
- 1第八篇【传奇开心果短博文系列】鸿蒙开发技术点案例示例:酷炫简单的ArkUI 动画和过渡效果_arkui lineargradient
- 2【鸿蒙开发】音频格式的转换
- 3Android.bp语法和使用,源码编译比平台低版本的sdk编译apk_.bp文件
- 4鸿蒙和安卓实际体验,鸿蒙2.0,你收到推送了么?告诉你实际体验!
- 5如何确保JDK版本与操作系统架构匹配?
- 6php登录接口开发文档,登录接口 - 阿里TV开放平台文档 - php中文网手册
- 7最常见的8个Android内存泄漏问题及解决方法_android 内存泄漏的场景和解决办法
- 8一个简单的Vue2例子讲明白拖拽drag、移入dragover、放下drop的触发机制先后顺序
- 9c++学习——(4)构造函数初始化列表以及拷贝构造函数_在初始化列表中未调用拷贝构造函数
- 10Android 系统架构_android系统架构
Vitis-AI量化编译YOLOv5(Pytorch框架)并部署ZCU104(二)_xmodel部署到开发板
赞
踩
系列文章目录
第一章 Vitis-AI量化编译YOLOv5(Pytorch框架)并部署ZCU104(一)
第二章 Vitis-AI量化编译YOLOv5(Pytorch框架)并部署ZCU104(二)
目录
前言
第一章已经详细介绍了在主机利用Vitis-Ai进行量化编译后,成功生成了.Xmodel文件,本章主要介绍如何将.Xmodel部署到ZCU104,并利用C++ API进行目标检测。
