
- 1platformIO上传程序到stm32失败,Warn : UNEXPECTED idcode: 0x2ba01477
- 2java 线程变量_Java线程变量问题-ThreadLocal
- 3如何使用 Python 爬取微信公众号文章_python拷贝微信公众号文字csdn
- 4DELL-R730服务器U盘安装操作系统指南_戴尔r730服务器u盘安装系统
- 5WeChat小程序开发:基础笔记(一)_bindtap和bind:tap
- 6(BN)批量归一化全面解析_批量归一化的前向传导过程
- 7基于机器学习的垃圾分类
- 8scrapy爬虫框架中基于redis分布式,数据存储mysql中_scrapy-redis分布式爬虫的数字存在数据库吗
- 9认识Docker及基本管理_docker容器技术可以在一台主机上轻松地为任何应用创建一个()、()、()的容器。
- 10使用 Docker 部署 Stirling-PDF 多功能 PDF 工具
HifiFace: 3D形状和语义先验引导高保真人脸交换阅读笔记
赞
踩
HifiFace: 3D Shape and Semantic Prior Guided High Fidelity Face Swapping HifiFace: 3D形状和语义先验引导高保真人脸交换
介绍

可以很好地保留源人脸的脸型,并产生逼真的结果。不同于现有的人脸交换只使用人脸识别模型来保持身份相似性的方法,我们提出了3D形状感知身份,利用3DMM的几何监督和3D人脸重建方法来控制人脸形状。
同时,引入语义面部融合模块,优化编码器和解码器特征的组合,进行自适应混合,使结果更加逼真。
为了生成高保真的人脸交换结果,需要解决以下几个关键问题:(1)结果人脸的身份特征(包括脸型)应接近源人脸。(2)结果应具有真实感,忠实于目标面部的表情和姿态,并与目标图像的光照、背景、遮挡等细节保持一致。
为了保持生成的人脸的身份,以前的作品通过3DMM拟合或人脸地标引导再现生成内人脸区域,并将其融合到目标图像中,如图2(a)所示。这些方法由于3DMM无法模拟身份细节,目标地标包含目标图像的身份,因此身份相似度较弱。此外,混合阶段限制了脸型的变化。(b)通过人脸识别网络提高身份相似度。然而,人脸识别网络更多地关注纹理,对几何结构不敏感。因此,这些方法不能很好地保持准确的脸型。
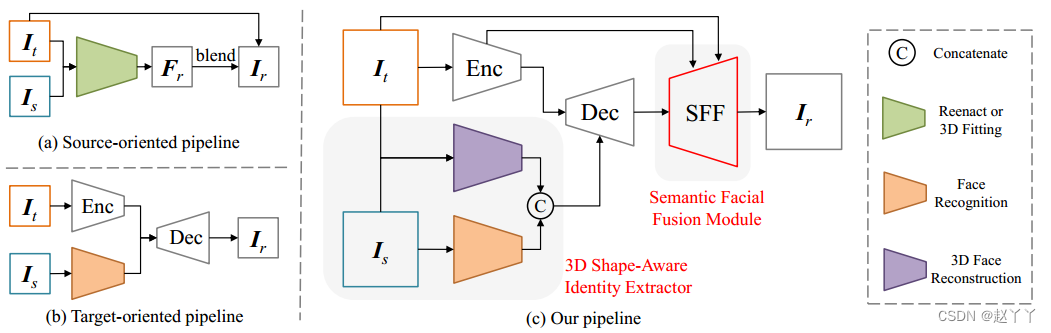
(a)面向源的管道使用3D拟合或再现生成内人脸区域,并将其融合到目标图像中,其中Fr为结果的人脸区域。(b)面向目标的管道使用人脸识别网络来精确识别身份,并将编码器特征与解码器中的身份相结合。©我们的管道由四个部分组成:Encoder部分,Decoder部分,3D形状感知身份提取器和SFF模块。编码器从中提取特征,解码器将编码器特征与三维形状感知身份特征融合。最后,SFF模块有助于进一步提高图像质量。
