
- 1LeetCode 刷题 [C++] 第3题.无重复字符的最长子串
- 2进阶无人驾驶—Apollo控制技术详解:控制理论_apollo无人车怎么遥控
- 3jenkins与apisix整合,实现自动化部署与负载均衡、灰度发布(蓝绿发布)_apisix 灰度发布
- 4前端canvas的学习和将网页生成canvas图片
- 5有孚网络临港新片区云计算数据中心喜获ODCC设计类4A级认证_上海有孚网络临港 一期
- 6Docker相关概念与安装(Docker-CE)_dockerce和docker
- 7鸿蒙 HarmonyOS4.0 Http数据请求封装详解_鸿蒙 接口请求封装
- 8MySQL学习笔记9——binlog格式、主备基本原理、主备延迟_binlog_format=statement
- 92021-09-11_compile error: /storage/emulated/0/android/data/co
- 10VS2008常用快捷键 最全的快捷键_vs2008怎么全局查找字符
大模型AI Agent 前沿调研_基于大语言模型的ai agent可以作为学术研究方向吗
赞
踩
前言
大模型技术百花齐放,越来越多,同时大模型的落地也在紧锣密鼓的进行着,其中Agent智能体这个概念可谓是火的一滩糊涂。
今天就分享一些Agent相关的前沿研究(仅限基于大模型的AI Agent研究),包括一些论文或者框架,小伙伴可以根据自己的兴趣有选择的看一下~,其中角色扮演也可以看作Agent的一个较为火热的方向(具体的Agent就是一个具体角色),最后在文末从技术的角度整体总结一下agent的核心。
先给两个综述,大家可直接阅读,然后笔者挑一些有意思的总结一下。
温馨提示:全文较长,建议收藏,慢慢啃~
综述
A Survey on Large Language Model based Autonomous Agents
论文链接:https://arxiv.org/pdf/2308.11432.pdf
这是一篇关于agents的综述
Autonomous-Agent
github链接:https://github.com/lafmdp/Awesome-Papers-Autonomous-Agent