一、Netron查看网络结构
Netron是一种用于神经网络、深度学习和机器学习模型的可视化工具,它可以为模型的架构生成具有描述性的可视化(descriptive visualization)。
使用这一工具好处在于不需要下载,在线导入即可立即生成模型结构。(Netron 在线工具)
将生成的.Xmodel导入后,可以看到会生成如下可视化网络结构。(部分结构,全部结构太大了,自己去寻找自己所需要的部分即可)
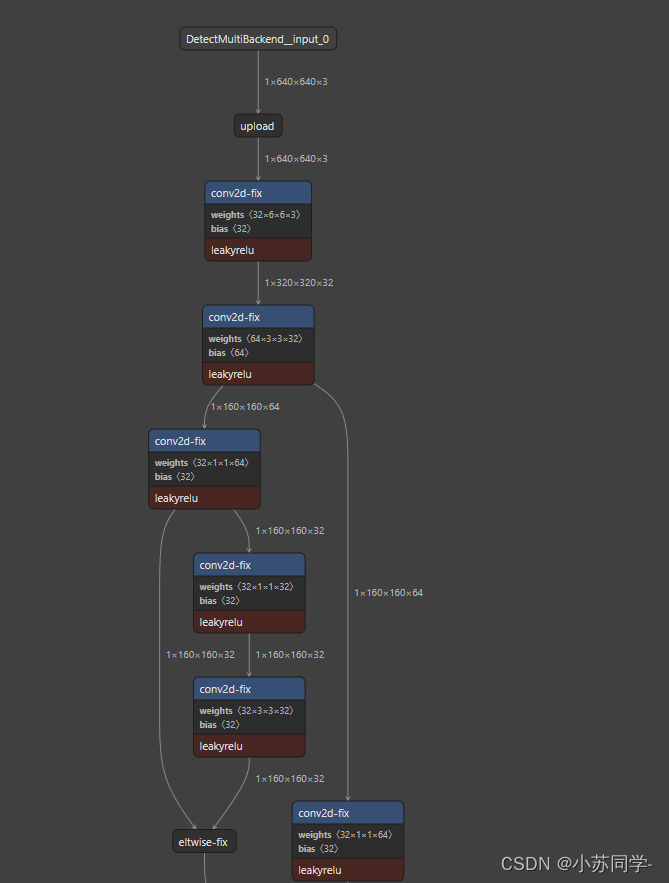
双击每一部分即可看到Input、Output具体信息。在这里主要是看输出层的名字,可以看到共有四个输出层,并且可看到这四个输出层名字。
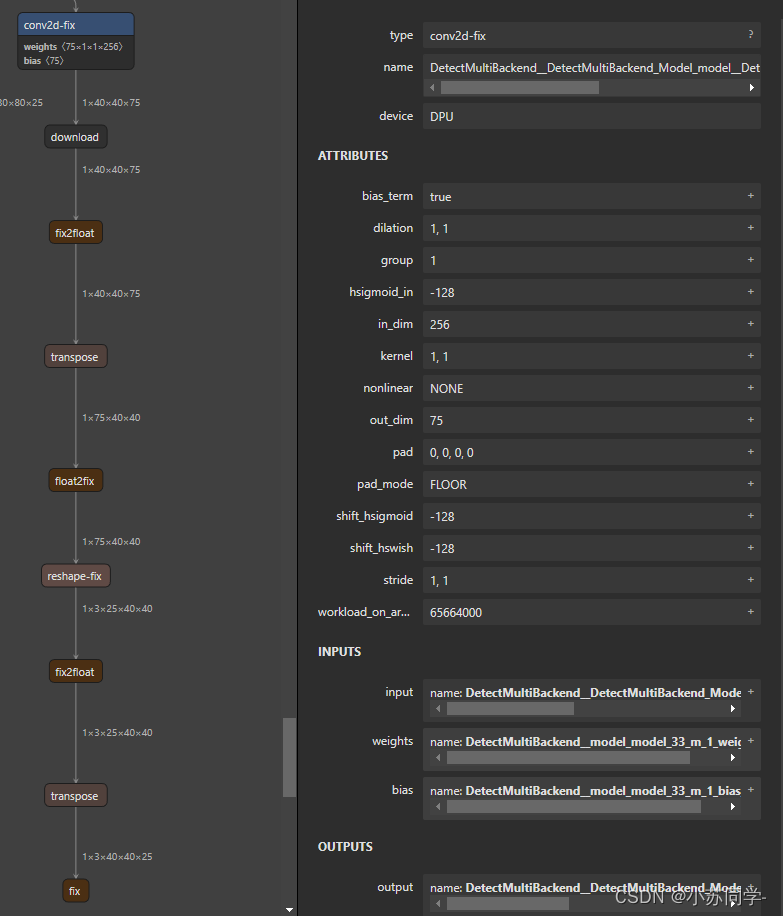
