
- 1SpringBoot中 Cannot find method ‘value‘报错解决_cannot find method 'value
- 2hive中dense_rank&row_number&rank函数_dense_number
- 3CSS3——flex布局_css flex布局换行50%
- 4企业DevOps探讨:“谁构建、谁运行”原则的理论基础_谁构建谁允许
- 5latex表格 分行 跨行跨列_latex中的tabular*单元格内公式分行
- 6【Mybatis代码生成器Mybatis-Generator】_mybatis generator在线生成
- 7【Testops学习积累之二】Jenkins Pipeline中Git打包、Sonar扫描静态代码实践操作过程记录_pipeline 里需要写git检出吗
- 8基于Redis的分布式限流详解_redis限流
- 9.net类库获取当前类库的配置(dll的app.config读写)_dll app.config 文件如何获取内容
- 10Linux基线检查与安全加固_linux系统查询密码策略口令csdn
【论文阅读】FedSage:Subgraph federated learning with missing neighbor generation
赞
踩
一、介绍
随着图越来越大,子图通常被单独收集并存储在多个局部系统中,其中每个局部系统都持有一个可能偏离整个图分布的小子图。因此,子图联邦学习旨在训练一个强大且可推广的图挖掘模型,且无需直接共享图数据。
挑战1:如何从多个局部子图中进行联邦学习?在我们考虑的情况下,全局图被分布成一组具有异构特征和结构分布的小子图。在每个子图上训练一个单独的图挖掘模型可能无法捕捉到全局的数据分布,也容易造成过拟合。
解决方案1:FedSage。使用FedAvg训练GraphSage。
挑战2:如何处理局部子图直接的缺失链接?图中的数据样本是连接和相关的。在子图联邦学习系统中,每个子图中的数据样本可能与其他子图中的数据样本有连接。这些连接携带着节点邻域的重要信息,并作为数据所有者之间的桥梁,然而,这些连接从未被任何数据所有者直接捕获。
