
- 1kube-bench初体验
- 2python头歌-python第六章作业_头歌python第六章作业答案
- 3嵌入式开发-各种干货_dsk嵌入视频
- 4Python 中filter函数用法
- 5etcd 与 Zookeeper、Consul 等其它 kv 组件的对比
- 6Java面向对象:封装、继承、多态_java面向对象 - 封装、继承和多态头歌
- 7androidsdktools安装_Android-sdk 安装
- 8使用javaAPI对HDFS进行文件上传,下载,新建文件及文件夹删除,遍历所有文件_hadoop 遍历hdfs指定文件夹
- 9spark 类别特征_Spark 贝叶斯分类算法
- 10聚焦AI4S,产学研专家齐聚,探讨AI工具在多领域应用的现状与趋势
用于讲话者视听追踪,基于自监督学习的多模态感知注意力网络——论文阅读
赞
踩
本文是在阅读原论文的过程中的一些学习笔记和自我理解,若有不当,敬请勘误。
1.摘要
概念解释
端到端模型:输入和输出之间没有中间步骤或阶段。端到端模型直接从原始输入数据映射到最终输出结果,没有人为设计的特征提取,中间表示或者预处理步骤。
异构信号:在某一信号环境中具有不同特性和属性的信号,这些信号可以是不同来源、不同类型,不同模态的信号,它们具有不同的物理特性,频谱特性,时域特性等。在图像处理或音频处理中,可能需要处理来自不同来源或不同类型的信号,例如同时处理彩色图像的RGB通道,或者处理来自不同麦克风的音频信号。
多模态信息互补性:多模态研究是指研究不同类型的数据融合的问题。模型从多种信息源获取多种模态的数据(例如语音,文字,图片等)之间的互相补充和增强关系,从而提高整体信息的丰富程度,准确性,鲁棒性。
时空全局相关域:是一种用于分析时间序列数据的空间-时间全局相干场。用于描述数据中的空间和时间相关性的方法,常用于cv等领域。可理解为对时间序列数据进行空间域和时间域的联合分析,获得数据的时序结构以及时序变化规律。通过计算坐标系中各点的空间相干性和时间相干性,获得全局的时空相干性。在本文中涉及到对视频的分析,使用stGCF推测主要目的是通过分析不同时间点和空间位置上的像素关系,提取位置信息,实现对声源位置的分析和估计。
总结
作者团队提出了一个用于讲话者的视听追踪,基于自监督学习的多模态感知注意力网络。它基于时空全局相关域(stGCF),采用相机模型将声学线索映射到与视觉线索一致的定位空间。接着使用了一个多模态感知注意力网络来推算出感知衡量,感知权重适用于衡量受到噪声干扰的间歇性和视频流的可靠性和有效性。通过利用多模态信息的互补性和一致性,作者团队还提出了一种独特的跨模态自监督学习机制来对声音和视觉观察的置信度进行建模。上述的多模态感知追踪模型在不利条件下实现了追踪的鲁棒性,且优于最先进的前沿算法。
介绍
概念解释
似然函数:似然函数表示在已知观测数据的情况下, 一个概率分布模型函数的参数取值可能性。
似然计算:计算给定参数值下观测数据的可能性,也就是计算似然函数值。
概率生成模型:是一种机器学习模型,用于对数据生成的概率分布进行建模。它们被设计用于描述观测数据与潜在变量之间的关系,常用于生成新的数据样本,或者用于推断潜在变量的值。
