
- 1Mac上PDF压缩软件哪款好用?推荐PDF Squeezer 4_mac好用的pdf压缩工具
- 2【算法】二分算法——x的平方根
- 3深度学习之基于YoloV5抽烟检测系统
- 4【Spark ML】第 1 章:机器学习简介_spark h2o isolationforest
- 5私有化部署FastGPT+OneAPI大模型知识库_fastgpt oneapi
- 6wps怎么投递简历发到boss直聘_简历这么投,让好工作主动来找你
- 7关于小程序服务器域名配置的一些坑
- 8常见的排序算法的时间复杂度_排序算法时间复杂度
- 924年考研管综199真题PDF共18页_24科研管理类联考真题pdf
- 10【论文笔记】Active Retrieval Augmented Generation_active retrieval augmented generation.
ChatGPT和Whisper的API基本看点_whisperapi
赞
踩
ChatGPT Official API Learning
今天 OpenAI 开放了 ChatGPT 背后的 GPT-3.5 的模型 API,模型代号为 Turbo,其定价甚至比此前的 Davinci 都要便宜,1000 tokens 仅为 0.2 美分。本次除了 GPT-3.5 模型 API 开放外,还在原有的几大任务类型(Text、Code、Image、Embedding、Moderation)基础上增加了 Chat、Speech to Text 两个任务,分别对应 ChatGPT 和 Whisper 两款此前用户就可以使用的产品。
此前 OpenAI 的 GPT-3 也早已开放 API,我在麦克船长的博客 MikeCaptain.com 中已介绍过,当时在 NLP 方面能使用的 API 主要是GPT-3。原文链接:http://www.mikecaptain.com/2023/01/24/openai-official-doc/。
OpenAI API 已经有了不同功能和价位的多种模型,还提供了在基础模型上的 fine-tune 服务(当然 fine-tune 本身收费,且 fine-tune 后的模型调用费用比 base model 要贵得多)。本次更新,主要是增加了 GPT-3.5(用于 NLP)和 Whisper(用于 audio to text)的 API:

ChatGPT 和 Whisper 模型现已在 OpenAI 的 API 上可用,通过一系列系统范围的优化,自去年 12 月以来,OpenAI 已将 ChatGPT 的成本降低了 90%;不仅仅是 GPT-3.5,开发人员现在可以在 API 中使用 OpenAI 的开源 Whisper large-v2 模型。
本文包含四部分内容:
- 首先速览一下本次 ChatGPT 和 Whisper 的 API 开放后的基本看点;
- 然后是 API 介绍和一些代码调用示例;
- 接着是 OpenAI 此前开放的 API 使用效果;
- 最后介绍了 OpenAI 提供的 finetune 接口,做好后续 GPT-3.5 开放 finetune 时的准备。
上船出发!
一、开放ChatGPT和Whisper的API基本看点
1.1、OpenAI 开放模型库里新增 GPT-3.5 模型
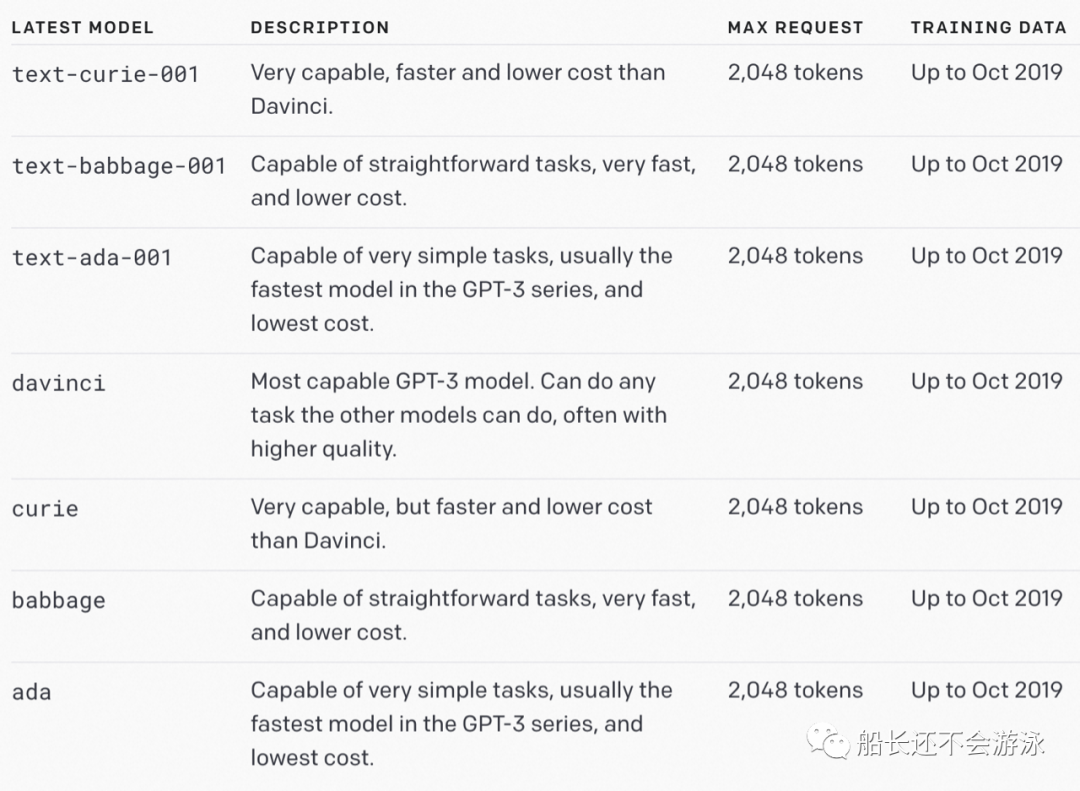
GPT-3.5 模型可以理解并生成自然语言或代码,其最强大的是 gpt-3.5-turbo,这可是之前的库里没有的。它针对聊天进行了优化,但也适用于传统的完成任务。GPT 开放模型里原本只有 GPT-3 系列,包括如下系列模型:
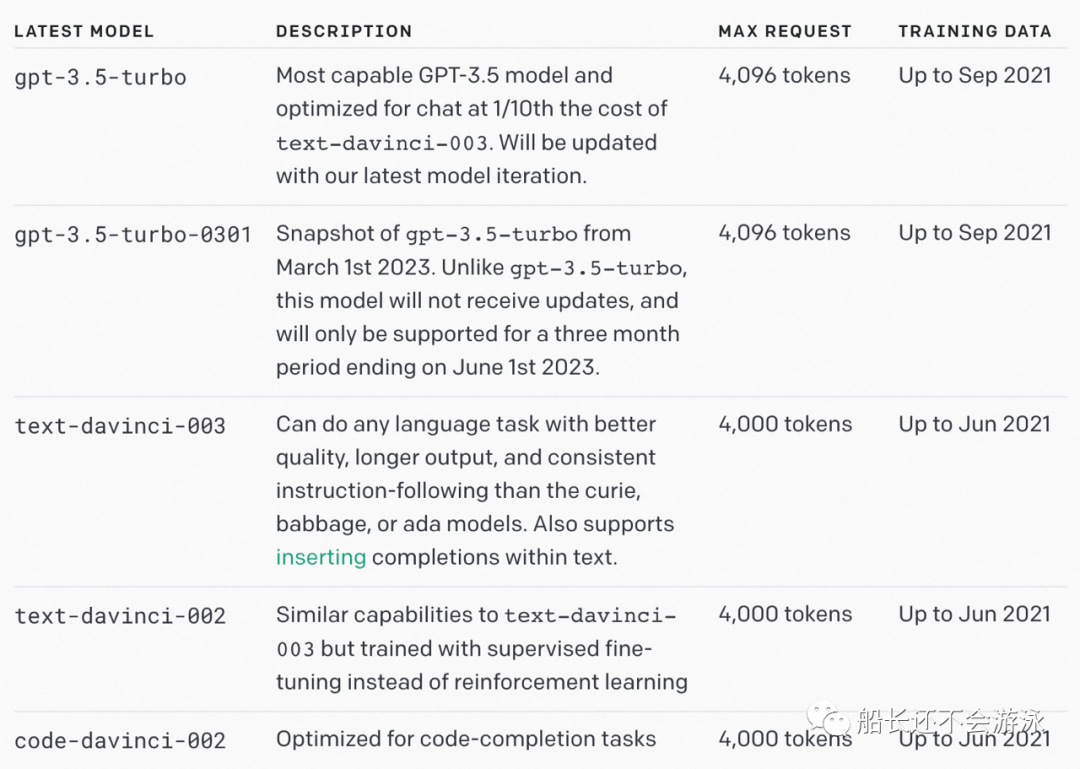
而这次更新后,增加了 GPT-3.5 系列,包括 5 款模型:
OpenAI 建议在试验时使用 gpt-3.5-turbo,因为它会产生最佳结果。一旦跑起来都一切正常,可以尝试其他模型,看看是否能以更低的延迟或成本获得相同的结果,这才更划算。
可能此前的 GPT-3 期间开放的 API 大部分人也还没来得及了解,下面补充一些基本概念。
1.2、补充一些 OpenAI API 的基础概念