解决方案2:FedSage+:沿着FedSage生成缺失的邻居。对于每个数据所有者,通过随机排除一些节点和相关链接得到缺失子图,然后根据排除的邻居来训练生成器,使其能够生成子图内潜在的缺失链接。并在子图FL设置中进一步训练生成器,使其能够生成分布式子图中的缺失邻居。然后数据持有者修复生成的交叉子图缺少邻居的子图,然后在修复的子图上应用FedSage。
二、FedSage
2.1、分布在局部系统中的子图
全局图表示为 G={V,E,X},中央服务器 S,客户端数量 M。数据所有者 拥有的子图
。
为了模拟具有大多数缺失连接的场景,假设数据所有者之间没有共享的重叠节点。因此,对于一条边 ,其中
,即
可能存在于现实中,但不存储在系统中。在典型的GNN中,预测节点的标签需要查询节点的ego-graph。对于图 G 中的一个节点 v ,我们用 G(v) 表示 v 的 ego-graph。
该系统利用FL框架在没有原始图数据共享的情况下,在所有数据所有者中的孤立子图上进行协作学习,以获得全局节点分类器 F。F中的可学习权重 是按照从全局图 G 中抽取的分布对被查询的ego-graph进行优化的。 我们把这个问题形式化为寻找
,使聚合风险最小。
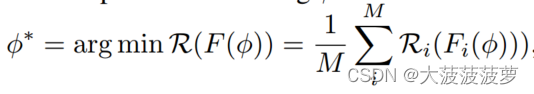
其中, 是局部经验风险,定义为:
![]()
其中, 是特定于任务的损失函数:
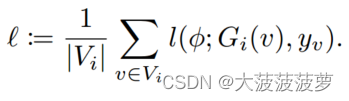
2.2、孤立子图上的协作学习
使用FedAvg框架训练GraphSage模型。
在子图 上,对于特征
的节点 v ,在每一层
(K为GraphSage模型测层数),F 计算 v 的表示:
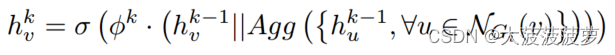
其中 是图
上节点 v 的邻居的集合,|| 为concatenation operation(concat 维度拼接),Agg(·) 是聚合器(例如,平均池化), σ 是激活函数(例如relu)。
对于节点 ,F输出推理标签