该git也在不断的收藏一些关于agent的前沿研究。
一些代表性的研究
(1) A Survey on Large Language Model based Autonomous Agents
论文链接:https://arxiv.org/pdf/2308.11432.pdf
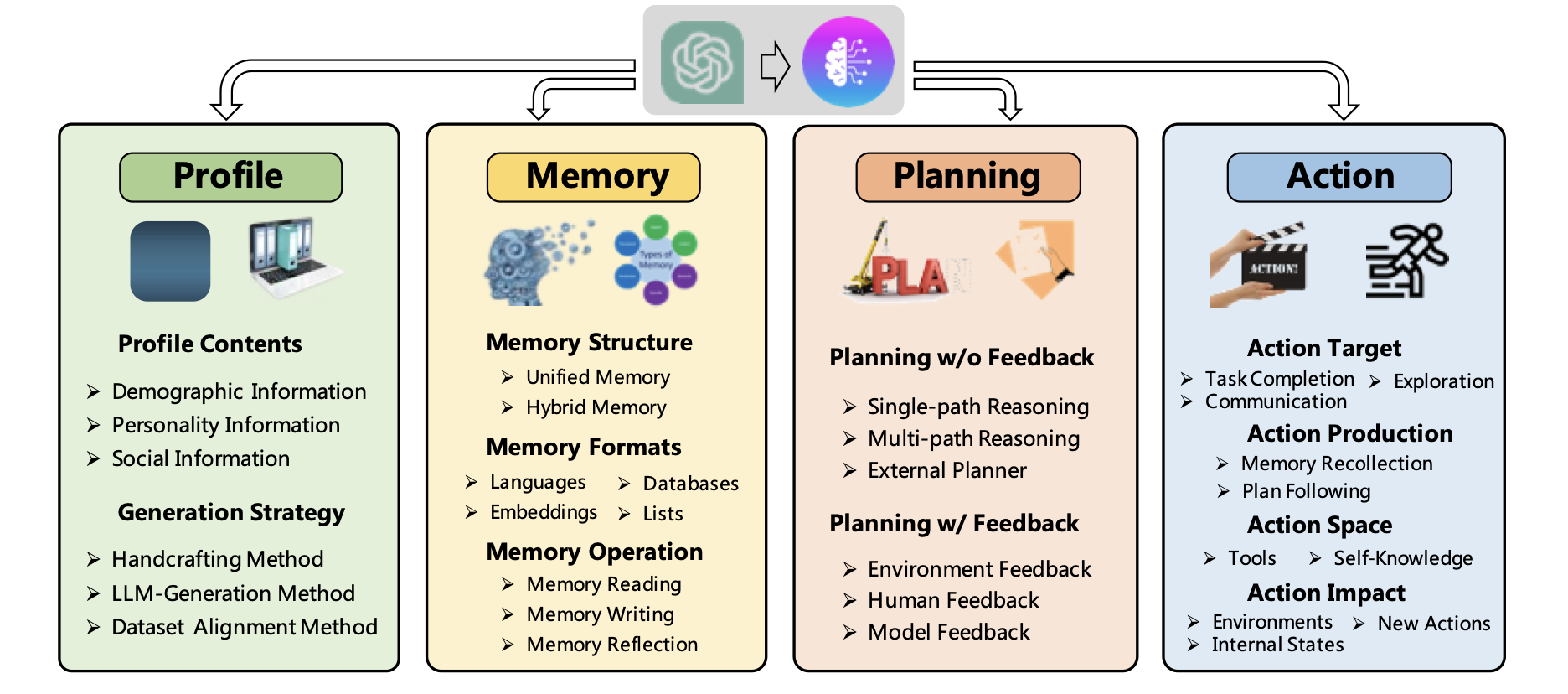
本文为基于大模型agent的构建设计了一个统一框架并给出了三种学习策略。
具体的该框架由4个模块构成(如上图):配置模块、记忆模块、规划模块和执行模块。配置模块有3种方法来生成配置文件:手工制作法、LLM生成方法、数据集对齐方法;记忆模块分为3个方面:结构、格式和操作;记忆结构包括两种:统一内存(该结构没有短期和长期记忆的区别)和混合内存(有短期和长期记忆的区别);规划模块包括没有反馈的规划和带反馈的规划;动作模块即是最终真真响应的模块。
三种学习策略分别为从例子、人类反馈和环境反馈中学习。
本篇paper很好的抽象规划了整个框架,尤其是4个模块的设计,可以借鉴一下。
(2)Improving Language Model Negotiation with Self-Play and In-Context Learning from AI Feedback
论文链接:https://arxiv.org/pdf/2305.10142.pdf

论文中的两个agent分别模拟买卖双方进行一场交易,具体就是利用两个agent来彼此不断互相对话、不断博弈,买方最终目的就是要以尽可能低的价格达成交易,而卖房则相反。其中核心技术看点就是在对话中使用一个中间agent利用cot进行反馈,告诉当前agent如何更好的回复才对自己最有利。
(3)Exploring Large Language Models for Communication Games: An Empirical Study on Werewolf
论文地址:https://arxiv.org/pdf/2309.04658.pdf
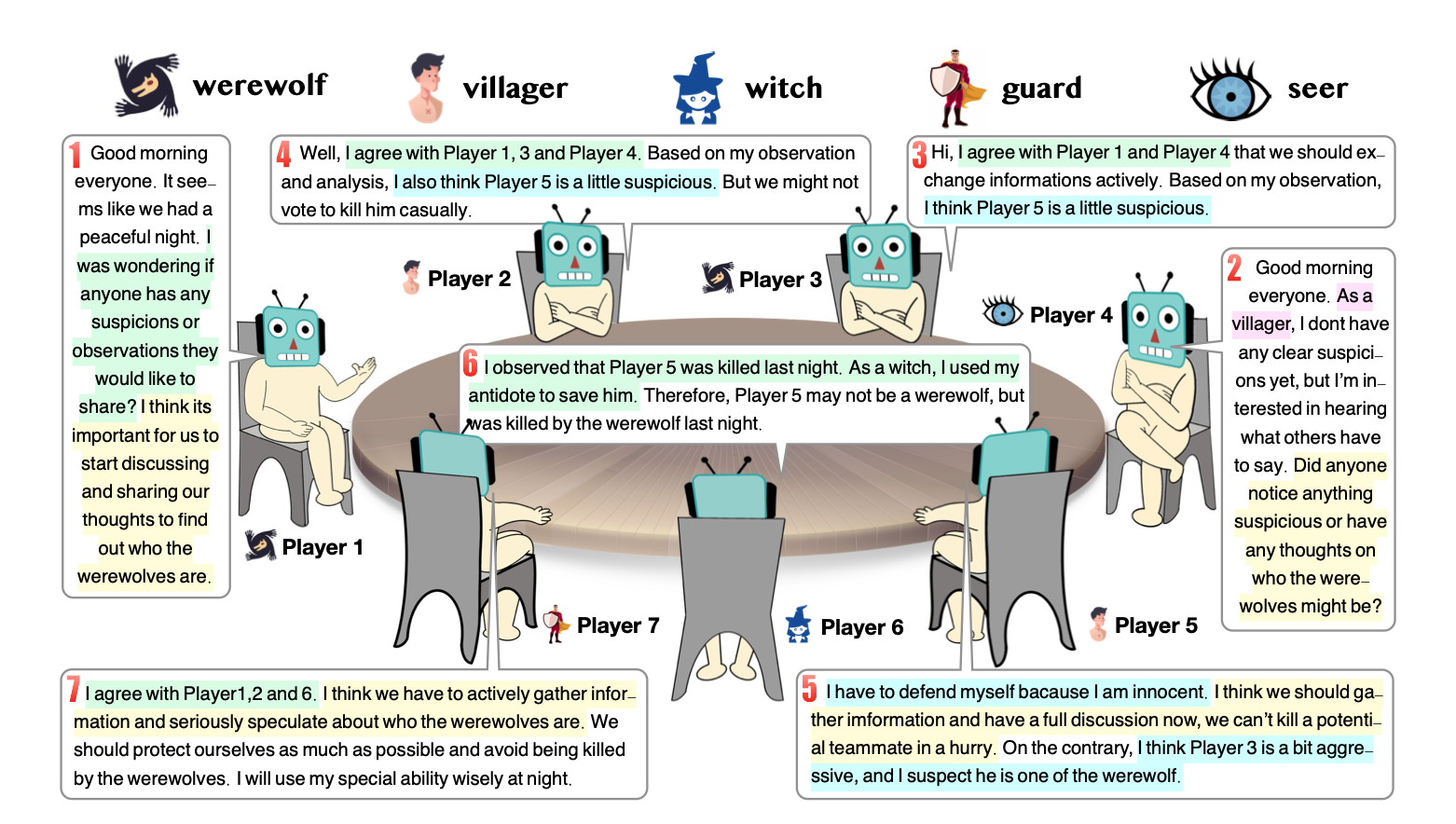