关于 prompt 和 completion:OpenAI 提到一个理念:「设计提示语,就相当于在用一些指令和少量例子给模型编程」。另外 OpenAI 还强调了在目标任务上的区别,就是 OpenAI 的 NLP 模型与其他 NLP 模型很大的一个区别是,它不是设计用来解决单一类型任务的,而是可以解决几乎各种类型的 NLP 任务,包括但不限于文本生成(content generation)、代码生成(code generation)、总结(summarization)、扩写(expansion)、对话(conversation)、创意写作(creative wrting)、风格转换(style transfer)等。
关于 token:我们理解和处理文本,是把文本先打碎成 token。以英文文本为例,token 可以是单词,也可以词根(一些字母组合),比如单词「hamburger」可能会被打碎成「ham」、「bur」、「ger」这几个 tokens。再比如「pear」这个单词,可能就会单独作为一个 token 不再打碎了。还有些 token 可能会以「空格」开头,比如「 hello」、「 bye」。一个大概的经验是,通常英文文本里 1 token 有 4 个字母或者 0.75 个单词。使用时的一个限制是,最好你的提示(prompt)或生成内容,不要超过 2048 个 tokens,大概相当于 1500 个单词。
关于 model:目前 OpenAI 有基于 GPT-3.5 的基础模型 Turbo 和这些基于 GPT-3 的基础模型 Davinci、Curie、Babbage、Ada 开放 API,另外 Codex 系列是 GPT-3 的后代,是用「自然语言 + 代码」训练的。
虽然新的 gpt-3.5-turbo 模型针对聊天进行了优化,但它也非常适合传统的完成任务。原始 GPT-3.5 模型针对原来就开放的 API 文本补全(text completion)也进行了优化。我们用于 create embeddings 和 edit text 的 API 都使用了它们各自针对性的模型。
1.3、模型概览
OpenAI 今天发布的 ChatGPT 模型系列 GPT-3.5-turbo 与 ChatGPT 产品中使用的模型相同。它的价格为每 1k tokens 0.002 美元,比 OpenAI 现有的 GPT-3.5 模型便宜 10 倍。即使对于许多非聊天用例,它也是 OpenAI 的最佳模型 —— 如果你之前就用了 text-davinci-003,那么迁移到 gpt-3.5-turbo 时只需要对他们的提示进行少量调整。
1.3.1、Turbo
Turbo 与支持 ChatGPT 的模型系列相同,它针对对话式聊天输入和输出进行了优化,但与 Davinci 模型系列相比,它在完成方面同样出色。在 ChatGPT 中可以很好地完成的任何用例都应该在 API 中与 Turbo 模型系列一起很好地执行。Turbo 模型家族也是第一个像 ChatGPT 一样接收定期模型更新的模型。
适合:对话、文本生成。
1.3.2、Davinci
Davinci 在 GPT-3 中就已经存在,是最有能力的模型系列,可以执行其他模型(Ada、Curie 和 Babbage)可以执行的任何任务,而且通常只需要很少的 instruction。对于需要对内容有大量理解的应用程序,例如针对特定受众的 summarization 和创意内容生成,Davinci 将产生最佳结果。这些增加的功能需要更多的计算资源,因此 Davinci 每次 API 调用更贵,并且不如其他模型那么快。
Davinci 的另一个亮点是理解文本的意图。Davinci 擅长解决多种逻辑问题和解释人物的动机。达芬奇已经能够解决一些涉及因果关系的最具挑战性的人工智能问题。
适合:复杂意图、因果分析、Summarization for Audience。
1.3.3、Curie
Curie 在 GPT-3 中就已经存在,也非常强大,速度也比较快。虽然 Davinci 在分析复杂文本方面更强大,但 Curie 能够胜任许多细微的任务,例如情感分类和摘要。Curie 还非常擅长回答问题和执行问答以及作为通用服务聊天机器人。
适合:机器翻译、复杂分类任务、情感分析、Summarization。
1.3.4、Babbage
同样是 GPT-3 里就存在的。Babbage 可以执行简单的任务,例如简单的分类。在语义搜索方面,它也非常有能力对文档与搜索查询的匹配程度进行排名。
适合:审核分类、语义搜索分类。
1.3.5、Ada
也是 GPT-3 时期就有的。Ada 通常是最快的模型,可以执行解析文本、地址更正和不需要太多细微差别的某些分类任务等任务。Ada 的性能通常可以通过提供更多上下文来提高。
适合:文本解析、简单分类、地址修正、关键词。