至于生成逼真的结果,使用泊松混合来固定光照,但容易造成重影,无法处理复杂的外观条件。额外的基于学习的阶段来优化照明或遮挡问题,但它们过于繁琐,无法在一个模型中解决所有问题。我们引入了语义面部融合(SFF)模块,使我们的结果更逼真。光照和背景等属性需要空间信息,高质量的图像结果需要详细的纹理信息。编码器中的底层特征不仅包含空间和纹理信息,还包含与目标图像的丰富身份信息。因此,为了在不损害身份的情况下更好地保留属性,我们的SFF模块通过学习到的自适应掩码将底层编码器特征和解码器特征集成在一起。最后,为了克服遮挡问题,获得完美的背景,我们也通过学习到的人脸掩码将输出混合到目标上。与直接使用目标图像的人脸蒙版进行混合不同,HifiFace在扩展的人脸语义分割的指导下同时学习人脸蒙版,这有助于模型更加关注面部区域,并在边缘周围进行自适应融合。
具体而言,我们首先通过三维人脸重建模型对源面和目标面系数进行回归,并将其重新组合为形状信息。然后我们将其与人脸识别网络中的身份向量连接起来。明确地利用三维几何结构信息,并将重组的三维人脸模型与源的身份、目标的表情和目标的姿态作为辅助监督,以实现精确的脸型转移。通过这种专门的设计,我们的框架可以实现更多相似的身份表现,特别是在脸型上。
相关工作
基于3D的方法
- [Blanz and Vetter, 1999]3D变形模型(3D Morphable Models, 3DMM)将样本的形状和纹理转换为向量空间表示。
- [Thies等人,2016]通过将一个3D可变形面部模型拟合到两个面部,将表情从源面部转移到目标面部。
- [Nirkin et al ., 2018]通过3DMM转移表情和姿态,并训练人脸分割网络来保留目标面部遮挡。
这些基于3D的方法遵循如图2(a)所示的面向源的管道,仅通过3D拟合生成人脸区域,并通过目标人脸的掩码将其融合到目标图像中。由于3DMM和渲染器不能模拟复杂的照明条件,它们遭受了不现实的纹理和照明。此外,混合阶段限制了脸型。相比之下,HifiFace通过3DMM的几何信息准确地保留了人脸形状,并通过语义先验引导的编码器和解码器特征重组获得了逼真的纹理和属性。
基于GAN的方法
- [Isola et al., 2017]提出了一种通用的图像到图像转换方法,证明了条件GAN架构在交换人脸方面的潜力,尽管它需要成对数据。
基于gan的人脸交换方法主要遵循面向源的管道或面向目标的管道。 - [Nirkin等人,2019;Jiang等人,2020]遵循图2(a)中的面向源的管道,使用人脸地标组成人脸再现。但它可能带来较弱的身份相似性,并且混合阶段限制了脸型的变化。
- [刘等,2019;Chen et al ., 2020;Li等人,2019]采用了图2(b)中的面向目标的管道,该管道使用人脸识别网络提取身份,并使用解码器将编码器特征与身份融合,但它们不能鲁棒地保持准确的人脸形状,并且图像质量较弱。相反,HifiFace在图2(c)中用3D形状感知身份提取器取代了人脸识别网络,以更好地保留包括面部形状在内的身份,并在解码器后引入SFF模块,进一步提高真实感。
其中FaceShifter和SimSwap遵循面向目标的流水线,可以生成高保真度的结果。FaceShifter利用两阶段框架实现了最先进的身份性能。但是,尽管使用了一个额外的固定阶段,它也不能完美地保持灯光。然而,HifiFace可以很好地在一个阶段保留照明和身份。同时,HifiFace可以生成比facshifter质量更高的逼真效果。facshifter提出了弱特征匹配损失来更好地保留属性,但损害了身份相似度。HifiFace可以更好地保留属性,不损害身份。