该篇论文尝试了同时启用很多的agent来互相配合完成一个更复杂的任务,具体的是使用了7个agent来完成一个狼人杀游戏,每个agent都要牢记自己的角色扮演规则。其中核心技术看点就是每个agnet都会提前定义好自己的角色定位,该规则和描述的prompt都是非常详细和具体的,同时更关键的是这些agent之间的复杂交互也即调用逻辑,其中下面就是agent角色的定义:

(4) METAGPT: META PROGRAMMING FOR A MULTI-AGENT COLLABORATIVE RAMEWORK
论文链接:https://arxiv.org/pdf/2308.00352.pdf
github: https://github.com/geekan/MetaGPT
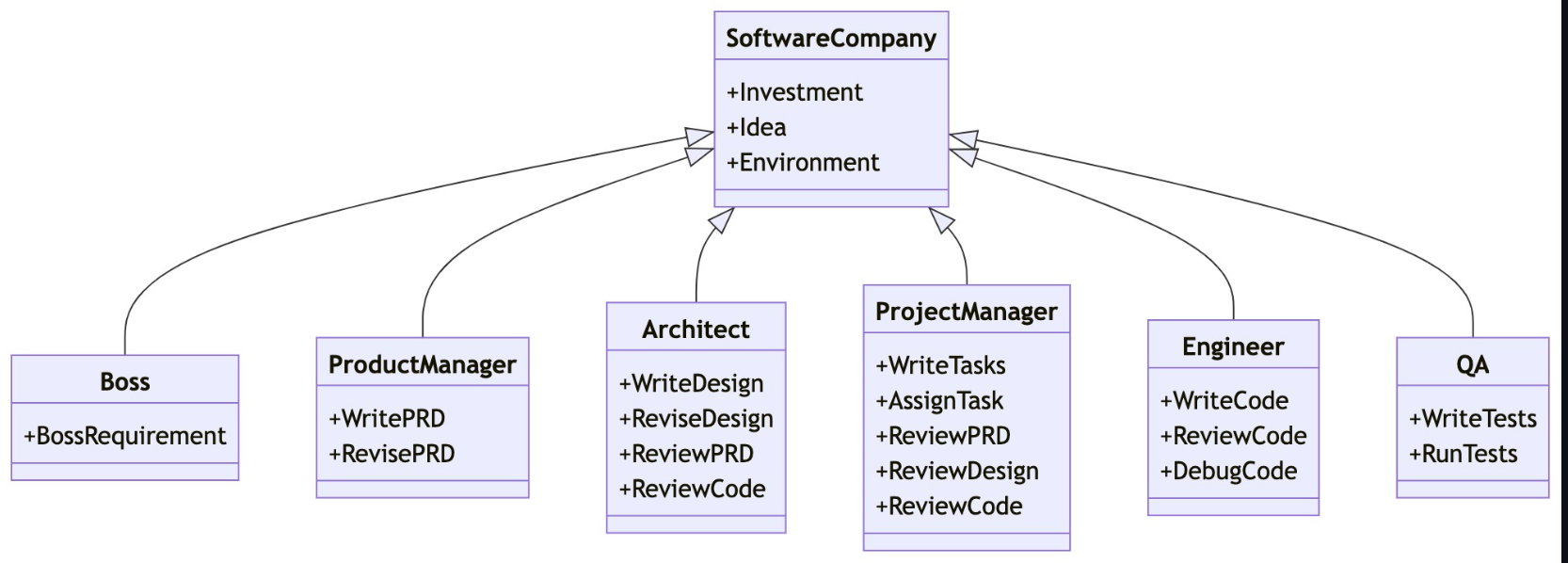
metagpt实现了一个多agent的框架,方便大家迅速落地自己的场景,目前github stars已经3w+,官方demo演示了如何自动开发一个代码需求,比如来了一个需求后,它的agent包括产品经理先分析需求,然后开发工程师开发,最后还有code review等等。同时也使用该框架实现了狼人杀。
metagpt核心技术看点就是封装好了很多agent的基础能力比如包括交互通信等等。
(5) CAMEL: Communicative Agents for “Mind” Exploration of Large Language Model Society
论文链接:https://arxiv.org/pdf/2303.17760.pdf
github: https://github.com/camel-ai/camel

camel提出的也是一种基于角色扮演来模拟多个agent交互的框架。具体的,camel重点研究任务导向的agent,其中一个是AI助手agent,另外一个是AI用户agent。
当camel收到一个具体需求和角色分配后,任务agent先提供详细描述以使这个需求更具体化,然后AI助手agent和AI用户agent会通过多轮对话一起合作来完成指定的任务。其中AI用户agent负责向AI助手agent提供指示并引导对话朝向任务完成方向进行,AI助手agent则理解AI用户agent的指示并提供具体的解决方案。
这里贴一下它的核心的agent prompt