需要注意的是:由像 Ada 这样更快的模型执行的任何任务都可以由像 Curie 或 Davinci 这样更强大的模型执行。
1.4、模型细节:按 GPT-3.5 还是 GPT-3 划分看下
1.4.1、关于 GPT-3.5
gpt-3.5-turbo:功能最强大的 GPT-3.5 模型并针对聊天进行了优化,成本仅为text-davinci-003的 1/10。将使用我们最新的模型迭代进行更新。gpt-3.5-turbo-0301:2023 年 3 月 1 日的gpt-3.5-turbo快照。与gpt-3.5-turbo不同,此模型不会收到更新,并且仅在 2023 年 6 月 1 日结束的三个月内提供支持。text-davinci-003:此前 GPT-3 期间就有的 Davinci 模型,这次直接升级到了 GPT-3.5,与 GPT-3 阶段一样,仍然是最大请求 4000 tokens,同样训练数据 up to 2021 年 6 月,能做几乎所有 NLP 任务。text-davinci-002:与text-davinci-003类似情况,这次直接升级到了 GPT-3.5,专门为了代码生成任务优化的模型。与 GPT-3 阶段一样,仍然是最大请求 4000 tokens;训练数据也没有变,依然是 up to 2021 年 6 月。
1.4.2、关于 GPT-3
以下模型不再由 GPT-3 提供支持:
text-davinci-003:此前在 GPT-3 接口中存在,本次更新后由 GPT-3.5 支持提供了,见上一段。
GPT-3 目前可用的模型包括下面这些,与 InstructGPT 背后的模型是一样的,它们的最大请求都是 2048 tokens,训练数据也都是 up to 2019 年 10 月:
text-curie-001:比 davinci 要弱一点,但是速度更快、更便宜。text-babbage-001:一些比较直接的任务(straightforward tasks),比text-curie-001更快、更便宜。text-ada-001:一些非常简单的任务,这些模型里最快、最便宜的。davinci:目前最强的 GPT-3 模型,任何其他模型能做的任务,davinci都可以做。curie:就是text-curie-001。babbage:就是text-babbage-001。ada:就是text-ada-001。
1.5、定价
这些模型根据输入的 token 数量做的如下定价,前四个是 GPT-3 阶段就存在的,也并未因本次 GPT-3.5 API 发布而调价:
- 基础模型使用 0.0004 USD/1K tokens,Ada;
- 基础模型使用 0.0005 USD/1K tokens,Babbage;
- 基础模型使用 0.0020 USD/1K tokens,Curie;
- 基础模型使用 0.0200 USD/1K tokens,Davinci;
- 基础模型使用 0.0020 USD/1K tokens,Turbo,支持 Chat API 。
从定价上看,Ada 和 Babbage 基本没有差多少。另外命名上,可以看出 OpenAI 有意地给他们取了 ABCD 开头的名字。另外你也可以 finetune 你自己的模型,对于 fine-tuned models 如下收费,并未因本次发布而调价:
- Ada 的 Finetune 训练价格 0.0004 USD/1K tokens,使用价格 0.0016 USD/1K tokens;
- Babbage 的 Finetune 训练价格 0.0006 USD/1K tokens,使用价格 0.0024 USD/1K tokens;
- Curie 的 Finetune 训练价格 0.0030 USD/1K tokens,使用价格 0.0120 USD/1K tokens;
- Davinci 的 Finetune 训练价格 0.0300 USD/1K tokens,使用价格 0.1200 USD/1K tokens;
- 暂未提供 Turbo 的 finetune。
GPT-3.5 的效果,大家应该都在 ChatGPT 上试用过了,这里我也在放一下链接可能有一些 late majority 朋友还没有用过:https://chat.openai.com/chat:
在 OpenAI 的基于 GPT-3 的 PlayGround 你可以试试:https://platform.openai.com/playground/p/default-chat:
1.6、专用实例
