
- 1apollo cyber_RT框架的常用操作指令_apollo cyber怎么通过终端查看通道数据
- 2kafka stream流式处理_1.1 kafka stream是什么
- 3Web3Tools - 助记词生成_web3钱包助词器
- 4VCU1525最新安装步骤记录(2019/11/17测试通过)
- 5Mamba VS Transformer,谁主沉浮?
- 6MySQL索引底层数据结构B+树详解
- 7LangChain带你轻松玩转ChatGPT等大模型开发
- 8hive lateral view语句
- 9【spark】什么是随机森林_spark 随机森林
- 10python 地理信息_GitHub - sujeek/geospatial-data-analysis-cn: Python地理信息数据教程中文版(GeoPandas、GIS)...
【赛尔笔记】病患相似度度量简述
赞
踩
点击上方,选择星标,每天给你送干货!
作者:哈工大SCIR 王昊淳
1.介绍
在人工智能技术飞速发展的当下,基于人工智能方法的智慧医疗系统也逐渐吸引了大量研究人员的目光,计算机辅助的分诊、诊断等应用可以一定程度地缓解部分地区的医疗条件紧张问题,同样可以为医生的决策提供辅助参考。在数字化医疗系统的普及下,与病患相关的医疗数据,如电子医疗记录、医嘱、生物化学检测结果以及基因组信息也已经基本实现电子化[1],因此,通过数据挖掘、深度学习等方法对上述电子化信息进行学习,进而得到患者与患者之间的相似程度,是实现疾病判断、病情预测以及精准医疗(precision medicine)等应用的重要的前提条件,且上述过程也受启发于实际临床中医生的诊疗过程。病患相似度度量方法的流程大致如图1,首先根据患者的数据信息进行数据抽象化,并选择合适算法与度量方法对抽象化结果进行相似度评估,进而将相似度结果应用于相应的下游任务中。
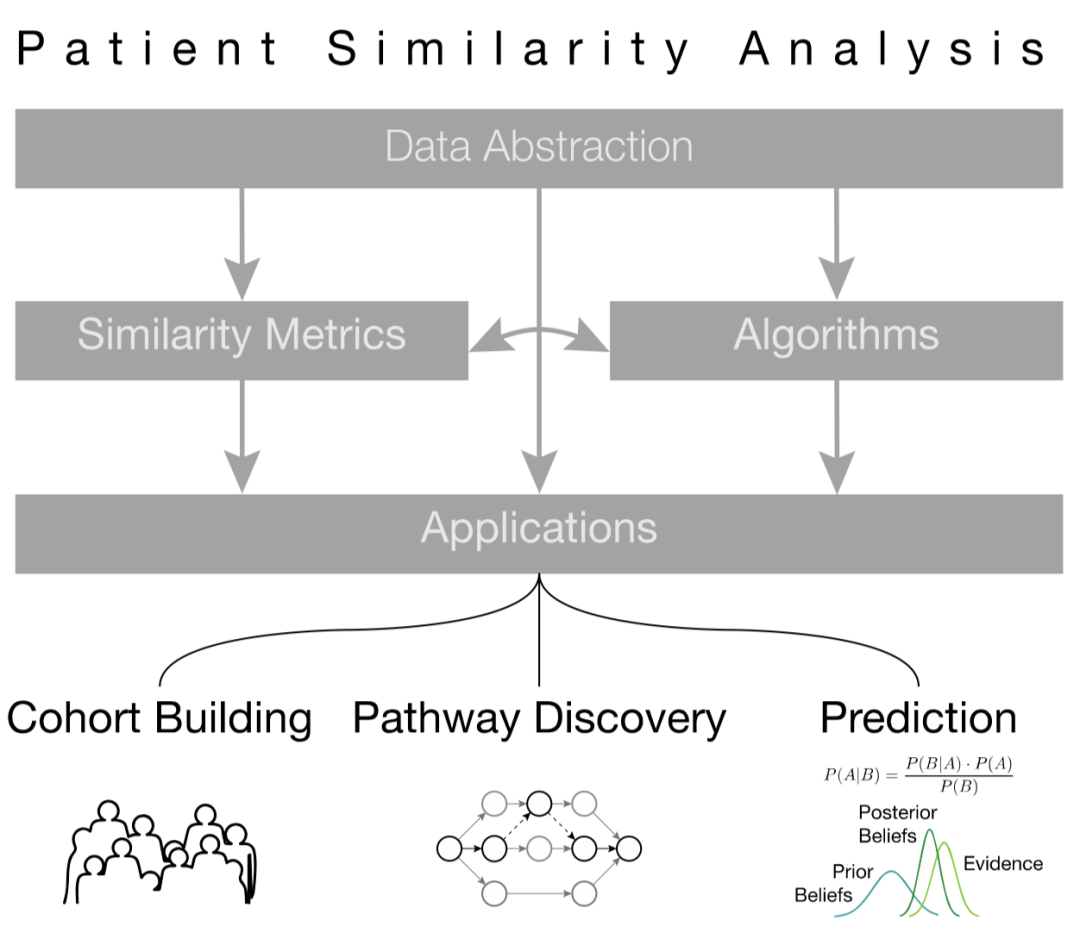
图1 病患相似度分析工作的基本流程[3]
2.病患数据
病患相关数据是天然多模态(multi-modal)且异构(heterogeneous)的,可能涵盖文本信息(如病历)、图像信息(如CT影像)、时序信号信息(如心电图)和数值信息(如血常规检查结果)等等,从病患相似度的历史研究中所包括的类型来看,一般可将病患数据分为以下五类[2]:
临床数据 Clinical data
分子数据 Molecular data
图像与生物信号 Imaging and bio signals
实验室结果 Lab results
病患所述结果 Patient-reported outcomes
临床数据包括电子病历信息、医保数据等;分子数据包括DNA信息、蛋白质序列信息等;图像与生物信号包括CT、MRI、心电图等;实验室结果包括血液检测结果、核酸抗体检测结果等;病患所述结果包括患者出院后的回访信息以及相关口述信息等。从形式上看,病患数据等的医学相关数据都属于纵向数据(longitudinal data),即数据来源于不同个体在不同时间节点测得的数据。