方法
首先,我们将It设置为编码器的输入,并使用几个res-block 来获得属性特征。然后,利用三维形状感知身份提取器得到三维形状感知身份。之后,我们在解码器中使用具有自适应实例归一化的res-block [Karras等,2019]来融合3D形状感知身份和属性特征。最后,我们使用SFF模块来获得更高的分辨率,使结果更逼真。
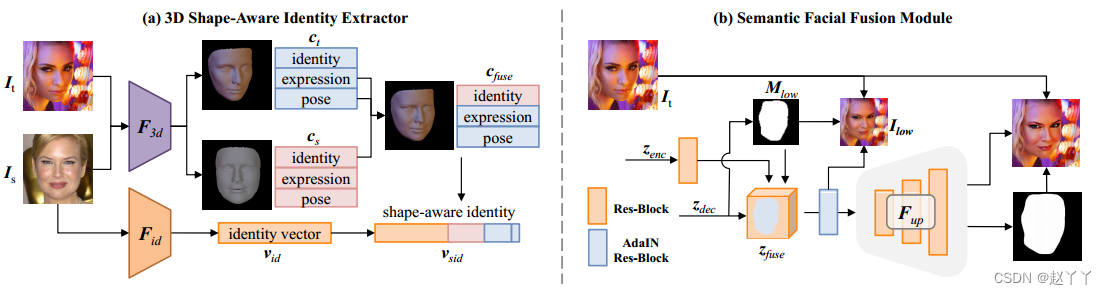
(a) 3D形状感知身份提取器使用F3d (3D人脸重建网络)和Fid(人脸识别网络)生成形状感知身份。(3D模型身份参数中包含脸型)(b) SFF模块由Mlow重新组合编码器(非面部区域)和解码器特征(人脸区域),由Mr.进行最后的混合。Fup是指上采样模块。
3D形状感知身份提取器
大多数基于gan的方法在人脸交换任务中只使用人脸识别模型来获取身份信息。然而,人脸识别网络更多地关注纹理,对几何结构不敏感。为了获得更精确的脸型特征,我们引入了3DMM,并使用预训练的最先进的3D人脸重建模型[Deng et al ., 2019]作为形状特征编码器,该模型通过仿射模型表示脸型S:
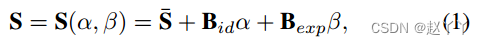
其中¯S为平均脸型;Bid、Bexp是身份和表情主成分分析的基础;α和β是生成三维人脸的相应系数向量。
如图3(a)所示,我们使用三维人脸重建模型F3d对包含源人脸和目标人脸身份、表情和姿态的3DMM系数cs和ct进行回归。然后,结合源的身份、目标的表情和姿态,生成新的三维人脸模型。请注意,姿势系数不能决定脸型,但在计算损失时可能会影响二维地标的位置。我们没有使用纹理和光照系数,因为纹理重建仍然令人不满意。最后,我们将cfuse与Fid提取的身份特征vid连接起来,Fid是一种预训练的最先进的人脸识别模型[Curricularface],并获得最终的矢量vsid,称为3D形状感知身份。因此,HifiFace可以很好地获得包括几何结构在内的身份信息,这有助于保持源图像的人脸形状。
语义面部融合模块
特征级
底层特征包含丰富的空间信息和纹理细节,可以显著帮助生成更逼真的结果。在这里,我们提出的SFF模块既充分利用了底层编码器和解码器的特性,又克服了由于目标图像身份信息在底层特征中而伤害身份的问题。
当解码器特征zdec的大小为目标的1/4时,我们首先预测掩码Mlow。然后用Mlow混合zdec得到zfuse,公式为:
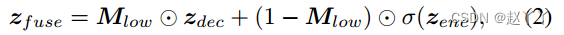
其中,zenc表示原始大小1/4的底层编码器特征,σ表示res-block。
SFF的关键设计是调整编码器和解码器的注意力,这有助于理清身份和属性。具体来说,非面部区域的解码器特征可能会被插入的源的身份信息所破坏,因此我们用干净的底层编码器特征来替换它,以避免潜在的危害。而人脸区域解码器特征由于包含丰富的源人脸身份信息,不应受到目标人脸的干扰,因此我们保留了人脸区域的解码器特征。
