
- 1关于ROS中对moveit和gazebo联动出现的问题进行解决_rosnoetic让moveit和gazebo联动
- 2数据结构-线性表_线性表的顺序存储结构和链式存储结构分别是
- 3了解哈希冲突_hash冲突产生的原因
- 4『App自动化测试之Appium应用篇』| uiautomator + accessibility_id定位方法完全使用攻略_appium中bounds [915,1941][1023,2049]右下角是那部分
- 5nlp的四大任务什么_nlp四大基本任务
- 6【动手学深度学习】使用块的网络(VGG)的研究详情
- 7人脸识别4-百度商用方案调研_人脸识别有源和无源的区别
- 8基于SpringBoot+Vue的酒店管理系统设计与实现_基于springboot+vue 酒店客
- 9MySQL8.0窗口函数_mysql窗口函数lead
- 10应用层协议:VPN协议
数据仓库技术及应用(高级操作)
赞
踩
Hive数据关联操作
一、SELECT语句
Hive查询即是SELECT语句
用于对表中的数据进行查询 按照规定的语法规则从表中选取数据
基本语法结构如下
- SELECT [ALL|DISTINCT] select_expr,select_expr,…
- FROM table_reference
- [WHERE where_condition]
- [GROUP BY col_list]
- [ORDER BY col_list]
- [CLUSTER BY col_list|[DISTRIBUTE BY col_list] [SORT BY col_list]]
- [LIMIT[offset,]rows]
1.WHERE 子句
WHERE条件必须是布尔表达式,用于过滤结果集。
常用条件表达式
| 条件表达式 | 操作数类型 | 描述 |
| A=B | 基本类型 | A与B相等返回TRUE,否则返回FALSE |
| A!=B | 基本类型 | A与B不相等返回TRUE,否则返回FALSE,如果A或B为空返回NULL |
| A(>/</>=/<=)B | 基本类型 | 比较运算符所返回的内容,符合条件返回TRUE,否则返回FALSE |
| A IS [NOT] NULL | 所有类型 | A为空时返回TRUE,否则返回FALSE,可使用NOT反转 |
| A [NOT] LIKE B | 字符串类型 | A为字符串,B为标准,如’abc’ like ‘a*’, ’abc’ like ‘a%’,’abc’ like ‘a__’均可返回TRUE,可使用NOT反转 |
| A RLIKE B | 字符串类型 | 使用正则表达式匹配,A为字符串,B为正则表达式,匹配上返回TRUE |
| A AND B | 布尔类型 | A,B均为TRUE返回TRUE,否则返回FALSE |
| A OR B | 布尔类型 | A或B为TRUE返回TRUE,否则返回FALSE |
| NOT A | 布尔类型 | A为FALSE,返回TRUE,否则返回FALSE |
| !A | 布尔类型 | 同NOT A |
| A [NOT] IN (val1,val2,….) | 基本类型 | A如果出现在值集合中则返回TRUE,未出现返回FALSE,可使用NOT反转 |
- # 所有年龄大于20岁的学生
- select * from where age > 20 ;
- # 所有年龄不等于20岁的学生
- select * from where age != 20 ;
- -- and (当有多个条件的时候,表示多个条件必须同时成立)
- -- 20和30之间的所有学生信息
- select * from students where age > 20 and age <=30;
- -- or (当有多个条件的时候,满足任意一个条件都可以)
- -- 20以上或者身高高过180(包含)以上
- select * from students where age > 20 or height >= 180;
2.ALL、DISTINCT、LIMIT子句
- ALL和DISTINCT子句表示是否返回重复行,默认是ALL,返回所有匹配行。
- DISTINCT子句可以返回删除结果集中的重复行。
- LIMIT子句用于限制SELECT语句返回的行数 ,其后的整型参数表示共返回多少行。
- # 名为 orders 的表中选择所有不同的 order_customer_id。即,它会返回表中 order_customer_id 列中所有唯一的值,确定哪些不同的客户在该表中下了订单
- select distinct order_customer_id from orders;
