
- 1猫头虎分享2023年12月17日博客之星候选--城市赛道博主文章数据
- 2物联网技术-第3章-物联网感知技术-3.1标识技术_物联网 标识 一维码和二维码
- 3数据结构之二叉树(详细版)_创建二叉树的代码数据结构
- 4推荐开源项目:Pritunl Docker 容器化企业级VPN解决方案
- 5游戏建模控件Aspose.3D for Java最新版支持在Wavefront OBJ中添加点云支持
- 6【特别篇】【单机部署】zabbix7 lts+postgresql+timescaleDB源码部署_zabbix7.0lts部署
- 7利用vue-codemirror展示编辑json数据_vue-codemirror json
- 8Cron表达式详解_cron 每个月15号执行
- 9100 个网络基础知识普及,看完成半个网络高手_bcos是什么意思
- 10新安全生产知识竞赛活动-闯关答题挑战_安全闯关 关卡
【论文讲解】CMT: Convolutional Neural Networks Meet Vision Transformers
赞
踩
CMT: Convolutional Neural Networks Meet Vision Transformers
Jianyuan Guo, Kai Han, Han Wu, Yehui Tang, Xinghao Chen, Yunhe Wang, Chang Xu School of Computer Science, Faculty of Engineering, University of Sydney. Huawei Noah’s Ark Lab.
