
- 1openai接口调用-如何接入openai获取 api key_获取 openai key
- 2嵌入式软件开发工程师就业发展前景怎么样?
- 3禁用el-tabs组件自带的键盘切换功能_element-plus 禁止键盘上下左右
- 4机器视觉三维点云分析系统3DPCAgent_3d点云数据测量系统架构
- 5ggplot 图像的保存_error in usemethod("grid.draw") : no applicable me
- 6120款超浪漫❤HTML5七夕情人节表白网页源码❤ HTML+CSS+JavaScript_浪漫网页
- 7Pytorch下查看各层名字及根据layers的name冻结层进行finetune训练;_model = net().cuda() for name, param in model.name
- 8《Python从入门到实践》外星人入侵学习笔记_python外星人入侵 求助 不按play键 一直处于活动状态
- 9Dump分析模式1: Multiple Exceptions(多线程异常)_multipe exceptions
- 10PyQtChart进行柱状图、饼图的基本设置_pyqt5 炫酷饼状图
基于分布式的智联招聘数据的大屏可视化分析与预测_基于大数据的招聘数据分析可视化系统设计与实现的功能有哪些
赞
踩
1.1项目介绍
互联网成了海量信息的载体,目前是分析市场趋势、监视竞争对手或者获取销售线索的最佳场所,数据采集以及分析能力已成为驱动业务决策的关键技能。《计算机行业岗位招聘数据分析》旨在利用python编写爬虫程序,从招聘网站上爬取数据,将数据存入到Mysql数据库中,将存入的数据作一定的数据清洗后做数据分析,最后将分析的结果做数据可视化。
1.2项目要求
爬取招聘网站(智联招聘)上的计算机行业数据,字段为公司招聘链接,公司名称,公司规模,公司性质,职位领域,职位名称,学历要求,职位类别,职位亮点(福利),工资水平,城市,工作经验,简历统计,公司打分,工作地址,职位要求,人员需求,公司业务范围,进行数据清洗及数据维度分析进行数据可视化。
1.3项目意义
此项目完成之后将大大节约我们查找招聘岗位的时间,它的重大意义是让我们查看工作岗位信息数据进行了数据化、规范化、自动化、可视化管理。它可以帮助我们了解行业的薪资分布、城市岗位分布、岗位要求关键字、岗位经验要求等等一系列的数据。
1.3.1 工作计划
(1)需求文档撰写
(2)数据预处理
(3)数据分析
(4)数据可视化绘图
(5)前端可视化大屏设计与整合
(6)预测算法模型训练
(7)前端预测界面的设计与实现
(8)项目整合
(9)实训报告书撰写
1.3.2 项目团队管理
xx:负责需求文档撰写,前端可视化大屏设计与整合、实训报告书撰写、项目演示、PPT。
xx:数据分析及数据设计存储、预测模型训练及展示功能实现、负责需求文档撰写、PPT。
xx:负责数据分析、数据爬取、负责数据预处理、数据可视化绘图、实训报告书。
xx:负责数据分析、负责需求文档撰写、数据可视化绘图、实训报告书撰写。
1.4数据结构(字段解释及说明)
| 字段名称 | 字段解释 | 字段内容 |
| url | 公司招聘链接 | https://jobs.zhaopin.com/158632619261019.html |
| company_name | 公司名称 | 深圳市珍爱网信息技术有限公司 |
| company_size | 公司规模 | 1000-9999人 |
| company_type | 公司性质 | 合资 |
| job_type | 职位领域 | 销售业务,大客户销售代表 |
| job_name | 职位名称 | 大客户销售顾问(六险一金+双休) |
| edu | 学历要求 | 中专 |
| empltype | 职位类别 | 全职 |
| tag | 职位亮点(福利) | 五险一金,绩效奖金,带薪年假,补充医疗保险,员工旅游,节日福利 |
| salary | 工资水平 | 薪资面议 |
| city | 城市 | 杭州-西湖区 |
| workingexp | 工作经验 | 不限 |
| resume_count | 简历统计 | 83 |
| company_score | 公司打分 | 316.07507 |
| work_place | 工作地址 | 西湖区嘉华国际商务中心 |
| require_content | 职位要求 | 任职要求:1、23--35岁,大专及以上学历(优秀者可适当放宽);2、形象气质佳,具备丰富的社会阅历;3、热情,开朗,乐于助人,热爱婚恋工作;4、情商高,善于挖掘会员内心情感需求;5、具备销售经验,有顾问式销售经验优先;6、能承受一定的工作压力。岗位职责:1、负责高端婚恋产品的推广(电话+面销为主);2、挖掘会员需求,制定与之匹配的婚恋方案;3、联络、跟进客户,维护良好的客户关系;4、顺利完成个人业务指标;5、完成上级交给的其他任务。 |