说的就是之前爆出消息的 Foundry,也都是跑在微软的 Azure 上的。OpenAI 现在还为希望更深入控制特定型号版本和系统性能的用户提供专用实例。默认情况下,开放的 API 都是在所有客户共享的基础设施上的模型中跑的,如果有额外需求得额外付费。开发人员可以完全控制实例的负载(更高的负载会提高吞吐量,当然这也会让对每个 request 的处理慢下来)、启用更长 context 限制等功能选项,以及保存模型快照的能力。
对于每天要跑 4.5 亿以上 tokens 的开发者来说,用专用实例更划算。并且针对专用实例,开发者可以自己决定用什么硬件配置,这个就属于 OpenAI 的中大客户销售策略了,具体可以看 OpenAI 官网的销售联系页面:https://openai.com/contact-sales/ 。
1.7、Whisper:每分钟 0.6 美分 的语音识别/翻译服务 API
Whisper 是 OpenAI 于 2022 年 9 月开源的语音转文本模型,开发者社区反馈还不错,但也挺麻烦的。今天开始,OpenAI 现在已经通过 OpenAI 的 API 提供了 large-v2 模型,它提供了方便的按需访问,价格为 0.006 美元/分钟。
Whisper API 可通过 OpenAI 的 transcriptions(以源语言转录)或 translations(转录成英语)端点使用,并接受多种格式(m4a、mp3、mp4、mpeg、mpga、wav、webm)。
1.8、开发者可能关注的几个问题
Q1:之前的模型都提供了 fine-tune,这次开放的 gpt-3.5-turbo 可以 fine-tune 吗?
A1:还不行,到目前为止,你还只能 fine-tune GPT-3 模型。
Q2:OpenAI 会把开发者调用 API 时发送的数据存下来吗?
从 2023 年 3 月 1 日开始,OpenAI 会把开发者调用 API 时发送的数据保留 30 天,但 OpenAI 声称不会使用开发者通过 API 发送的数据来改进模型(Who knows)。具体的政策,可以从 OpenAI 官网了解更多,这里是他们的数据使用政策链接:https://platform.openai.com/docs/data-usage-policies 。
二、主要API介绍及代码示例
安装 OpenAI 的 python 库,参考 https://anaconda.org/conda-forge/openai:
mikecaptain@local $ conda install -c conda-forge openai
- 1
在 https://platform.openai.com/account/api-keys 创建自己的 API。完成这两步后就可以编写代码尝试一下:
import os
import openai
openai.api_key = os.getenv("OPENAI_API_KEY")
print(openai.Model.list())
- 1
- 2
- 3
- 4
- 5
会打印出 OpenAI 的各个 models 的一些信息、权限等等。
2.1、一起看看 Chat 的 API
2.1.1、Chat 的 REST API
curl https://api.openai.com/v1/chat/completions
-H "Authorization: Bearer $OPENAI_API_KEY"
-H "Content-Type: application/json"
-d '{
"model": "gpt-3.5-turbo",
"messages": [{"role": "user", "content": "What is the OpenAI mission?"}]
}'
- 1
- 2
- 3
- 4
- 5
- 6
- 7
相应的返回结果:
{
"id": "chatcmpl-6p5FEv1JHictSSnDZsGU4KvbuBsbu",
"object": "messages",
"created": 1677693600,
"model": "gpt-3.5-turbo",
"choices": [
{
"index": 0,
"finish_reason": "stop",
"messages": [
{
"role": "assistant",
"content": "OpenAI's mission is to ensure that artificial general intelligence benefits all of humanity."
