
- 1测试Ocr工具IronOCR
- 2YOLOv8 升级之路:GhostNetV2 主干网络解析与实操
- 3TF-IDF介绍及Python实现文本聚类_python tfidf
- 4如何使用Springboot集成华为云OCR服务,实现文字识别的功能?_ocrclient client = ocrclient.newbuilder()
- 5政安晨:【示例演绎】【Python】【Google/JAX】—— 专为高性能与大规模机器学习设计
- 6如何成为一名正义黑客?你应该学习什么?_ethical hacker golf ball diver cheese sculptor
- 7大模型和向量数据库怎么搭建 RAG 系统?Step by step 例子来了。
- 8计算机视觉_high-level的视觉任务
- 9Meta开源的LLaMa到底好不好用?最全测评结果来了
- 10Attentional Feature Fusion 注意力特征融合_注意力融合
在 Elasticsearch 中使用 PyTorch 进行现代自然语言处理的介绍_eland_import_hub_model
赞
踩

随着 8.0 的发布,Elastic 很高兴能够将 PyTorch 机器学习模型上传到 Elasticsearch 中,以在 Elastic Stack 中提供现代自然语言处理 (NLP)。 现在,Elasticsearch 用户能够集成用于构建 NLP 模型的最流行的格式之一,并将这些模型作为 NLP 数据管道的一部分通过我们的 Inference processor 整合到 Elasticsearch 中。 添加 PyTorch 模型以及新的 ANN 搜索 API的能力为 Elastic Enterprise Search 添加了一个全新的向量(双关语)。
在 Elasticsearch 中使用 PyTorch 进行现代自然语言处理
在 Elasticsearch 中使用 PyTorch 进行现代自然语言处理_哔哩哔哩_bilibili
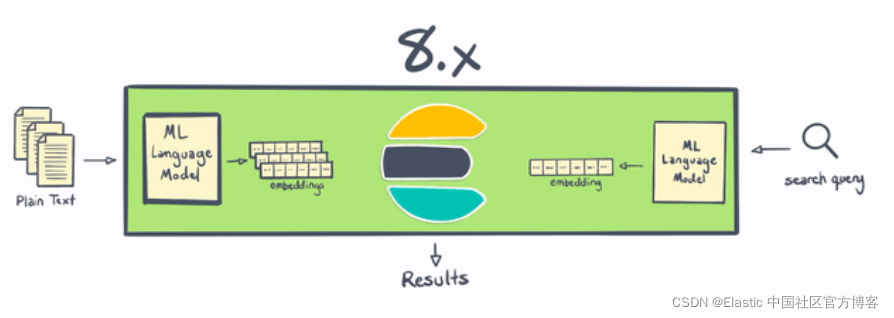
NLP 在 Elastic Stack 7.x 和 8.0 中的区别
Elasticsearch 一直是进行 NLP 的好地方,但从历史上看,它需要在 Elasticsearch 之外进行一些处理,或者编写一些非常复杂的插件。 借助 8.0,用户现在可以在 Elasticsearch 中更直接地执行命名实体识别、情感分析、文本分类等操作——无需额外的组件或编码。 不仅在 Elasticsearch 中本地计算和创建向量在水平可扩展性方面是“胜利”(通过在服务器集群中分布计算)——这一变化还为 Elasticsearch 用户节省了大量时间和精力。
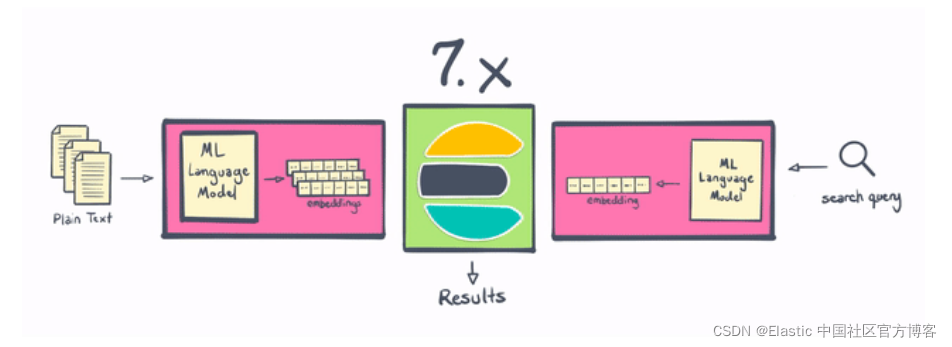
借助 Elastic 8.0,用户可以直接在 Elasticsearch 中使用 PyTorch 机器学习模型(例如 BERT),并在 Elasticsearch 中使用这些模型进行推理。 这些模型可以是你自己的自定义模型,也可以是在 Hugging Face 等存储库中发布到社区的模型。
通过使用户能够直接在 Elasticsearch 中执行推理,将现代 NLP 的强大功能集成到搜索应用程序和体验(想想:无需编码)、本质上更高效(得益于 Elasticsearch 的分布式计算能力)和 NLP 本身比以往任何时候都更容易 变得更快,因为你不需要将数据移出到单独的进程或系统中。
什么是自然语言处理?
