
- 1Oauth2系列9:JWT令牌各种实现_nimbus-jose-jwt.version
- 2flutter实现选择图片视频上传到oss和图片视频的预览功能
- 3Python工程师面试必备25条Python知识点_python 中级工程师必备
- 4(渲染统计窗口)优化
- 53D点云深度学习框架PointNet、PointNet++详解
- 6Hadoop_安装与部署_大数据导论hadoop的安装与部署
- 7Mysql 怎么产生隐藏主键 和 还要不要学MySQL
- 8大龄程序员的4年生涯_4年没跳槽德程序员
- 9Linux(13):期中架构(5)--- 前端部分:keepalived高可用 & HTTPS & iptables防火墙...
- 10生命周期,axios以及动画
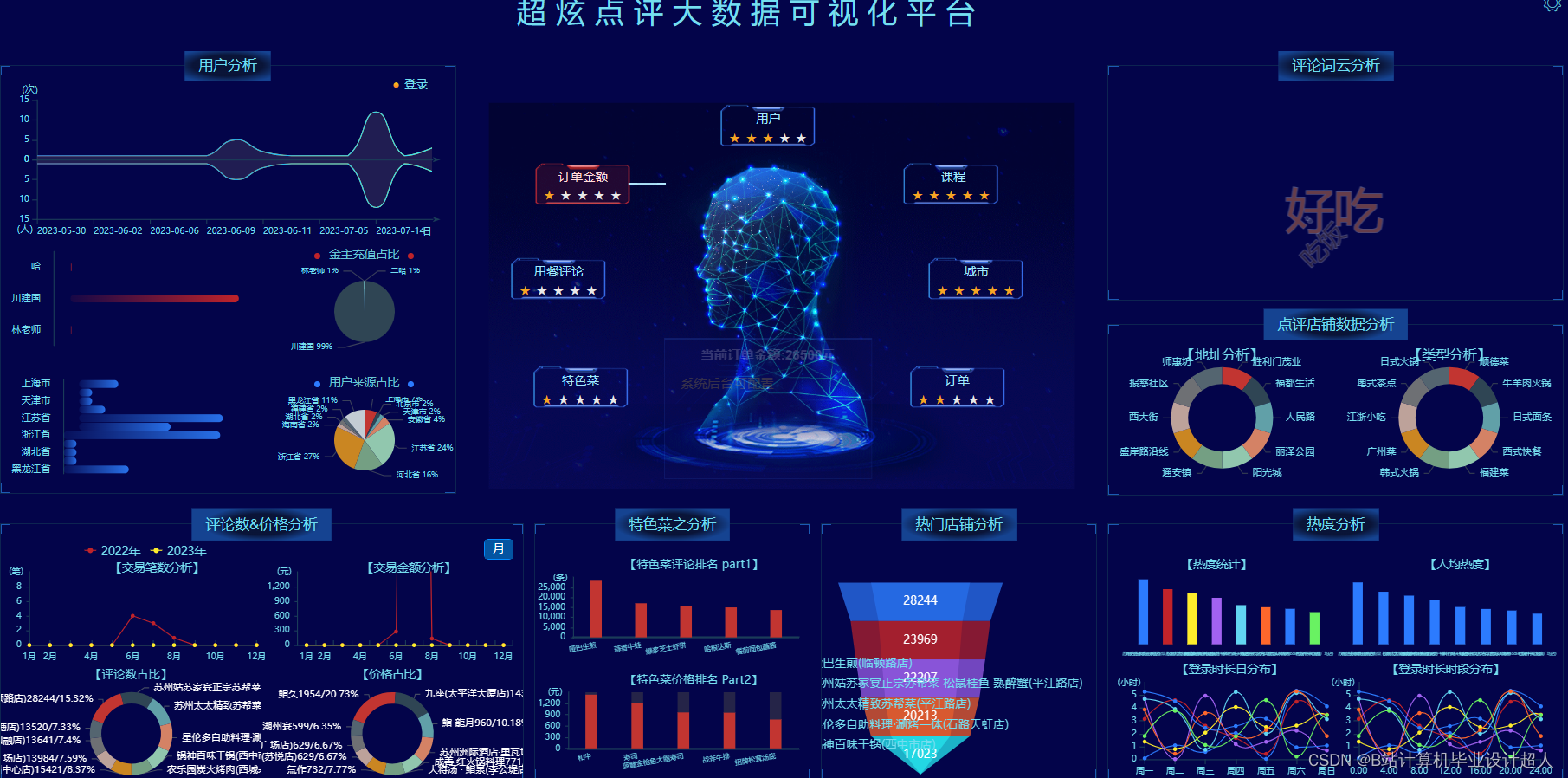
计算机毕业设计python+spark知识图谱美团美食推荐系统 美团餐厅推荐系统 美团推荐系统 美食价格预测 美团爬虫 美食数据分析 美食可视化大屏 大数据毕业设计 深度学习 知识图谱 人工智能_基于大数据的美团外卖数据分析系统
赞
踩
毕业设计(论文)
题 目: 基于大数据的美团数据分析与推荐系统
院 系:
专 业:
班 级:
学 号:
学生姓名:
指导教师:
年 月
郑州经贸学院
毕业论文开题报告
| 论文题目 | 基于大数据的美团数据分析与推荐系统 | ||||||
| 姓名 | 院系 | 专业班级 | 学号 | ||||
| 1.选题背景和意义 背景 伴随着外卖行业蓬勃发展,为了满足商家需要及时了解消费者的消费需求,以及消费者能够找到直观了解外卖商品的信息并且能更好更准确的为顾客服务,因此开发一个完善的美团数据分析与推荐系统十分必要。本课题的主要目的是开发美团数据分析与推荐系统,以满足广大消费者和商家的需要。 意义 本课题来源于生产实际,本系统基于美团外卖店铺自营的商业模式,并且在校期间有做过类似于基于Hadoop大数据平台下的用户喜好推荐分析而进行课题研究,美团数据分析与推荐系统解决的是消费者选择到自己合意的商品,同时扩大了外卖店铺的知名度和提高外卖销量,被更多的用户所选择,而不仅仅局限于以往的大海捞针。 | |||||||
| 2.本选题在国内外的研究状况及发展趋势(参考文献不少于10篇) 在大数据时代,数据已经成为企业竞争力的重要组成部分。美团作为一个交易平台,拥有海量的用户行为数据和丰富的业务场景,因此,如何利用这些数据来提高用户体验和业务效率,成为了美团面临的重要问题。同时,随着推荐系统的广泛应用,如何利用数据来优化推荐算法,提高推荐精度和用户满意度,也成为了业界研究的热点[1]。 在国内外研究现状方面,美团已经开展了一系列基于大数据的分析和推荐系统方面的研究和实践。例如,美团通过对用户历史行为数据进行分析,发现用户的口味偏好和消费习惯,从而为用户推荐更加符合其需求的商家和菜品[2]。此外,美团还利用机器学习和深度学习等技术,对用户行为数据进行建模和分析,从而优化推荐算法和提高推荐精度。 在国内方面,美团在大数据分析和推荐系统方面的研究和实践已经取得了一些成果。例如,美团通过引入多种数据源,包括用户行为数据、商家数据、菜品数据等,构建了一个多维度的推荐系统,从而提高了推荐精度和用户满意度[3]。此外,美团还通过引入实时数据处理技术,实现了对用户行为的实时监测和反馈,从而提高了用户体验和业务效率。 在国外方面,大数据分析和推荐系统已经成为了电商、在线视频、音乐平台等领域的重要应用。例如,亚马逊通过利用大数据分析用户的购物历史、浏览历史等信息,从而为用户推荐更加符合其需求的商品[4]。此外,Netflix通过利用大数据分析用户的观影历史、口味偏好等信息,从而为用户推荐更加符合其需求的电影和电视剧。这些应用的成功实践为美团开展基于大数据的分析和推荐系统方面的研究提供了有益的借鉴和参考[5]。 综上所述,基于大数据的美团数据分析与推荐系统方面的研究和实践已经取得了一定的成果。但是随着业务规模的不断扩大和数据量的不断增加,如何进一步提高推荐精度和用户满意度,仍需要不断探索和研究[6]。同时,随着技术的不断发展,如何将新技术应用到实际业务中,也是需要不断尝试和创新的重要方向。 附:参考文献 [1]王建芳,韩鹏飞,苗艳玲,司马海峰.一种基于用户兴趣联合相似度的协同过滤算[J].河南理工大学学报(自然科学版),2022,38(05):118-123. [2] 褚宏林.一种改进的协同过滤推荐算法及其并行算法研究[D].烟台大学,2021. [3] 张雨豪.基于协同过滤与启发式关联规则的混合推荐系统[D].南京邮电大学,2021. [4] 王佳斐,范伊红,宋永旗,王帅杰,付炳威.基于协同过滤算法的个性化影视推荐系统[J].电脑知识与技术,2022,18(23):12-13+18. [5] 葛林博.基于协同过滤的推荐算法研究与应用[D].西安电子科技大学,2021. [6] 何泽灵.基于协同过滤的推荐算法研究[D].重庆邮电大学,2022. [7] 薛亮,徐慧,冯尊磊,贾俊铖.一种改进的协同过滤的商品推荐方法[J].计算机技术与发展,2023,32(07):201-207. [8] 董立岩,修冠宇,马佳奇.基于权重调节和用户偏好的协同过滤算法[J].吉林大学学报(理学版),2022,58(03):599-604. [9]孙文心。社会化美食推荐系统研究与设计[D].大连:大连海事大学.2021(05):13—16 [10]王聪;刘启华;曹宇。融合情境的移动美食推荐系统研究[J].电脑知识与技术.2021(11):86-97 [11]王玉雯。中小餐饮企业智能服务系统设计与实现[D].成都:电子科技大学。2021(03):36-41 [12]周建亮.餐饮业智能点餐系统的设计与实现[D]。北京:北京邮电大学.2021(03):65—71 [13]陈婷婷.融合上下文和项目属性的美食商店信息推荐算法研究与实现[D]。北京:北京邮电大学。2023(03)11-17 [14] 张如云.基于大数据和搜索的关联推荐系统的设计与实现探析[J].办公自动化,2021,23(07):34-36. [15] 刘中林,郑凯东.基于大数据技术的购房推荐系统的设计与实现[J].信息与电脑(理论版),2022,34(07):190-193. [16] 朱本瑞.基于Spark的离线与实时的电影推荐系统设计与实现[D].南京信息工程大学,2022. [17] Zhao Junqing and Tie Pengfei. Design and Implementation of Energy-Saving Logistics Management System for Route Optimization[J].Wireless Communications and Mobile Computing, 2022. [18] Qi liang SUN. Design and Implementation of Personnel Management Information System Based on SSM[C].2023. | |||||||