根据以上信息可知,病患数据特征一般有着较多的维度,每维特征的采样次数与分辨率有所不同,且数据完备程度也不一样[3],因此病患数据中大多存在噪声、异常数据以及数据缺失等问题。同时,由于患者在患病就医后,病症的减轻或加重都会导致患者的多次来访和复检,因此病患数据多为纵向数据,即数据来源于每个个体在不同时间点上的观测值[4]。
3.病患相似度度量相关数据
3.1 UCI 数据集[5]
UCI数据集是机器学习社区中使用率很高的领域丰富的数据集仓库,其中也涵盖与医学健康相关的数据集,相关数据也为病患相似度度量工作的数据来源,包括帕金森氏症数据集[6]、心脏病数据集[7]、糖尿病数据集[8]、癌症数据集[9]等等。
3.2 ADNI数据集[10]
ADNI(Alzheimer's Disease Neuroimaging Initiative)是一个通过生物标记与临床数据追踪阿尔兹海默症发展过程的纵向研究计划,数据内容包括临床诊断、生物样本、药物使用历史、基因组数据以及脑补成像数据,疾病的诊断工作每数月进行一次并持续数年,研究对象被分为三组,分别为正常对照组、中度认知障碍(MCI, Mild Cognitive Impairment)和阿尔兹海默症患者(AD, Alzheimer’s Disease)。
3.3 SOF数据集[11]
SOF(Study of Osteoporotic Fracture)是一个长达二十余年的针对年长白人女性骨质疏松病症的医院来访纵向研究,研究旨在分析高龄白人女性患骨质疏松的风险因素,研究对象被分为正常对照组、骨质减少(osteopenia)以及骨质疏松(osteoporosis)。
3.4 MIMIC数据集[12]
MIMIC-III(Medical Information Mart for Intensive Care III)是大规模的匿名化健康数据库,包括了十余年间超过四千名患者在危重症监护病房的相关记录,包括患者个人信息、生命体征监测数据、实验室监测数据、图像报告等多种病患数据信息。
3.5 ICD-9-CM 编码集[13]
ICD-9-CM(The international classification of disease, ninth revision, clinical modification) 是在临床中将诊断结果编码表示的一种官方标准,包括疾病编码列表,疾病类型分类以及手术、诊断、诊疗手段分类系统。
4.深度病患相似度学习[14]
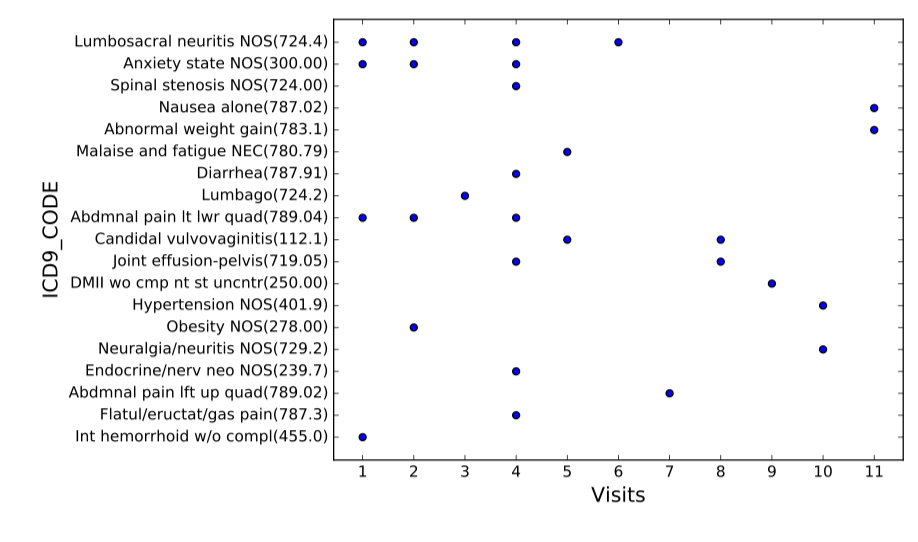
图2 患者数据样例(横轴为病患来访医院序列,纵轴为医疗事件对应的ICD9编码)
Suo等人[14]于2018年在IEEE TRANSACTIONS ON NANOBIOSCIENCE上发表了一种基于深度学习的病患相似度学习方法,模型分为两个模块,分别是表示学习和相似度学习。病患数据是由代表医疗相关事件对应的ICD编码形成的独热编码矩阵,如图2,每名患者对应一个矩阵,横轴代表患者来访医院的时间序列,纵轴为医疗事件对应的ICD9编码,若患者患有疾病或有相关症状,则矩阵对应位置为1。在表示学习中,作者通过全连接层将患者的高维稀疏独热向量矩阵映射到低维稠密空间,并依托卷积神经网络捕捉病患信息的连续的时序特征;对于相似度学习,作者使用基于softmax的有监督分类方法并通过triplet loss使每两个患者对相似的患者距离更近而不相似的患者距离更远,以此在患者聚类任务上实现较好的效果。