NLP 是指我们可以使用软件来操作和理解口语或书面文本或自然语言的方式。NLP 是人工智能 (AI) 的一个分支,专注于尽可能接近人类解释的理解人类语言,将计算语言学与统计、机器学习和深度学习模型相结合。
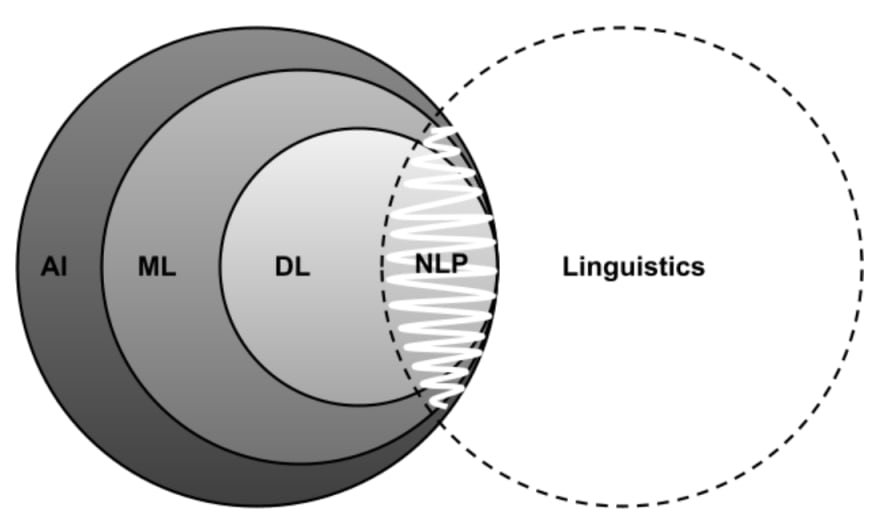
一些常见的 NLP 任务:
命名实体识别
将单词或短语识别为实体。比如:

使用的 model 可以在地址找到。
情感分析
试图从文本中提取主观情感。

在这种情况下,快乐的得分更高。使用的模型可以在地址 找到。
摘要
是在不删除文本语义结构的情况下创建较短文本的过程。

使用的模型可以在地址找到。
翻译
是将一种自然语言自动转换为另一种自然语言的任务,同时保留输入文本的含义。

使用的模型可以在地址找到。
2018 年,Google 开源了一种用于 NLP 预训练的新技术,称为来自 Transformers 的双向编码器呈现,或 BERT。 BERT 通过在没有任何人工参与的情况下对互联网大小的数据集(例如,想想所有的维基百科和数字书籍)进行训练来利用 “transfer learning”。
Transfer learning 允许对 BERT 模型进行预训练以进行通用语言理解。一旦模型只经过一次预训练,它就可以被重用并针对更具体的任务进行微调,以了解语言的使用方式。
为了支持类 BERT 模型(使用与 BERT 相同的标记器的模型),Elasticsearch 将首先通过 PyTorch 模型支持支持大多数最常见的 NLP 任务。 PyTorch 是最受欢迎的现代机器学习库之一,拥有大量活跃用户,它是一个支持深度神经网络的库,例如 BERT 使用的 Transformer 架构。
以下是一些示例 NLP 任务:
- 情绪分析:用于识别正面与负面陈述的二元分类
- 命名实体识别 (NER):从非结构化文本构建结构,尝试提取名称、位置或组织等细节
- 文本分类:零样本分类允许你根据你选择的类对文本进行分类,而无需进行预训练。
- 文本嵌入:用于 k 近邻 (kNN) 搜索
Elastic Stack NLP 能做什么?
