
- 1海康威视-下载的录像视频浏览器播放问题_海康录像机导出来的视频不能播放
- 2OWASP Top 10 详细解读_owasp top 10介绍
- 3DL相关基础概念-待补充_数据处理层dl
- 4MySQL高级-MVCC- readview介绍
- 5huggingface 本地模型加载报错 Error no file named pytorch_model.bin, tf_model.h5, model.ckpt.index or flax_mo_model is not found as a file or in hugging face, p
- 6在k8s中部署单机版Elasticsearch,并进行数据持久化_elasticsearch有数据持久化吗
- 7Hadoop 教程 - Hadoop YARN Fair Scheduler公平调度器深入研究
- 8基于bert的文本匹配任务(二)_bert 中文文本匹配任务
- 9直接插入排序算法的C++实现
- 10关于NACHI机器人语言程序的反编译_那智什么语言
虹软人脸识别SDK接入Milvus实现海量人脸快速检索_milvus c++jiekou
赞
踩
背景
人脸识别是近年来最热门的计算机视觉领域的应用之一,而且现在已经出现了非常多的人脸识别算法,如:DeepID、FaceNet、DeepFace等等。人脸识别被广泛应用于景区、客运、酒店、办公室、工地、小区等场所,极大的方便了人们的生活。在安防领域,人脸识别也展现出巨大的活力,通过人脸识别对摄像头采集的图像进行处理,可以更快的发现可以人员。
1:1人脸核验通常不会过度考虑速度问题,而1:N的人脸识别场景有的时候速度是非常重要的。比如用户想通过人脸识别快速确定图片中的明星是谁,而后台的明星数据库中有几百万甚至几千万的数据,一一对比将很难在短时间内返回结果,在高并发的时候更是非常占用资源。所以使用向量近似搜索将在大规模的人脸识别场景中显得非常重要。
虹软SDK及Milvus简介
虹软人脸识别SDK是一款集人脸检测、人脸跟踪、人脸比对、人脸查找、人脸属性、IR/RGB活体检测多项能力于一身的离线人脸识别SDK。支持Windows,Linux,Android等多个平台。支持离线服务,可在无网络环境下使用,本地化部署。有增值版很免费版两个版本。

Milvus 是一款开源的向量相似度搜索引擎,提供了Python、Java、Go、C++、RESTful 等API接口,支持针对 TB 级向量的增删改操作和近实时查询,具有高度灵活、稳定可靠以及高速查询等特点。Milvus 集成了 Faiss、NMSLIB、Annoy 等广泛应用的向量索引库,提供了一整套简单直观的 API,让你可以针对不同场景选择不同的索引类型。此外,Milvus 还可以对标量数据进行过滤,进一步提高了召回率,增强了搜索的灵活性。
开发环境
本文中虹软SDK使用C++调用,Milvus使用Python API。如需使用C++版本的Milvus API 请自行编译。
本文代码所需环境:
- 虹软人脸识别SDK4.0增值版
- Milvus 1.0.0
- OpenCV 2.4.9
- VS 2013
- Python 3.6 +(低于3.6可能无法安装pymilvus)
虹软人脸识别SDK使用简介
虹软人脸识别SDK使用非常简单。对于一般的人脸识别流程:
- 调用
ASFOnlineActivation在线激活,激活后会生成激活文件,下次再运行就不用再次激活了。 - 调用
ASFInitEngine初始化引擎,在这里可以选择人脸检测模式或人脸追踪模式(人脸追踪更快)以及传入其他参数。 - 调用
ASFDetectFaces检测人脸,得到一帧图像里所有的人脸框。 - 调用
ASFFaceFeatureExtract提取人脸特征 - 调用
ASFFaceFeatureCompare对两个人脸特征进行对比,返回相似度。