高斯系统:以高斯分布(正态分布)为基础的系统或模型。高斯分布是统计学中一种常见的概率分布。在信号处理领域,许多信号和噪声的分布都可以近似为高斯分布,因此高斯系统常用于信号滤波、降噪和特征提取等任务。
粒子:粒子滤波中使用的一组随机样本,系统的状态被表示为一组粒子,每个粒子代表了系统可能的状态。
生成算法:一类用于生成复合某种规则或者约束条件的数据、图像、文本或其他类型的信息。这些算法通常是基于概率模型或规则系统设计,旨在模拟或生成复合特定分布或结构的数据。
多模态的冗余性:不同模态的数据可能包含相似的信息,即冗余信息。虽然冗余信息可能会增加计算成本,但也可以提高系统的鲁棒性。当一个模态的数据不完整或不可靠时,其他模态的信息可以弥补其不足,从而提高整个系统的性能。
总结
声源识别问题是智能系统进行行为分析和人际交互的基础任务。通过对人对声源的多模态感知可知,视听线索的整合更有利于从其中获得补充性线索。与单模态相比,视听信号的互补性对提高追踪准确性和鲁棒性是有贡献的,特别是当处理目标遮挡,摄像机视觉受限,光照变化以及房间混响等复杂情景。除此之外多模态融合相较于单模态线索缺失或两种模态都无法单独提供可靠观测时,多模态融合显示出明显的优势。所以提出一种可以融合异构信号并且可以处理间歇性噪声试听数据的多模态追踪方法是至关重要的。
现如今主要的追踪方法就是概率生成模型,因为它们处理多模态信息的能力。最具代表性的方法是粒子滤波(PF)。无论是传统的粒子滤波方法还是其变形,都倾向于使用单一模态的检测结果来辅助其他模态以获得更准确的观测值,忽略了充分利用视听结合的互补性和冗余性。目前存在的视听追踪算法都适用生成模型,但是其很难适应目标外表的随机性,复杂性变化。基于色彩直方图和欧式距离的似然计算容易受到观测噪声干扰,限制了信息融合的似然性能。
作者团队使用注意力机制来测量多模态的置信度,该置信度决定了融合算法的有效性。引入注意力机制不仅整合了数据,而且通过估计多种信号来源的可靠性并基于可靠性对各个信息员获取的证据进行加权(较可靠的信息源提供的证据通常会被赋予更高的权重)。
本篇文章主要有三个突出贡献:
-
提出一种具有创新性的跟踪体系——多模态感知跟踪器,以及一种用来估计多模态数据观测结果的置信度和实用性。
-
一个创新性的声学图,stGCF,通过相机模型在升学和视觉定位之间建立起关系映射。由于多模态数据的互补性和一致性,提出了一种新的跨模态自监督学习机制。
-
在基本数据集和遮挡数据集上取得了优异的结果证明了该方法的鲁棒性和优异性。
提出方法
MPT的总体框架组成为:视听测量,多模态感知注意网络,跨模态自监督学习和基于PF的多模式跟踪器。
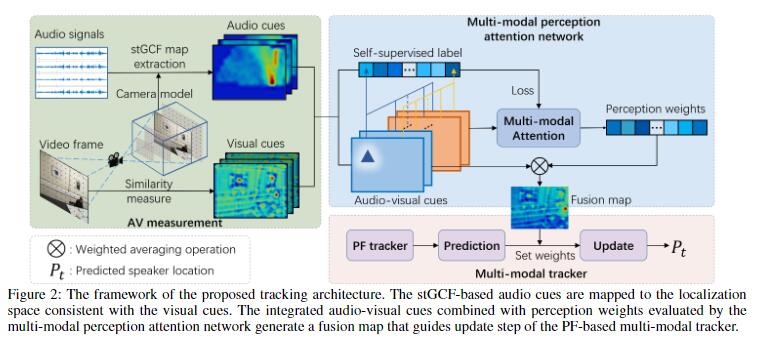
视听测量
听觉测量
通过视听测量可以从视觉帧和听觉信号中获得相应的线索。将听觉线索映射到与视觉线索相同的定位空间,以在相同的空间集成多模态线索。
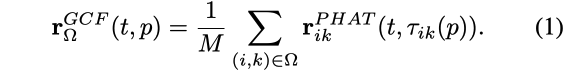
-
是麦克风对(i,k)的GCC-PHAT结果,它显示了一个突出的峰值,\tau代表了实际的TDOA
-
指的是从既定点p到麦克风对(i,k)的理论时延。
-
对于一个由M个麦克风对组成的集合
,GCF值被定义为属于
给定一个带有潜在声源位置的空间网格,GCF值代表了在每一点存在声源的可能性。
构建空间网格:
-
利用针孔相机模型将2D图片平面上的点映射到3D世界坐标系中一系列不同深度的3D点,这里的深度指的是从3D点到相机光学中心的不同垂直距离。
假设具有d个深度的集合D={Dk, k=1,...,d},给定一个深度Dk,图片到3D投影过程公式化为:
-
-
代表投影运算符,i和j是点的垂直坐标和水平坐标。P2d被投影到不同深度的多重平面上,
-
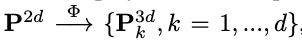
-
P3dk是深度为Dk的平面。
从P3dk导出的GCF功率图是
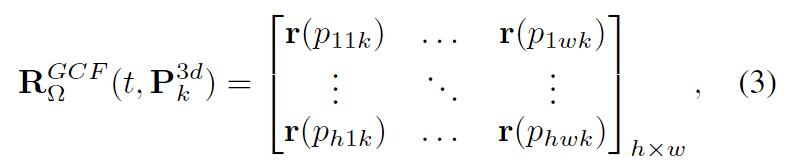
r(p..k)是的简写。假设GCF功率图的峰值在第k_{max}个深度上,那么时刻t时的空间GCF图可以表示为:
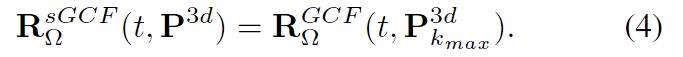
在时间段[t-m1, t]内,从共计m1+1帧中寻找带有最大sGCF峰值的帧集合m2。在时刻t的stGCF被定义为:
其中T代表帧集合m2对应的时间集。
视觉测量
在视觉测量阶段,为了更好的对搜索空间和已知目标进行相似度分析,引入了深度度量学习(是一种基于距离度量,通过将原始数据转换到含有距离信息的新空间,通过增加不同对象之间的距离,减少相同对象之间距离,建立对象之间相似性的方法)。在此模块中,作者还引入了一个预训练的孪生神经网络,该模块使用互相关作为卷积操作完成以后的度量函数。输出的相应图含有视觉线索,可以表示为:
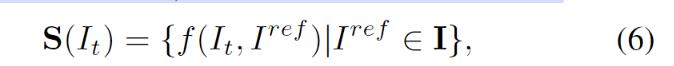
代表当前视频帧;
是参考帧,是在第一帧中用户定义的追踪对象;I是不同尺度的参考帧的集合。f(·)指的是用于输出代表性分数图的度量函数。
反映了追踪对象出现在每张图像的任意位置上的置信度。
多模态感知注意力网络
多模态感知注意力网络通过给定的音频和视频线索,生成一个置信度分数图来表示说话者的位置。人脑的注意力机制可以让人从丰富信息中获得更关键的特定信息。在该模块中,作者也使用了人脑的这种机制。
为了整合视觉和音频线索,将stGCF图和视觉响应图都归一化并且重塑为3D矩阵形式。
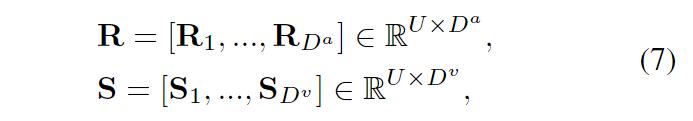
U代表了每个视频输入帧U = H * W。D^a是声学线索的维度,它取决于集合m2,指代的是时序线索。是
的数量。整合的视听线索,
,都输入到一个基础网络中进行处理。该网络借鉴了通道注意模块的架构,通道对应了从视觉或者听觉模态中提取的观察结果。通道数共计
个,注意力机制
生成了一个正分数
去测量在第i个通道上观察结果的置信度:
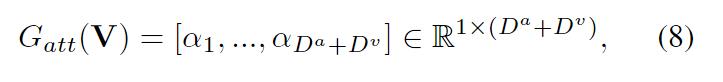
被称为感知权重,反映了通过之前获得的整合多模态线索的置信度。
在可信赖的观察结果上表现更高,在模糊不清的观察结果(如背景噪音,房间混响,视觉遮挡,)上表现低水平。这都得益于神经网络从观察图谱中学习到的统计特征。通过这点,神经网络展示出了多模态观察的感知能力,为上述模型提供了可解释性。
跨模态自监督学习
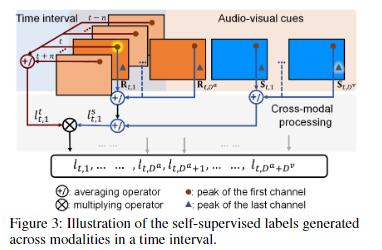