,监督损失函数定义为:
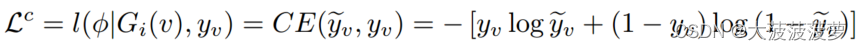
其中 CE(·) 是交叉熵损失函数,是节点v在
上的 K 跳 ego-graph,他包含节点 v 及其在
上的K跳邻居的信息。
每个客户端在本地训练一个由 参数化的本地节点分类器。中央服务器 S 收集
并对其求平均。然后 S 向数据所有者广播
并完成一轮训练 F。F 作为全局分类器。
三、FedSage+
3.1、缺失邻居生成器(NeighGen)
NeighGen的神经结构:由编码器 和生成器
组成,如下图:
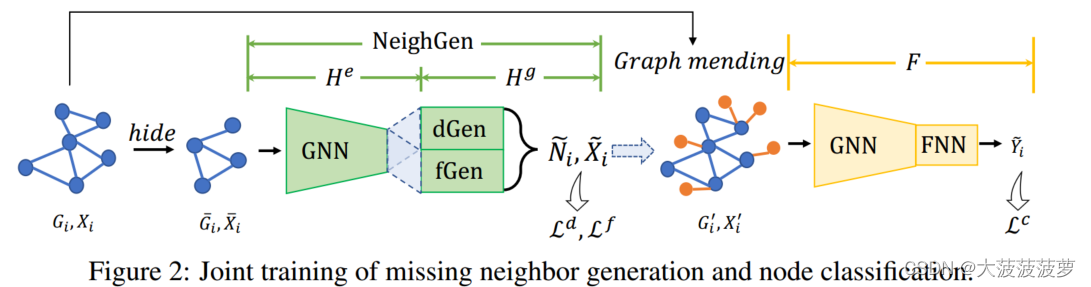
:由参数为
的具有K层的GraphSage模型组成。
:一种基于节点嵌入的生成模型,用于恢复输入图的缺失邻居,包含dGen和fGen。dGen 是由
参数化的线性回归模型,用于预测缺失邻居的数量
。fGen 是由
参数化的特征生成器,用于生成一组
个特征向量
。dGen 和 fGen 都被构造为全连接神经网络,fGen还配备了生成
维噪声向量的高斯噪声生成器 N(0, 1) 和随机采样器R。对于节点
,fGen是变分的,它在嵌入
中插入噪声后生成 v 的缺失邻居的特征,而 R 通过从特征生成器的输出中采样
特征向量来确保 fGen 输出特定数量邻居的特征。从数学上讲,我们有:
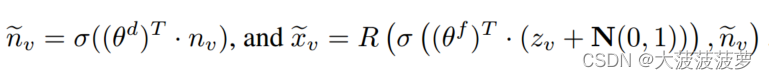
图形修补模拟:对于系统中每个数据所有者,假设只有一组特定的节点具有交叉子图缺失的邻居。具体来说,在每个局部子图 中,随机取出其节点
的h%以及涉及它们的所有连接
,以形成受损子图,表示为
。
基于缺失节点 和连接
,NeighGen在受损图
上的训练可以归结为联合训练 dGen 和fGen,如下所示:
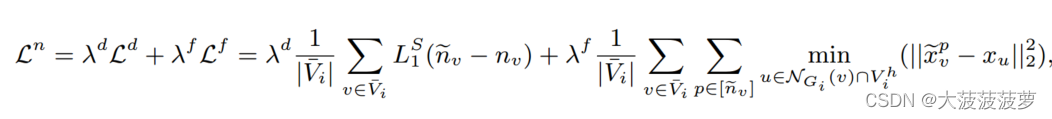
其中是 smooth L1距离,
是
中的第p个预测特征。
邻居世代:为了从 中检索
,数据所有者
执行两个步骤。1、
在受损图
上训练NeighGen,并对ground-true 隐藏邻居