CVPR 2022
IEEE Conference on Computer Vision and Pattern Recognition
目录
1)Local Perception Unit(局部感知单元)
2)Lightweight Multi-head Self-attention (轻量级的多头注意力机制)
3)Inverted Residual Feed-forward Network (反向残差前馈网络)
2)Ablation Study——Stage-wise architecture.
2)Ablation Study——Scaling strategy
1 Abstract
Vision Transformer已经成功地应用于图像识别任务,因为它能够捕获图像中的随机依赖关系。然而,Transformer和现有的CNN之间在性能和计算成本方面仍然存在差距。 本文提出的CMT,在性能和计算成本上均优于Transformer和CNN模型。CMT是一种基于Transformer的混合网络,利用Transformer捕获远程依赖,利用CNN提取局部信息。 CMT与CNN和基于Transformer的模型相比,在准确性和效率方面获得了更好的权衡:CMT-S在ImageNet上达到了83.5%的top1精度,而在FLOPs上比现有的DeiT和EfficientNet分别小14倍和2倍。 本文提出的CMT-S也适用于CIFAR10(99.2%)、CIFAR100(91.7%)、Flowers(98.7%)、COCO(44.3% mAP)等数据集,同时计算成本要小得多。
2 Introduction
尽管Transformer在迁移到视觉任务时表现出了出色的能力,但它们的性能仍然远远低于类似大小的卷积神经网络。作者认为,有以下三点原因: 1)在ViT 和其他基于Transformer的模型中,将图像分成patch,它忽略了基于序列的NLP任务和基于图像的视觉任务之间的根本区别,即在每个patch分块中的2维结构和空间局部信息。 2)由于patch大小的固定,Transformer难以明确提取低分辨率和多尺度的特征,这给检测和分割等密集的预测任务带来了很大的挑战。 3)与基于CNN的O(NC^2)相比Transformer中自注意模块的计算和存储成本是输入分辨率的平方倍(O(N^2C)),使用Transformer来处理这些图像将不可避免地会导致GPU内存不足和计算效率低的问题。
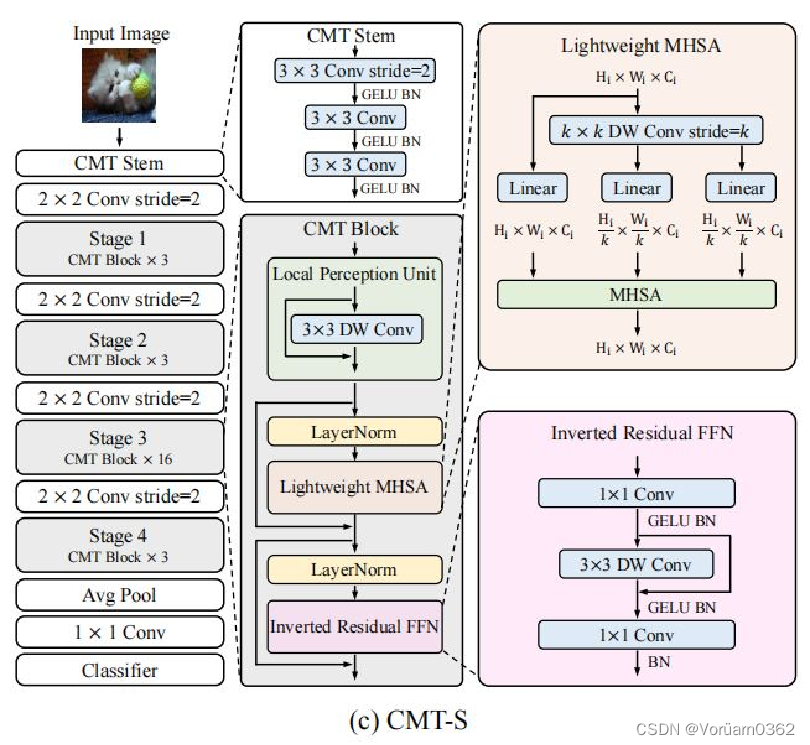
输入图像首先通过卷积杆进行细粒度特征提取,并分别为然后被输入到一堆CMT块中进行表示学习。具体来说,引入的CMT块是Transformer块的一种改进变体,其局部信息通过深度卷积得到增强。 与ViT相比,CMT第一阶段生成的特征可以保持更高的分辨率,即H/4×W/4/ViT中的H/16×W/16,这对于其他密集预测任务是必不可少的。