
- 1LeetCode 27题 移除元素 -- JavaScript_leecode移除元素
- 2Simulink 快速入门(二)--创建简单模型_simulink模型
- 32、SQL学习:排序查询and分组查询_分组排序查询
- 4AI大模型低成本快速定制秘诀:RAG和向量数据库_rag和向量库的关系
- 5python-使用scikit-learn工具计算文本TF-IDF值_python sklearn tf-idf
- 6mysql 将date字段默认值设置为CURRENT_DATE_mysql date 默认设置成当前时间
- 7Atlas 200I DK A2(小藤) 开箱_atlas200
- 8MySQL的指令大全和注意事项(强烈推荐收藏)_mysql命令语句大全
- 9视频码率
- 10postgresql 语句_postgresql 循环
YoLov5从环境搭建到训练自己的数据,以良性皮肤痣和恶性皮肤痣的分类与血红细胞类型目标检测识别为例(非常详细,包括环境安装配置、源码下载、配置运行环境、代码改写、数据集制作、训练、预测和优化)等_yolov5皮肤病分割
赞
踩
一、软硬件的准备与虚拟环境搭建
1、Python环境:直接安装Anaconda 3-2022
(1)百度网盘下载地址(下载文件中附了非常详细的安装教程):https://pan.baidu.com/s/1KQNOlYU-GMKbkPGcip1Hzw?pwd=5678
(2)直接网上百度下载和安装,非常多教程,这里直接略过
安装好之后,可以打开Anaconda Prompt(install),查看python版本:
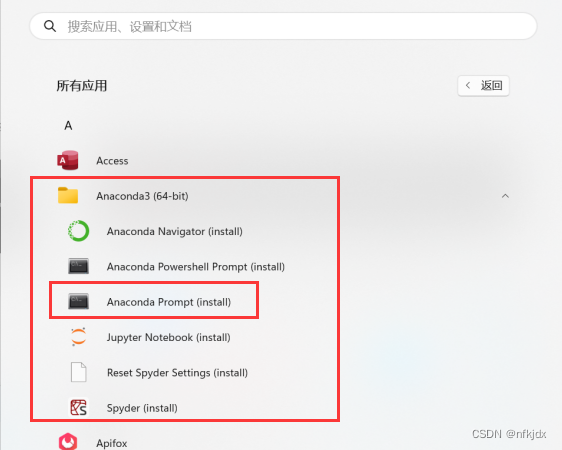
(3)将安装的Anaconda加入电脑的系统环境变量里面
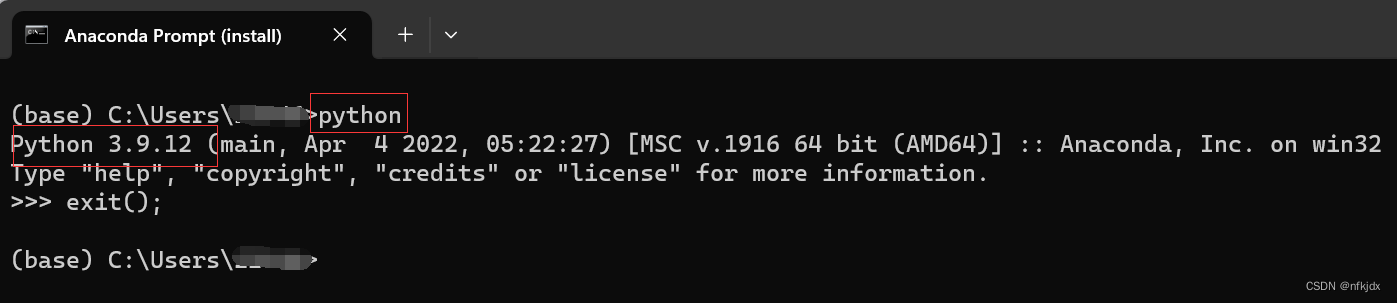
3.1 如下图所示:直接搜索系统环境变量,点击 编辑系统环境变量
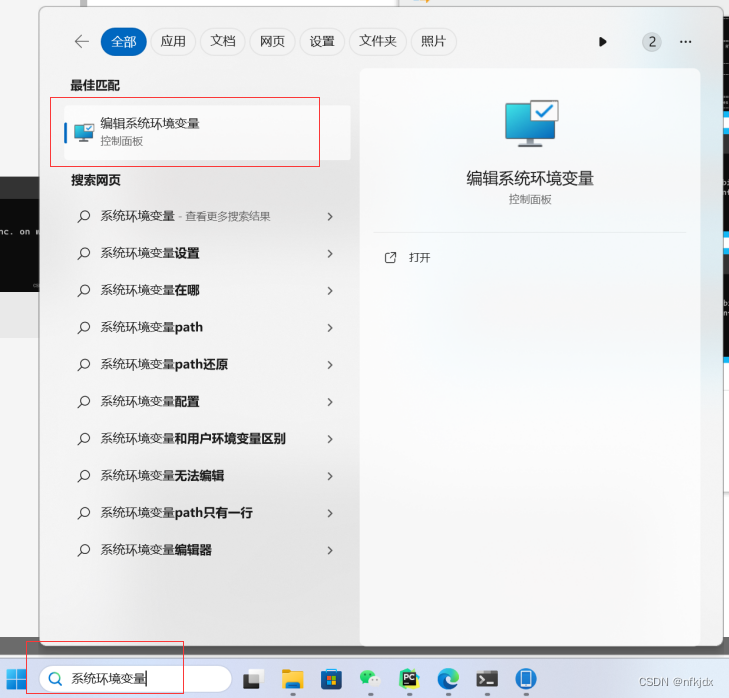
3.2 点击 右下角环境变量
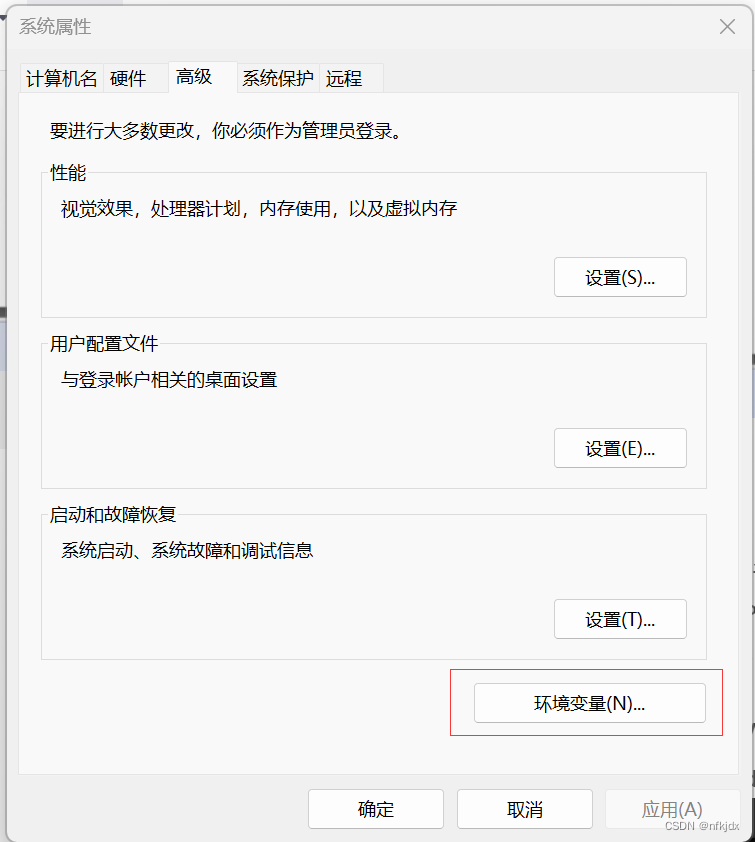
3.3 进入之后可以看见有xxx用户变量和系统变量两部分,里面都有path变量,选择path变量,点击编辑
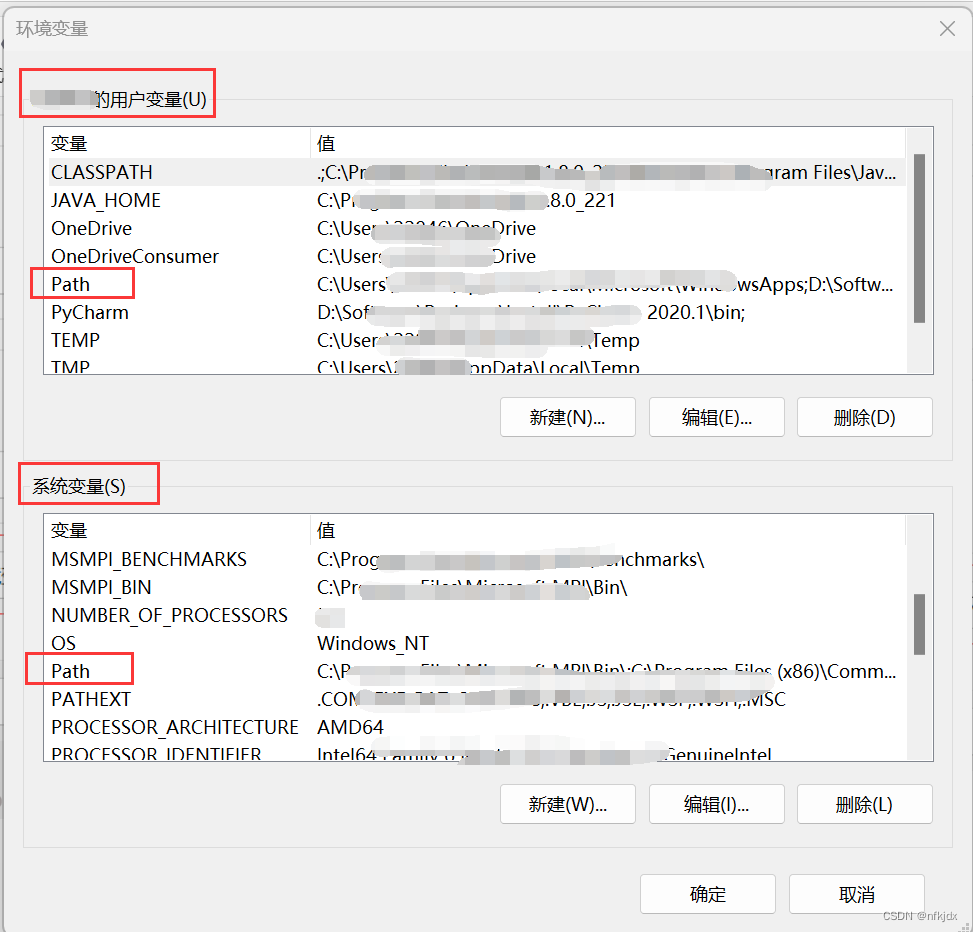
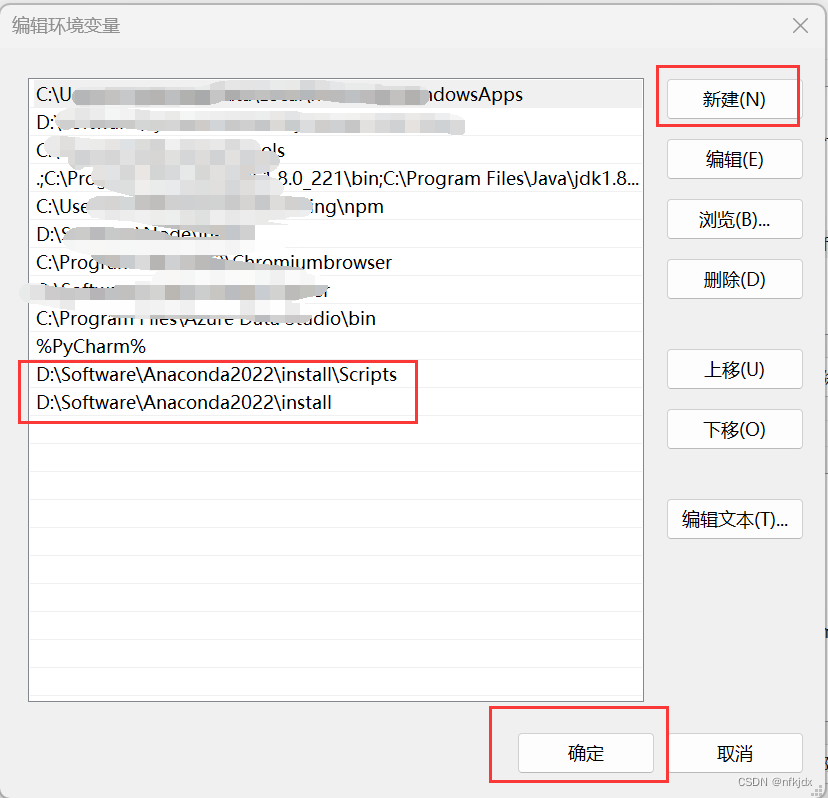
3.4 进入之后点击新建,将Anaconda的安装路径和Scripts路径填写进去,最后点击确定就完成了环境变量的添加(注意:每个页面都有确定,请一一点击确定)
2、软件:安装Pycharm 2020.1 x64 软件(这是专业版)
(1)百度网盘下载地址(下载文件中附了非常详细的安装教程):https://pan.baidu.com/s/1KQNOlYU-GMKbkPGcip1Hzw?pwd=5678
(2)直接网上百度下载和安装,非常多教程,这里直接略过

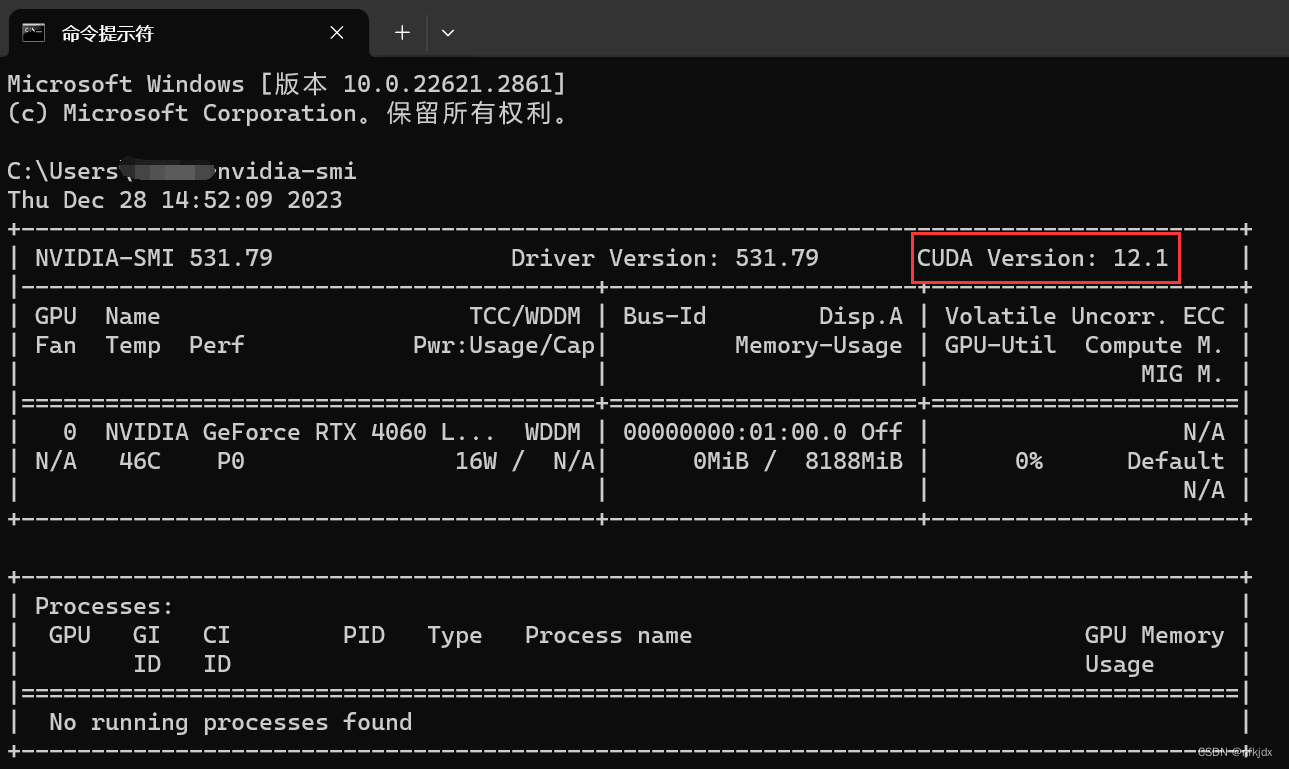
3、查看当前电脑的cuda版本,为后面安装pytorch做准备
打开cmd的shell,输入命令:nvidia-smi,cuda版本为12.1
4、打开Anaconda Prompt(install),创建虚拟环境,如下图所示:
1、创建虚拟环境
方法一:默认情况下虚拟环境创建在Anaconda安装目录下的envs文件夹中
conda create --name yolov5 #yolov5是虚拟环境名称(自定义)
- 1
方法二:如果想将虚拟环境创建在指定位置,使用–prefix参数即可:
conda create --prefix D:\Software\Envs\yolov5 python==3.9 #yolov5是虚拟环境名称(自定义)
- 1
2、查看已经创建好的虚拟环境:
conda env list
- 1

