
- 1牛客练习赛126(O(n)求取任意大小区间最值)_牛客练习赛126,
- 2栅格瓦片和矢量瓦片
- 3HMC 命令行登陆设置_ibm ssh hmc mtmenu ~+.
- 4使用VitePress搭建个人博客_vitepress框架支持node版本
- 5mac苹果电脑下载vscode_苹果电脑下载vs code的inside和table
- 6OpenHarmony开发实战:新闻数据加载(ArkTS)_arkts 上拉加载
- 7大学生搜题答案神器 物理?3个公众号和软件推荐清单! #微信#经验分享#媒体
- 8Hbase用法总结_hbase怎么用
- 9专业技能篇--算法
- 10VulnHub渗透测试实战靶场 - TOPHATSEC: FRESHLY_vulnhub tophatsec: freshly
基于深度语义特征的图像情感分类算法
赞
踩
现有的基于语义特征的图像情感分类算法,更多的是在低端特征的基础上通过低端特征的不同组合,构建相应的语义分类器,比如物体或者场景,然后对于具体的图像,将其在分类器上的对各概念的响应作为语义特征,最后利用语义特征进行图像情感分类的研宄。显然,该方法非常依赖于语义特征的表征能力,而基于低端特征构建的语义特征相比较深度语义特征而言,其在表征能力上有着非常大的差距,因此提出基于深度语义特征的图像情感分类算法。一方面,提出使用深度语义特征进行图像情感分类,具体包括使用不同语义特征以及同一语义特征不同抽象层次的图像情感分类算法;另一方面,提出改进的多特征融合算法,包括基于微调双路网络的多特征早融合算法,以及强调不同特征分类结果对最终分类结果不同影响力的多特征晚融合算法。
1.基于单一深度语义特征的图像情感分类算法
在卷积神经网络中,随着层次逐渐深入,对所获取的信息不断抽象,因而从其中所抽取到的特征也从低级到高级。从图中可以看出,对于卷积神经网络而言,底层特征是非常类似的,大多是边缘以及形状等信息,而后随着层次深入,特征抽象程度越来越高,越来越接近分类的物体。基于这一点,对于我们提出的基于单一深度语义特征的图像情感分类算法而言,显然语义特征的抽取需要从卷积神经网络的较高层中进行。
具体而言,在卷积神经网络模型的选择上,我们选择了在计算机视觉领域中
广泛应用的VGGNET。图给出了VGGNET的具体架构,从图中,我们可以看出与传统的卷积神经网络类似,VGGNet也是低层通过卷积操作抽取局部特征,高层通过全连接层去构建高级的语义抽象。因而在深度语义特征的选择上,我们更多应该从全连接层去选取。VGGNET算上最后的分类层,总共有三个全连接层。显然三个全连接层,都可以看作深度语义特征,不过区别在于一层比一层抽象,一层比一层接近分类内容。我们的算法即选取该三种不同层次的特征,分别构建相应的分类器,进行图像情感分类。

对于VGGNET而言,其基础模型训练的目的不同,所抽取到的语义特征也是完全不同的。分析发现,我们在观察一幅图像时,主要关注其中的物体跟场景信息,因而在基础模型的选择上,我们选取的是物体分类模型以及场景分类模型。
2基于深度语义特征融合的图像情感分类算法
正如前文提及的一样,物体与场景是图像中的两个重要因素,因而基于单一语义特征的图像情感分类算法,虽然在图像情感分类上有不错的效果,但是其仍有较大的提升空间。其中一种提升方式,即多种信息融合,多信息融合有助于图像情感分类性能的进一步提升。传统的融合方式,一种是早融合,即在特征层面的融合,首先将抽取到的不同信息合并,然后再将其通过分类器进行分类;一种是晚融合,即结果层面的融合,首先通过不同的信息分别进行分类,然后将分类的结果进行合并。在传统融合策略的基础上,分别提出了基于深度语义特征早融合的图像情感分类算法以及基于深度语义特征晚融合的图像情感分类算法。
