
热门标签
热门文章
- 116_安装gradle并在IDEA中进行整合_idea gradle
- 2uniapp小程序设置页面横屏_uniapp如何控制页面横屏显示
- 3纯SQL去除字段特殊符号_删除数据库表中的某字段的特定符号
- 4BP神经网络用于预测_p=[3.2 3.2 3 3.2 3.2 3.4 3.2 3 3.2 3.2 3.2 3.9 3.1
- 5Linux子系统下的pytorch3d安装记录_linux pytorch3d
- 6PAT 乙级 1011 A+B 和 C C语言实现
- 7构建多语言数字资产交易平台和秒合约系统:从概念到实现
- 8ionic3 文件上传(控件上传)_fileuploadoptions
- 9算法笔记(Java)——动态规划_java动态规划
- 10bp神经网络是用来干嘛的,bp神经网络是什么网络_bp神经网络预测是干什么的
当前位置: article > 正文
OS-AIGC通用生成式人工智能模型加密接入标准API协议-2023 Beta版_osaigc
作者:花生_TL007 | 2024-03-24 07:53:51
赞
踩
osaigc

说明
OS-AIGC通用生成式人工智能模型加密接入标准API协议(Universal Language Model Encryption Access Standard API Protocol)国内的通用语言大模型的加密接入标准API协议。能够适配各种语言模型,主要为了解决API传输过程中的明文输入可能会造成的隐私信息泄露问题,同时也为了方便各种服务商想要接入API而需要写不同的API接口,我们想要达成的是服务商只需要接入一个API协议就可以访问请求各种语言模型的统一API协议标准
执行标准
- 安全加密传输:该协议要求所有数据在传输过程中进行加密,保护数据的安全性和隐私性。具体实现可以采用对称密钥加密、非对称密钥加密或其他加密方式,确保数据无法被未授权的第三方获取。
- 接口规范:该协议定义了统一的API接口规范,包括输入参数、输出参数、返回码等。各种语言模型的API必须遵守这个规范,确保服务商可以通过同样的方式调用不同的语言模型API。
- 兼容性:该协议要求兼容不同的语言模型,能够适配各种语言模型,为服务商提供多样化的选择。同时,该协议也要求兼容不同的操作系统和开发语言,能够在不同的平台下运行。
- 维护和更新:该协议要求定期维护和更新,及时解决可能存在的漏洞和BUG,确保协议的可靠性和安全性。同时,该协议也需要按照新的技术和需求进行更新和改进。
加密传输流程
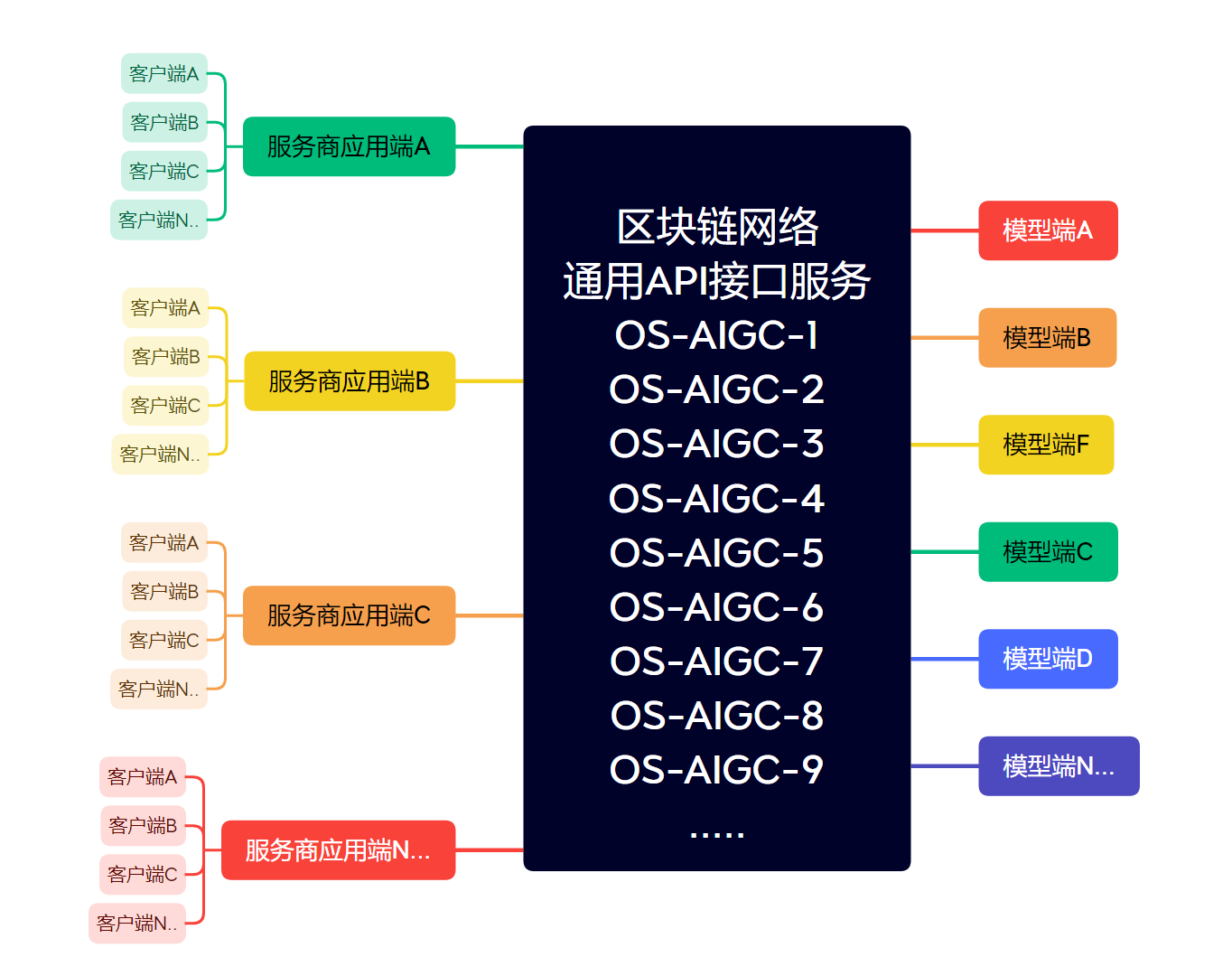
- 客户端独立生成私钥KEY1(独立存储于客户端),客户端发送请求经过私钥加密后密文发送给服务商应用端
- 服务商应用端只需要判断客户端(鉴权、计费、并附带随机请求码-此请求码仅作为回复标识)等流程后,将加密报文发送给OS-AIGC区块链节点网络服务器。
- OS-AIGC服务器接收到加密报文后与用户生成预留的公钥进行解密得到原始数据(原始数据不留存),将报文请求发送给模型端。
- 模型端接收到报文请求后将回复内容回复给OS-AIGC服务器,OS-AIGC服务器将报文加密后返回致服务商应用端。
- 服务商应用端接收到加密信息后直接回复给客户端,客户端私钥进行解密并显示原文。
计划支持接口
国内通用版
- ERNIE(Enhanced Representation through kNowledge IntEgration):由百度研究团队开发的一种基于Transformer架构和知识增强技术的中文预训练语言模型。