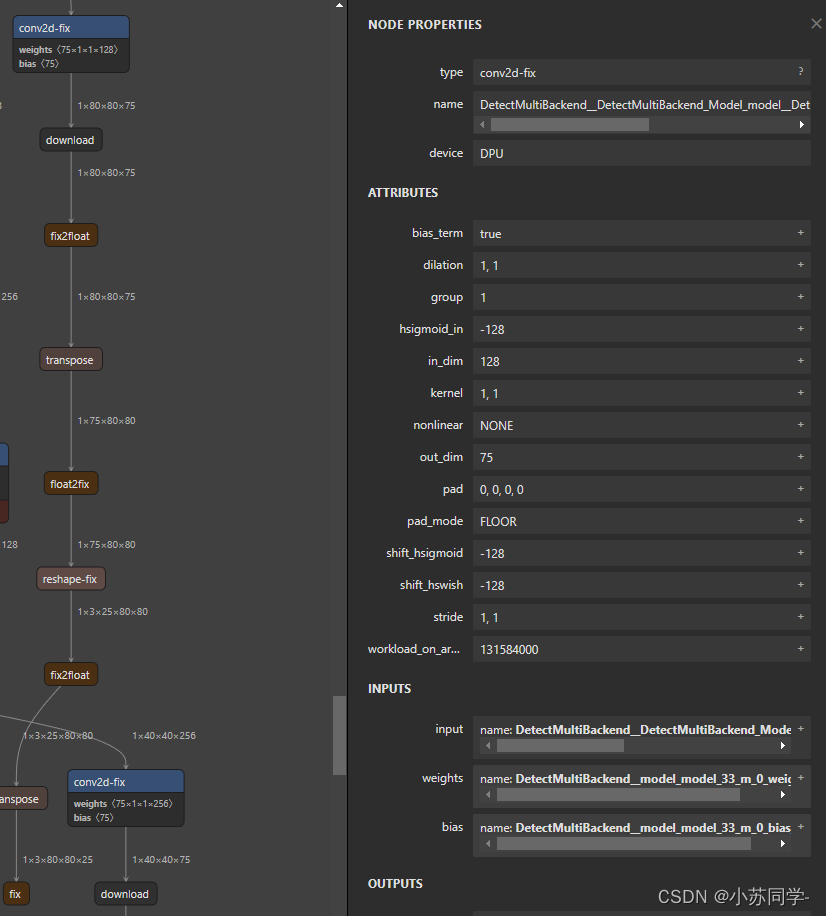
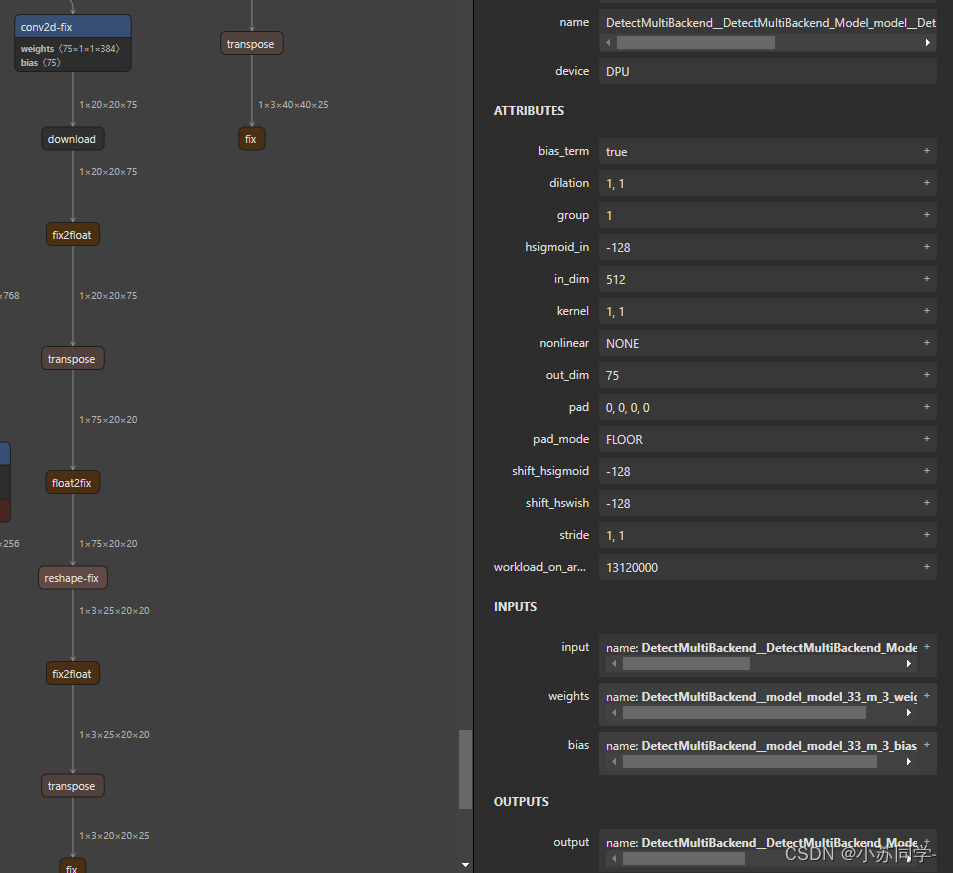
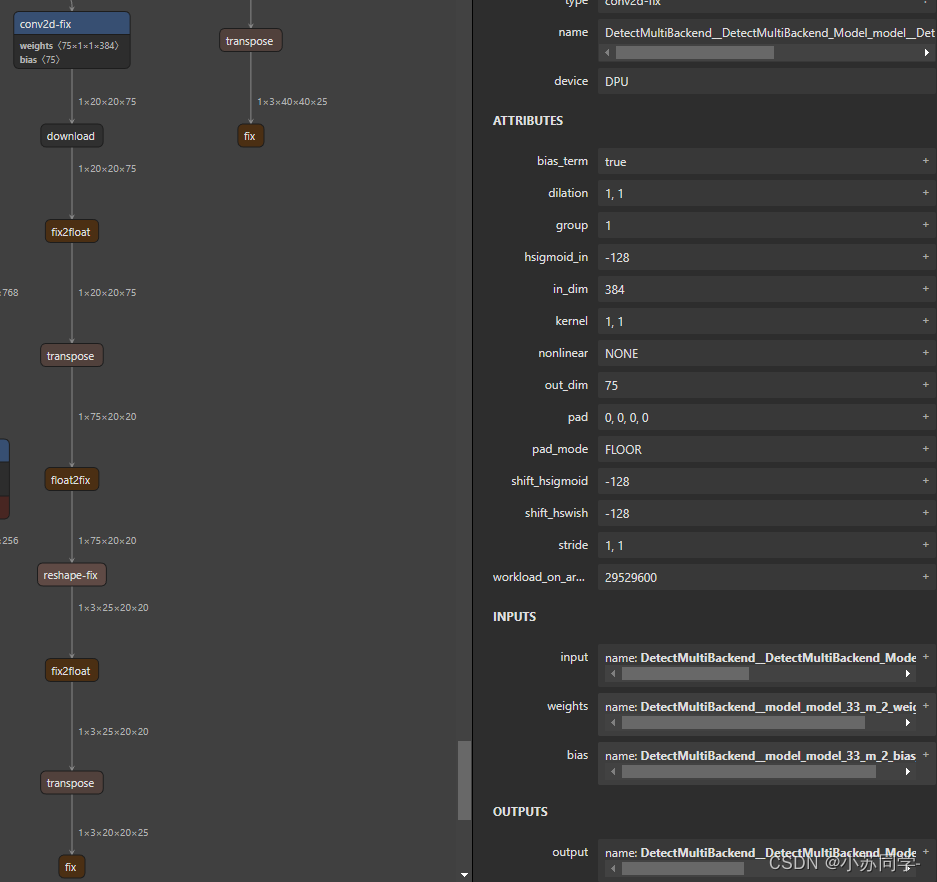
可以看到4个输出层的名字和dim。(这里有一点,dim应该为128,256,512三层,但是中间多出一个输出层,dim为384,但是不影响检测,后续代码检测四层输出即可)
二、与开发板建立通信
1.设置主机
为了方便,用网线直接将板子和PC连接,接下来就是配置同一网段的问题
我在学校用的是校园网,所以为了方便之后开发板可以联网,直接将WiFi网络给以太网共享,如下图。