前端内容(门户系统) ①美食智能搜索,提供各种搜索条件; ②查询我的订单; ③在线支付; ⑤美食评价; ⑥购物车; ⑦美食详情查看; ⑧个性化美团美食推荐 后端内容(后台管理系统) 用户管理 评论管理 订单管理 美食管理 知识图谱 商家管理 Hadoop+Spark大屏统计端内容 价格分析、交易分析、购买指数、菜系分析、热门菜品 爬虫端内容 数据爬取、数据清洗、数据集入库mysql | |||||||
| 4.基本设计(研究)思路及技术关键点 (1)基本设计(研究)思路 (一)Selenium自动化Python爬虫工具采集大众点评上的美团店铺数据、美食数据约10万条存入.csv文件作为数据集; (二)使用pandas+numpy或MapReduce对数据进行数据清洗,生成最终的.csv文件并上传到hdfs; (三)使用hive数仓技术建表建库,导入.csv数据集; (四)离线分析采用hive_sql完成,实时分析利用Spark之Scala完成; (五)统计指标使用sqoop导入mysql数据库; (六)使用Flask+echarts进行可视化大屏开发; (七)使用机器学习、深度学习的算法进行个性化美团美食推荐; (八)使用卷积神经网络KNN、CNN实现店铺流量预测; (九)搭建springboot+vue.js前后端分离web系统进行个性化推荐界面、店铺预测界面、知识图谱等实现; (2)技术关键点
| |||||||
| 5.预期成果 本课题旨在通过设计一种基于大数据技术的美食推荐系统帮助解决本地美食的推广与智能推荐问题。预期用户可以通过网站首页进行美食搜索、个性化美食推荐、支付宝下单、美食点评等功能。管理员能够登录后台管理系统进行美食管理、美食知识图谱查看、评价管理等数据维护。Python爬虫可以采集美团约1W条本地美食数据。用户可以直观观看可视化统计大屏。 | |||||||
| 6.指导教师意见及建议 签字: 年 月 日 | |||||||
附页
关于“XXXXXX设计(论文)题目”的文献综述
要求:
一级标题(宋体,四号,加粗,左对齐,行距 1.5 倍,段前、段 后 0.5 行)
二级标题(宋体,小四号,加粗,左对齐,行距 1.5 倍,段前、段后 0.5 行)
正文(要求 3000 字以上)(宋体,小四号,首行缩进 2 字符,行距 1.5 倍,段前段后 0 行。其中英文、数字应为新罗马字体








核心算法代码分享如下:
- import ast
- import collections
- import datetime
- import findspark
- findspark.init()
- import math
- import numpy as np
- import pandas as pd
- from pyspark import Row, SparkContext, SparkConf
- from pyspark.sql import SQLContext
- from pyspark.sql.functions import col
-
- # 该文件为系统的电影推荐的spark离线处理脚本
- # 可放置linux下单独运行,只需在liunx下安装python3同时安装相应的库即可运行
- # 当然也可放置在windows下运行,但环境配置较复杂容易出错,不建议
- # 内部需要改动mysql数据库配置信息(33行、34行、36行)、spark信息(24行)、hadoop信息(39行)
- # 注:该脚本做了数据量的限制,于 221行 可以取消数据量的限制
- # 执行完成后会将数据更新到表“user_usermovierecommend”,同时在hadoop中路径movie_system会生成计算的相关相似度文件
- # 算法参考 recommenderSystemBasedOnSpark 项目:
-
-
- class Calculator:
- def __init__(self):
- self.localClusterURL = "local[2]"
- self.clusterMasterURL = "spark://master:7077"
- self.conf = SparkConf().setAppName('Movie_System').setMaster(self.clusterMasterURL)
- self.sc = SparkContext.getOrCreate(self.conf)
- self.sqlContext = SQLContext(self.sc)
- # spark 初始化
- # self.sqlContext = SparkSession.Builder().appName('sql').master('spark://Spark:7077').getOrCreate()
-
- # mysql 配置
- self.prop = {'user': '127_0_0_1',
- 'password': 'RjHysK3TfjSdGwmJ',
- 'driver': 'com.mysql.cj.jdbc.Driver'}
- self.jdbcURL = "jdbc:mysql://172.19.107.58:3306/127_0_0_1" \
- "?useUnicode=true&characterEncoding=utf-8&useSSL=false"
-
- # user\rating\links\tags在hdfs中的位置 ===> 即推荐原料在hdfs中的存档路径
- self.hdfs_data_path = 'hdfs://master:9000/movie_system/'
-
- self.date_time = datetime.datetime.now().strftime("%Y-%m-%d")
-
- def __del__(self):
- # 关闭spark会话
