
- 1Scikit-learn 数据挖掘和数据分析工具的使用指南
- 2使用遗忘因子最小二乘法(FFRLS)的锂离子电池二阶RC参数辨识
- 3论文笔记:Cross -Scale Self-Attention Module(CSSA):跨尺度自注意力模块
- 4图片/视频等效果质量评测指标
- 5Python基础篇(二)-- 数据类型和运算符_print(str[0:7:2])的结果为
- 6【AI大模型应用开发】【LangChain系列】1. 全面学习LangChain输入输出I/O模块:理论介绍+实战示例+细节注释_langchain+openai构建module i/o
- 7100天精通Python(可视化篇)——第100天:Pyecharts绘制多种炫酷漏斗图参数说明+代码实战_phtyon漏斗图
- 810亿数据要存要查,选Mongodb还是Elalsticsearch?_manticoresearch和es比较
- 9上采样、下采样、过采样、欠采样是什么?_欠采样和过采样 谢邀
- 10Vue官网下载Vue.js和Vue.min.js_vue.js官网
通俗讲解bert原理_bert模型通俗理解
赞
踩
bert与GPT一样均是采用transformer的结构,与GPT不同的是,bert是双向的,而GPT是单向的。如图所示:

bert结构
先看下bert的内部结构,官网最开始提供了两个版本,L表示的是transformer的层数,H表示输出的维度,A表示mutil-head attention的个数:
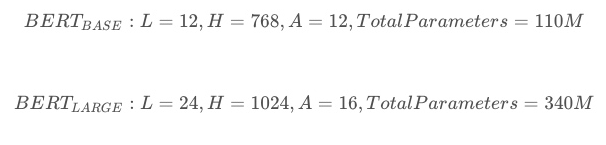
如今已经增加了多个模型,其中包括中文模型:

从模型的层数来说其实已经很大了,但是由于transformer的残差(residual)模块,层数并不会引起梯度消失等问题,但是并不代表层数越多效果越好,有论点认为低层偏向于语法特征学习,高层偏向于语义特征学习。
BERT的预训练过程
接下来我们看看BERT的预训练过程,BERT的预训练阶段包括两个任务,一个是Masked Language Model,还有一个是Next Sentence Prediction。
-
Masked Language Model:MLM可以理解为完形填空,作者会随机mask每一个句子中15%的词,用其上下文来做预测,例如:my dog is hairy → my dog is [MASK]。
此处将hairy进行了mask处理,然后采用非监督学习的方法预测mask位置的词是什么,但是该方法有一个问题,因为是mask15%的词,其数量已经很高了,这样就会导致某些词在fine-tuning阶段从未见过,为了解决这个问题,作者做了如下的处理:- 80%的时间是采用[mask],my dog is hairy → my dog is [MASK];
- 10%的时间是随机取一个词来代替mask的词,my dog is hairy -> my dog is apple;
- 10%的时间保持不变,my dog is hairy -> my dog is hairy。
注意:
- 有参数dupe_factor决定数据duplicate的次数;
- 其中,create_instance_from_document函数,是构造了一个sentence-pair的样本。对每一句,先生成[CLS]+A+[SEP]+B+[SEP],有长(0.9)有短(0.1),再加上mask,然后做成样本类object;
- create_masked_lm_predictions函数返回的tokens是已经被遮挡词替换之后的tokens;
- masked_lm_labels则是遮挡词对应位置真实的label。
-
Next Sentence Prediction:选择一些句子对A与B,其中50%的数据B是A的下一条句子,剩余50%的数据B是语料库中随机选择的,学习其中的相关性,添加这样的预训练的目的是目前很多NLP的任务比如QA和NLI都需要理解两个句子之间的关系,从而能让预训练的模型更好的适应这样的任务。
个人理解:- Bert先是用Mask来提高视野范围的信息获取量,增加duplicate再随机Mask,这样跟RNN类方法依次训练预测没什么区别了除了mask不同位置外;
- 全局视野极大地降低了学习的难度,然后再用A+B/C来作为样本,这样每条样本都有50%的概率看到一半左右的噪声;
- 但直接学习Mask A+B/C是没法学习的,因为不知道哪些是噪声,所以又加上next_sentence预测任务,与MLM同时进行训练,这样用next来辅助模型对噪声/非噪声的辨识,用MLM来完成语义的大部分的学习。

bert模型输入
bert的输入可以是单一的一个句子或者是句子对,实际的输入值是segment embedding与position embedding相加,具体的操作流程可参考这篇Transformer讲解。
BERT的输入词向量是三个向量之和:
Token Embedding:WordPiece tokenization subword词向量。
Segment Embedding:表明这个词属于哪个句子(NSP需要两个句子)。
Position Embedding:学习出来的embedding向量。这与Transformer不同,Transformer中是预先设定好的值。