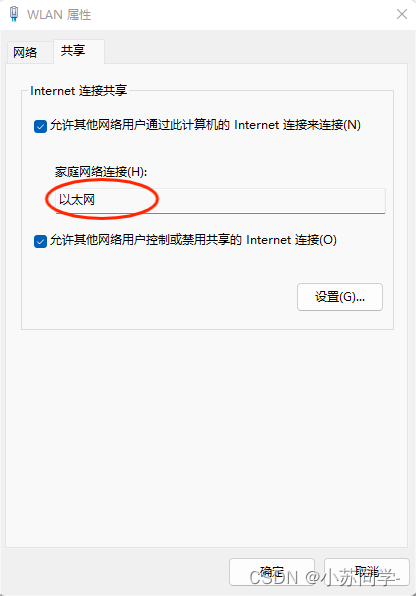
之后确认之后,以太网的IPV4地址可以自动分配,下图是我的IPV4地址。
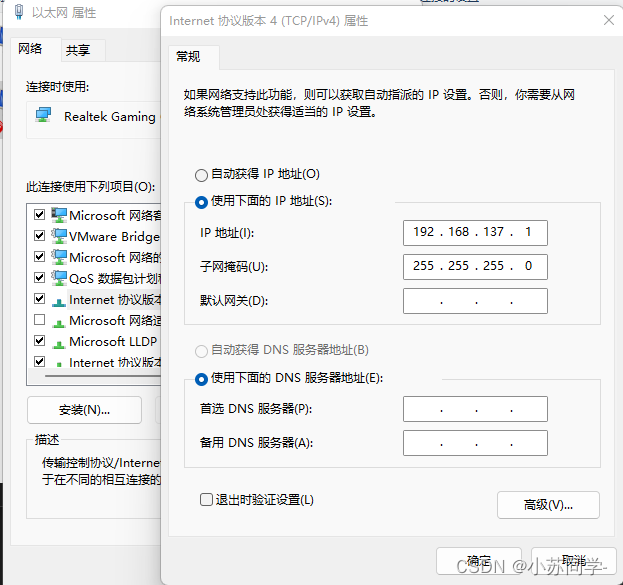
可以看到主机网段是192.168.137,所以只需要将开发板设置到同一网段即可。
2.设置开发板
我使用的是MobaXterm串口软件,首先用Serial串口软件与开发板相连接,因为使用了usb与主机相连接,具体端口查看自己的设备管理器即可。比如我的端口为COM9,如下图。
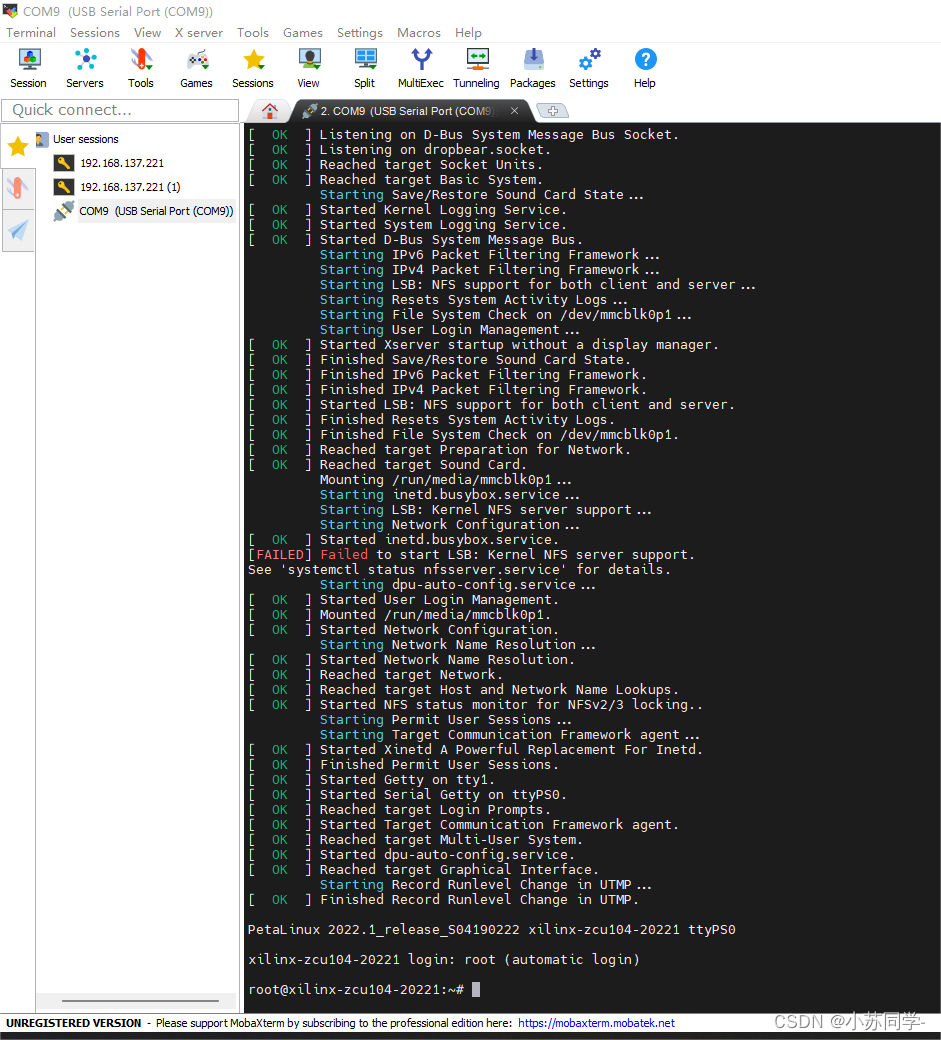
接下来将板子配置到PC同一网段(192.168.137),这里我选择将其配置为192.168.137.221.