- RoFormer:由哈工大讯飞联合实验室开发的一种基于Transformer架构和多层级任务式预训练技术的中文预训练语言模型。
- CPM(Chinese Pre-Trained Language Model):由华中科技大学、哈工大讯飞联合实验室等研究机构共同开发的一种基于Transformer架构和自监督学习技术的中文预训练语言模型。
- ALBERT-CHINESE:由清华大学计算机系自然语言处理与社会人文计算实验室开发的一种基于ALBERT架构和预训练技术的中文预训练语言模型。
- UER(Universal Encoder Representations):由南京大学计算机科学与技术系开发的一种基于Transformer架构和预训练技术的通用语言模型,包括中文、英文等多语种支持。
- GPT-Chinese:由中国科学院自动化研究所开发的一种基于GPT-2架构和预训练技术的中文预训练语言模型。
- HFL-CHINESE-ROBERTA-wwm-ext:由哈工大讯飞联合实验室开发的一种基于RoBERTa架构和预训练技术的中文预训练语言模型。
- SimBERT(Simple BERT):由华为Noah’s Ark Lab开发的一种基于BERT架构和预训练技术的中文预训练语言模型。
- TinyBERT:由清华大学计算机系自然语言处理与社会人文计算实验室开发的一种基于BERT架构和知识蒸馏技术的轻量级中文预训练语言模型。
- DistilBERT-Chinese:由百度研究团队开发的一种基于DistilBERT架构和知识蒸馏技术的轻量级中文预训练语言模型。
国际版
- GPT(Generative Pre-trained Transformer 3):由OpenAI开发的一种基于Transformer架构和预训练技术的大规模语言模型。
- T5(Text-to-Text Transfer Transformer):由Google Brain开发的一种基于Transformer架构和自监督学习技术的通用语言模型。
- BERT(Bidirectional Encoder Representations from Transformers):由Google研究团队开发的一种基于Transformer架构和预训练技术的双向语言模型。
- RoBERTa(A Robustly Optimized BERT Pretraining Approach):由Facebook AI研究团队开发的一种基于BERT架构和预训练技术的强化版语言模型。
- XLNet(eXtreme MultiLingual Language Understanding):由CMU、Google Brain等研究机构共同开发的一种基于Transformer架构和自监督学习技术的高效语言模型。
- ELECTRA(Efficiently Learning an Encoder that Classifies Token Replacements Accurately):由Google Research开发的一种基于Transformer架构和对抗训练技术的高效语言模型。
- ALBERT(A Lite BERT for Self-supervised Learning of Language Representations):由Google Research和Toyota Technological Inst
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/花生_TL007/article/detail/300866
推荐阅读
相关标签

