
- 1github托管项目流程_github tuoku
- 2312戳气球——力扣算法系列2020.07.19 Python_力扣戳气球python
- 3学习成长指导:文心一言智能体详细介绍和开发_文心一言 学习成长
- 4基于IndRNN的微博短文本情感分析设计与实现_基于rnn的新浪微博评论情感分析
- 5web信息泄露总结
- 6探索AI大模型在目标检测领域的应用
- 7解决adb端口被占用的问题_adb端口被占用怎么办
- 8宝塔搭建站点(无域名版本、解决80端口占用)_宝塔没有域名直接做网站怎么弄
- 9android traceview性能调试_android trace level
- 10fastDFS的安装和配置_fastdfs安装配置
【PyTorch 实战2:UNet 分割模型】10min揭秘 UNet 分割网络如何工作以及pytorch代码实现(详细代码实现)_pytorch unet
赞
踩
UNet网络详解及PyTorch实现
一、UNet网络原理
U-Net,自2015年诞生以来,便以其卓越的性能在生物医学图像分割领域崭露头角。作为FCN的一种变体,U-Net凭借其Encoder-Decoder的精巧结构,不仅在医学图像分析中大放异彩,更在卫星图像分割、工业瑕疵检测等多个领域展现出强大的应用能力。UNet是一种常用于图像分割的卷积神经网络架构,其特点在于其U型结构,包括一个收缩路径(下采样)和一个扩展路径(上采样)。这种结构使得UNet能够在捕获上下文信息的同时,也能精确地定位到目标边界。
-
收缩路径(编码器Encoder):通过连续的卷积和池化操作,逐步减小特征图的尺寸,从而捕获到图像的上下文信息。
-
扩展路径(解码器Decoder):通过上采样操作逐步恢复特征图的尺寸,并与收缩路径中对应尺度的特征图进行拼接(concatenate),以融合不同尺度的特征信息。
-
跳跃连接:UNet中的跳跃连接使得扩展路径能够利用到收缩路径中的高分辨率特征,从而提高了分割的精度。
-
输出层:UNet的输出层通常是一个1x1的卷积层,用于将特征图转换为与输入图像相同尺寸的分割图。
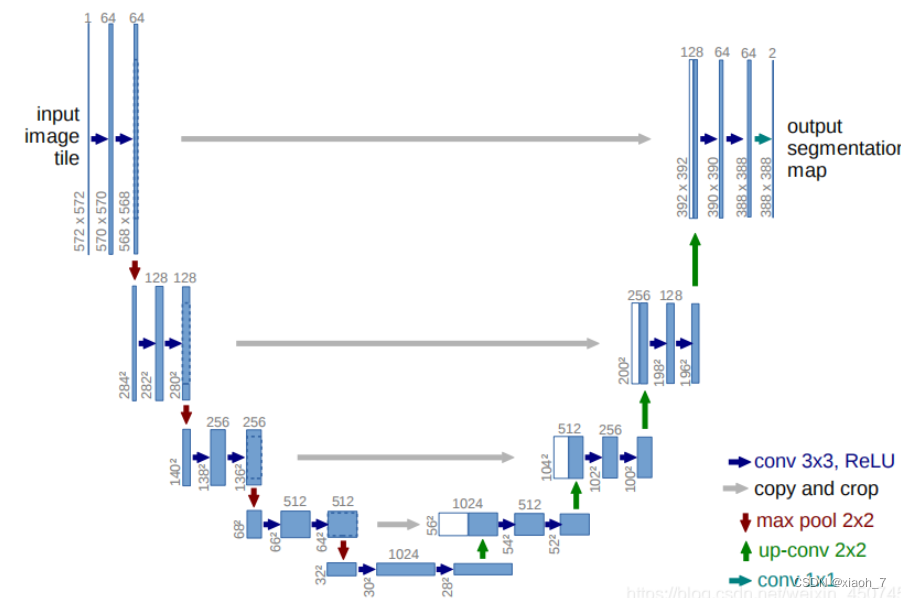
二、基于PyTorch的UNet实现
下面是一个简单的基于PyTorch的UNet实现,用于图像分割任务。(环境安装可以看我往期博客)
import torch import torch.nn as nn import torch.nn.functional as F class DoubleConv(nn.Module): """(convolution => [BN] => ReLU) * 2""" def __init__(self, in_channels, out_channels): super(DoubleConv, self).__init__() self.conv = nn.Sequential( nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1), nn.BatchNorm2d(out_channels), nn.ReLU(inplace=True), nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1), nn.BatchNorm2d(out_channels), nn.ReLU(inplace=True) ) def forward(self, x): return self.conv(x) class UNet(nn.Module): def __init__(self, n_channels, n_classes, bilinear=True): super(UNet, self).__init__() self.n_channels = n_channels self.n_classes = n_classes self.bilinear = bilinear self.inc = DoubleConv(n_channels, 64) self.down1 = DoubleConv(64, 128) self.down2 = DoubleConv(128, 256) self.down3 = DoubleConv(256, 512) factor = 2 if bilinear else 1 self.down4 = DoubleConv(512, 1024 // factor) self.up1 = nn.ConvTranspose2d(1024 // factor, 512 // factor, kernel_size=2, stride=2) self.up2 = nn.ConvTranspose2d(512 // factor, 256 // factor, kernel_size=2, stride=2) self.up3 = nn.ConvTranspose2d(256 // factor, 128 // factor, kernel_size=2, stride=2) self.up4 = nn.ConvTranspose2d(128, 64, kernel_size=2, stride=2) self.outc = nn.Conv2d(64, n_classes, kernel_size=1) def forward(self, x): x1 = self.inc(x) x2 = self.down1(x1) x3 = self.down2(x2) x4 = self.down3(x3) x5 = self.down4(x4) x = self.up1(x5, x4) x = self.up2(x, x3) x = self.up3(x, x2) x = self.up4(x, x1) logits = self.outc(x) return logits

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
三、训练与推理的完整代码
首先,我们需要准备数据集、定义损失函数和优化器,然后编写训练循环。