由于网络获得感知力是一个抽象的过程,所以这使得难以对数据进行人为标记。作者提出了一种自监督学习策略去训练网络。自监督包括时间因素和空间因素,考虑了运动目标的时间连续性,以及多模态数据中的位置一致性。对于第i个通道,假设点是在时间t的特征图峰值位置,其对应的在通道i上的空间因子是跨模态平均算子。跨模态空间因素被定义为:
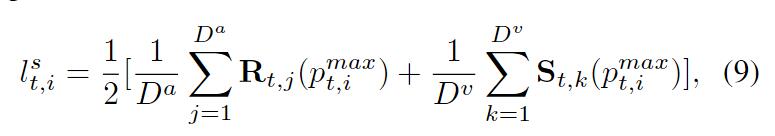
指的是在点p的归一化视觉响应,
是在点p的归一化sGCF值,j代表深度索引。
时间因子是通过对以时刻t为中心的时间间隔执行平均操作来导出的,时间因素和自监督标签可以表示为:
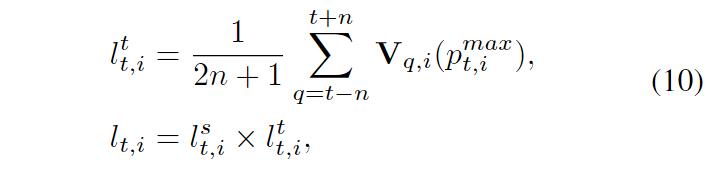
V指代的是视觉图或声学图,自监督标签集成了一个时间间隔内不同模式的估计结果。当目标在一个观察上发生偏移时,由于模态数据之间的互补性和目标移动的连续性,另一个提供更准确观察的通道提供的值会更低,偏移导致了数据干扰,当一个通道上的值越小时,它产生的偏移和影响就越小,所以就会更加准确。除此之外,当所有观察的峰值都集中在一个区域时,这表明不同观察之间存在一致性和一致的目标位置。这种一致性可以被视为对目标位置的更高置信度,因此值会相应增加,以反映观察的一致性。
多模态追踪
注意力网络通过在PF算法上替身从而获得了多模态追踪能力。网络输出的注意力被用于对视听线索V进行加权,相较于传统的加性似然和乘性似然相比,基于注意力机制的加权方法更接近人的感官选择。通过平均加权获得的融合图可以表示为:
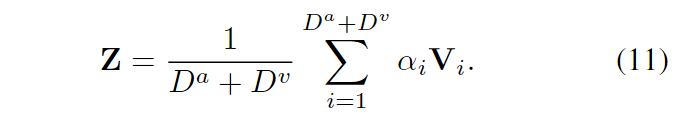
a_i代表在第i通道上观察的置信度。
将不同模态的感知注意值融合到融合图中,并且在PF的更新步骤对例子进行加权,之后将粒子位置融合图的值设置为新的例子权重。为了利用融合图的全局信息,在每一次迭代开始时,将一组粒子重置在融合图的峰值位置。
通过对峰值的矫正,避免了因某些帧存在观察噪声而造成的追踪漂移问题。当环境存在严重噪声干扰时,该方法表现出色。
实验和讨论
数据集
作者使用了AV16.3语料库,该语料库提供从校准相机派生的真实 3D 嘴位置和各种图像上的 2D 测量以进行系统评估。实验在 seq08、11 和 12 上进行了测试,其中单个参与者绕、快速移动和间歇性说话。每组实验使用来自两个麦克风阵列和单个相机的信号。
实施细节
视觉线索是基于AlexNet的预训练孪生模型生成。参考图像集1包含尺度为1,1.25的两个目标矩形,由第一帧中的用户定义。对于音频测量,垂直和水平方向的2D采样点数为w=20,h=16。桌子高度0.8m,房间规格为3.6x8.2x2.4,去除了桌子下方和房间外的采样带你,避免了圆形麦克风阵列对称性带来的歧义。3D点的深度数为6。计算stGCF的参数设置为M = 120,m1 = 15, m2 = 5。注意力机制网络的主干是MobileNetv3-large ,该网络在seq01,02,03上进行训练,包含超过4500个样本。生成自监督训练标签的参数设置为Da = 5, Dv = 2, n = 6。所有模型都训练了20个epoch,批大小为16,学习率为0.01。定位方法和比较方法都基于采样重要性重采样(SIR)-PF,粒子数为100。
评估指标