}
]
}
],
"usage": {
"prompt_tokens": 20,
"completion_tokens": 18,
"total_tokens": 38
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
2.1.2、Chat 的 Python API
import openai
completion = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": "Tell the world about the ChatGPT API in the style of a pirate."}]
)
print(completion)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
2.2、Whisper API
2.2.1、Whisper 的 REST API
curl https://api.openai.com/v1/audio/transcriptions \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-H "Content-Type: multipart/form-data" \
-F model="whisper-1" \
-F file="@/path/to/file/openai.mp3"
- 1
- 2
- 3
- 4
- 5
{
"text": "Imagine the wildest idea that you've ever had, and you're curious about how it might scale to something that's a 100, a 1,000 times bigger..."
}
- 1
- 2
- 3
2.2.2、Whisper 的 Python API
import openai
file = open("/path/to/file/openai.mp3", "rb")
transcription = openai.Audio.transcribe("whisper-1", f)
print(transcription)
- 1
- 2
- 3
- 4
- 5
- 6
2.3、Text Completion 任务
下面这个例子会简单调用一下 completion,并打印出结果,用了一句需要你自己编写的 prompt:
import os
import openai
openai.api_key = os.getenv("OPENAI_API_KEY")
text_prompt = "In a shocking turn of events, scientists have discovered that "
completion = openai.Completion.create(
model="text-davinci-002",
prompt=text_prompt,
max_tokens=100,
n=1,
stop=None,
temperature=0.5,
)
generated_text = completion.choices[0].text
print(generated_text)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
这里用到了最重要的 openai.Completion,其 create 函数的参数解释如下:
model:之前 OpenAI 把它叫「engine」,后来给 deprecated 了,现在都是用model,所有的可用 models 可以通过open.Model.list()来查看。prompt:string类型,就是输入数据。suffix:string类型,生成文本的结束符。max_tokens:integer类型,生成文本的最大 tokens 数。n:integer类型,表示你要产生几个不同的输出结果。比如设置 3 就会得到 3 个不同的结果,以便您可以从中选择最合适的一个。stop:string类型,用于指定模型何时应该停止生成文本。当模型在生成的文本中遇到 stop 字符串时,它将停止生成文本。ChatGPT 推出后迭代过一版增加了「stop generating」就是用的这个参数。temperature:number类型,这是 NLP 模型里常见的一个超参数。这个参数,来自于统计热力学的概念,温度越高表示系统的熵越高、混乱度越高、随机性越强,这里的 temperature 也是值越高输出结果的随机性也越高。这样如果 temperature 设置得很低,生成的结果可能更正确,但没有多少创造性和随机性。
2.4、Text Edit 任务
Completion 类任务,通俗点理解的话,完形填空、句子补齐、写作文、翻译 …… 都算 Completion,就是无中生有。而对于已经有的内容,做修改,就是 OpenAI 的 API 里的「Edit」类的任务了。
import os
import openai
openai.api_key = os.getenv("OPENAI_API_KEY")
openai.Edit.create(
model="text-davinci-edit-001",
input="The qick brown fox jumps over the layz dog.",
instruction="Fix the spelling mistakes"
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
调用 openai.Edit.create,用 text-davinci-edit-001 模型,输入一句有拼写错误的英文「The qick brown fox jumps over the layz dog.」,并提供一句指令 instruction「Fix the spelling mistakes」。
instruction:要告诉模型如何修改,其实这句话就是新时代的「programming」了。temperature:默认是 0,对于纠正拼写类的任务,我们用默认 0 就可以了,不需要什么创造性和随机性。
2.5、顺便提一下基于 DALL·E 的 Image 生成
这里也提一下 text2image 的 API,这与文本生成用的 GPT 是不同的,基于 DALL·E 的模型,但是很多开发者可能也是文本、图像、对话混合使用的,所以这里也提一下。
2.5.1、Image Create 任务(Beta)
截止 2023 年年初 1 月份,这个 API 还是 beta,我们看个例子:
import os
import openai
openai.api_key = os.getenv("OPENAI_API_KEY")
openai.Image.create(
prompt="A cute baby sea otter",
n=2,
size="1024x1024"
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
这也是一个 OpenAI 官网的例子。大家可能看到这里,船长没有指定 model,但是可以想到一定用的是 DALL·E,因为它没有像 GPT-3 一样提供很多版本的选择,所以就不需要传参数了。这个程序就是生成一个 1024x1024 的图片。
prompt:就是输入的提示语,返回的数据里,会告诉你生成的图片的 URL.n:是图片结果数量,最多 10,默认 1.
