
- 1学习笔记——技术调研——EasyExcel_java easyexcel哪个版本支持设置密码
- 2golang开发技巧_golang 开发思路
- 3YOLOv5核心基础知识讲解_yolov5江大白
- 4阿里云 ECS服务器 开放 8080 端口 -- 图解_ecs gre服务端口
- 5Linux离线安装NTP服务,无外网环境下配置本地时间同步_linux服务器时间校正 无网
- 6cv2.Canny 边缘检测
- 7Samba服务器(一):windows访问samba服务器共享文件的简单实现(图文并茂)
- 8云计算 2月28号 (linux的磁盘分区)
- 9linux驱动-线程_kthread create suspend
- 10一键搭建幻兽帕鲁游戏服务器和迁移存档教程_幻兽帕鲁如何从腾讯云服务器迁移到阿里云服务器
11史上最全最详细大数据大一统环境安装,包含各个组件的安装_海贝大数据管理系统 安装教程图解
赞
踩
- 安装Vmware虚拟机
- 安装虚拟机
正常下一步即可
注意 安装 d盘/opt目录下, 这个目录没有中文没有空格
-
- 在vm中配置网关
-
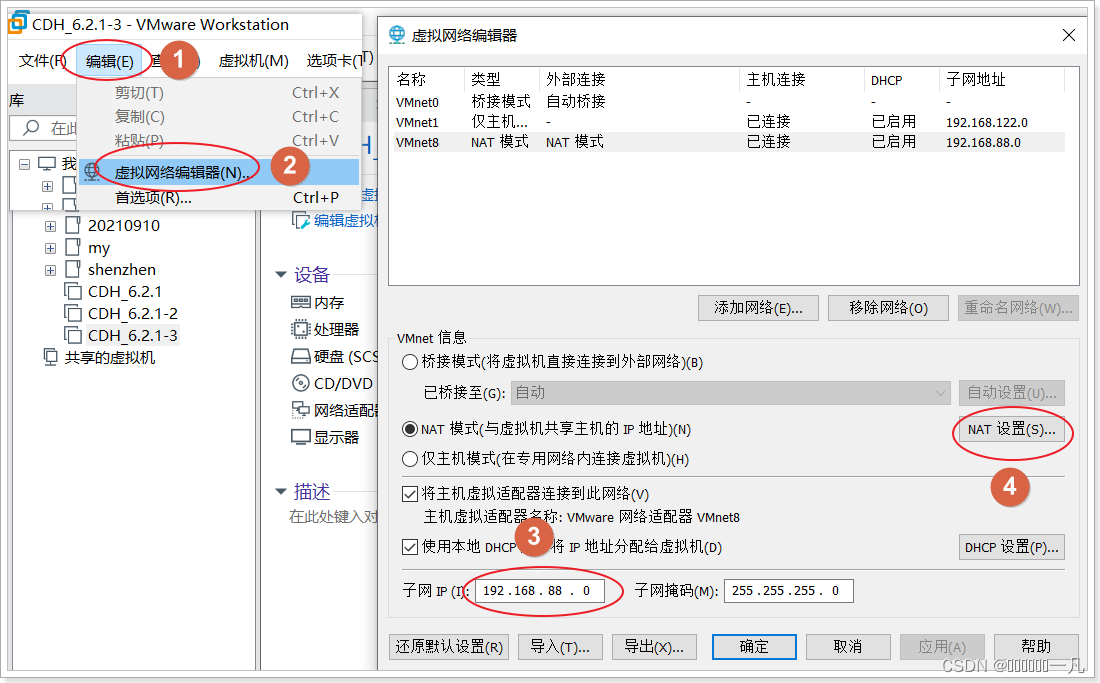
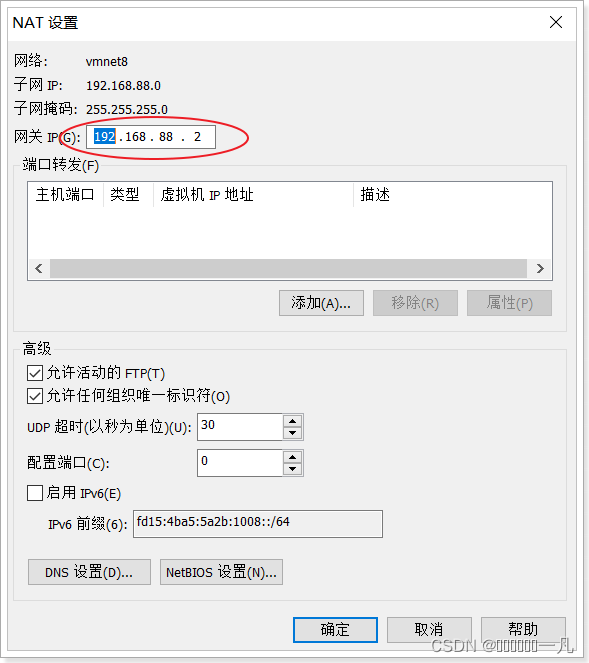
-
- 修改 windows 的网卡信息
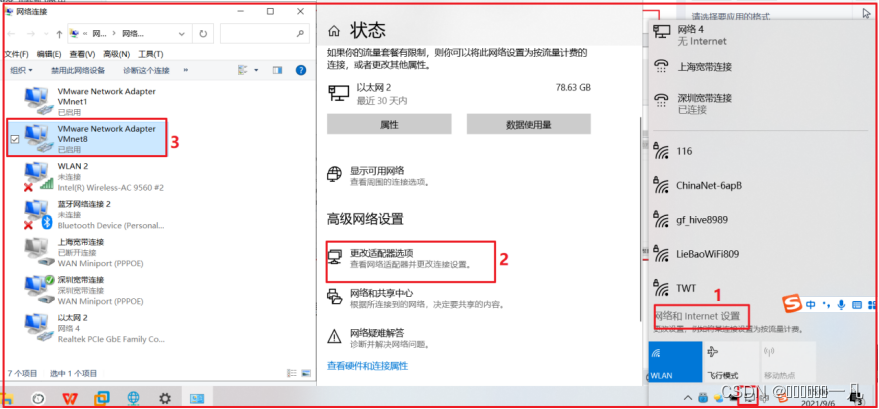
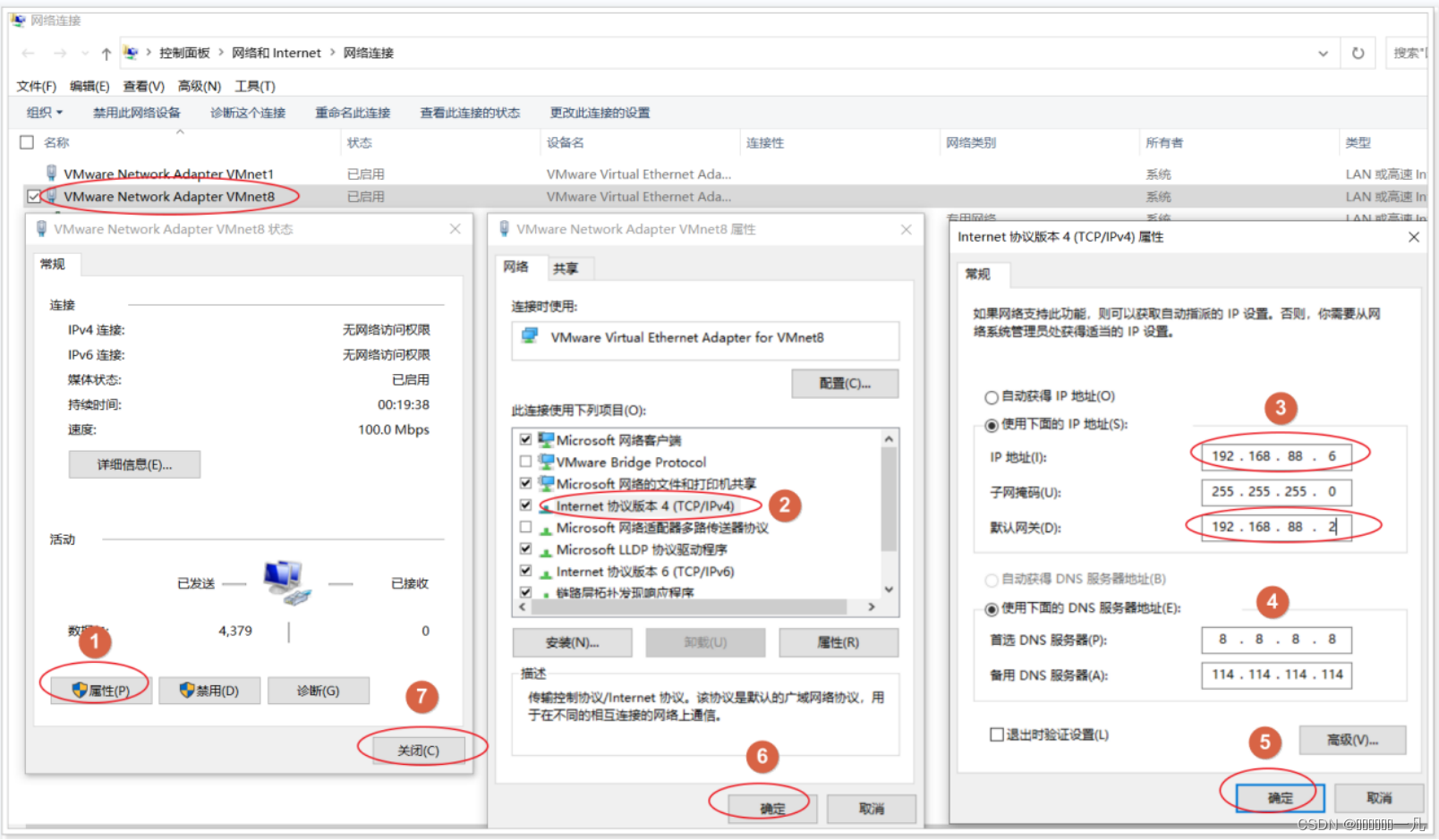
- 安装centos
- 模拟硬件
-
- 删除不用的硬件
删除前
删除后
-
- 关联centos镜像
-
- 安装centos镜像
设置 默认超级管理员 root 密码
- 使用命令行客户端 finalshell 连接 linux
- 使用文本客户端 nodepad++ 连接 linux
- 使用nodepad 修改 linux的 网卡信息
/etc/sysconfig/network-scripts/ifcfg-ens32
| TYPE="Ethernet" PROXY_METHOD="none" BROWSER_ONLY="no" BOOTPROTO="static" DEFROUTE="yes" IPV4_FAILURE_FATAL="no" IPV6INIT="yes" IPV6_AUTOCONF="yes" IPV6_DEFROUTE="yes" IPV6_FAILURE_FATAL="no" IPV6_ADDR_GEN_MODE="stable-privacy" NAME="ens32" UUID="0719155e-8ed9-413d-a93a-98f64bfed5c8" DEVICE="ens32" ONBOOT="yes" IPADDR="192.168.88.161" GATEWAY="192.168.88.2" NETMASK="255.255.255.0" DNS1="8.8.8.8" DNS2="114.114.114.114" IPV6_PRIVACY="no" |
在VM中 重启网卡服务, 加载新的配置文件
| systemctl restart network |
修改成功后, 所有客户端需要把ip地址修改成 192.168.52.161
- 部署单台 linux集群的准备工作
- 关闭防火墙
- 查看防火墙状态
systemctl status firewalld
- 关闭防火墙
systemctl stop firewalld
- 禁止开机启动
systemctl disable firewalld
-
- 关闭 selinux
- 什么是SELinux ?