- self.sc.stop()
- del self.sc
-
- def select(self, sql):
- # 读取表
- data = self.sqlContext.read.jdbc(url=self.jdbcURL, table=sql, properties=self.prop)
- return data
- # # 离线计算时从mysql加载movies数据到hive中
- # movies_sql = self.sqlContext.read.format('jdbc') \
- # .options(url=self.jdbcURL,
- # driver=self.prop['dirver'],
- # dbtable=self.movieTab,
- # user=self.prop['user'],
- # password=self.prop['password']).load()
-
- def get_data(self, path):
- data = self.sqlContext.read.parquet(path)
- return data
-
- # def show(self):
- # sql = '(select user_id,tag_type,tag_weight,tag_name from user_usertag) aaa'
- # data = self.select(sql)
- # # 打印data数据类型 <class 'pyspark.sql.dataframe.DataFrame'>
- # # print(type(data))
- # # 展示数据
- # data.show()
-
- def write(self, data, path):
- data.write.csv(path + "_csv", header=True, sep=",", mode='overwrite')
- data.write.parquet(path, mode='overwrite')
-
- def change_sql_data_to_hdfs(self, sql, path):
- data = self.select(sql)
- self.write(data, path)
-
- # 根据电影类型、语言、国家、年份计算相似度
- def calculator_movie_type(self, read_path, write_path):
- dfMovies = self.get_data(read_path)
- dfMovies.show()
- """计算两个rdd的笛卡尔积"""
- rddMovieCartesianed = dfMovies.rdd.cartesian(dfMovies.rdd)
- rddMovieIdAndGenre = rddMovieCartesianed.map(lambda line: Row(movie1=line[0]['movie_id'],
- movie2=line[1]['movie_id'],
- sim=countSimBetweenTwoMovie(line[0], line[1])))
- dfFinal = self.sqlContext.createDataFrame(rddMovieIdAndGenre)
- dfFinal.show()
- self.write(dfFinal, write_path)
-
- # 根据用户喜好、兴趣、年龄、城市计算相似度
- def calculator_user_base(self, read_path, write_path):
- dfUsers = self.get_data(read_path)
- dfUsers.show()
- """计算两个rdd的笛卡尔积"""
- rddUserCartesianed = dfUsers.rdd.cartesian(dfUsers.rdd)
- rddUserIdAndGenre = rddUserCartesianed.map(lambda line: Row(user1=line[0]['user_id'],
- user2=line[1]['user_id'],
- sim=countSimBetweenTwoUser(line[0], line[1])))
- dfFinal = self.sqlContext.createDataFrame(rddUserIdAndGenre)
- dfFinal.show()
- self.write(dfFinal, write_path)
-
- # 根据用户的标签进行计算相似度
- def calculator_user_tag(self, read_path, write_path):
- dfUsers = self.get_data(read_path)
- # dfUsers.show()
- # print(change_user_tag_data(dfUsers.toPandas()))
- dfUsers = self.sqlContext.createDataFrame(change_user_tag_data(dfUsers.toPandas()))
- # dfUsers.show()
- # """计算两个rdd的笛卡尔积"""
- rddUserCartesianed = dfUsers.rdd.cartesian(dfUsers.rdd)
- rddUserIdAndGenre = rddUserCartesianed.map(lambda line: Row(user1=line[0]['user_id'],
- user2=line[1]['user_id'],
- sim=countSimBetweenTwoUserByTag(line[0], line[1])))
- dfFinal = self.sqlContext.createDataFrame(rddUserIdAndGenre)
- # dfFinal.show()
- self.write(dfFinal, write_path)
-
- @staticmethod
- def change_dataframe_to_li(data_frame, li_name):
- data_frame = data_frame.toPandas()
- data_li = np.array(data_frame[li_name])
