
- 13D GS谁敢一战?26ms完成三维重建!
- 2SciPy 线性代数_scipy.linalg.eig
- 3Python开发GUI常用库PyQt6和PySide6介绍之二:设计师(Designer)_ubuntu qt6 designer
- 4【案例实战】NodeJS+Vue3+MySQL实现列表查询功能_nodejs分页查询和获取文章列表接口
- 5JavaScript表单验证与交互_js input表单验证
- 6Android 设置秒开全屏启动屏_安卓盒子浏览器 启动全屏
- 7基于RabbitMQ订单未支付30分钟自动取消_rabbitmq订单过期取消
- 8Kafka——Rebalance重平衡_kafka rebalance触发的条件
- 9MySQL - undo log 图文详解_undo_log表
- 10【MySQL进阶之路丨第九篇】一文带你精通MySQL子句
书生·浦语大模型全链路开源体系
赞
踩
1 背景概述
在人工智能高速发展的今天,尤其是以ChatGPT为代表的大语言模型,给人们带来了非常震撼的体验效果。各大公司、研究机构纷纷发布自己的大模型,国内发布的大模型就有:书生(InternLM)、文心一言(Yiyan)、百川(Baichuan)、通义千问(Qwen)、ChatGLM等,国外比较知名的有:Llama系列、GPT3.5、GPT4、Claude、Gemini等。上述大模型有些开源,有些未开源,并且大模型逐步开始往多模态方向发展演进。