- 关闭 selinux
1)SELinux是Linux的一种安全子系统
2)Linux中的权限管理是针对于文件的, 而不是针对进程的, 也就是说, 如果root启动了某个进程, 则这个进程可以操作任何一个文件。
3)SELinux在Linux的文件权限之外, 增加了对进程的限制, 进程只能在进程允许的范围内操作资源
-
-
- 为什么要关闭SELinux
-
如果开启了SELinux, 需要做非常复杂的配置, 才能正常使用系统, 在学习阶段, 在非生产环境, 一般不使用SELinux
SELinux的工作模式:
enforcing 强制模式
permissive 宽容模式
disabled 关闭
-
-
- 关闭SELinux方式
-
编辑每台虚拟机的Selinux的配置文件
| vim /etc/selinux/config |
Selinux的默认工作模式是强制模式
将Selinux工作模式关闭:
-
-
- 分别重启三台虚拟机
-
| reboot |
-
- 安装jdk
JDK 是个绿色软件,解压并且配置环境变量即可使用
-
-
- 在虚拟机中创建两个目录
-
| # 软件包放置的目录 mkdir -p /export/software # 软件安装的目录 mkdir -p /export/server |
-
-
- 上传jdk的安装包:
-
进入 /export/software 目录, 上传 jdk-8u241-linux-x64.tar.gz
| cd /export/software |
-
-
- 解压压缩包到/export/server目录下
-
| tar -zxvf jdk-8u241-linux-x64.tar.gz -C /export/server |
查看解压后的目录,目录中有 jdk1.8.0_144 为 jdk 解压的目录
-
-
- 配置 jdk 环境变量,
-
打开/etc/profile 配置文件,将下面配置拷贝进去。export 命令用于将 shell 变量输出为环境变量
第一步: vi /etc/profile
第二步: 通过键盘上下键 将光标拉倒最后面
第三步: 然后输入 i, 将一下内容输入即可
| #set java environment JAVA_HOME=/export/server/jdk1.8.0_241 CLASSPATH=.:$JAVA_HOME/lib PATH=$JAVA_HOME/bin:$PATH export JAVA_HOME CLASSPATH PATH |
第四步: esc键 然后 :wq 保存退出即可
-
-
- 重新加载环境变量:
-
| source /etc/profile 或 . /etc/profile |
-
-
- 配置jdk是否安装成功
-
| java -version |
- 配置linux集群
- 克隆linux
-
- 配置三台虚拟机的内存
三台虚拟机再加上windows本身, 需要同时运行4台机器, 所以在分配的时候, 每台虚拟机的内存为: 总内存 ÷ 4,比如电脑总内存为16G,则每台虚拟机内存为4G。
下面是以node1为例对内存进行配置:
-
- 配置mac地址
先配置node2的mac地址
配置node3的MAC地址 同上
-
- 配置ip地址
三台虚拟机的IP地址配置如下:
node1 192.168.52.161
node2 192.168.52.162
node3 192.168.52.163
-
-
- 配置node2 和 node3 的ip地址
- 第一步: 打开配置文件
- 配置node2 和 node3 的ip地址
-
| vim /etc/sysconfig/network-scripts/ifcfg-ensXX |
-
-
-
- 第二步: 将 161 改成 162
-
-
-
-
-
- 第三步 重启网卡服务
-
-
| systemctl restart network |
-
-
-
- 查看ip地址
-
-
| ifconfig |
-
-
-
- 测试网络连接
-
-
| ping www.baidu.com |
-
- 配置主机名
分别编辑每台虚拟机的hostname文件,直接填写主机名,保存退出即可。
| vim /etc/hostname |
第一台主机主机名为: node1.itcast.cn
第二台主机主机名为: node2.itcast.cn
第三台主机主机名为: node3.itcast.cn
-
- 配置每台虚拟机域名映射
分别编辑每台虚拟机的hosts文件,在原有内容的基础上,填下以下内容:
注意:不要修改文件原来的内容,三台虚拟机的配置内容都一样。
| vim /etc/hosts |
| 192.168.52.161 node1 node1.itcast.cn 192.168.52.162 node2 node2.itcast.cn 192.168.52.163 node3 node3.itcast.cn |
配置后效果如下:
-
- 三台机器机器免密码登录
注意:配置前, 先重启
-
-
- 三台机器生成公钥与私钥
-
在三台机器执行以下命令,生成公钥与私钥
| ssh-keygen -t rsa |
执行该命令之后,按下三个回车即可,然后敲(三个回车),就会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥),默认保存在/root/.ssh目录。
-
-
- 拷贝公钥到同一台机器
-
三台机器将拷贝公钥到第一台机器
三台机器执行命令:
| ssh-copy-id node1 |
在执行该命令之后,需要输入yes和node1的密码:
-
-
- 复制第一台机器的认证到其他机器
-
将第一台机器的公钥拷贝到其他机器上
在第一台机器上指行以下命令
| scp /root/.ssh/authorized_keys node2:/root/.ssh scp /root/.ssh/authorized_keys node3:/root/.ssh |
执行命令时,需要输入yes和对方的密码
-
-
- 测试SSH免密登录
-
可以在任何一台主机上通过ssh 主机名命令去远程登录到该主机,输入exit退出登录
例如:在node1机器上,免密登录到node2机器上
执行效果如下:
-
- 三台机器时钟同步
- 为什么需要时间同步
- 三台机器时钟同步
因为很多分布式系统是有状态的, 比如说存储一个数据, A节点 记录的时间是1, B节点 记录的时间是2, 就会出问题
-
-
- 通过网络进行时钟同步
-
通过网络连接外网进行时钟同步,必须保证虚拟机连上外网
-
-
-
- 启动定时任务
-
-
| [root@node1 ~]# crontab -e |
随后在输入界面键入以下内容,每隔一分钟就去连接阿里云时间同步服务器,进行时钟同步
| */1 * * * * /usr/sbin/ntpdate -u ntp4.aliyun.com; |
-
-
-
- 测试
-
-
| [root@nodeX ~]# date |
- 拍摄快照
- 先关机
| shutdown -h now |
-
- 拍摄快照
node2和node3的拍摄快照同上
- 安装zoopeeper3.4.6
zk集群在搭建部署的时候,通常选择 2n+1 奇数台。底层 Paxos 算法支持(过半成功)。
-
- zk安全前提
服务器基础环境
| IP 主机名 hosts映射 防火墙关闭 时间同步 ssh免密登录 |
JDK环境
| jdk1.8 配置好环境变量 |
-
- zk具体安装部署(选择node1安装 scp给其他节点)
- 安装包
- zk具体安装部署(选择node1安装 scp给其他节点)
zookeeper-3.4.6.tar.gz
-
-
- 上传解压重命名
-
| cd /export/software/ tar zxvf zookeeper-3.4.6.tar.gz -C /export/server/ cd /export/server/ mv zookeeper-3.4.6/ zookeeper |
-
-
- 修改配置文件
- zoo.cfg
- 修改配置文件
-
| #zk默认加载的配置文件是zoo.cfg 因此需要针对模板进行修改。保证名字正确。 cd zookeeper/conf mv zoo_sample.cfg zoo.cfg vi zoo.cfg #修改 dataDir=/export/data/zkdata #文件最后添加 2888心跳端口 3888选举端口 server.1=node1:2888:3888 server.2=node2:2888:3888 server.3=node3:2888:3888 |
-
-
-
- myid
-
-
| #在每台机器的dataDir指定的目录下创建一个文件 名字叫做myid #myid里面的数字就是该台机器上server编号。server.N N的数字就是编号 [root@node1 conf]# mkdir -p /export/data/zkdata [root@node1 conf]# echo 1 >/export/data/zkdata/myid |
-
-
- 把安装包同步到其他节点上
-
| cd /export/server scp -r zookeeper/ node2:$PWD scp -r zookeeper/ node3:$PWD |
-
-
- 创建其他机器上myid和datadir目录
-
| [root@node2 ~]# mkdir -p /export/data/zkdata [root@node2 ~]# echo 2 > /export/data/zkdata/myid [root@node3 ~]# mkdir -p /export/data/zkdata [root@node3 ~]# echo 3 > /export/data/zkdata/myid |
-
- zk集群的启动
- 每台机器上单独启动服务
- zk集群的启动
| #在哪个目录执行启动命令 默认启动日志就生成当前路径下 叫做zookeeper.out /export/server/zookeeper/bin/zkServer.sh start|stop|status #3台机器启动完毕之后 可以使用status查看角色是否正常。 #还可以使用jps命令查看zk进程是否启动。 [root@node3 ~]# jps 2034 Jps 1980 QuorumPeerMain #看我,我就是zk的java进程 |
-
- 扩展:编写shell脚本 一键脚本启动。
本质:在node1机器上执行shell脚本,由==shell程序通过ssh免密登录==到各个机器上帮助执行命令。
-
-
- 一键关闭脚本
-
| [root@node1 ~]# mkdir -p /onekey && cd /onekey [root@node1 onekey]# vim zk2_stop.sh #!/bin/bash # 1 数组 放 主机名 hosts=(node1 node2 node3) # 2 遍历 关闭 for host in ${hosts[*]} do ssh $host "source /etc/profile;/export/server/zookeeper/bin/zkServer.sh stop" done |
-
-
- 一键启动脚本
-
| [root@node1 onekey]# vim zk1_start.sh #!/bin/bash # 1 数组 放 主机名 hosts=(node1 node2 node3) # 2 遍历 启动 for host in ${hosts[*]} do ssh $host "source /etc/profile;/export/server/zookeeper/bin/zkServer.sh start" done |
- 注意:关闭java进程时候 根据进程号 直接杀死即可就可以关闭。启动java进程的时候 需要JDK。
- shell程序ssh登录的时候不会自动加载/etc/profile 需要shell程序中自己加载。
chmod 777 /onekey/*
-
- 使用客户端访问
| /export/server/zookeeper/bin/zkCli.sh [-server ip] |
- 安装 hadoop-3.3.0
- 路径
| 服务器基础环境准备 安装包目录结构 配置文件的修改 - 第一类 1个 hadoop-env.sh - 第二类 4个 core|hdfs|mapred|yarn-site.xml - site表示的是用户定义的配置,会覆盖default中的默认配置。 - core-site.xml 核心模块配置 - hdfs-site.xml hdfs文件系统模块配置 - mapred-site.xml MapReduce模块配置 - yarn-site.xml yarn模块配置 - 第三类 1个 workers scp安装包到其他机器 Hadoop环境变量配置 hadoop namenode format Hadoop集群启动 Hadoop初体验 |
-
- 实现
- 服务器基础环境准备
- 实现
| ip、主机名 hosts映射 别忘了windows也配置 防火墙关闭 时间同步 免密登录 node1---->node1 node2 node3 JDK安装 |
-
-
- 安装包目录结构
-
#上传安装包到 /export/software 解压
[root@node1 ~]# cd /export/software/
[root@node1 software]# tar -zxvf hadoop-3.3.0-Centos7-64-with-snappy.tar.gz -C /export/server/
| bin #hadoop核心脚本 最基础最底层脚本 etc #配置目录 include lib libexec LICENSE.txt NOTICE.txt README.txt sbin #服务启动 关闭 维护相关的脚本 share #官方自带实例 hadoop相关依赖jar |
-
-
- 配置文件的修改
-
| cd /export/server/hadoop-3.3.0/etc/hadoop |
hadoop-env.sh
| export JAVA_HOME=/export/server/jdk1.8.0_241 #文件最后添加 export HDFS_NAMENODE_USER=root export HDFS_DATANODE_USER=root export HDFS_SECONDARYNAMENODE_USER=root export YARN_RESOURCEMANAGER_USER=root export YARN_NODEMANAGER_USER=root |
core-site.xml
| <!-- 设置默认使用的文件系统 Hadoop支持file、HDFS、GFS、ali|Amazon云等文件系统 --> <property> <name>fs.defaultFS</name> <value>hdfs://node1:8020</value> </property> <!-- 设置Hadoop本地保存数据路径 --> <property> <name>hadoop.tmp.dir</name> <value>/export/data/hadoop-3.3.0</value> </property> <!-- 设置HDFS web UI用户身份 --> <property> <name>hadoop.http.staticuser.user</name> <value>root</value> </property> <!-- 整合hive 用户代理设置 --> <property> <name>hadoop.proxyuser.root.hosts</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.root.groups</name> <value>*</value> </property> |
hdfs-site.xml
| <!-- 设置SNN进程运行机器位置信息 --> <property> <name>dfs.namenode.secondary.http-address</name> <value>node2:9868</value> </property> |
mapred-site.xml
| <!-- 设置MR程序默认运行模式: yarn集群模式 local本地模式 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <!-- MR程序历史服务器端地址 --> <property> <name>mapreduce.jobhistory.address</name> <value>node1:10020</value> </property> <!-- 历史服务器web端地址 --> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>node1:19888</value> </property> <property> <name>yarn.app.mapreduce.am.env</name> <value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value> </property> <property> <name>mapreduce.map.env</name> <value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value> </property> <property> <name>mapreduce.reduce.env</name> <value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value> </property> |
yarn-site.xml
| <!-- 设置YARN集群主角色运行机器位置 --> <property> <name>yarn.resourcemanager.hostname</name> <value>node1</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 是否将对容器实施物理内存限制 --> <property> <name>yarn.nodemanager.pmem-check-enabled</name> <value>false</value> </property> <!-- 是否将对容器实施虚拟内存限制。 --> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property> <!-- 开启日志聚集 --> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <!-- 设置yarn历史服务器地址 --> <property> <name>yarn.log.server.url</name> <value>http://node1:19888/jobhistory/logs</value> </property> <!-- 保存的时间7天 --> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>604800</value> </property> |
workers
| node1 node2 node3 |
-
-
- scp安装包到其他机器
-
| cd /export/server scp -r hadoop-3.3.0 root@node2:/export/server scp -r hadoop-3.3.0 root@node3:/export/server |
-
-
- Hadoop环境变量配置
-
| vim /etc/profile # set hadoop env export HADOOP_HOME=/export/server/hadoop-3.3.0 export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin |
| [root@node1 server]# scp /etc/profile node2:/etc/ [root@node1 server]# scp /etc/profile node3:/etc/ [root@node1 server]# source /etc/profile [root@node2 ~]# source /etc/profile [root@node3 ~]# source /etc/profile |
-
-
- hadoop namenode format
-
(首次启动)格式化namenode
| hdfs namenode -format |
-
-
- 在windows配置 ip地址映射
-
C:\Windows\System32\drivers\etc\hosts 文件
| 192.168.52.161 node1 node1.itcast.cn 192.168.52.162 node2 node2.itcast.cn 192.168.52.163 node3 node3.itcast.cn |
-
-
- Hadoop集群启动
- 单节点逐个启动
- Hadoop集群启动
-
| [root@node1 server]# hdfs --daemon start namenode [root@node1 server]# hdfs --daemon start datanode [root@node1 server]# yarn --daemon start resourcemanager [root@node1 server]# yarn --daemon start nodemanager [root@node1 server]# mapred --daemon start historyserver [root@node2 ~]# hdfs --daemon start secondarynamenode [root@node2 ~]# yarn --daemon start nodemanager [root@node2 ~]# hdfs --daemon start datanode [root@node3 ~]# yarn --daemon start nodemanager [root@node3 ~]# hdfs --daemon start datanode |
-
-
-
- 脚本一键启动
-
-
| [root@node1 ~]# start-dfs.sh [root@node1 ~]# start-yarn.sh [root@node1 server]# mapred --daemon start historyserver |
-
-
- Hadoop集群关闭
- 单节点逐个启动
- Hadoop集群关闭
-
| [root@node1 server]# hdfs --daemon stop namenode [root@node1 server]# hdfs --daemon stop datanode [root@node1 server]# yarn --daemon stop resourcemanager [root@node1 server]# yarn --daemon stop nodemanager [root@node1 server]# mapred --daemon stop historyserver [root@node2 ~]# hdfs --daemon stop secondarynamenode [root@node2 ~]# yarn --daemon stop nodemanager [root@node2 ~]# hdfs --daemon stop datanode [root@node3 ~]# yarn --daemon stop nodemanager [root@node3 ~]# hdfs --daemon stop datanode |
-
-
-
- 脚本一键启动
-
-
| [root@node1 ~]# stop-dfs.sh [root@node1 ~]# stop-yarn.sh [root@node1 server]# mapred --daemon stop historyserver |
-
-
- 编写自定义一键脚本
- 自定义一键启动
- 编写自定义一键脚本
-
[root@node1 onekey]# vim /onekey/hd1_start.sh
| #!/bin/bash /export/server/hadoop-3.3.0/sbin/start-dfs.sh /export/server/hadoop-3.3.0/sbin/start-yarn.sh /export/server/hadoop-3.3.0/bin/mapred --daemon start historyserver |
-
-
-
- 自定义一键关闭
-
-
[root@node1 onekey]# vim /onekey/hd2_stop.sh