Elastic Stack NLP 1_哔哩哔哩_bilibili
Elasticsearch 中的自然语言处理
在将 NLP 模型集成到 Elastic 平台时,我们希望为上传和管理模型提供出色的用户体验。使用用于上传 PyTorch 模型的 Eland 客户端和用于管理 Elasticsearch 集群上模型的 Kibana 的 ML 模型管理用户界面,用户可以尝试不同的模型并很好地了解它们在数据上的表现。我们还希望使其可跨集群中的多个可用节点进行扩展,并提供良好的推理吞吐量性能。
Elastic Stack NLP 工作流程
Elastic Stack NLP 2_哔哩哔哩_bilibili
为了使这一切成为可能,我们需要一个机器学习库来执行推理。在 Elasticsearch 中添加对 PyTorch 的支持需要使用原生库 libtorch,它支持 PyTorch,并且仅支持已导出或保存为 TorchScript 表示的 PyTorch 模型。这是 libtorch 需要的模型的表示,它将允许 Elasticsearch 避免运行 Python 解释器。
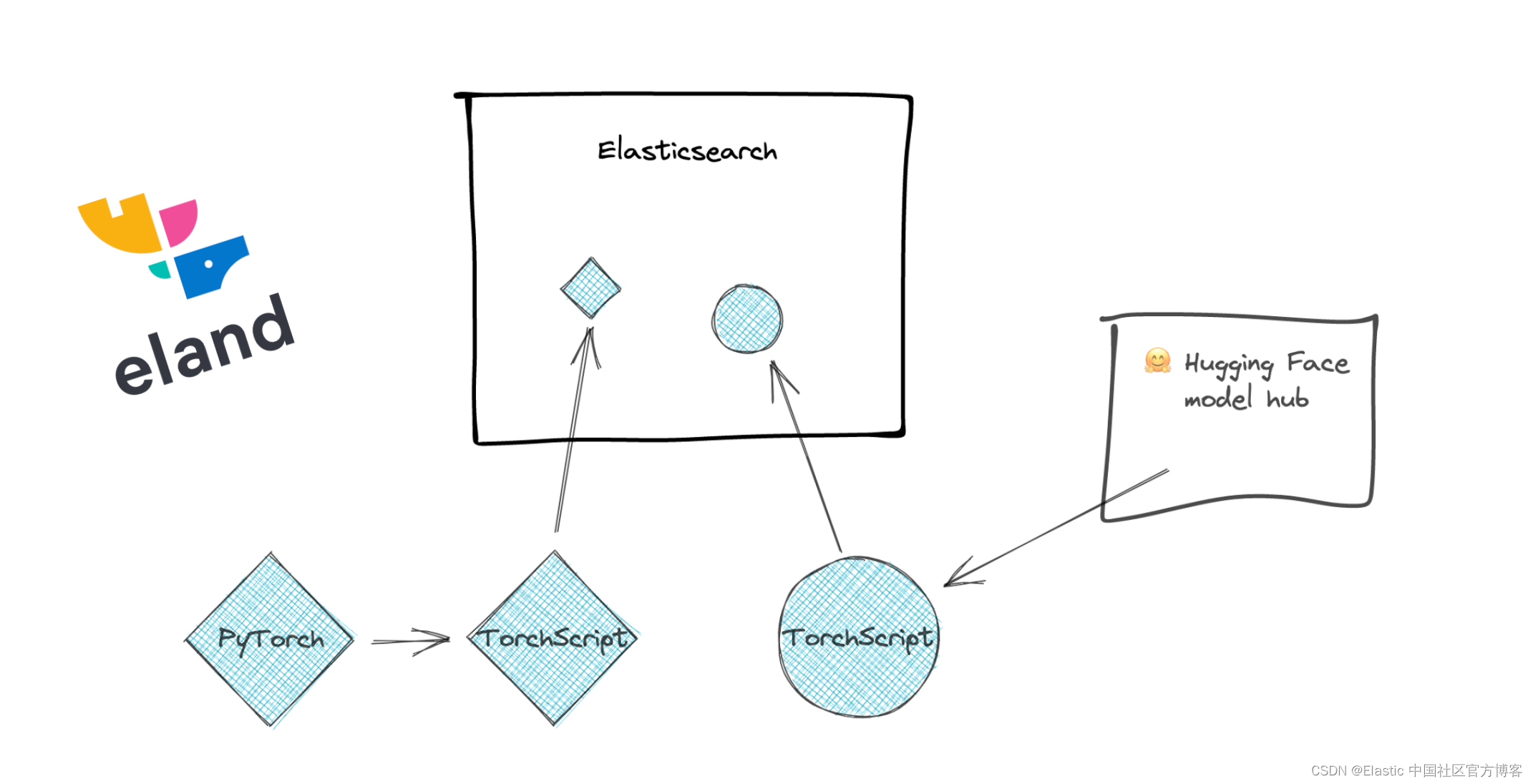
通过与在 PyTorch 模型中构建 NLP 模型的最流行的格式之一集成,Elasticsearch 可以提供一个平台,该平台可处理大量 NLP 任务和用例。许多优秀的库可用于训练 NLP 模型,因此我们暂时将其留给其他工具。无论你是使用 PyTorch NLP、Hugging Face Transformers 还是 Facebook 的 fairseq 等库来训练模型,你都可以将模型导入 Elasticsearch 并对这些模型进行推理。 Elasticsearch 推理最初将仅在摄取时进行,未来还可以扩展以在查询时引入推理。

到目前为止,已经有一些方法可以通过 API 调用和插件以及其他选项将 NLP 模型集成到 Elasticsearch 和 Elasticsearch 之间。但是通过在你的 Elasticsearch 数据管道中集成 NLP 模型,你可以获得以下好处:
- 围绕你的 NLP 模型构建更好的基础架构
- 扩展你的 NLP 模型推理
- 维护你的数据安全和隐私
NLP 模型可以集中管理,并且可以协调加载和分发这些模型。