- # 返回 products 表中前五条记录的 product_id 和 product_name 列的值
- select product_id,product_name from products limit 5;
3.CTE(common table expressions)
- CTE也称公共表表达式
- 它可以表示一个临时的结果集(表),该表由一个简单的查询指定,只要在CTE语句范围内均可共享该临时表。
- # CTE语法
- WITH t1 AS(SELECT …) SELECT * FROM t1;
4.嵌套查询
也称为子查询,通常用于FROM子句之后。
- # 嵌套查询语法
- SELECT … FROM (subquery) [AS] name …
嵌套查询的常见规则
- 必须给定名称,因为FROM子句中每个表必须有表名
- 列必须有唯一的名称,并且在外部查询中可以引用
- 可以进行UNION、JOIN操作
- Hive支持任意级别的子查询
5.列匹配正则表达式
- Hive SELECT语句支持使用正则表达式指定列名称
- 凡是符合正则表达式规则的列名将被视作结果集中一列
- 列匹配正则表达式语法
- SELECT ‘regex_expr’ FROM table_reference
- #需要设置”hive.support.quoted.identifiers”属性为”none”
6.虚拟列
虚拟列是并未在表中真正存在的列 ,但对应数据进行相关验证时非常有用。Hive的两个常用虚拟列介绍如下:
- INPUT__FILE__NAME,包含Mapper任务运行时的输入文件名,即该行数据在哪个文件夹中
- BLOCK__OFFSET__INSIDE__FILE,包含文件中的块内偏移量。其中"__"是两个下划线。
二、Hive 关联查询
- 关联查询是指对多表进行联合查询
- 主要通过JOIN语句将多个表中的行组合查询
- hive JOIN仅支持等值连接
常见关联查询
- 内连接(INNER JOIN):用于按连接条件组合两个表的记录, 返回两个表的交集。
table_reference [INNER] JOIN table_factor [join_condition]
外连接(OUTER JOIN):分为左外连接(LEFT OUTER JOIN)、右外连接(RIGTH OUTER JOIN)、全外连接(FULL OUTER JOIN)3类。
- # 左外连接
- #左表记录全部被选择,右表只选择符合条件的记录
- table_reference LEFT [OUTER] JOIN table_factor [join_condition]
-
- #右外连接
- #右表记录全部被选择,左表只选择符合条件的记录
- table_reference RIGHT [OUTER] JOIN table_factor [join_condition]
-
- #全外连接
- #结合左右连接的结果
- table_reference FULL [OUTER] JOIN table_factor [join_condition]
交叉连接 (CROSS JOIN):又称笛卡尔乘积,相当于两表相乘
table_reference CROSS JOIN table_factor [join_condition]
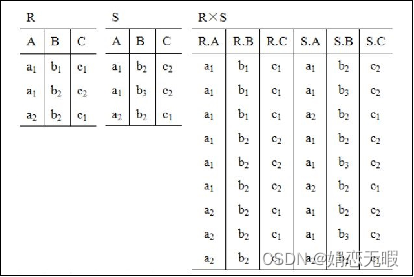
三、联合查询
- 联合查询主要通过UNION子句对列进行多表组合
- UNION语句用于合并多个SELECT语句的结果集
- # 语法
- select_statement UNION [ALL|DISTINCT] select_statement…
- UNION的每个子集都必须有相同的列名和类型
- 排序、分组、LIMIT等操作应用在整个UNION结果之后
- UNION合并两个结果集,并去除重复行,保持默认排序
- UNION ALL合并两个结果集,不去重,不排序
四、数据排序
Hive提供了四种排序方式
1.ORDER BY,对结果集进行全局排序,数据规模较大时,比较耗时
- # ORDER BY:这是用于排序的SQL子句。
- # colName:这是你想要排序的列名。
- # (ASC|DESC)?:这表示你可以选择使用 ASC(升序)或 DESC(降序)来指定排序顺序,默认是 ASC。问号表示这是可选的。
- # , colName(ASC|DESC)?:你可以使用逗号分隔多个列名,对结果进行多列排序,每列可以分别指定升序或降序。
- ORDER BY colName(ASC|DESC)?(, colName(ASC|DESC)?)
