
- 1DataCanvas会员中心正式上线,这些新春福利请接住!
- 2计算机科学与技术专业毕业设计最新最全选题精华汇总-持续更新中_计算机科学与技术毕业设计选题
- 3系统集成的2种方式_a系统集成到b系统,谁提供接口
- 4基于SSM的红色文化展示小程序系统设计与实现【包调试】_红色展示系统
- 5k8s教程----零基础快速入门
- 6【SLAM随手记】ROS中编译ORB-SLAM2出错及解决方案:[rosrun] Couldn't find executable named Mono_[rosbuild] rospack found package "orb_slam2" at ""
- 7解决虚拟机无法联网_博途16虚拟机 不连网
- 8(C/C++)STL函数(3)二分算法题以及二分模板 和(蓝桥杯)递推与递归题目及解法(ACwing)_c语言实现stl分解
- 9java Maven连接mysql_java maven mysql
- 10从零开始理解Hugging Face中的Tokenization类_tokenizer.unk_token
美团发布VisionLLaMA,为视觉生成和理解提供新基线
赞
踩
在人工智能领域,统一的模型架构对于简化模型设计、提高模型效率以及促进跨领域应用具有重要意义。近年来,大语言模型(Large Language Models, LLMs)在处理文本输入方面取得了显著的进展,其中基于变换器(Transformer)架构的LLaMA模型家族在众多开源实现中脱颖而出。然而,一个引人关注的问题是,这些为文本输入设计的变换器是否同样适用于处理二维图像?
对此,本研究提出了一个类似于LLaMA的视觉变换器——VisionLLaMA,它以平面(plain)和金字塔(pyramid)形式出现,专为视觉任务量身定制。VisionLLaMA是一个统一且通用的模型框架,适用于解决大多数视觉任务。通过典型的预训练范式对其有效性进行了广泛评估,并在图像感知和尤其是图像生成的下游任务中取得了显著成果。在许多情况下,VisionLLaMA在性能上超越了先前的最先进视觉变换器。相信VisionLLaMA可以作为视觉生成和理解的强大新基线模型。
论文标题:VisionLLaMA: A Unified LLaMA Interface for Vision Tasks
论文链接:https://arxiv.org/pdf/2403.00522.pdf
VisionLLaMA模型:从LLaMA到视觉的转变
1. VisionLLaMA的设计理念
VisionLLaMA模型的设计理念源自于LLaMA模型,LLaMA模型是一种基于transformer架构的大语言模型,它在文本输入处理方面表现出色。研究者们提出了一个问题:能否使用相同的transformer架构来处理2D图像?VisionLLaMA模型正是为了回答这个问题而设计的,它是一种类似于LLaMA的视觉transformer,旨在减少语言和视觉之间的架构差异。VisionLLaMA模型是一个统一和通用的建模框架,适用于解决大多数视觉任务。