论文中对prompt的每一条为啥要这样写都给出了理由,比如AI助手agent的prompt中有一条是“Always end your solution with: Next request”,这个是和AI用户agent要新一轮的指令,这样可以确保对话自动聊下去,这才是是非常关键的一点!!!是整个机制能自动run起来的关键。
另外作者为了自动获得对话数据,还借助大模型自动生成各种各样“AI助手agent&AI用户agent” 角色pair对,然后再为各个角色pair对生成多个相关话题,有了这些后就可以借助上面的机制进行多轮聊天。
这篇很好的实现完全自动化,无限挖掘;其中起了关键作用的就是上面这些prompt怎么写,论文都给出来了,大家感兴趣的可以去看原论文。
(6) AgentTuning: Enabling Generalized Agent Abilities for LLMs
论文地址:https://arxiv.org/abs/2310.12823
github链接:https://github.com/THUDM/AgentTuning
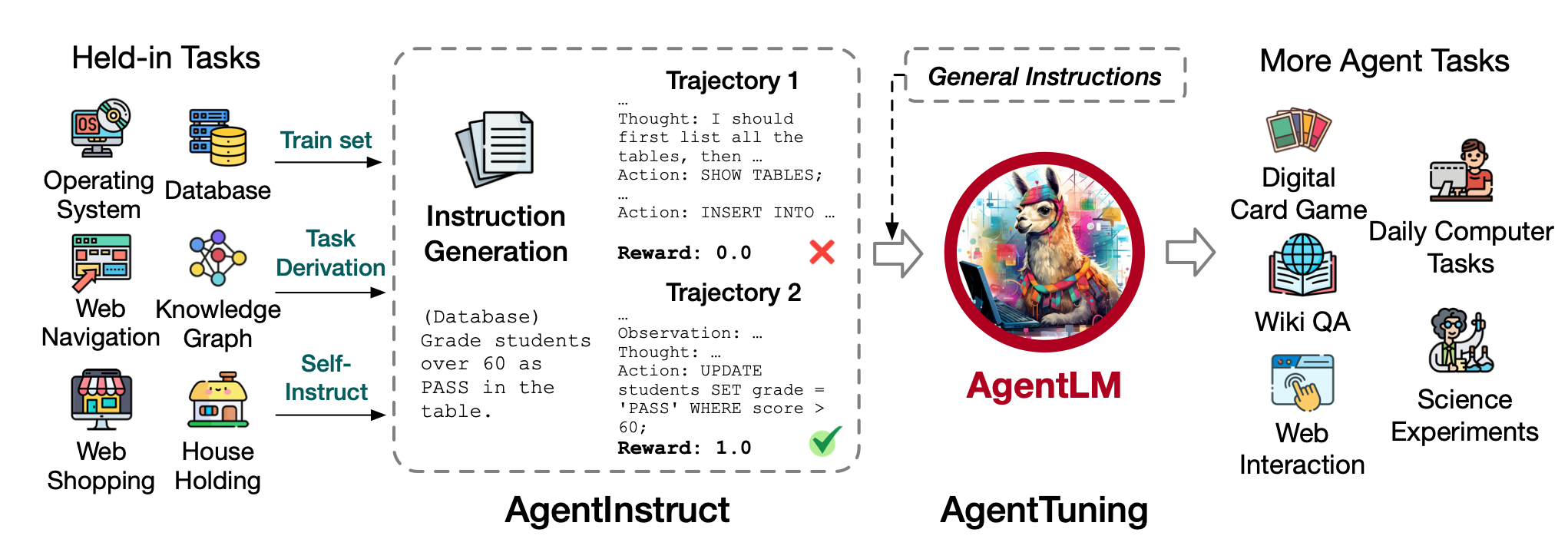
文中构建了一个包含高质量交互轨迹的微调数据集AgentInstruct,并且将其和通用能力的sft数据混合训练得到AgentLM。
其最大的亮点就是AgentInstruct数据集的构建,其主要依托的数据是来自AgentBench,其包含了6个来自真实世界的智能体任务。在构建好了基本的输入指令后,便以GPT-4作为智能体生成AgentInstruct。
(7) CHATANYTHING: FACETIME CHAT WITH LLM-ENHANCED PERSONAS
论文链接: https://arxiv.org/pdf/2311.06772.pdf
github链接: https://chatanything.github.io

本篇论文比较脑洞大,他是给定一张图片比如西瓜,然后会自动生成一个西瓜人agent回你对话。它主要涉及到三块,生成图像、tts以及人物性格生成;其中前两个分别是图像和语音技术这里我们不展开说了,感兴趣的小伙伴可以自己去读一下;人物性格生成这个主要也是借助LLM去自动生成贴切的性格,文章也给出了最核心的prompt:


(8) ROLELLM: BENCHMARKING, ELICITING, AND ENHANCING ROLE-PLAYING ABILITIES OF LARGE LANGUAGE MODELS
论文链接:https://arxiv.org/pdf/2310.00746.pdf

本文构建实现了一套角色扮演的方案,比如扮演孙悟空、哈利波特等等,每个角色都会有自己的说话风格并且都会有自己对应的角色背景,比如孙悟空自己的师傅是唐僧等等,在遇到有关唐僧的问题的时候,要注意结合师徒这个背景来回答。
文章主要的idea就是借助剧本来检索增强回复,同时作者基于llama训练了一个英文角色模型,基于glm训练了一个中文角色模型。
(9) Does Role-Playing Chatbots Capture the Character Personalities? Assessing Personality Traits for Role-Playing Chatbots
论文链接:https://arxiv.org/pdf/2310.17976.pdf

本文重点关注角色扮演agent领域,具体是研究如何评估大模型的角色扮演效果。
论文中的方法是基于大五人格、MBTI等心理学的人格相关理论,对角色扮演AI进行了人格测试。具体的是提出了一套为角色扮演AI设计的面谈式人格测试框架,基于人格测试量表与角色扮演AI展开开放式问答来进行评估。
(10) AutoGPT、XAgent、LangChain
AutoGPT : https://news.agpt.co
XAgent: https://github.com/OpenBMB/XAgent
LangChain: https://www.langchain.com
类似Metagpt, AutoGPT、XAgent、LangChain都是一些基于大模型开源的agent框架,其中LangChain更是在业界大名鼎鼎。
总结
Agent概念很大,这里如果我们纯从技术角度来看的话(且是依靠大模型的AI Agent),它的核心壁垒在哪里呢?或者说其最值钱的那部分技术是啥呢?
笔者将其归纳为如下两个核心:
- 拆分问题 & 调用逻辑