BERT预训练模型的输出结果,无非就是一个或多个向量。下游任务可以通过精调(改变预训练模型参数)或者特征抽取(不改变预训练模型参数,只是把预训练模型的输出作为特征输入到下游任务)两种方式进行使用。BERT原论文使用了精调方式,但也尝试了特征抽取方式的效果,比如在NER任务上,最好的特征抽取方式只比精调差一点点。但特征抽取方式的好处可以预先计算好所需的向量,存下来就可重复使用,极大提升下游任务模型训练的速度。
总结下BERT的主要贡献:
- 引入了Masked LM,使用双向LM做模型预训练。
- 为预训练引入了新目标NSP,它可以学习句子与句子间的关系。
- 进一步验证了更大的模型效果更好: 12 --> 24 层。
- 为下游任务引入了很通用的求解框架,不再为任务做模型定制。
- 刷新了多项NLP任务的记录,引爆了NLP无监督预训练技术。
BERT是谷歌团队糅合目前已有的NLP知识集大成者,刷新11条赛道彰显了无与伦比的实力,且极容易被用于多种NLP任务。宛若一束烟花点亮在所有NLP从业者心中。更为可贵的是谷歌选择了开源这些,让所有从业者看到了在各行各业落地的更多可能性。
BERT优点
- Transformer Encoder因为有Self-attention机制,因此BERT自带双向功能;
- 因为双向功能以及多层Self-attention机制的影响,使得BERT必须使用Cloze版的语言模型Masked-LM来完成token级别的预训练;
- 为了获取比词更高级别的句子级别的语义表征,BERT加入了Next Sentence Prediction来和Masked-LM一起做联合训练;
- 为了适配多任务下的迁移学习,BERT设计了更通用的输入层和输出层;
- 微调成本小。
BERT缺点
- task1的随机遮挡策略略显粗犷,推荐阅读《Data Nosing As Smoothing In Neural Network Language Models》;
- [MASK]标记在实际预测中不会出现,训练时用过多[MASK]影响模型表现;
- 每个batch只有15%的token被预测,所以BERT收敛得比left-to-right模型要慢(它们会预测每个token);
- BERT对硬件资源的消耗巨大(大模型需要16个tpu,历时四天;更大的模型需要64个tpu,历时四天。
BERT适用场景
第一,对于某些任务,除了文本类特征外,其它特征也很关键,比如搜索的用户行为/链接分析/内容质量等也非常重要,所以Bert的优势可能就不太容易发挥出来。再比如,推荐系统也是类似的道理,Bert可能只能对于文本内容编码有帮助,其它的用户行为类特征,不太容易融入Bert中。
第二,Bert特别适合解决句子或者段落的匹配类任务。Bert特别适合用来解决判断句子关系类问题,这是相对单文本分类任务和序列标注等其它典型NLP任务来说的,很多实验结果表明了这一点。而其中的原因,我觉得很可能主要有两个,一个原因是:很可能是因为Bert在预训练阶段增加了Next Sentence Prediction任务,所以能够在预训练阶段学会一些句间关系的知识,而如果下游任务正好涉及到句间关系判断,就特别吻合Bert本身的长处,于是效果就特别明显。第二个可能的原因是:因为Self Attention机制自带句子A中单词和句子B中任意单词的Attention效果,而这种细粒度的匹配对于句子匹配类的任务尤其重要,所以Transformer的本质特性也决定了它特别适合解决这类任务。
第三,Bert的适用场景,与NLP任务对深层语义特征的需求程度有关。感觉越是需要深层语义特征的任务,越适合利用Bert来解决;而对有些NLP任务来说,浅层的特征即可解决问题,典型的浅层特征性任务比如分词,POS词性标注,NER,文本分类等任务,这种类型的任务,只需要较短的上下文,以及浅层的非语义的特征,貌似就可以较好地解决问题,所以Bert能够发挥作用的余地就不太大,有点杀鸡用牛刀,有力使不出来的感觉。
这很可能是因为Transformer层深比较深,所以可以逐层捕获不同层级不同深度的特征。于是,对于需要语义特征的问题和任务,Bert这种深度捕获各种特征的能力越容易发挥出来,而浅层的任务,比如分词/文本分类这种任务,也许传统方法就能解决得比较好,因为任务特性决定了,要解决好它,不太需要深层特征。
第四,Bert比较适合解决输入长度不太长的NLP任务,而输入比较长的任务,典型的比如文档级别的任务,Bert解决起来可能就不太好。主要原因在于:Transformer的self attention机制因为要对任意两个单词做attention计算,所以时间复杂度是n平方,n是输入的长度。如果输入长度比较长,Transformer的训练和推理速度掉得比较厉害,于是,这点约束了Bert的输入长度不能太长。所以对于输入长一些的文档级别的任务,Bert就不容易解决好。结论是:Bert更适合解决句子级别或者段落级别的NLP任务。
这个是直接整理的一个大佬的博客,原文链接:https://blog.csdn.net/jiaowoshouzi/article/details/89073944

