
热门标签
热门文章
- 1护网行动及注意事项_护网行动报名条件
- 2flutter-web中使用js工具类_fluter 使用 js
- 3在Genymotion虚拟机上安装Google Apps_genymotion 安装gms
- 42024年还有人不知道Web3吗?_web3 csdn
- 5大学四年..就混了毕业证的我,出社会深感无力..辞去工作,从头开始_大学学的计算机混了个毕业证
- 6搭建DVWA漏洞环境靶场_dvwa靶场搭建
- 7Ubuntu20.04安装MongoDB
- 8Flink进阶篇-CDC 原理、实践和优化&采集到Doris中_flinkcdc sink doris
- 9python怎么创建一个文件夹,用python创建一个文件夹_python创建文件夹
- 10Android开发——BroadcastReceiver知识总结_粘性广播废弃
当前位置: article > 正文
lstm原始论文_论文笔记:Matching Networks for One Shot Learning
作者:花生_TL007 | 2024-04-27 11:26:12
赞
踩
lstm原始论文_论文笔记:Matching Networks for One Shot Learning

今天写点关于 "one-shot" learning(就是从一个(或极少个)样本学习而非现在普遍的大量数据集,毕竟,一个小孩能通过一个图片知道什么是长颈鹿,而机器却需要大量的样本!) 的东西
Matching Networks for One Shot Learning这篇论文是来自谷歌DeepMind的一篇论文,主要在于解决:基于小样本去学习归类(或者别的任务),并且这个训练好的模型不需要经过调整,也可以用在对训练过程中未出现过的类别进行归类(这里可能有些绕,稍后会结合符号定义做详细的解释,其实个人觉得这个任务也颇有些“迁移学习”的感觉)。
PS. 本文的大部分内容参考自Andrej Karpathy关于这篇论文的读文笔记。也许可以看做加了自己的理解和一些补充的笔记翻译?然后,这篇论文的说话方式有点晦涩难懂,就连Andrej Karpathy也在笔记中多次提到作者的各种地方说的不太清楚,所以本人的理解也难免有错,希望有意见不一致的地方大家可以多多交流。
PPS. 其实这篇论文是下周要讲的paper reading,所以也可以说是对自己的屁屁踢做了个翻译 []~( ̄▽ ̄)~*,虽然毕设是做对抗样本,但是平时的一些进度还是要跟着组里的方向来的。
核心思想:
训练一个端到端的类似于nearest neighbor的分类器,之所以说类似,是因为虽然整体思想是很相像的,但对于NN而言,样本是什么输入就是什么,但是在这里需要对样本学习一个样本的表示,把他们编码一下。
模型结构:
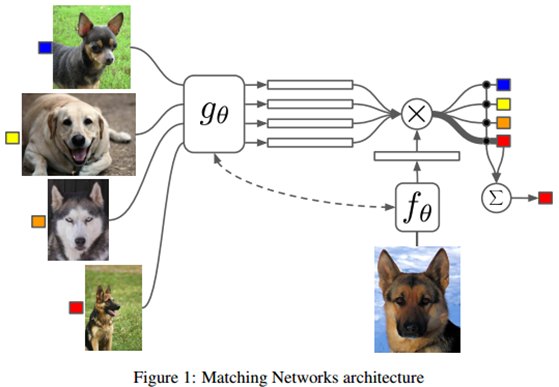
Task:
训练过程:给定一个有k个样本的支撑集
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/花生_TL007/article/detail/496502
推荐阅读
相关标签