在特征级融合后,我们生成Ilow来计算辅助损失,以便更好地分离身份和属性。然后,我们使用包含多个res-block的4×上采样模块Fup来更好地融合特征映射。基于Fup,我们的HifiFace可以方便地生成更高分辨率的结果(例如512 × 512)。
图像级
脸型变化会带来伪影,因此使用SFF来学习轻微扩张的掩膜,并接受脸型的变化。具体来说,我们预测了一个3通道的Iout和1通道的Mr,并通过Mr将Iout与目标图像混合,公式为:
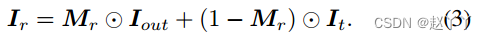
综上所述,在SFF模块的帮助下,HifiFace可以生成具有高图像质量的逼真效果,并且可以很好地保留光照和遮挡。请注意,尽管脸型发生了变化,但这些能力仍然有效,因为掩膜已经扩大,我们的SFF受益于在预测的面部轮廓周围进行绘制。
损失函数
3D形状感知身份(SID)损失
SID损失包括形状损失和ID损失。我们使用二维地标关键点作为几何监督来约束人脸形状(约束生成人脸像源),这在三维人脸重建中被广泛使用。首先利用网格渲染器根据源图像的身份系数和目标图像的表情和姿态系数生成三维人脸模型。然后,通过回归3DMM系数,生成Ir和Ilow的三维人脸模型。最后将重建的人脸形状的三维人脸地标顶点投影到图像上,得到地标qfuse、qr和qlow。
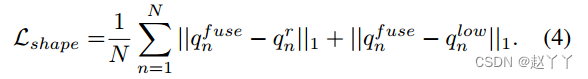
此外,我们使用身份损失来保持源图像的身份:
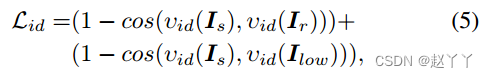
其中,id表示由Fid生成的单位向量,cos(;)表示两个向量的余弦相似度。最后,我们的SID损失公式为:
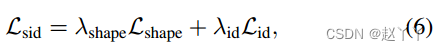
λid = 5 and λshape = 0.5
真实感损失
包括分割损失、重建损失、周期损失、感知损失和对抗损失。具体来说,SFF模块中的Mlow和Mr都在SOTA人脸分割网络HRNet的指导下。我们对目标图像的掩模进行了扩展,消除了人脸变化的限制,得到了Mtar。
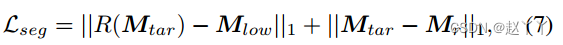
R(.)表示大小调整操作。
如果Is和It具有相同的身份,则预测的图像应该与它相同。所以我们使用重建损失来进行像素级监督:
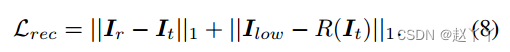
循环过程也可以在换脸任务中进行。设Ir为重目标图像,原目标图像为重源图像。周期损失是像素监督的补充,可以帮助生成高保真的结果:
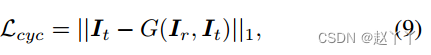
G表示HifiFace的整个生成器
为了捕捉细节并进一步提高真实感,使用了感知图像Patch Similarity (LPIPS) loss。
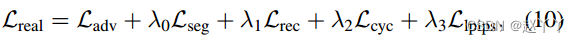
λ0 = 100, λ1 = 20, λ2 = 1 and λ3 = 5
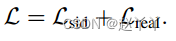
实验
实验细节