进行训练;2、
利用NeighGen为
上的节点生成缺失邻居,然后用生成的邻居将
修正到
中。仅就局部图
而言,这个过程可以被理解为数据增强,进一步生成
内潜在的缺失邻居。然而,实际的目标是让NeighGen生成跨子图的缺失邻居,这可以通过用FL训练NeighGen来实现。
3.2、GraphSage和NeighGen的本地联合训练
定义GraphSage和NeighGen在局部图上的集成叫做LocSage+。在NeighGen将 修正成
后,GraphSage分类器F被应用于
。因此,NeighGen和GraphSage的联合训练是通过优化以下损失函数完成的:
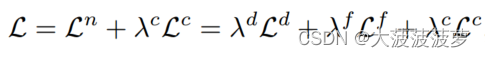
GraphSage和NeighGen的本地联合训练允许NeighGen在本地的图中生成缺失的邻居,这对GraphSage所做的分类有帮助。然而,像GraphSage一样,本地NeighGen中编码的信息仅限于并偏向于本地的图,这使得它无法真正生成属于由缺失的交叉子图链接连接的其他数据所有者的邻居。为此,需要使用FL来训练NeighGen。
3.3、GraphSage和NeighGen的联邦学习
在整个系统中直接平均的权重可能会对其性能产生负面影响,即平均单个
模型的权重并不能真正允许它从不同的子图生成不同的邻居。我们不训练单个集中式的NeighGen,二十为每个数据所有者
训练一个本地
。在
中添加交叉子图特征重建损失,如下:
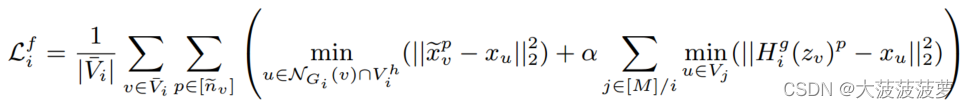
其中 被选为除
之外的
的最近节点,以模拟遗漏到
中的
的邻居。
然而 中的节点特征无法传输到
中。因此,为了让
使用上述公式更新NeighGeni而不是直接访问
的特征
,对于
,
本地计算
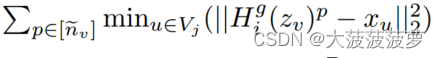 并将各自的梯度送回给
并将各自的梯度送回给 。在次过程中,只有 1:
;2:
的输入
和
的局部计算损失项的模型梯度通过服务器 S 在系统之间进行传输。对于数据所有者
,使用 α 对从