2.SORT BY,指出数据在每个Reducer内如何排序的,通常与DISTRIBUTE BY一起使用 3.DISTRIBUTE BY,控制Map输出在Reducer中的划分
- # 将 table 表中的数据按 col_name1 列的值进行分区,使得每个分区中的记录具有相同的 col_name1 值。
- #然后在每个分区内部,按 col_name2 列的值进行排序。
- select * from table DISTRIBUTE BY col_name1 SORT BY col_name2
4.CLUSTER BY,相当于DISTRIBUTE BY和SORT BY结合
五、分组聚合
聚合函数指对一组值进行计算,返回单个值 。Hive提供了多种聚合函数,通常与GROUP BY语句一起使用 。
- # 分组函数
- SELECT expression(,expression) FROM src
- GROUP BY expression(,expression) HAVING condition
- #除了聚合函数,SELECT所选列必须出现在GROUP BY子句中
- #GROUP BY 支持使用CASE WHEN表达式
- #GROUP BY配合使用HAVING进行过滤
常用基础聚合函数
| 函数名 | 描述 |
| max(col) | 返回组内某列最大值 |
| min(col) | 返回组内某列最小值 |
| count(*) | 返回组内总行数 |
| count(expr) | 返回组内expr表达式不是NULL的总行数 |
| count(DISTINCT expr) | 返回组内expr是唯一的行的数量 |
| sum(col) | 返回组内某列的和,即对组内某列求和 |
| avg(col) | 返回组内某列元素的平均值 |
| collect_set(col) | 返回消除了重复元组的数组 |
| collect_list(col) | 返回允许重复元素的数组 |
六、窗口函数
- 窗口函数是一组特殊的函数
- 它能扫描多个输入行以计算每个输出值
- 可为每行数据都生成一行结果记录
- 窗口函数按功能划分可分为三类:排序、聚合、分析
- function(arg1,….) OVER([PARTITION BY <…>][ORDER BY<…>[<window_clause>]])
-
- #窗口函数的位置作为SELECT语句中的一列出现,类似基本聚合函数,如count(*)
- #OVER()表示在当前查询的结果集上操作,包括分区与排序两种,均可选
- #PARTITION BY类似于GROUP BY,表示对当前结果集按其中某列进行分组,如果未指定该子句,意味着整个SELECT结果集作为一个分组
- #只有在指定ORDER BY子句后才能进行窗口定义( window_clause )
- #在一个SELECT语句中可以出现多次窗口函数
- #对窗口函数的计算结果进行过滤,必须在窗口函数所在SELECT语句往外一层
1. 排序类
(1).ROW_NUMBER() 函数基于OVER对象分组、排序的结果为每一行分组记录返回一个序号。序号从1开始,依次递增,遇到新组则重新从1开始记。
(2).RANK()功能与ROW_NUMBER()类似,不同的是,RANK()产生序号时,当排序的值相同时,返回的排名将重复。
(3).DENSE_RANK()功能与RANK()类似,不同的是,DENSE_RANK()产生相同序号时,下一个序号将连续
ROW_NUMBER()、RANK()、DENSE_RANK()区别
| score | row_number() | rank() | dense_rank() |
| 99 | 1 | 1 | 1 |
| 99 | 2 | 1 | 1 |
| 98 | 3 | 3 | 2 |
(4).NTILE(n)将OVER对象的分组结果按顺序平均分成n片,并为每一行记录返回一个切片号。
(5).PERCENT_RANK()该函数返回OVER对象分组内当前行的RANK值与组内总行数的比值。
2.聚合类
常用聚合类函数包括
- COUNT(col),计数
- SUM(col),求和
- MAX(col),求最大值
- MIN(col),求最小值
- AVG(col),求平均值
聚合类窗口函数使用示例(count函数)
COUNT(col) OVER([PARTITION BY <…>][ORDER BY<…>[<window_clause>]])3.分析类
常用分析类函数包括
(1)CUME_DIST() 返回小于等于当前值的行数与分组内总行数的比值。
(2)LAG/LEAD(col,n,DEFAULT) 统计窗口内往上/下第n行值。
(3)FIRST_VALUE/LAST_VALUE(col) 返回OVER对象分组内第一个值/最后一个值 。
4.窗口的定义
窗口定义由子句[<window_clause>]描述
窗口分为两类:行类型窗口,根据当前行之前或之后的行号确定窗口
- ROWS BETWEEN start_expr AND end_expr
- #start_expr/end_expr可以为:
- #UNBOUNED PRECEDING(start_expr)/FOLLOWING(end_expr):窗口起始(结束)位置,为分组的第一行(最后一行)
- #CURRENT ROW:当前行
- #n PRECEDING/FOLLOWING:当前行之前/之后n行
范围类型窗口,取分组内值在指定范围区间内的行
- RANGE BETWEEN start_expr AND end_expr
- #start_expr/end_expr可以为:
- #n PRECEDING/FOLLOWING:当前行之前/之后n行
- #CURRENT ROW:表示当前行的值
只要方向坚定,无所谓走走停停!