| peopleneed | 人员需求 | 招2人 |
| companyarea | 公司业务范围 | 互联网/电子商务 |
1.5体系架构
|
招聘数据分析流程 |
|
数据源 智联招聘大数据方面的岗位 |
|
数据获取 python定义爬虫获取 |
|
数据预测 岗位地理分布预测及岗位薪资预测 |
|
数据可视化 大屏数据展示 |
|
数据存储 hdfs及MySQL分布式存储 |
|
数据分析 spark离线数据分析 |
|
数据总结 |
图1.1 项目体系架构
1.5.1系统开发环境及开发语言
系统开发环境使用: Pycharm,Idea,Hadoop,Spark
语言:Python、Scala、Mysql
数据分析与展示框架:selenium、Django、pyecharts、spark SQL
1.5.2 MySql数据库及可视化工具
MySql是一个关系型数据库管理系统,由瑞典MySQL AB公司开发,属于 Oracle 旗下产品。MySQL是最流行的关系型数据库管理系统之一,在WEB应用方面,MySQL是最好的RDBMS (Relational Database Management System,关系数据库管理系统)应用软件之一。
Navicat Premium 是一套数据库开发工具,可同时连接 MySQL、MariaDB、MongoDB、SQL Server、Oracle、PostgreSQL 和 SQLite 数据库。它与 Amazon RDS、Amazon Aurora、Amazon Redshift、Microsoft Azure、Oracle Cloud、MongoDB Atlas、阿里云、腾讯云和华为云等云数据库兼容。你可以使用Navicat快速轻松地创建、管理和维护数据库。
1.5.3 Pycharm开发工具
PyCharm是一种Python IDE,带有一整套可以帮助用户在使用Python语言开发时提高其效率的工具,比如调试、语法高亮、Project管理、代码跳转、智能提示、自动完成、单元测试、版本控制。此外,该IDE提供了一些高级功能,以用于支持Django框架下的专业Web开发。
1.5.4 cookie技术
Cookie并不是它的原意“甜饼”的意思,而是一个保存在客户机中的简单的文本文件,这个文件与特定的Web文档关联在一起,保存了该客户机访问这个Web 文档时的信息,当客户机再次访问这个Web文档时这些信息可供该文档使用。由于“Cookie”具有可以保存在客户机上的神奇特性,因此它可以帮助我们实现记录用户个人信息的功能,而这一切都不必使用复杂的CGI等程序。
举例来说, 一个 Web 站点可能会为每一个访问者产生一个唯一的ID, 然后以 Cookie 文件的形式保存在每个用户的机器上。如果使用浏览器访问 Web, 会看到所有保存在硬盘上的 Cookie。在这个文件夹里每一个文件都是一个由“名/值”对组成的文本文件,另外还有一个文件保存有所有对应的 Web 站点的信息。在这里的每个 Cookie 文件都是一个简单而又普通的文本文件。透过文件名, 就可以看到是哪个 Web 站点在机器上放置了Cookie(当然站点信息在文件里也有保存) 。
所谓“cookie”数据是指某些网站为了辨别用户身份,储存在用户本地终端上的数据(通常经过加密),由用户客户端计算机暂时或永久保存的信息。
通俗来讲就是指缓存数据,包括用户名、密码、注册账户、手机号等公民个人信息。
1.5.5 hadoop分布式系统
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。Hadoop实现了一个分布式文件系统(Distributed File System),其中一个组件是HDFS(Hadoop Distributed File System)。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算。
对外部客户机而言,HDFS就像一个传统的分级文件系统。可以创建、删除、移动或重命名文件,等等。但是HDFS的架构是基于一组特定的节点构建的(参见图1),这是由它自身的特点决定的。这些节点包括NameNode(仅一个),它在HDFS内部提供元数据服务;DataNode,它为HDFS提供存储块。由于仅存在一个NameNode,因此这是HDFS 1.x版本的一个缺点(单点失败)。在Hadoop 2.x版本可以存在两个NameNode,解决了单节点故障问题。
存储在HDFS中的文件被分成块,然后将这些块复制到多个计算机中(DataNode)。这与传统的RAID架构大不相同。块的大小(1.x版本默认为64MB,2.x版本默认为128MB)和复制的块数量在创建文件时由客户机决定。NameNode可以控制所有文件操作。HDFS内部的所有通信都基于标准的TCP/IP协议。