此外,本文采用了类似于CNNs [16,46,53]的阶段级体系结构设计,采用了具有步幅2的四个卷积层,逐步降低分辨率(序列长度),灵活地增加维度。 阶段性设计有助于提取多尺度特征,减轻高分辨率带来的计算负担。CMT块中的局部感知单元(LPU)和反向残差前馈网络(IRFFN)有助于捕获中间特征中的局部和全局结构信息,提高网络的表示能力。最后,利用平均池化来替换ViT中的类标记,以获得更好的分类结果。
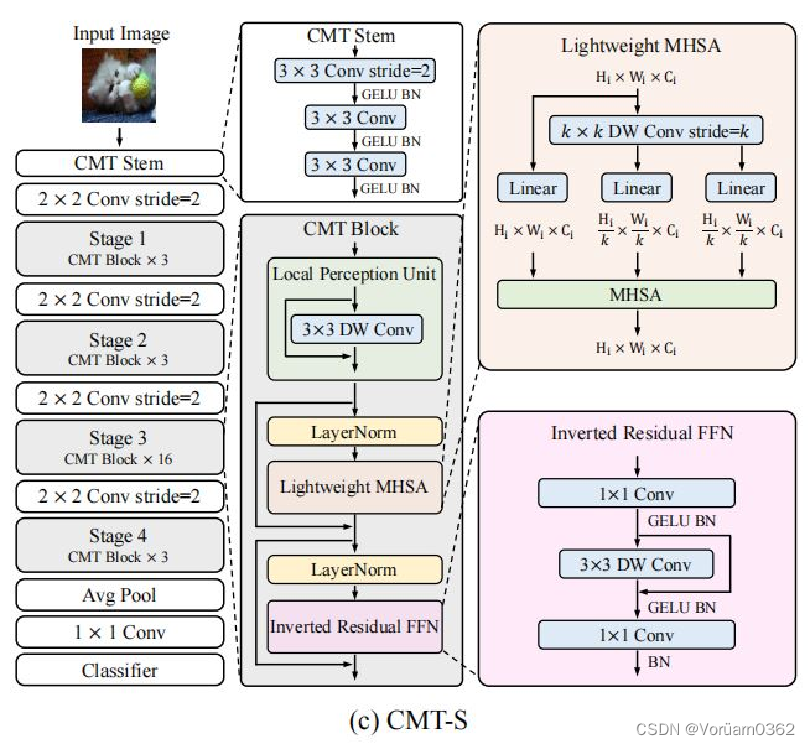
3 Approach
给定一个输入图像,我们可以得到四个不同分辨率的层次特征图,类似于典型的cnn。利用上述特征图的输入步幅分别为4、8、16和32,我们的CMT可以获得输入图像的多尺度表示,并可以很容易地应用于目标检测和语义分割等下游任务。
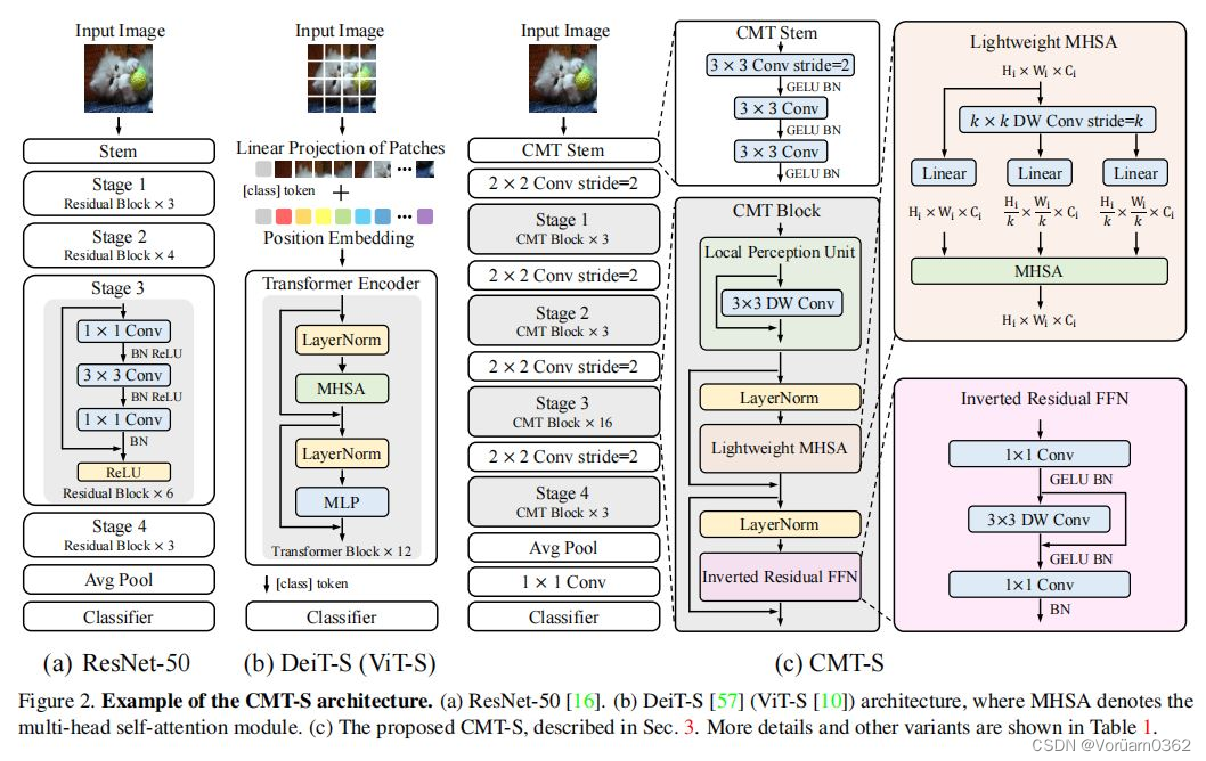
CMT模型的核心是CMT Block,其主要由以下几个模块构成:
1)Local Perception Unit(局部感知单元)
2)Lightweight Multi-head Self-attention(轻量级的多头注意力机制)
3)Inverted Residual Feed-forward Network(反向残差前馈网络)
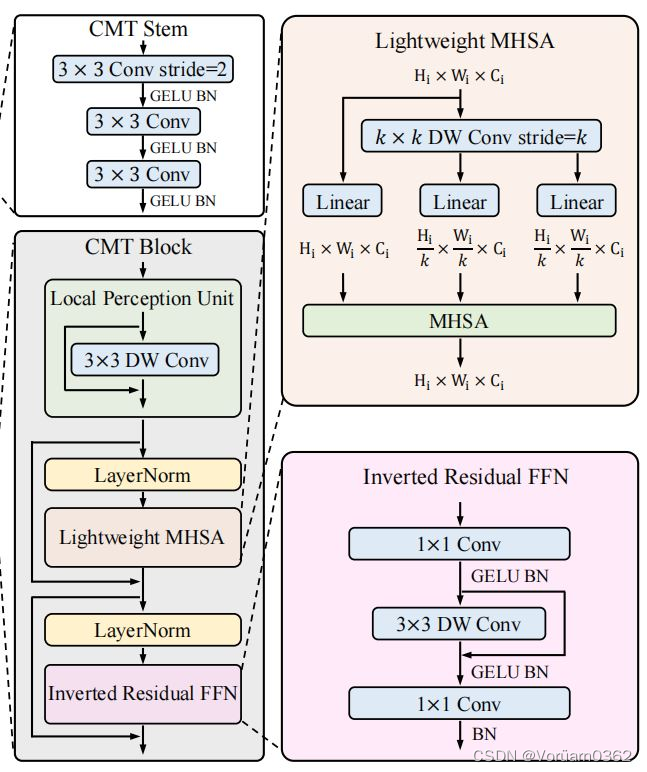
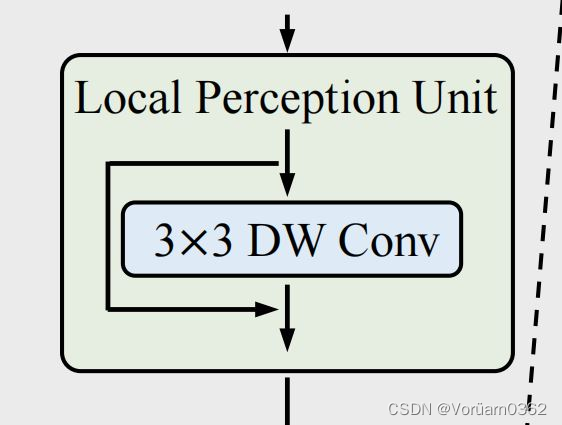