鉴于当前百模齐放、百模大战,作为一个初学者,估计已经迷失其中,不知如何选择,问题众多。那家模型效果更好?如何训练、微调?如何构建智能体?如何部署大模型?如何评测模型能力?
上述问题,在书生·浦语大模型全链路开源体系均能找到答案,书生·浦语大模型由上海人工智能实验室发布,其云集了众多青年科学家和社区大佬,值得信赖。(重要的事情说三遍:没有打广告,个人觉得以书生·浦语大模型全链路开源体系为切入点,是一个学习大模型实践的不错路径,能够有效解决很多初学者面临的困惑)
废话不多说,直接上书生·浦语大模型全链路开源体系介绍视频链接:书生·浦语大模型全链路开源体系_哔哩哔哩_bilibili
视频全长42分钟,由上海人工智能实验室 陈恺(青年科学家)为大家介绍。视频精简总结如下,时间充裕可以结合视频阅读本帖。
2 大模型训练部署决策流程图
通常,如果你自己想训练部署大模型,你会面临如下图所示决策流程。接下来,借助书生·浦语大模型全链路开源体系,介绍流程图中各环节如何实践,解决怎么做的问题。
至于其他开源大模型项目实践过程,一是大体过程相差不大,二是只专注于大模型全流程体系某一环节,不成体系。还是那句话,个人觉得以书生·浦语大模型全链路开源体系为切入点,是一个学习大模型实践的不错路径,一通百通。