| #!/bin/bash /export/server/hadoop-3.3.0/sbin/stop-dfs.sh /export/server/hadoop-3.3.0/sbin/stop-yarn.sh /export/server/hadoop-3.3.0/bin/mapred --daemon stop historyserver |
-
-
-
- 修建自定义脚本权限
-
-
| [root@node1 onekey]# chmod 777 /onekey/* |
-
-
-
- 启动测试
-
-
| [root@node1 onekey]# /onekey/hd1_start.sh [root@node1 onekey]# jps |
-
-
-
- 关闭测试
-
-
| [root@node1 onekey]# /onekey/hd2_stop.sh [root@node1 onekey]# jps |
-
-
- Hadoop初体验
-
HDFS集群:http://node1:9870/
YARN集群:http://node1:8088/
historyserver:http://node1:19888/
- 在node1上安装离线mysql
- 卸载Centos7自带的mariadb
| [root@node1 ~]# rpm -qa|grep mariadb mariadb-libs-5.5.64-1.el7.x86_64 [root@node1 ~]# rpm -e mariadb-libs-5.5.64-1.el7.x86_64 --nodeps [root@node1 ~]# rpm -qa|grep mariadb [root@node1 ~]# |
-
- 安装mysql
| mkdir /export/software/mysql cd /export/software/mysql #上传mysql-5.7.29-1.el7.x86_64.rpm-bundle.tar 到上述文件夹下 解压 tar xvf mysql-5.7.29-1.el7.x86_64.rpm-bundle.tar #执行安装 yum -y install libaio [root@node3 mysql]# rpm -ivh mysql-community-common-5.7.29-1.el7.x86_64.rpm mysql-community-libs-5.7.29-1.el7.x86_64.rpm mysql-community-client-5.7.29-1.el7.x86_64.rpm mysql-community-server-5.7.29-1.el7.x86_64.rpm warning: mysql-community-common-5.7.29-1.el7.x86_64.rpm: Header V3 DSA/SHA1 Signature, key ID 5072e1f5: NOKEY Preparing... ################################# [100%] Updating / installing... 1:mysql-community-common-5.7.29-1.e################################# [ 25%] 2:mysql-community-libs-5.7.29-1.el7################################# [ 50%] 3:mysql-community-client-5.7.29-1.e################################# [ 75%] 4:mysql-community-server-5.7.29-1.e################ ( 49%) |
-
- mysql初始化设置
| #初始化 mysqld --initialize #更改所属组 chown mysql:mysql /var/lib/mysql -R #启动mysql systemctl start mysqld.service #查看生成的临时root密码 cat /var/log/mysqld.log [Note] A temporary password is generated for root@localhost: o+TU+KDOm004 |
-
- 修改root密码 授权远程访问 设置开机自启动
| [root@node2 ~]# mysql -u root -p Enter password: #这里输入在日志中生成的临时密码 Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 3 Server version: 5.7.29 Copyright (c) 2000, 2020, Oracle and/or its affiliates. All rights reserved. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql> #更新root密码 设置为hadoop mysql> alter user user() identified by "123456"; Query OK, 0 rows affected (0.00 sec) #授权 mysql> use mysql; mysql> GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY '123456' WITH GRANT OPTION; mysql> FLUSH PRIVILEGES; mysql> exit #mysql的启动和关闭 状态查看 (这几个命令必须记住) systemctl stop mysqld systemctl status mysqld systemctl start mysqld #建议设置为开机自启动服务 [root@node2 ~]# systemctl enable mysqld Created symlink from /etc/systemd/system/multi-user.target.wants/mysqld.service to /usr/lib/systemd/system/mysqld.service. #查看是否已经设置自启动成功 [root@node2 ~]# systemctl list-unit-files | grep mysqld mysqld.service enabled |
-
- Centos7 干净卸载mysql 5.7(看情况卸载)
| #关闭mysql服务 systemctl stop mysqld.service #查找安装mysql的rpm包 [root@node3 ~]# rpm -qa | grep -i mysql mysql-community-libs-5.7.29-1.el7.x86_64 mysql-community-common-5.7.29-1.el7.x86_64 mysql-community-client-5.7.29-1.el7.x86_64 mysql-community-server-5.7.29-1.el7.x86_64 #卸载 [root@node3 ~]# yum remove mysql-community-libs-5.7.29-1.el7.x86_64 mysql-community-common-5.7.29-1.el7.x86_64 mysql-community-client-5.7.29-1.el7.x86_64 mysql-community-server-5.7.29-1.el7.x86_64 #查看是否卸载干净 rpm -qa | grep -i mysql #查找mysql相关目录 删除 [root@node1 ~]# find / -name mysql /var/lib/mysql /var/lib/mysql/mysql /usr/share/mysql [root@node1 ~]# rm -rf /var/lib/mysql [root@node1 ~]# rm -rf /var/lib/mysql/mysql [root@node1 ~]# rm -rf /usr/share/mysql #删除默认配置 日志 rm -rf /etc/my.cnf rm -rf /var/log/mysqld.log |
- 在node1上安装hive
- 上传安装包 解压
| [root@node1 ~]# cd /export/software/ [root@node1 ~]# tar zxvf apache-hive-3.1.2-bin.tar.gz -C /export/server/ |
-
- 解决Hive与Hadoop之间guava版本差异
| cd /export/server mv apache-hive-3.1.2-bin hive-3.1.2 cd /export/server/hive-3.1.2 rm -rf lib/guava-19.0.jar cp /export/server/hadoop-3.3.0/share/hadoop/common/lib/guava-27.0-jre.jar ./lib/ |
测试
| [root@node1 hive-3.1.2]# ll lib | grep guava -rw-r--r-- 1 root root 2747878 9月 10 13:10 guava-27.0-jre.jar -rw-r--r-- 1 root root 971309 5月 21 2019 jersey-guava-2.25.1.jar |
-
- 修改配置文件
- hive-env.sh
- 修改配置文件
| cd /export/server/hive-3.1.2/conf mv hive-env.sh.template hive-env.sh vim hive-env.sh export HADOOP_HOME=/export/server/hadoop-3.3.0 export HIVE_CONF_DIR=/export/server/hive-3.1.2/conf export HIVE_AUX_JARS_PATH=/export/server/hive-3.1.2/lib |
-
-
- hive-site.xml(新建)
-
| vim hive-site.xml |
| <configuration> <!-- 存储元数据mysql相关配置 --> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://node1:3306/hive3?createDatabaseIfNotExist=true&useSSL=false</value> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>123456</value> </property> <!-- H2S运行绑定host --> <property> <name>hive.server2.thrift.bind.host</name> <value>node1</value> </property> <!-- 远程模式部署metastore metastore地址 --> <property> <name>hive.metastore.uris</name> <value>thrift://node1:9083</value> </property> <!-- 关闭元数据存储授权 --> <property> <name>hive.metastore.event.db.notification.api.auth</name> <value>false</value> </property> </configuration> |
-
- 上传mysql jdbc驱动到hive安装包lib下
| mysql-connector-java-5.1.32.jar |
验证是否上传:
| [root@node1 conf]# cd /export/server/hive-3.1.2/ [root@node1 hive-3.1.2]# ll lib | grep mysql-connector -rw-r--r-- 1 root root 969018 9月 11 11:52 mysql-connector-java-5.1.32.jar |
-
- 初始化元数据
| cd /export/server/hive-3.1.2/ bin/schematool -initSchema -dbType mysql -verbos #初始化成功会在mysql中创建74张表 |
-
- 在hdfs创建hive存储目录
先启动 hadoop
[root@node1 hive-3.1.2]# /onekey/hd1_start.sh
| hadoop fs -mkdir /tmp hadoop fs -mkdir -p /user/hive/warehouse hadoop fs -chmod g+w /tmp hadoop fs -chmod g+w /user/hive/warehouse |
-
- 启动hive
- 启动metastore服务
- 启动hive
| #前台启动 关闭ctrl+c /export/server/hive-3.1.2/bin/hive --service metastore #前台启动开启debug日志 /export/server/hive-3.1.2/bin/hive --service metastore --hiveconf hive.root.logger=DEBUG,console #后台启动 进程挂起 关闭使用jps+ kill -9 nohup /export/server/hive-3.1.2/bin/hive --service metastore & |
-
-
- 启动hiveserver2服务
-
| nohup /export/server/hive-3.1.2/bin/hive --service hiveserver2 & #注意 启动hiveserver2需要一定的时间 不要启动之后立即beeline连接 可能连接不上 |
-
-
- 检测
-
| [root@node1 hive-3.1.2]# jps 26645 Jps 25981 RunJar 24553 RunJar 20086 NameNode 20311 DataNode 20849 ResourceManager 21051 NodeManager 21498 JobHistoryServer |
-
-
- beeline客户端连接
-
l连接访问
| [root@node1 ~]# /export/server/hive-3.1.2/bin/beeline beeline> ! connect jdbc:hive2://node1:10000 beeline> root beeline> 直接回车 0: jdbc:hive2://node1:10000> show databases; +----------------+ | database_name | +----------------+ | default | +----------------+ 1 row selected (1.242 seconds) |
拷贝node1安装包到beeline客户端机器上(node3)
| scp -r /export/server/hive-3.1.2/ node3:/export/server/ |
-
- 常见问题
- 问题1
- 常见问题
- 现象
| Error: Could not open client transport with JDBC Uri: jdbc:hive2://node1:10000: Failed to open new session: java.lang.RuntimeException: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.authorize.AuthorizationException): User: root is not allowed to impersonate root (state=08S01,code=0) |
- 修改
| 在hadoop的配置文件core-site.xml中添加如下属性: <property> <name>hadoop.proxyuser.root.hosts</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.root.groups</name> <value>*</value> </property> |
- 连接访问
| /export/server/hive-3.1.2/bin/beeline beeline> ! connect jdbc:hive2://node1:10000 beeline> root beeline> 直接回车 0: jdbc:hive2://node1:10000> show databases; +----------------+ | database_name | +----------------+ | default | +----------------+ 1 row selected (1.242 seconds) |
-
-
- 问题2
-
错误解决:==Hive3执行insert插入操作 statstask异常
现象
| 在执行insert + values操作的时候 虽然最终执行成功,结果正确。但是在执行日志中会出现如下的错误信息。 |
开启hiveserver2执行日志。查看详细信息
| 2020-11-09 00:37:48,963 WARN [5ce14c58-6b36-476a-bab8-89cba7dd1706 main] metastore.RetryingMetaStoreClient: MetaStoreClient lost connection. Attempting to reconnect (1 of 1) after 1s. setPartitionColumnStatistics ERROR [5ce14c58-6b36-476a-bab8-89cba7dd1706 main] exec.StatsTask: Failed to run stats task |
但是 ==此错误并不影响最终的插入语句执行成功==。
分析原因和解决
- statstask是一个hive中用于统计插入等操作的状态任务 其返回结果如下
- 此信息类似于计数器 用于告知用户插入数据的相关信息 但是不影响程序的正常执行。
- Hive新版本中 这是一个issues 临时解决方式如下
Solved: Hive Metastore Connection Failure then Retry - Cloudera Community - 151661
解决在mysql metastore中删除 PART_COL_STATS这张表即可。
- datagrip客户端
- 使用datagrip 连接mysql
-
- 使用datagrip 连接hive
- 将hive驱动 上传到 hive/lib_my 目录中
- 使用datagrip 连接hive
-
-
- 使用datagrip 连接hive
-
- Spark安装
- Spark环境搭建-Local
- 基本原理
- Spark环境搭建-Local
在本地使用单机多线程模拟Spark集群中的各个角色
Local模式就是常用于本地开发测试,本地还分为local单线程和local-cluster多线程;
本质:启动一个JVM Process进程(一个进程里面有多个线程),执行任务Task
- 该模式被称为Local[N]模式,是用单机的多个线程来模拟Spark分布式计算,直接运行在本地,便于调试,通常用来验证开发出来的应用程序逻辑上有没有问题。
- 通常Cpu有几个Core,就指定几个线程,最大化利用计算能力.
- 其中N代表可以使用N个线程,每个线程拥有一个cpu core。如果不指定N,则默认是1个线程(该线程有1个core)。
- 如果是local[*],则代表 Run Spark locally with as many worker threads as logical cores on your machine.按照Cpu最多的Cores设置线程数
图解:
-
-
- 安装包下载
-
目前Spark最新稳定版本:课程中使用目前Spark最新稳定版本:3.1.x系列
https://spark.apache.org/docs/3.1.2/index.html
★注意1:
Spark3.0+基于Scala2.12
★注意2:
目前企业中使用较多的Spark版本还是Spark2.x,如Spark2.2.0、Spark2.4.5都使用较多,但未来Spark3.X肯定是主流,毕竟官方高版本是对低版本的兼容以及提升
Spark Release 3.0.0 | Apache Spark
-
-
- 基础操作
-
1.上传:将安装包上传至node1
2.解压:将spark安装包【spark-3.0.1-bin-hadoop2.7.tgz】解压至【/export/server】目录:
| tar -zxvf spark-3.1.2-bin-hadoop3.2.tgz -C /export/server/ |
3.改权限:如果有权限问题,可以修改为root,方便学习时操作,实际中使用运维分配的用户和权限即可
| chown -R root /export/server/spark-3.1.2-bin-hadoop3.2 chgrp -R root /export/server/spark-3.1.2-bin-hadoop3.2 |
注意:chgrp命令用来改变文件或目录所属的用户组
4.改名或创建软链接:方便后期升级
| ln -s /export/server/spark-3.1.2-bin-hadoop3.2 /export/server/spark |
5.更新环境变量
| # spark export SPARK_HOME=/root/anaconda3/bin export PATH=$PATH:$SPARK_HOME/bin |
查看目录结构:其中各个目录含义如下:
| bin 可执行脚本 conf 配置文件 data 示例程序使用数据 examples 示例程序 jars 依赖 jar 包 python pythonAPI sbin 集群管理命令 yarn 整合yarn需要的东东 |
-
-
- 测试
- 运行spark-shell
- 测试
-
●开箱即用:直接启动bin目录下的spark-shell:
| /export/server/spark/bin/spark-shell |
●运行成功以后,有如下提示信息:
sc:SparkContext实例对象:
spark:SparkSession实例对象
4040:Web监控页面端口号
●Spark-shell说明:
1.直接使用./spark-shell
表示使用local 模式启动,在本机启动一个SparkSubmit进程
2.还可指定参数 --master,如:
spark-shell --master local[N] 表示在本地模拟N个线程来运行当前任务
spark-shell --master local[*] 表示使用当前机器上所有可用的资源
3.不携带参数默认就是
spark-shell --master local[*]
4.后续还可以使用--master指定集群地址,表示把任务提交到集群上运行,如
./spark-shell --master spark://node1:7077,node2:7077
5.退出spark-shell
使用 :quit
-
-
-
- 运行pyspark-shell
-
-
为什么学习PySpark?
Python 现在是 Spark 上使用最广泛的语言。PySpark 在 PyPI(Python 包索引)上的每月下载量超过 500 万次。此版本改进了其功能和可用性,包括重新设计带有 Python 类型提示的 Pandas UDF API、新的 Pandas UDF 类型和更多 Pythonic 错误处理。
参考链接:Spark Release 3.0.0 | Apache Spark
执行pyspark也就是使用python语言操作Spark集群,在安装完Spark基础环境之后,我们还需要安装python环境,而今支持python环境最佳的环境就是Anaconda,避免再去安装的单独的python发行版,因此Anaconda也称之为数据学科必备python环境。
接下来首先学习PySpark安装以及Anaconda安装及基本使用。
-
- PySpark安装
- PySpark安装
- PySpark安装
首先PySpark需要从PyPi上面安装,如下URL:pyspark · PyPI
若安装PySpark需要首先具备Python环境,这里使用Anaconda环境,安装过程如下:
-
-
- Linux的Anaconda安装
-
安装版本:https://www.anaconda.com/distribution/#download-section
Python3.8.8版本:Anaconda3-2021.05-Linux-x86_64.sh
-
-
- PySpark Vs Spark
-
同学们可能有疑问, 我们不是学的Spark框架吗? 怎么会安装一个叫做PySpark呢?