1)Local Perception Unit(局部感知单元)
架构如上图,公式定义如下图。 本质就是,将输入图片信息,与 3*3 的卷积操作后相加,旨在增加了空间信息,可以和 ViT 的绝对位置编码的对应理解。
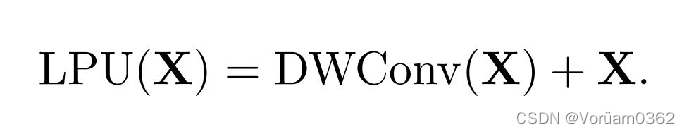
2)Lightweight Multi-head Self-attention (轻量级的多头注意力机制)
在原始的self-attention模块中,输入 X 被线性变换为 query、key、value 再进行计算,运算成本高。
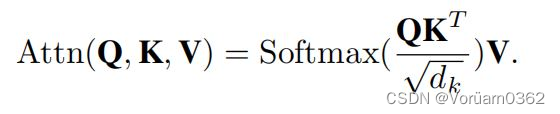
此模块主要功能就是使用深度卷积计算代替了 key 和 value 的计算,从而减轻了计算开销。
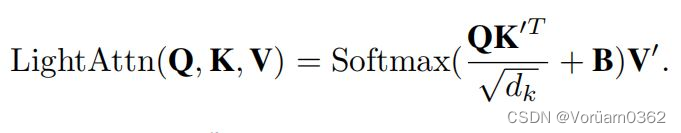
3)Inverted Residual Feed-forward Network (反向残差前馈网络)
反向残差前馈网络(IRFFN)类似于反向残差块,由扩展层、深度卷积和投影层组成。具体来说,我们改变了快捷方式连接的位置,以获得更好的性能。 其中,省略了激活层。深度卷积用于提取局部信息,而额外的计算成本可以忽略不计。插入快捷方式的动机与经典的残差网络相似,可以提高梯度跨层的传播能力。
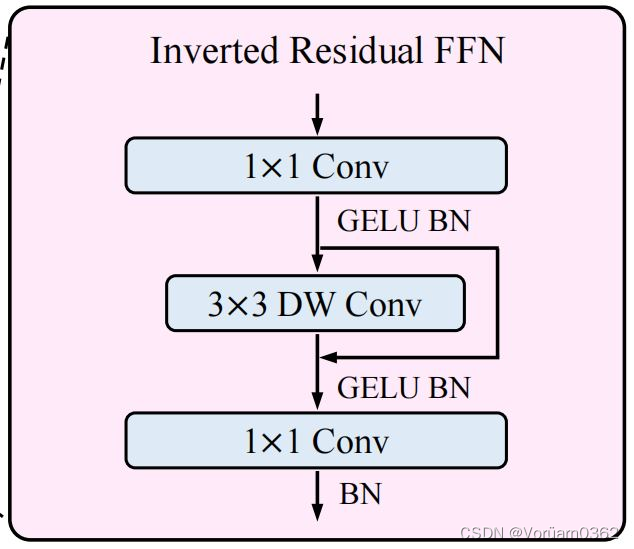
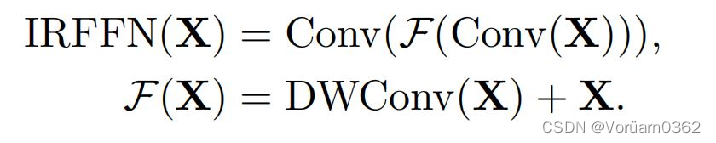