- data_li = data_li.tolist()
- return data_li
-
- # 查找相似的电影
- def select_movie_to_movie(self, df_sim_movie, movie_id):
- min_sim = 0.5
- max_num = 300
- df_sim_movie = df_sim_movie.orderBy('sim', ascending=0)\
- .where(
- (col('movie1') == movie_id) &
- (col('sim').__ge__(min_sim)) &
- (col('movie1') != col('movie2')))\
- .limit(max_num).select('movie2')
- df_sim_movie_li = self.change_dataframe_to_li(df_sim_movie, "movie2")
- return df_sim_movie_li
-
- # 查找相似的用户
- def select_user_to_user(self, df_sim_user, user_id):
- min_sim = 0.5
- max_num = 300
- df_sim_user = df_sim_user.orderBy('sim', ascending=0)\
- .where(
- (col('user1') == user_id) &
- (col('sim').__ge__(min_sim)) &
- (col('user1') != col('user2')))\
- .limit(max_num).select('user2')
- df_sim_user_li = self.change_dataframe_to_li(df_sim_user, "user2")
- return df_sim_user_li
-
- # 查询用户收藏、评论、评分良好的电影
- def select_user_movie(self, df_users, user_id):
- min_score = 3
- max_num = 300
- df_movies = df_users.orderBy('tag_weight', ascending=0) \
- .where((
- (col('tag_type') == 'like_movie_id') |
- (col('tag_type') == 'rating_movie_id') |
- (col('tag_type') == 'comment_movie_id')
- # (col('tag_type') == 'rating_movie_id')
- ) & (col('tag_weight').__ge__(min_score)) & (col('user_id').__eq__(user_id))) \
- .limit(max_num).select('tag_name').distinct()
- movie_li = self.change_dataframe_to_li(df_movies, "tag_name")
- # movie_li = np.array(df_movies.toPandas()["tag_name"])
- # movie_li = movie_li.tolist()
- return movie_li
-
- def calculator_user_movie_recommend(self, user_path, tag_path, movie_sim_path, user_sim_path, calculator_type):
- finial_rs = list()
- # 取出用户信息user_id数据
- df_users = self.get_data(user_path).select('user_id')
- df_users.show()
- # 读取用户标签信息
- df_tag_users = self.get_data(tag_path)
- df_tag_users.show()
- # 读取电影相似度数据
- df_movie_sim = self.get_data(movie_sim_path)
- df_movie_sim.show()
- # 读取用户相似度数据
- df_user_sim = self.get_data(user_sim_path)
- df_user_sim.show()
-
- user_id_li = self.change_dataframe_to_li(df_users, "user_id")
-
- if calculator_type == "movie": # 根据电影查找电影
- for id, user_id in enumerate(list(user_id_li)):
- user_movie_li = self.select_user_movie(df_tag_users, user_id)
- user_movie_li_rs = list()
- for user_movie_id in list(user_movie_li):
- select_movie_to_movie_li = list(self.select_movie_to_movie(df_movie_sim, user_movie_id))
- user_movie_li_rs = list(set(select_movie_to_movie_li + user_movie_li_rs)) # 合并List
- user_movie_li_rs = ",".join(map(str, user_movie_li_rs)) # 转成字符串
- finial_rs.append([id, user_id, user_movie_li_rs, datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')])
- elif calculator_type == "user": # 根据用户查找电影
- for id, user_id in enumerate(list(user_id_li)):
- user_id_li_rs = self.select_user_to_user(df_user_sim, user_id)