1.5.6 Django框架
Django是高水准的Python编程语言驱动的一个开源模型.视图,控制器风格的Web应用程序框架,它起源于开源社区。使用这种架构,程序员可以方便、快捷地创建高品质、易维护、数据库驱动的应用程序。这也正是OpenStack的Horizon组件采用这种架构进行设计的主要原因。另外,在Dj ango框架中,还包含许多功能强大的第三方插件,使得Django具有较强的可扩展性。Django项目源自一个在线新闻Web站点,于2005年以开源的形式被释放出来。Django框架的核心组件有:用于创建模型的对象关系映射;为最终用户设计较好的管理界面;URL设计;设计者友好的模板语言;缓存系统。
Django(发音:[`dʒæŋɡəʊ])是用python语言写的开源web开发框架(open source web framework),它鼓励快速开发,并遵循MVC设计。Django遵守BSD版权,初次发布于2005年7月,并于2008年9月发布了第一个正式版本1.0。
Django根据比利时的爵士音乐家Django Reinhardt命名,他是一个吉普赛人,主要以演奏吉它为主,还演奏过小提琴等。
由于Django在近年来的迅速发展,应用越来越广泛,被著名IT开发杂志SD Times评选为2013 SD Times 100,位列“API、库和框架”分类第6位,被认为是该领域的佼佼者。
1.5.7 Selenium框架
Selenium是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。支持的浏览器包括IE(7,8,9,10,11),Mozilla Firefox,Safari,GoogleChrome,Opera,Edge等。这个工具的主要功能包括:测试与浏览器的兼容性——测试应用程序看是否能够很好得工作在不同浏览器和操作系统之上。测试系统功能——创建回归测试检验软件功能和用户需求。支持自动录制动作和自动生成.Net、Java、Perl等不同语言的测试脚本。
框架底层使用JavaScript模拟真实用户对浏览器进行操作。测试脚本执行时,浏览器自动按照脚本代码做出点击,输入,打开,验证等操作,就像真实用户所做的一样,从终端用户的角度测试应用程序。使浏览器兼容性测试自动化成为可能,尽管在不同的浏览器上依然有细微的差别。
使用简单,可使用Java,Python等多种语言编写用例脚本。Selenium测试直接在浏览器中运行,就像真实用户所做的一样。Selenium测试可以在Windows、Linux和Macintosh上的Internet Explorer、Chrome和Firefox中运行。其他测试工具都不能覆盖如此多的平台。使用Selenium和在浏览器中运行测试还有很多其他好处。Selenium完全开源,对商业用户也没有任何限制,支持分布式,拥有成熟的社区与学习文档。
1.5.8 spark架构
Apache Spark是专为大规模数据处理而设计的快速通用的计算引擎。Spark是UC Berkeley AMP lab(加州大学伯克利分校的AMP实验室)所开源的类Hadoop MapReduce的通用并行框架,Spark,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是——Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
Spark是一种与Hadoop相似的开源集群计算环境,但是两者之间还存在一些不同之处,这些有用的不同之处使Spark在某些工作负载方面表现得更加优越,换句话说,Spark启用了内存分布数据集,除了能够提供交互式查询外,它还可以优化迭代工作负载。
Spark是在Scala语言中实现的,它将Scala用作其应用程序框架。与Hadoop不同,Spark和Scala能够紧密集成,其中的Scala可以像操作本地集合对象一样轻松地操作分布式数据集。
尽管创建Spark是为了支持分布式数据集上的迭代作业,但是实际上它是对Hadoop的补充,可以在Hadoop文件系统中并行运行。通过名为Mesos的第三方集群框架可以支持此行为。Spark由加州大学伯克利分校AMP实验室(Algorithms,Machines,and People Lab)开发,可用来构建大型的、低延迟的数据分析应用程序。
2.1 Pycharm
在Pycharm官网https://www.jetbrains.com/pycharm/下载最新客户端,编译环境选用anaconda3,下载地址为https://www.anaconda.com/。
2.2 mysql数据库
2.2.1下载MySql压缩包
官方链接:https://dev.mysql.com/downloads/repo/yum/,选则需要的Linux版本后点击 下载,这里选用Linux7下的rpm包,获取安装包的链接地址,然后使用wget命令从官方网站获取rpm包,命令:
wget https://dev.mysql.com/get/mysql80-community-release-el7-5.noarch.rpm
2.2.2 安装MySQL
1. 使用yum命令安装MySQL
yum localinstall mysql80-community-release-el7-5.noarch.rpm
2.安装mysql-server
yum install mysql-community-server
2.2.3 启动MySQL并配置MySQL
1. 启动Mysql命令:service mysqld start
2. 一般MySQL都有初始密码,获取MySQL初始密码的命令:grep 'temporary password' /var/log/mysqld.log
3. 输入mysql -uroot -p 初始密码 按下回车键进入MySQLshell交互界面;在交互界面可以查看数据库,数据库表,及相关安全性设置。
4. 修改密码命令
ALTER user 'root'@'localhost' IDENTIFIED WITH mysql_native_password BY '密码';写入密码:flush privileges。
5. 设置远程登录,操作代码如下:
use mysql;
update user set host='%' where user ='root';
FLUSH PRIVILEGES;
2.3 idea环境
2.3.1 在idea添加maven模块
从idea官网https://www.jetbrains.com/idea/下载idea,然后在maven官网下载maven3.6文件,解压修改conf文件夹中的settings.xml文件配置如下:
<mirror>// 镜像源配置
<id>alimaven</id>
<name>aliyun maven</name> //指定阿里云maven镜像仓库
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
<mirrorOf>central</mirrorOf>
</mirror>
<localRepository>D:\hbwe\data\repository</localRepository> // 修改maven的缓存路径
修改完maven配置文件后,在idea设置里Build,Execution、Deployment选项下的Build Tools,展开单机Maven修改页面内的Maven home path为本地maven路径,User settings file修改为本地maven目录下的conf的settings.xml。
2.3.2 Scala库依赖
在idea的设置界面,单击plugins,在Marketplace界面中搜索Scala安装。
2.4 spark环境搭建
2.4.1 从 Spark 官网下载 Spark 的安装文件
spark-2.3.0-bin-hadoop2.7.tgz
2.4.2 下载后解压下载的文件
tar zxvf spark-2.3.0-bin-hadoop2.7.tgz
2.4.3 配置环境变量如图2

图2.1 配置参数
3.1数据获取
数据为智联招聘的大数据方向及数据分析师相关的公司招聘信息。字段为公司招聘链接,公司名称,公司规模,公司性质,职位领域,职位名称,学历要求,职位类别,职位亮点(福利),工资水平,城市,工作经验,简历统计,公司打分,工作地址,职位要求,人员需求,公司业务范围。
通过python的第三方库selenium框架搭载edge diver,实现智联网址的动态获取,根据xpath语句获取到爬取信息。

图3.1 数据爬取主要代码

图3.2 数据爬取主要代码(续)
3.2数据存储
将爬取的数据通过pandas库保存为csv文件,然后通过sparksql对数据进行分析并将分析数据结果保存到MySQL数据库中。
其中MySQL数据库中各表为:
表3.1不同地区不同岗位数
| 字段名称 | 数据类型 | 长度 | 备注 |
| job_name | Varchar | 255 | 职位名称 |
| city | Varchar | 255 | 城市 |
| count | int | 12 | 数量 |
表3.2 不同地区的相同岗位的平均工资水平
| 字段名称 | 数据类型 | 长度 | 备注 |
| city | Varchar | 255 | 城市 |
| Job_type | Varchar | 255 | 职位类别 |
| Avg_salary | double | 20 | 工资 |
表3.3 职位领域对工作经验的关系
| 字段名称 | 数据类型 | 长度 | 备注 |
| job_type | Varchar | 255 | 职位领域 |