4 Experiments
本文在图像分类、目标检测和实例分割等多个任务上进行实验,来研究CMT体系结构的有效性。 为了与最近的工作进行公平的比较,作者采用了与DeiT 相同的训练和增强策略,使用AdamW优化器训练模型300个周期(CMT-Ti为800个,需要更多的周期来收敛)。所有模型都在8台NVIDIA Tesla V100 GPU上进行训练。
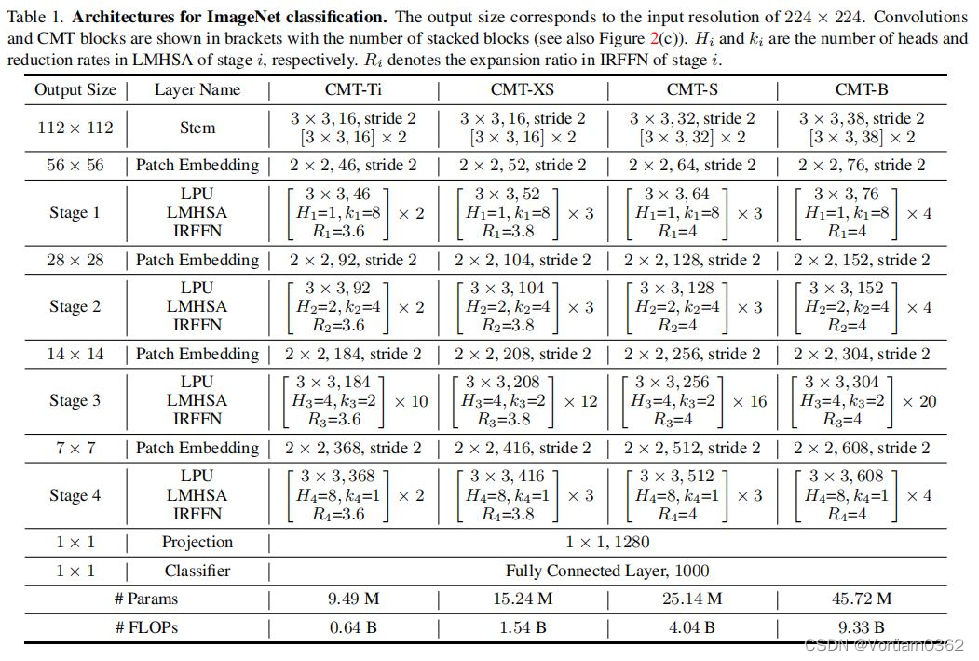
1)ImageNet Classification
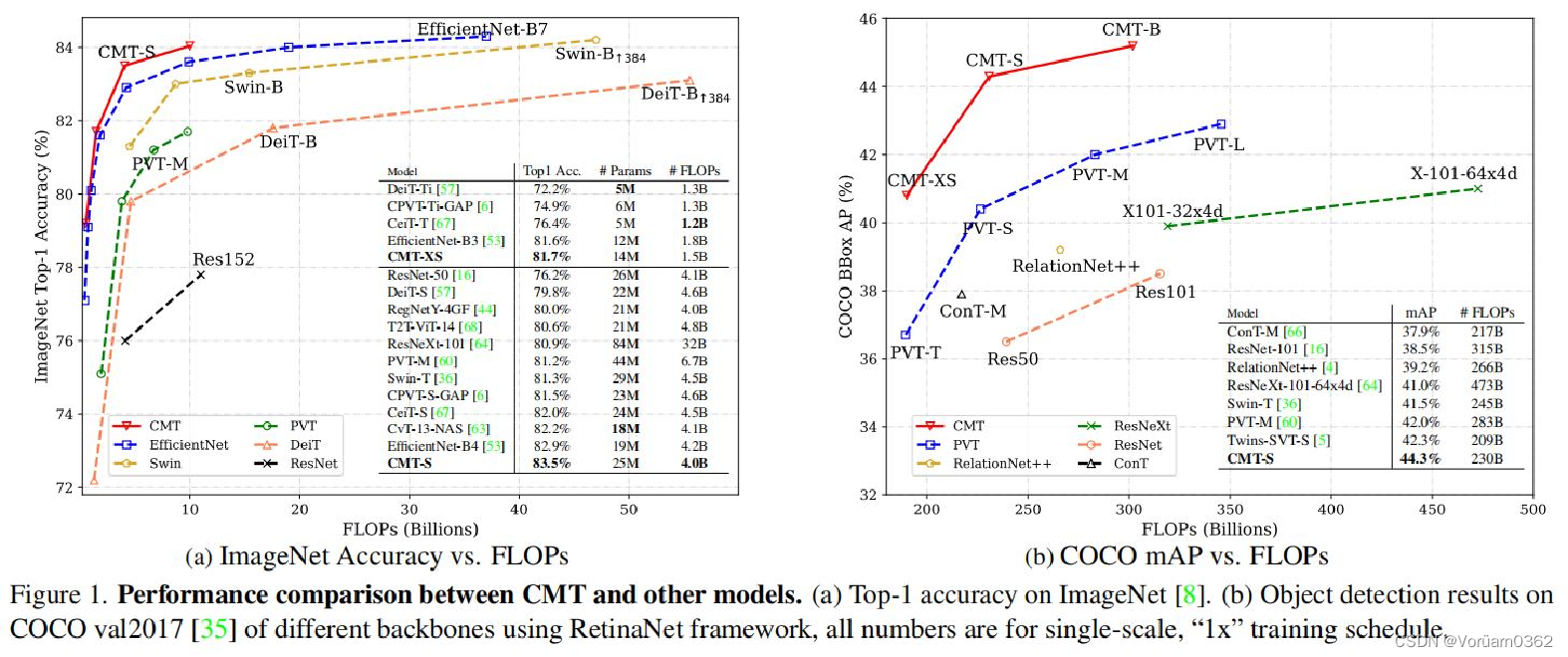
与其他基于卷积和Transformer的模型相比,本文的CMT模型在更少的参数和FLOPs(floating point operations,浮点运算数)下获得了更好的精度。 之前所有基于Transformer的模型仍然不如通过彻底的架构搜索(NAS)获得的EfficientNet,然而,本文的CMT-S比Efficient-B4高0.6%,计算成本更低,这证明了本文提出的混合结构的有效性,并显示出很强的进一步改进潜力。

2)Ablation Study——Stage-wise architecture.
阶段式结构的消融研究:基于Transformer的ViT/DeiT只能生成单尺度特征图,丢失了大量对密集预测任务至关重要的多尺度信息。本文将柱状的DeiT-S阶段改为分层的DeiT-S-4阶段,同时保持了原来的FFN。本文还将MHSA更改为LMHSA,以降低计算成本。如表3所示,DeiT-S-4阶段在较少的FLOPS下比DeiT-S高出1.6%,说明在CNN中广泛采用的阶段设计是促进基于变压器的架构的更好选择。