2.5.2、Image Edit 任务
给定一个图片,OpenAI 也可以来修改指定区域:
import os
import openai
openai.api_key = os.getenv("OPENAI_API_KEY")
openai.Image.create_edit(
image=open("otter.png", "rb"),
mask=open("mask.png", "rb"),
prompt="A cute baby sea otter wearing a beret",
n=2,
size="1024x1024"
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
image:这里对输入图片有要求,必须是正方形的!另外不能超过 4MB,还得是 PNG。mask:还可以提供掩码图片(叫什么比较合适,掩图?哈哈)。如果不提供的话,image里就必须有透明的部分(必须全透明,即 alpha = 0),那个透明部分就是被用来 Edit 的。如果有mask则透明部分用来做「掩图」来改image。- 同样地,结果图片的 URL 会返回给你。
2.6、Code 生成
这里也提一下 Code 生成,也是此前就有的能力,用的是 Codex 的模型。有个沙河可以感受下 JS 代码生成,你可以在这里试用一下:https://platform.openai.com/codex-javascript-sandbox。
2.7、审查(Moderation)
也不是随本次 GPT-3.5 发布的,我们也大致浏览一下。Moderation 用来审查内容是否符合 OpenAI 的内容政策,快速使用的方式如下:
response = openai.Moderation.create(
input="Sample text goes here"
)
output = response["results"][0]
- 1
- 2
- 3
- 4
API 官网给出我们如下的返回结果示例:
{
"id": "modr-XXXXX",
"model": "text-moderation-001",
"results": [
{
"categories": {
"hate": false,
"hate/threatening": false,
"self-harm": false,
"sexual": false,
"sexual/minors": false,
"violence": false,
"violence/graphic": false
},
"category_scores": {
"hate": 0.18805529177188873,
"hate/threatening": 0.0001250059431185946,
"self-harm": 0.0003706029092427343,
"sexual": 0.0008735615410842001,
"sexual/minors": 0.0007470346172340214,
"violence": 0.0041268812492489815,
"violence/graphic": 0.00023186142789199948
},
"flagged": false
}
]
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
输入参数很简单,关键看返回的输出结果。OpenAI 对于包含哪类不适内容,做了比较详尽的分类,比如对于色情内容,也分成了未成年色情和易引起性兴奋的内容。
hate:是否包含基于种族、性别、民族、宗教、国籍、性取向、残疾状况或种姓表达、煽动或促进仇恨的内容,如果没有则是false,否则为true。hate/threatening:是否包含仇恨内容还包括对目标群体的暴力或严重伤害,没有则false,包含则值为true。self-harm:是否包含提倡、鼓励或描述自残行为(例如自杀、割伤和饮食失调)的内容,没有则false,否则true。sexual:是否包含意在引起性兴奋的内容,例如对性活动的描述,或宣传性服务(不包括性教育和健康)的内容,没有则false,否则true。sexual/minors:是否包含包含 18 岁以下个人的色情内容,没有则false,否则true。violence:是否包含宣扬或美化暴力或颂扬他人的痛苦或屈辱的内容,没有为false,否则true。violence/graphic:是否包含以极端的画面细节描绘死亡、暴力或严重身体伤害的暴力内容,没有false,否则true。
显然,对于使用 OpenAI 生成内容的场景下如果需要用到 Moderation,则是免费调用的。如果你不是对 OpenAI 的输入 & 生成场景,而是自己的其他内容想白嫖 Moderation API 是不可能的。但是我们也注意到,这里其实没有整治敏感的分类,因为 OpenAI 没有考虑具体的使用者所处的政体或政治环境,而且这些尺度是比较容易变化的,并且有一些可能并不是普适性的理念,因此某些国家的使用者要额外配套自己的内容审查能力。
三、一些 OpenAI 目前开放的 API 使用效果
在 OpenAI 的 API 官方首页的大标题写着的是「用 OpenAI 的强力模型构建下一代应用(Build next-gen apps with OpenAI’s powerful models)」,并直接点出了自己最拿得出手的三个商业化产品 GPT-3、Codex、DALL·E。
并提到自己的 API 调用非常简单:
import openai
openai.Completion.create(
engine="davinci",
prompt="Make a list of astronomical observatories:"
)
- 1
- 2
- 3
- 4
- 5
- 6
引入 OpenAI 的 python 依赖库后,调用时指定用哪个引擎、提示词是什么即可。轻松一些,我们先来看一些示例吧。
3.1、执行各种自然语言任务的一些使用案例
GPT-3.5 已经在一些应用上跑起来了,OpenAI 列举了一些 ChatGPT 和 Whisper API 的早期客户:
- **Snapchat(snap.com)**的创建者 Snap Inc. 本周推出了适用于 Snapchat+ 的 My AI。实验性功能在 ChatGPT API 上运行。My AI 为 Snapchatter 提供了一个友好的、可定制的聊天机器人,可以在他们指尖提供建议,甚至可以在几秒钟内为朋友写一句俳句。Snapchat 是日常交流和消息传递的场所,每月有 7.5 亿 Snapchatter。
- **Quizlet(quizlet.com/labs/qchat)**是一个全球学习平台,有超过 6000 万学生使用它来学习、练习和掌握他们正在学习的任何内容。Quizlet 在过去三年中一直与 OpenAI 合作,在多个用例中利用 GPT-3,包括词汇学习和练习测试。随着 ChatGPT API 的推出,Quizlet 推出了 Q-Chat,这是一种完全自适应的 AI 导师,可让学生根据通过有趣的聊天体验提供的相关学习材料提出自适应问题。