| workingexp | Varchar | 255 | 工作经验 |
| workexp | int | 12 | 计数 |
表3.4 职位领域和职位对学历要求的关系
| 字段名称 | 数据类型 | 长度 | 备注 |
| job_type | Varchar | 255 | 职位领域 |
| edu | Varchar | 255 | 学历要求 |
| edu_count | int | 12 | 计数 |
表3.5 城市所在地和人员需求以及公司业务范围的关系
| 字段名称 | 数据类型 | 长度 | 备注 |
| city | Varchar | 255 | 城市 |
| People_sum | int | 20 | 人员需求 |
| companyarea | Varchar | 255 | 公司业务范围 |
表3.6 职位的要求词频
| 字段名称 | 数据类型 | 长度 | 备注 |
| Word | Varchar | 255 | 词 |
| count | Int | 12 | 个数 |
表3.7 学历要求和工作经验与工资水平的关系
| 字段名称 | 数据类型 | 长度 | 备注 |
| edu | Varchar | 255 | 学历要求 |
| workingexp | Varchar | 255 | 工作经验 |
| Salary_avg | double | 20 | 工资水平 |
表3.8 公司性质的学历要求与经验要求
| 字段名称 | 数据类型 | 长度 | 备注 |
| company_type | Varchar | 255 | 公司性质 |
| Edu | Varchar | 255 | 职位名称 |
| workingexp | Varchar | 255 | 工资水平 |
| Edu_exp_count | int | 12 | 个数 |
表3.9 公司福利的词云展示
| 字段名称 | 数据类型 | 长度 | 备注 |
| Word | Varchar | 255 | 词 |
| count | int | 12 | 计数 |
4.1数据处理
将数据通过spark SQL,分别进行数据处理与筛选,根据数据存储格式依次编写sql语句如图4.1,并将处理好的数据保存到数据库,方便分析调用。

图4.1 数据处理SQL语句
数据预测代码
首先创建spark对象,然后通过创建的spark对象实例,读取本地的待处理数据文件,通过Scala函数创建数据文件的临时表,对临时表执行如下操作语句:
|select salary,company_size,company_type,empltype,workingexp,resume_count
|from tbl_onsalecode
|""".stripMargin)
对查出的数据中的特征列即除薪资以外的所有列,将标签值与特征列进行map方法映射,拆分组合。
随机森林预测代码及相关注释如下:
val data=value.toDS()
val splits=data.randomSplit(Array(0.8,0.2))//定义训练集、测试集比例
val(trainingData,testData)=(splits(0),splits(1))
val featureIndexer=new VectorIndexer()///VectorIndexer():提高决策树或随机森林等ML方法的分类效果
.setInputCol("features")
.setOutputCol("indexedFeatures")
.setMaxCategories(4)//把特征值中的离散值数量大于4的认为是连续特征,小于4的认为是离散特征
.fit(data)
//Train a RandomForest model.
val rf=new RandomForestRegressor()
.setLabelCol("label") //设置标签列(标签列的名称)
.setFeaturesCol("indexedFeatures") //设置特征列,训练集DF中存储特征列的列名
.setMaxDepth(10)
val pipeline=new Pipeline() //把特征处理和回归树组成一个pineLine
.setStages(Array(featureIndexer,rf))
//Train model.This also runs the indexer.
//使用pineLine训练一个模型
val model=pipeline.fit(trainingData)
//Make predictions.
//使用模型对训练数据进行预测
val predictions=model.transform(testData)
//Select(prediction,true label)and compute test error.