使用虹软SDK的时候需要注意,每次调用ASFDetectFaces、ASFFaceFeatureExtract等接口时保存结果的位置是固定的,并且这个位置是在初始化引擎时就确定好了的,返回的结构仅仅是指向这个位置的一个指针,也就是说下一次调用ASFDetectFaces就会覆盖上一次ASFDetectFaces的结果,如果需要保存上一次的结果,请将这部分内存copy出来。 虹软这样做的好处是函数不会因为申请不到内存而失败,并且不会造成内存泄漏。
这只是最简单的人脸识别流程,除此之外,虹软人脸识别SDK还支持RGB活体识别,IR活体识别,口罩检测,闭眼检测,遮挡检测,图像质量检测等等功能。更多文档参考虹软文档中心
Milvus环境搭建
Milvus最简单的安装方式是通过docker安装。Milvus有CPU版和GPU版,这里以CPU版为例。可以参考Milvus官方参考文档。
https://milvus.io/cn/docs/v1.0.0/milvus_docker-cpu.md
- 安装CentOS或Ubuntu,我使用的这个
https://vault.centos.org/7.4.1708/isos/x86_64/CentOS-7-x86_64-DVD-1708.iso - 安装Docker,使用官方安装脚本自动安装。
curl -fsSL https://get.docker.com | bash -s docker --mirror Aliyun
- 1
- 拉取 Milvus 镜像
sudo docker pull milvusdb/milvus:1.0.0-cpu-d030521-1ea92e
- 1
- 下载Milvus配置文件
mkdir -p /home/$USER/milvus/conf
cd /home/$USER/milvus/conf
wget https://raw.githubusercontent.com/milvus-io/milvus/v1.0.0/core/conf/demo/server_config.yaml
- 1
- 2
- 3
如果无法通过 wget 命令下载配置文件,也可以在 /home/$USER/milvus/conf 目录下创建 server_config.yaml 文件,然后将 server_config.yaml文件 的内容复制到你创建的配置文件中。
5. 启动 Milvus Docker 容器
sudo docker run -d --name milvus_cpu_1.0.0 \
-p 19530:19530 \
-p 19121:19121 \
-v /home/$USER/milvus/db:/var/lib/milvus/db \
-v /home/$USER/milvus/conf:/var/lib/milvus/conf \
-v /home/$USER/milvus/logs:/var/lib/milvus/logs \
-v /home/$USER/milvus/wal:/var/lib/milvus/wal \
milvusdb/milvus:1.0.0-cpu-d030521-1ea92e
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
使用sudo docker ps确认 Milvus 运行状态。
如果Milvus没有正常运行,可以通过sudo docker logs milvus_cpu_1.0.0查看错误日志。如果CPU不支持SSE42、AVX、AVX2、AVX512中的一个,可能无法启动Milvus。
如需安装GPU版,参考GPU版安装
快速检索实现
人脸识别流程简介
前面已经介绍了使用虹软SDK人脸识别的基本流程,现在的人脸识别基本上流程都是一样的这里再简单说明一下一般人脸识别的三个步骤:
1. 人脸检测
给出图像,获取图像中人脸的位置。有的也会获取人脸的一些关键点、角度等信息,用来对人脸进行对齐。
3. 提取特征
将检测出来的人脸图像截取出来,通过神经网络进行特征提取。提取出来的通常是一个128维或者256维的特征向量(通常还会加入归一化等操作)。
4. 特征对比
将上一步提取出来的特征向量进行对比,计算两个向量的距离,再对距离简单的处理就可以得到两个人脸相似度。常见的相似度计算方法有欧氏距离、余弦相似度等。
快速检索
通常1:N人脸搜索最常见的办法是直接暴力搜索,对人脸库中全部人脸都进行对比,找出相似度最高的k个。虹软SDK提供了ASFFaceFeatureCompare来对两个人脸特征向量进行对比。如果人脸库过大,搜索的速度无疑会变慢,在一些对实时性要求高的场景下将很难有好的表现。通过一些向量相似度搜索的算法,可以在短的时间内对大量数据进行相似度计算,找出相似度最高的。本文使用虹软人脸识别SDK进行人脸检测和人脸特征提取。提取出来的人脸特征向量使用Milvus进行检索。
虹软SDK如何获取特征向量
废话不多说,直接上结果。
C++版本虹软SDK中,人脸特征使用结构体ASF_FaceFeature结构体存储。
typedef struct {
MByte* feature; // 人脸特征信息
MInt32 featureSize; // 人脸特征信息长度
}ASF_FaceFeature, *LPASF_FaceFeature;
- 1
- 2
- 3
- 4
查看多个feature指向的内存,稍微对机器学习有过了解的人就可以很容易的发现规律,这些数据除了前两个整数,后面的都是的浮点数,明显是经过归一化后的特征向量。
结论:feature指向的是一个float类型的数组。前8个字节固定是浮点数类型的2004,78(可能用于区别SDK的不同版本) 。后面的2048个字节是512个浮点数。如果ASFFaceFeatureExtract设置的registerOrNot参数为false,那么这512个数据的前256个是0。