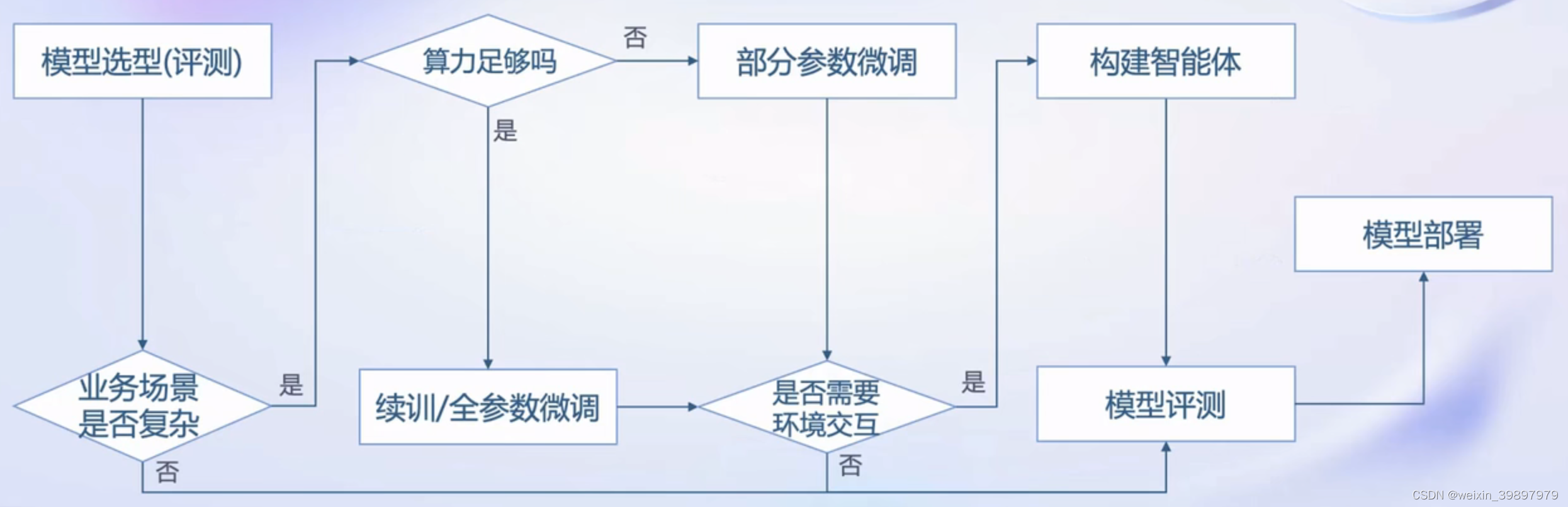
大模型训练部署决策流程图
3 书生·浦语大模型全链路开源体系
下图为书生·浦语大模型全链路开源体系,包含数据、预训练、微调、部署、评测、应用端到端全流程体系。
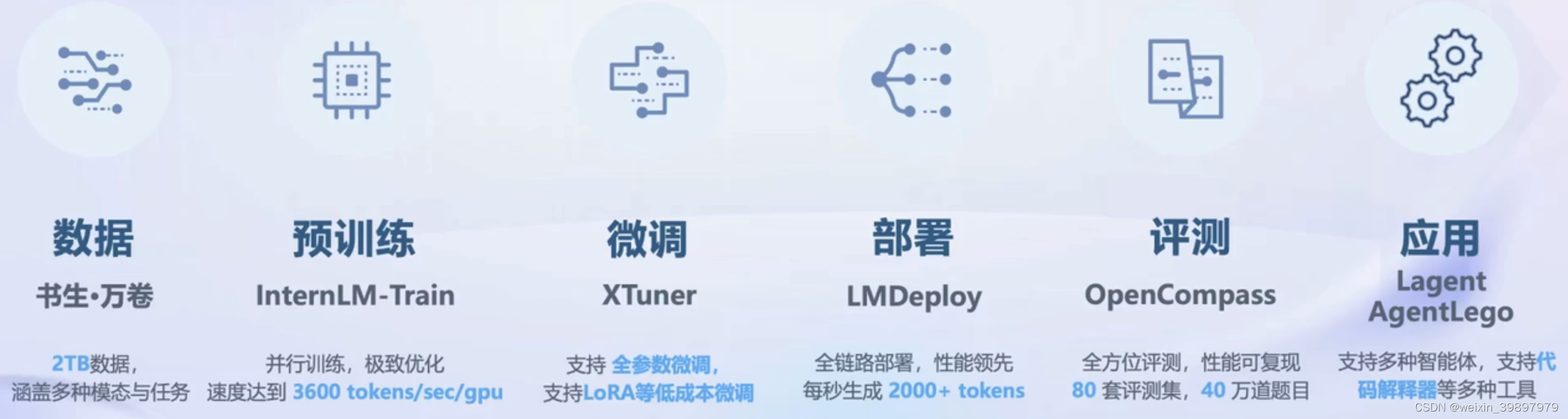
书生·浦语大模型全链路开源体系
3.1 数据
如果各位缺乏数据,别慌,可以在OpenDataLab开源数据管理平台上,大概率能找到你想要的数据,当然,你也可以在上面共享自己高质量的数据,为社区做贡献。上数据链接:OpenDataLab开源数据集

OpenDataLab开源数据管理平台数据总览
平台上也包括InternLM大模型预训练数据:书生·万卷1.0数据,下载链接:书生·万卷1.0数据集
以书生·万卷1.0为例,数据包含文本数据集、图文数据集、视频数据集三部分,数据总量超过2TB。基于大模型数据联盟构建的语料库,上海人工智能实验室对其中部分数据进行细粒度清洗、去重以及价值对齐,形成了书生·万卷1.0,具备多元融合、精细处理、价值对齐、易用高效等四大特征。
而其中的文本数据集部分,由来自网页、百科、书籍、专利、教材、考题等不同来源的清洗后预训练语料组成,数据总量超过5亿个文档,数据大小超过1TB。该语料将html、text、pdf、epub等多种格式的数据统一处理为字段统一的jsonl格式,并经过细粒度的清洗、去重、价值对齐,形成了一份安全可信、高质量的预训练语料。数据组成及样例如下:
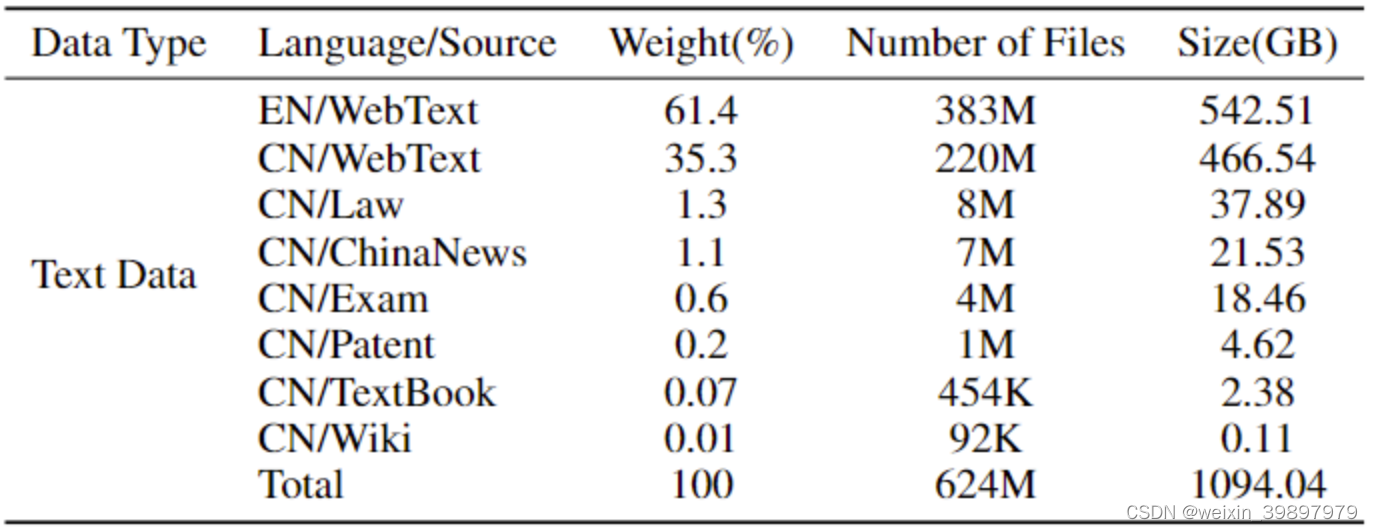
书生·万卷1.0文本数据集组成

书生·万卷1.0文本数据集样例
看了上面的数据介绍,数据管理、预处理,构建高质量的数据集,只是大模型炼丹的第一步。并且大模型数据管理、构建高质量数据集也相当重要,否则后续大模型训练无从谈起。关于大模型数据管理,时间充裕可以参考这篇文章详细了解:Data Management For Large Language Models: A Survey。
3.2 预训练
InternLM(github搜索关键字)为上海人工智能实验室发布的大模型,具体模型下载、使用、训练过程可以参考开源项目链接:InternLM大模型
项目支持从8卡到千卡训练,千卡加速效率达92%。支持Hybrid Zero独特技术+极致优化,加速50%。支持无缝接入HuggingFace等技术生态,支持各类轻量化技术。关于Zero优化技术,时间充裕可以参考这篇文章学习:ZeRO++: Extremely Efficient Collective Communication for Giant Model Training
InternLM大模型有三个不同量级参数,分别如下:
InternLM-7B:70亿模型参数、1000亿训练token数据、支持8K语境窗口长度
InternLM-20B:200亿模型参数、采用深而窄的网络结构、4K训练语境长度,推理时可外推至16K
InternLM-123B:1230亿模型参数、极强推理能力、全面的知识覆盖面、超级理解能力与对话能力
社区主流评测数据集评测结果:
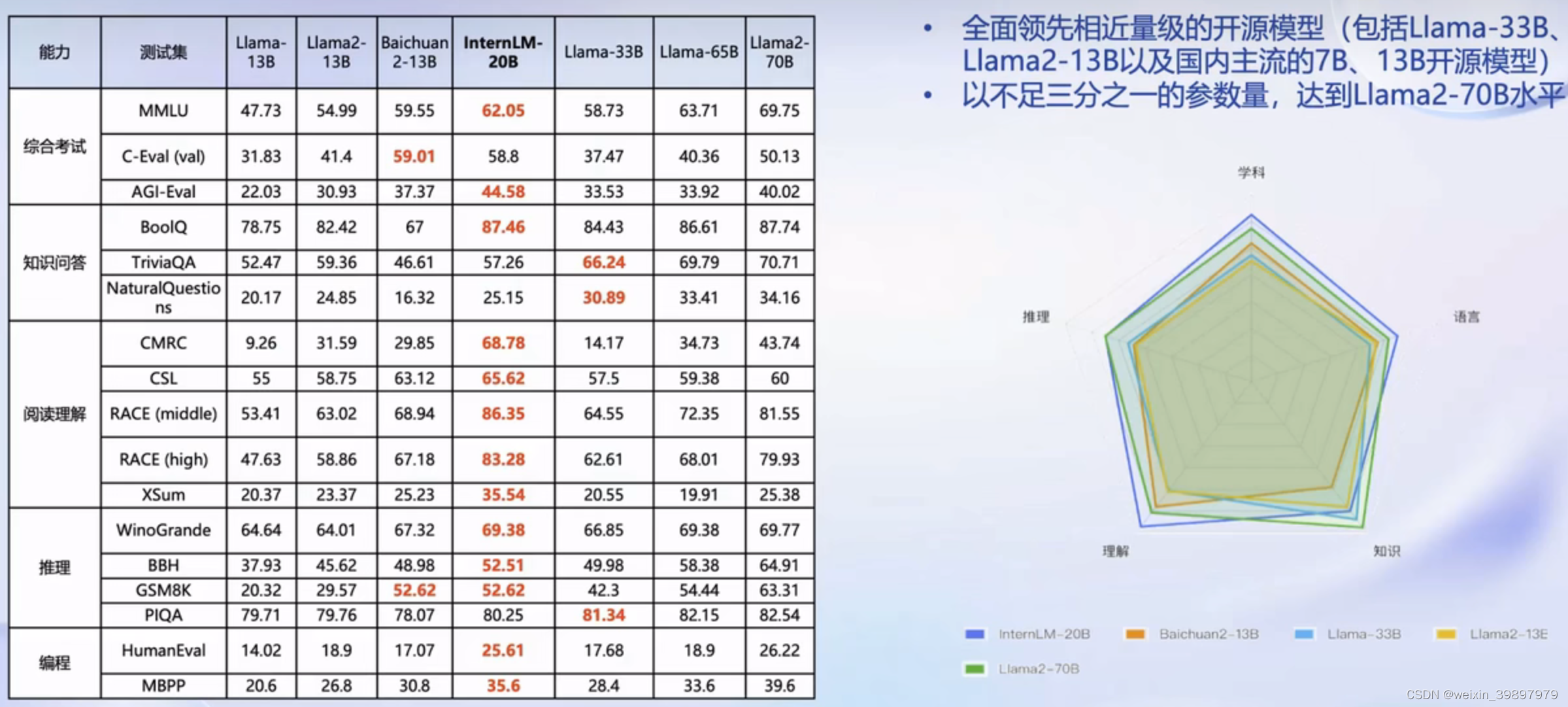
InternLM-20B大模型性能与Llama系列对比
结论:相同参数量级,InternLM效果更好。不过预训练普通玩家一般玩不起,因需要占用大量GPU算力,不过接下来的微调,普通玩家可以玩一玩,最低只需8G显存即可微调7B模型。
3.3 微调
微调包括增量续训和有监督微调。增量续训主要用于让基座模型学习到一些新知识,如某个垂类领域知识文章、书籍、代码等;有监督微调主要用于让模型学会理解和遵循各种指令,或者注入少量领域知识,如高质量对话、问答数据。
上海人工智能实验室为支持各类主流模型微调,开源了xtuner项目,具体微调过程,可参考链接:xtuner大模型微调
xtuner项目支持各类微调数据集和主流的大模型,并且支持能力也在持续升级中,如强化学习对齐人类偏好。
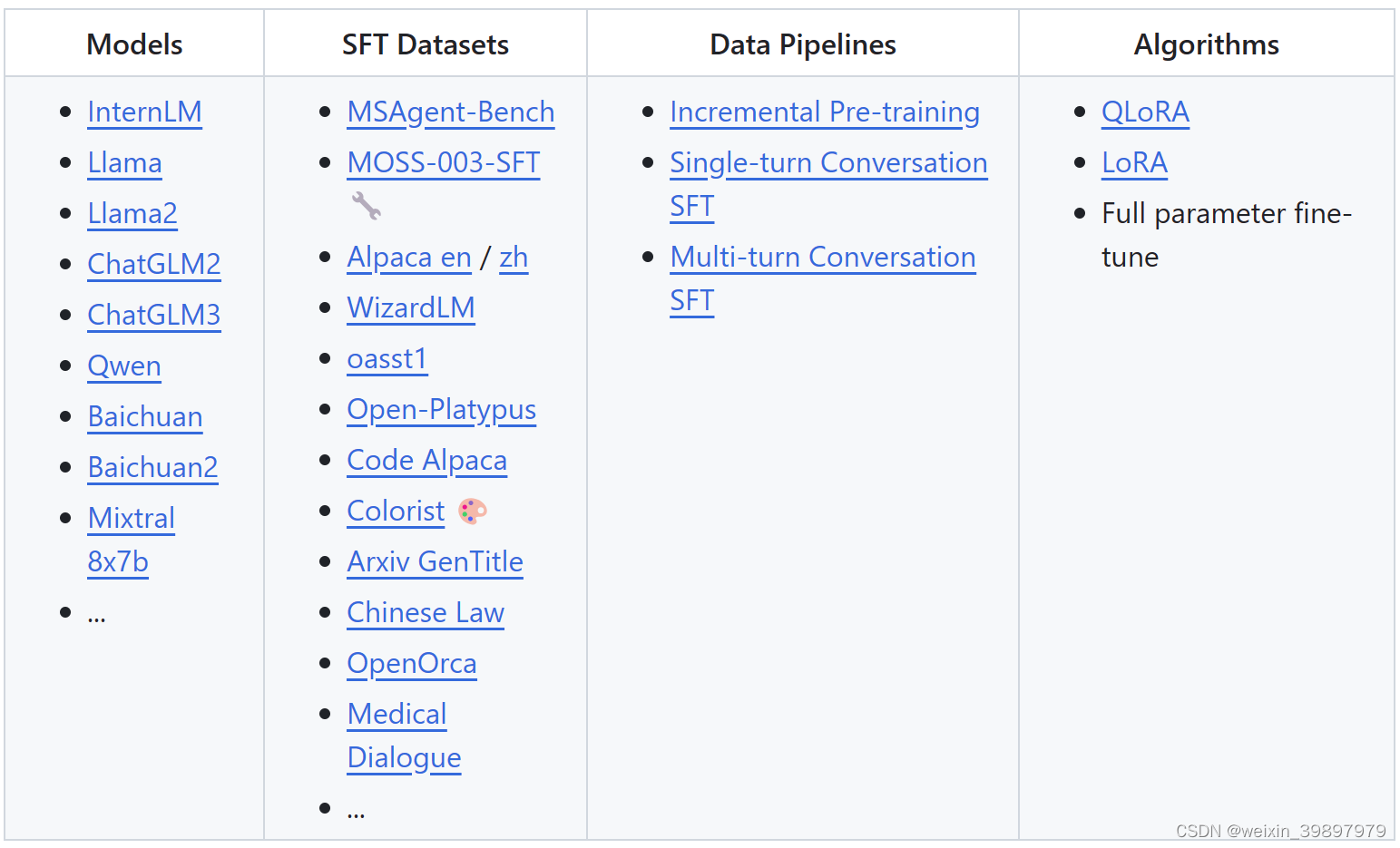
xtuner项目微调能力集