2. VisionLLaMA的架构特点
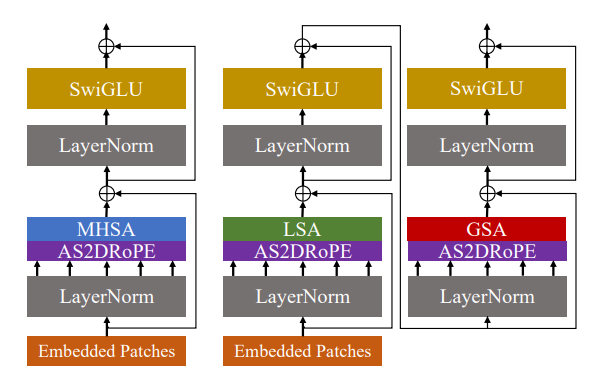
VisionLLaMA的架构特点包括两种形式:平面形式和金字塔形式。在平面形式中,VisionLLaMA遵循ViT的流程,尽可能保留LLaMA的架构设计。在金字塔形式中,VisionLLaMA适用于基于窗口的transformer,如Swin和Twins,它们使用相对位置编码。VisionLLaMA在这些架构中的应用通过最小化对架构和超参数的修改来实现。
VisionLLaMA在图像理解任务中的应用
1. 图像分类
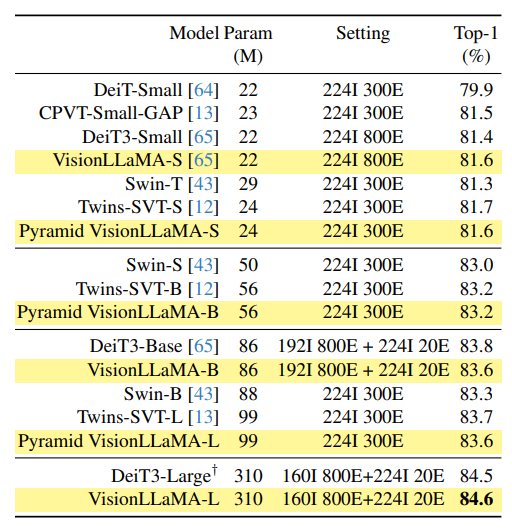
在图像分类任务中,VisionLLaMA通过监督学习和自监督学习的方式在ImageNet-1K数据集上进行训练。在监督学习中,VisionLLaMA与DeiT3等先进的平面视觉transformer进行比较,展示了与DeiT3相当的性能。在自监督学习中,VisionLLaMA使用MAE框架,并在不同的预训练长度下取得了优于ViT模型的性能。
2. 语义分割
在ADE20K数据集上的语义分割任务中,VisionLLaMA作为UperNet框架的骨干网络,与Swin和Twins等模型进行了比较。结果显示,VisionLLaMA在相似的FLOPs下,其性能超过了Swin和Twins超过1.2%的mIoU。
3. 目标检测
在COCO数据集上的目标检测任务中,VisionLLaMA作为Mask R-CNN框架的骨干网络,展示了优于Swin和Twins的性能。此外,VisionLLaMA在ViTDet框架下,使用平面视觉transformer取得了与金字塔对应模型相当的性能。
VisionLLaMA在图像生成任务中的应用
1. DiT框架下的图像生成
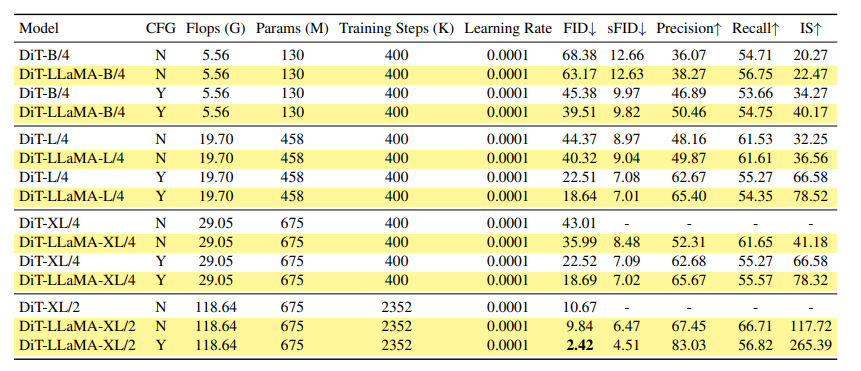
VisionLLaMA在DiT框架下的图像生成任务中展现出了显著的性能。通过将DiT框架中原有的视觉变换器替换为VisionLLaMA,同时保持其他组件不变,这一受控实验展示了VisionLLaMA在图像生成任务上的通用性。在这一过程中,原始的超参数保持不变,尽管这可能不是实现最佳性能的最优选择。使用预训练的VAE模型,以及分类器自由引导系数为1.5,图像的训练分辨率为256×256。在不同模型尺寸下,VisionLLaMA在多项指标上显著优于DiT,包括FID、sFID、Precision/Recall和Inception Score。此外,VisionLLaMA不仅计算效率更高,而且性能也超过了DiT。
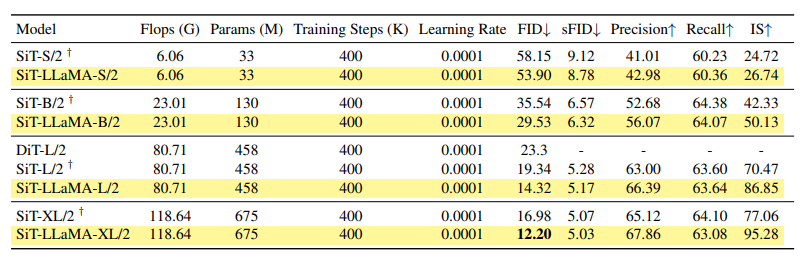
2. SiT框架下的图像生成