//使用回归评估模型评估预测的结果
val evaluator=new RegressionEvaluator().setLabelCol("label").setPredictionCol("prediction")
.setMetricName("rmse")val rmse=evaluator.evaluate(predictions)
println(s"Root Mean Squared Error(RMSE)on test data=$rmse")//输出训练过程中使用的回归树的具体参数
val rfModel=model.stages(1).asInstanceOf[RandomForestRegressionModel]
val resultRDD:RDD[Row]=predictions.select("prediction","label","features")
.rdd.map(x=>{
var features=x.get(2).toString.slice(1,x.get(2).toString.length-1).split(",")
Row(scala.math.ceil(x.get(0).toString.toDouble),x.get(1).toString,features(0).toString,features(1).toString,
features(2).toString,features(3).toString,features(4).toString)}) //将预测的结果重新排列组合
val schema=new StructType()
.add("prediction",DoubleType).add("salary",StringType).add("company_size",StringType).add("company_type",StringType).add("empltype",StringType).add("workingexp",StringType).add("resume_count",StringType)
val result=spark.createDataFrame(resultRDD,schema)//保存数据预测结果
result.write//将结果保存到Hadoop集群的MySQL关系型数据库中
.format("jdbc")//指定驱动类型
.option("url","jdbc:mysql://192.168.121.200:3306/house")//指定MySQL关系型数据库地址及数据库名称
.option("driver","com.mysql.cj.jdbc.Driver") // 指定驱动程序
.option("user","root") //指定MySQL数据库用户名
.option("password","Root123.")// 指定MySQL数据库用户名对应的密码
.option("dbtable","tbl_predict_price")//指定数据保存在MySQL数据库中的表名称
.mode(SaveMode.Overwrite) //指定保存类型,这里为覆盖写入
.save()
4.2数据分析
4.2.1岗位地区分析
分析特征列:city,count
将count列的数据按照城市相同的条件相加,根据count的大小做一个气泡地图,对其分析,如图4.3所示
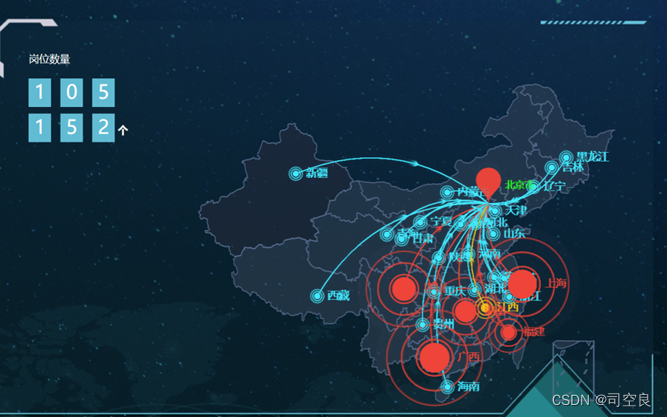