基于xtuner项目微调,以InternLM 7B为例,结合LoRA技术,在普通消费级显卡上即可实现微调训练。具体显存占用及对应显卡名称见下图,其他更大参数量规模模型显存占用,可以参考此7B基线进行放大预估。
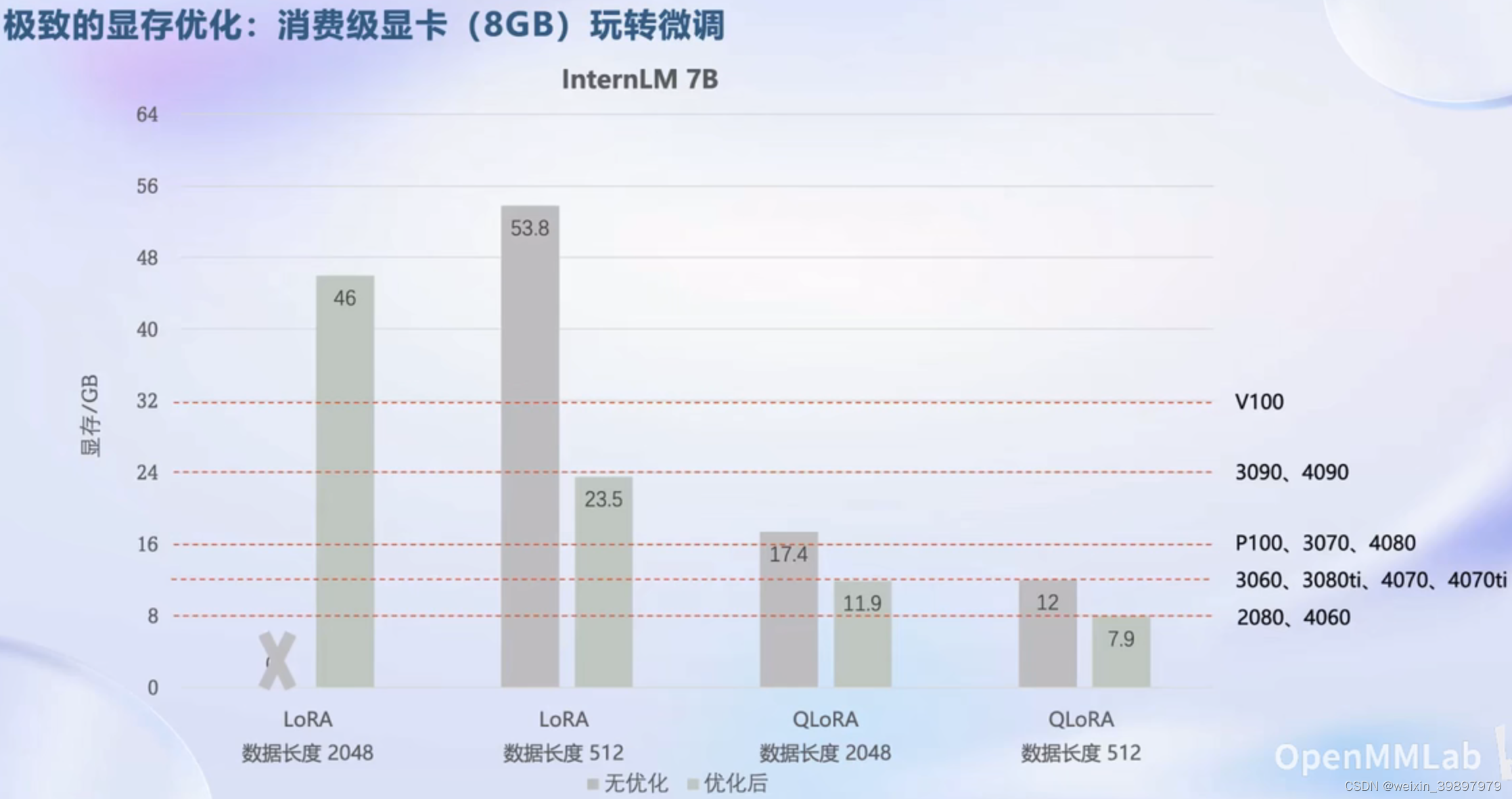
xtuner对InternLM 7B模型微调显存占用
为什么显存占用这么低?因为使用了LoRA技术,其主要是利用了矩阵奇异值分解思想,降低了权重矩阵的维度,实现了训练参数的减少,并且最终模型效果与全量微调差别不大。如果时间充裕,有对LoRA技术不了解的,可以参考阅读这篇文章:LoRA: Low-Rank Adaptation of Large Language Models
3.4 部署
针对大语言模型内存开销巨大、庞大的参数量、采用自回归生成token、需要缓存k/v、动态Shaps、请求数不固定、逐个生成数量不定token、transformer结构特点。如何加速token的生成速度?如何解决动态shape,让推理可以不间断?如何有效管理和利用内存服务?如何提升系统整体吞吐量?如何降低请求的平均响应时间?
上海人工智能实验室结合模型并行技术、低比特量化技术、Atterntion优化技术、计算和访存优化技术、Continuous Batching技术,有效解决上述问题,推出高效推理引擎LMDeploy开源项目。具体的,大模型项目如何高效推理部署,可参考开源项目:LMDeploy大模型高效推理部署