3、激活虚拟环境并查看下面已安装的库

4、如果想要删除yolov5这个虚拟环境:
conda remove --prefix D:\Software\Envs\yolov5 --all
- 1
二、下载yolov5项目的代码
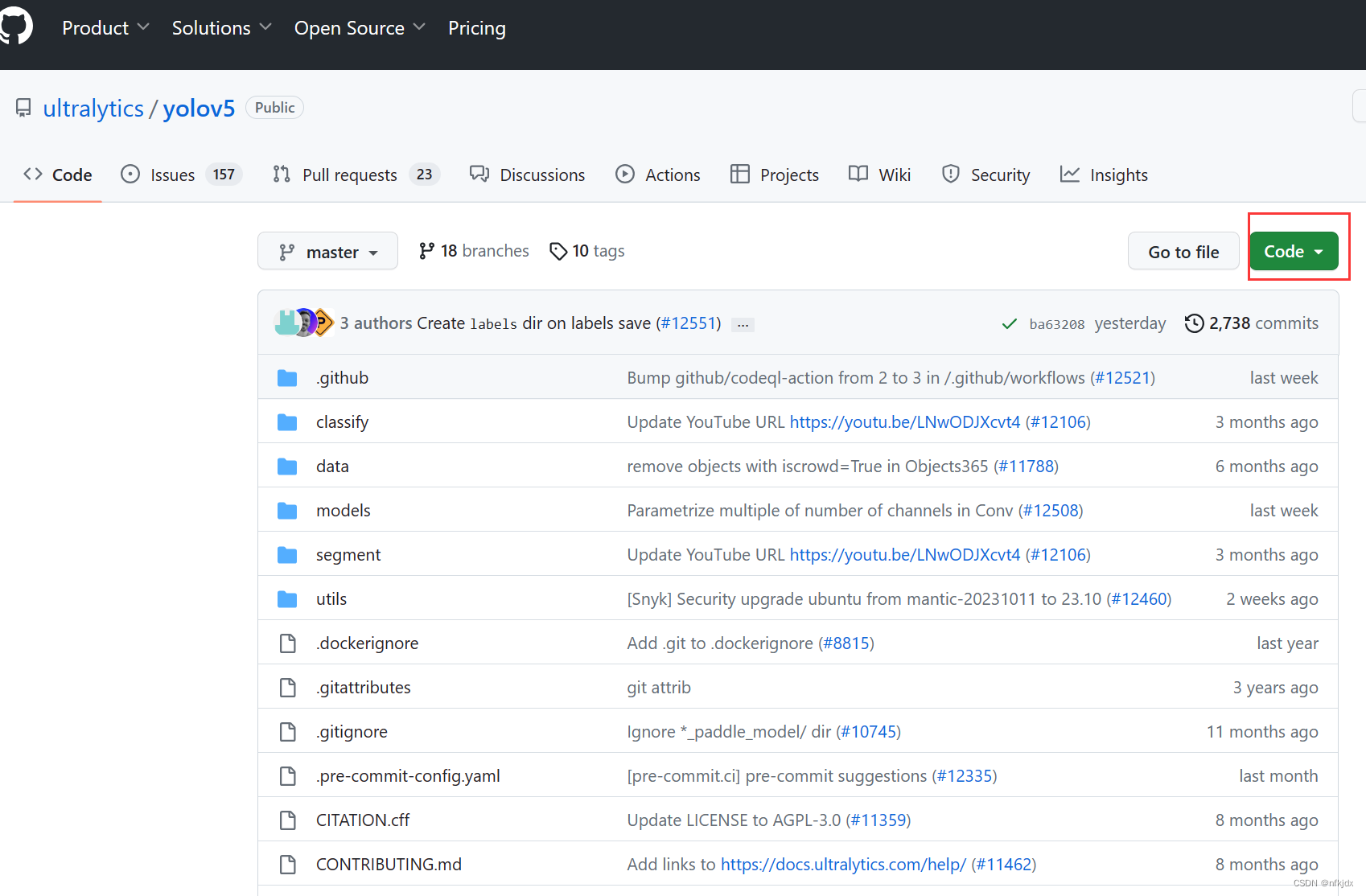
在github官网下载源码
下载网址:https://github.com/ultralytics/yolov5
- 1
三、使用安装的pycharm软件打开项目并配置运行环境
1、打开软件,点击左上角的File,再点击Open

2、打开之后,在相应的路径下找到项目,点击ok,项目就被打开了
3、运行环境的配置:再一次点击左上角的File,接着点击Settings
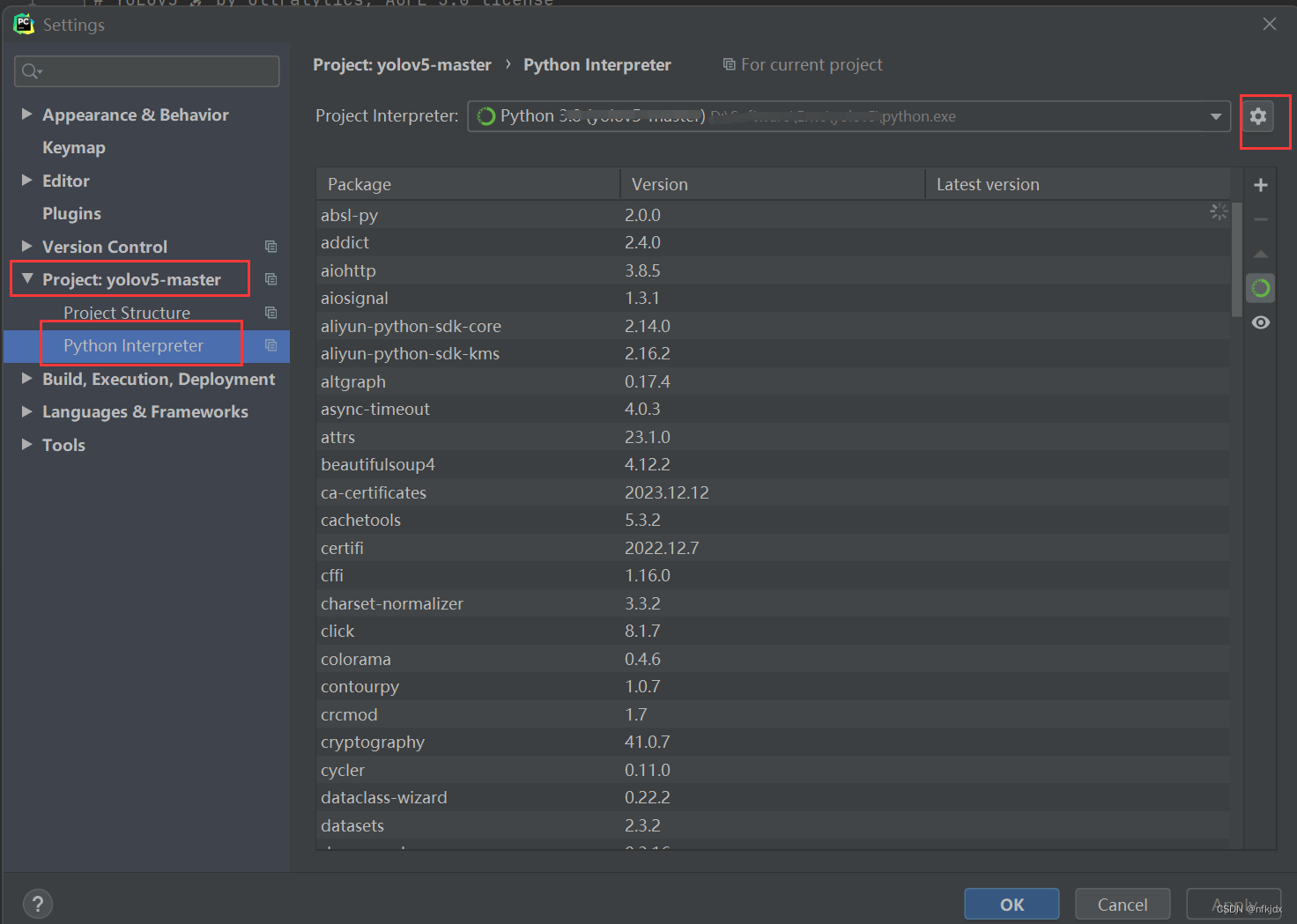
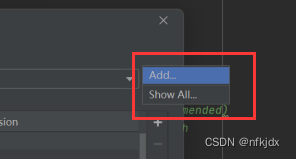
4、进入之后,首先在页面左边找到 【Project:你的项目名】按钮并点击,再点击里面的 Python Interpreter,接着点击右上角的设置符号,里面会出来Add与Show All两个选项,再点击Add,如下图所示:
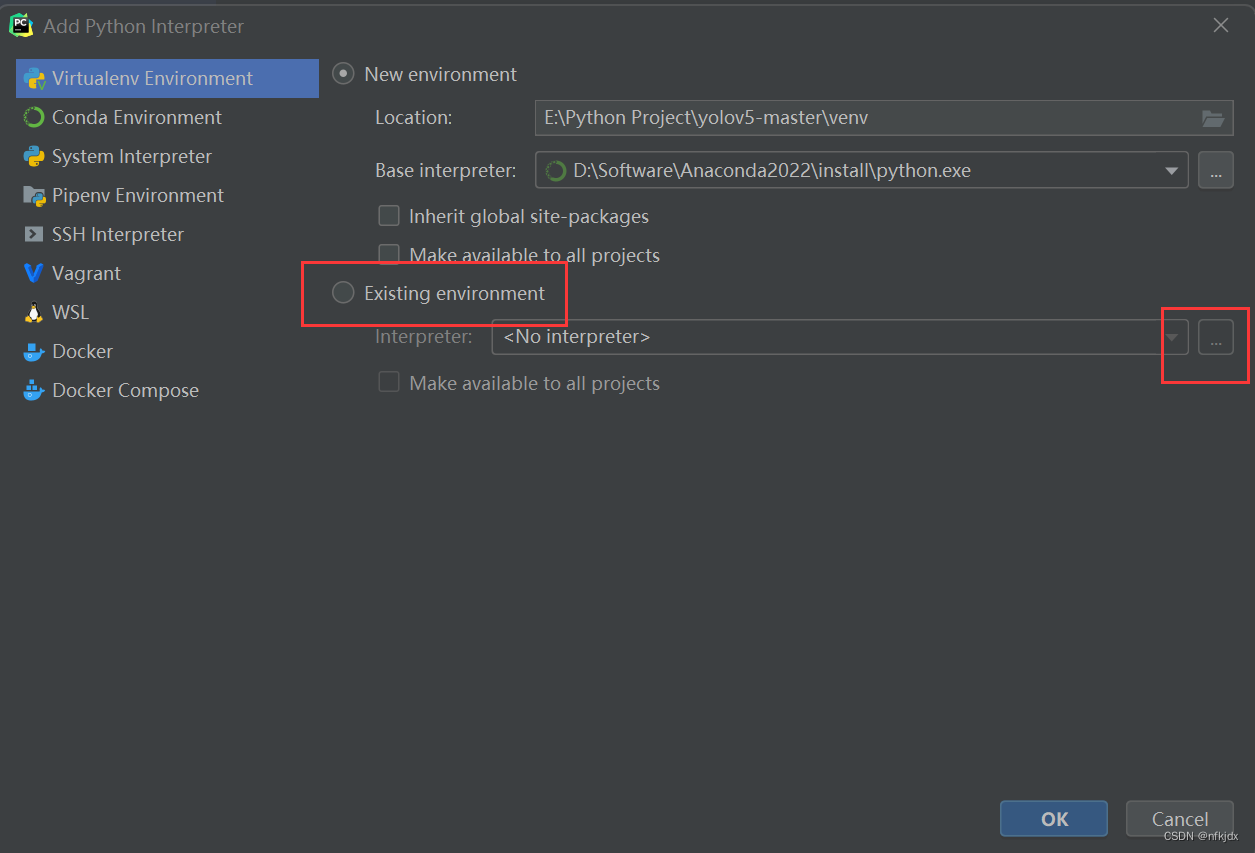
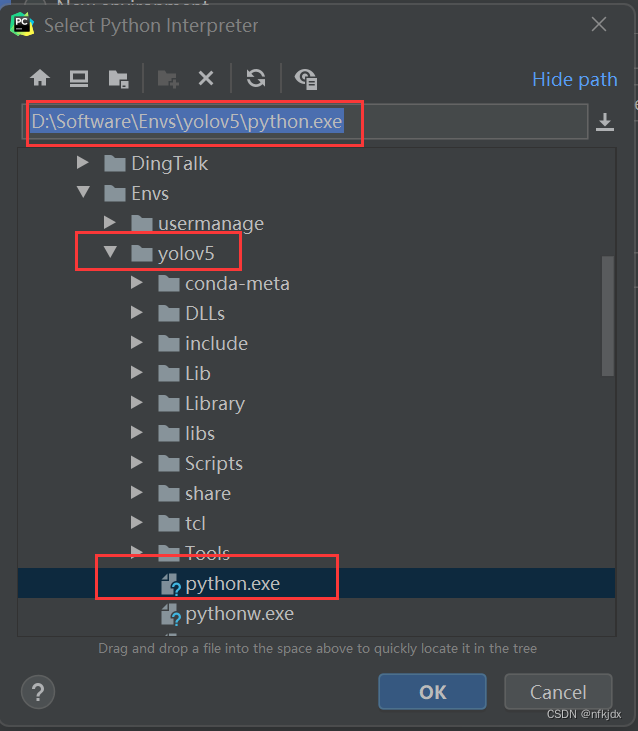
5、进入之后,选择Existing environment,再进行环境的选择,最后点击确定即可(在这里我选择了前面创建的yolov5环境,注意:选择到环境下面的python.exe路径才可以)
到这里项目的打开和运行环境的设置就完成了!
四、torch、opencv等库的安装
1、在上一个步骤中,我们已经使用pycharm打开了项目并配置了运行环境,接下里在打开的项目中找到requirements.txt文件并打开,这里面正是所需要安装的库,如下图所示:
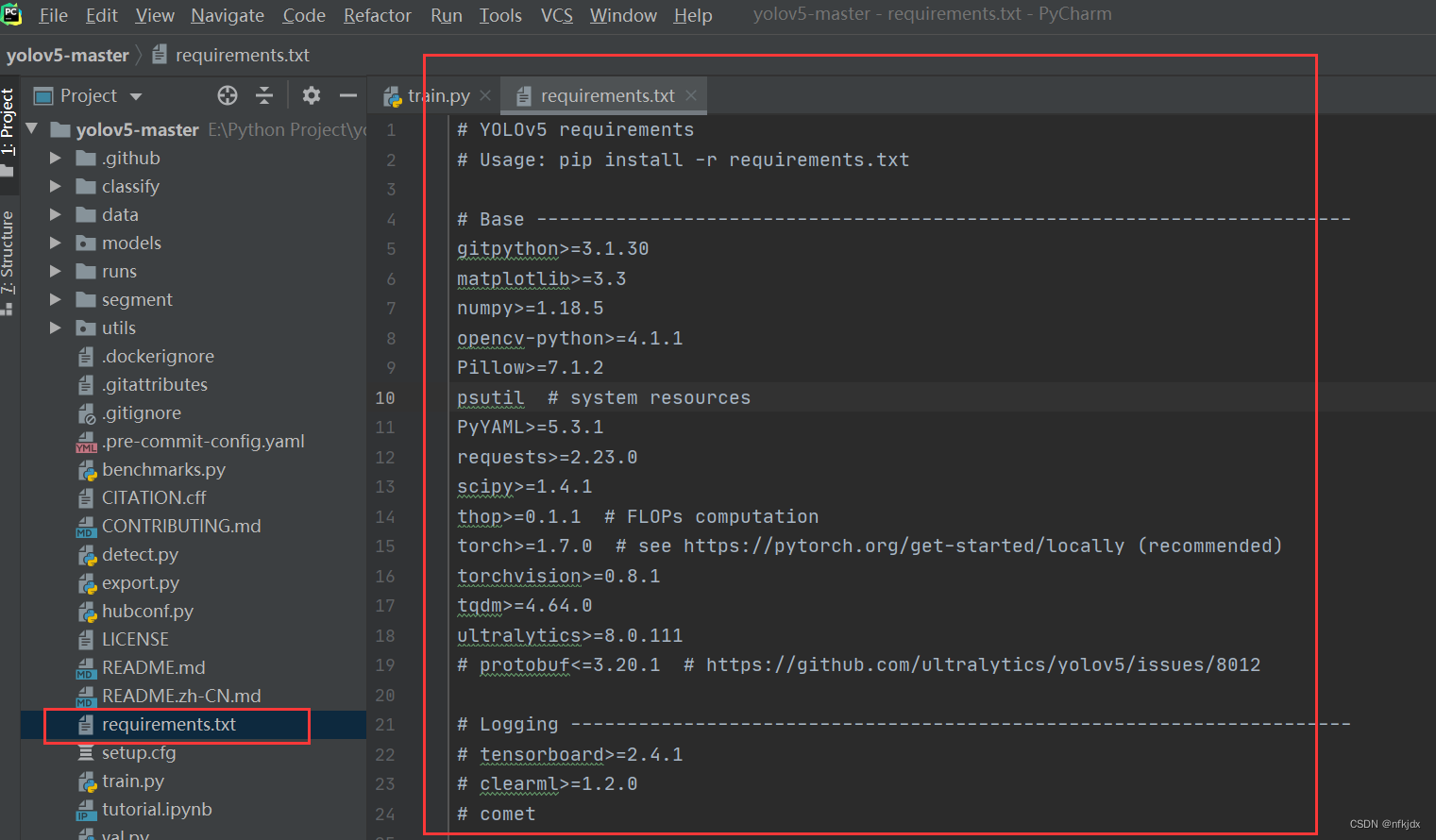
2、首先安装除torch之外的所有包(因为torch需要与cuda对应):可以使用清华、华为等源地址快速安装
清华大学 :https://pypi.tuna.tsinghua.edu.cn/simple/
阿里云:http://mirrors.aliyun.com/pypi/simple/
中国科学技术大学 :http://pypi.mirrors.ustc.edu.cn/simple/
华中科技大学:http://pypi.hustunique.com/
豆瓣源:http://pypi.douban.com/simple/
腾讯源:http://mirrors.cloud.tencent.com/pypi/simple
华为镜像源:https://repo.huaweicloud.com/repository/pypi/simple/
比如:pip install -i https://pypi.tuna.tsinghua.edu.cn/simple/ matplotlib==3.3
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
3、安装torch:通过步骤一中的第3小点知道了本机cuda版本
(1)方式一(在线安装):打开网址:https://pytorch.org/get-started/previous-versions/,查找本机对应的torch,并通过命令在线安装,如下图所示;
# CUDA 11.8
pip install torch==2.0.0+cu118 torchvision==0.15.1+cu118 torchaudio==2.0.1 --index-url https://download.pytorch.org/whl/cu118
- 1
- 2