- ifconfig //可以查看当前网络信息
- ifconfig eth0 192.168.137.221 //设置板子IP地址
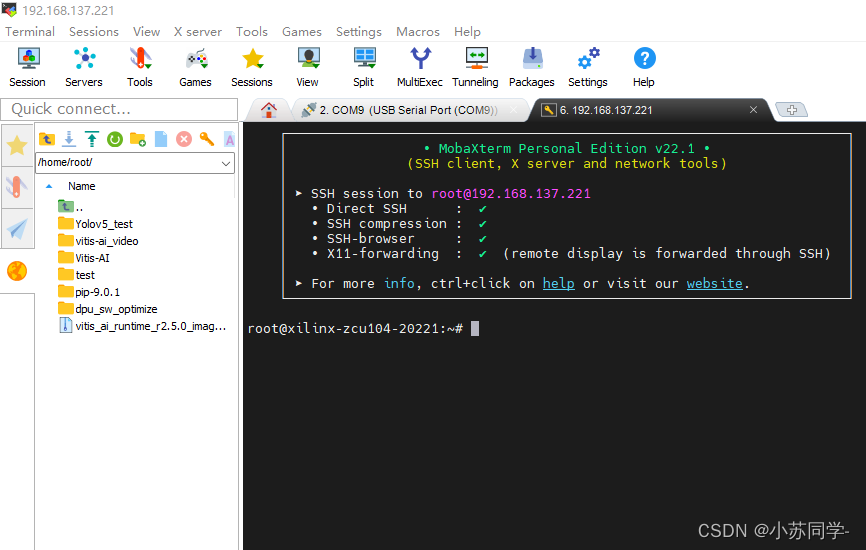
之后仍然使用MobaXterm,用ssh与板子建立远程连接,如下图。
三、C++ API编写
首先需要看手册中C++ API的函数使用。
- // create runner
- auto runner = vart::Runner::create_runner(dpu_subgraph, ”run”);
- // get input tensors
- auto input_tensors = runner->get_input_tensors();
- // get input tensor buffers
- auto input_tensor_buffers = std::vector<vart::TensorBuffer*>();
- for (auto input : input_tensors) {
- auto t = vart::alloc_cpu_flat_tensor_buffer(input);
- input_tensor_buffers.emplace_back(t.get());
- }
- // get output tensors
- auto output_tensors = runner->get_output_tensors();
- // get output tensor buffers
- auto output_tensor_buffers = std::vector< vart::TensorBuffer*>();
- for (auto output : output _tensors) {
- auto t = vart::alloc_cpu_flat_tensor_buffer(output);
- output_tensor_buffers.emplace_back(t.get());
- }
- // sync input tensor buffers
- for (auto& input : input_tensor_buffers) {
- input->sync_for_write(0, input->get_tensor()->get_data_size() /
- input->get_tensor()->get_shape()[0]);
- }
- // run runner
- auto v = runner->execute_async(input_tensor_buffers, output_tensor_buffers);
- auto status = runner->wait((int)v.first, 1000000000);
- // sync output tensor buffers
- for (auto& output : output_tensor_buffers) {
- output->sync_for_read(0, output->get_tensor()->get_data_size() /
- output->get_tensor()->get_shape()[0]);
- }

可以看到create 、get input 、get output等API的写法,DPU使用4个runner,代码如下:
- auto graph = xir::Graph::deserialize(argv[2]);