对 PyTorch 模型的推理调用可以分布在集群周围,并且可以允许用户在未来根据负载进行扩展。通过不移动数据并针对基于 CPU 的推理优化云虚拟机,可以提高性能。通过在 Elasticsearch 中整合 NLP 模型,我们可以将数据保存在一个整体集中、安全的网络中,同时考虑到数据隐私和合规性。通用基础设施、查询性能和数据隐私都可以通过在 Elasticsearch 中整合 NLP 模型得到增强。
展示
在接下来的环节中,我们将使用一个简单的例子来展示如何使用 Elastic NLP。如果要在集群中执行自然语言处理任务,则必须部署适当的训练模型。 Eland 和 Kibana 提供工具支持,可帮助你准备和管理模型。
选择一个训练好的模型编辑
根据概述,你可以通过多种方式在 Elastic Stack 中使用 NLP 功能。 在确定要执行哪种类型的 NLP 任务后,你必须选择合适的训练模型。
最简单的方法是使用已经针对你要执行的分析类型进行了微调的模型。 例如,Hugging Face 上有可用于特定 NLP 任务的模型和数据集。 这些说明假定你正在使用其中一种模型,并且不描述如何创建新模型。 有关支持的模型架构的当前列表,请参阅第三方 NLP 模型。
如果你选择使用集群中提供的 lang_ident_model_1 执行语言识别,则不需要进一步的步骤来导入或部署模型。 你可以跳到在摄取管道中使用模型。
导入训练好的模型和词汇
选择模型后,你必须将其及其标记器词汇表导入集群。 导入模型时,由于其大小,必须将其分块并一次导入一个块,以便分段存储。
经过训练的模型必须采用 TorchScript 表示,才能与 Elastic Stack 机器学习功能一起使用。
Eland 将 Hugging Face 转换器模型到其 TorchScript 表示的转换和分块过程封装在一个 Python 方法中; 因此,这是推荐的导入方法。
- 安装 Eland Python 客户端。
- 运行 eland_import_hub_model 脚本。 例如:
- eland_import_hub_model --url <clusterUrl> \
- --hub-model-id elastic/distilbert-base-cased-finetuned-conll03-english \