图4.3 城市岗位数量分布图
图4.3是一个典型的地图气泡图,从中我们可以很容易的看出我国岗位数量的分布极不平衡,大部分岗位分布在我国的南方和沿海东部,考虑到我国的经济水平南方比北方高,东部比西部高,这一现象也是比较符合我国当前部分地区发展不平衡不充分这一现象。
4.2.2岗位数量分析
分析特征列:city,count
对所有地区的岗位数量求和然后按照降序排列,同时对排名前十的地区城市做环形图可视化分析如图4.4所示。
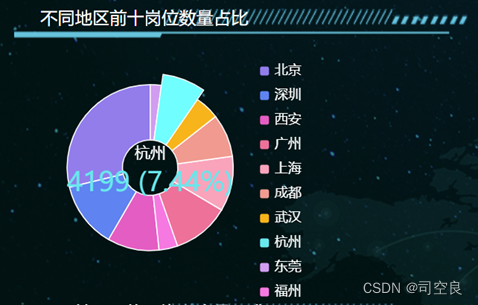
图4.4 不同地区岗位前十数量占比图
图4.4是一个环形图,图中清晰的显示出了各个地区的岗位数量和所占比例,按照降序排列,北京的数据最高达到了16243,所占比例为28.79%,其次则是深圳7253,所占比例是12.86%,广州6278,所占比例11.68%,上海6036,所占比例10.7%,西安5687,所占比例10.08%,成都4725,所占比例8.37%,杭州4199,所占比例7.44%,武汉2720,所占比例4.82%,福州2053,所占比例3.63%,东莞1222,所占比例2.17%。
4.2.3不同地区的工资和人员需求分析
分析数据列:city,people_sum,Avg_salary
对不同地区的工资求和后求平均值,对不同地区的需求人员累加求和同时加以分析,如图4.5,4.6所示。
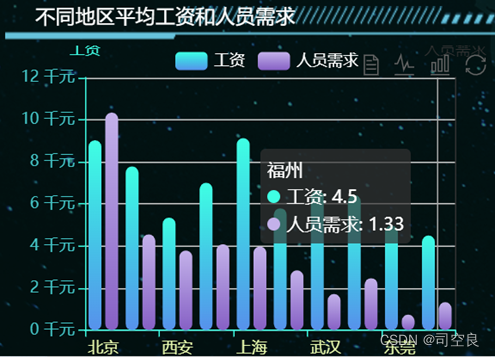
图4.5 不同地区的平均工资和人员需求条形图
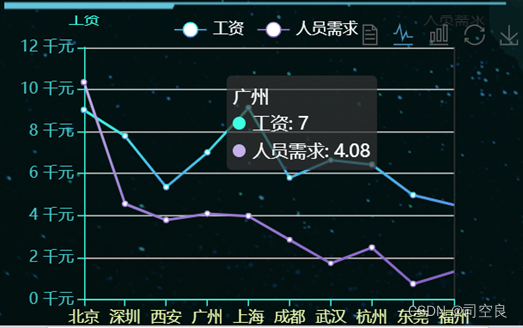
图4.6 不同地区的平均工资和人员需求折线图
图4.5是一个条形图,通过条形图展示各个地区的平均工资,其中工资最高的是上海平均工资达到了9.12k,其次则是北京达到了9.02k,深圳7.78k,广州7k,武汉6.63k,杭州6.42k,成都5.79k,西安5.43k,东莞4.97k,福州4.5k。人员需求方面北京的人员需求最多,但是北京的平均工资不是最高的,福州的平均工资最低,但是人员需求不是最低的,从图4.6可以看出人员需求和平均工资没有太大的关系。
4.2.4学历要求分析
析数据列:edu,edu_count
将不同职业所要求的学历个数求和做条形图同时加以分析如图4.7所示。

图4.7 学历要求分析图
从图4.7可以看出,目前的主流学历是大专,所占比例达到了54.11%占一半以上,其中本科占33.46%,中专占7.18%,硕士占2.86%,不限学历的行业占1.66%,高中占0.72%,博士占0.02%。
4.2.5工作经验分析
分析数据列:workingexp,workexp
将不同的工作所需要的工作经验,按照所需要的工作经验时间相加,同时做环形图加以分析如图4.8所示。
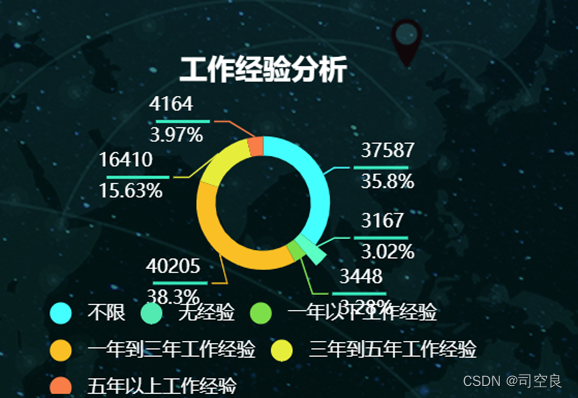
图4.8 工作经验分析
从图4.8可以发现在目前的职场中,不限工作经验的工作数量达到了37587,所占比例为35.8%,一年一下工作经验为3448,所占比例为3.28%,无经验为3167,所占比例是3.02%,一年到三年工作经验为40205,所占比例是38.3%,三年到五年工作经验为16410,所占比例是15.63%,五年以上工作经验为4164,所占比例是3.97%。
4.2.6不同学历收入
分析数据列:edu,Salary_avg
将不同学历的工资求和再求平均值做环形图分析如图4.9所示。

图4.9 不同学历收入环形图