- auto subgraph = get_dpu_subgraph(graph.get());
- CHECK_EQ(subgraph.size(), 1u)
- << "yolov3 should have one and only one dpu subgraph.";
- LOG(INFO) << "create running for subgraph: " << subgraph[0]->get_name();
-
- auto runner = vart::Runner::create_runner(subgraph[0], "run");
- auto runner1 = vart::Runner::create_runner(subgraph[0], "run");
- auto runner2 = vart::Runner::create_runner(subgraph[0], "run");
- auto runner3 = vart::Runner::create_runner(subgraph[0], "run");
- //auto runner4 = vart::Runner::create_runner(subgraph[0], "run");
- // get in/out tenosrs
- auto inputTensors = runner->get_input_tensors();
- auto outputTensors = runner->get_output_tensors();
- int inputCnt = inputTensors.size();
- int outputCnt = outputTensors.size();
- // init the shape info
- TensorShape inshapes[inputCnt];
- TensorShape outshapes[outputCnt];
- shapes.inTensorList = inshapes;
- shapes.outTensorList = outshapes;
- getTensorShape(runner.get(), &shapes, inputCnt,
- //{"layer81", "layer93", "layer105", "layer117"});
- //{"DetectMultiBackend__DetectMultiBackend_Model_model__Detect_model__Detect_24__Conv2d_m__ModuleList_0__9160", "DetectMultiBackend__DetectMultiBackend_Model_model__Detect_model__Detect_24__Conv2d_m__ModuleList_1__9207", "DetectMultiBackend__DetectMultiBackend_Model_model__Detect_model__Detect_24__Conv2d_m__ModuleList_2__9254"});