- **Instacart(instacart.com)**正在增强 Instacart 应用程序,使客户能够询问食物并获得鼓舞人心的、可购买的答案。这使用 ChatGPT 以及 Instacart 自己的 AI 和来自其 75,000 多家零售合作伙伴商店位置的产品数据来帮助客户发现开放式购物目标的想法,例如「我如何制作美味的鱼炸玉米饼?」或「对我的孩子来说,什么是健康的午餐?」Instacart 计划在今年晚些时候推出「Ask Instacart」。
- Shopify 的消费者应用程序 **Shop(shop.app)**被 1 亿购物者用来寻找和参与他们喜爱的产品和品牌。ChatGPT API 用于为 Shop 的新购物助手提供动力。当购物者搜索商品时,导购会根据他们的需求进行个性化推荐。Shop 的新人工智能购物助手将通过扫描数百万种产品来简化应用程序内购物,以快速找到买家正在寻找的东西,或者帮助他们发现新东西。
- **Speak(speak.com)**是一款人工智能语言学习应用程序,专注于打造流利口语的最佳途径。他们是韩国发展最快的英语应用程序,并且已经在使用 Whisper API 来支持新的 AI 语音伴侣产品,并迅速将其推向全球其他地区。Whisper 为各个级别的语言学习者提供了人类水平的准确性,解锁了真正的开放式会话练习和高度准确的反馈。
3.2、一些更详细的示例
API 还能实现什么功能?这里列举一些 GPT-3 API 期间就有的功能,调用的效果如何。
3.2.1、写作 Copywriting
人类输入:
Create promo copy for the FamilyTime mobile application. It allows unlimited uploading, special filters and makes it easy to create albums of photos and videos. It runs on iOS and Android:
- 1
下面是 GPT-3 的输出:
FamilyTime is the perfect app to share and create memories with your family. FamilyTime is a free, unlimited photo and video editor that allows you to create albums of your memories. It has a special filter for the perfect summer look and is so simple to use.
- 1
3.2.2、摘要 Summarization
人类输入:
Summarize this email into a single sentence:
Dear Olivia,
The solar energy conference went great. New Horizon Manufacturing wants to meet with us to talk about our photovoltaic window system we’re about to launch.
I think it would be great to talk this Tuesday.
Best,
Allison
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
下面是 GPT-3 输出:
Allison is excited to meet with New Horizon Manufacturing to discuss their photovoltaic window system.
- 1
3.2.3、分析无结构文本 Parsing Unstructured Text
人类输入:
Answer the following questions about this customer email:
I’m wondering if you could provide me with information about your cloud services for companies. I’m CTO for Moon Door, a movie production company and want to know if it can help us manage our different projects that are in production.
Questions:
1. What industry is the company
2. What is the name of the company
3. What are they interested in
4. What is the customer’s position
Answers:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
下面是 GPT-3 输出:
1. The company is in the movie production industry.
2. The company is Moon Door.
3. The customer is interested in cloud services for companies.
4. The customer is the CTO.
- 1
- 2
- 3
- 4
3.2.4、分类 Classification
人类输入:
Choose a genre category for each book 1. The Hunger Games, 2. The Kite Runner 3. A Wrinkle in Time (“fiction”, “young adult”, “science fiction”, “fantasy”, “other”) and make a list of the book and its genre:
- 1
下面是 GPT-3 输出:
1. The Hunger Games: young adult, fiction
2. The Kite Runner: fiction, young adult
3. A Wrinkle in Time: science fiction, fantasy, other
- 1
- 2
- 3
3.2.5、翻译 Translation
人类输入:
Translate this into French: Where can I find a bookstore?
- 1
下面是 GPT-3 输出:
Où puis-je trouver un magasin de livres?
- 1
3.3、将自然语言翻译成代码的 Codex
3.3.1、用自然语言写 SQL
人类输入:
Table customers, columns = [CustomerId, FirstName, LastName, Company, Address, City, State, Country, PostalCode, Phone, Fax, Email, SupportRepId, TotalSpend]
Create a MySQL query for all customers in Texas who have spent over five thousand dollars.