选择VGGFace2和asia - celeb作为训练集。对于分辨率为256的模型,我们删除尺寸小于256的图像以获得更好的图像质量。对于每张图像,使用5个地标对齐面部并裁剪到256×256,其中包含整个面部和一些背景区域。对于512,采用了肖像增强网络将训练图像的分辨率提高到512×512作为监督,相比于256增加了一个res-block在SFF的Fup中。具有相同身份的训练对的比例为50%。采用ADAM, β1 = 0;β2 = 0.99,学习率= 0.0001。该模型使用4个V100 gpu和32个批处理大小,以200K步进行训练。
定性对比

FSGAN与目标人脸具有相同的脸型,但也不能很好地传递目标图像的光照。SimSwap算法使用了特征匹配损失,更多地关注属性,不能很好地保持源图像的身份,特别是对于脸型。FaceShifter表现出强烈的身份保留能力,但它有两个局限性:(1)属性恢复,而我们的HifiFace可以很好地保留人脸颜色、表情、遮挡等所有属性。(2)两阶段复杂框架,HifiFace端到端框架更优雅,复原效果更好。

AOT是专门为克服光照问题而设计的,但在身份相似性和保真度方面较弱。DF减少了风格不匹配的不良情况,但身份相似度也较弱。HifiFace不仅完美地保留了光线和面部风格,而且很好地捕捉了源图像的面部形状,并生成了高质量的交换脸。
定量对比
指标:ID检索、姿势误差、脸型误差和面部伪造检测算法的性能,对于FaceSwap和FaceShifter,我们均匀地从每个视频中采样10帧,并组成一个10K的测试集。对于SimSwap和HifiFace,我们使用上面相同的源和目标对生成人脸交换结果。
HifiFace获得了最好的ID检索分数,并且在姿态保存方面与其他方法相当,对于脸型误差,使用另一种3D人脸重建模型[Learning to regress 3d face shape and expression from an image without 3d supervision]对每个测试人脸的系数进行回归。通过交换后的人脸与其源人脸之间的L2距离来计算误差,我们的HifiFace实现了最低的人脸形状误差。参数和速度的比较也显示在表1中,我们的HifiFace比FaceShifter更快,并且具有更高的生成质量。
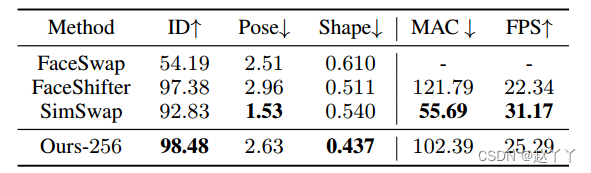
为了进一步说明HifiFace控制脸型的能力,可视化了HifiFace和FaceShifter之间的样本形状差异。
在200对形状差异较大的FF++对中,Ir和Is的脸型误差。根据HifiFace的形状误差对样本进行分类。相同的列索引表示相同的源/目标对。结果表明,当源和目标的面部形状差异较大时,HifiFace显著优于facshifter, 95%的样本的形状误差较小。
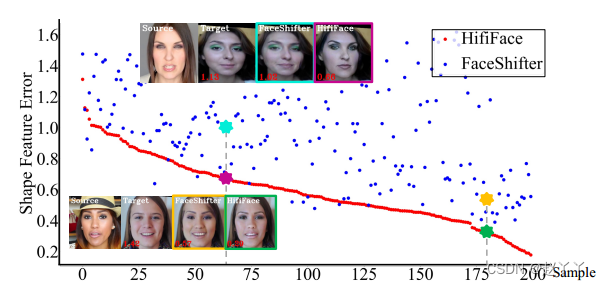
此外,我们还应用了来自FF++和DFDC的模型来检验HifiFace的伪造能力。
对于每种方法,测试集包含10K个交换的人脸和10K个来自FF++的真实人脸。HifiFace得分最高,保真度更高,有助于进一步改进人脸伪造检测。
