
热门标签
热门文章
- 1同样的APP为何在Android 8以后网络感觉变卡?
- 2史上最全!用Pandas读取CSV,看这篇就够了
- 3基础编码管理组件 Example 程序
- 4【实用党】推荐几款实用的AI工具_手绘生成图片
- 5【C语言篇】链表的基本操作-创建链表、插入节点、删除节点、打印链表_链表结构体打印链表程序
- 6【行为识别现状调研1】_多尺度时空特征和运动特征的异常行为识别
- 7QUIC:基于UDP的多路复用安全传输(部分翻译)_quic的多路复用
- 8mysql查询和修改的底层原理_数据库修改的实质是什么
- 9技术的正宗与野路子 c#, AOP动态代理实现动态权限控制(一) 探索基于.NET下实现一句话木马之asmx篇 asp.net core 系列 9 环境(Development、Staging ...
- 10中兴新支点桌面操作系统——一些小而美的功能
当前位置: article > 正文
五一 Llama 3 超级课堂 | XTuner 微调 Llama3 图片理解多模态 实践笔记_llava-llama3 is a llava model fine-tuned from llam
作者:花生_TL007 | 2024-05-30 21:11:50
赞
踩
llava-llama3 is a llava model fine-tuned from llama 3 instruct and clip-vit-
基于 Llama3-8B-Instruct 和 XTuner 团队预训练好的 Image Projector 微调自己的多模态图文理解模型 LLaVA。
课程文档:Llama3-Tutorial/docs/llava.md at main · SmartFlowAI/Llama3-Tutorial · GitHub
环境、模型、数据准备
1.环境准备
使用之前课程中已经配置好的环境、XTuner和Llama3-Tutorial
2.模型准备
-
Llama3 权重:使用之前课程软链接过的Llama3-8B-Instruct
-
Visual Encoder 权重:Llava 所需要的 openai/clip-vit-large-patch14-336,权重,即 Visual Encoder 权重。(使用软链接)
-
Image Projector 权重

3.数据准备
微调
1.训练启动
- 使用XTuner启动基于Llama3的LLaVA训练
xtuner train ~/Llama3-Tutorial/configs/llama3-llava/llava_llama3_8b_instruct_qlora_clip_vit_large_p14_336_lora_e1_finetune.py --work-dir ~/llama3_llava_pth --deepspeed deepspeed_zero2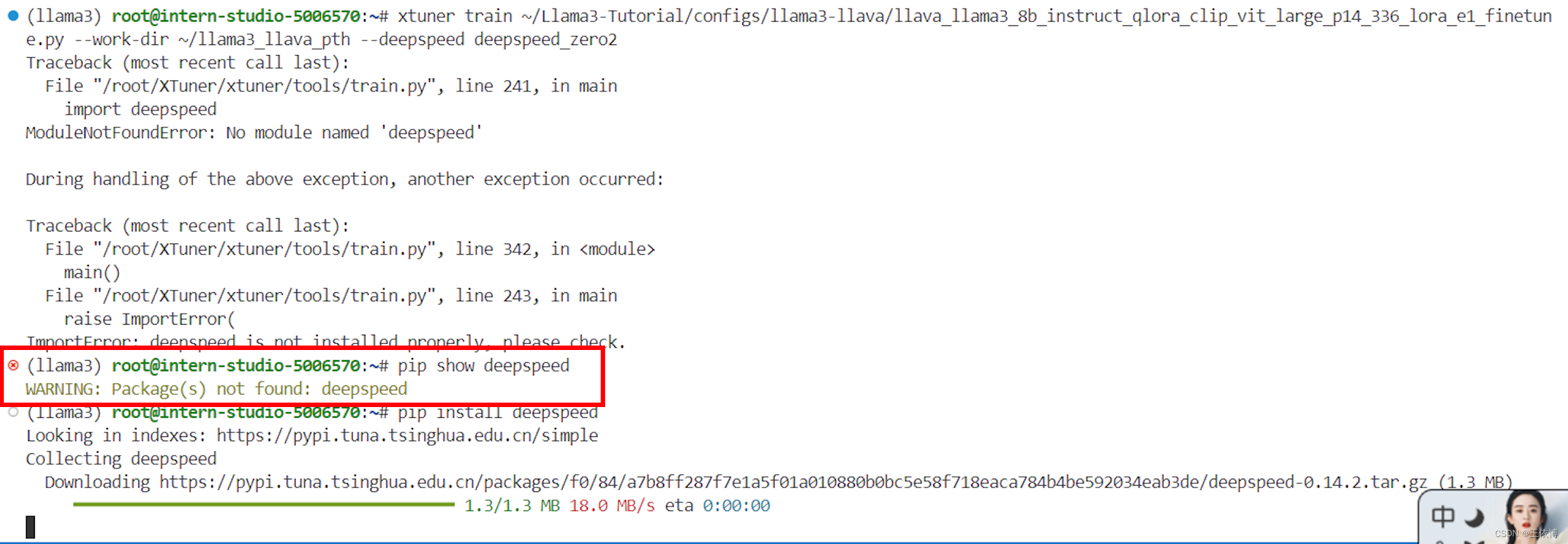
需要先安装deepspeed,重试

30%的A100好像不太够用,加上offload重试,启动成功

大约用时4个小时左右
- 将原始 image projector 和 我们微调得到的 image projector 都转换为 HuggingFace 格式
- xtuner convert pth_to_hf ~/Llama3-Tutorial/configs/llama3-llava/llava_llama3_8b_instruct_qlora_clip_vit_large_p14_336_lora_e1_finetune.py \
- ~/model/llama3-llava-iter_2181.pth \
- ~/llama3_llava_pth/pretrain_iter_2181_hf
-
- xtuner convert pth_to_hf ~/Llama3-Tutorial/configs/llama3-llava/llava_llama3_8b_instruct_qlora_clip_vit_large_p14_336_lora_e1_finetune.py \
- ~/llama3_llava_pth/iter_1200.pth \
- ~/llama3_llava_pth/iter_1200_hf
2.效果比对
检验模型效果
问题1:Describe this image. 问题2:What is the equipment in the image?
Pretrain 模型


Finetune 后 模型
- export MKL_SERVICE_FORCE_INTEL=1
- xtuner chat /root/model/Meta-Llama-3-8B-Instruct \
- --visual-encoder /root/model/clip-vit-large-patch14-336 \
- --llava /root/llama3_llava_pth/iter_1200_hf \
- --prompt-template llama3_chat \
- --image /root/tutorial/xtuner/llava/llava_data/test_img/oph.jpg

原始模型回答不出第二个问题,经过微调后可以回答出来
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/花生_TL007/article/detail/648636
推荐阅读

相关标签