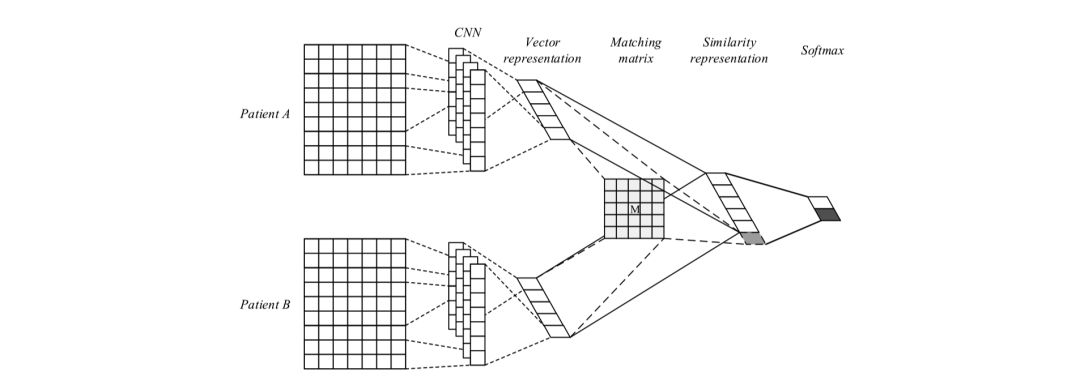
图3 模型结构
5.病患相似度度量的可解释性
在各种病患相似度度量方法被初步探索后,在真实的使用场景下,医疗相关从业人员在关注模型的性能的同时,更加关注模型输出结果过程中的透明度和可解释性。Huai等人[15]因此在BIBM 2020提出了一种为所学习到的病患相似度模型行为提供全局解释的模型无关的方法。一般来说,病患相似度的研究工作可能包括数十种特征,作者认为通过筛选选择众多特征中数量最少且足以解释模型判断结果的特征子集作为解释模型判断的依据可以很好地为实际场景下的相关人员提供参考。对于数据集中的患者个体,每两个患者间即可计算一次相似度,相似度结果一般为相似或相异,而当随机减少数据集中的特征数量后重新计算每两个患者间的相似度,结果会产生一定的变化,而通过量化评估这一变化即可评价去除的特征的重要性,并以此作为该特征在度量病患间相似度时的贡献程度。
6.病患数据安全
在数据驱动的病患相似度度量方法不断发展的同时,方法背后所使用数据的安全性也逐渐成为了患者、医疗机构以及相关监管部门关心的话题,同时很多医疗机构出于对患者个人信息的保护,不愿将敏感的医疗相关数据对研究人员开放,在这种背景下,在不访问所有人数据的前提下进行模型学习成为了解决这一数据安全问题的前提。Huai等人[16]在SDM 2018上,在提出不相关特征提取模型的前提下,还考虑了上述数据安全问题,进而提出了分布式病患相似度度量模型,即分布在不同地点的数据在进行度量模型学习时,只将学习得到的参数上传学习器,而学习器通过对全局参数进行优化迭代将结果回传至每个节点进行迭代直至全局收敛。Xu等人[17]在AAAI 2019的工作中将联邦学习(Federated Learning)方法引入病患相似度度量工作,实现在数据本地保存的同时完成模型的训练,并通过最小化相似度留存损失以及异质信息损失进而同时保留同类与异类数据间的关系。
说个正事哈
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方“深度学习自然语言处理”,进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心 。
。
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
整理不易,还望给个在看!
参考资料
[1]
Kohane, Isaac S. "Ten things we have to do to achieve precision medicine." Science 349.6243 (2015): 37-38.
[2]Parimbelli, Enea, et al. "Patient similarity for precision medicine: A systematic review." Journal of biomedical informatics 83 (2018): 87-96.