- --task-type ner
- 指定 URL 以访问你的集群。 例如,https://<user>:<password>@<hostname>:<port>。
- 在 Hugging Face 模型中心中指定模型的标识符。
- 指定 NLP 任务的类型。 支持的值为 fill_mask、ner、text_classification、text_embedding 和 zero_shot_classification。
如果你还没有安装好自己的 Elastic Stack 8.0,请参考我之前的文章 “Elastic Stack 8.0 安装 - 保护你的 Elastic Stack 现在比以往任何时候都简单”。在进行下面的操作之前,我们必须启动白金版试用:

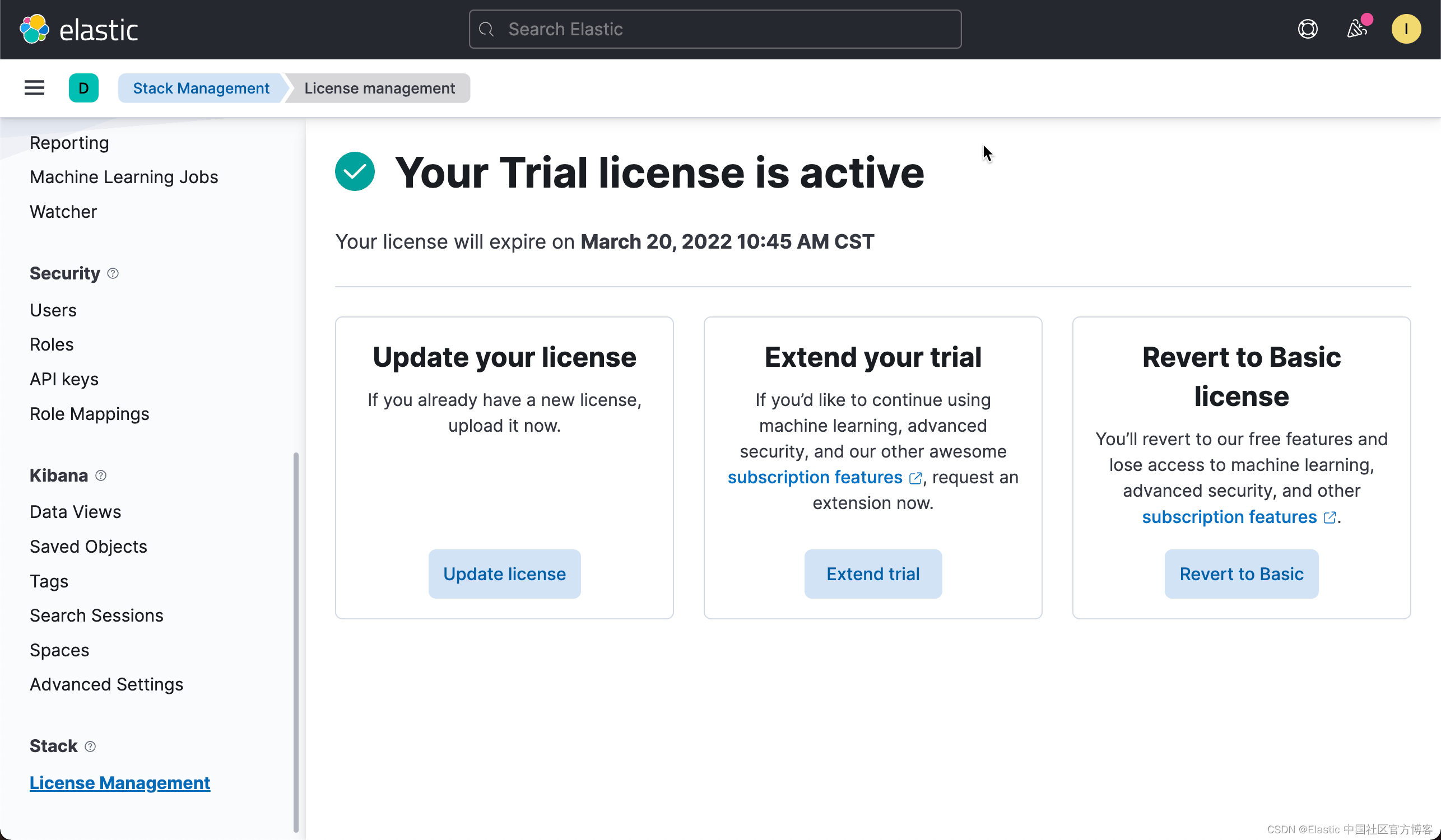
如果我们不启动白金版试用,我们在下面启动 docker 上传模型时,可能看的如下的错误信息:
 如果我们的 Elasticsearch 位于 https://192.168.0.3:9200,那么我们可以使用如下的命令来执行:
如果我们的 Elasticsearch 位于 https://192.168.0.3:9200,那么我们可以使用如下的命令来执行:
python -m pip install elandgit clone https://github.com/elastic/eland下面修改代码的部分已经在最新的 eland 发布版中有更新,请略过。详细的步骤可以参考文章 “Elasticsearch:如何部署 NLP:文本嵌入和向量搜索”。
我们进入到下载的代码根目录中。如果你部署的 Elasticsearch 集群不是使用自签名的,那么一下的步骤你直接跳过。针对自签名集群,你需要修改如下的文件:
eland/bin/eland_import_hub_model
在 def main(): 的下面的位置:

在上面,我们添加 verify_certs 为 False,以及设置 http_auth。在 http_auth 里设置超级用户 elastic 的用户名及密码。
我们使用如下的命令来创建 docker image:
docker build -t elastic/eland .