SiT框架提供了灵活的漂移和扩散系数选择,通过最近提出的插值框架得到支持,显著提高了使用视觉变换器的图像生成性能。在SiT框架中,将视觉变换器替换为VisionLLaMA,用于评估更优模型架构的好处,称为SiT-LLaMA。实现基于SiT的开源代码,通过精心控制的实验进行评估。所有模型均使用相同步数进行训练,并使用线性插值和速度模型。为了公平比较,还重新运行了发布的代码,并报告了使用250步SDE采样器采样的50k 256×256图像的结果。SiT-LLaMA在不同容量级别的模型上一致性能优于SiT。
VisionLLaMA的位置编码策略
1. 从1D RoPE到2D RoPE的扩展
在视觉任务中处理不同输入分辨率是一个常见的需求。与大多数视觉变换器采用局部窗口操作或插值不同,VisionLLaMA扩展了1D RoPE到2D形式,2D RoPE在不同头之间共享。在金字塔设置下的GSA中,需要特殊处理以添加位置信息到总结键中,这些键是通过对特征图的抽象生成的。

2. AS2DRoPE的自适应位置编码
位置插值帮助2D RoPE更好地泛化。受到使用插值扩展LLaMA上下文窗口的启发,涉及更高分辨率类似于扩展VisionLLaMA的2D上下文窗口。与语言任务不同,视觉任务如目标检测通常在不同迭代中处理不同的采样分辨率。在224×224的输入分辨率下训练小型模型,并在不重新训练的情况下评估更大分辨率的性能,这指导了应用插值或外推的良好策略。因此,基于“锚分辨率”应用自动缩放插值(即AS2DRoPE)。假设处理H×H的正方形图像,并且在训练期间使用B×B的锚分辨率,我们计算可以高效实现且不引入额外成本的AS2DRoPE。如果训练分辨率保持不变,AS2DRoPE退化为2D RoPE。
实验结果与分析
1. VisionLLaMA与现有模型的性能比较
VisionLLaMA在多个视觉任务中与现有模型进行了比较。在图像生成任务中,使用DiT框架的VisionLLaMA在不同模型大小下均显著优于DiT模型。例如,DiT-LLaMA-XL/2的FID比DiT-XL/2低0.83,表明VisionLLaMA在计算效率和性能上均优于DiT。在SiT框架下,SiT-LLaMA在各种容量级别的模型中一致超越了SiT,例如SiT-LLaMA-L/2的FID比SiT-L/2低5.0,这一改进幅度甚至超过了新框架的引入(4.0 FID)。
在ImageNet-1K数据集上的分类任务中,VisionLLaMA在监督训练下与DeiT3相比,在不同的模型大小上表现相当。在不同分辨率下的性能评估中,VisionLLaMA在更高分辨率下的泛化能力更强,这对于许多下游任务(如对象检测)至关重要。
2. VisionLLaMA的收敛速度和性能优势
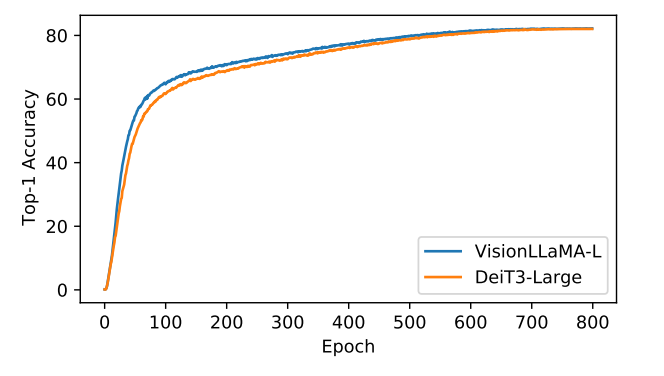
VisionLLaMA在多个实验中显示出更快的收敛速度。在图像生成任务中,VisionLLaMA在300k训练迭代后的性能甚至超过了基线模型在400k步骤后的性能。在DeiT3-Large的监督训练设置中,VisionLLaMA的收敛速度也快于DeiT3-L。此外,在MAE框架下,VisionLLaMA在训练初期的损失较低,并且趋势持续到训练结束