这里简单说明一下:
PySpark: 是Python的库, 由Spark官方提供. 专供Python语言使用. 类似Pandas一样,是一个库
Spark: 是一个独立的框架, 包含PySpark的全部功能, 除此之外, Spark框架还包含了对R语言\ Java语言\ Scala语言的支持. 功能更全. 可以认为是通用Spark。
| 功能 | PySpark | Spark |
| 底层语言 | Scala(JVM) | Scala(JVM) |
| 上层语言支持 | Python | Python\Java\Scala\R |
| 集群化\分布式运行 | 支持 | 支持 |
| 定位 | Python库 (客户端) | 标准框架 (客户端和服务端) |
| 是否可以Daemon运行 | No | Yes |
| 使用场景 | 生产环境集群化运行 | 生产环境集群化运行 |
我们先从安装PySpark开始
-
-
-
- Anaconda安装步骤
-
-
cd /export/software 2.安装anaconda,执行下列命令 bash Anaconda3-2021.05-Linux-x86_64.sh 3.在安装过程中会显示配置路径 Prefix=/root/anaconda3/ 4.安装完之后,配置环境变量 vim /etc/profile ##增加如下配置 export ANACONDA_HOME=/root/anaconda3/bin export PATH=$PATH:$ANACONDA_HOME/bin source /etc/profile 5.重启所有的Crt窗口,运行python,如果仍是Centos自带的python信息,必须重启Crt窗口 |
该部分通过下述步骤完成安装。Anaconda是一个数据科学环境,可以不需要在安装任何python环境支持下使用,而且Anaconda内部集成了多达180+多的工具包可以很好帮助到数据分析和数据科学任务的处理。
-
-
-
- Anaconda启动并测试
-
-
输入Python启动:
测试:
注意:如果有问题请切记修改
| sudo vim ~/.bashrc export PATH=~/anaconda3/bin:$PATH |
-
-
-
- Anaconda相关组件介绍
-
-
Anaconda(水蟒):是一个科学计算软件发行版,集成了大量常用扩展包的环境,包含了 conda、Python 等 180 多个科学计算包及其依赖项,并且支持所有操作系统平台。下载地址:https://www.continuum.io/downloads
- 安装包:pip install xxx,conda install xxx
- 卸载包:pip uninstall xxx,conda uninstall xxx
- 升级包:pip install upgrade xxx,conda update xxx
Jupyter Notebook:启动命令
| jupyter notebook |
功能如下:
- Anaconda自带,无需单独安装
- 实时查看运行过程
- 基本的web编辑器(本地)
- ipynb 文件分享
- 可交互式
- 记录历史运行结果
修改jupyter显示的文件路径:
通过jupyter notebook --generate-config命令创建配置文件,之后在进入用户文件夹下面查看.jupyter隐藏文件夹,修改其中文件jupyter_notebook_config.py的202行为计算机本地存在的路径。
IPython:
命令:ipython,其功能如下
1.Anaconda自带,无需单独安装
2.Python的交互式命令行 Shell
3.可交互式
4.记录历史运行结果
5.及时验证想法
Spyder:
命令:spyder,其功能如下
1.Anaconda自带,无需单独安装
2.完全免费,适合熟悉Matlab的用户
3.功能强大,使用简单的图形界面开发环境
下面就Anaconda中的conda命令做详细介绍和配置。
-
-
-
- conda环境安装及配置[了解]
-
-
- conda命令及pip命令
conda管理数据科学环境,conda和pip类似均为安装、卸载或管理Python第三方包。
| conda install 包名 pip install 包名 conda uninstall 包名 pip uninstall 包名 conda install -U 包名 pip install -U 包名 |
(2) Anaconda设置为国内下载镜像
| conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/ conda config --set show_channel_urls yes |
(3)conda创建虚拟环境
| conda env list conda create xxx python=版本号 #创建python3.8.8环境 activate 环境 #激活环境 deactivate 环境 #退出环境 |
-
-
- PySpark安装
-
这里介绍三种安装方式,方式1最为简单,大家可以尝试使用。
-
-
-
- [动手安装]方式1:直接安装PySpark
-
-
安装如下:
| 使用PyPI安装PySpark如下:也可以指定版本安装 pip install pyspark 或者指定清华镜像(对于网络较差的情况): pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pyspark # 指定清华镜像源 如果要为特定组件安装额外的依赖项,可以按如下方式安装(此步骤暂不执行,后面Sparksql部分会执行): pip install pyspark[sql] |
截图如下:
-
-
-
- [动手安装]方式2:创建Conda环境安装PySpark
-
-
| #从终端创建新的虚拟环境,如下所示 conda create -n pyspark_env python=3.8 #创建虚拟环境后,它应该在 Conda 环境列表下可见,可以使用以下命令查看 conda env list #现在使用以下命令激活新创建的环境: conda activate pyspark_env #您可以在新创建的环境中通过使用PyPI安装PySpark来安装pyspark,例如如下。它将pyspark_env在上面创建的新虚拟环境下安装 PySpark。 pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pyspark # 指定清华镜像源 #或者,可以从 Conda 本身安装 PySpark: conda install pyspark |
如下截图:
-
-
-
- 初体验-PySpark shell方式
-
-
前面的Spark Shell实际上使用的是Scala交互式Shell,实际上 Spark 也提供了一个用 Python 交互式Shell,即Pyspark。
-
-
-
-
- 启动命令
-
-
-
链接如下:Overview - Spark 3.1.2 Documentation
我们可以看到PySpark提供了对应启动脚本位于bin目录下,可以执行bin/pyspark执行
启动:
这里采用单机方式,命令如下:
| bin/pyspark --master local[*] |
截图如下:
-
-
-
-
- WordCount案例
-
-
-
1.准备数据
上传文件到hdfs
hadoop fs -put /root/words.txt /pydata/input/words.txt
目录如果不存在可以创建
hadoop fs -mkdir -p /pydata/input
结束后可以删除测试文件夹
hadoop fs -rm -r /pydata
2.执行WordCount
| # 第一步、读取本地数据 封装到RDD集合,认为列表List wordsRDD = sc.textFile("hdfs://node1:8020/pydata/input/words.txt") # 第二步、处理数据 调用RDD中函数,认为调用列表中的函数 # a. 每行数据分割为单词 flatMapRDD = wordsRDD.flatMap(lambda line: line.split(" ")) # b. 转换为二元组,表示每个单词出现一次 mapRDD = flatMapRDD.map(lambda x: (x, 1)) # c. 按照Key分组聚合 resultRDD = mapRDD.reduceByKey(lambda a, b: a + b) # 第三步、输出数据 res_rdd_col2 = resultRDD.collect() # 输出到hdfs文件系统中 resultRDD.saveAsTextFile("hdfs://node1:8020/pydata/output2/") |
关键步骤截图如下:
3.查看结果文件
hadoop fs -text /pydata/output2/part*
-
-
- 监控页面
-
每个Spark Application应用运行时,都有一个WEB UI监控页面,默认端口号为4040,可以使用浏览器打开页面,
如下为完成的Job截图。
-
-
- 运行圆周率
-
Spark框架自带的案例Example中涵盖圆周率PI计算程序,可以使用【$SPARK_HOME/bin/spark-submit】提交应用执行,运行在本地模式。
- 自带案例jar包:【/export/server/spark/examples/jars/spark-examples_2.12-3.1.2.jar】
- 提交运行PI程序
| SPARK_HOME=/export/server/spark ${SPARK_HOME}/bin/spark-submit \ --master local[2] \ ${SPARK_HOME}/examples/src/main/python/pi.py \ 10 |
-
- 环境搭建-Standalone
Standalone模式是Spark自带的一种集群模式,不同于前面本地模式启动多个进程来模拟集群的环境,Standalone模式是真实地在多个机器之间搭建Spark集群的环境,完全可以利用该模式搭建多机器集群,用于实际的大数据处理。
-
-
- Standalone 架构
-
Standalone集群使用了分布式计算中的master-slave模型,master是集群中含有Master进程的节点,slave是集群中的Worker节点含有Executor进程。
在StandAlone模式下, Master角色和Worker角色各自有各自的进程, 这些进程连接在一起,形成一个Spark环境, 其中:
Cluster Mode Overview - Spark 3.4.1 Documentation
| 主要组件如下: |
Spark Standalone集群,类似Hadoop YARN,管理集群资源和调度资源:
- 主节点Master:
- 管理整个集群资源,接收提交应用,分配资源给每个应用,运行Task任务
- 从节点Workers:
- 管理每个机器的资源,分配对应的资源来运行Task;
- 每个从节点分配资源信息给Worker管理,资源信息包含内存Memory和CPU Cores核数
- 历史服务器HistoryServer(可选):
- Spark Application运行完成以后,保存事件日志数据至HDFS,启动HistoryServer可以查看应用运行相关信息。
- 角色分析
- Spark Application运行完成以后,保存事件日志数据至HDFS,启动HistoryServer可以查看应用运行相关信息。
如下图:
Master角色, 启动一个名为Master的进程, Master进程有且仅有1个(HA模式除外)
Worker角色, 启动一个名为 Worker的进程., Worker进程最少1个, 最多不限制
Master进程负责资源的管理, 并在有程序运行时, 为当前程序创建管理者Driver
Worker进程负责干活, 向Master汇报状态, 并听从程序Driver的安排,创建Executor干活
其中, 职责分配上:
- - Master进程负责资源的管理
- - 程序运行后的Driver运行在Master进程内, 负责任务的管理
- - 程序运行后的Executor运行在Worker进程内, 负责任务的计算
-
- Spark Application运行完成以后,保存事件日志数据至HDFS,启动HistoryServer可以查看应用运行相关信息。
-
-
- 集群规划
-
Standalone集群安装服务规划与资源配置:
| node1:master/worker node2:slave/worker node3:slave/worker |
官方文档:http://spark.apache.org/docs/3.1.2/spark-standalone.html
-
-
- 为每台机器安装Python3
-
由于是在分布式集群模式上运行Spark
那么,我们执行的程序,将会分配到集群的机器上去运行.
由于使用Python语言开发, 所以,集群中每一台服务器都需要有Python执行环境.
我们需要在每台机器上安装Python3环境
上传资料提供的: Anaconda3-2021.05-Linux-x86_64.sh到服务器
| # 执行 sh Anaconda3-2021.05-Linux-x86_64.sh 在弹出选择安装位置的时候, 建议安装到: /export/server/anaconda3,这里使用默认安装到/root/anaconda 安装完成后执行[这里可不执行,因为我们选择的是默认安装路径]: ln -s /export/server/anaconda3/bin/python3 /usr/bin/python3 |
为每台机器,增加环境变量:
| # SPARK_HOME export SPARK_HOME=/export/server/spark export PATH=$PATH:$SPARK_HOME/bin #Anaconda export ANACONDA_HOME=/root/anaconda3 export PATH=$PATH:$ANACONDA_HOME/bin |
-
-
- 修改配置并分发
- Workers节点主机名
- 修改配置并分发
-
将【$SPARK_HOME/conf/slaves.template】名称命名为【slaves】,填写从节点名称。
| ##进入配置目录 cd /export/server/spark/conf ##修改配置文件名称 mv workers.template slaves vim slaves ##内容如下: node1 node2 node3 |
-
-
-
- 配置Master、Workers、HistoryServer
-
-
在配置文件$SPARK_HOME/conf/spark-env.sh添加如下内容:
| ## 进入配置目录 cd /export/server/spark/conf ## 修改配置文件名称 mv spark-env.sh.template spark-env.sh ## 修改配置文件 vim spark-env.sh ## 增加如下内容: ## 设置JAVA安装目录 JAVA_HOME=/export/server/jdk ## HADOOP软件配置文件目录,读取HDFS上文件和运行YARN集群 HADOOP_CONF_DIR=/export/server/hadoop/etc/hadoop YARN_CONF_DIR=/export/server/hadoop/etc/hadoop ## 指定spark老大Master的IP和提交任务的通信端口 export SPARK_MASTER_HOST=node1 export SPARK_MASTER_PORT=7077 SPARK_MASTER_WEBUI_PORT=8080 SPARK_WORKER_CORES=1 SPARK_WORKER_MEMORY=1g SPARK_WORKER_PORT=7078 SPARK_WORKER_WEBUI_PORT=8081 ## 历史日志服务器 SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://node1:8020/sparklog/ -Dspark.history.fs.cleaner.enabled=true" |
注意:上述的hadoop3.3.0需要创建软连接
ln -s /export/server/hadoop-3.3.0/ /export/server/hadoop
-
-
-
- 创建EventLogs存储目录
-
-
启动HDFS服务,创建应用运行事件日志目录,命令如下:
| hdfs dfs -mkdir -p /sparklog/ |
如果遇到Hadoop处理安全模式,可以按照下面方式退出Hadoop安全模式:hadoop dfsadmin -safemode leave 。
-
-
-
- 配置Spark应用保存EventLogs
-
-
将【$SPARK_HOME/conf/spark-defaults.conf.template】名称命名为【spark-defaults.conf】,填写如下内容:
| ## 进入配置目录 cd /export/server/spark/conf ## 修改配置文件名称 mv spark-defaults.conf.template spark-defaults.conf vim spark-defaults.conf ## 添加内容如下: spark.eventLog.enabled true spark.eventLog.dir hdfs://node1:8020/sparklog/ spark.eventLog.compress true |
-
-
-
- 设置日志级别
-
-
将【$SPARK_HOME/conf/log4j.properties.template】名称命名为【log4j.properties】,修改级别为警告WARN。
| ## 进入目录 cd /export/server/spark/conf ## 修改日志属性配置文件名称 mv log4j.properties.template log4j.properties ## 改变日志级别 vim log4j.properties |
修改内容如下:
-
-
- 分发到其他机器
-
将配置好的将 Spark 安装包分发给集群中其它机器,命令如下:
| cd /export/server/ scp -r spark-3.1.2-bin-hadoop3.2 root@node2:$PWD scp -r spark-3.1.2-bin-hadoop3.2 root@node3:$PWD ##创建软连接 ln -s /export/server/spark-3.1.2-bin-hadoop3.2 /export/server/spark |
-
-
- 启动服务进程
-
- 启动方式1:集群启动和停止
在主节点上启动spark集群
| cd /export/server/spark sbin/start-all.sh sbin/start-history-server.sh |
在主节点上停止spark集群
| /export/server/spark/sbin/stop-all.sh |
- 启动方式2:单独启动和停止
在 master 安装节点上启动和停止 master:
| start-master.sh stop-master.sh |
在 Master 所在节点上启动和停止worker(work指的是slaves 配置文件中的主机名)
| start-slaves.sh stop-slaves.sh |
- WEB UI页面
可以看出,配置了3个Worker进程实例,每个Worker实例为1核1GB内存,总共是2核 2GB 内存。目前显示的Worker资源都是空闲的,当向Spark集群提交应用之后,Spark就会分配相应的资源给程序使用,可以在该页面看到资源的使用情况。
- 历史服务器HistoryServer:
| /export/server/spark/sbin/start-history-server.sh |
WEB UI页面地址:http://node1:18080
-
-
- 测试
- Wordcount测试
- 测试
-
Pyspark shell脚本
| /export/server/spark/bin/pyspark --master spark://node1:7077 \ --conf "spark.pyspark.driver.python=/root/anaconda3/bin/python3" \ --conf "spark.pyspark.python=/root/anaconda3/bin/python3" |
截图如下:
- 运行程序
| resultRDD2 = sc.textFile("hdfs://node1:8020/pydata/input/words.txt") \ .flatMap(lambda line: line.split(" ")) \ .map(lambda x: (x, 1)) \ .reduceByKey(lambda a, b: a + b) resultRDD2 .collect() |
查看文件
| hadoop fs -text /wordcount/output2/part* |
截图如下:
- 注意
集群模式下程序是在集群上运行的,不要直接读取本地文件,应该读取hdfs上的
因为程序运行在集群上,具体在哪个节点上我们运行并不知道,其他节点可能并没有那个数据文件
- SparkContext web UI
- 查看Master主节点WEB UI界面:
-
-
-
- 提交运行圆周率
-
-
将上述运行在Local Mode的圆周率PI程序,运行在Standalone集群上,修改【--master】地址为Standalone集群地址:spark://node1:7077,具体命令如下:
| ${SPARK_HOME}/bin/spark-submit \ --master spark://node1:7077 \ --conf "spark.pyspark.driver.python=/root/anaconda3/bin/python3" \ --conf "spark.pyspark.python=/root/anaconda3/bin/python3" \ ${SPARK_HOME}/examples/src/main/python/pi.py \ 10 |
查看Master主节点WEB UI界面:
注意:
Python程序不像Java可以使用Maven打包,需要使用-py-files将项目达成zip包
在提交spark的时候,我们往往python工程是多个python文件,彼此之间有调用关系。
- 那如何提交python工程呢?
| ./bin/spark-submit –py-files XXXX.zip aaa.py |
- XXXX是你将你所有需要用到的python文件打包成一个zip文件
- aaa是你的python文件的main函数所在的py文件。
- 对于提交之后不同节点显示Python版本不一致
| import os os.environ['PYTHONPATH']='python3' |
- 提交任务后遇到ascii码问题
其实我们是想要utf-8默认运行python的,但是就算你在文件里指定了#coding:utf-8仍然不行
| import sys reload(sys) sys.setdefaultencoding('utf-8') |
-
- 环境搭建-Standalone HA
Spark Standalone集群是Master-Slaves架构的集群模式,和大部分的Master-Slaves结构集群一样,存在着Master单点故障(SPOF)的问题。
-
-
- 高可用HA
-
如何解决这个单点故障的问题,Spark提供了两种方案:
1.基于文件系统的单点恢复(Single-Node Recovery with Local File System)--只能用于开发或测试环境。
2.基于zookeeper的Standby Masters(Standby Masters with ZooKeeper)--可以用于生产环境。
ZooKeeper提供了一个Leader Election机制,利用这个机制可以保证虽然集群存在多个Master,但是只有一个是Active的,其他的都是Standby。当Active的Master出现故障时,另外的一个Standby Master会被选举出来。由于集群的信息,包括Worker, Driver和Application的信息都已经持久化到文件系统,因此在切换的过程中只会影响新Job的提交,对于正在进行的Job没有任何的影响。加入ZooKeeper的集群整体架构如下图所示。
-
-
- 基于Zookeeper实现HA
-
如何解决这个单点故障的问题,Spark提供了HA方案:
即, 运行2个或多个Master进程.