从图4.9可以得到硕士工资最高达到了8.6k,中专的工资最低只有2.8k,其中平均工资是5.5k。
5.1数据规格化
将数据中自然语言转换成数值类型,并通过卡方检测进行相关性分析,最后分析得分如图5.1。
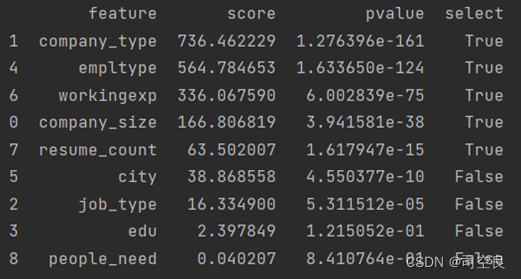
图5.1 特征列得分
5.2薪资预测
通过随机森林算法选取图5.1的特征列进行薪资预测。最后将数据映射会原特征值,并进行存储。
6.1 项目封装
将数据处理与分析代码,通过maven框架中的Lifecycle的package进行项目打包。将打包的jar文件及数据文件上传到虚拟机。
6.2 项目可视化与预测展示
6.2.1 可视化展示
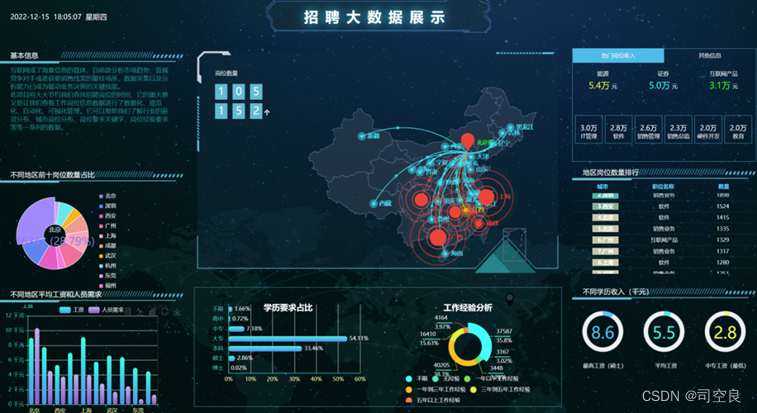
图6.1 可视化
6.2.2 预测界面
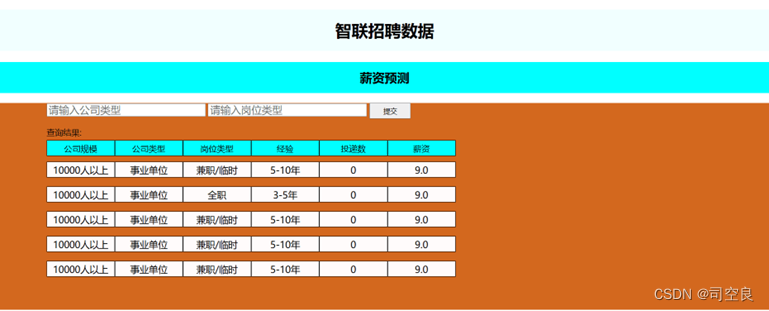
图6.2 预测
通过本次长达一个月左右的综合实训,接触到了一些之前没有接触过的技术,如spring boot、django框架等,并且也使学到的相关技术知识串联到了一起形成了一个较完整的项目。虽然说项目中一些功能没有完全的整合到一起,但相对来说有了一定的体系结构框架,把他们连接到了一起。由于一些技术是初次接触,导致程序中的代码冗余比较严重,实现过程过于复杂,程序响应起来有一定的延迟,有许多地方还需优化。
最后通过以上分析与预测得出以下结论与建议:
- 南方比北方的工作岗位和需求人员更多。
- 北上广深的就业机会更大一些。
- 工资的高低与需求人员的多少没有太大关联。
- 本科以下的学历占比64%左右。
- 不限工作经验、无经验的岗位占比36%左右
- 热门岗位前三是证券、能源、互联网产品
- 不同学历之间收入差距明显
建议:
工作优先选择大城市,大城市的就业岗位更多,薪资水平更高,同时北方人也可以选择去南方发展,南方工作岗位和需求人员更多,同时要具备一定的工作经验,大四如果不考研考公的话要积极准备实习,大部分工作岗位需要工作经验,本科的学历足矣就业,当然学历更高就业后的薪资水平更高,根据每个人的计划,是选择就业或者考研。
参考文献:
[1]段红秀, 刘梅,and 陈震啸."基于大数据技术的招聘服务平台设计与实现." 互联网周刊 .19(2022):13-15.
[2]王金威."基于大数据分析的高校云招聘信息个性化推送研究." 安徽电子信息职业技术学院学报 21.04(2022):25-31.
[3]吴莉萍, 刘科,and 谢鹏."互联网招聘大数据分析对于高职院校学生就业的推进作用." 内江科技 43.07(2022):55-56+37.
[4]张振寰."基于大数据面向就业岗位招聘的数据分析." 科技资讯 20.12(2022):228-231. doi:10.16661/j.cnki.1672-3791.2203-5042-4550.
[5]殷乐."大数据在企业人力资源招聘管理中的应用研究——以JJ公司为例." 中国管理信息化 25.12(2022):167-169.
[6]宋东翔, 王怡然,and 马伽洛伦."基于ECharts的高校教师招聘大数据可视化平台构建与应用." 软件 43.05(2022):42-45.
[7]甘丽新, et al."基于招聘网络大数据的软件行业相关人才需求的挖掘与分析." 信息与电脑(理论版) 34.08(2022):39-41.
[8]陈芬. 浅析网络Cookie[J]. 电脑知识与技术, 2005(35):93-95.