我们接着使用如下的方法来上传模型:
- docker run -it --rm --network host \
- elastic/eland \
- eland_import_hub_model \
- --url https://liuxg.com:9200/ \
- --hub-model-id elastic/distilbert-base-cased-finetuned-conll03-english \
- --task-type ner \
- --start
在这里,请注意我们必须使用当前电脑的 hostname,否则我们将建立不起来连接。在我的电脑上:
- $ ping liuxg.com
- PING liuxg.com (192.168.0.3): 56 data bytes
- 64 bytes from 192.168.0.3: icmp_seq=0 ttl=64 time=0.076 ms
- 64 bytes from 192.168.0.3: icmp_seq=1 ttl=64 time=0.268 ms
我们需要在 /etc/hosts 里进行设置。
运行上面的命令:
等上述的命令完成后,我们在 Kinana 中进行查看:
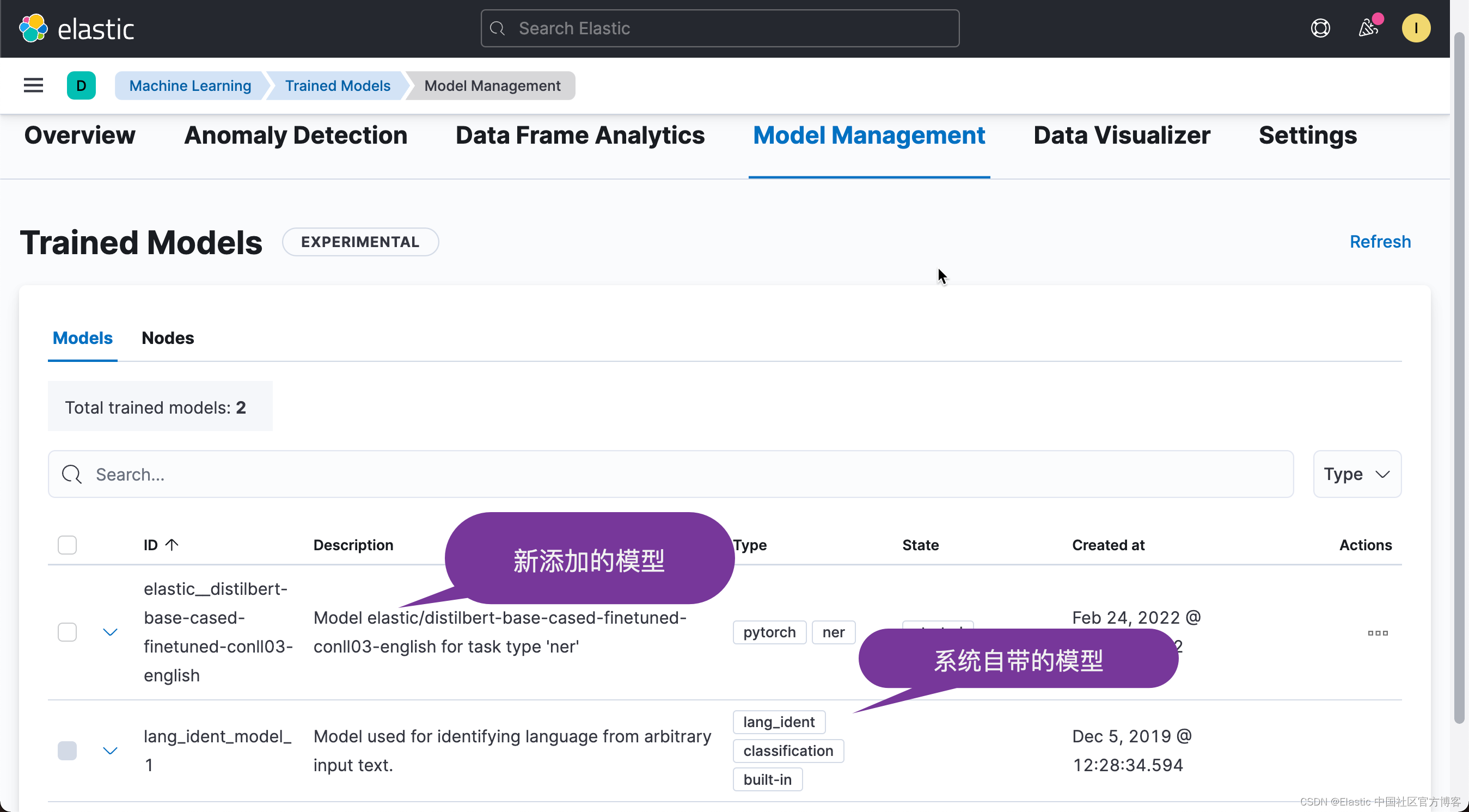
从上面的界面中,我们可以看出一个新怎讲的模型。现在我们已经成功地把模型上传到 Elasticsearch 中。
测试模型
当模型部署在集群中的至少一个节点上时,你就可以开始执行推理了。 推理是一种机器学习功能,可让你使用经过训练的模型对传入数据执行 NLP 任务(例如文本提取、分类或嵌入)。
针对新数据测试模型的最简单方法是使用推理训练模型部署 API。还记得我们之前在启动 docker 时有一个选项为 ner,也即命名实体识别。 例如,要尝试命名实体识别任务,请提供一些示例文本:
- POST /_ml/trained_models/elastic__distilbert-base-cased-finetuned-conll03-english/deployment/_infer
- {
- "docs": {
- "text_field": "Sasha bought 300 shares of Acme Corp in 2022."
