
搜索语义模型的大规模量化实践
赞
踩

作者 | 把酒问青天
导读
经过近几年的技术演进,语义模型在百度搜索场景中被广泛地应用,消耗了大量的GPU资源,模型压缩技术也随之得到大量研究和实践。通过兼顾推理性能、业务效果和迭代效率的优化目标,我们成功地将INT8量化技术大面积地应用到了搜索场景中,极大地提高了资源效能。此外,目前大模型正在被研究和应用,算力资源已经成为瓶颈,如何以更低的成本进行落地是一个非常热点的问题。基于对模型压缩技术的实践和积累,我们能够更好地助力大模型的探索和应用。
全文6287字,预计阅读时间16分钟。
01 搜索语义模型现状
ERNIE: Enhanced Representation through Knowledge Integration是百度在2019年4月的时候,基于BERT模型做的进一步优化,在中文的NLP任务上得到了state-of-the-art的结果。
近年来,ERNIE 1.0/2.0/3.0等语义模型在搜索各个重点业务场景下得到了广泛应用,包括相关性、排序等多个子方向,消耗了大量GPU资源。每个业务方向一般由多个模型组成链路来完成最终计算,整体搜索业务所涉及的模型数量多、迭代快。目前,线上全流量模型超过几百个,月级迭代近百次。语义模型的大量应用对搜索产生了巨大影响,相关业务指标对模型精度的变化非常敏感。总的来说,在模型压缩技术的工程实践中,推理性能、业务指标和迭代效率三者的优化目标应当统一考虑:
1、推理性能:采用INT8量化,ERNIE模型的性能加速平均达25%以上。其主要影响因素包含输入数据量大小(batch size、sequence length等)、隐藏节点数、非标准网络结构与算子融合优化。
2、业务指标:以某相关性场景下的ERNIE模型为例,模型输出在数值上的diff率不超过1%,在离线测试集上的评价指标达到几乎无损。
3、迭代效率:离线量化达小时级,流水线式快速产出量化模型,不阻塞模型全生命周期的相关环节(如模型多版本迭代、小流量实验、全量化推全等)。
02 模型量化简述
简而言之,模型量化就是将高精度存储(运算)转换为低精度存储(运算)的一种模型压缩技术。优势如下:
-
更少的存储开销与带宽需求:如每层权重量化后,32位比特压缩到8比特甚至更低比特,模型占用空间变小;内存访问带宽的压力自然也会变小。
-
更快的计算速度:单位时间内执行整型计算指令比浮点计算指令更多;另,英伟达安培架构芯片还有专用INT8 Tensor core。
如果我们从不同的技术角度来看待它,那么:
-
从映射函数是否是线性,分为线性和非线性。非线性量化计算较为复杂,一般主要研究线性量化,其公式如下:
Q = clip(round(R/S) + Z),其中R: high precision float number,Q:quantized integer number,s:scale,z:zero point。
-
从零点对应位置区分,线性量化又分为对称和非对称。
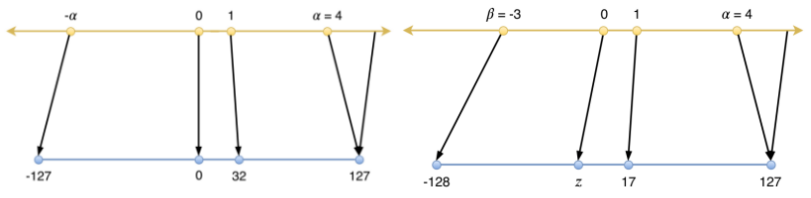
△1:对称与非对称量化
以矩阵乘为例,计算公式如下:
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