其中一个是Active状态, 正常工作.
其余的为Standby状态, 待命中, 一旦Active Master出现问题, 立刻接上.
由于多个Master需要共享状态, 即大家要明确谁才是Active, 谁是Standby, 所以,这个方案需要引入Zookeeper
ZooKeeper提供了一个Leader Election机制,利用这个机制可以保证虽然集群存在多个Master,但是只有一个是Active的,其他的都是Standby。当Active的Master出现故障时,另外的一个Standby Master会被选举出来, 作为Active Master去工作。
官方文档:http://spark.apache.org/docs/3.1.2/spark-standalone.html#standby-masters-with-zookeeper
- 先停止Sprak集群
| /export/server/spark/sbin/stop-all.sh |
- 在node1上配置
| vim /export/server/spark/conf/spark-env.sh |
注释或删除MASTER_HOST内容:
| # SPARK_MASTER_HOST=node1 |
增加如下配置
| SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=node1:2181,node2:2181,node3:2181 -Dspark.deploy.zookeeper.dir=/spark-ha" |
参数含义说明:
| spark.deploy.recoveryMode:恢复模式 spark.deploy.zookeeper.url:ZooKeeper的Server地址 spark.deploy.zookeeper.dir:保存集群元数据信息的文件、目录。包括Worker、Driver、Application信息。 |
- 将spark-env.sh分发集群
| cd /export/server/spark/conf scp -r spark-env.sh root@node2:$PWD scp -r spark-env.sh root@node3:$PWD |
- 启动集群服务
启动ZOOKEEPER服务
| zkServer.sh status zkServer.sh stop zkServer.sh start |
- node1上启动Spark集群执行
| /export/server/spark/sbin/start-all.sh |
- 在node2上再单独只起个master:
| /export/server/spark/sbin/start-master.sh |
查看WebUI
默认情况下,先启动Master就为Active Master,如下截图所示:
如果将node1的Master进程Kill掉,node2的Master在1Min-2Min左右会接替node1的Master作用。 也就是在执行过程中,使用jps查看Active Master进程ID,将其kill,观察Master是否自动切换与应用运行完成结束。(需要等待1-2min)
-
-
- 测试运行
- Wordcount测试
- 测试运行
-
●测试主备切换
1.在node1上使用jps查看master进程id
2.使用kill -9 id号强制结束该进程
3.稍等片刻后刷新node2的web界面发现node2为Alive
如启动spark-shell,需要指定多个master地址
/export/server/spark/bin/spark-shell --master spark://node1:7077,node2:7077
| bin/pyspark --master spark://node1:7077,node2:7077 \ --conf "spark.pyspark.driver.python=/root/anaconda3/bin/python3" \ --conf "spark.pyspark.python=/root/anaconda3/bin/python3" |
如下代码:
| resultRDD2 = sc.textFile("hdfs://node1:8020/pydata/input/words.txt") \ .flatMap(lambda line: line.split(" ")) \ .map(lambda x: (x, 1)) \ .reduceByKey(lambda a, b: a + b) resultRDD2 .collect() |
截图如下:
停止集群
| /export/server/spark/sbin/stop-all.sh |
-
-
-
- 提交测试运行圆周率
-
-
Standalone HA集群运行应用时,指定ClusterManager参数属性为
| --master spark://host1:port1,host2:port2 |
提交圆周率PI运行集群,命令如下:
| ${SPARK_HOME}/bin/spark-submit \ --master spark://node1.itcast.cn:7077,node2.itcast.cn:7077 \ --conf "spark.pyspark.driver.python=/root/anaconda3/bin/python3" \ --conf "spark.pyspark.python=/root/anaconda3/bin/python3" \ ${SPARK_HOME}/examples/src/main/python/pi.py \ 100 |
结果截图如下:
-
- 环境搭建-Spark on YARN
将Spark Application提交运行到YARN集群上,至关重要,企业中大多数都是运行在YANR上,文档:http://spark.apache.org/docs/3.1.2/running-on-yarn.html#launching-spark-on-yarn。
spark on yarn 模式官方文档说明:
Running Spark on YARN - Spark 3.4.1 Documentation
http://spark.apache.org/docs/latest/running-on-yarn.html#configuration
同时注意,如果我们的spark程序是运行在yarn上面的话,那么我们就不需要spark 的集群了,我们只需要找任意一台机器配置我们的spark的客户端提交任务到yarn集群上面去即可。
Yarn是一个成熟稳定且强大的资源管理和任务调度的大数据框架,在企业中市场占有率很高,意味着有很多公司都在用Yarn,将公司的资源交给Yarn做统一的管理!并支持对任务做多种模式的调度,如FIFO/Capacity/Fair等多种调度模式!
所以很多计算框架,都主动支持将计算任务放在Yarn上运行,如Spark/Flink
企业中也都是将Spark Application提交运行在YANR上。
-
-
- SparkOnYarn本质
-
- Spark On Yarn的本质?
将Spark任务的pyspark文件,经过Py4J转换,提交到Yarn的JVM中去运行
- Spark On Yarn需要啥?
1.需要Yarn集群:已经安装了
2.需要提交工具:spark-submit命令--在spark/bin目录
3.需要被提交的PySpark代码:Spark任务的文件,如spark/examples/src/main/python/pi.py中有示例程序,或我们后续自己开发的Spark任务)
4.需要其他依赖jar:Yarn的JVM运行PySpark的代码经过Py4J转化为字节码,需要Spark的jar包支持!Spark安装目录中有jar包,在spark/jars/中
-
-
- 修改配置
-
当Spark Application运行到YARN上时,在提交应用时指定master为yarn即可,同时需要告知YARN集群配置信息(比如ResourceManager地址信息),此外需要监控Spark Application,配置历史服务器相关属性。
-
-
-
- 修改spark-env.sh
-
-
基础操作
| cd /export/server/spark/conf vim /export/server/spark/conf/spark-env.sh |
添加内容
| ## HADOOP软件配置文件目录,读取HDFS上文件和运行YARN集群 HADOOP_CONF_DIR=/export/server/hadoop/etc/hadoop YARN_CONF_DIR=/export/server/hadoop/etc/hadoop |
同步
| cd /export/server/spark/conf scp -r spark-env.sh root@node2:$PWD scp -r spark-env.sh root@node3:$PWD |
-
-
-
- 整合历史服务器MRHistoryServer并关闭资源检查
-
-
- 整合Yarn历史服务器并关闭资源检查
在【$HADOOP_HOME/etc/hadoop/yarn-site.xml】配置文件中,指定MRHistoryServer地址信息,添加如下内容,
在node1上修改
| cd /export/server/hadoop/etc/hadoop vim /export/server/hadoop/etc/hadoop/yarn-site.xml |
添加内容
| <configuration> <!-- 配置yarn主节点的位置 --> <property> <name>yarn.resourcemanager.hostname</name> <value>node1</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 设置yarn集群的内存分配方案 --> <property> <name>yarn.nodemanager.resource.memory-mb</name> <value>20480</value> </property> <property> <name>yarn.scheduler.minimum-allocation-mb</name> <value>2048</value> </property> <property> <name>yarn.nodemanager.vmem-pmem-ratio</name> <value>2.1</value> </property> <!-- 开启日志聚合功能 --> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <!-- 设置聚合日志在hdfs上的保存时间 --> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>604800</value> </property> <!-- 设置yarn历史服务器地址 --> <property> <name>yarn.log.server.url</name> <value>http://node1:19888/jobhistory/logs</value> </property> <!-- 关闭yarn内存检查 --> <property> <name>yarn.nodemanager.pmem-check-enabled</name> <value>false</value> </property> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property> </configuration> |
由于使用虚拟机运行服务,默认情况下YARN检查机器内存,当内存不足时,提交的应用无法运行,可以设置不检查资源
同步
| cd /export/server/hadoop/etc/hadoop scp -r yarn-site.xml root@node2:$PWD scp -r yarn-site.xml root@node3:$PWD |
-
-
-
- 历史服务HistoryServer地址
-
-
在【$SPARK_HOME/conf/spark-defaults.conf】文件增加SparkHistoryServer地址信息:
- 配置spark历史服务器
| ## 进入配置目录 cd /export/server/spark/conf ## 修改配置文件名称 mv spark-defaults.conf.template spark-defaults.conf vim spark-defaults.conf |
## 添加内容:
| spark.eventLog.enabled true spark.eventLog.dir hdfs://node1:8020/sparklog/ spark.eventLog.compress true spark.yarn.historyServer.address node1:18080 |
- 设置日志级别
| ## 进入目录 cd /export/server/spark/conf ## 修改日志属性配置文件名称 mv log4j.properties.template log4j.properties ## 改变日志级别 vim log4j.properties |
修改内容如下:
同步
| cd /export/server/spark/conf scp -r spark-defaults.conf root@node2:$PWD scp -r spark-defaults.conf root@node3:$PWD scp -r log4j.properties root@node2:$PWD scp -r log4j.properties root@node3:$PWD |
-
-
-
- 配置依赖Spark Jar包
-
-
当Spark Application应用提交运行在YARN上时,默认情况下,每次提交应用都需要将依赖Spark相关jar包上传到YARN 集群中,为了节省提交时间和存储空间,将Spark相关jar包上传到HDFS目录中,设置属性告知Spark Application应用。
| ## hdfs上创建存储spark相关jar包目录 hadoop fs -mkdir -p /spark/jars/ ## 上传$SPARK_HOME/jars所有jar包 hadoop fs -put /export/server/spark/jars/* /spark/jars/ |
在spark-defaults.conf中增加Spark相关jar包位置信息:
| 在node1上操作 vim /export/server/spark/conf/spark-defaults.conf 添加内容 spark.yarn.jars hdfs://node1:8020/spark/jars/* |
同步
| cd /export/server/spark/conf scp -r spark-defaults.conf root@node2:$PWD scp -r spark-defaults.conf root@node3:$PWD |
-
-
- 启动服务
-
Spark Application运行在YARN上时,上述配置完成
启动服务:HDFS、YARN、MRHistoryServer和Spark HistoryServer,命令如下:
| ## 启动HDFS和YARN服务,在node1执行命令 start-dfs.sh start-yarn.sh 或 /export/server/hadoop/sbin/start-all.sh 注意:在onyarn模式下不需要启动start-all.sh(jps查看一下看到worker和master) ## 启动MRHistoryServer服务,在node1执行命令 /export/server/hadoop/sbin/mr-jobhistory-daemon.sh start historyserver ## 启动Spark HistoryServer服务,,在node1执行命令 /export/server/spark/sbin/start-history-server.sh |
- Spark HistoryServer服务WEB UI页面地址:
-
-
- 提交应用测试
-
先将圆周率PI程序提交运行在YARN上,命令如下:
| SPARK_HOME=/export/server/spark ${SPARK_HOME}/bin/spark-submit \ --master yarn \ --conf "spark.pyspark.driver.python=/root/anaconda3/bin/python3" \ --conf "spark.pyspark.python=/root/anaconda3/bin/python3" \ ${SPARK_HOME}/examples/src/main/python/pi.py \ 10 |
运行完成在YARN 监控页面截图如下:
设置资源信息,提交运行WordCount程序至YARN上,命令如下:
| SPARK_HOME=/export/server/spark ${SPARK_HOME}/bin/spark-submit \ --master yarn \ --driver-memory 512m \ --executor-memory 512m \ --executor-cores 1 \ --num-executors 2 \ --queue default \ --conf "spark.pyspark.driver.python=/root/anaconda3/bin/python3" \ --conf "spark.pyspark.python=/root/anaconda3/bin/python3" \ ${SPARK_HOME}/examples/src/main/python/pi.py \ 10 |
当WordCount应用运行YARN上完成以后,从8080 WEB 页面点击应用历史服务连接,查看应用运行状态信息。
-
- SparkSQL整合Hive步骤
- 第一步:将hive-site.xml拷贝到spark安装路径conf目录
- SparkSQL整合Hive步骤
node1执行以下命令来拷贝hive-site.xml到所有的spark安装服务器上面去
| cd /export/server/hive/conf cp hive-site.xml /export/server/spark/conf/ scp hive-site.xml root@node2:/export/server/spark/conf/ scp hive-site.xml root@node3:/export/server/spark/conf/ |
-
-
- 第二步:将mysql的连接驱动包拷贝到spark的jars目录下
-
node1执行以下命令将连接驱动包拷贝到spark的jars目录下,三台机器都要进行拷贝
| cd /export/server/hive/lib cp mysql-connector-java-5.1.32.jar /export/server/spark/jars/ scp mysql-connector-java-5.1.32.jar root@node2:/export/server/spark/jars/ scp mysql-connector-java-5.1.32.jar root@node3:/export/server/spark/jars/ |
-
-
- 第三步:Hive开启MetaStore服务
-
(1)修改 hive/conf/hive-site.xml新增如下配置
| 远程模式部署metastore 服务地址 <?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>hive.metastore.uris</name> <value>thrift://node1:9083</value> </property> </configuration> |
2: 后台启动 Hive MetaStore服务
前台启动:
| bin/hive --service metastore & |
后台启动:
| nohup /export/server/hive/bin/hive --service metastore 2>&1 >> /var/log.log & |
完整的hive-site.xml文件
| <configuration> <!-- 存储元数据mysql相关配置 --> <property> <name>javax.jdo.option.ConnectionURL</name> <value> jdbc:mysql://node1:3306/hive?createDatabaseIfNotExist=true&useSSL=false&useUnicode=true&characterEncoding=UTF-8</value> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>123456</value> </property> <!-- H2S运行绑定host --> <property> <name>hive.server2.thrift.bind.host</name> <value>node1</value> </property> <!-- 远程模式部署metastore 服务地址 --> <property> <name>hive.metastore.uris</name> <value>thrift://node1:9083</value> </property> <!-- 关闭元数据存储授权 --> <property> <name>hive.metastore.event.db.notification.api.auth</name> <value>false</value> </property> <!-- 关闭元数据存储版本的验证 --> <property> <name>hive.metastore.schema.verification</name> <value>false</value> </property> </configuration> |
-
-
- 第四步:测试Sparksql整合Hive是否成功
-
- [方式1]Spark-sql方式测试
先启动hadoop集群,在启动spark集群,确保启动成功之后node1执行命令,指明master地址、每一个executor的内存大小、一共所需要的核数、mysql数据库连接驱动:
| cd /export/server/spark bin/spark-sql --master local[2] --executor-memory 512m --total-executor-cores 1 或 bin/spark-sql --master spark://node1.itcast.cn:7077 --executor-memory 512m --total-executor-cores 1 |
执行成功后的界面:进入到spark-sql 客户端命令行界面
查看当前有哪些数据库, 并创建数据库
| show databases; create database sparkhive; |
看到数据的结果,说明sparksql整合hive成功!