需要构思好怎么将当前的任务进行更好的拆分成一个个子任务,以确保这些子任务足够简单、完成的准确率足够高;当这些子任务都确保能被很好的完成,那么最终的任务就能很好的完成了。
所以拆分问题很关键,拆分的粒度如果太粗,子任务难度系数就高,就很容易失败;拆分的粒度如果太西,调用逻辑就很繁琐,整个链路就会很臃肿,所以对需求和业务的理解越深刻,拆解才会越相对合理。
同时拆分的是否合理还会影响另外一个关键问题:后期自研模型的开发。当我们想利用大模型开发Agent的时候,一般来说会先去使用GPT4去试一试(毕竟其目前是大模型的天花板),如果它都完成的不好,那要么自己当前Agent的设计框架需要进一步完善,要么就是这个事目前大模型还真的是很难完成。当GPT4完成的还不错后,出于安全和成本等考虑我们必定是想走自研模型这条路的,做到自主可控,那么我们就可以前期使用GPT4去积累数据,然后用这部分数据去蒸馏训练出自己的大模型。
那么如果你的任务拆分的粒度太细,假设有100个子任务(这里指要最终调用大模型能力),那么如何将这100个任务同时进行大模型训练,平衡住所有任务的能力,这是很难的(每个子任务训练一个大模型也太不现实了),当然如果拆分的粒度太粗,单个子任务本身就很难,那单训练好这个子任务可能都是问题,就更别提要融合所有子任务了;
- prompt engineering
当我们把当前这个Agent需要完成的任务多步拆解后以及理顺子任务之间的联动调用链路后,那么完成这些子任务就需要调用大模型了(当然有时候是调用一些其他插件比如计算器、搜索引擎等等;即使是调用插件其实上一步也一般是需要调用大模型来分析出要调用哪个插件以及插件需要的参数)。
既然是调用大模型,那么如何写好prompt让大模型完全get到你的需求,这是非常关键的,如果没写好prompt,那么子任务就失败了,整个链路就run不起来。
这块工作也是最繁琐和最需要经验的,要不断的去试进而润色出一个很棒的prompt。甚至笔者觉得在某些场景下,当你要做一个agent项目时,prompt engineering是你第一步要去做的事情,先去试着写几个prompt看看大模型能完成的怎么样?自己感受感受摸个底,这样也才可以有更多灵感看看怎么将任务进行更好的拆解,通过多步调用大模型(也即上面说的第一个核心点)来合作完成。
关注
欢迎关注,下期再见啦~