LMDeploy开发了两个推理引擎——Pytorch和TurboMind,它们各自侧重于不同的方面,前者致力于推理性能的最终优化,而后者则纯粹在Python中开发,旨在降低开发人员的门槛。
在各种规模的模型中,TurboMind引擎的请求吞吐量比vLLM高1.36 ~ 1.85倍。 在静态推理能力方面,TurboMind的4bit模型推理的token吞吐量(输出token/s)显著优于FP16/BF16推理,最高提高了2.4倍。

TurboMind引擎性能对比
3.5 评测
大模型效果好不好,关键在于建立科学的评测体系,当前国内外主流的评测体系如下:
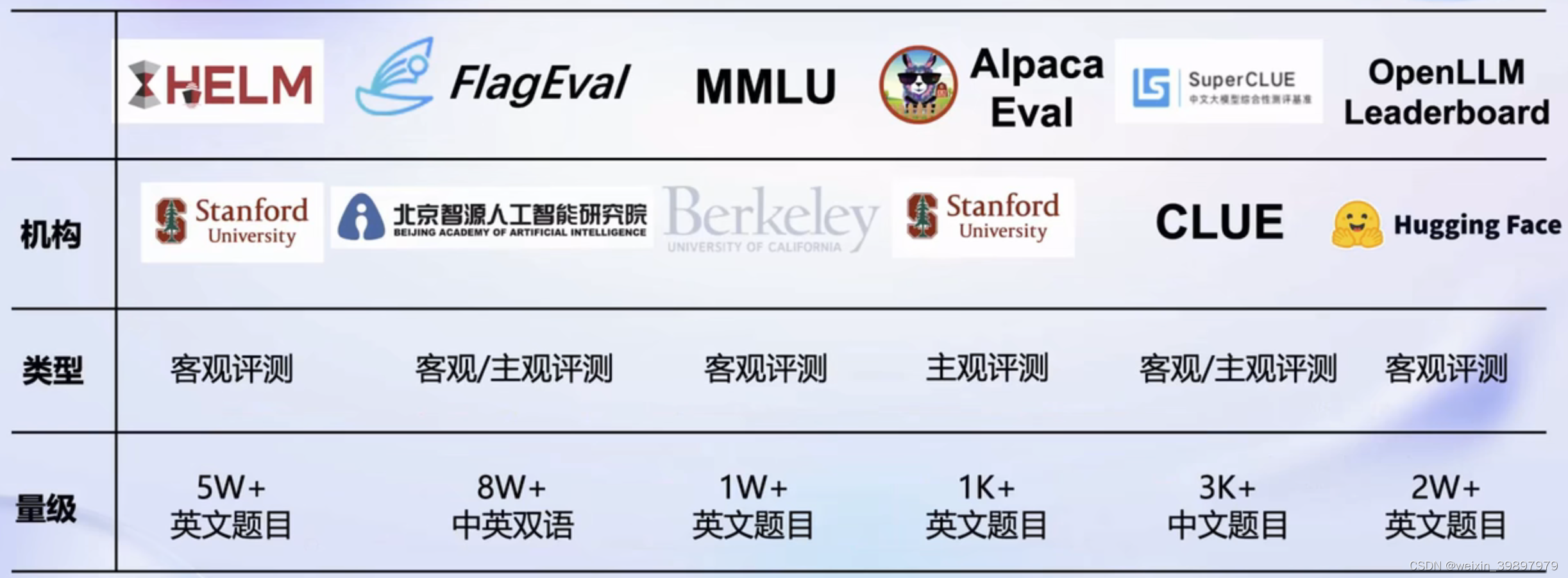
国内外主流大模型评测体系
斯坦福HELM评测,感兴趣可以通过项目链接进行了解,包括对应论文:HELM评测项目
FlagEval评测项目链接:FlagEval评测项目
MMLU评测官网:MMLU评测
Alpaca Eval评测项目链接:Alpaca Eval评测项目
SuperCLUE评测项目链接:SuperCLUE评测项目
OpenLLM LeaderBoard:OpenLLM评测榜单