- 1
- 2
- 3
下面是 Codex 输出:
query = "SELECT * FROM customers WHERE State = 'TX' AND TotalSpend > 5000"
- 1
3.3.2、用自然语言调用一个 API
人类输入:
Python 3
Get the current value of a Bitcoin in US dollars using the bitcoincharts api
- 1
- 2
Codex 输出:
import requests
import json
def get_bitcoin_price():
url = 'http://api.bitcoincharts.com/v1/weighted_prices.json'
response = requests.get(url)
data = json.loads(response.text)
return data['USD']['7d']
if __name__ == '__main__':
print(get_bitcoin_price())
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
3.3.3、用自然语言续写代码
人类输入:
Extract all the html from the string and replace the tags with ''
- 1
Codex 输出:
def extract_html(text):
return re.sub('<[^<]+?>', '', text)
- 1
- 2
上面也提到了,暂时未开放对 Turbo(也就是 ChatGPT 背后的 GPT-3.5)的 finetune,但是开放后的使用方式也会是与 GPT-3 的 finetune 类似的。我们来看看目前 OpenAI 是如何让开发者来 finetune 他们的基础模型的。
Few-shot learning 是什么?:GPT-3 用了互联网上的海量文本数据训练,所以当你给少量示例(a promopt with just a few examples)时,GPT-3 会从「直觉上」知道你大概是想要解决什么任务,然后给出一些大概齐的反馈内容作为 completion,这通常就被叫做「few-shot learning」或者「few-shot prompting」。
而如果你提供一些针对目标任务的训练数据,很可能可以实现没有 examples 也可以执行任务,也就是使用时连「few-shot learning」都免了。OpenAI 也提供了让用户自己 fine-tune 模型的接口,自己 fine-tune 的好处是:
- 高质量:这是显然的,比「设计提示(prompt design)」得到的结果质量更高。
- 相当于批量 prompt:可以比 prompt 给模型更多的 examples,比如用一个文件,里面包含大量用于 fine-tuning 的输入数据。
- 更省:可以更省 tokens,也就更省钱。
- 更快:更低的延迟的请求响应。
步骤和价格方面,Fine-tune 一共三步:上传用于 fine-tune 的数据、用数据 fine-tune 模型、使用属于你自己的 fine-tune 过的模型。从定价上我们看到 Fine-tune 后的模型使用费用基本翻了 4~6 倍,可以说相比基本模型的使用,是非常贵了。
另外 OpenAI 也支持你对一个 fine-tune 过的模型继续 fine-tune,而不用从头开始。目前 davinci、curie、babbage、ada 都支持 fine-tuning。训练数据的格式也很简单,就是一组 prompt-completion 的 JSONL 文件,just like this:
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}
...
- 1
- 2
- 3
- 4
Fine-tune 的 example 与 few-shot learning 的最大区别:
- few-shot learning 要给出详尽的 instruction 来描述任务
- few-shot learning 的一个 prompt 是在使用时给出的,所以一个 prompt 大概率会带多个 examples(相对详细);而 fine-tune 的 example 都是一些简单直接的 prompt 以及直接对应的 completion。
OpenAI 建议 fine-tune 的 examples 数量至少几百(a couple hundred)。另外 fine-tune 也符合 scaling law,基本上 fine-tune 的数据集成倍上翻的话,效果是线性增长的。
1、创建一个 fine-tune 模型
CLI 下运行如下命令,其中 <TRAIN_FILE_ID_OR_PATH> 是你的训练数据文件,<BASE_MODEL> 是你要用的模型,具体的参数可以用 ada、babbage、curie 和 davinci。
mikecaptain@local $ openai api fine_tunes.create -t <TRAIN_FILE_ID_OR_PATH> -m <BASE_MODEL>
- 1
这句命令让 OpenAI 不仅基于 base model 创建了一个模型,而且开始运行训练任务。训练任务可能会花费几分钟、几小时甚至根据,取决于你的训练集和模型选择。训练任务可能会被 OpenAI 排队,不一定马上开始运行。如果过程中被打断了,可以如下继续:
mikecaptain@local $ openai api fine_tunes.follow -i <YOUR_FINE_TUNE_JOB_ID>
- 1
保存一个 fine-tune job 的命令如下:
mikecaptain@local $ openai api fine_tunes.get -i <YOUR_FINE_TUNE_JOB_ID>
- 1
取消一个 fine-tune job 的命令如下:
mikecaptain@local $ openai api fine_tunes.cancel -i <YOUR_FINE_TUNE_JOB_ID>
- 1
2、使用 fine-tuned 模型
import openai
openai.Completion.create(model=FINE_TUNED_MODEL, prompt=YOUR_PROMPT)
- 1
- 2
3、删掉一个 fine-tuned 模型
import openai
openai.Model.delete(FINE_TUNED_MODEL)
- 1
- 2
4、一个 fine-tuned 模型之上继续 fine-tune
如果你微调了一个模型,现在又有为的训练数据想要合并进来,可以基于已 fine-tuned 模型继续微调,无需从头再全部训练一遍。唯一要做的,就是在创建新的 fine-tune job 时传入已 fine-tune 的模型名称,替代<BASE_MODEL>(例如 -m curie:ft-<org>-<date>),不必更改其他训练参数。
有一个要注意的,如果新增的训练数据比以前的训练数据规模小得多,那最好把 learning_rate_multiplier 减少 2 到 4 倍,否则很可能跳过了最优解。
参考文献:
[1] https://openai.com/blog/introducing-chatgpt-and-whisper-apis
[2] https://openai.com/pricing
[3] https://platform.openai.com/docs/guides/chat/chat-vs-completions
[4] https://platform.openai.com/docs/usage-policies
[5] https://platform.openai.com/docs/models/gpt-3-5
[6] https://openai.com/api/
[7] https://developer.aliyun.com/article/933516
[8] http://www.mikecaptain.com/2023/03/02/chatgpt-api/
[9] http://www.mikecaptain.com/2023/01/24/openai-official-doc/