(2)方式二(离线安装):打开网址:https://download.pytorch.org/whl/torch_stable.html
https://download.pytorch.org/whlversions/,查找到对应的torch、torchaudio、torchvision并下载下来,通过命令:pip install 下载地址+文件 进行安装

安装好之后,可以通过pip list 或者 conda list查看:

五、良性皮肤痣和恶性皮肤痣数据集的制作(分类)
1、数据集下载
url:https://www.cvmart.net/
大家打开网址,进行注册登录,再点击里面的数据集就可以去筛选自己需要的数据进行下载。
- 1
- 2

2、简介
下载文件解压后,里面有三个文件夹,分别是训练集(train)、测试集(test)和数据(data);
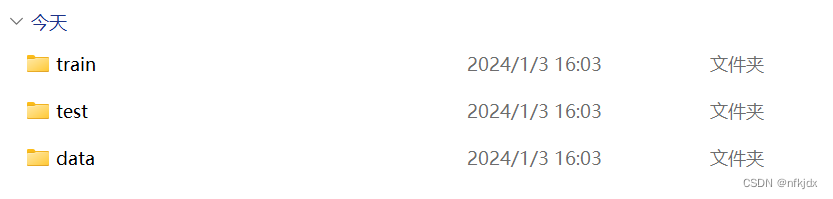
而训练集中又包含两个文件夹,分别是:“malignant” 常用来描述恶性的、有害的或恶意的事物;“benign” 常用来描述良性的、无害的或温和的事物。测试集里面也是一样,只是数据量不同,data里面就是测试集和训练集。

其中:
train文件夹中malignant有1197张图片,benign有1440张图片;
test文件夹中malignant有300张图片,benign有360张图片。
训练集 : 测试集 = 2637 : 660 = 4 : 1
- 1
- 2
- 3
- 4
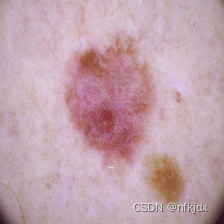
malignant恶性图片实例:
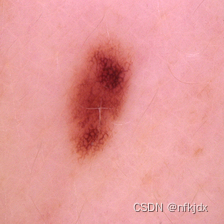
benign良性图片实例:
六、改写代码,进行分类训练实战
1、首先下载官方的分类预训练模型
下载地址:https://github.com/ultralytics/yolov5/releases/download/v6.2/yolov5s-cls.pt
- 1
2、将下载的模型放入项目的classify文件夹里面
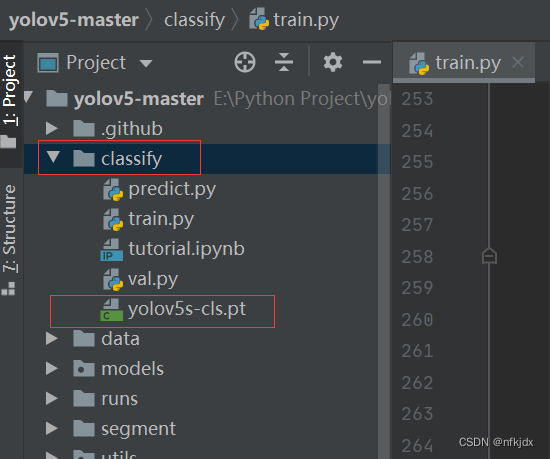
3、打开classify里面的train.py文件,将下载好的预训练模型位置添加

4、再将下载好的训练集与测试集数据位置添加
(1)先在classify里面建立一个data文件夹,再将train与test文件夹放在里面
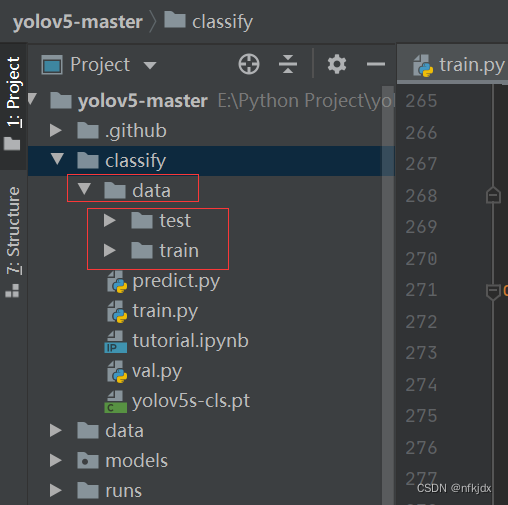
(2)在train.py里面添加数据位置
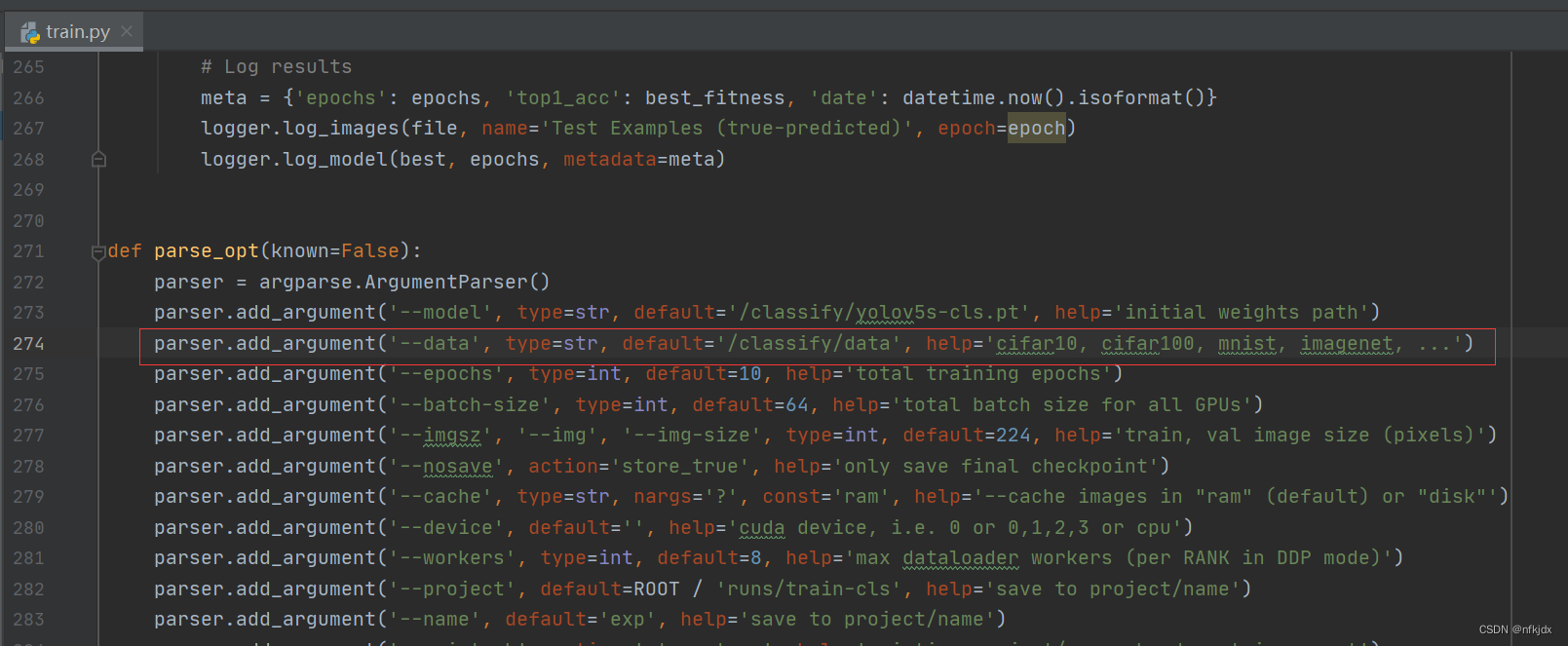
(3)在train.py里面设置运行的epochs、batch-size等,根据自己电脑或者服务器的配置进行调整即可!
在 YOLOv5 模型中,argparse.ArgumentParser 用于解析命令行参数。下面是一些常用的参数说明和设置示例:
--img-size:指定输入图像的尺寸。例如,--img-size 640 表示将输入图像的宽度和高度调整为 640 像素。
--batch-size:指定训练时每个批次中的图像数量。例如,--batch-size 16 表示每个批次中包含 16 张图像。
--epochs:指定训练的迭代轮数。例如,--epochs 100 表示进行 100 轮迭代训练。
--data:指定数据集的配置文件路径。例如,--data data.yaml 表示使用名为 data.yaml 的配置文件。
--cfg:指定模型的配置文件路径。例如,--cfg models/yolov5s.yaml 表示使用名为 yolov5s.yaml 的模型配置文件。
--weights:指定预训练模型的权重文件路径。例如,--weights weights/yolov5s.pt 表示使用名为 yolov5s.pt 的权重文件。
--device:指定使用的设备,如 --device cpu 表示使用 CPU 进行训练,--device 0 表示使用 GPU 0 进行训练。
--name:指定训练任务的名称。例如,--name my_model 表示训练任务的名称为 my_model。
--resume:指定是否从之前的训练中恢复。例如,--resume 表示从之前的训练中恢复,--resume weights/last.pt 表示从 last.pt 权重文件中恢复训练。
这些参数可以根据具体的训练需求进行设置。可以通过在命令行中使用 --help 参数来查看更多参数选项和说明。例如,python train.py --help 可以显示出所有可用的参数选项和说明。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
本人这里设置为:

5、运行train.py文件,训练模型
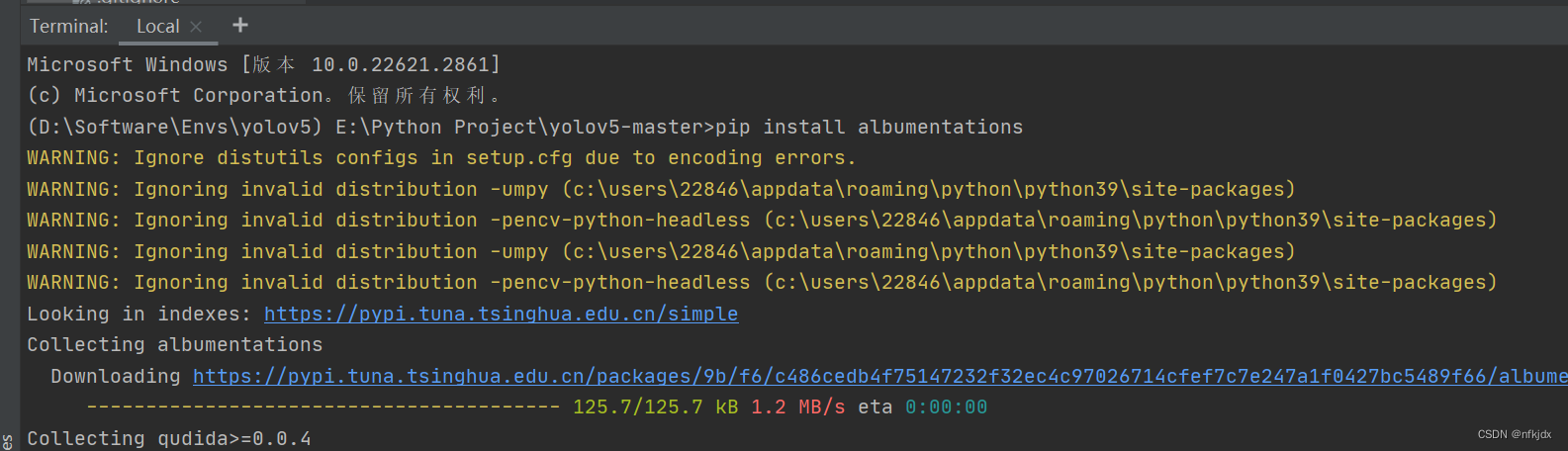
(1)运行过程中可能会报错:
我这里就报错了:缺少下面这个库,安装即可。如果遇见类似错误,根据提醒信息进行修改就可以!