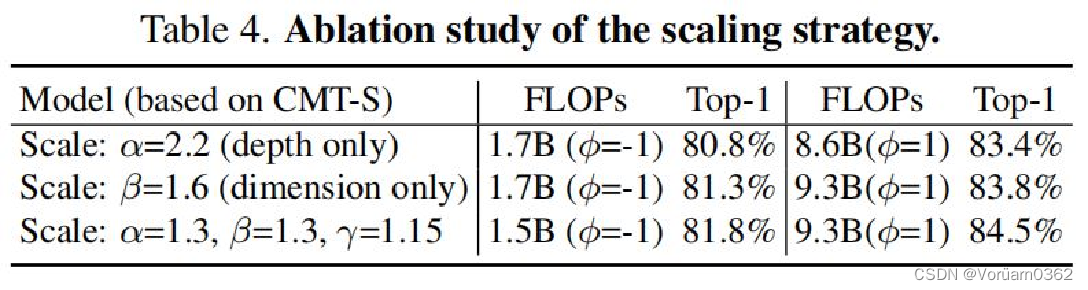
2)Ablation Study——CMT block
CMT中不同模块的消融情况如表5所示。DeiT-S-4Stage有4个补丁嵌入层(第一层是4×4与步幅4的卷积)。““+Stem”表示我们将CMT茎添加到网络中,用2×2的卷积替换第一个补丁嵌入层。这一改进显示了基于卷积的阀杆的好处。此外,提出的LPU和IRFFN可以进一步提高网络0.8%和0.6%。值得注意的是,LPU和IRFFN中的快捷连接对最终的性能也至关重要。
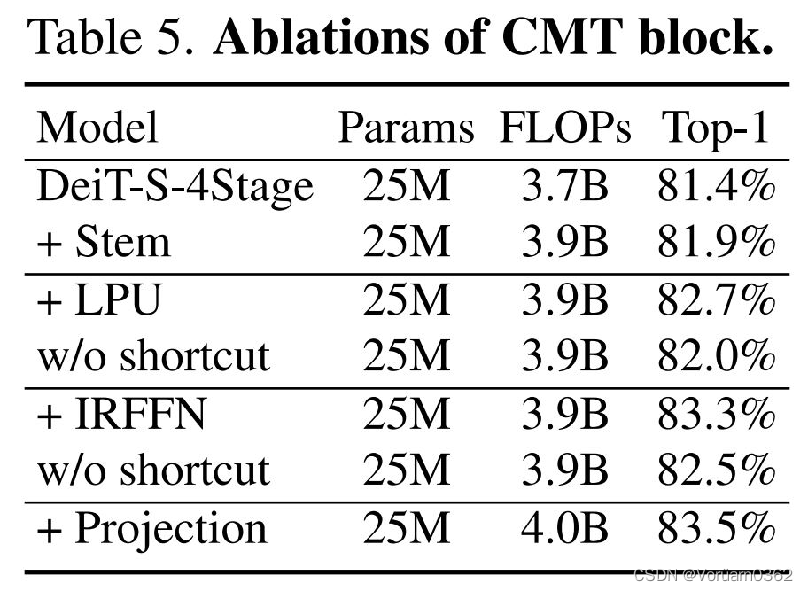
2)Ablation Study——Scaling strategy
表4显示了不同尺度策略下CMT架构的ImageNet结果。单维缩放策略明显低于所提出的复合缩放策略,特别是对于仅深度缩放策略,当网络被放大时,其结果为83.4%,而原始CMT-S为83.8%。
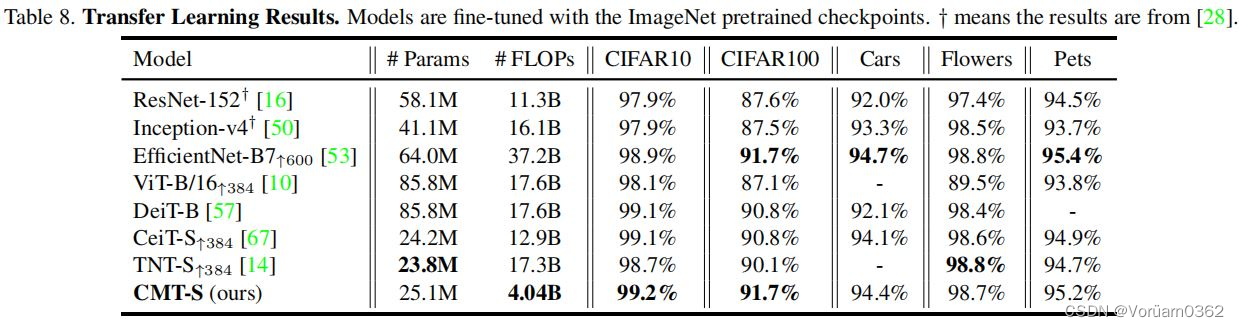
3)Transfer Learning
本文使用两个典型的框架来评估所提出的CMT-S:分别是RetinaNet和Mask R-CNN,用于目标检测和实例分割。具体来说,用CMT-S替换了原来的骨干网络来构建新的检测器。所有的模型都是在PVT之后的标准单尺度和“1x”时间表(12个epoch)下进行训练的。