- user_movie_li_rs = list()
- for user_id_rs in list(user_id_li_rs):
- select_user_to_movie_li = list(self.select_user_movie(df_tag_users, user_id_rs))
- user_movie_li_rs = list(set(select_user_to_movie_li + user_movie_li_rs)) # 合并List
- user_movie_li_rs = ",".join(map(str, user_movie_li_rs)) # 转成字符串
- finial_rs.append([id, user_id, user_movie_li_rs, datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')])
-
- # print(finial_rs)
- # 将数据转换
- recommend = self.sqlContext.createDataFrame(finial_rs, ["id", "user_id", "movie_id_li", "create_time"])
- # 写入数据库
- recommend.write.jdbc(url=self.jdbcURL, table='user_usermovierecommend', mode='overwrite', properties=self.prop)
-
- # 将数据从数据库中取出,并以parquet文件格式写入到HDFS里
- def step_1(self):
- sql1 = '(select user_id,tag_type,tag_weight,tag_name from user_usertag) user_tag_base'
- path1 = self.hdfs_data_path + 'user_tag_base_'+self.date_time
- self.change_sql_data_to_hdfs(sql1, path1)
- # 测试时限制数量防止计算量过大
- sql2 = '(SELECT `movie_id`,`title`,`rating`,`genres`,`countries`,`languages`,`year` FROM ' \
- 'movie_collectmoviedb limit 0,1000) movie_base'
- path2 = self.hdfs_data_path + 'movie_base_'+self.date_time
- self.change_sql_data_to_hdfs(sql2, path2)
- # 用户信息
- sql3 = '(select d.id user_id, b.user_gender gender, d.user_age age, d.user_prefer prefers, ' \
- 'd.user_hobbies hobbies, d.user_province province, d.user_city city, d.user_district district ' \
- 'from user_usersbase b join user_usersdetail d on b.id = d.user_id_id where b.user_status = 1) user_base'
- path3 = self.hdfs_data_path + 'user_base_'+self.date_time
- self.change_sql_data_to_hdfs(sql3, path3)
-
- # 读取parquet文件,然后计算相似度
- def step_2(self):
- read_path1 = self.hdfs_data_path + 'user_tag_base_'+self.date_time
- write_path1 = self.hdfs_data_path + 'user_tag_simContent_' + self.date_time
- read_path2 = self.hdfs_data_path + 'movie_base_' + self.date_time
- write_path2 = self.hdfs_data_path + 'movie_simContent_' + self.date_time
- read_path3 = self.hdfs_data_path + 'user_base_'+self.date_time
- write_path3 = self.hdfs_data_path + 'user_simContent_' + self.date_time
- self.calculator_movie_type(read_path2, write_path2)
- self.calculator_user_base(read_path3, write_path3)
- self.calculator_user_tag(read_path1, write_path1)
-
- # 读取parquet相似度数据,然后生成推荐内容,存储到mysql和HDFS
- def step_3(self):
- user_base_path = self.hdfs_data_path + 'user_base_'+self.date_time
- user_tag_base_path = self.hdfs_data_path + 'user_tag_base_'+self.date_time
- movie_sim_path = self.hdfs_data_path + 'movie_simContent_' + self.date_time
- user_sim_path = self.hdfs_data_path + 'user_tag_simContent_'+self.date_time
-
- # 根据相似用户进行推荐
- # self.calculator_user_movie_recommend(user_base_path, user_tag_base_path,
- # movie_sim_path, user_sim_path, "user")
-
- # 根据相似电影进行推荐
