进行微调
如前所述,我们可以在 [CLS] 输出上添加几层并微调权重,然后使用BERT进行分类任务。
以下是论文中介绍的 BERT 用于其他任务的方法:
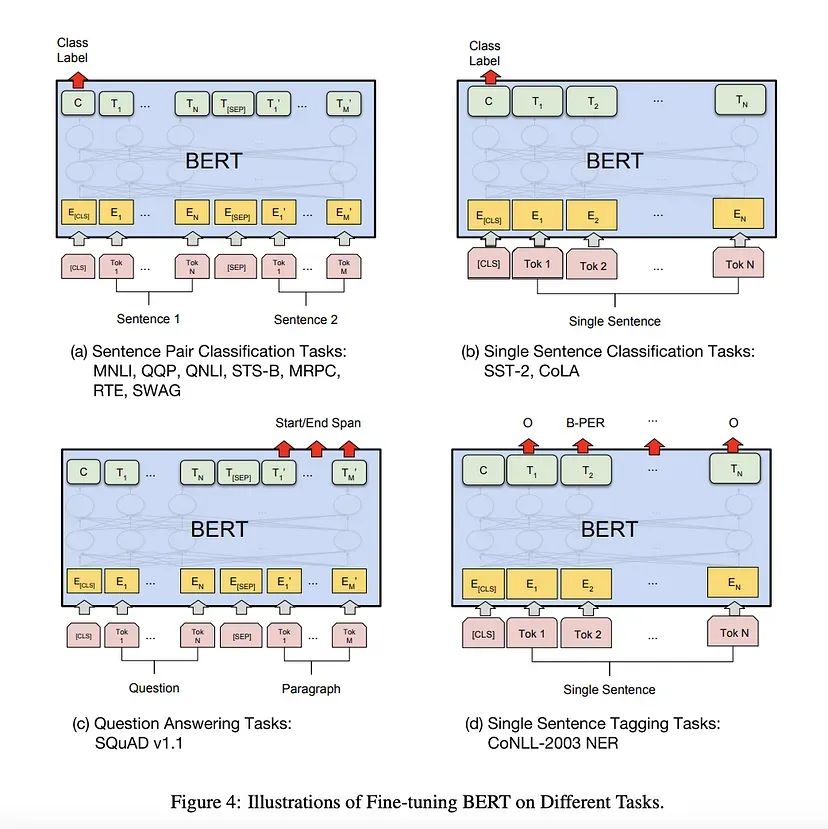
让我们逐一浏览这些任务:
1. 句子对分类任务:这与分类任务非常相似。即在大小为768的[CLS]输出上添加一个线性层和一个Softmax层(Linear + Softmax)。
2. 单句分类任务:与句子对分类任务相同。
4. 单句标注任务:与训练 BERT 时的设置非常相似,只是我们需要为单句中的每个 Token 进行标注。如对于词性标注任务(如预测名词、动词或形容词),我们只需添加一个大小为(768 x n_outputs)的线性层,并在上面添加一个Softmax层进行预测。
3. 问答任务——这个任务中,我们给出一个问题和一个包含答案的段落:目标是确定答案在段落中的起始和结束位置。
六、问答任务详细工作流程
BERT 执行问答任务的原理与 GPT 等以自回归生成答案的模型不同。以下是关于 BERT 在执行问答任务时的详细流程:
1. 输入序列
输入序列由问题和段落拼接而成,并添加特殊标记:
[CLS] 问题 [SEP] 段落 [SEP]
- 1
2. BERT模型输出
输入序列通过 BERT 模型处理,生成每个 token 的上下文表示。假设输入序列长度为
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