注意:日志太多,我们可以修改spark的日志输出级别(conf/log4j.properties)
注意:
在spark2.0版本后由于出现了sparkSession,在初始化sqlContext的时候,会设置默认的spark.sql.warehouse.dir=spark-warehouse,
此时将hive与sparksql整合完成之后,在通过spark-sql脚本启动的时候,还是会在那里启动spark-sql脚本,就会在当前目录下创建一个spark.sql.warehouse.dir为spark-warehouse的目录,存放由spark-sql创建数据库和创建表的数据信息,与之前hive的数据息不是放在同一个路径下(可以互相访问)。但是此时spark-sql中表的数据在本地,不利于操作,也不安全。
所有在启动的时候需要加上这样一个参数:
--conf spark.sql.warehouse.dir=hdfs://node1:8020/user/hive/warehouse
保证spark-sql启动时不在产生新的存放数据的目录,sparksql与hive最终使用的是hive同一存放数据的目录。如果使用的是spark2.0之前的版本,由于没有sparkSession,不会出现spark.sql.warehouse.dir配置项,不会出现上述问题。
Spark2之后最后的执行脚本,node1执行以下命令重新进去spark-sql
| cd /export/server/spark bin/spark-sql \ --master spark://node1:7077 \ --executor-memory 512m --total-executor-cores 1 \ --conf spark.sql.warehouse.dir=hdfs://node1:8020/user/hive/warehouse |
- [方式2]PySpark-Shell方式启动:
| bin/spark-shell --master local[3] spark.sql("show databases").show |
如下图:
- [方式3]PySpark-Shell方式启动:
| bin/pyspark --master local[2] spark.sql("show databases").show() |
- Kafka环境搭建
-
- 搭建Kafka集群
-
- 将Kafka的安装包上传到虚拟机,并解压
| cd /export/software/ tar -xvzf kafka_2.12-2.4.1.tgz -C ../server/ cd /export/server/kafka_2.12-2.4.1/ |
- 修改 server.properties
| cd /export/server/kafka_2.12-2.4.1/config vim server.properties # 指定broker的id broker.id=0 # 指定 kafka的绑定监听的地址 listeners=PLAINTEXT://node1.itcast.cn:9092 # 指定Kafka数据的位置 log.dirs=/export/server/kafka_2.12-2.4.1/data # 配置zk的三个节点 zookeeper.connect=node1.itcast.cn:2181,node2.itcast.cn:2181,node3.itcast.cn:2181 |
- 将安装好的kafka复制到另外两台服务器
| cd /export/server scp -r kafka_2.12-2.4.1/ node2.itcast.cn:$PWD scp -r kafka_2.12-2.4.1/ node3.itcast.cn:$PWD 修改另外两个节点的broker.id分别为1和2 ---------node2.itcast.cn-------------- cd /export/server/kafka_2.12-2.4.1/config vim server.properties broker.id=1 listeners=PLAINTEXT://node2.itcast.cn:9092 --------node3.itcast.cn-------------- cd /export/server/kafka_2.12-2.4.1/config vim server.properties broker.id=2 listeners=PLAINTEXT://node3.itcast.cn:9092 |
- 配置KAFKA_HOME环境变量
| vim /etc/profile export KAFKA_HOME=/export/server/kafka_2.12-2.4.1 export PATH=:$PATH:${KAFKA_HOME} 分发到各个节点 scp /etc/profile node2.itcast.cn:$PWD scp /etc/profile node3.itcast.cn:$PWD 每个节点加载环境变量 source /etc/profile |
- 启动服务器
| # 启动ZooKeeper /export/server/zookeeper/bin/zkServer.sh start # 启动Kafka cd /export/server/kafka_2.12-2.4.1 nohup bin/kafka-server-start.sh config/server.properties 2>&1 & # 测试Kafka集群是否启动成功 : 使用 jps 查看各个节点 是否出现有kafka 或者通过 zookeeper查看 brokers节点目录下, 是否有三个ids |
-
-
- 目录结构分析
-
| 目录名称 | 说明 |
| bin | Kafka的所有执行脚本都在这里。例如:启动Kafka服务器、创建Topic、生产者、消费者程序等等 |
| config | Kafka的所有配置文件 |
| libs | 运行Kafka所需要的所有JAR包 |
| logs | Kafka的所有日志文件,如果Kafka出现一些问题,需要到该目录中去查看异常信息 |
| site-docs | Kafka的网站帮助文件 |
-
-
- Kafka一键启动/关闭脚本
-
为了方便将来进行一键启动、关闭Kafka,我们可以编写一个shell脚本来操作。将来只要执行一次该脚本就可以快速启动/关闭Kafka。
- 在节点1中创建 /export/onekey 目录
cd /export/onekey
- 准备slave配置文件,用于保存要启动哪几个节点上的kafka
| node1.itcast.cn node2.itcast.cn node3.itcast.cn |
- 编写start-kafka.sh脚本
| vim start-kafka.sh cat /export/onekey/slave | while read line do { echo $line ssh $line "source /etc/profile;export JMX_PORT=9988;nohup ${KAFKA_HOME}/bin/kafka-server-start.sh ${KAFKA_HOME}/config/server.properties >/dev/nul* 2>&1 & " }& wait done |
- 编写stop-kafka.sh脚本
| vim stop-kafka.sh cat /export/onekey/slave | while read line do { echo $line ssh $line "source /etc/profile;jps |grep Kafka |cut -d' ' -f1 |xargs kill -s 9" }& wait done |
- 给start-kafka.sh、stop-kafka.sh配置执行权限
| chmod u+x start-kafka.sh chmod u+x stop-kafka.sh |
- 执行一键启动、一键关闭
| ./start-kafka.sh ./stop-kafka.sh |
-
-
- 安装Kafka-Eagle监控
- 开启Kafka JMX端口
- JMX接口
- 开启Kafka JMX端口
- 安装Kafka-Eagle监控
-
JMX(Java Management Extensions)是一个为应用程序植入管理功能的框架。JMX是一套标准的代理和服务,实际上,用户可以在任何Java应用程序中使用这些代理和服务实现管理。很多的一些软件都提供了JMX接口,来实现一些管理、监控功能。
-
-
-
-
- 开启Kafka JMX
-
-
-
在启动Kafka的脚本前,添加:
| cd ${KAFKA_HOME} export JMX_PORT=9988 nohup bin/kafka-server-start.sh config/server.properties & |
-
-
-
- 安装Kafka-Eagle
-
-
| |
| |
| |
vim /etc/profile
| |
| source /etc/profile
vim conf/system-config.properties
| |
| |
| |
| |
./ke.sh start | |
| |
| http://node1.itcast.cn:8048/ke |
- Hbase集群搭建
- Hbase集群搭建
- Hbase数据模型
- Hbase集群搭建
-
-
- Hbase逻辑结构
-
-
-
- Hbase物理结构
-
Type:对于删除操作,类型为delete,写入操作类型为put
TimeStamp:不同版本Verison的数据根据timestamp进行区分
-
-
- Hbase原理初探
-
Master:所有RegionServer管理者,实现类为HMaster,主要作用如下:
- 对于表的操作:create,delete,alter
- 对于RegionServer的操作:分配regions到每个RegionServer,发现失效的Region server并重新分配其上的region;负载均衡和故障转移
RegionServer:为Region的管理者,实现类HRegionServer,作用如下:
- 对于数据的操作:get、put、delete
- 对于Region的操作:splitRegion,compactRegion
Region:
- Region是HBase中分布式存储和负载均衡的最小单元;
- 不同的region可以分别在不同的Region Server上;
Zookeeper:
Hbase通过ZK来做Master高可用,RegionServer的监控,元数据的入口以及集群配置
HDFS:
HDFS为Hbase提供底层数据存储服务,同时为Hbase提供高可用的支持。
Hbase中核心组件与作用[大数据平台架构-深入理解]
HBase中的组件包括Client、Zookeeper、HMaster、HRegionServer、HRegion、Store、MemStore、StoreFile、HFile、HLog等。
Client的作用
1.1 包含访问HBase的接口,并维护cache来加快对HBase的访问,比如region的位置信息
1.2 HBase Client通过RPC方式和HMaster、HRegionServer通信
Zookeeper的作用
2.1 实现HMaster主从节点的failover,集群高可用;
2.2 存储所有Region的寻址入口;
2.3 实时监控Region server的上线和下线信息。并实时通知给master;
2.4 存储HBase的schema和table元数据;
2.5 通过选举,保证任何时候,集群中只有一个master,Master与Regionserver 启动时会向ZooKeeper注册。
HMaster的作用
3.1 为HRegionServer分配region;
3.2 管理HRegionServer实现其负载均衡;
3.3 发现失效的Region server并重新分配其上的region;
3.4 HDFS上的垃圾文件回收;
3.5 实现DDL操作,处理schema更新请求。
从Hmaster功能可以看出,如果Hmaster挂掉,并不影响数据的读写,而会导致元数据无法修改,以及region的分配工作。
HRegionServer的作用
4.1 存放和管理本地HRegion,并负责切分正在运行过程中变的过大的region;
4.2 维护master分配给他的region,处理对这些region的io请求。
(ps:client访问hbase上的数据时不需要master的参与,因为数据寻址访问zookeeper和region server, 而数据读写访问region server。master仅仅维护table和region的元数据信息,而table的元数据信息 保存在zookeeper上,因此master负载很低。)
HRegion的作用
5.1 Region是HBase中分布式存储和负载均衡的最小单元;
5.2 不同的region可以分别在不同的Region Server上;
5.3 Region按大小分隔,每个表一般是只有一个region,当region的某个列族达到一个阈值(默认256M)时就会分成两个新的region;
5.4 Region被分配给哪个Region Server是完全动态透明的。
Store的作用
6.1 每一个region由一个或多个store组成,至少是一个store;
6.2 hbase会把一起访问的数据放在一个store里面,即为每个 ColumnFamily建一个store,
如果有几个ColumnFamily,也就有几个Store;
6.3 一个Store由一个memStore和0或者多个StoreFile组成,HBase以store的大小来判断是否需要切分region。
MemStore的作用
7.1 memStore 是放在内存里的,其保存修改的数据即keyValues;
7.2 当memStore的大小达到一个阀值(默认128MB)时,memStore会被flush到文件,即生成一个快照。
StoreFile的作用
8.1 memStore内存中的数据写到文件后就是StoreFile;
8.2 StoreFile底层是以HFile的格式保存,即数据保存在hdfs上。
HLog的作用
9.1 HLog(WAL log):WAL意为write ahead log,用来做灾难恢复使用,HLog记录数据的所有变更,一旦region server 宕机,就可以从log中进行恢复;
9.2 HLog文件就是一个普通的Hadoop Sequence File,Sequence File的value是key时HLogKey对象,其中记录了写入数据的归属信息,除了table和region名字外,还同时包括sequence number和timestamp
- timestamp是写入时间,sequence number的起始值为0,或者是最近一次存入文件系统中的sequence number。
- Sequence File的value是HBase的KeyValue对象,即对应HFile中的KeyValue。
| tar -xvzf hbase-2.1.0.tar.gz -C ../server/ |
-
-
-
- 修改HBase配置文件
- hbase-env.sh
- 修改HBase配置文件
-
-
| cd /export/server/hbase-2.1.0/conf vim hbase-env.sh # 第28行 export JAVA_HOME=/export/server/jdk1.8.0_241/ export HBASE_MANAGES_ZK=false |
-
-
-
-
- hbase-site.xml
-
-
-
| vim hbase-site.xml ------------------------------ <configuration> <!-- HBase数据在HDFS中的存放的路径 --> <property> <name>hbase.rootdir</name> <value>hdfs://node1.itcast.cn:8020/hbase</value> </property> <!-- Hbase的运行模式。false是单机模式,true是分布式模式。若为false,Hbase和Zookeeper会运行在同一个JVM里面 --> <property> <name>hbase.cluster.distributed</name> <value>true</value> </property> <!-- ZooKeeper的地址 --> <property> <name>hbase.zookeeper.quorum</name> <value>node1.itcast.cn,node2.itcast.cn,node3.itcast.cn</value> </property> <!-- ZooKeeper快照的存储位置 --> <property> <name>hbase.zookeeper.property.dataDir</name> <value>/export/server/apache-zookeeper-3.6.0-bin/data</value> </property> <!-- V2.1版本,在分布式情况下, 设置为false --> <property> <name>hbase.unsafe.stream.capability.enforce</name> <value>false</value> </property> </configuration> |
-
-
-
-
- 修改regionserver文件
-
-
-
| vim regionserver node1.itcast.cn node2.itcast.cn node3.itcast.cn |
-
-
-
- 配置环境变量
-
-
| # 配置Hbase环境变量 vim /etc/profile export HBASE_HOME=/export/server/hbase-2.1.0 export PATH=$PATH:${HBASE_HOME}/bin:${HBASE_HOME}/sbin #加载环境变量 source /etc/profile |
-
-
-
- 复制jar包到lib
-
-
| cp $HBASE_HOME/lib/client-facing-thirdparty/htrace-core-3.1.0-incubating.jar $HBASE_HOME/lib/ |
-
-
-
- 分发安装包与配置文件
-
-
| cd /export/server scp -r hbase-2.1.0/ node2.itcast.cn:$PWD scp -r hbase-2.1.0/ node3.itcast.cn:$PWD 在node2.itcast.cn和node3.itcast.cn配置加载环境变量 source /etc/profile |
-
-
-
- 启动HBase
-
-
| cd /export/server # 启动ZK ./start-zk.sh # 启动hadoop start-dfs.sh # 启动hbase start-hbase.sh |
-
-
-
- 验证Hbase是否启动成功
-
-
| # 启动hbase shell客户端 hbase shell # 输入status [root@node1 onekey]# hbase shell SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/export/server/hadoop-2.7.5/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/export/server/hbase-2.1.0/lib/client-facing-thirdparty/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory] HBase Shell Use "help" to get list of supported commands. Use "exit" to quit this interactive shell. Version 2.1.0, re1673bb0bbfea21d6e5dba73e013b09b8b49b89b, Tue Jul 10 17:26:48 CST 2018 Took 0.0034 seconds Ignoring executable-hooks-1.6.0 because its extensions are not built. Try: gem pristine executable-hooks --version 1.6.0 Ignoring gem-wrappers-1.4.0 because its extensions are not built. Try: gem pristine gem-wrappers --version 1.4.0 2.4.1 :001 > status 1 active master, 0 backup masters, 3 server, 0 dead, 0.6667 average load Took 0.4562 seconds 2.4.1 :002 > |
http://node1.itcast.cn:16010/master-status
| 目录名 | 说明 |
| bin | 所有hbase相关的命令都在该目录存放 |
| conf | 所有的hbase配置文件 |
| hbase-webapps | hbase的web ui程序位置 |
| lib | hbase依赖的java库 |
| logs | hbase的日志文件 |
-
- 安装Phoenix
- 下载
- 安装Phoenix
大家可以从官网上下载与HBase版本对应的Phoenix版本。对应到HBase 2.1,应该使用版本「5.0.0-HBase-2.0」。
Phoenix Downloads | Apache Phoenix
也可以使用资料包中的安装包。
-
-
- 安装
-
- 上传安装包到Linux系统,并解压
| cd /export/software tar -xvzf apache-phoenix-5.0.0-HBase-2.0-bin.tar.gz -C ../server/ |
- 修改三台Linux文件句柄数
| vim /etc/security/limits.conf #在文件的末尾添加以下内容,*号不能去掉 * soft nofile 65536 * hard nofile 131072 * soft nproc 2048 * hard nproc 4096 |
- 将phoenix的所有jar包添加到所有HBase RegionServer和Master的复制到HBase的lib目录
| # 拷贝jar包到hbase lib目录 cp /export/server/apache-phoenix-5.0.0-HBase-2.0-bin/phoenix-*.jar /export/server/hbase-2.1.0/lib/ # 进入到hbase lib 目录 cd /export/server/hbase-2.1.0/lib/ # 分发jar包到每个HBase 节点 scp phoenix-*.jar node2.itcast.cn:$PWD scp phoenix-*.jar node3.itcast.cn:$PWD |
- 修改配置文件