上海人工智能实验室,在此基础上,发布了更加全面的OpenCompass评测体系:OpenCompass项目链接,包含6大维度,80+评测集,40万+评测题目,如下:

OpenCompass评测体系
3.6 应用
大模型应用方面,上海人工智能实验室推出两个开源项目:轻量级智能体Lagent,多模态智能体工具箱AgentLego。
Lagent是一个轻量级的开源框架,允许用户高效地构建基于大型语言模型(LLM)的代理。项目链接:Lagent智能体开源项目。框架及能力图如下:

Lagent智能体框架

Lagent智能体能力图
关于智能体一个典型的应用场景是,大模型不擅长数学计算,智能体会将PythonInterpreter作用工具使用,从而增强模型输出的正确性。关于智能体PythonInterpreter使用demo,可参考如下链接第3部分(Lagent 智能体工具调用 Demo)学习:Lagent 智能体工具调用 Demo
为了进一步扩展智能体的工具集,AgentLego项目应运而生,是一个通用工具api的开源库,用于扩展和增强基于大型语言模型(LLM)的智能体能力。AgentLego项目链接:Agentlego开源项目。能力图如下:

AgentLego能力图谱
4 结语
上海人工智能实验室构建了书生·浦语大模型全链路开源体系,是一个很好的学习大模型切入点。如果对大模型体系内容感兴趣、或者内容对自己有帮助,可以为支持的项目点一个star,进一步深入学习。