- }
- }
上面的命令返回的结果为:
- {
- "predicted_value" : "[Sasha](PER&Sasha) bought 300 shares of [Acme Corp](ORG&Acme+Corp) in 2022.",
- "entities" : [
- {
- "entity" : "Sasha",
- "class_name" : "PER",
- "class_probability" : 0.9953193610539933,
- "start_pos" : 0,
- "end_pos" : 5
- },
- {
- "entity" : "Acme Corp",
- "class_name" : "ORG",
- "class_probability" : 0.9996392196076958,
- "start_pos" : 27,
- "end_pos" : 36
- }
- ]
- }

从上面的返回结果中,我们可以看出来有 99.5% 的可能性判定 Sasha 是一个人名,而有 99.96% 的可能性判定 Acme Corp 为一个 ORG,即一个公司或组织。
我们来尝试另外一个例子:
- POST /_ml/trained_models/elastic__distilbert-base-cased-finetuned-conll03-english/deployment/_infer
- {
- "docs": {
- "text_field": "Xiaoguo said that Elastic was a great company in the world"
- }
- }
上面返回的结果为:
- {
- "predicted_value" : "[Xiaoguo](PER&Xiaoguo) said that [Elastic](ORG&Elastic) was a great company in the world",
- "entities" : [
- {
- "entity" : "Xiaoguo",
- "class_name" : "PER",
- "class_probability" : 0.9977009282482645,
- "start_pos" : 0,
- "end_pos" : 7
- },
- {
- "entity" : "Elastic",
- "class_name" : "ORG",
- "class_probability" : 0.9954152045770668,
- "start_pos" : 18,
- "end_pos" : 25
- }
- ]
- }
按照同样的方法,我们尝试 fill_mask:
- docker run -it --rm --network host \
- elastic/eland \
- eland_import_hub_model \
- --url https://liuxg.com:9200/ \
- --hub-model-id bert-base-uncased \
- --task-type fill_mask \
- --start
我们在机器学习的界面看到:
我们在 Kibana 中使用如下的测试:
- POST /_ml/trained_models/bert-base-uncased/deployment/_infer
- {
- "docs": {
- "text_field": "Paris is the [MASK] of France"
- }
- }
上面的查询返回结果:
- {
- "predicted_value" : "capital",
- "prediction_probability" : 0.9975749159388136,
- "predicted_value_sequence" : "Paris is the capital of France"
- }
我们再做一个测试:
- POST /_ml/trained_models/bert-base-uncased/deployment/_infer
- {
- "docs": {
- "text_field": "Beijing is the [MASK] of China"
- }
- }
上面的查询返回的结果为:
- {
- "predicted_value" : "capital",
- "prediction_probability" : 0.9989096738963879,
- "predicted_value_sequence" : "Beijing is the capital of China"
- }
- POST /_ml/trained_models/bert-base-uncased/deployment/_infer
- {
- "docs": {
- "text_field": "Beijing is the capital of [MASK]."
- }
- }
返回:
- {
- "predicted_value" : "china",
- "prediction_probability" : 0.9913708584213007,
- "predicted_value_sequence" : "Beijing is the capital of china."
- }
请注意 [MASK] 后面的那个点。它非常重要,否则你可能得不到你想要的结果。
- POST /_ml/trained_models/bert-base-uncased/deployment/_infer
- {
- "docs": {
- "text_field": "Amsterdam is a city in the [MASK]."
- }
- }
- {
- "predicted_value" : "netherlands",
- "prediction_probability" : 0.9997222917917266,
- "predicted_value_sequence" : "Amsterdam is a city in the netherlands."
