
- 12022届秋招,从被拒到上岸 | 谈谈YK菌在2021年的经历与收获_不好好学习被sp
- 2详解iOS开发中处理屏幕旋转的几种方法_swift开发ios14手机旋转
- 3[[i-OTO]] "Annabelle" [[Full Movie 2014]] ONLINE HD Quality
- 4OpenHarmony实战:烧录Hi3516DV300开发板
- 5Pytorch入门实战(5):基于nn.Transformer实现机器翻译(英译汉)
- 6新基建风向标:关于ChatGPT,必知10件事!_并不是,我是基于gpt-2模型的chatgpt,相比于gpt-4,我还远远不够强大,但我会不
- 7单光感pid巡线_PID非常好的光感巡线思路
- 8YOLOv5与CVAT联合进行预标注并修正labels--[全网独家]_cvat标注好的图片怎么调整
- 9upload-labs·文件上传(靶场攻略)_uploads labs
- 10下一代Windows命名为Win 11?微软的下一步要来了
推荐系统架构详解_推荐系统整体架构总结
赞
踩
推荐系统全貌
一、导论
之前对推荐系统进行学习的过程中,发现自己只是拘泥于其中的一小部分进行学习,没有一个全局系统的认知,经常容易陷入困惑,因此借分享会机会,将推荐系统架构梳理一遍,在梳理的过程中才对推荐系统有了更加清楚的整体认知,并知道了自己还有哪些没学到,也相当于给自己后续的学习提供了方向。
二、推荐系统介绍
推荐系统出现的原因:
- 信息过载
- 个体个性化表达的需要
- 在特定场景下,个人对自己的需求不是那么明显
推荐系统解决的问题:
本质是在用户需求不明确的情况下,从海量信息中为用户寻找感兴趣信息的技术手段。结合用户的信息(构建用户画像),物品(广告)画像,利用机器学习/深度学习技术构建兴趣模型,为用户提供精准推荐。
推荐系统应用领域:
- 电商(阿里,淘宝,京东)
- 视频(Netflix,优酷,YouTube等)
- 音乐(网易云等)
- 社交(Facebook)
- 新闻(头条,天天快报等)
- 生活服务类(美团、携程等)
- …
如果将推荐系统简单拆开来看,推荐系统主要是数据,算法和架构三方面组成。
-
数据提供了信息。数据储存了信息,包括用户与内容的属性,用户的行为偏好、历史行为记录等。
-
算法提供了逻辑。数据通过不断的积累,存储了巨量的信息。在巨大的数据量与数据维度下,人已经无法通过人工策略进行分析干预,因此需要基于一套复杂的信息处理逻辑,基于逻辑返回推荐的内容或服务。