python import torch import torch.nn as nn import torch.optim as optim from torch.utils.data import DataLoader from torchvision import transforms, datasets from unet_model import UNet # 假设UNet定义在unet_model.py文件中 # 设定超参数 num_epochs = 10 learning_rate = 0.001 batch_size = 4 # 数据预处理 transform = transforms.Compose([ transforms.Resize((256, 256)), transforms.ToTensor(), transforms.Normalize(mean=[0.5], std=[0.5]) ]) # 加载训练集 train_dataset = datasets.ImageFolder(root='path_to_train_dataset', transform=transform) train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True) # 定义模型、损失函数和优化器 device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') num_classes = len(train_dataset.classes) # 根据数据集确定类别数 model = UNet(n_channels=3, n_classes=num_classes).to(device) criterion = nn.CrossEntropyLoss() optimizer = optim.Adam(model.parameters(), lr=learning_rate) # 训练循环 for epoch in range(num_epochs): model.train() # 设置模型为训练模式 running_loss = 0.0 for i, data in enumerate(train_loader): inputs, labels = data[0].to(device), data[1].to(device) optimizer.zero_grad() # 梯度清零 outputs = model(inputs) # 前向传播 loss = criterion(outputs, labels) # 计算损失 loss.backward() # 反向传播 optimizer.step() # 更新权重 running_loss += loss.item() * inputs.size(0) epoch_loss = running_loss / len(train_loader.dataset) print(f'Epoch {epoch+1}/{num_epochs}, Loss: {epoch_loss:.4f}') # 保存模型 torch.save(model.state_dict(), 'unet_model.pth') 推理 在推理阶段,我们加载已训练好的模型,并对测试集或单个图像进行预测。 python # 加载模型 model.load_state_dict(torch.load('unet_model.pth')) model.eval() # 设置模型为评估模式 # 如果需要,准备测试集 test_dataset = datasets.ImageFolder(root='path_to_test_dataset', transform=transform) test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False) # 对测试集进行推理 with torch.no_grad(): for inputs, _ in test_loader: inputs = inputs.to(device) outputs = model(inputs) _, predicted = torch.max(outputs, 1) # 可以将predicted保存为文件或进行其他处理 # 对单个图像进行推理 image_path = 'path_to_single_image.png' image = Image.open(image_path).convert('RGB') # 确保是RGB格式 image = transform(image).unsqueeze(0).to(device) # 对图像进行预处理并添加到batch维度 with torch.no_grad(): prediction = model(image) _, predicted = torch.max(prediction, 1) predicted_class = train_dataset.classes[predicted.item()] # 获取预测的类别名 # 可以将predicted保存为文件或进行可视化 这里我假设你已经有了适当的训练和测试数据集,并且它们已经被组织成了ImageFolder可以理解的格式(即每个类别的图像都在一个单独的子文件夹中)。此外,代码中的transform可能需要根据你的具体数据集进行调整。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
在推理阶段,我们使用torch.max来找出每个图像最有可能的类别,并通过predicted_class变量打印或返回该类别。对于测试集,你可能希望将预测结果保存为文件,以便后续分析或可视化。对于单个图像,你可以直接进行可视化或将其保存为带有分割结果的图像。
四、总结
我们详细介绍了如何使用PyTorch实现并训练一个U-Net模型,以及如何在训练和推理阶段使用它。首先,我们定义了一个U-Net模型的结构,该结构通过下采样路径捕获上下文信息,并通过上采样路径精确定位目标区域。然后,我们准备了训练和测试数据集,并应用了适当的数据预处理步骤。
在训练阶段,我们设置了模型、损失函数和优化器,并编写了一个循环来迭代训练数据集。在每个迭代中,我们执行前向传播来计算模型的输出,计算损失,执行反向传播来更新模型的权重,并打印每个epoch的平均损失以监控训练过程。训练完成后,我们保存了模型的权重。在推理阶段,我们加载了已训练的模型,并将其设置为评估模式以关闭诸如dropout或batch normalization等训练特定的层。然后,我们对测试数据集或单个图像进行推理,使用模型生成预测,并通过torch.max找到最有可能的类别。对于测试集,你可能希望保存预测结果以便后续分析;对于单个图像,你可以直接进行可视化或将其保存为带有分割结果的图像。
通过本博客,你应该能够了解如何使用PyTorch实现和训练一个U-Net模型,并能够将其应用于图像分割任务。当然,实际应用中可能还需要考虑更多的细节和优化,如更复杂的数据增强、学习率调整策略、模型的正则化等。