- }
我们接下来安装另外一个模型。它能帮我们识别情绪:

我们使用如下的命令来安装这个模型:
- docker run -it --rm --network host \
- elastic/eland \
- eland_import_hub_model \
- --url https://192.168.0.3:9200/ \
- --elasticsearch-model-id sentiment-analysis \
- --hub-model-id distilbert-base-uncased-finetuned-sst-2-english \
- --task-type text_classification \
- --start
等上述命令完成后,我们在 Kibana 中进行查看:
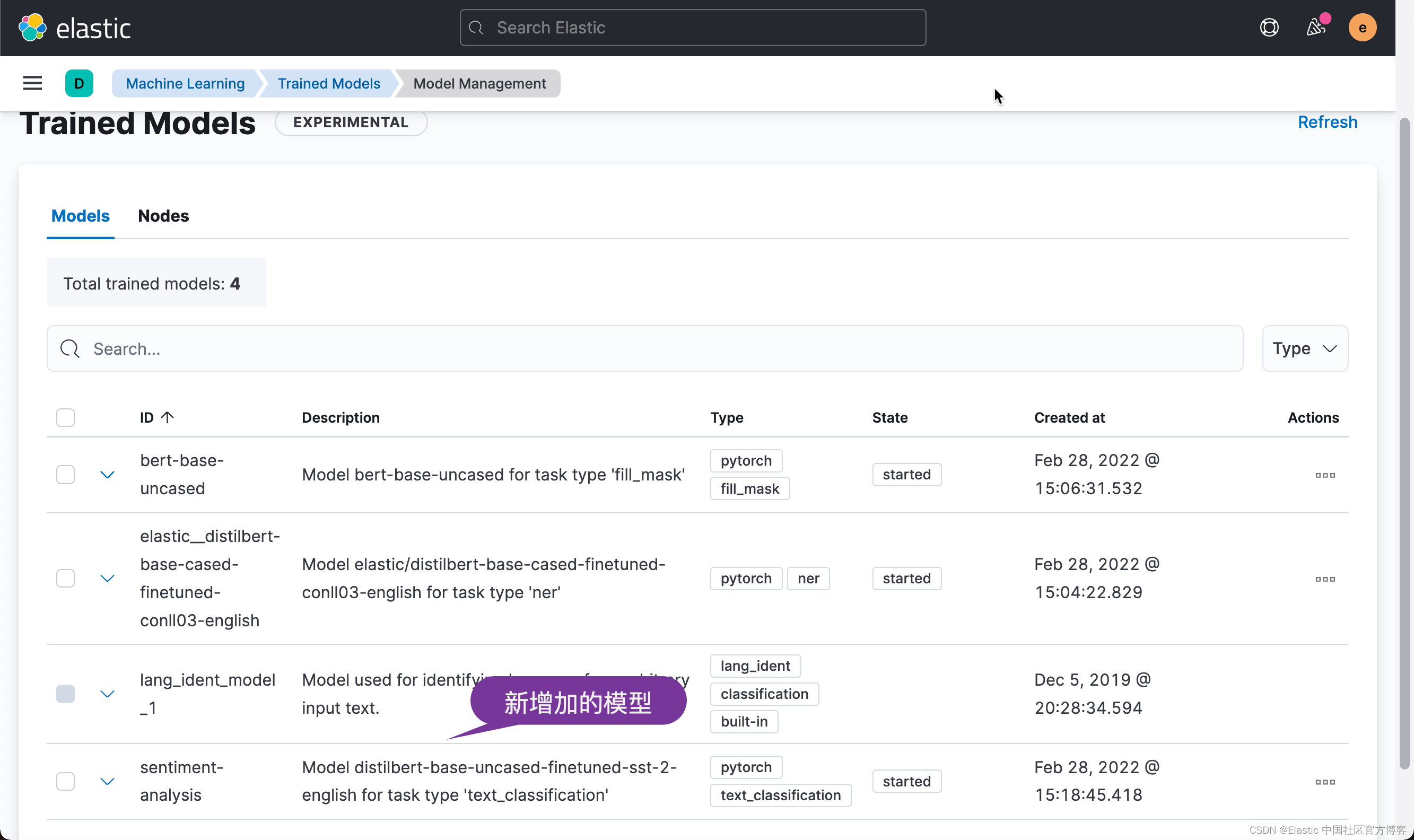
我们尝试如下的例子:
- POST _ml/trained_models/sentiment-analysis/deployment/_infer
- {
- "docs": { "text_field": "I didn't like the soundtrack from the movie Dune"}
- }
上面的命令返回:
- {
- "predicted_value" : "NEGATIVE",
- "prediction_probability" : 0.9973273752945672
- }
如果我们尝试如下的例子;
- POST _ml/trained_models/sentiment-analysis/deployment/_infer
- {
- "docs": { "text_field": "That movie was awesome!"}
- }
上面的命令返回:
- {
- "predicted_value" : "POSITIVE",
- "prediction_probability" : 0.9998595046118174
- }
从上面的句子中,我们可以看到一句话是积极的还是消极的。如果我们应用这样的 NLP 技术来分析影视评论,我们就很容易得出来有多少百分比的人评论是正面的,有多少是负面的。