-
架构解放了双手。架构保证整个推荐自动化、实时性的运行。架构包含了接收用户请求,收集、处理,存储用户数据,推荐算法计算,返回推荐结果等。有了架构之后算法不再依赖于手动计算,可以进行实时化、自动化的运行。例如在淘宝推荐中,对于数据实时性的处理,就保证了用户在点击一个物品后,后续返回的推荐结果就可以立刻根据该点击而改变。一个推荐系统的实时性要求越高、访问量越大那么这个推荐系统的架构就会越复杂。
三、推荐系统的整体架构
推荐的框架主要有以下几个模块:
1、协议调度:请求的发送和结果的回传。在请求的过程中,用户会发送自己的ID,地理位置等信息。结果会回传返回推荐给用户的结果。
2、推荐算法:算法按照一定的逻辑未用户产生最终的推荐结果。
3、消息队列:数据的上报与处理。根据用户的ID,拉取用户的性别,之前的点击,收藏等用户消息。而用户在APP中产生的新行为,例如新的点击将会存储在存储单元里面。
4、存储单元:不同的数据类型和用户会储存在不同的存储单元中。
四、用户画像
4.1 用户标签
标签是我们对多维事物的降维理解,抽象出事物更具有代表性的特点。例如:我们永远都无法深入的了解一个人,但是可以通过一个一个标签来刻画,所有的标签最终会构建一个立体的画像,一个详细的用户画像会更有利于我们理解用户,进而推荐更加适合的内容。
4.2 用户画像分类
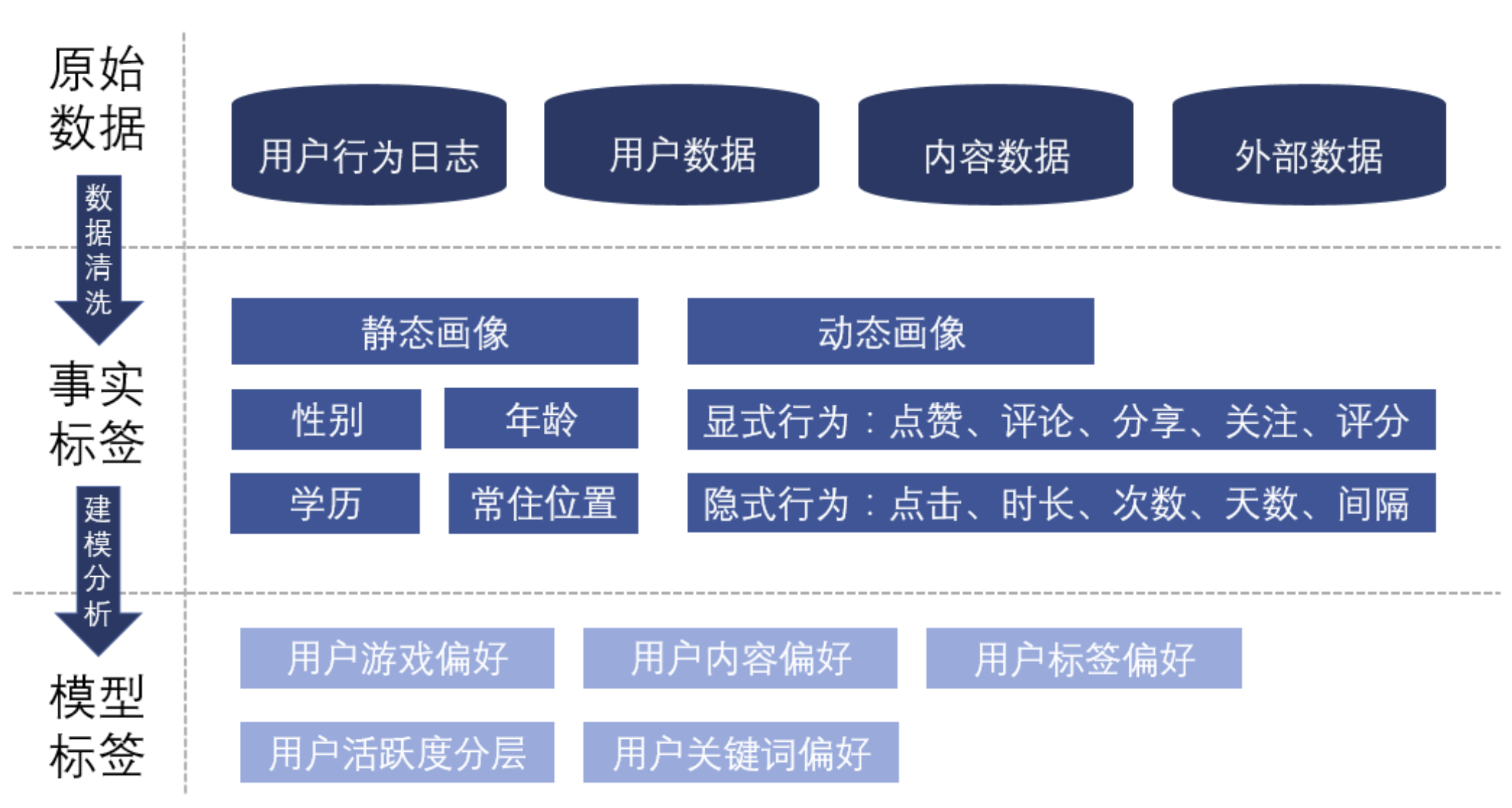
1、原始数据
原始数据一共包括4方面
- 用户数据:性别、年龄、渠道、注册时间等。
- 内容数据:商品的品类,商民的描述,标签等。
- 用户与内容的交互:基于用户的行为,了解用户喜欢的商品类别,关键词等。
- 外部数据:单一的产品只能描述用户的某一喜好,外部数据标签可以让用户更加立体。
2、事实标签
事实标签可以分为静态画像和动态画像的属性。例如用户的自然属性,比较稳定,具有统计性意义。
- 静态画像:用户独立于产品场景之外的属性
- 动态画像:用户在场景中所产生的线性行为或隐性行为。
- 显性行为:
- 隐性行为:这两个都很熟悉了所以不打算再赘述。
3、模型标签
模型标签是由事实经过加权计算或是聚类分析所得。通过一层加工处理,标签包含的信息量得到提升,在推荐过程中效果更好。
- 聚类分析:例如根据用户的活跃度进行聚类,及那个用户分为:高活跃-低活跃-中活跃三类
- 加权计算:根据用户的行为将用户的标签进行加权计算,得到每一个标签的分数,用于之后推荐算法的计算。
五、内容画像