(左图RetinaNet,右图Mask RCNN)
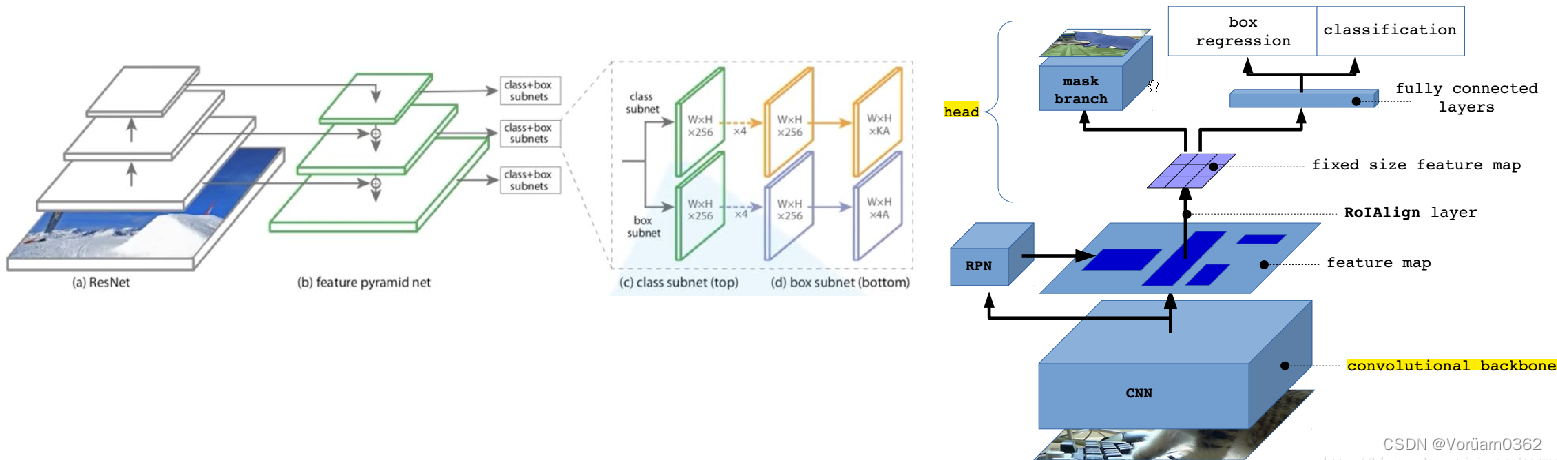
对于以RetinaNet为基础框架的目标检测,CMT-S-S的性能优于Twins-PCPVT-S,平均精度比Twins-SVT-S高2.0%。
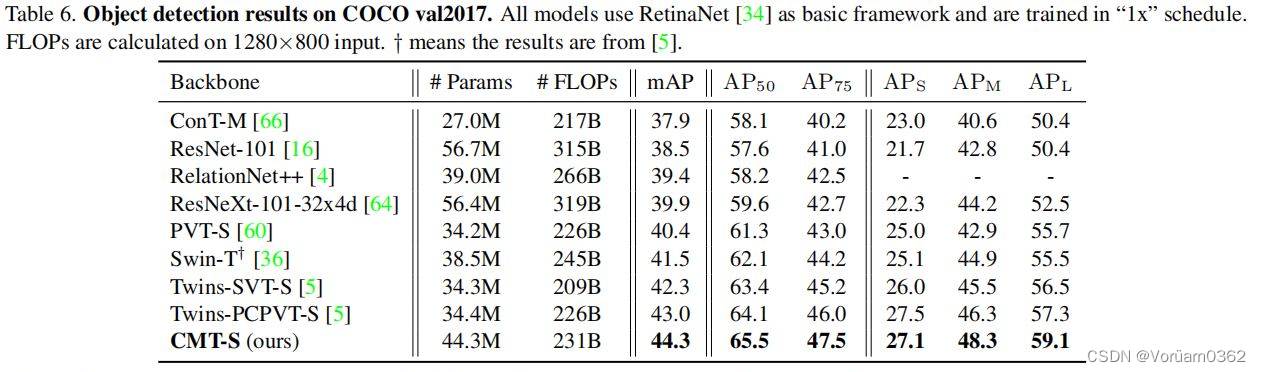
以Mask RCNN为基本框架的实例分割任务中,CMT-S超过Twins-PCPVTS 1.7%,超过Twins-SVT-S 1.9%。
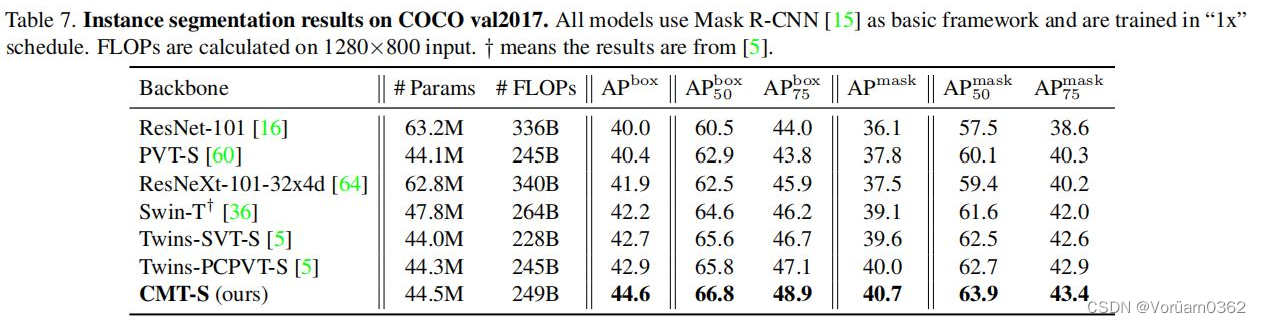
本文还报告了在COCO val2017上,输入量为1280×800、基于CMT-S的RetinaNet和Mask RCNN分别实现14.8 FPS和11.2 FPS的推理速度。
5 Conclusion
- 本文提出了一种新的混合架构CMT,用于视觉识别和其他下游计算机视觉任务,如目标检测和实例分割,并解决了在计算机视觉领域以残酷的强制方式利用Transformer的局限性。
- 所提出的CMT架构同时利用cnn和Transformer来捕获局部和全局信息,提高了网络的表示能力。 还提出了一种扩展策略来生成一个适用于不同资源约束的CMT变量族。
- 在ImageNet和其他下游视觉任务上进行的大量实验证明了所提出的CMT架构的有效性和优越性。

