
热门标签
热门文章
- 1Java中ArrayList的使用_java for : arraylist
- 2阿里云服务器安装nginx,以及相关配置_阿里云安装nginx
- 3Oracle启动和停止的方式详解_oracle startup过程中可以重启吗
- 4一个简单的HTML网页——传统节日春节网页(HTML+CSS)_春节html素材
- 5element-ui动态增加表单项并验证_element表单模块里面实现一个按钮 通过点击可以添加一个模块在表单上
- 6文心一言和ChatGPT最全对比!_文心一言与chatgpt对比
- 7Galance镜像服务_cirros-0.3.4-x86_64-disk.img
- 8Chrome您使用的是不受支持的命令行标记:--ignore-certificate-errors
- 9怎样进行 maven 离线编译 install
- 10Vue中使用require.context()自动引入组件和自动生成路由的方法介绍_vue自动引入组件
当前位置: article > 正文
全局平均池化层(GLP)
作者:羊村懒王 | 2024-02-16 10:55:55
赞
踩
全局平均池化层
一、全局平均池化
全局平均池化层(GAP)在2013年的《Network In Network》(NIN)中首次提出,于是便风靡各种卷积神经网络。为什么它这么受欢迎呢?
一般情况下,卷积层用于提取二维数据如图片、视频等的特征,针对于具体任务(分类、回归、图像分割)等,卷积层后续会用到不同类型的网络,拿分类问题举例,最简单的方式就是将卷积网络提取出的特征(feature map)输入到softmax全连接层对应不同的类别。首先,这里的feature map是二维多通道的数据结构,类似于三个通道(红黄绿)的彩色图片,也就是这里的feature map具有空间上的信息;其次,在GAP被提出之前,常用的方式是将feature map直接拉平成一维向量(下图左),但是GAP不同,是将每个通道的二维图像做平均,最后也就是每个通道对应一个均值(下图右)。
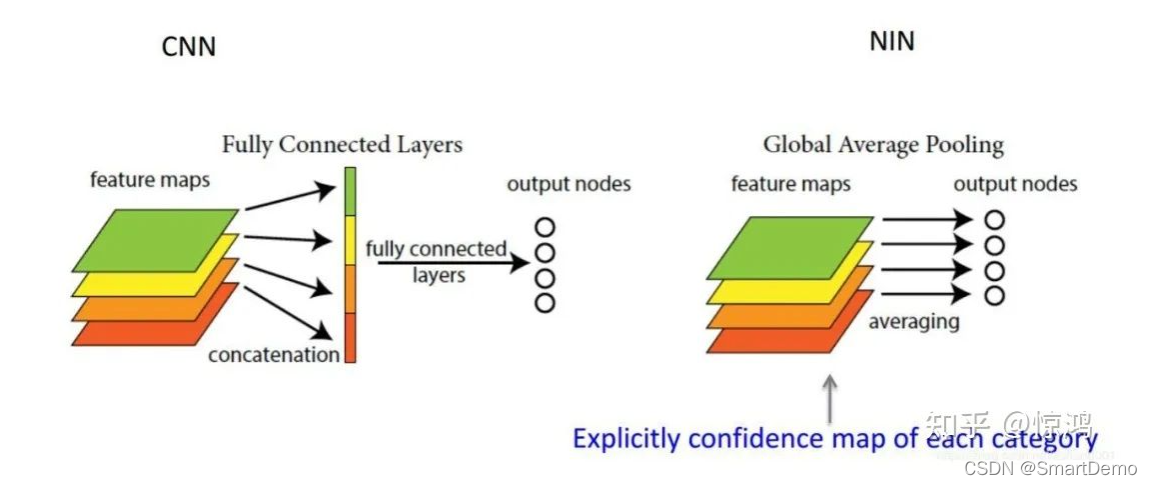
思想:对于输出的每一个通道的特征图的所有像素计算一个平均值,经过全局平均池化之后就得到一个 维度==类别数 的特征向量,然后直接输入到softmax层
如果有一批特征图,其尺寸为 [ B, C, H, W], 经过全局平均池化之后,尺寸变为[B, C, 1, 1]。
也就是说,全局平均池化其实就是对每一个通道图所有像素值求平均值,然后得到一个新的1 * 1的通道图。
可以看到,GAP的设计非常简单直接,但是为什么要这么做呢?或者说GAP区别于全连接的方式有哪些优势呢?
- 抑制过拟合。直接拉平做全连接层的方式依然保留了大量的空间信息,假设feature map是32个通道的10*10图像,那么拉平就得到了32*10*10的向量,如果是最后一层是对应两类标签,那么这一层就需要3200*2的权重矩阵,而GAP不同,将空间上的信息直接用均值代替,32个通道GAP之后得到的向量都是32的向量,那么最后一层只需要32*2的权重矩阵。相比之下GAP网络参数会更少,而全连接更容易在大量保留下来的空间信息上面过拟合。
- 可解释的雏形。在《NIN》原文当中有这样一句话,GAP相比全连接更加自然地加强了类别和feature map之间的联系,(这个类别指的是分类的类别)因此,feature map可以很容易地解释成categories confidence maps。后半句可能有些难以理解,这块我们在第二节展开来讲。如果之前对Class Activation Mapping (CAM) 有过了解的同学可能会不禁感叹:“这其实就是CAM的核心思想!”
- 输入尺寸更加灵活。在第1点的举例里面可以看到feature map经过GAP后的神经网络参数不再与输入图像尺寸的大小有关,也就是输入图像的长宽可以不固定。
除了这些优势,GAP也有个缺点——训练的收敛速度会变慢。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/羊村懒王/article/detail/92434
推荐阅读
相关标签