内容画像:例如对文章中的新闻资讯类推荐,需要采用NLP技术对文章的标题,正文等提取关键词。找到对应的标签。视频除了对于分类,标题关键词的抓取之外,还以来图片处理的技术。
环境变量:对于推荐系统来说,环境画像也十分重要。例如在短视频推荐场景每用户在看到一条视频所处的时间,地点以及当时浏览的前文内容,当天浏览的内容,时间等都是十分重要的变量。
六、算法构建
6.1 推荐算法构建
推荐算法本质上是一种信息处理逻辑,当获取了用户与内容的信息之后,按照一定的逻辑处理信息后,产生推荐结果。最简单的是根据据热度排行榜。
6.2 推荐算法的步骤
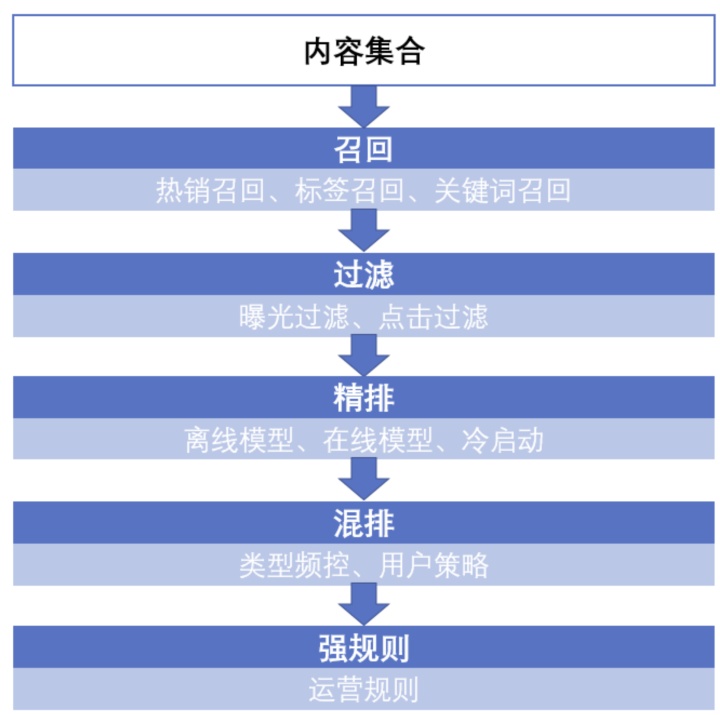
1、召回
a、召回目的
召回是推荐系统的第一阶段,主要是根据用户和商品部分特征,从海量成品库里,快速召回一小部分用户潜在感兴趣的物品,然后交给排序环节。这部分处理的数据量非常打,通常要求使用的策略,模型和特征都不能太复杂。
b、召回方法(传统的是采用多路召回模式)

传统的标准召回结构一般是多路召回,如上图所示,如果我们根据召回路是否有用户个性化因素存在来划分,可以分为两大类:一是无个性化因素的召回路,比如热门商品/热门文章/历史点击率高的物料的召回;二是有个性化因素在内的召回路,比如用户兴趣标签召回,主题召回等。
传统召回模式向着embedding演变:若重新理解上述的个性化召回路,可以把某个个性化召回路看作是:单特征模型排序的排序结果,即可以把某路召回,看成是某个排序模型的排序结果,只不过这个排序模型只使用单一特征进行排序。
如果使用上面角度看待个性化因素召回路(即没一种召回都是单一特征某一模型排序结果),那么在召回阶段引入模型,无非是把单特征排序,拓展成多特征排序的模型;而多路召回,则可以通过引入多特征,被融入到独立的召回模型,找到它的替代品。(所以,随着技术的发展,embedding基础上的模型召回,必然是符合技术发展潮流的方向)
-
热度召回(热门):根据item的曝光量、点击量,已经点击做筛选,三者均满足要求的item进入item热度池,作为热度召回的来源,热度池需要实时维护更新。
-
标签召回:对于不同标签的item,按照标签,时间等进行召回,每个类别召回n个items,作为召回候选集。
-
LDA主题召回:根据item(例如是新闻的)主题召回,结合用户近期画像。
-
探索类召回:随机选取两个用户从没看过的类别作为探索类召回候选集。
-
基于内容召回(CB召回):使用item之间的相似性来推荐用户喜欢的item相似的item。
-
协同过滤(召回)(CF):同时使用query和item之间的相似性来推荐。