- {"DetectMultiBackend__DetectMultiBackend_Model_model__Detect_model__Detect_33__Conv2d_m__ModuleList_1__12481", "DetectMultiBackend__DetectMultiBackend_Model_model__Detect_model__Detect_33__Conv2d_m__ModuleList_0__12434", "DetectMultiBackend__DetectMultiBackend_Model_model__Detect_model__Detect_33__Conv2d_m__ModuleList_2__12528","DetectMultiBackend__DetectMultiBackend_Model_model__Detect_model__Detect_33__Conv2d_m__ModuleList_3__12575"});
最后一行 getTensorShape 是我们需要得到输出张量的输出层名字,此时就需要步骤一中Netron查看结构所得到名字。
其次是Detect部分,网上现有的包括GitHub中基本上全都是用Python进行编写的,几乎没有C++,所以需要自己整理一下思路。
第一个思路:如果串行处理,也就是读取视频每一帧,送到DPU处理,再输出显示为视频。这样子可以吗?很明显有缺陷,如果读帧速度和DPU处理速度相冲突,必然会造成堵塞或进程崩溃,所以这个思路不可行。
第二个思路:串行行不通,很明显,并行是可以的。分为三个进程,第一个进程处理视频,读取每一帧并存入输入帧队列;第二个进程DPU读取输入帧队列,只要输入帧队列不空,就每次取一帧进行检测;第三个进程将DPU输出帧放入输出队列,并转换为视频进行输出。为了提供检测速率,共设置六个进程,一个进程作为输入帧队列,一个进程作为输出帧队列,其余进程用于DPU进行帧检测。
四、编译运行
因为自己制作的Linux系统没有GUI界面,所以如果直接用Serial相连,命令行运行输出展示时会报错,所以我们利用MobaXterm进行ssh连接,主要是为了利用ssh连接所提供的X11 server。可以看到,编译后运行命令:
./test video/test.webm ./yolov5.xmodel视频格式看自己的opencv库,我的opencv很奇怪,不支持mp4或avi格式,可以看到检测效果如下:
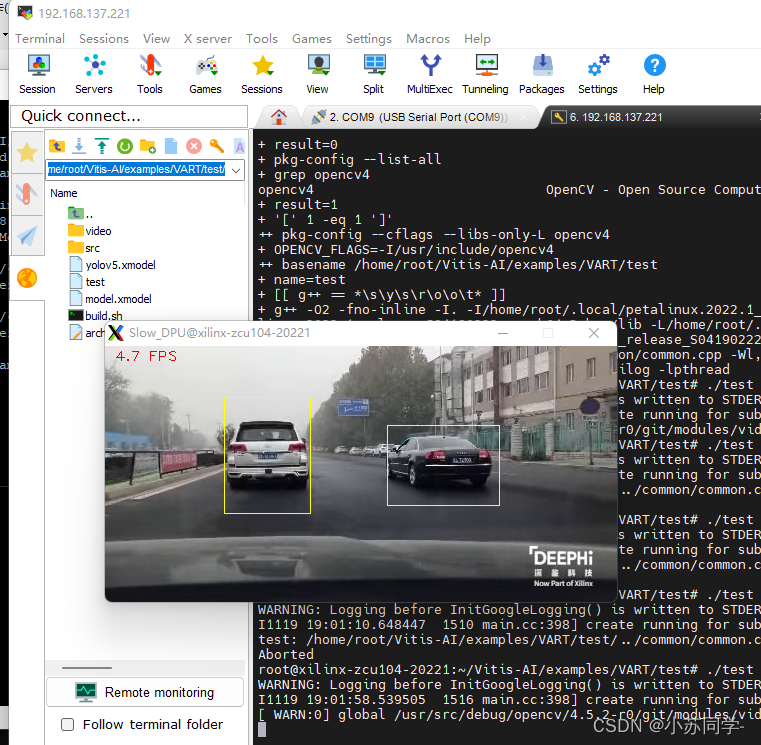
可以看到居然只有5帧左右。???很奇怪,按理说DPU会加速,怎么帧率这么低呢?分析一下原因:
1、ssh连接的问题。我们知道ssh相当于远程服务器连接,DPU推理结果最后生成的视频是由板子所产生的,而最后是在主机也就是本地展示的视频,所以相当于远程服务器推理完成后再传输至本地进行展示,会有一定的延迟,也就造成了帧率的降低。
2、mobaxterm ssh传输速率低。和第一个问题类似,主要是因为ssh传输所带来的问题。
所以根据分析尝试进行解决,两个方案:
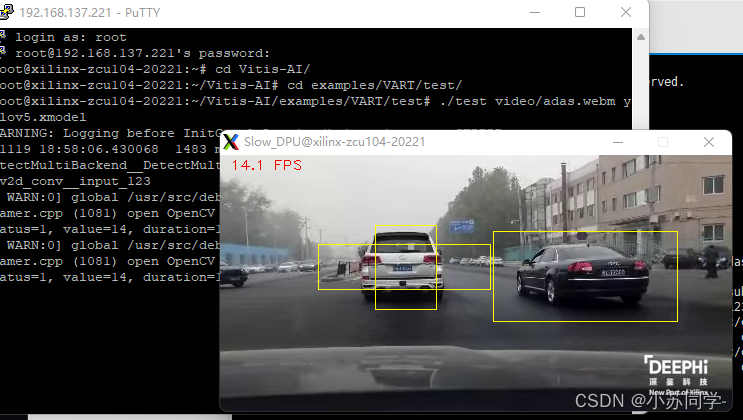
1、换用别的更好的串口软件,寻找ssh传输速率更高的方法。我又尝试了两个软件:
Xmanager:
Putty:
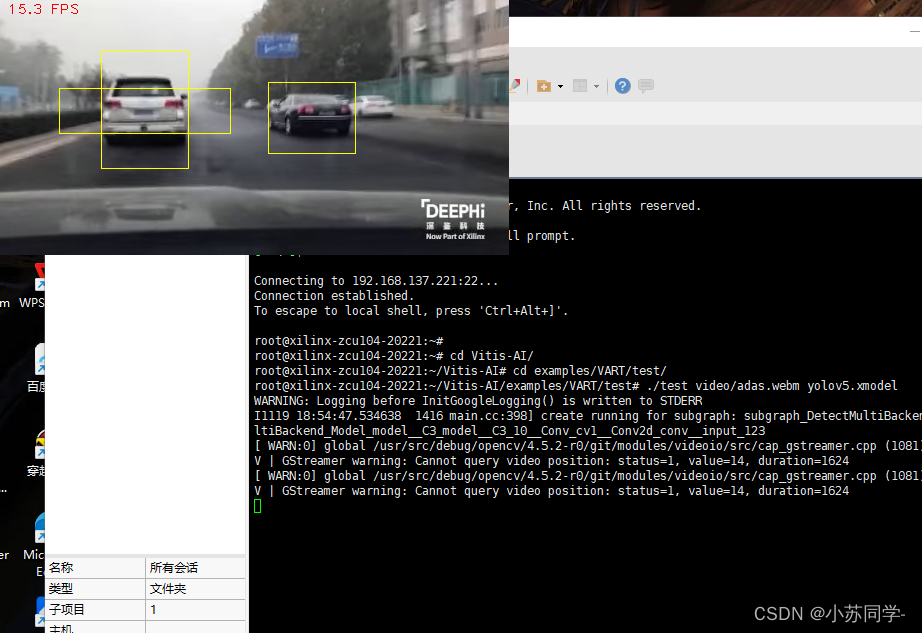
可以看到,帧率显著提高了,所以第一次帧率过低确实是ssh传输所导致。此时在分辨率为640*640的情况下,FPS可以稳定在15帧,所以大胆推测一波,若直接输出视频,帧率还会更高。
所以接下来可以改进一下代码,先不输出视频,检测完后将视频保存到本地,就不会出现传输延时的情况,之后实现后会继续更新!
总结
至此,用Vitis-AI部署的全过程就做完了,时间很仓促,前后大约只做了一周左右的时间,之前一个月从0开始做PYNQ,也算是对Xilinx的软硬件结合开发有了一定得了解。
这次DPU用的是Xilinx的小黑盒,明年要做自己编写的深度学习协处理器,并基于Risc-V进行开发,之后再更新!