(2)运行过程和结果:
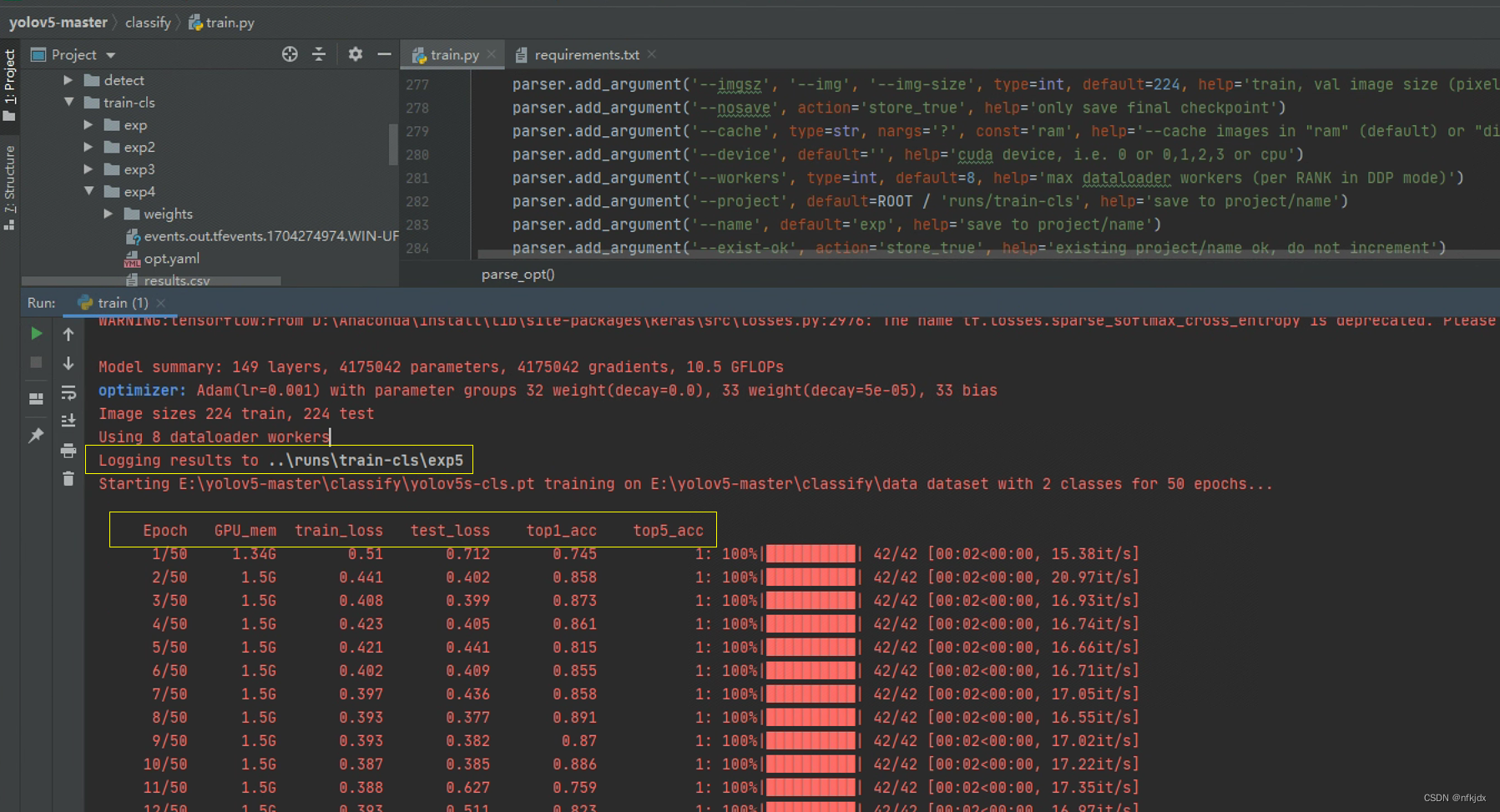
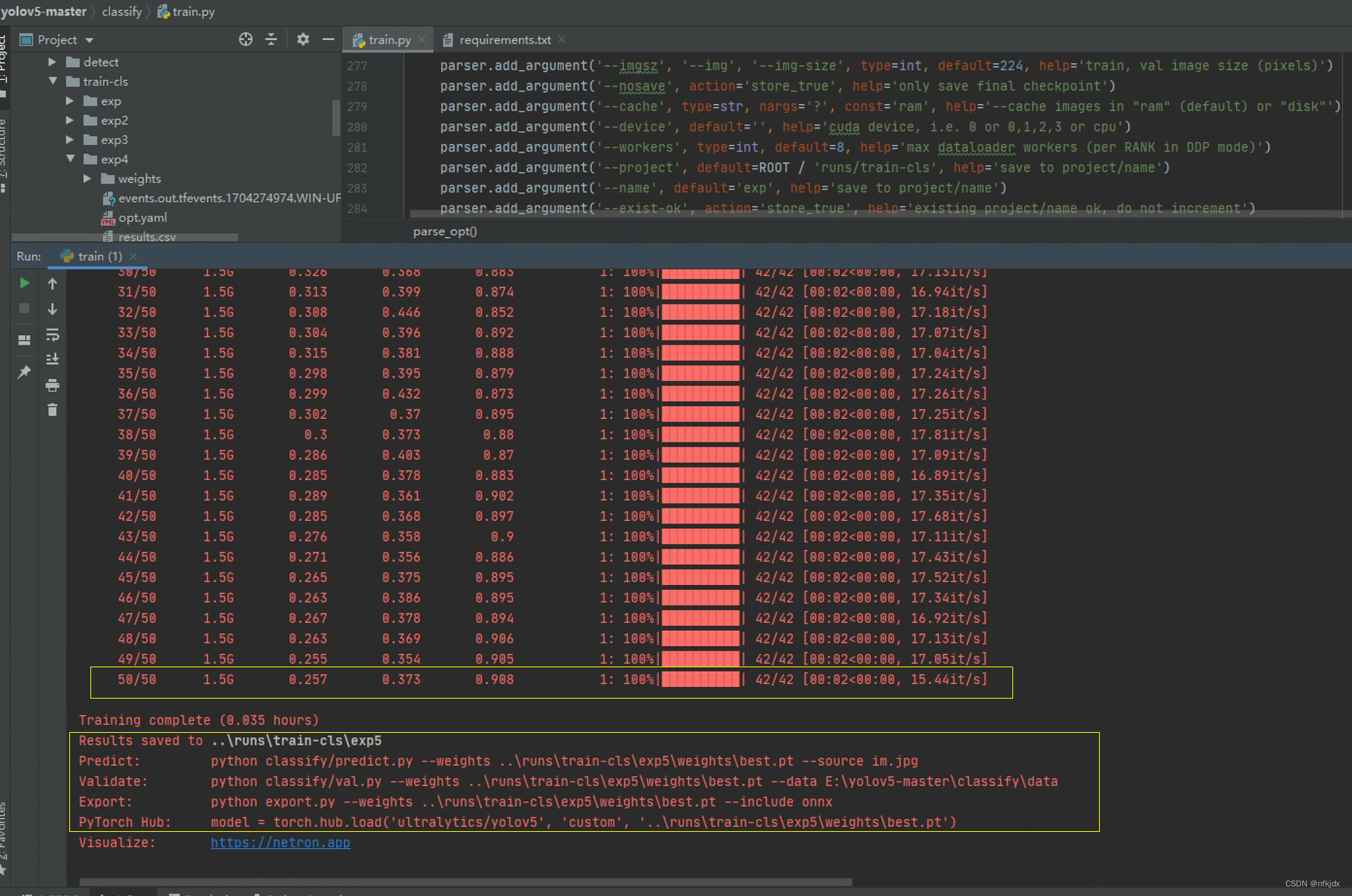
下图中的【..\runs\train-cls\exp5】路径就是存放训练出的权重路径;
Epoch(迭代轮数):一个 epoch 表示将训练集中的所有样本都用于训练的一次迭代。在每个 epoch 中,模型会依次使用训练集中的每个样本进行训练。
GPU_mem(显存占用):指的是在训练过程中 GPU 使用的显存量。显存占用通常会随着模型的复杂度和批量大小的增加而增加。
train_loss(训练损失):在每个 epoch 结束时,使用训练集计算的损失值。训练损失用于衡量模型在训练集上的拟合程度。
test_loss(测试损失):在每个 epoch 结束时,使用测试集计算的损失值。测试损失用于衡量模型在测试集上的拟合程度。通常用于评估模型的泛化能力。
top1_acc(Top-1 准确率):在每个 epoch 结束时,使用测试集计算的准确率。Top-1 准确率表示模型在预测时,与真实标签完全匹配的样本所占的比例。
top5_acc(Top-5 准确率):在每个 epoch 结束时,使用测试集计算的准确率。Top-5 准确率表示模型在预测时,真实标签在模型预测的前五个最高概率中的样本所占的比例。
这些指标可以用来评估模型的性能和训练过程的进展。通常,我们希望训练损失和测试损失都能够逐渐减小,而准确率则逐渐提高。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
【…\runs\train-cls\exp5】:
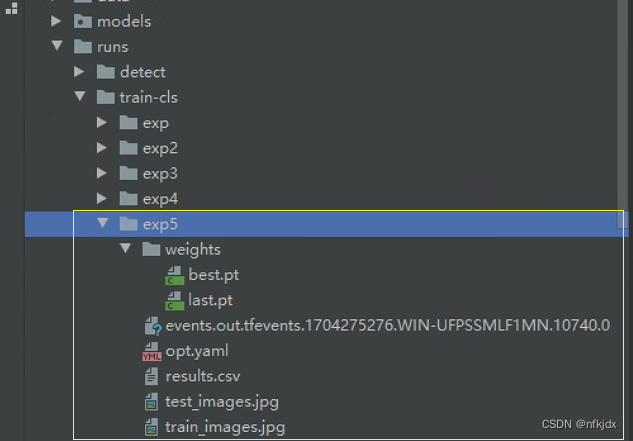
weights:存放模型权重;
在训练深度学习模型时,通常会保存模型的权重文件,以便在需要时进行加载和使用。YOLOv5模型中,best.pt和last.pt是两个常见的权重文件。
best.pt:best.pt是在训练过程中根据验证集表现选择的最佳模型权重文件。它是根据模型在验证集上的性能指标(如精度、损失等)来决定的。通常情况下,best.pt对应于在验证集上获得最佳性能的模型。
last.pt:last.pt是训练过程中最后一次保存的模型权重文件。它保存了模型在训练过程中的最新状态,无论其在验证集上的性能如何。last.pt可以用作继续训练的起点或进行推理和预测。
区别:
best.pt是基于验证集性能选择的最佳模型权重文件,而last.pt是训练过程中最后一次保存的模型权重文件。
best.pt对应于在验证集上获得最佳性能的模型,而last.pt保存了模型在训练过程中的最新状态。
在模型训练完毕后,可以使用best.pt进行性能评估和推理,而last.pt可以用作继续训练的起点。
选择使用哪个权重文件取决于具体的需求。如果需要获得在验证集上最佳性能的模型,可以使用best.pt。如果需要继续训练模型或进行推理和预测,可以使用last.pt。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
6、打开classify文件夹里面的predict.py文件,进行预测
(1)同样与train.py文件操作大致相同,分别修改模型路径和预测图片路径,如下图:

(2)运行predict.py文件进行预测:
运行结果:将运行的结果保存在了【…\runs\predict-cls\exp5】里面

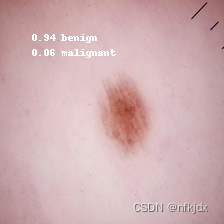
预测结果:预测数据本身为benign(良性),预测后结果如下图:
预测为benign的准确率为0.94,为malignant的准确率为0.06

预测数据本身为malignant(恶性),预测后结果如下图:
预测为benign的准确率为0.04,为malignant的准确率为0.96
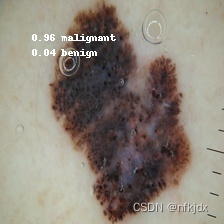
以上就是yolov5分类检测的操作,从这里我们就可以看见yolov5的分类检测功能也很强大!
七、血红细胞数据集的制作(目标检测)
1、数据集的下载
同样进入以下地址:
url:https://www.cvmart.net/
大家打开网址,进行注册登录,再点击里面的数据集就可以去筛选自己需要的数据进行下载。
- 1
- 2
- 3
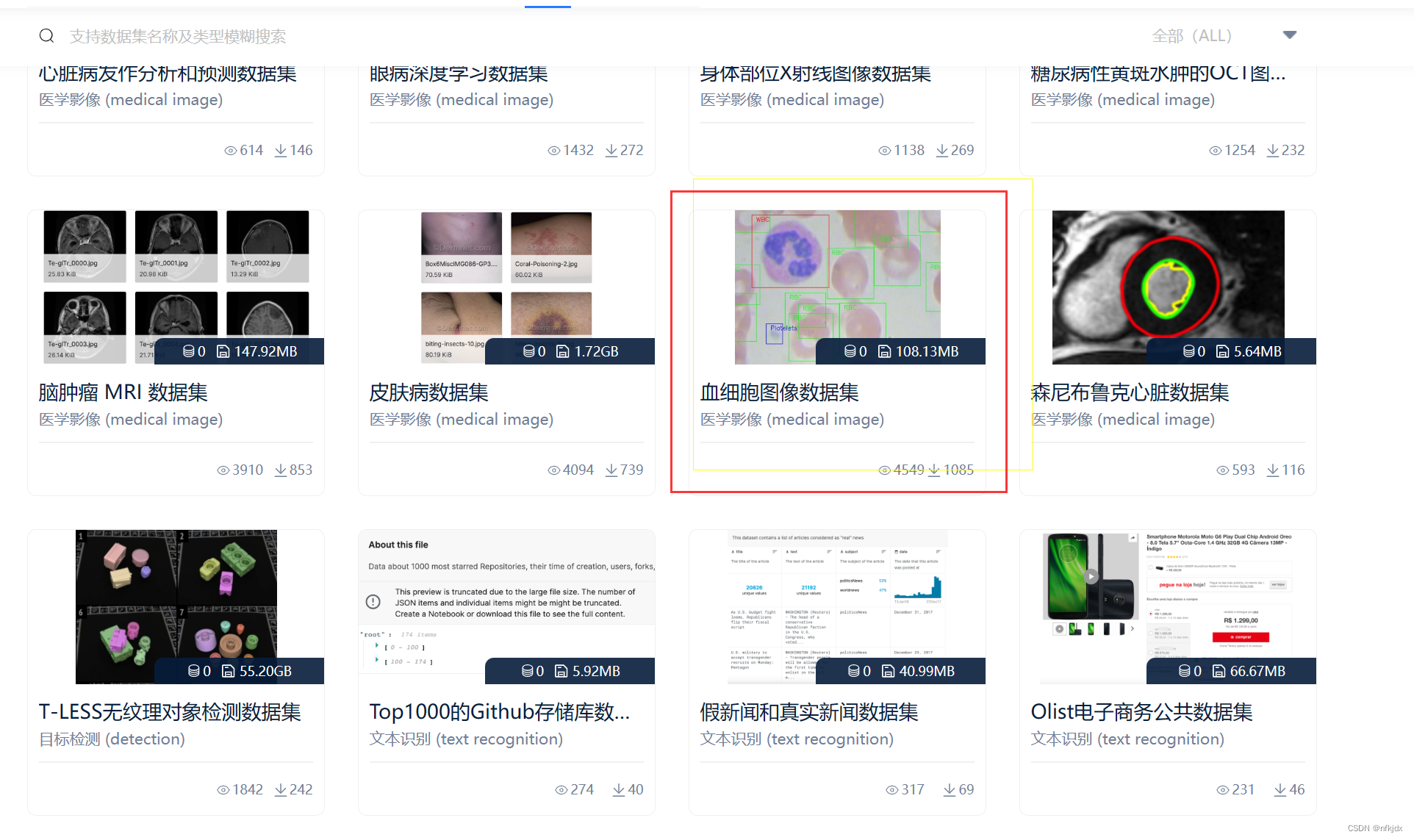
官方介绍:该数据集包含 12,500 张带有细胞类型标签 (CSV) 的增强血细胞图像 (JPEG)。4 种不同细胞类型中的每一种都有大约 3,000 张图像,这些图像被分组到 4 个不同的文件夹中(根据细胞类型)。细胞类型是嗜酸性粒细胞、淋巴细胞、单核细胞和中性粒细胞。该数据集附带一个额外的数据集,其中包含原始 410 幅图像(预增强)以及两个额外的子类型标签(WBC 与 WBC),以及这 410 幅图像中每个单元格的边界框(JPEG + XML 元数据)。更具体地说,“dataset-master”文件夹包含 410 张带有子类型标签和边界框(JPEG + XML)的血细胞图像,而“dataset2-master”文件夹包含 2,500 个增强图像以及 4 个额外的子类型标签(JPEG + CSV)。
下载解压后的数据分为两个文件夹:dataset-master与dataset2-master;
其中dataset-master文件夹是已经做好标签的文件数据,可以直接使用,而dataset2-master文件夹是原始数据,需要自己进行制作数据集;在这里我选择自己制作数据集。
- 1
- 2
- 3
dataset2-master文件夹内的数据形式:
而每一个文件夹里面又分为四类:
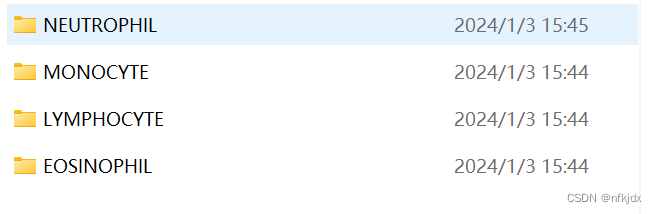
NEUTROPHIL:中性粒细胞;MONOCYTE:单核细胞;LYMPHOCYTE:淋巴细胞;EOSINOPHIL:嗜酸性粒细胞。
TRAIN文件夹中分别NEUTROPHIL:2499张;MONOCYTE:2478张;LYMPHOCYTE:2483张;EOSINOPHIL:2497张。
TEST_SIMPLE文件夹中分别NEUTROPHIL:48张;MONOCYTE:4张;LYMPHOCYTE:6张;EOSINOPHIL:13张。
TEST文件夹中分别NEUTROPHIL:624张;MONOCYTE:620张;LYMPHOCYTE:620张;EOSINOPHIL:623张。
- 1
- 2
- 3
- 4
由于制作数据集时间消耗比较长,我这里直接从train里面选择500张数据进行标注用作训练集,分别从NEUTROPHIL中随机选取125张,MONOCYTE中随机选取125张,LYMPHOCYTE中随机选取125张,EOSINOPHIL中随机选取125张,放在新建的cells文件夹中。
但在选取前先对每一类细胞的图片重命名,防止混淆,因为单纯表面上区分,有些难以区别出来,因此
如下所示:
import os import shutil # 指定文件夹路径 folder_path = r"C:/Users/22846/Downloads/dataset2-master/dataset2-master/images/TRAIN/" # 获取文件夹中的所有文件 files = os.listdir(folder_path) # 遍历文件夹中的文件 for file in files: pics = os.listdir(folder_path+file) #对每一个文件夹内的图片进行遍历重命名 i = 1 for p in pics: # 判断文件是否为图片文件 if p.endswith(".jpg") or p.endswith(".png") or p.endswith(".jpeg"): # 构建新的文件名 new_name = file[0] + str(i)+'.'+p.split('.')[1] # 构建文件的完整路径 old_path = os.path.join(folder_path+file, p) new_file_path = os.path.join(folder_path+file, new_name) i = i + 1 # 重命名文件 os.rename(old_path, new_file_path) print(f"已将文件 {old_path} 重命名为 {new_file_path}")