-
时间召回:将一段时间内最新的内容召回,在新闻视频等时效性的领域常用。是常见的几种召回方法之一。
-
基于FM模型召回:FM是矩阵分解的推荐算法,核心是二阶特征组。
-
基于深度神经网络召回:利用深度神经网络来生成相应的候选集。
c、更多召回模型
- YouTube DNN 召回
- DSSM语义召回
- TDM深度匹配召回
- …

2、过滤(又可以叫做粗排)
粗排作用:粗排是为了进一步减少召回的item数量,减轻精排压力,同时不损失线上效果。
双塔DNN模型做推荐系统粗排
1、理论
双塔DNN结构
2、工程实践
3、精排
排序是推荐系统的第二阶段,从召回阶段获取少量的商品交给排序阶段,排序阶段可以融入较多特征。使用复杂模型,来精准地做个性化推荐。排序所强调地是快和准,快指的是高效地反馈结果,准指的是推荐结果准确性高。
具体来说,在生成候选对象之后,另外一个模型会对生成地候选对象进行打分和排序,得到最后要推送到Item列表。推荐系统可能具有是哟不同来源地多个召回队列,例如:
- 矩阵分解模型的相关item。
- 根据各类标签下的用户item。
- “本地”与“非本地”项目,即需要考虑地理位置/
- 热门或流行item
- 社交网络
a、精排模型
- 精排的不同类别
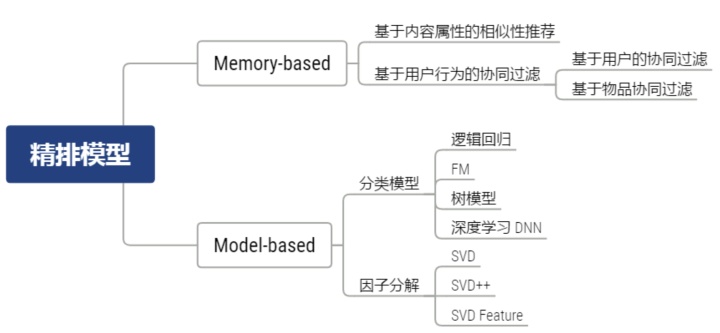
-
精排模型的基本原理
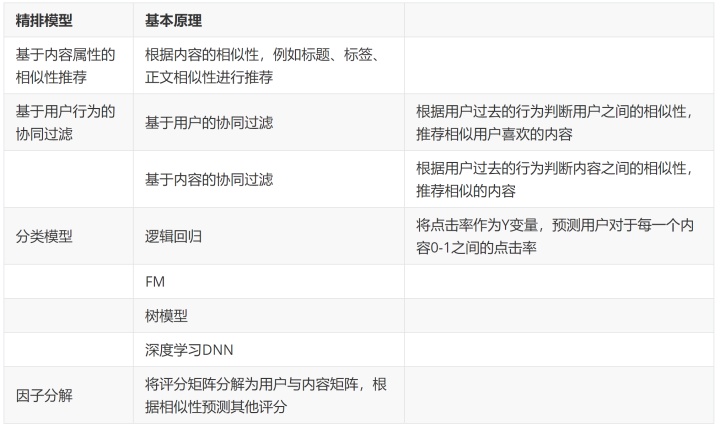 - 其他精排模型
- 其他精排模型
4、混排
5、强规则
七、算法衡量的标准
- 硬指标:对于大多数的平台而言,推荐系统最重要的作用是提升一些“硬指标”。利润也新闻推荐中的点击率,但是单纯以点击率提升为目标,最后容易成为一些低俗内容,“标题党”的天下了。
- 软指标:除了硬指标,推荐系统还需要很多“软指标”以及“反向指标”来衡量除了点击等之外的价值。好的推荐系统能够拓展用户的事业,发现那些他们感兴趣,但是不会主动获取的内容。同时推荐系统还可以帮助平台挖掘被埋没的优质长尾内容,介绍给感兴趣的用户。

7.1 获得推荐的效果

主要可以通过离线实验,用户调查,在线实验三种方法。
- 离线实验:通过反复在样本数据进行实验来获得算法的效果。方法比较简单,明确,但是由于数据是离线的,基于过去的历史数据,不能够真实反映线上效果,同时还需要时间窗口的滚动来保证模型的客观性和普适性(即:每隔一段时间进行新的离线实验)
- 用户调查:当
- 在线测试(AB Test)