| cd /export/server/hbase-2.1.0/conf/ vim hbase-site.xml ------ # 1. 将以下配置添加到 hbase-site.xml 后边 <!-- 关闭流检查,从2.x开始使用async --> <property> <name>hbase.unsafe.stream.capability.enforce</name> <value>false</value> </property> <!-- 支持HBase命名空间映射 --> <property> <name>phoenix.schema.isNamespaceMappingEnabled</name> <value>true</value> </property> <!-- 支持索引预写日志编码 --> <property> <name>hbase.regionserver.wal.codec</name> <value>org.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec</value> </property> # 2. 将hbase-site.xml分发到每个节点 scp hbase-site.xml node2.itcast.cn:$PWD scp hbase-site.xml node3.itcast.cn:$PWD |
- 将配置后的hbase-site.xml拷贝到phoenix的bin目录
| cp /export/server/hbase-2.1.0/conf/hbase-site.xml /export/server/apache-phoenix-5.0.0-HBase-2.0-bin/bin/ |
- 重新启动HBase
| stop-hbase.sh start-hbase.sh |
注意:如果linux是python3需要按照如下操作改为centos自带的python2的解析器
- 启动Phoenix客户端,连接Phoenix Server
注意:第一次启动Phoenix连接HBase会稍微慢一点。
| cd /export/server/apache-phoenix-5.0.0-HBase-2.0-bin/ bin/sqlline.py node1.itcast.cn:2181 # 输入!table查看Phoenix中的表 !table |
- 查看HBase的Web UI,可以看到Phoenix在system命名空间下创建了一些表,而且该系统表加载了大量的协处理器。
Flink支持多种安装模式。
- local(本地)——本地模式
- standalone——独立模式,Flink自带集群,开发测试环境使用
- standaloneHA—独立集群高可用模式,Flink自带集群,开发测试环境使用
- yarn——计算资源统一由Hadoop YARN管理,生产环境测试
-
-
- [了解] - Standalone - 伪分布环境(开发测试)
-
和Local模式不同的是,Standalone模式中Flink的各个角色都是独立的进程。
-
-
-
- 架构图
-
-
- Flink程序需要提交给JobClient
- JobClient将作业提交给JobManager
- JobManager负责协调资源分配和作业执行。 资源分配完成后,任务将提交给相应的TaskManager
- TaskManager启动一个线程以开始执行。TaskManager会向JobManager报告状态更改。例如开始执行,正在进行或已完成。
- 作业执行完成后,结果将发送回客户端(JobClient)
-
-
- 环境准备
-
-
- jdk1.8及以上【配置JAVA_HOME环境变量】
- ssh免密码登录【集群内节点之间免密登录】
-
-
- 下载安装包
-
-
https://archive.apache.org/dist/flink/flink-1.14.0/flink-1.14.0-bin-scala_2.12.tgz
-
-
-
- 服务器规划
-
-
- 服务器: node1(Master + Slave)
-
-
- 安装步骤
-
-
| 操作步骤 | 说明 |
| 1 | 上传Flink压缩包到指定目录 |
| 2 | 解压缩flink到 /export/server 目录 |
| tar -zxvf flink-1.14.0-bin-scala_2.12.tgz -C /export/server/ | |
| 3 | 改名或创建软链接:方便后期升级 |
| ln -s /export/server/flink-1.14.0 /export/server/flink | |
| 4 | 启动Flink |
| bin/start-cluster.sh | |
| 5 | 通过jps查看进程信息 |
| 6 | 访问web界面 |
| http://node1:8081 | |
| slot在flink里面可以认为是资源组,Flink是通过将任务分成子任务并且将这些子任务分 配到slot来并行执行程序 | |
| 7 | 运行测试任务 |
| bin/flink run /export/server/flink/examples/batch/WordCount.jar | |
| 8 | 观察WebUI |
| 9 | 日志的查看 |
| JobManager 和 TaskManager 的启动日志可以在 Flink binary 目录下的 log 子目录中找到 | |
| log 目录中以“flink-${user}-standalonesession-${id}-${hostname}”为前缀的文件对应的即是 JobManager 的输出,其中有三个文件: | |
| flink-${user}-standalonesession-${id}-${hostname}.log:代码中的日志输出 flink-${user}-standalonesession-${id}-${hostname}.out:进程执行时的 stdout 输出 flink-${user}-standalonesession-${id}-${hostname}-gc.log:JVM 的 GC 的日志 | |
| log 目录中以“flink-${user}-taskexecutor-${id}-${hostname}”为前缀的文件对应的是 TaskManager 的输出,也包括三个文件,和 JobManager 的输出一致。 | |
| 10 | 日志的配置文件在 Flink binary 目录的 conf 子目录下: |
| log4j-cli.properties:用 Flink 命令行时用的 log 配置,比如执行“flink run”命令 log4j-yarn-session.properties:是用 yarn-session.sh 启动时命令行执行时用的 log 配置 log4j.properties:无论是 standalone 还是 yarn 模式,JobManager 和 TaskManager 上用 的 log 配置都是 log4j.properties | |
| 这三个“log4j.*properties”文件分别有三个“logback.*xml”文件与之对应,如果想使用 logback 的同学,之需要把与之对应的“log4j.*properties”文件删掉即可,对应关系如下: | |
| log4j-cli.properties -> logback-console.xml log4j-yarn-session.properties -> logback-yarn.xml log4j.properties -> logback.xml | |
| 需要注意的是,“flink-${user}-standalonesession-${id}-${hostname}”和“flink-${user}- taskexecutor-${id}-${hostname}”都带有“${id}”,“${id}”表示本进程在本机上该角色(JobManager 或 TaskManager)的所有进程中的启动顺序,默认从 0 开始。 |
-
-
- [了解] - Standalone – 完全分布式集群环境(开发测试)
- 架构图
- [了解] - Standalone – 完全分布式集群环境(开发测试)
-
- client客户端提交任务给JobManager
- JobManager负责Flink集群计算资源管理,并分发任务给TaskManager执行
- TaskManager定期向JobManager汇报状态
- flink的TM就是运行在不同节点上的JVM进程(process),这个进程会拥有一定量的资源。比如内存,cpu,网络,磁盘等。flink将进程的内存进行了划分到多个slot中.图中有2个TaskManager,每个TM有2个slot的,每个slot占有1/2的内存。
-
-
- 集群规划
-
-
- 服务器: node1(Master + Slave)
- 服务器: node2(Slave)
- 服务器: node3(Slave)
-
-
- 安装步骤
-
-
| 操作步骤 | 说明 |
| 1 | 修改安装目录下conf文件夹内的flink-conf.yaml配置文件,指定JobManager |
| # jobManager 的IP地址 jobmanager.rpc.address: node1 # JobManager 的端口号 jobmanager.rpc.port: 6123 # JobManager JVM heap 内存大小 jobmanager.memory.process.size: 1600m # TaskManager JVM heap 内存大小 taskmanager.memory.process.size: 1728m # 每个 TaskManager 提供的任务 slots 数量大小 taskmanager.numberOfTaskSlots: 2 #是否进行预分配内存,默认不进行预分配,这样在我们不使用flink集群时候不会占用集群资源 taskmanager.memory.preallocate: false # 程序默认并行计算的个数 parallelism.default: 1 #JobManager的Web界面的端口(默认:8081) jobmanager.web.port: 8081 | |
| slot和parallelism总结 | |
| taskmanager.numberOfTaskSlots:2 每一个taskmanager中的分配2个TaskSlot,3个taskmanager一共有6个TaskSlot parallelism.default:1 运行程序默认的并行度为1,6个TaskSlot只用了1个,有5个空闲 slot是静态的概念,是指taskmanager具有的最大并发执行能力 parallelism是动态的概念,是指程序运行时实际使用的并发能力 | |
| 2 | 修改安装目录下conf文件夹内的workers配置文件,指定TaskManager |
| node1 node2 node3 | |
| 3 | 使用vi修改 /etc/profile 系统环境变量配置文件,添加HADOOP_CONF_DIR目录 |
| export HADOOP_CONF_DIR=/export/server/hadoop-3.3.0/etc/hadoop | |
| 4 | 分发/etc/profile到其他两个节点 |
| scp -r /etc/profile node2:/etc scp -r /etc/profile node3:/etc | |
| 5 | 每个节点重新加载环境变量 |
| source /etc/profile | |
| 6 | 将配置好的Flink目录分发给其他的两台节点 |
| for i in {2..3}; do scp -r /export/server/flink-1.14.0/ node$i:$PWD; done | |
| 7 | 启动Flink集群 |
| bin/start-cluster.sh | |
| 8 | 通过jps查看进程信息 |
| --------------------- node1 ---------------- 86583 Jps 85963 StandaloneSessionClusterEntrypoint 86446 TaskManagerRunner --------------------- node2 ---------------- 44099 Jps 43819 TaskManagerRunner --------------------- node3 ---------------- 29461 TaskManagerRunner 29678 Jps | |
| 9 | 启动HDFS集群 |
| 10 | 在HDFS中创建/test/input目录 |
| hadoop fs -mkdir -p /test/input | |
| 11 | 上传wordcount.txt文件到HDFS /test/input目录 |
| hadoop fs -put /root/wordcount.txt /test/input | |
| 12 | 并运行测试任务 |
| bin/flink run /export/server/flink/examples/batch/WordCount.jar --input hdfs://node1:8020/test/input/wordcount.txt | |
| 注意: flink与hadoop整合的时候需要上传整合的jar包:\4.资料\1.软件\flink-shaded-hadoop-3-uber-3.1.1.7.2.9.0-173-9.0.jar,到flink安装目录的lib目录下 | |
| 将jar包同时上传到node1、node2、node3节点,因为作业是递交到TaskManager节点去执行的,因此每个节点都要上传,上传后重启flink集群 | |
| 13 | 浏览Flink Web UI界面 |
| http://node1:8081 | |
-
-
-
- 启动/停止flink集群
-
-
- 启动:./bin/start-cluster.sh
- 停止:./bin/stop-cluster.sh
-
-
- Flink集群的重启或扩容
-
-
- 启动/停止jobmanager
- 启动:./bin/start-cluster.sh
- 停止:./bin/stop-cluster.sh
- 如果集群中的jobmanager进程挂了,执行下面命令启动
- bin/jobmanager.sh start
- bin/jobmanager.sh stop
- 添加新的taskmanager节点或者重启taskmanager节点
- bin/taskmanager.sh start
- bin/taskmanager.sh stop
- [了解] - Standalone – 完全分布式之高可用HA模式(生产可用)
从上述架构图中,可发现JobManager存在单点故障,一旦JobManager出现意外,整个集群无法工作。所以,为了确保集群的高可用,需要搭建Flink的HA。(如果是部署在YARN上,部署YARN的HA),我们这里演示如何搭建Standalone 模式HA。
-
-
-
- HA架构图
-
-
-
-
-
- 集群规划
-
-
- 服务器: node1(Master + Slave)
- 服务器: node2(Master + Slave)
- 服务器: node3(Slave)
-
-
- 前置条件
-
-
需要将hadoop组件上传到Flink安装包的lib目录下,因为Flink1.8开始,安装包不再基于flink版本进行划分,因此需要手动下载hadoop组件,同时需要注意Hadoop版本号需要与开发环境版本保持一致,以生产环境使用Hadoop3.3.0为例,需要下载flink-shaded-hadoop-3-uber、commons-cli包
| 操作步骤 | 说明 |
| 1 | 下载hadoop的组件Jar包 |
| 2 | 将下载的jar文件拷贝到flink安装目录lib目录下(每个节点都需要拷贝) |
| 3 | 拷贝完成jar到每个节点以后需要重启flink集群 |
-
-
-
- 安装步骤
-
-
| 操作步骤 | 说明 |
| 1 | 在flink-conf.yaml中添加zookeeper配置 |
| #开启HA,使用文件系统作为快照存储 state.backend: filesystem #默认为none,用于指定checkpoint的data files和meta data存储的目录 state.checkpoints.dir: hdfs://node1:8020/flink-checkpoints #默认为none,用于指定savepoints的默认目录 state.savepoints.dir: hdfs://node1:8020/flink-checkpoints #使用zookeeper搭建高可用 high-availability: zookeeper # 存储JobManager的元数据到HDFS,用来恢复JobManager 所需的所有元数据 high-availability.storageDir: hdfs://node1:8020/flink/ha/ high-availability.zookeeper.quorum: node1:2181,node2:2181,node3:2181 # blob存储文件是在群集中分发Flink作业所必需的 blob.storage.directory: /export/server/flink/tmp | |
| 2 | 将配置过的HA的 flink-conf.yaml 分发到另外两个节点 |
| for i in {2..3}; do scp -r /export/server/flink/conf/flink-conf.yaml node$i:$PWD; done | |
| 3 | 到节点2中修改flink-conf.yaml中的配置,将JobManager设置为自己节点的名称 |
| jobmanager.rpc.address: node2 | |
| 4 | 在 masters 配置文件中添加多个节点 |
| node1:8081 node2:8081 | |
| 5 | 分发masters配置文件到另外两个节点 |
| scp /export/server/flink/conf/masters node3:/export/server/flink/conf/ scp /export/server/flink/conf/masters node2:/export/server/flink/conf/ | |
| 6 | 启动 zookeeper 集群 |
| [root@node1 server]# zkServer.sh start [root@node2 server]# zkServer.sh start [root@node3 server]# zkServer.sh start | |
| 7 | 启动 HDFS 集群 |
| 8 | 启动 flink 集群 |
| [root@node1 flink]# bin/start-cluster.sh Starting HA cluster with 2 masters. Starting standalonesession daemon on host node1. Starting standalonesession daemon on host node2. Starting taskexecutor daemon on host node1. Starting taskexecutor daemon on host node2. Starting taskexecutor daemon on host node3. | |
| 9 | 分别查看两个节点的Flink Web UI |
| 10 | kill掉一个节点,查看另外的一个节点的Web UI |
注意事项
切记搭建HA,需要将第二个节点的 jobmanager.rpc.address 修改为node2
-
-
- [理解] - yarn集群环境(生产推荐)
-
Local模式:通过一个JVM进程中,通过线程模拟出各个Flink角色来得到Flink环境
Standalone模式:各个角色是独立的进程存在
YARN模式:Flink的各个角色,均运行在多个YARN的容器内,其整体上是一个YARN的任务
flink on yarn的前提是:hdfs、yarn均启动
在企业实际开发中,使用Flink时,更多的使用方式是Flink On Yarn模式,原因如下:
- Yarn的资源可以按需使用,提高集群的资源利用率
- Yarn的任务有优先级,根据优先级运行作业
- 基于Yarn调度系统,能够自动化地处理各个角色的 Failover(容错)
- JobManager 进程和 TaskManager 进程都由 Yarn NodeManager 监控
- 如果 JobManager 进程异常退出,则 Yarn ResourceManager 会重新调度 JobManager 到其他机器
- 如果 TaskManager 进程异常退出,JobManager 会收到消息并重新向 Yarn ResourceManager 申请资源,重新启动 TaskManager
-
-
-
- 准备工作
-
-
- jdk1.8及以上【配置JAVA_HOME环境变量】
- ssh免密码登录【集群内节点之间免密登录】
- 至少hadoop2.2
- hdfs & yarn均启动
-
-
- 集群规划
-
-
- 服务器: node1(ResourceManager+ NodeManager)
- 服务器: node2(NodeManager)
- 服务器: node3(NodeManager)
-
-
- 修改hadoop的配置参数
-
-
| 操作步骤 | 说明 |
| 1 | 打开yarn配置页面(每台hadoop节点都需要修改) |
| vim etc/hadoop/yarn-site.xml | |
| 添加 | |
| <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property> | |
| 是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是true。 在这里面我们需要关闭,因为对于flink使用yarn模式下,很容易内存超标,这个时候yarn会自动杀掉job | |
| 2 | 分发yarn-site.xml到其它服务器节点 |
| scp yarn-site.xml node2:$PWD scp yarn-site.xml node3:$PWD | |
| 3 | 启动HDFS、YARN集群 |
| start-all.sh |
-
-
-
- Flink on Yarn的运行机制
-
-
从图中可以看出,Yarn的客户端需要获取hadoop的配置信息,连接Yarn的ResourceManager。所以要有设置有 YARN_CONF_DIR或者HADOOP_CONF_DIR或者HADOOP_CONF_PATH,只要设置了其中一个环境变量,就会被读取。如果读取上述的变量失败了,那么将会选择hadoop_home的环境变量,都区成功将会尝试加载$HADOOP_HOME/etc/hadoop的配置文件。
- 当启动一个Flink Yarn会话时,客户端首先会检查本次请求的资源是否足够。资源足够将会上传包含HDFS配置信息和Flink的jar包到HDFS。
- 随后客户端会向Yarn发起请求,启动applicationMaster,随后NodeManager将会加载有配置信息和jar包,一旦完成,ApplicationMaster(AM)便启动。
- 当JobManager and AM 成功启动时,他们都属于同一个container,从而AM就能检索到JobManager的地址。此时会生成新的Flink配置信息以便TaskManagers能够连接到JobManager。同时,AM也提供Flink的WEB接口。用户可并行执行多个Flink会话。
- 随后,AM将会开始为分发从HDFS中下载的jar以及配置文件的container给TaskMangers.完成后Fink就完全启动并等待接收提交的job.