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
结果如下:

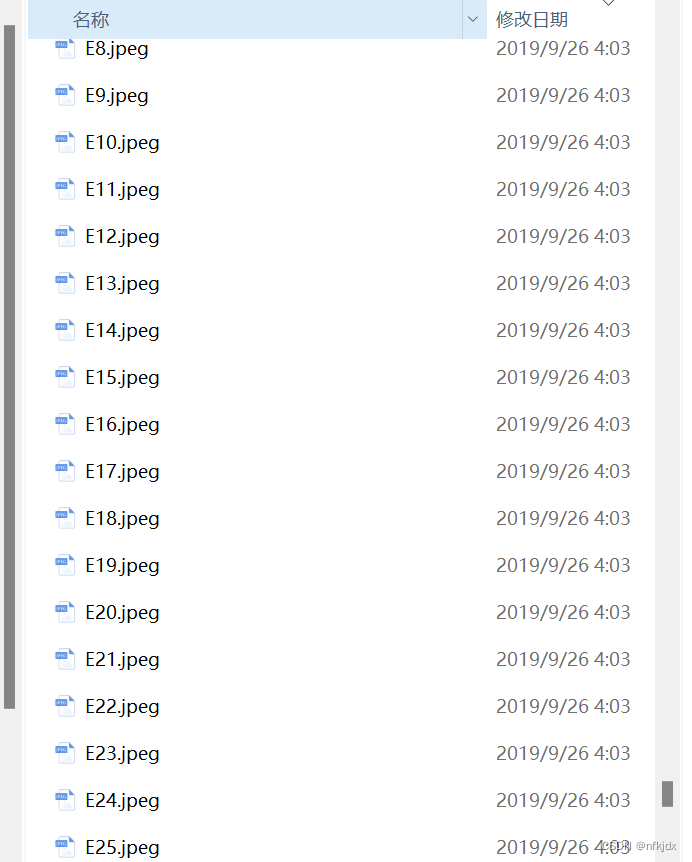
随机选取各类图片一共500张放入cells文件夹里面:

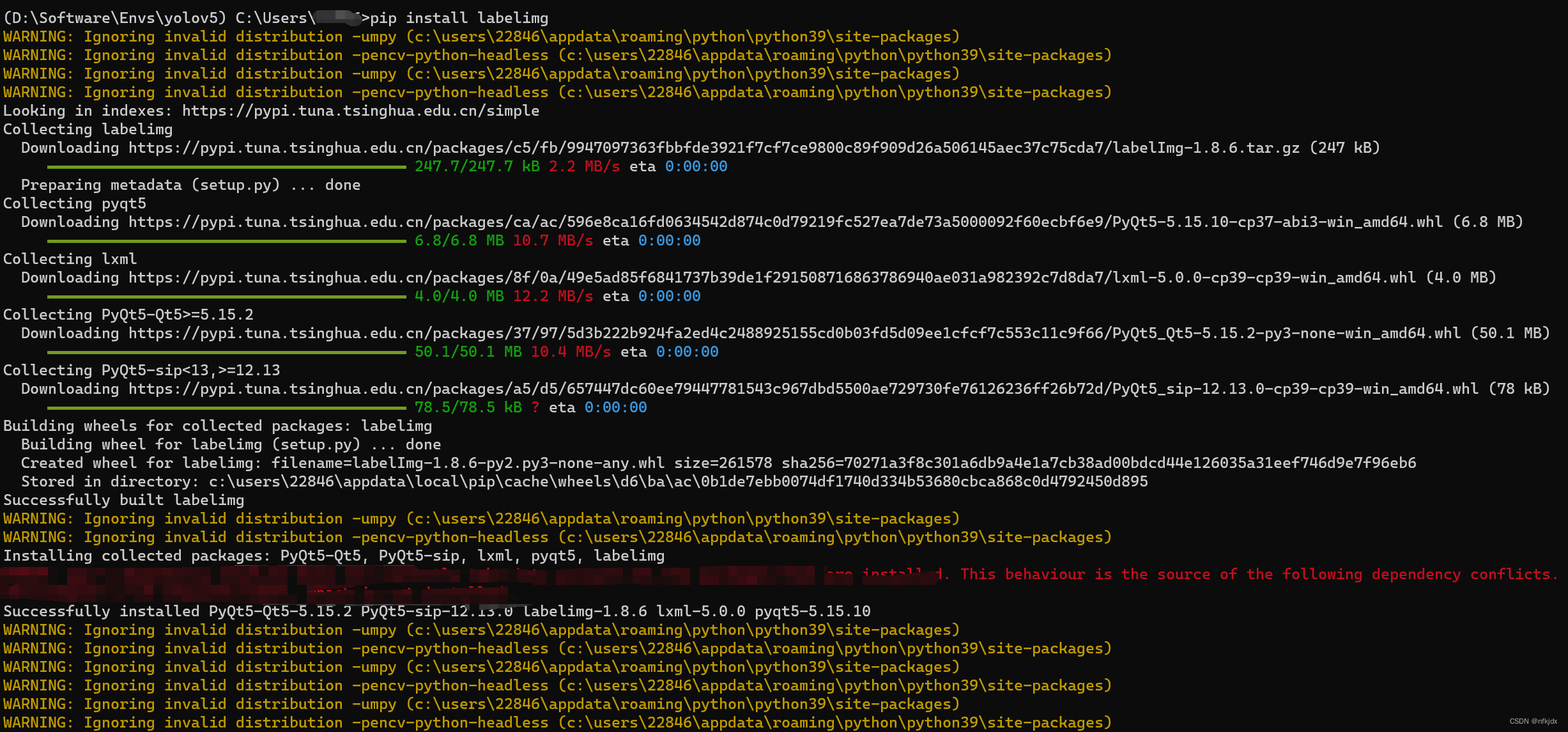
2、首先安装labelimg
pip install labelimg
or
conda install labelimg
- 1
- 2
- 3
3、labelimg 简介
LabelImg是一款开源的图像标注工具,用于创建和编辑图像数据集的标注。它支持多种常见的标注格式,如Pascal VOC、YOLO等。
使用LabelImg,用户可以加载图像,并在图像上绘制边界框或者进行点标注,以标记图像中的目标物体或者感兴趣区域。该工具提供了简单易用的界面和交互操作,使得标注过程更加高效和准确。
LabelImg支持在Windows、Linux和macOS等操作系统上运行,并且提供了多种语言的界面,方便用户根据自己的需要进行选择。
除了标注功能,LabelImg还提供了一些辅助功能,如自动保存标注结果、快捷键操作、标注结果的导出等,使得用户能够更好地管理和利用标注数据。
总之,LabelImg是一款功能强大、易于使用的图像标注工具,对于进行目标检测、图像分割等任务的数据集准备非常有帮助。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
4、在窗口输入LabelImg,就会弹出LabelImg的操作界面


5、LabelImg的操作界面的使用
1、导入图像:点击界面上方的“Open Dir”按钮,选择要标注的图像文件,然后图像将显示在主窗口中。
2、创建标注框:在主窗口中,你可以使用鼠标左键点击并拖动来创建一个边界框,将其框住图像中的目标物体。你可以调整边界框的大小和位置,以确保它准确地包围目标。
3、标注物体类别:在主窗口的左下角,你可以选择目标物体的类别。点击下拉菜单,选择适当的类别。
4、保存标注结果:点击界面上方的“change Save dir”按钮,将标注结果保存到文件目录中。LabelImg会自动将标注结果以XML或txt格式保存。
5、继续标注:如果你需要标注多个目标物体,可以重复步骤4到步骤6,直到所有目标都被标注。
6、导出标注结果:如果你需要将标注结果导出为其他格式(如Pascal VOC或YOLO),可以点击界面上方的“Export”按钮,选择要导出的格式,并指定导出路径。
7、进行下一张图像的标注:点击界面上方的“Next Image”按钮,加载下一张图像,继续进行标注。
以上是LabelImg的基本使用步骤。在实际使用中,你可能还会使用一些其他功能,如快捷键操作、调整标注框的大小和位置、删除标注等。你可以在LabelImg的官方文档中找到更详细的操作指南。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
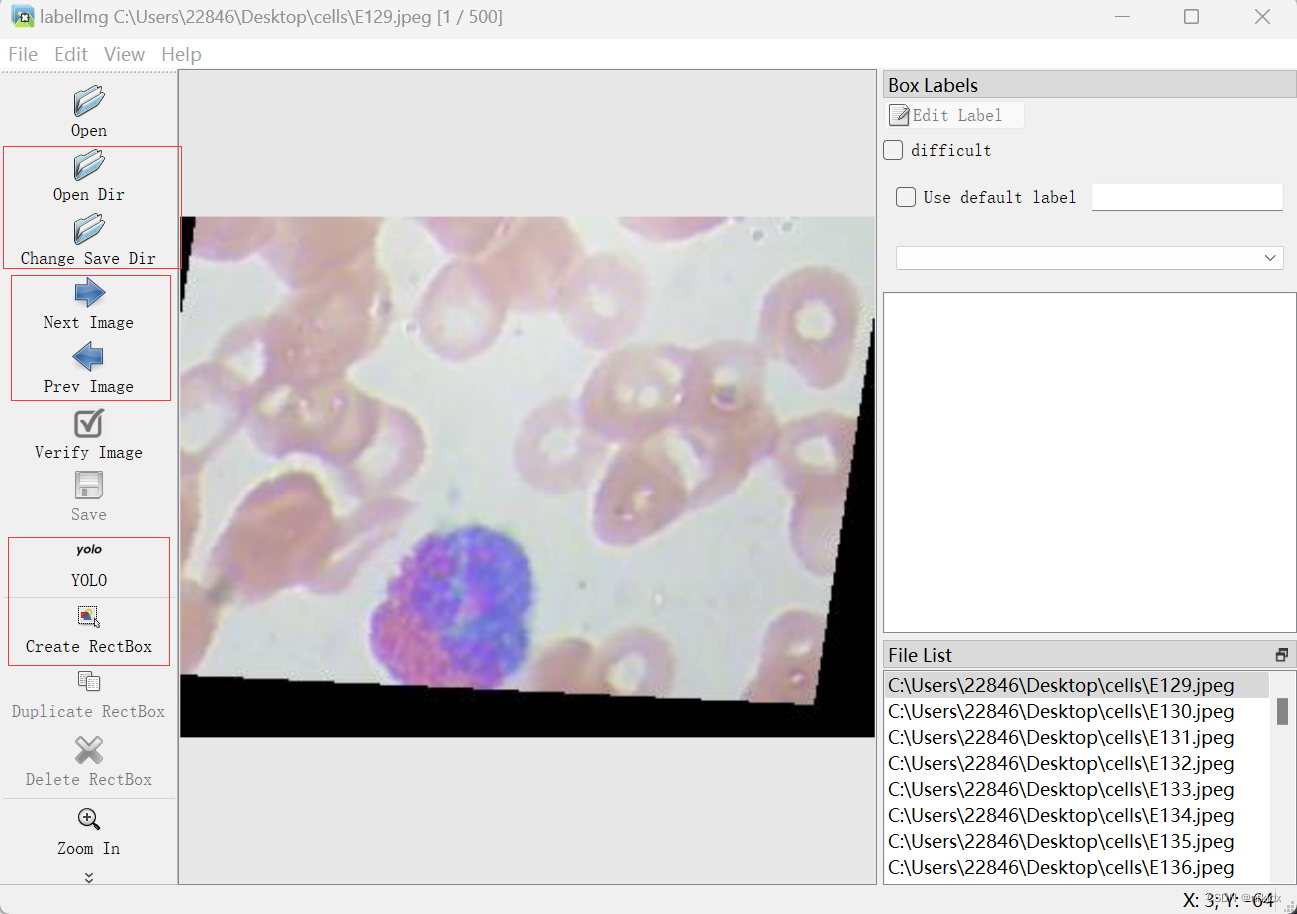
我选择保存在这个文件夹里面:
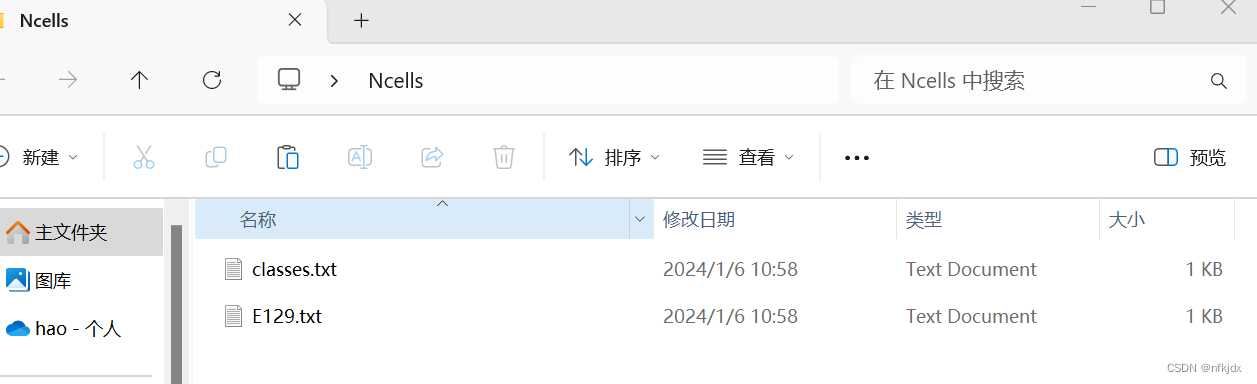
那接下里就继续制作数据集!!!!:
其中:
NEUTROPHIL:中性粒细胞标注为N;MONOCYTE:单核细胞标注为M;
LYMPHOCYTE:淋巴细胞标注为L;EOSINOPHIL:嗜酸性粒细胞标注为E。
- 1
- 2
- 3
- 4
数据集制作完成:

其中标注文件中多一个classes.txt,这里面记录的是标签:

八、改写代码,进行目标检测实战训练
1、先将cells与Ncells文件夹名称分别改为images与labels,目的是显得更加清晰明了;接着将数据集按照一定的比例进行划分为训练集,测试集,验证集(train、test、val),下述的代码中我按照了 8:1:1 的比例去划分,若想根据自己的需要去划分数据集,修改下述代码中的:
在项目中新建DataSplit.py文件并放入以下代码,根据自己的需求改写路径和比例(如下图所示)
import os import random from shutil import copyfile def split_dataset(image_folder, txt_folder, output_folder, split_ratio=(0.8, 0.1, 0.1)): # Ensure output folders exist for dataset in ['train', 'val', 'test']: if not os.path.exists(os.path.join(output_folder, dataset, 'images')): os.makedirs(os.path.join(output_folder, dataset, 'images')) if not os.path.exists(os.path.join(output_folder, dataset, 'txt')): os.makedirs(os.path.join(output_folder, dataset, 'txt')) # Get list of image filesa image_files = [f for f in os.listdir(image_folder) if f.endswith(('.jpg', '.jpeg', '.png'))] random.shuffle(image_files) num_images = len(image_files) num_train = int(split_ratio[0] * num_images) num_val = int(split_ratio[1] * num_images) train_images = image_files[:num_train] val_images = image_files[num_train:num_train + num_val] test_images = image_files[num_train + num_val:] # Copy images to respective folders for dataset, images_list in zip(['train', 'val', 'test'], [train_images, val_images, test_images]): for image_file in images_list: image_path = os.path.join(image_folder, image_file) copyfile(image_path, os.path.join(output_folder, dataset, 'images', image_file)) txt_file = os.path.splitext(image_file)[0] + '.txt' txt_path = os.path.join(txt_folder, txt_file) # Copy corresponding txt file if exists if os.path.exists(txt_path): copyfile(txt_path, os.path.join(output_folder, dataset, 'txt', txt_file)) if __name__ == "__main__": image_folder_path = "C:/XXXXXXXXX/cell/images" txt_folder_path = "C:/XXXXXXXXX/cell/labels" output_dataset_path = "C:/XXXXXXXXX/Ncell" split_dataset(image_folder_path, txt_folder_path, output_dataset_path) print("数据集划分完成!!!")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
其中:
split_ratio=(0.8, 0.1, 0.1)为划分比例传入的参数,根据自己的实际需求改写即可
image_folder_path 为images图片的文件夹的路径
txt_folder_path 为labels的txt文件夹的路径
output_dataset_path 为你保存的数据集的文件夹的路径,代码会在改路径下自动生成子文件夹,分别进行测试集,训练集,验证集的存储。
- 1
- 2
- 3
- 4
- 5
结果如下:
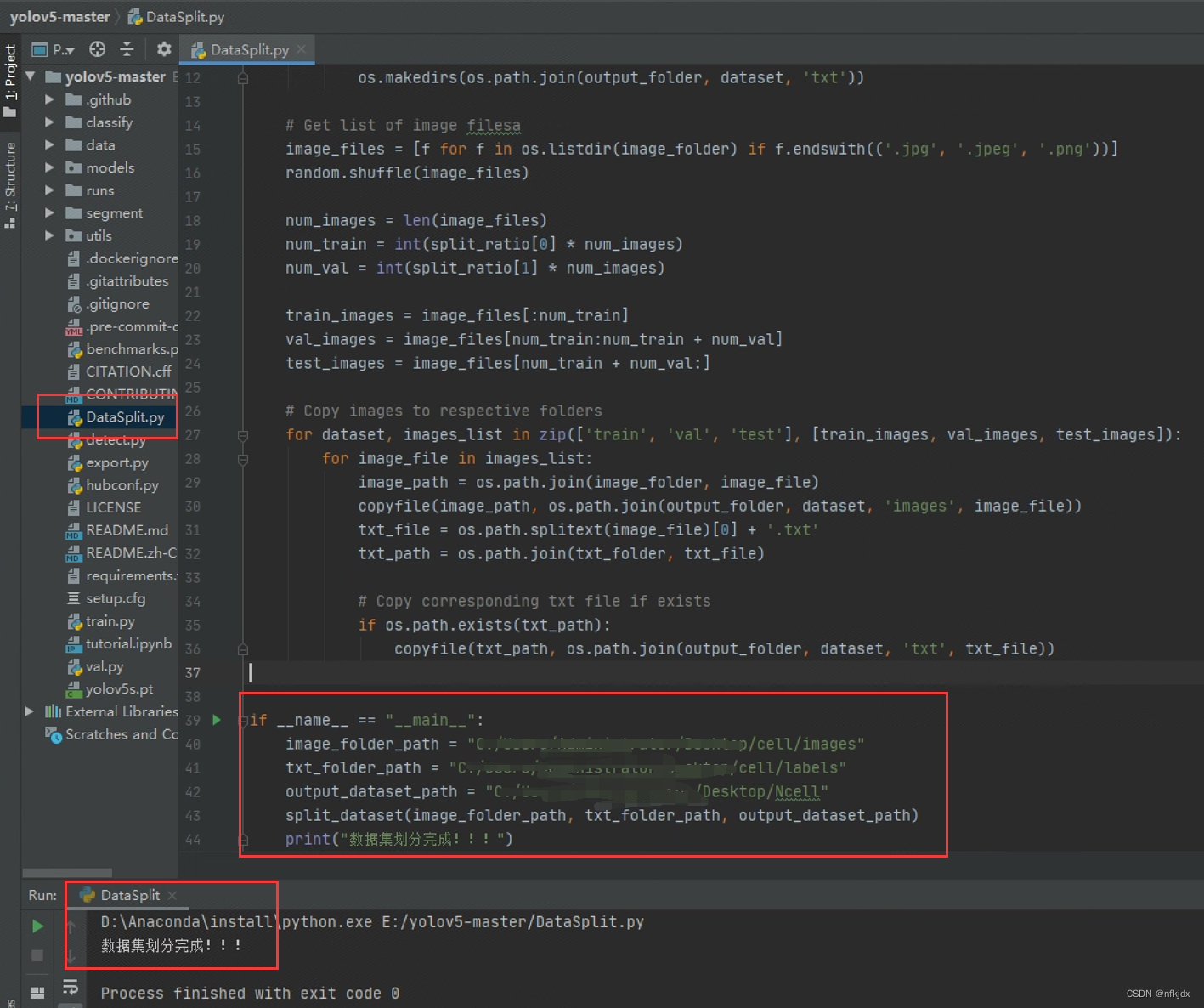
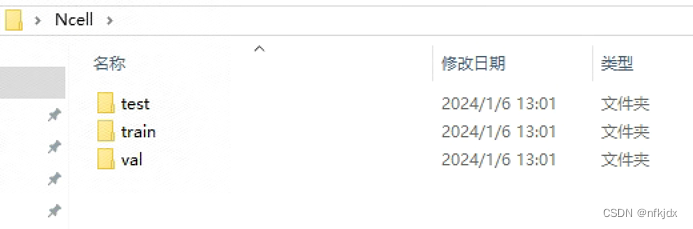
同时将test、train、val里面的txt文件名改为labels!
2、在项目里新建mydata文件夹,将划分的文件放进去;打开项目中的data文件夹,复制里面的ImageNet.yaml,再粘贴进data文件夹里面并改名为cells.yaml。分别如下图所示:


3、添加训练数据路径:改写cells.yaml内的代码
原代码:里面已经表明训练集、测试集、验证集与标签的添加位置,我们只需要更改即可
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..] path: ../datasets/imagenet # dataset root dir train: train # train images (relative to 'path') 1281167 images val: val # val images (relative to 'path') 50000 images test: # test images (optional) # Classes names: 0: tench 1: goldfish 2: great white shark 3: tiger shark 4: hammerhead shark 5: electric ray 6: stingray 7: cock 8: hen ........... # Download script/URL (optional) download: data/scripts/get_imagenet.sh
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
改写后:
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: E:/yolov5-master/mydata # dataset root dir
train: train # train images (relative to 'path') 1281167 images
val: val # val images (relative to 'path') 50000 images
test: test # test images (optional)
# Classes
names:
0: E
1: L
2: M
3: N
# Download script/URL (optional)
download: data/scripts/get_imagenet.sh
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
4、改写train.py代码,训练数据
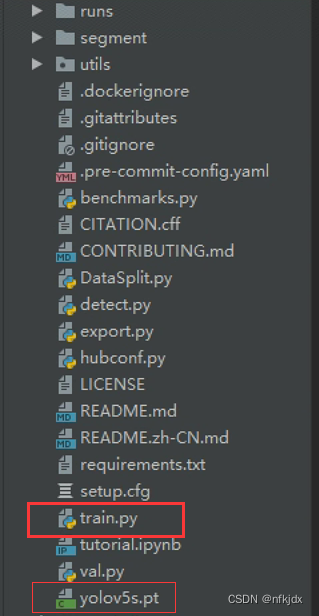
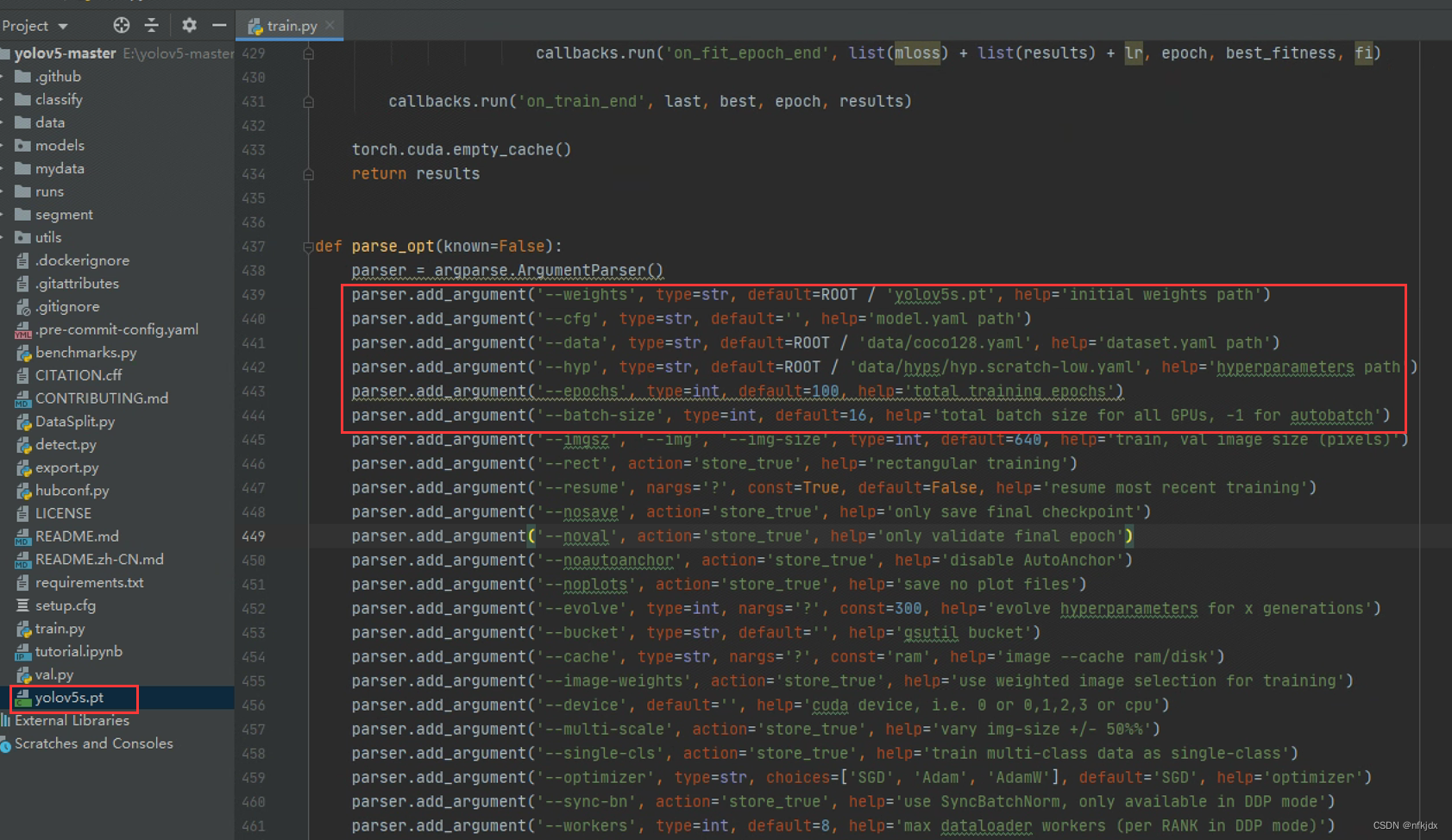
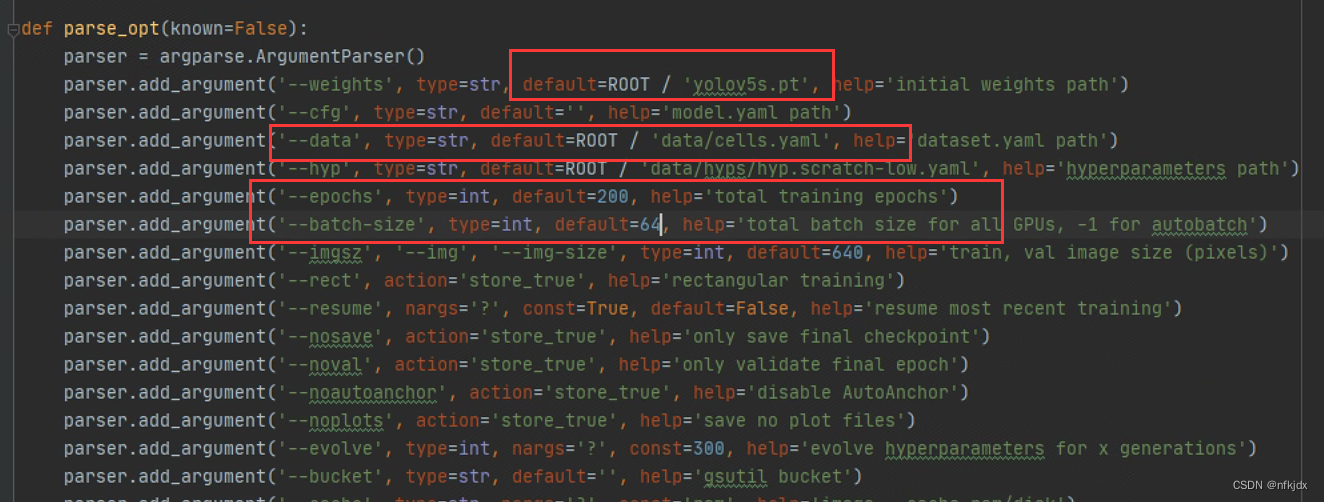
(1)首先引入官方的目标检测预训练模型,在我们下载项目文件的时候,里面就包含了这个预训练模型:yolov5s.pt,你也可以去官网中进行下载其它的权重模型。如上图左侧标记所示;
(2)更改data路径:data/cells.yaml;
(3)更改epochs为:200;
(4)更改batch-size为:64;
如下图所示:
- 1
- 2
- 3
- 4
- 5
5、开始执行train.py,结果如下:
我在执行过程中报了一个错误:
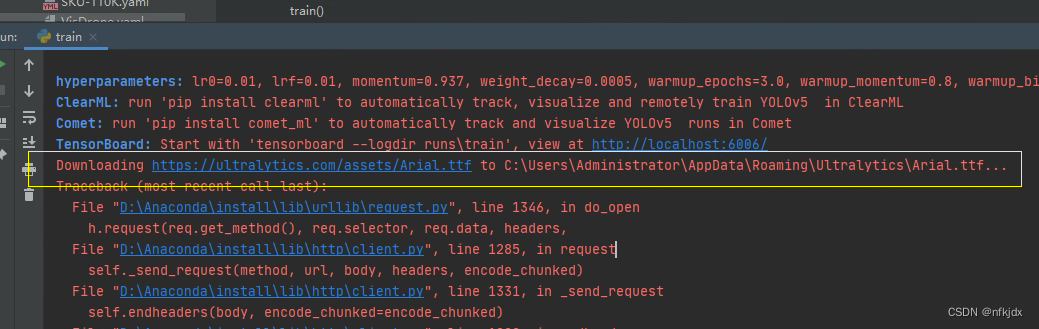
这是因为:yolov5在训练时需要下载字体Arial.ttf,你可以复制下载网址:https://ultralytics.com/assets/Arial.ttf,在网页打开直接就下载了,再把下载的文件放在下载的目录中,如下图:
再次运行就可以了!
运行结果如下所示:
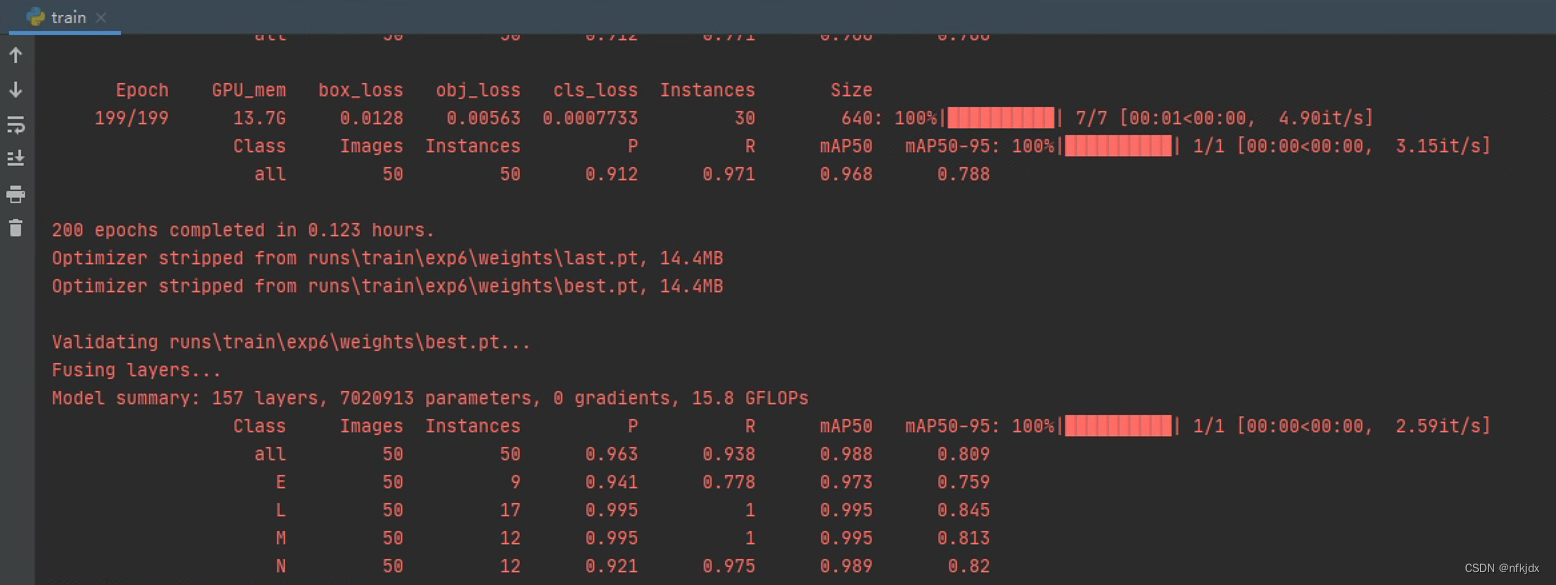
在目标检测任务中,常用的评估指标包括Precision(P)、Recall(R)、mAP50和mAP50-95。
Precision(精确率)表示检测出的正样本中有多少是真正的正样本。它的计算公式是:P = TP / (TP + FP),其中TP是真正例(正确检测的正样本数),FP是假正例(错误检测的正样本数)。Precision越高,表示检测结果中的正样本越准确。
Recall(召回率)表示真实的正样本中有多少被正确地检测出来。它的计算公式是:R = TP / (TP + FN),其中TP是真正例,FN是假负例(未能检测到的正样本数)。Recall越高,表示模型能够更好地检测出真实的正样本。
mAP50(平均精确率,IoU阈值为0.5)表示在不同类别上的平均精确率。它的计算方法是先计算每个类别的精确率,然后对所有类别的精确率取平均值。mAP50衡量了模型在不同类别上的整体性能,当IoU阈值为0.5时,表示检测框与真实框的重叠程度达到50%以上时才被视为正确检测。
mAP50-95(平均精确率,IoU阈值从0.5到0.95)是在不同IoU阈值范围内的平均精确率。它计算了从0.5到0.95不同IoU阈值下的精确率,并对其取平均值。mAP50-95更全面地评估了模型在不同IoU阈值下的检测性能。
这些评估指标可以帮助我们了解目标检测模型的准确性和召回率,并对模型的性能进行综合评估。
- 1
- 2
- 3
- 4
- 5
- 6
运行的结果保存在:…runs\train\exp6目录下
里面包含生成的权重文件:weights,精确率与召回率的图像等,如下图所示:
- 1