- self.calculator_user_movie_recommend(user_base_path, user_tag_base_path,
- movie_sim_path, user_sim_path, "movie")
-
-
- def countIntersectionForTwoSets(list1, list2):
- """计算两个集合的交集的模"""
- count = 0
- for i in range(len(list1)):
- m = list1[i]
- for j in range(len(list2)):
- if list2[j] == m:
- count = count + 1
- break
- return count
-
-
- def countSimBetweenTwoList(list1, list2):
- s1 = len(list1)
- s2 = len(list2)
- m = math.sqrt(s1 * s2)
- if m == 0:
- if s1 == 0 and s2 == 0:
- return 1
- else:
- return 0
- return countIntersectionForTwoSets(list1, list2) / m
-
-
- def countSimBetweenTwoMovie(list1, list2):
- """计算两个Movie的相似度"""
- movie_type_list1 = ast.literal_eval(list1['genres'])
- movie_type_list2 = ast.literal_eval(list2['genres'])
- movie_country_list1 = ast.literal_eval(list1['countries'])
- movie_country_list2 = ast.literal_eval(list2['countries'])
- movie_language_list1 = ast.literal_eval(list1['languages'])
- movie_language_list2 = ast.literal_eval(list2['languages'])
- movie_year1 = list1['year']
- movie_year2 = list2['year']
- movie_year = 1 if movie_year1 == movie_year2 else 0
- movie_type = countSimBetweenTwoList(movie_type_list1, movie_type_list2)
- movie_country = countSimBetweenTwoList(movie_country_list1, movie_country_list2)
- movie_language = countSimBetweenTwoList(movie_language_list1, movie_language_list2)
- sim = (movie_type * 5 + movie_country * 2 + movie_language * 2 + movie_year * 1) / 10
- return sim
-
-
- def countSimBetweenTwoUser(list1, list2):
- """计算两个User的相似度"""
- user_prefer_list1 = list1['prefers'].split(",") if list1['prefers'] != '' and list1['prefers'] is not None else []
- user_prefer_list2 = list2['prefers'].split(",") if list2['prefers'] != '' and list2['prefers'] is not None else []
- user_hobbie_list1 = list1['hobbies'].split(",") if list1['hobbies'] != '' and list1['hobbies'] is not None else []
- user_hobbie_list2 = list2['hobbies'].split(",") if list2['hobbies'] != '' and list2['hobbies'] is not None else []
- user_gender = 1 if list1['gender'] == list2['gender'] else 0
- user_province = 1 if list1['province'] == list2['province'] else 0
- user_city = 1 if list1['city'] == list2['city'] else 0
- user_district = 1 if list1['district'] == list2['district'] else 0
- user_prefer = countSimBetweenTwoList(user_prefer_list1, user_prefer_list2)
- user_hobbie = countSimBetweenTwoList(user_hobbie_list1, user_hobbie_list2)
- sim = (user_prefer * 5 + user_hobbie * 2 + user_gender * 1 + user_province * 1 +
- user_city * 0.5 + user_district * 0.5) / 10
- return sim
-
-
- def countSimBetweenTwoDict(info_movie_tag1_dict, info_movie_tag2_dict):
- if not info_movie_tag1_dict and not info_movie_tag2_dict or info_movie_tag1_dict == info_movie_tag2_dict:
- return 1
- key_li1 = list(info_movie_tag1_dict.keys())