VisionLLaMA的优势与挑战
1. 模型的通用性与适应性
VisionLLaMA作为一个统一的视觉建模框架,能够解决大多数视觉任务。它在图像理解和生成任务中表现出色,并且在不同分辨率下具有良好的泛化能力。它的设计旨在减少语言和视觉之间的架构差异,使得同一架构可以处理文本和图像输入。
2. 模型在不同任务中的表现
在不同的视觉任务中,VisionLLaMA均展现出了优异的性能。在图像生成、分类、语义分割和对象检测任务中,VisionLLaMA均能达到或超越现有最先进模型的性能。这些结果表明,VisionLLaMA不仅在特定任务上有效,而且具有广泛的适用性和潜力。
VisionLLaMA未来发展方向及潜在影响
VisionLLaMA代表了对大语言模型(LLaMA)架构在视觉任务中应用的一次重要尝试。通过对LLaMA架构的适应性改进,VisionLLaMA不仅在图像理解和生成任务中展现出了显著的性能提升,而且还为未来的研究和应用提供了新的方向。以下是VisionLLaMA未来发展的几个关键方向及其潜在影响:
1. 架构的统一与优化: VisionLLaMA的提出,意味着语言和视觉模型可以共享统一的架构,这有助于简化模型部署和加速模型推理。未来,可以预见到更多的研究将致力于进一步优化这一统一架构,使其在不同的视觉任务中都能达到最优性能。
2. 多模态学习的深入: VisionLLaMA的成功实践为多模态学习提供了新的可能性。未来,研究者可能会探索如何将VisionLLaMA与其他模态的模型结合,例如音频和视频,以实现更加全面的多模态理解和生成。
3. 高效的预训练和微调策略: VisionLLaMA在预训练和微调方面展现出了高效性,这为大规模模型的训练提供了新的思路。未来的研究可能会探索更加节省资源的训练方法,以减少计算成本和环境影响。
4. 新的应用场景: VisionLLaMA在图像生成、分类、语义分割和目标检测等任务中的表现,预示着它在医学图像分析、无人驾驶、安全监控等领域具有广泛的应用前景。随着模型性能的不断提升,VisionLLaMA可能会在这些领域中扮演更加重要的角色。
5. 开源社区的贡献与发展: VisionLLaMA的开源实现鼓励了更广泛的社区参与和贡献。这种开放的研究态度有助于加速技术的创新和发展,同时也为研究者和开发者提供了更多的合作机会。
6. 持续的性能提升: VisionLLaMA在多个基准测试中已经超越了现有的状态艺术模型。随着研究的深入,可以期待VisionLLaMA在未来能够解决更加复杂的视觉任务,并在性能上达到新的高度。
总体而言,VisionLLaMA不仅为视觉任务的处理提供了一个强大的新基线模型,而且其统一的建模框架和在多个下游任务中的有效性,都预示着它将对未来的视觉任务处理产生深远的影响。随着技术的不断进步和社区的共同努力,VisionLLaMA有潜力成为推动视觉和多模态领域发展的关键力量。