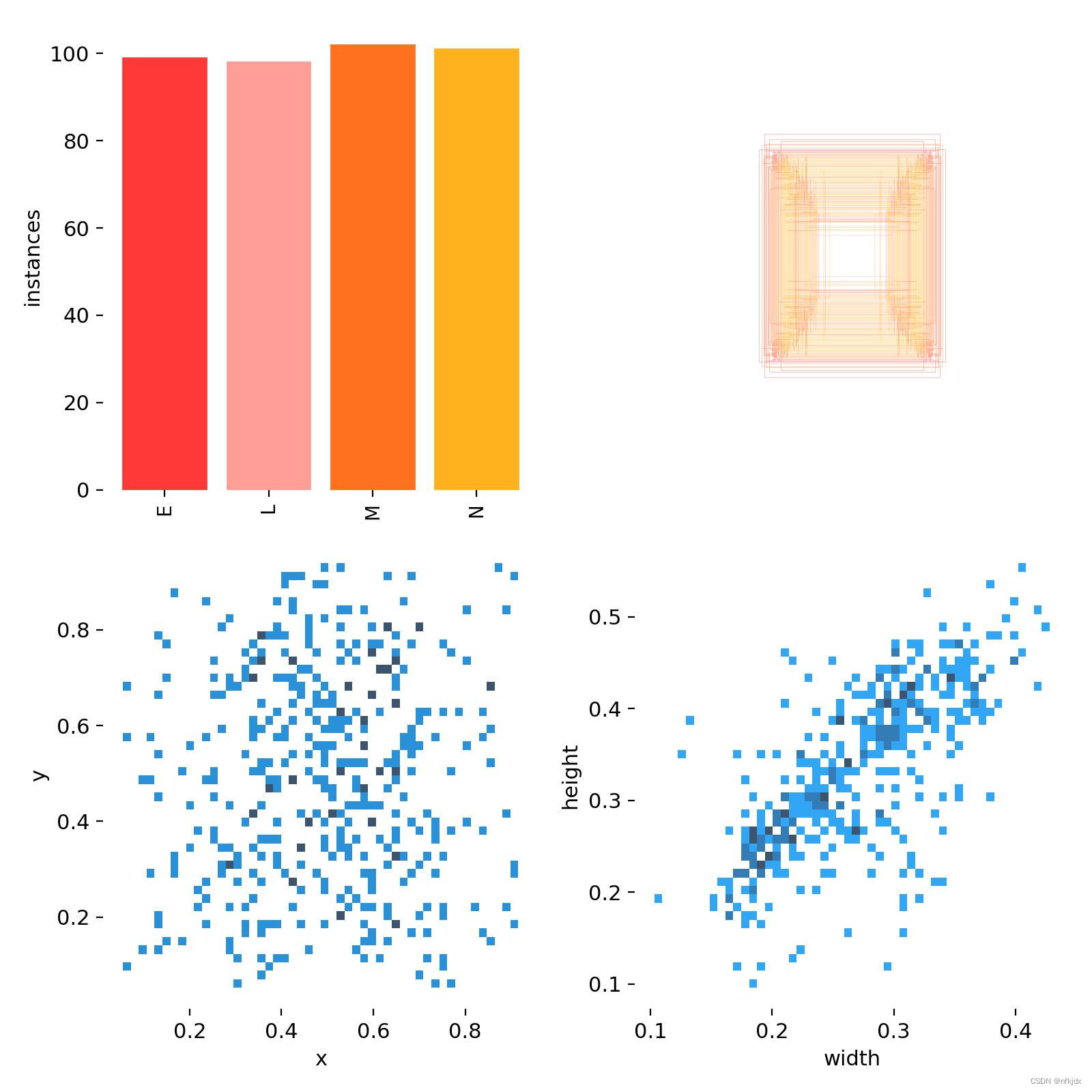
(1)"labels.jpg"通常是指包含训练数据集中所有类别标签的图像文件。
第一个图是训练集得数据量,每个类别有多少个;
第二个图是框的尺寸和数量;
第三个图是中心点相对于整幅图的位置;
第四个图是图中目标相对于整幅图的高宽比例;
- 1
- 2
- 3
- 4
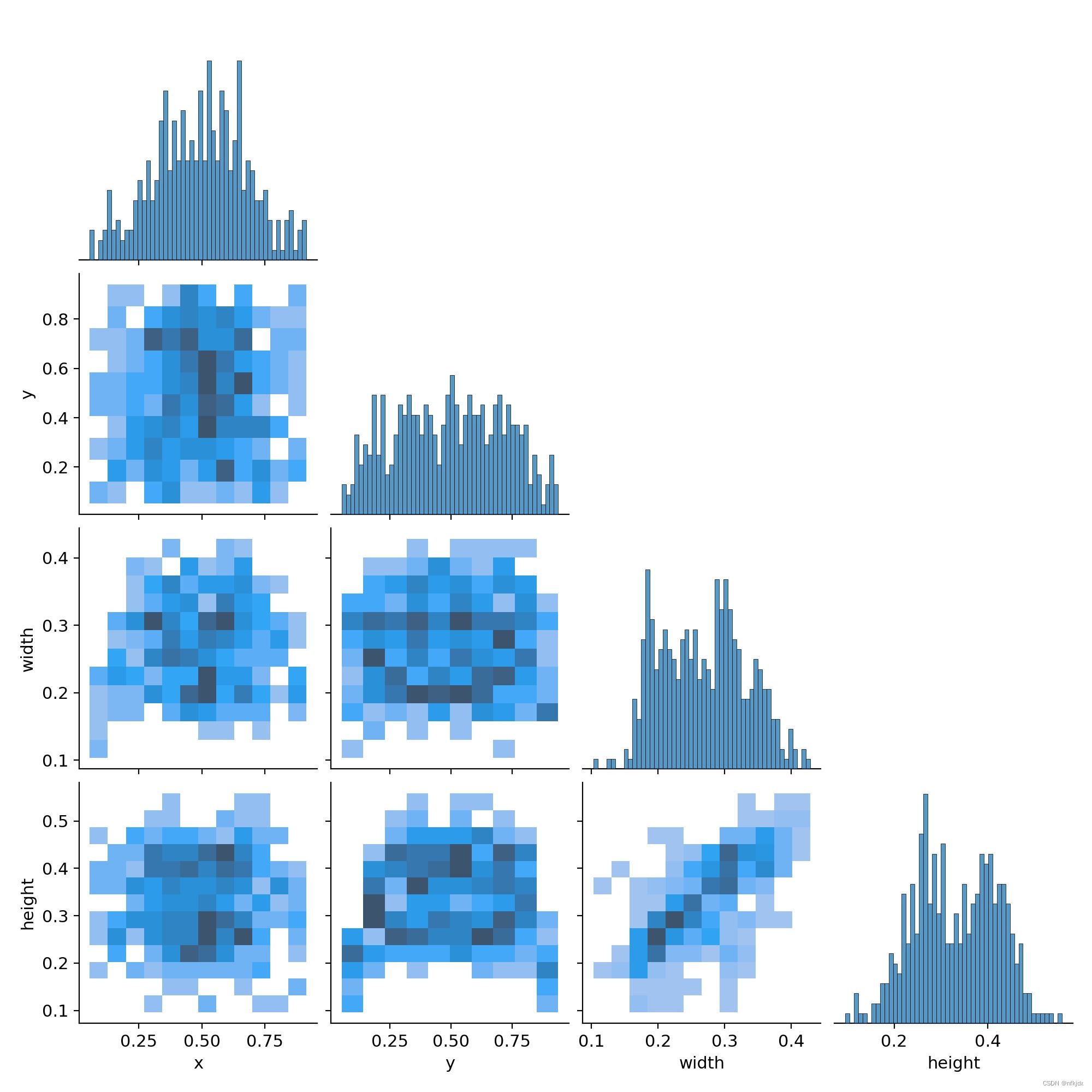
(2)labels_correlogram.jpg是一张颜色矩阵图,它展示了目标检测算法在训练过程中预测标签之间的相关性。
矩阵的行列分别代表了模型训练时使用的标签(classes),而每个单元格则代表了对应标签的预测结果之间的相关性。
矩阵中的颜色越深,表示对应标签之间的相关性越强;颜色越浅,表示相关性越弱。对角线上的颜色表示每个标签的自身相关性,通常都是最深的。
通过这张图,我们可以看出哪些标签之间具有较强的相关性,从而有助于优化模型的训练和预测效果。例如,如果我们发现某些标签之间的相关性过强,可以考虑将它们合并成一个标签,从而简化模型并提高效率。
最上面的图(0,0)表明中心点横坐标x的分布情况;
(1,1)图表明中心点纵坐标y的分布情况;
(2,2)图表明框的宽的分布情况;
(3,3)图表明框的宽的分布情况
- 1
- 2
- 3
- 4
- 5
- 6
- 7
(3)P曲线:P_curve.png:准确率precision与置信度confidence的关系图。
【置信度confidence:用来判断边界框内的物体是正样本还是负样本,大于置信度阈值的判定为正样本,小于置信度阈值的判定为负样本即背景。】
- 1
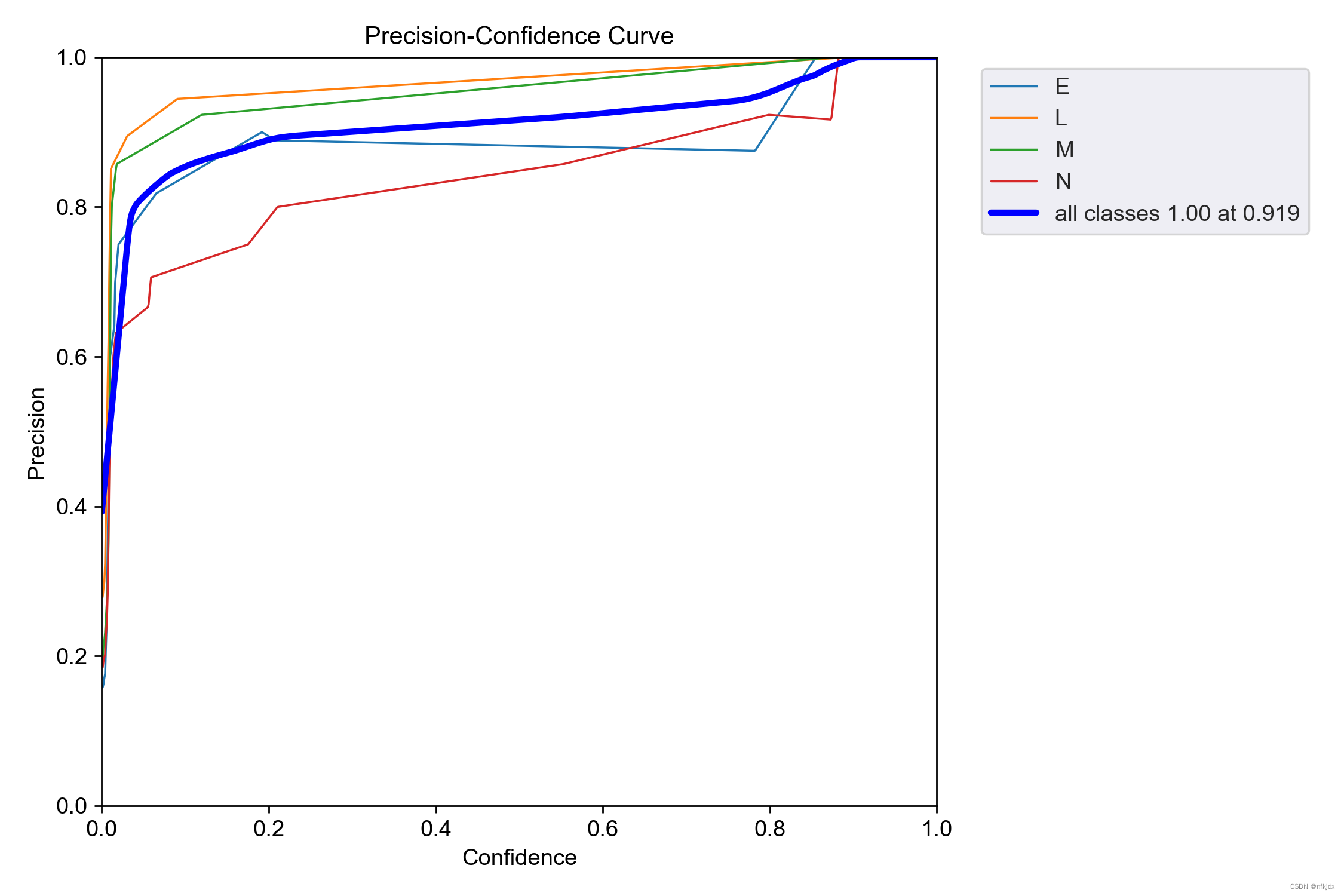
(4)R_curve.png(信度阈值 - 召回率曲线图):Recall-Confidence Curve (RCC)图是目标检测中用于评估算法性能的一种方法。它是在不同置信度阈值下,召回率的变化情况的可视化表示。
通常情况下,我们希望算法能够在高召回率的同时保持较高的精度。
当RCC图中的曲线在较高的置信度水平下具有较高的召回率时,说明算法在检测目标时能够较为准确地预测目标的存在,并且在过滤掉低置信度的预测框后,依然可以保持较高的召回率。这说明算法在目标检测任务中具有较好的性能。
需要注意的是,在RCC图中,曲线的斜率越陡峭,说明在过滤掉低置信度的预测框后,能够获得较大的召回率提升,从而提高模型的检测性能。
在该图表中,曲线越靠近右上角,则表示模型的性能越好。当曲线接近图表的右上角时,意味着模型在保持高召回率的同时,也能够保持较高的精确度。因此,R_curve.png可以用于评估模型的整体表现和找到一个合适的阈值,来平衡模型的召回率和精确度。
- 1
- 2
- 3
- 4