- key_li2 = list(info_movie_tag2_dict.keys())
- content_sim = countSimBetweenTwoList(key_li1, key_li2)
- key_score = 0
- if key_li1 and key_li2 and key_li1[0] == key_li2[0]:
- key_score += 5
- if len(key_li1) >= 2 and len(key_li2) >= 2 and key_li1[1] == key_li2[1]:
- key_score += 3
- if len(key_li1) >= 3 and len(key_li2) >= 3 and key_li1[2] == key_li2[2]:
- key_score += 2
- key_score = (content_sim + key_score / 10) / 2
- return key_score
-
-
- def countSimBetweenTwoUserByTag(list1, list2):
- """计算两个User的相似度"""
- # info_age、info_city、info_phone_city、info_province、info_sex
- # info_movie_tag、info_movie_type
- # List:like_movie_id、info_hobbies、rating_movie_id
-
- user_tag_list1 = ast.literal_eval(list1['user_data'])
- user_tag_list2 = ast.literal_eval(list2['user_data'])
- info_age1 = user_tag_list1.get("user_info").get("info_age")
- info_city1 = user_tag_list1.get("user_info").get("info_city")
- info_phone_city1 = user_tag_list1.get("user_info").get("info_phone_city")
- info_province1 = user_tag_list1.get("user_info").get("info_province")
- info_sex1 = user_tag_list1.get("user_info").get("info_sex")
- info_movie_tag1_dict = user_tag_list1.get("info_movie_tag")
- info_movie_type1_dict = user_tag_list1.get("info_movie_type")
- like_movie_id1_li = user_tag_list1.get("like_movie_id")
- info_hobbies1_li = user_tag_list1.get("info_hobbies")
- rating_movie_id1_li = user_tag_list1.get("rating_movie_id")
-
- info_age2 = user_tag_list2.get("user_info").get("info_age")
- info_city2 = user_tag_list2.get("user_info").get("info_city")
- info_phone_city2 = user_tag_list2.get("user_info").get("info_phone_city")
- info_province2 = user_tag_list2.get("user_info").get("info_province")
- info_sex2 = user_tag_list2.get("user_info").get("info_sex")
- info_movie_tag2_dict = user_tag_list2.get("info_movie_tag")
- info_movie_type2_dict = user_tag_list2.get("info_movie_type")
- like_movie_id2_li = user_tag_list2.get("like_movie_id")
- info_hobbies2_li = user_tag_list2.get("info_hobbies")
- rating_movie_id2_li = user_tag_list2.get("rating_movie_id")
-
- if (info_age1 and info_age2 and int(info_age1) in range(int(info_age2)-3, int(info_age2)+3)) or \
- (not info_age1 and not info_age2):
- info_age = 1
- else:
- info_age = 0
-
- info_city = is_exist_and_equal(info_city1, info_city2)
- info_sex = is_exist_and_equal(info_sex1, info_sex2)
- info_phone_city = is_exist_and_equal(info_phone_city1, info_phone_city2)
- info_province = is_exist_and_equal(info_province1, info_province2)
- like_movie_id_li = is_exist_and_equal_li(like_movie_id1_li, like_movie_id2_li)
- info_hobbies_li = is_exist_and_equal_li(info_hobbies1_li, info_hobbies2_li)
- rating_movie_id_li = is_exist_and_equal_li(rating_movie_id1_li, rating_movie_id2_li)
- if (info_movie_tag1_dict and info_movie_tag2_dict) or (not info_movie_tag1_dict and not info_movie_tag2_dict):
