
- 1基于单片机按键控制看门狗仿真设计
- 2golang 和java区别详细讲解
- 3ctfshow 命令执行_blueiris ctfshow
- 4《C语言进阶》2--位操作_将操作数的各二进制位按位取反,然后将9按位取反并编程输出
- 5大模型日报-20240104_justine tunney
- 6Salesforce推出以AI驱动的高级数据分析产品
- 7漫说数据湖——如何建湖?如何做数据ETL?如何使用数据......
- 8人类和 AI 能够“双向奔赴”吗? | 近匠
- 9swift 实现flutter基本交互 - 传值篇_swift flutter 传值
- 10数仓知识11:Hadoop生态及Hive、HBase、Impala、HDFS之间的关系_hive 生态链关系
word2vec模型的导出和载入不同格式(model、vector、bin)模型的疑问与解答_word2vecmodel.bin
赞
踩
一、.model格式模型的导出与载入
from gensim.models import word2vec
# 训练模型并导出
sentences = list(word2vec.LineSentence('./question_corcus.txt'))
model = word2vec.Word2Vec(sentences, min_count=1)
model.save('./question.model')
print(model)
输出:Word2Vec(vocab=59, size=100, alpha=0.025)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
导出之后可以发现直接打开question.model的时候,出现乱码,这是正常的现象

# 导出模型
model2 = word2vec.Word2Vec.load("./question.model")
print(model2)
输出:Word2Vec(vocab=59, size=100, alpha=0.025)
- 1
- 2
- 3
- 4
这样子的save()方法和load()方法实现对接,只要能够维数差不多就可以
增量训练:后面新加的词,可以不用与旧词一起训练,而是可以训练加载好词向量后加在后面,不过还是要经过分词和去停词,最后在已有模型上使用两个函数
只能使用.model模型,而不能使用 .vector或者.bin模型,.model格式的文件可以继续训练,.vector格式的不可以
建立并加载词表
model.build_vocab(sentences_cut,update=True) #注意update = True 这个参数很重要
#训练
model.train(sentences_cut,total_examples=model.corpus_count,epochs=10)
# 增量训练
def add_train(new_sentence, model):
sentences_cut = []
for i in new_sentence:
sentences_cut.append(word_process(i))
model.build_vocab(sentences_cut, update=True) # 注意update = True 这个参数很重要
model.train(sentences_cut, total_examples=model.corpus_count, epochs=10)
model.save('D:\workbase\FAQ\FAQrobot-master\long_faq\dataset\question.model')
return model
sentence = ['如何考研上岸?']
model2 = add_train(sentence, model2)
print(model2)
输出:Word2Vec(vocab=61, size=100, alpha=0.025) 添加了“考研”和“上岸”两个词
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
二、.vector和.bin模型的导出与载入
from gensim.models import word2vec
# 训练模型并导出
sentences = list(word2vec.LineSentence('./question_corcus.txt'))
model = word2vec.Word2Vec(sentences, min_count=1)
model.wv.save_word2vec_format('./question.vector')
print(model)
输出:Word2Vec(vocab=59, size=100, alpha=0.025)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
打开输出的question.vector,可以看到已经训练好的每个词对应的向量信息,原因是保存方法model.wv.save_word2vec_format(),以向量的格式进行保存

因为.vector模型不适用于增量训练,因此在这里我们就不用去测试
直接来到加载模型
# 载入模型,以向量的形式
from gensim.models import KeyedVectors
model2 = KeyedVectors.load_word2vec_format('./question.model',binary=False)
print(model2)
输出:<gensim.models.keyedvectors.KeyedVectors object at 0x000001D0D39F2C18> 返回一个模型对象
- 1
- 2
- 3
- 4
- 5
使用这个返回的模型对象可以调用一些方法,用于计算相似度之类
-
两段文本之间的相似度计算:需要将文本分词和去停词,得到词列表
最大距离 :distance=model.wv.wmdistance(sent1, sent2)
余弦相似度:similarity=model.wv.n_similarity(sent1, sent2)
distance越小越相似,similarity越大越相似 -
两个词之间的相似度计算
similarity=model.wv.similarity(w1, w2)
eg. pprint.pprint(model2.similarity(‘百度’,‘登录’))
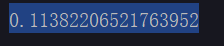
-
向量之间的相似度计算
model.wv.cosine_similarities(vector_1, vectors_all) -
找出前N个最相似的词的相似度
model2.most_similar('百度')或者model2.most_similar_cosmul('百度') 余弦相似度

-
关联相似度查询
result=model.wv.most_similar(positive=None, negative=None, topn=10, restrict_vocab=None, indexer=None)
eg.pprint.pprint(model2.wv.most_similar_cosmul(positive=[‘百度’,‘登录’],negative=[‘账号’]))

常用的api方法:
model.init_sims(replace=True)模型锁定,可以提高模型和后续任务的速度,同时也使得模型不能训练了,read only!
print(model.wv[‘男人’]) 查看某个单词的词向量
print( model.wv.index2word) 获取模型中全部的词
print(model.wv.vocab) 查看词典