接收到的梯度进行加权,并将其与上述特征重建损失中的局部梯度相结合,以更新NeighGen的参数
。
四、实验
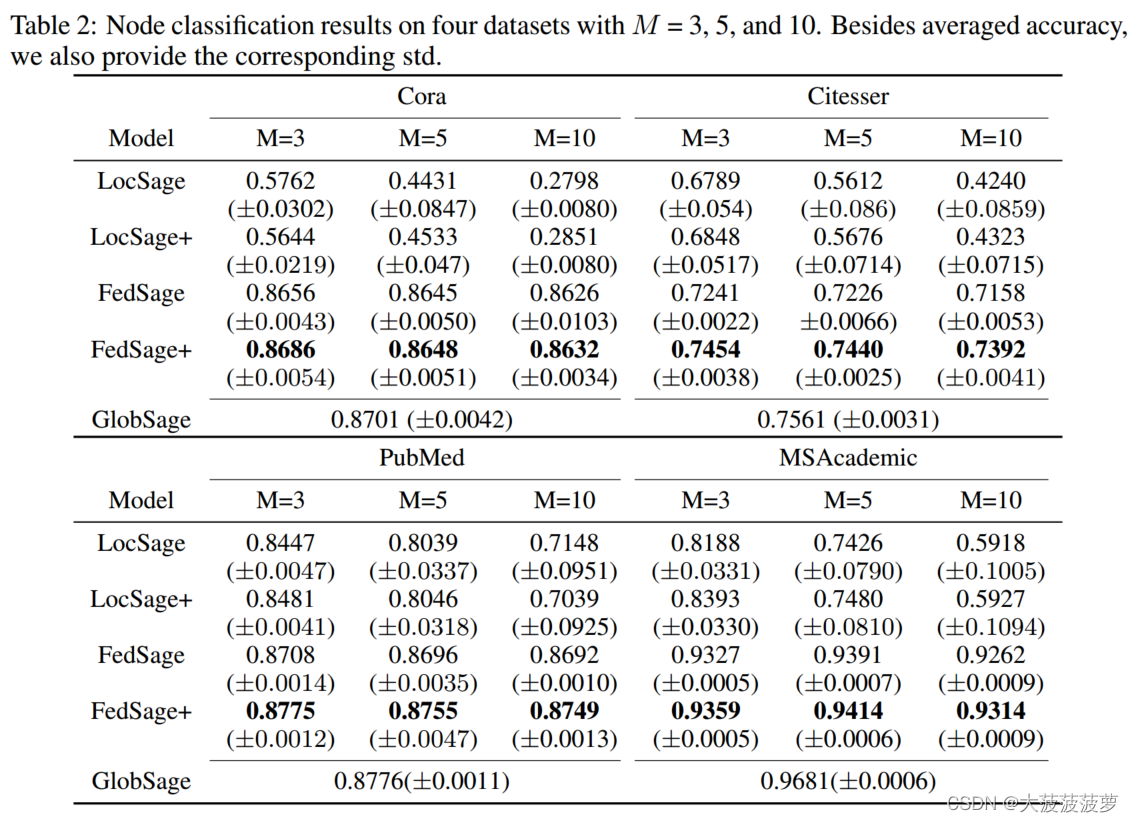
数据集:Cora、Citeseer、PubMed、MSAcademic。
客户端构造:使用Louvain算法在每个数据集上找到层次图聚类,并使用具有3个、5个和10个相似大小聚类的聚类结果来获得数据所有者的子图。
GraphSage设置:均值聚合器;层数为2;每层中采样节点数为5;批大小64;训练周期50。
对比方法:1)GlobSage:在原始全局图上训练的GraphSage模型,没有缺失链接。2)LocSage:在每个子图上单独训练一个GraphSage模型。3)LocSage+:GraphSage加NeighGen模型仅在每个子图上联合训练。
消融实验:
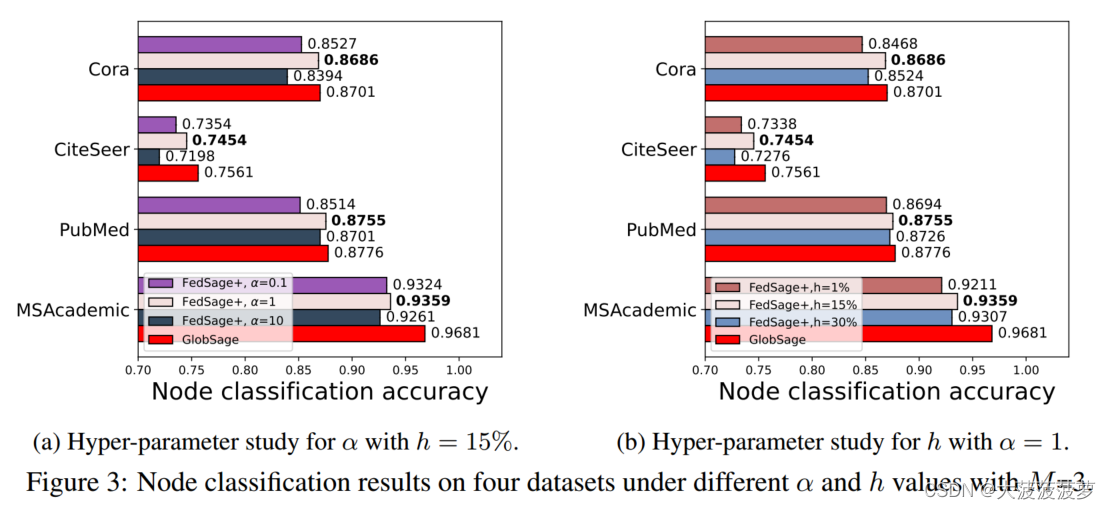
超参数研究:比较了三个数据所有者在不同 α 和 h% 的下游任务性能。
案例分析:
1)为PubMed上的五个数据所有者设置20%的具有相当有偏差的标签分布节点,且本文提出的FL模型在学习更真实的标签分布方面表现出了优势。
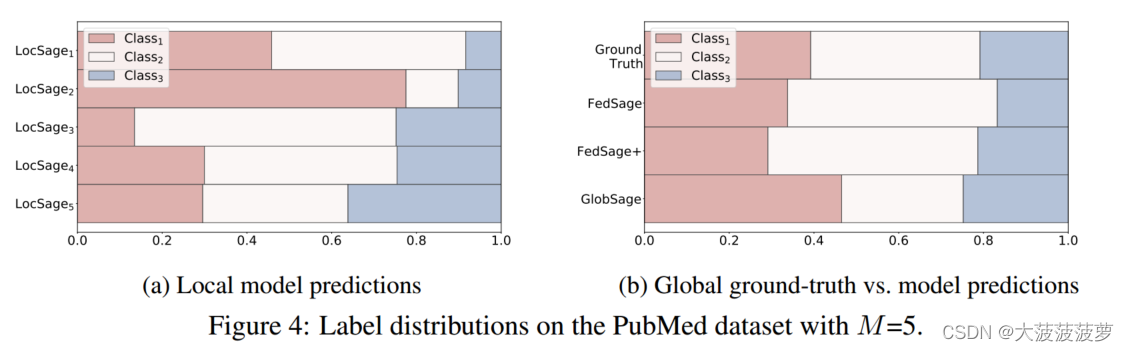
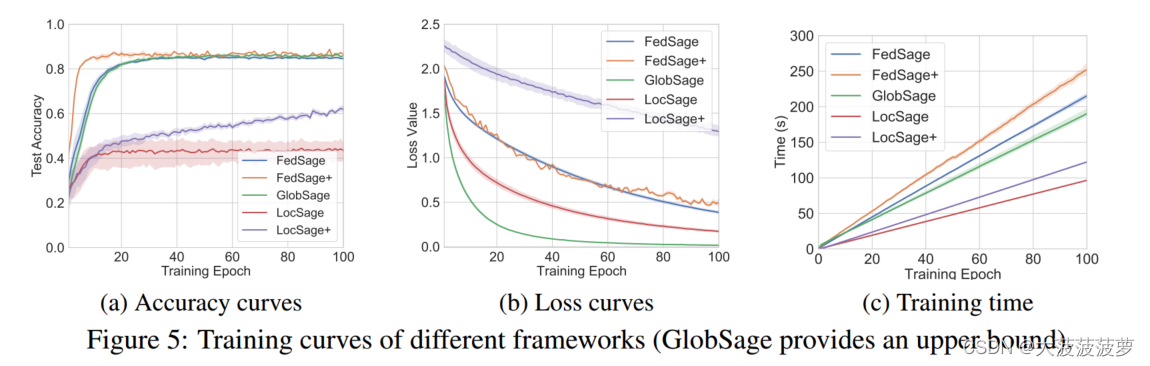
2)对于具有五个数据所有者的Core数据集,可视化了100个周期的测试准确性、损失收敛性和运行时间。
五、结论
优势:通过设计缺失邻居生成器,解决了交叉子图链接缺失的问题。
劣势:客户端通过服务器传输邻居的累积特征及模型梯度,会产生大量额外的通信成本和潜在隐私问题。有待解决。
参考文献:Zhang K, Yang C, Li X, et al. Subgraph federated learning with missing neighbor generation[J]. Advances in Neural Information Processing Systems, 2021, 34: 6671-6682.

