
- 1ChatGPT生成 SD 和 Midjourney 的提示(prompt)_一些有趣的sd提示词
- 2一键掌控:Shell脚本自动化安装与管理Conda环境的艺术
- 3unity mac android sd卡,[Unity] Mac 下設定 Android Studio SDK 路徑
- 4C语言重开29:例题赏析——统计素数并求和_统计素数并求和:输入两个正整数 m 和 n(1≤m≤n≤500),统计给定整数 m 和 n
- 5使用 TensorFlow 2.0 实现高水准的自然语言处理_tensorfolw 自然语言处理demo
- 6Ubuntu 22.04 安装Mongodb_ubuntu22.04安装mongodb
- 7gpt论文写作_gpt+论文写作
- 8机器学习中的数学原理——模型评估与交叉验证
- 9command a expects \ followed by text
- 10Ant Design Pro 兼容性问题_ant design pro 兼容ie
百度飞桨python小白逆袭大神总结_python飞浆试图
赞
踩
Python小白逆袭大神心得:
首先感谢百度提供的免费学习课程,我是一名电气学生,之前都没有接触过python,所以说为啥一名真真正正的小白,完成作业的过程中,对于我来说并不是那么容易的,但是经过这一个星期的学习中虽然仍然不太会写代码,但是对于python多多少少有了一些了解。
课程如下:
-
Day1:人工智能概述与入门基础
-
Day2:获取《青春有你2》成员剧照
-
Day3:《青春有你2》小姐姐单人助力榜单揭秘
-
Day4:自制数据集,利用PaddleHub 颜值打分
-
Day5:《青春有你2》评论调取、词频统计、绘制词云;自制数据集、利用PaddleHub进行评论情感分析
day1:基础练习
作业Day1中有两个作业,其中一是九九乘法表,这个很好容易实现,第二个找出包含某个名字的文件,
#遍历”Day1-homework”目录下文件;找到文件名包含“2020”的文件 #导入OS模块 import os #待搜索的目录路径 path = "Day1-homework" #待搜索的名称 filename = "2020" #定义保存结果的数组 result = [] number=0 def findfiles(path): #在这里写下您的查找文件代码吧! li = os.listdir(path) global number #print(li) for p in li: temppathname=p #print(temppathname) pathname =os.path.join(path,temppathname) #print(pathname) if os.path.isdir(pathname): findfiles(pathname) elif os.path.isfile(pathname): if(temppathname.find(filename)!=-1): number=number+1 result=[] result.append(number) result.append(pathname) if(len(result)>0): print(result) if __name__ == '__main__': findfiles(path)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
day2:《青春有你2》选手信息爬取
作业要求使用Python来爬取百度百科中《青春有你2》所有参赛选手的信息。这个运用到了爬虫

本实践中将会使用以下两个模块,首先对这两个模块简单了解以下:
request模块:
requests是python实现的简单易用的HTTP库,官网地址:http://cn.python-requests.org/zh_CN/latest/
requests.get(url)可以发送一个http get请求,返回服务器响应内容。
BeautifulSoup库:
BeautifulSoup 是一个可以从HTML或XML文件中提取数据的Python库。网址:https://beautifulsoup.readthedocs.io/zh_CN/v4.4.0/
BeautifulSoup支持Python标准库中的HTML解析器,还支持一些第三方的解析器,其中一个是 lxml。
BeautifulSoup(markup, “html.parser”)或者BeautifulSoup(markup, “lxml”),推荐使用lxml作为解析器,因为效率更高。
day3:《青春有你2》选手数据分析
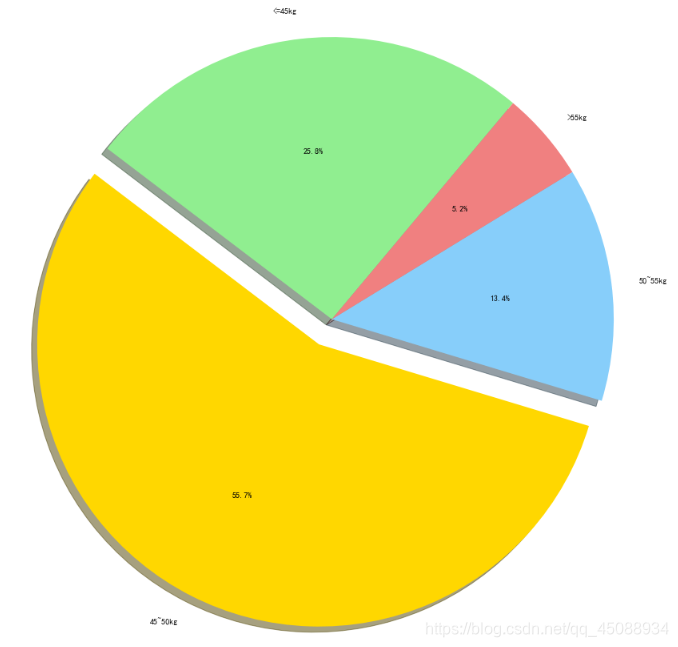
第三天的作业是将第二天作业所爬取的《青春有你》的选手信息的信息进行可视化处理,主要针对matplotlib使用。
#对选手体重分布进行可视化,绘制饼状图 import matplotlib.pyplot as plt import numpy as np import json import matplotlib.font_manager as font_manager import pandas as pd #显示matplotlib生成的图形 %matplotlib inline df = pd.read_json('data/data31557/20200422.json') #print(df) grouped=df['weight'] #print(grouped) lists=[] Last_list=[] list1=0 list2=0 list3=0 list4=0 for star in grouped: list = star lists.append(list) #print(lists) nowList = [i.split('k', 1)[0] for i in lists] for last_list in nowList: list_int = float(last_list) Last_list.append(list_int) #print(type(Last_list)) print(Last_list) for L in Last_list: if L<=45: list1 += 1 if L>45 and L<50: list2 += 1 if L>50 and L<=55: list3 += 1 if L>55: list4 += 1 #设置显示中文 plt.