-
-
-
- Flink on Yarn的三种部署方式介绍
- Session模式
- Flink on Yarn的三种部署方式介绍
-
-
这种模式会预先在yarn或者或者k8s上启动一个flink集群,然后将任务提交到这个集群上,这种模式,集群中的任务使用相同的资源,如果某一个任务出现了问题导致整个集群挂掉,那就得重启集群中的所有任务,这样就会给集群造成很大的负面影响。
特点:需要事先申请资源,使用Flink中的yarn-session(yarn客户端),启动JobManager和TaskManger
优点:不需要每次递交作业申请资源,而是使用已经申请好的资源,从而提高执行效率
缺点:作业执行完成以后,资源不会被释放,因此一直会占用系统资源
应用场景:适合作业递交比较频繁的场景,小作业比较多的场景
-
-
-
-
- Per-Job模式
-
-
-
考虑到集群的资源隔离情况,一般生产上的任务都会选择per job模式,也就是每个任务启动一个flink集群,各个集群之间独立运行,互不影响,且每个集群可以设置独立的配置。
特点:每次递交作业都需要申请一次资源
优点:作业运行完成,资源会立刻被释放,不会一直占用系统资源
缺点:每次递交作业都需要申请资源,会影响执行效率,因为申请资源需要消耗时间
应用场景:适合作业比较少的场景、大作业的场景
-
-
-
-
- application模式
- 背景
- application模式
-
-
-
flink-1.11 引入了一种新的部署模式,即 Application 模式。目前,flink-1.11 已经可以支持基于 Yarn 和 Kubernetes 的 Application 模式。
-
-
-
-
-
- 优势
-
-
-
-
Session模式:所有作业共享集群资源,隔离性差,JM 负载瓶颈,main 方法在客户端执行。
Per-Job模式:每个作业单独启动集群,隔离性好,JM 负载均衡,main 方法在客户端执行。
通过以上两种模式的特点描述,可以看出,main方法都是在客户端执行,社区考虑到在客户端执行 main() 方法来获取 flink 运行时所需的依赖项,并生成 JobGraph,提交到集群的操作都会在实时平台所在的机器上执行,那么将会给服务器造成很大的压力。尤其在大量用户共享客户端时,问题更加突出。
此外这种模式提交任务的时候会把本地flink的所有jar包先上传到hdfs上相应的临时目录,这个也会带来大量的网络的开销,所以如果任务特别多的情况下,平台的吞吐量将会直线下降。
因此,社区提出新的部署方式 Application 模式解决该问题。
-
-
-
-
-
- 原理
-
-
-
-
Application 模式下,用户程序的 main 方法将在集群中而不是客户端运行,用户将程序逻辑和依赖打包进一个可执行的 jar 包里,集群的入口程序 (ApplicationClusterEntryPoint) 负责调用其中的 main 方法来生成 JobGraph。Application 模式为每个提交的应用程序创建一个集群,该集群可以看作是在特定应用程序的作业之间共享的会话集群,并在应用程序完成时终止。在这种体系结构中,Application 模式在不同应用之间提供了资源隔离和负载平衡保证。在特定一个应用程序上,JobManager 执行 main() 可以节省所需的 CPU 周期,还可以节省本地下载依赖项所需的带宽。
-
-
-
- Flink on Yarn的三种部署方式使用说明
- 第一种方式:YARN session
- Flink on Yarn的三种部署方式使用说明
-
-
| 操作步骤 | 说明 |
| 1 | yarn-session.sh(开辟资源)+flink run(提交任务) |
| 这种模式下会启动yarn session,并且会启动Flink的两个必要服务:JobManager和Task-managers,然后你可以向集群提交作业。同一个Session中可以提交多个Flink作业。需要注意的是,这种模式下Hadoop的版本至少是2.2,而且必须安装了HDFS(因为启动YARN session的时候会向HDFS上提交相关的jar文件和配置文件) 通过./bin/yarn-session.sh脚本启动YARN Session 脚本可以携带的参数: | |
| -n(--container):TaskManager的数量。(1.10 已经废弃) -s(--slots): 每个TaskManager的slot数量,默认一个slot一个core,默认每个taskmanager的slot的个数为1,有时可以多一些taskmanager,做冗余。 -jm:JobManager的内存(单位MB)。 -q:显示可用的YARN资源(内存,内核); -tm:每个TaskManager容器的内存(默认值:MB) -nm:yarn 的appName(现在yarn的ui上的名字)。 -d:后台执行。 | |
| 注意: 如果不想让Flink YARN客户端始终运行,那么也可以启动分离的 YARN会话。该参数被称为-d或--detached。 | |
| 确定TaskManager数: Flink on YARN时,TaskManager的数量就是:max(parallelism) / yarnslots(向上取整)。例如,一个最大并行度为10,每个TaskManager有两个任务槽的作业,就会启动5个TaskManager。 | |
| 2 | 启动: |
| bin/yarn-session.sh -tm 1024 -s 4 -d | |
| 上面的命令的意思是,每个 TaskManager 拥有4个 Task Slot(-s 4),并且被创建的每个 TaskManager 所在的YARN Container 申请 1024M 的内存,同时额外申请一个Container用以运行ApplicationMaster以及Job Manager。 TM的数量取决于并行度,如下图: 执行:bin/flink run -p 8 examples/batch/WordCount.jar | |
| 3 | 启动成功之后,控制台显示: |
| 4 | 去yarn页面:ip:8088可以查看当前提交的flink session |
| 5 | 然后使用flink提交任务 |
| bin/flink run examples/batch/WordCount.jar | |
| 在控制台中可以看到wordCount.jar计算出来的任务结果 | |
| 6 | 在yarn-session.sh提交后的任务页面中也可以观察到当前提交的任务: |
| 7 | 点击查看任务细节: |
| 8 | 停止当前任务: |
| yarn application -kill application_1527077715040_0007 |
-
-
-
-
- 第二种方式:在YARN上运行一个Flink作业
-
-
-
上面的YARN session是在Hadoop YARN环境下启动一个Flink cluster集群,里面的资源是可以共享给其他的Flink作业。我们还可以在YARN上启动一个Flink作业,这里我们还是使用./bin/flink,但是不需要事先启动YARN session:
- 使用flink直接提交任务
| bin/flink run -m yarn-cluster ./examples/batch/WordCount.jar 常用参数:
下面的参数仅可用于 -m yarn-cluster 模式
|
| 在8088页面观察: |
- 停止yarn-cluster
| yarn application -kill application的ID |
| 注意: |
| 在创建集群的时候,集群的配置参数就写好了,但是往往因为业务需要,要更改一些配置参数,这个时候可以不必因为一个实例的提交而修改conf/flink-conf.yaml; 可以通过:-yD <arg> Dynamic properties 来覆盖原有的配置信息:比如: bin/flink run -m yarn-cluster -yD fs.overwrite-files=true examples/batch/WordCount.jar -yD fs.overwrite-files=true -yD taskmanager.network.numberOfBuffers=16368 |
-
-
-
-
- 第三种方式:Application Mode
-
-
-
application 模式使用 bin/flink run-application 提交作业;通过 -t 指定部署环境,目前 application 模式支持部署在 yarn 上(-t yarn-application) 和 k8s 上(-t kubernetes-application);并支持通过 -D 参数指定通用的 运行配置,比如 jobmanager/taskmanager 内存、checkpoint 时间间隔等。
通过 bin/flink run-application -h 可以看到 -D/-t 的详细说明:(-e 已经被废弃,可以忽略)
| bin/flink run-application -h 参数: Options for Generic CLI mode: -D <property=value> Generic configuration options for execution/deployment and for the configured executor.The available options can be found at https://ci.apache.org/projects/flink/flink-docs-stable/ops/config.html -e,--executor <arg> DEPRECATED: Please use the -t option instead which is also available with the "Application Mode". The name of the executor to be used for executing the given job, which is equivalent to the "execution.target" config option. The currently available executors are: "collection", "remote", "local", "kubernetes-session", "yarn-per-job", "yarn-session". -t,--target <arg> The deployment target for the given application, which is equivalent to the "execution.target" config option. The currently available targets are: "collection", "remote", "local", "kubernetes-session", "yarn-per-job", "yarn-session", "yarn-application" and "kubernetes-application". |
- 下面列举几个使用 Application 模式提交作业到 yarn 上运行的命令:
| 第一种方式 | 带有 JM 和 TM 内存设置的命令提交: |
| ./bin/flink run-application -t yarn-application \ -Djobmanager.memory.process.size=1024m \ -Dtaskmanager.memory.process.size=1024m \ -Dyarn.application.name="MyFlinkWordCount" \ ./examples/batch/WordCount.jar --output hdfs://node01:8020/wordcount/output_51 | |
| 第二种方式 | 在上面例子 的基础上自己设置 TaskManager slots 个数为3,以及指定并发数为3: |
| ./bin/flink run-application -t yarn-application -p 3 \ -Djobmanager.memory.process.size=1024m \ -Dtaskmanager.memory.process.size=1024m \ -Dyarn.application.name="MyFlinkWordCount" \ -Dtaskmanager.numberOfTaskSlots=3 \ ./examples/batch/WordCount.jar --output hdfs://node01:8020/wordcount/output_52 | |
| 当然,指定并发还可以使用 -Dparallelism.default=3,而且社区目前倾向使用 -D+通用配置代替客户端命令参数(比如 -p)。所以这样写更符合规范: | |
| ./bin/flink run-application -t yarn-application \ -Dparallelism.default=3 \ -Djobmanager.memory.process.size=1024m \ -Dtaskmanager.memory.process.size=1024m \ -Dyarn.application.name="MyFlinkWordCount" \ -Dtaskmanager.numberOfTaskSlots=3 \ ./examples/batch/WordCount.jar --output hdfs://node01:8020/wordcount/output_53 | |
| 第三种方式 | 和 yarn.provided.lib.dirs 参数一起使用,可以充分发挥 application 部署模式的优势:我们看 官方配置文档 对这个配置的解释: |
| yarn.provided.lib.dirs: A semicolon-separated list of provided lib directories. They should be pre-uploaded and world-readable. Flink will use them to exclude the local Flink jars(e.g. flink-dist, lib/, plugins/)uploading to accelerate the job submission process. Also YARN will cache them on the nodes so that they doesn't need to be downloaded every time for each application. An example could be hdfs://$namenode_address/path/of/flink/lib | |
| 意思是我们可以预先上传 flink 客户端依赖包 (flink-dist/lib/plugin) 到远端存储(一般是 hdfs,或者共享存储),然后通过 yarn.provided.lib.dirs 参数指定这个路径,flink 检测到这个配置时,就会从该地址拉取 flink 运行需要的依赖包,省去了依赖包上传的过程,yarn-cluster/per-job 模式也支持该配置。在之前的版本中,使用 yarn-cluster/per-job 模式,每个作业都会单独上传 flink 依赖包(一般会有 180MB左右)导致 hdfs 资源浪费,而且程序异常退出时,上传的 flink 依赖包往往得不到自动清理。通过指定 yarn.provided.lib.dirs,所有作业都会使用一份远端 flink 依赖包,并且每个 yarn nodemanager 都会缓存一份,提交速度也会大大提升,对于跨机房提交作业会有很大的优化。 | |
| 上传 Flink 相关 plugins 到hdfs | |
| cd /export/servers/flink-1.13.1/plugins hdfs dfs -mkdir /flink/plugins hdfs dfs -put \ external-resource-gpu/flink-external-resource-gpu-1.13.1.jar \ metrics-datadog/flink-metrics-datadog-1.13.1.jar \ metrics-graphite/flink-metrics-graphite-1.13.1.jar \ metrics-influx/flink-metrics-influxdb-1.13.1.jar \ metrics-jmx/flink-metrics-jmx-1.13.1.jar \ metrics-prometheus/flink-metrics-prometheus-1.13.1.jar \ metrics-slf4j/flink-metrics-slf4j-1.13.1.jar \ metrics-statsd/flink-metrics-statsd-1.13.1.jar \ /flink/plugins | |
| 根据自己业务需求上传相关的 jar | |
| cd /export/servers/flink-1.13.1/libs hdfs dfs -mkdir /flink/libs | |
| hdfs dfs -put flink-csv-1.13.1.jar \ flink-dist_2.11-1.13.1.jar \ flink-json-1.13.1.jar \ flink-shaded-hadoop-2-uber-2.7.5-10.0.jar \ flink-shaded-zookeeper-3.4.14.jar \ flink-table_2.11-1.13.1.jar \ flink-table-blink_2.11-1.13.1.jar \ log4j-1.2-api-2.12.1.jar log4j-api-2.12.1.jar \ log4j-core-2.12.1.jar \ log4j-slf4j-impl-2.12.1.jar \ /flink/libs | |
| 上传用户 jar 到 hdfs | |
| cd /export/servers/flink-1.13.1 hdfs dfs -mkdir /flink/user-libs hdfs dfs -put ./examples/batch/WordCount.jar /flink/user-libs | |
| 提交任务 | |
| bin/flink run-application -t yarn-application \ -Djobmanager.memory.process.size=1024m \ -Dtaskmanager.memory.process.size=1024m \ -Dtaskmanager.numberOfTaskSlots=2 \ -Dparallelism.default=2 \ -Dyarn.provided.lib.dirs="hdfs://node01:8020/flink/libs;hdfs://node01:8020/flink/plugins" \ -Dyarn.application.name="batchWordCount" \ hdfs://node01:8020/flink/user-libs/WordCount.jar --output hdfs://node01:8020/wordcount/output_54 | |
| 也可以将 yarn.provided.lib.dirs 配置到 conf/flink-conf.yaml,这时提交作业就和普通作业没有区别了: | |
| ./bin/flink run-application -t yarn-application \ -Djobmanager.memory.process.size=1024m \ -Dtaskmanager.memory.process.size=1024m \ -Dyarn.application.name="MyFlinkWordCount" \ -Dtaskmanager.numberOfTaskSlots=3 \ /local/path/to/my-application.jar | |
| 注意:如果自己指定 yarn.provided.lib.dirs,有以下注意事项:
该种模式的操作使得 flink 作业提交变得很轻量,因为所需的 Flink jar 包和应用程序 jar 将到指定的远程位置获取,而不是由客户端下载再发送到集群。这也是社区在 flink-1.11 版本引入新的部署模式的意义所在。 Application 模式在停止、取消或查询正在运行的应用程序的状态等方面和 flink-1.11 之前的版本一样,可以采用现有的方法。 |
-
-
-
- 注意
-
-
如果使用的是flink on yarn方式,想切换回standalone模式的话,需要删除文件:【/tmp/.yarn-properties-root】
因为默认查找当前yarn集群中已有的yarn-session信息中的jobmanager
如果是分离模式运行的YARN JOB后,其运行完成会自动删除这个文件
但是会话模式的话,如果是kill掉任务,其不会执行自动删除这个文件的步骤,所以需要我们手动删除这个文件。