(5)PR_curve.png —— 精确率和召回率的关系图:PR Curve是Precision-Recall Curve的缩写,表示的是在不同阈值下,精确率与召回率之间的关系曲线。其中精确率(Precision)表示预测为正例的样本中真正为正例的比例,召回率(Recall)表示真正为正例的样本中被预测为正例的比例。
在PR Curve中,横坐标为召回率,纵坐标为精确率。一般而言,当召回率较高时,精确率较低;当精确率较高时,召回率较低。而PR Curve则体现了这种“取舍”关系。当PR Curve越靠近右上角时,表示模型在预测时能够同时保证高的精确率和高的召回率,即预测结果较为准确。相反,当PR Curve越靠近左下角时,表示模型在预测时难以同时保证高的精确率和高的召回率,即预测结果较为不准确。
通常,PR Curve与ROC Curve(受试者工作特征曲线)一同使用,以更全面地评估分类模型的性能。
- 1
- 2
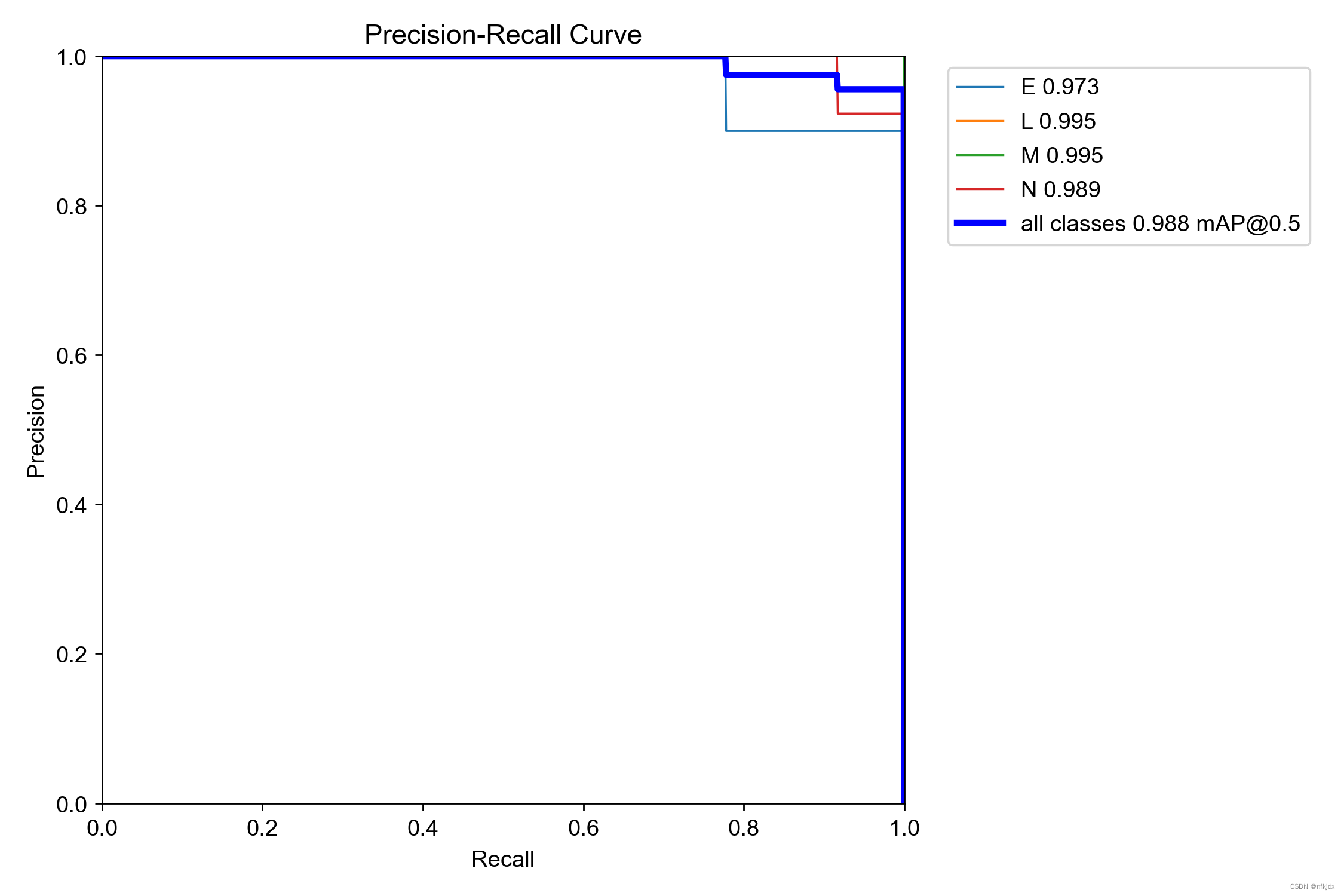
(6)result.png:
定位损失box_loss:预测框与标定框之间的误差(CIoU),越小定位得越准;
置信度损失obj_loss:计算网络的置信度,越小判定为目标的能力越准;
分类损失cls_loss:计算锚框与对应的标定分类是否正确,越小分类得越准;
mAP@0.5:0.95(mAP@[0.5:0.95]):
表示在不同IoU阈值(从0.5到0.95,步长0.05)(0.5、0.55、0.6、0.65、0.7、0.75、0.8、0.85、0.9、0.95)上的平均mAP;
mAP@0.5:表示阈值大于0.5的平均mAP
- 1
- 2
- 3
- 4
- 5
- 6
通过上图中的结果发现:该准确率平均达到0.963, 精确率平均达到0.938,已经时一个不错的效果了!
6、改写detect.py代码,进行预测,如下图所示:

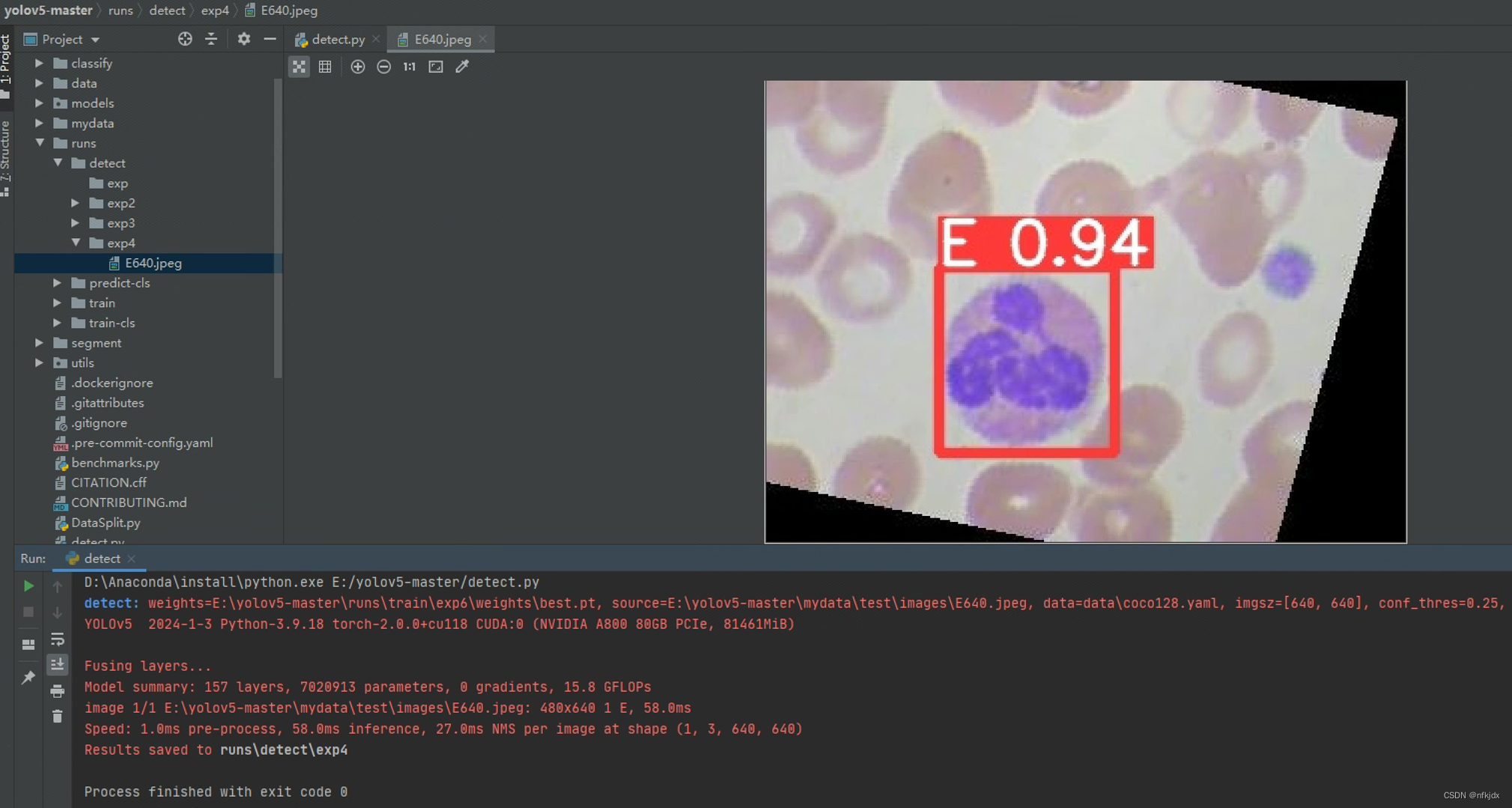
选择一张图片预测:该图片为EOSINOPHIL:嗜酸性粒细胞
预测结果:
再在验证集val选择一张图片预测:该图片为NEUTROPHIL:中性粒细胞

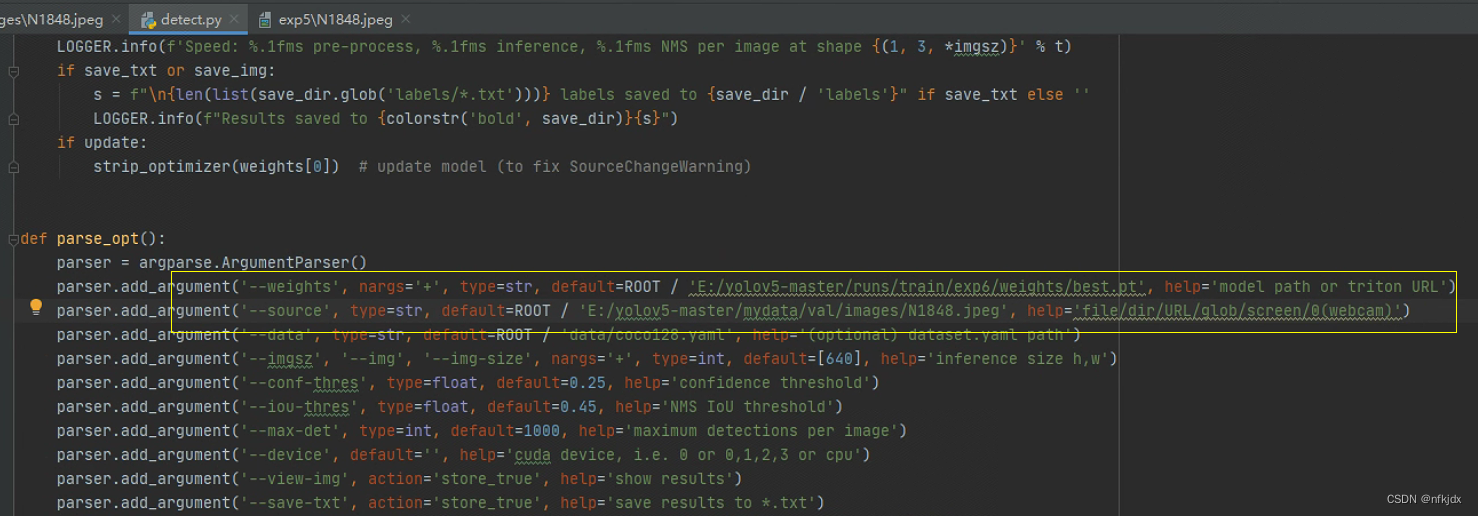
预测结果:

九、简单总结
1、以上就是多使用yolov5模型进行一个分类与目标检测的介绍和实践,大家可以参考与提出问题,看见了就会回答,一起讨论!项目代码和数据也上传了,大家可以下载!
2、再这个过程中大家肯定会遇见一些错误,但是不要害怕,可以去根据提示进行改正或者上网查找解决方法,还有就是询问chatgpt大模型!
3、不管是分类训练,还是目标检测,准确率平均达到0.94及其以上, 精确率也平均达到0.94左右,已经时一个不错的效果了!,但是大家如果还需要提高精确度,比如增加数据来,我这里的数据量不是太多,数据增强等,可以参考以下方法:
要提高YOLOv5模型的精确度和准确度,可以尝试以下方法: 增加训练数据量:增加训练数据可以提供更多的样本和场景,有助于模型学习更多的特征和模式。 数据增强:使用数据增强技术,如随机缩放、翻转、旋转、裁剪等,可以扩充训练数据集,增加模型的鲁棒性和泛化能力。 调整模型架构:可以根据任务需求调整YOLOv5的网络架构,如增加卷积层、调整通道数、调整网络深度等,以提升模型的表达能力。 调整训练参数:可以尝试不同的学习率、批量大小、优化器、学习率衰减策略等训练参数,以找到最优的训练配置。 使用预训练模型:可以使用在大规模数据集上预训练的模型作为初始权重,然后在目标数据集上进行微调,以加快收敛速度和提高模型性能。 多尺度训练和推理:使用多尺度训练和推理可以提升模型对不同尺寸目标的检测能力,可以在训练时随机选择不同的输入尺寸,并在推理时使用多个尺度的图像进行预测。 使用更大的输入图像尺寸:增加输入图像的尺寸可以提高模型对小目标的检测能力,但同时也会增加计算和内存开销。 引入注意力机制:可以在YOLOv5中引入注意力机制,如SENet、CBAM等,以增强模型对重要特征的关注和响应能力。 集成学习:通过模型集成方法,如投票、平均等,结合多个训练好的YOLOv5模型的预测结果,可以提高模型的稳定性和性能。 以上是一些常用的方法,可以根据具体的任务和数据集进行尝试和调整,以获得更好的精确度和准确度。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22