- info_movie_tag_dict = countSimBetweenTwoDict(info_movie_tag1_dict, info_movie_tag2_dict)
- else:
- info_movie_tag_dict = 0
- if (info_movie_type1_dict and info_movie_type2_dict) or (not info_movie_type1_dict and not info_movie_type2_dict):
- info_movie_type_dict = countSimBetweenTwoDict(info_movie_type1_dict, info_movie_type2_dict)
- else:
- info_movie_type_dict = 0
- sim = (info_movie_tag_dict * 2 + info_movie_type_dict * 2 + like_movie_id_li * 1 + info_hobbies_li * 1 +
- rating_movie_id_li * 1 + info_age * 1 + info_city * 0.5 + info_sex * 0.5 + info_phone_city * 0.5 +
- info_province * 0.5) / 10
- return sim
-
-
- def is_exist_and_equal_li(str1, str2):
- if not str1 and not str2:
- return 1
- if str1 and str2:
- return countSimBetweenTwoList(str1, str2)
- else:
- return 0
-
-
- def is_exist_and_equal(str1, str2):
- # if (str1 and str2 and str2 == str1) or (not str1 and not str2):
- if str2 == str1:
- return 1
- else:
- return 0
-
-
- # 将用户的数据进行格式化
- def change_user_tag_data(data):
- list_tag = ["like_movie_id", "info_hobbies", "rating_movie_id"]
- dict_tag = ["info_movie_tag", "info_movie_type"]
- all_user_data_rs = list()
- for user_data in data.groupby(["user_id"]):
- user_data_rs = dict()
- user_id = user_data[0]
- user_data_rs["user_id"] = user_id
- user_tag_rs = dict()
- user_info_dict = dict()
- for user_tag_data in pd.DataFrame(user_data[1]).drop("user_id", axis=1).groupby(["tag_type"]):
- if user_tag_data[0] in dict_tag:
- # print(user_data[1])
- info_movie_tag = pd.DataFrame(user_tag_data[1]).drop(["tag_type"], axis=1).sort_values("tag_weight",
- ascending=False)
- info_movie_tag = collections.OrderedDict(zip(info_movie_tag["tag_name"], info_movie_tag["tag_weight"]))
- user_tag_rs[user_tag_data[0]] = dict(info_movie_tag)
- # print(dict(info_movie_tag))
- elif user_tag_data[0] in list_tag:
- # print(user_data[1])
- like_movie_id = pd.DataFrame(user_tag_data[1]).drop(["tag_type"], axis=1).sort_values("tag_weight",
- ascending=False)
- like_movie_id = list(like_movie_id["tag_name"])
- user_tag_rs[user_tag_data[0]] = like_movie_id
- # print(like_movie_id)
- else:
- user_info = pd.DataFrame(user_tag_data[1]).drop(["tag_weight"], axis=1)
- user_info_dict[user_info["tag_type"].values[0]] = user_info["tag_name"].values[0]
- user_tag_rs["user_info"] = user_info_dict
- user_data_rs["user_data"] = str(user_tag_rs)
- all_user_data_rs.append(user_data_rs)
- # print(all_user_data_rs)
- # return all_user_data_rs
- return pd.DataFrame(all_user_data_rs)
-
-
- # 将数据从数据库中取出,并以parquet文件格式写入到HDFS里
- calculator = Calculator()
- try:
- # 从HDFS中读取出
- calculator.step_1()
- calculator.step_2()
- calculator.step_3()
- except Exception as ex:
- print(ex)
- # 终止程序
- calculator.sc.stop()
- calculator.sc.stop()
-