使用平均绝对误差和准确度来评估跟踪方法的性能。MAE计算预测声源位置和地面实况像素级别的欧几里得距离,除以帧数。ACC测量城阙估计的百分比,其在像素中的误差距离不超过GT边界框对角线的1/2。
比较结果
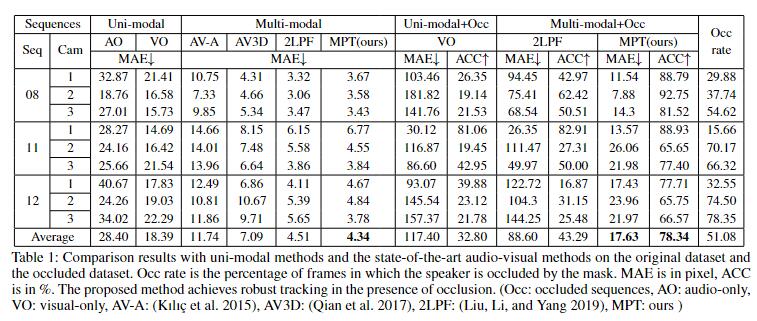
将所提出的MPT与基于PF架构的单模态方法和最先进的视听方法进行了比较。AO 和 VO 方法是根据上一节中提出的音频线索和视觉线索实现的。此外,为了验证跟踪器在干扰条件下的鲁棒性,作者对遮挡数据进行了对比实验。遮挡区域被人为地覆盖在图像的中间(帧的1/3),用于模拟视场有限或相机探视器被遮挡的情况。在序列中,说话者走在遮挡区域后面,然后再次出现在屏幕上。为了更好地评估,我们计算每个序列中目标被遮挡的帧的比例。比较结果如表1所示。首先,音频和视觉模式的组合对说话人跟踪有很大的好处。在标准数据集上,所提出的MPT的MAE像素为4.34,优于最先进的算法。2LPF 通过在音频和视觉空间中分别使用额外的粒子滤波器实现了准确的估计。然而,2LPF中融合似然的计算依赖于稳定的观测,当视觉观测不可用时,导致迅速下降。
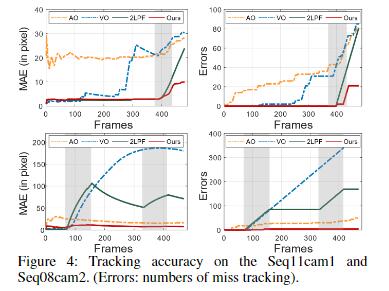
相比之下,MPT 在平均遮挡率为 51.08% 的序列上实现了 78.34% 的更好跟踪精度。图 4 显示了两个典型序列的 MAE 和错误数,其中阴影框表示目标被遮挡的帧。VO和2LPF受到遮挡的严重影响,这可以从阴影区域曲线的显著上升看出。 MPT 也受到遮挡的影响,但影响相对较小。
消融研究和分析
表2对MPT主要创新组建的有效性进行了评估。
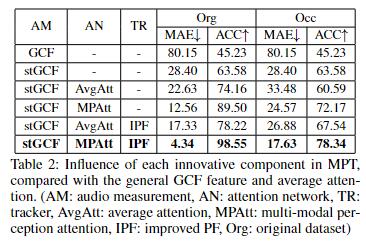
普通的GCF计算给定房间所有可能源位置的特定坐标下活动声源的存在合理性,如果没有先验信息,那么很难在有限的计算资源下寻找到准确的坐标。stGCF方法中将搜索范围通过投影关系缩小到不同深度的平面上,这是此前从未有人研究过的。
stGCF收到相机和麦克风阵列等几何配置的影响,特别是当扬声器位于相机和阵列的连线上时。由于声音信号的方向性,峰值通常出现在 stGCF 图中的大突出显示区域,这提供了模棱两可的搜索结果。作者使用两个麦克风阵列计算的结果优于传统方法,MAE 从 80.15 下降到 28.40。请注意,结果不会因视觉遮挡而改变。
可视化分析
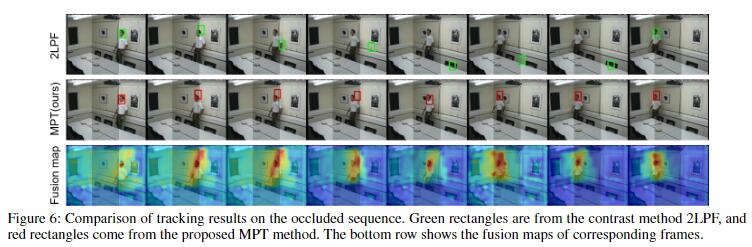
试听线索和融合图被用来生成热力图来可视化所提出方法的子过程。受益于网络感知每个模态状态的能力,该模型可以通过使用视听线索之间互补性来学习相应的感知权重(图5)。

当视觉场有限时,可以实现连续跟踪。由于听觉感觉不受到视觉分心的干扰,音频线索在此种情景中具有优势,当说话者走到遮挡区域时,追踪器可以粗略估计说话者位置,这有利于当目标再次可见时重新追踪(图6)。
结论
在本文中,作者提出了一种新的多模态感知跟踪器,用于具有挑战性的视听说话人跟踪任务。以及一种新的多模态感知注意网络和一种新的声学图谱提取方法。所提出的跟踪器利用多种模式的互补性和一致性以自监督的方式学习不同模态之间观察的可用性和可靠性。大量实验表明,所提出的跟踪器优于当前最先进的跟踪器,尤其是在不利条件下显示出足够的鲁棒性。使用可视化中间过程以证明所提出的跟踪器网络的可解释性。