分析Hififace
3D形状感知身份

为了验证形状监督Lshape对面部形状的有效性,我们训练了另一个模型ours-n3d,该模型将形状感知的身份向量替换为Fid中的标准的身份向量。our-n3d的结果几乎不会改变脸型,也不会有明显的伪影,而our -256的结果可以生成更接近脸型的结果。
语义面部融合
为了验证SFF模块的必要性,我们对比了3个基线模型:(1)去除特征级和图像级融合的“Bare”。(2)去除特征级融合的“Blend”。(3)用concatenate替换特征级融合的“Concat”。

“Bare”不能很好地保留背景和遮挡,“Blend”缺乏易读性,“Concat”的身份相似度较弱,这证明了SFF模块可以在不损害身份的情况下保留属性,提高图像质量。
人脸交换中的脸型保持
不仅由于难以获得形状信息,而且当面部形状发生变化时,喷漆也是一个挑战。混合是一种有效的保护遮挡和背景的方法,但在人脸形状发生变化时很难应用。

“Blend-T”、“Blend-DT”、“Blend-R”分别表示通过目标的掩模、目标的扩张掩模和bare结果的掩模将bare结果混合到目标图像。
当源脸比目标脸(第1行)胖时,可能会限制Blend-T中脸型的变化。如果我们使用Blend-DT或Blend-R,它不能很好地处理遮挡。
当源面比目标面细(第2行)时,在Blend-T和Blend-DT中很容易在面周围产生伪影,并且可能导致Blend-R中的双面。相比之下,我们的HifiFace可以在没有上述问题的情况下应用混合,因为我们的SFF模块有能力对预测蒙版的边缘进行涂漆。
为了进一步说明SFF如何解决这个问题,我们展示了SFF模块中每个阶段的差异特征映射,称为SFF-0 ~ 3,在(Is,It)和(It,It)的输入之间,其中(Is,It)获得our -256, (It,It)实现目标本身。
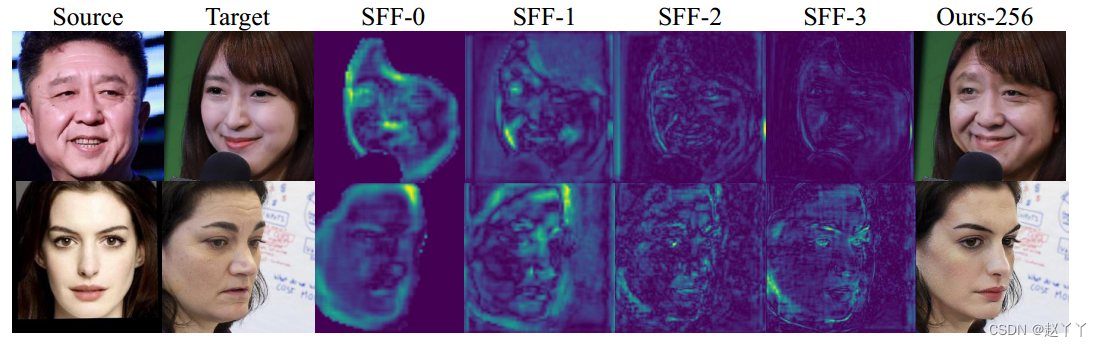
明亮区域表示脸型变化或包含伪影的地方。SFF模块将人脸区域和非人脸区域之间的特征重新组合,更加关注预测掩模的轮廓,这对形状变化区域的涂漆有很大的好处。
网络结构
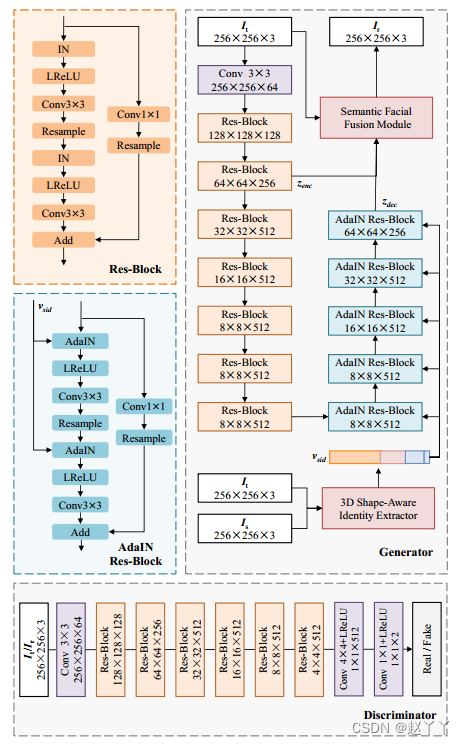
Resample是指平均池化(Average Pooling)或上采样(Upsampling),用于改变特征映射的大小。
编码器使用带有实例规范化(IN)的res - block,解码器使用带有自适应实例规范化(AdaIN)的res - block。
为了分析来自三维人脸重建模型的形状信息和来自人脸识别模型的身份信息的具体影响,我们调整了SID的组成来生成插值结果。
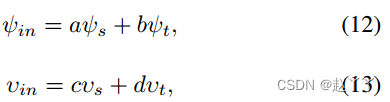
表示源、目标、插值图像的三维身份系数
表示识别模型中源、目标、插值图像的身份向量
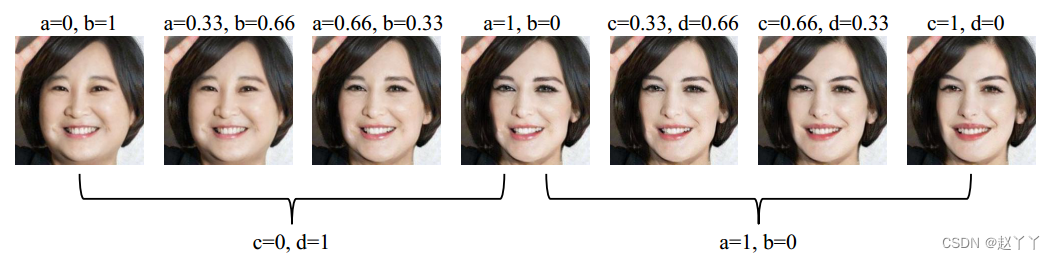
首先固定c = 0和d = 1,脸型仍然可以改变,但缺乏身份细节。固定a = 1和b = 0,身份变得更加相似。结果表明,形状信息控制着形状和身份的基础,而身份向量有助于识别纹理。