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体 plt.figure(figsize=(20,15)) labels='<=45kg','45~50kg','50~55kg','>55kg' sizes=[list1,list2,list3,list4] colors='lightgreen','gold','lightskyblue','lightcoral' explode=[0,0.1,0,0] plt.pie(sizes,explode=explode,labels=labels,colors=colors,autopct='%1.1f%%',shadow=True,startangle=50) plt.axis('equal') plt.savefig('/home/aistudio/work/result/bar_result03.jpg') plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
效果如下:
day4:《青春有你2》选手识别
主要任务:图像分类是计算机视觉的重要领域,它的目标是将图像分类到预定义的标签。近期,许多研究者提出很多不同种类的神经网络,并且极大的提升了分类算法的性能。本文以自己创建的数据集:青春有你2中选手识别为例子,介绍如何使用PaddleHub进行图像分类任务。PaddleHub用起来是真的方便,主要难点就是数据集的制作与处理,看似很简单的问题做起来却困难重重,可能是我太笨了吧。
day5:综合大作业
作业任务:
- 完成爱奇艺《青春有你2》评论数据爬取:爬取任意一期正片视频下评论,评论条数不少于1000条
- 词频统计并可视化展示
- 绘制词云
- 结合PaddleHub,对评论进行内容审核
需要的配置和准备:
- 中文分词需要jieba
- 词云绘制需要wordcloud
- 可视化展示中需要的中文字体
- 网上公开资源中找一个中文停用词表
- 根据分词结果自己制作新增词表
- 准备一张词云背景图(附加项,不做要求,可用hub抠图实现)
- paddlehub配置
最后一次综合大作业看似很难,其实只要仔细分析一下就会发现这次作业只不过是前几次作业的综合。例如:第一步用爬虫爬取视频下方的评论,唯一难点就是如何才能爬取到所有人的评论,经过老师的讲解发现只要获取每页评论的最后一个评论的用户ID的url就可以了
代码如下
#请求爱奇艺评论接口,返回response信息 def getMovieinfo(url): ''' 请求爱奇艺评论接口,返回response信息 参数 url: 评论的url :return: response信息 ''' session = requests.Session() headers = { 'User-Agent': 'Mozilla/5.0', #'Accept': 'application/json', #'accept-encoding': 'gzip, deflate, br', #'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8', #'Referer': 'https://www.iqiyi.com/v_19ryi45hd8.html' } response = session.get(url, headers=headers) if response.status_code == 200: return response.text return None #解析json数据,获取评论 def saveMovieInfoToFile(lastId,arr): ''' 解析json数据,获取评论 参数 lastId:最后一条评论ID arr:存放文本的list :return: 新的lastId ''' url = "https://sns-comment.iqiyi.com/v3/comment/get_comments.action?agent_type=118&\ agent_version=9.11.5&authcookie=null&business_type=17&content_id=15535092800&hot_size=0&last_id=" url += str(lastId) responseTxt = getMovieinfo(url) responseJson = json.loads(responseTxt) comments = responseJson['data']['comments'] for val in comments: if 'content' in val.keys(): print(val['content']) arr.append(val['content']) lastId =str(val['id']) return lastId
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
第二部是用分词、停止词以及词频统计,第三部词频绘图,第四部是根据词频生成词云。
这就是最后生成词云的效果如下:

到此作业结束了,总的来说百度飞桨的这期课程是非常的不错的,对于python小白来说相当仁慈了,而且上手还很快,再次感谢百度提供的这次机会,我也收获颇多,对百度深度学习的框架有了更多深层次的了解,希望百度越做越好,以后多进行这种训练营,来帮助更多的同学。