**另外,如果registerOrNot设置为false的话,前256个特征向量全部为0,可以忽略。我们只需要把后256个特征向量复制出来就可以了。
//registerOrNot设置为false时,只复制后256个向量即可
float data[256];
memcpy(data, f.feature + 8 + 1024, 1024);
- 1
- 2
- 3
到这里我们已经获取到了虹软SDK提取出来的人脸特征向量。
批量提取特征向量并插入Milvus
将CelebA数据集里面的人脸照片提取出特征向量并保存到文件中。如果使用多线程提取的话,最后copy /b *.txt res.txt即可合并成一个。
#include "FaceEngine.h" #include <string> #include <atomic> #include <fstream> #include "TP.cpp" #include <windows.h> atomic_int n = 0; void task(int start, int end , int index) { ofstream save("D:/Face/feature/" + to_string(index) + ".txt"); //调用前请先确保已经激活 FaceEngine x(ASF_DETECT_MODE_IMAGE, ASF_OP_0_ONLY, 1); char file[50] = { 0 }; for (int i = start; i <= end; i++) { sprintf(file, "D:/Face/img_celeba/%06d.jpg", i); Mat img = imread(file); auto faces = x.DetectFace(img); if (faces.faceNum == 1) { auto face = x.GetSingleFace(faces,0); auto f = x.GetFaceFeature(img,face); float data[256]; memcpy(data, f.feature + 8 + 1024, 1024); save << i << "|"; for (int u = 0; u < 256; u++) save << data[u] << "|"; save << endl; } n++; } } int main() { ThreadPool pool(2); pool.AddTask(bind(task, 1, 100000, 1)); pool.AddTask(bind(task, 100001, 202599, 2)); while (n < 202599) { cout << "\r" << n << "\t" << n * 100 / 202599 << "\t"; Sleep(1000); } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
为了简化虹软SDK的使用,我对SDK简单封装了一下,还有一个简单的线程池实现,可以在文末链接下载。
上面已经将特征向量保存到txt中了,接下来将20万特征向量插入Milvus(20万数据量有点少,不过由于我的电脑配置较低,提取20万个人脸的特征向量花了接近2个小时,这里就不添加过多数据了。有条件的话可以添加更多数据。)。也可以通过编译Milvus的C++ SDK,提取插入一步到位。
首先安装一下pymilvuspip3 install pymilvus==1.0.1
from milvus import Milvus, IndexType, MetricType, Status import numpy as np m = Milvus(host='IP', port='19530') # 创建collection param = { 'collection_name':'face', 'dimension':256, 'index_file_size':256, 'metric_type':MetricType.IP #相似度计算方式使用內积 } print(m.create_collection(param)) num = 200000 step = 5000 now = 0 def GetBatch(data): global now ids = np.zeros(step,dtype=np.int32) vects = np.zeros((step,256),dtype=np.float32) for i in range(step): tmp = data[i+now].split("|") ids[i] = int(tmp[0]) for u in range(256): vects[i][u] = float(tmp[u+1]) now += step return ids.tolist() , vects.tolist() # 将所以人脸向量插入Milvus data = open("G:\\feature\\res.txt").readlines() for i in range(int(num / step)): ids , vs = GetBatch(data) res = m.insert(collection_name='face', records=vs, ids=ids) print(i)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
这里要注意的是,Milvus的Python SDK插入时使用的是list,numpy创建的数据需要使用tolist()来转成list
默认插入后是使用的FLAT索引(暴力搜索),暴力搜索的速度最慢,但召回率为100%,如果数据量很大,可以通过建立其他的索引来加快检索速度。在CPU上查询常见的索引有:

了解更多索引,参考Milvus官方文档
创建索引:
# `ivf_param` 是创建索引的参数,`IVF_FLAT`是索引类型。
ivf_param = {'nlist': 16384}
print(m.create_index('face', IndexType.IVF_FLAT, ivf_param))
- 1
- 2
- 3
查询
data = open("G:\\feature\\res.txt").readlines()
ids , vs = GetBatch(data)
idx = int(input("index:")) # 输入一个下标,从Batch中取出第idx个进行查询
print("id:" , ids[idx]) # 输出下标为idx的特征向量的id,这里的id就是文件名。14就是CelebA数据集中的000014.jpg
search_param = {'nprobe': 16}
res = m.search(collection_name='face', query_records=[vs[idx]], top_k=3, params=search_param)
print(res)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
查询batch里面随便一项得到结果:
index:12
id: 14
(Status(code=0, message='Search vectors successfully!'), [
[
(id:14, distance:1.0000004768371582),
(id:39306, distance:0.8084499835968018),
(id:109420, distance:0.776871919631958)
]
])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
Milvus搜索到的tok3个相似度最高的id是14、39306、109420(id就是文件名编号,14就是000014.jpg)。14就是这个文件本身,所以计算出来內积为1,39306和109420的內积分别是0.8084、0.7769。这三个id对应的图片分别是:

可见,Top3的人脸确实为同一个值。可以根据计算出来的distance设置一个阈值来判断是否为同一个人。阈值可以设置为0.55-0.6左右,有需要的话可以自行测试确定一个更合适的阈值。
性能说明
使用虹软SDK的ASFFaceFeatureCompare接口单线程检索20万人脸需要156ms。Milvus(运行在虚拟机中)使用默认FLAT索引,检索20万人脸需要168ms,建立IVF_FLAT 索引并且搜索nprobe设置为16时耗时70ms。
在高并发场景下,使用GPU版的Milvus可以很大程度的减少搜索时间,并且可以通过设置参数获得一个理想的召回率。但是在低并发且数据量少的时候,推荐之间使用ASFFaceFeatureCompare接口。
补充
关于相似度计算方式,Milvus中常用的有两种:
- 欧氏距离 (L2)
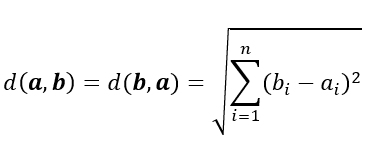
- 内积 (IP)
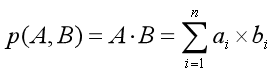
当向量归一化后,这两种计算方式是等价的。虹软SDK提取的人脸特征是经过归一化的,所以选择这两种计算方式都是可以的。
全部代码已经上传github
https://github.com/Memory2414/milvus-arcface
如果你连OpenCV环境也懒得配置,也可以在这里下载已经配置好的虹软SDK和OpenCV的环境(VS2013),提取码:atkw。