[3]Allam, Ahmed, et al. "Patient Similarity Analysis with Longitudinal Health Data." arXiv preprint arXiv:2005.06630 (2020).
[4]陈彦靓, 田茂再. 关于纵向数据分析方法的比较研究[J]. 统计与决策, 2013(10):23-26.
[5]UCI 数据集. https://archive.ics.uci.edu/ml/datasets.php
[6]UCI 帕金森氏症数据集. https://archive.ics.uci.edu/ml/datasets/parkinsons
[7]UCI 心脏病数据集. https://archive.ics.uci.edu/ml/datasets/heart+disease
[8]UCI 糖尿病数据集. https://archive.ics.uci.edu/ml/datasets/diabetes
[9]UCI 癌症数据集. https://archive.ics.uci.edu/ml/datasets/breast+cancer
[10]ADNI数据集. http://adni.loni.usc.edu
[11]SOF 数据集. https://sofonline.epi-ucsf.org/interface
[12]MIMIC 数据集. https://mimic.physionet.org
[13]ICD-9编码. https://www.cdc.gov/nchs/icd/icd9cm.htm
[14]Suo, Qiuling, et al. "Deep patient similarity learning for personalized healthcare." IEEE transactions on nanobioscience 17.3 (2018): 219-227.
[15]Huai, Mengdi, et al. "Global Interpretation for Patient Similarity Learning." 2020 IEEE International Conference on Bioinformatics and Biomedicine (BIBM). IEEE, 2020.
[16]Huai, Mengdi, et al. "Uncorrelated patient similarity learning." Proceedings of the 2018 SIAM International Conference on Data Mining. Society for Industrial and Applied Mathematics, 2018.
[17]Xu, Jie, et al. "Federated patient hashing." Proceedings of the AAAI Conference on Artificial Intelligence. Vol. 34. No. 04. 2020.
本期责任编辑:刘 铭
本期编辑:朱文轩