2.1基于深度语义特征早融合的图像情感分类算法
对于多特征融合而言,其融合方式非常关键,合适的融合方式能够进一步提升模型的性能表现,而不恰当的融合方式不仅有可能使得最终性能不是最佳,甚至有可能起到反作用。传统的早融合策略将不同特征结合起来,虽然具有一定的分类效果,但是其没有考虑到两种特征的搭配是否合适,甚至是否最优。考虑到上述问题,本节提出基于双路网络早融合的图像情感分类算法。图是具体的网络架构图。双路网络中,一路网络为物体识别网络,一路网络为场景识别网络,两路网络分别抽取图像的物体特征以及场景特征,最终两路特征融合作为深度网络中的一层,然后通过一个全连接层进行图像情感分类。需要注意的适,与传统的早融合策略不同,两路特征抽取网络参数不再是完全固定不动,其部分参数可以通过最终的分类误差进行调整,从而使得两路网络以最终的图像情感分类为目标,在考虑两者融合的基础上找到各自最合适的特征表达。

具体来说,在训练开始之前,双路网络分别用预训练好的物体识别网络与场景识别网络初始化,然后在训练过程中,固定其中的卷积层权重参数,允许全连接层进行参数更新。整个网络通过常用的多分类损失函数Softmax loss进行监督。
总结起来,整个基于图像显著性的图像情感分类算法的训练流程如下:
输入:训练数据集{It},初始化深度网络参数
执行以下步骤,直到t>T:
1)从所有训练数据中采样,获取训练的batch。
2)通过物体识别网络抽取深度物体特征。
3)通过场景识别网络抽取深度场景特征。
4)融合双路特征,得到融合后的图像特征表示。
5)预测图像情感,并根据损失函数计算当前误差。
6)反向传播误差到每一层,并更新层中对应的参数。
2.2基于深度语义特征晚融合的图像情感分类算法
传统的后融合方法,直接将每一种特征的分类结果进行加权,虽然能够取得一定的效果,但是其存在一定的缺陷,即其直接默认每个特征的分类结果对最终的分类影响完全是凭借经验估计而来,而实际上,单纯凭借估计,不一定能够得到最优的权重组合,因而也不一定能够获得最好的图像情感分类效果。另外,传统的后融合方法,默认同一特征对于所有的分类类别的贡献是相同的,而实际中也并非究全如此。基于这些考虑,我们提出了两种改进的基于深度语义特征晚融合的图像情感分类算法。
1)同一特征分类结果对最后各分类类别的影响是相同的。
该种方法默认同一特征分类结果对最后各分类类别的影响是相同的,只是不同特征分类结果所占的权重不同。具体而言,各特征分类结果的相对权重,在训练中通过优化以下损失函数得到
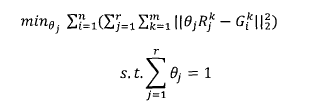
其中,
2)同一特征分类结果对最后各类分类结果的影响是不同的。与上面的方法认为同一特征分类结果对最后各分类类别的影响是相同的不同,该种方法认为,同一特征分类结果,对于最终分类结果中不同类别的影响力是不同的。具体而言,各特征分类结果对于最终分类结果中各类别的相对贡献,在训练中通过优化以下损失函数训练获得:
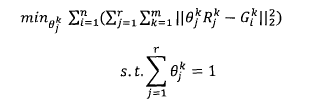
其中,
在实际训练过程中,只有
输入:训练数据集{It},初始化深度网络参数
执行以下步骤,直到t>T:
1)从所有训练数据中采样,获取训练的batch。
2)通过基于深度物体特征的图像情感分类器获取图像情感分类结果。
3)通过基于深度场景特征的图像情感分类器获取图像情感分类结果。
4)晚融合两种结果,得到最终的图像情感分类结果,并根据对应的损失函数计算当前误差。
5)根据所得误差,更新相应的权重参数。

