
- 1开源存在漏洞 红帽团队联合Black Duck为容器安全保驾护航
- 2【Flink-1.17-教程】-【二】Flink 集群搭建、Flink 部署、Flink 运行模式_flink1.17.0集群搭建
- 3Arduino支持STM32芯片开发_arduino stm32
- 4hive 查看历史job的执行sql_hive查询sql执行历史
- 5单目深度估计(Monocular Depth Estimation)论文阅读 2021-01-15
- 6c语言结构体成员变量私有化,C语言结构体变量私有化
- 7EduCoder 计算机系统基础硬件设计答案_在 logisim 模拟器中打开 alu.circ 文件,在对应子电路中利用已经封装好的全加器设
- 8基于传统方法的单目深度估计
- 9【Neo4j × Python】基于知识图谱的电影问答系统(含问题记录与解决)附:源代码(含Bug解决)_基于python的neo4j电影推荐
- 10javaSwing图书管理系统
如何从0开始建立数据库(五):数据库系统的实现_数据库的实现怎么实现
赞
踩
本文转载于https://www.cnblogs.com/muchen/p/5291325.html,仅做学习参考使用,侵删
前言
前面的文章中,主要都是在围绕关系数据库理论进行研究,没有涉及到数据库系统的具体实现。
虽说数据库系统的具体实现因业务环境,RDBMS等因素而异,但总体开发流程,以及开发过程中所涉及到的一些问题,也具有不少统一的套路、标准。
本文主要讨论数据库系统实现过程中的重点环节、基本开发流程、数据库管理以及数据质量工程等话题。
参照完整性约束对更新删除操作的影响
在第三篇中,我们已经讨论过,关系设计的目的就是为了减少冗余消除更新异常。但当时也留下一个问题:外码本身是冗余的,那么涉及到外码的更新时怎么办呢?
关系数据库理论将这个问题交给了RDBMS,让它来解决涉及外码的更新异常。下面先来看一下,涉及外码的更新异常到底长什么样子。
在下面的这个关系中:
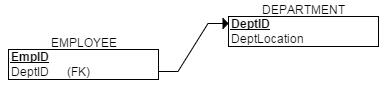
关系EMPLOYEE中的Dept属性是一个外码,它对应DEPARTMENT关系的主码。如果对该属性进行更新或者删除,那么这个外码就找不到它对应的主码,两个关系的联系就被破坏了。针对这个问题,RDBMS的解决方案有四个,下面以删除异常为例进行说明:

-
限制删除
限制删除是指如果某记录主码被另一个记录外码对应,则该记录不允许被删除。如上面示例DEPARTMENT关系中的记录在删除的时候有可能被RDBMS禁止。 -
级联删除
级联删除是指如果某个记录的主码被另一个记录的外码对应,那么这两个记录将一起被删除。 -
设置为空
是指如果某个记录的主码被另一个记录的外码对应,那么在删除这个记录后,另外那个记录的外码字段置为空。 -
设置默认值
同3,不过是将置为空改为设置成一个默认值。
更新情况和删除一样,要注意的是所有处理都发生在对外码映射中的非外码关系进行操作时发生。这些处理主要是对外码关系进行附加操作,如级联删除,置空,置默认值,或者报错。
索引机制
索引(index)机制的本质是一种检索加速机制,本文将从索引的逻辑意义上对它进行解析,至于其在各RDBMS里的物理实现细节则不做介绍。事实上若非数据库维护管理人员,也没必要知道。在下面这张客户关系表中:
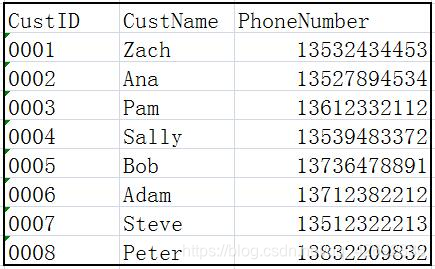
id是按顺序排列的,因此如果要检索某id对应记录,则由于记录已按id排好序,可使用多种查找算法提高检索效率,如二分查找等。但关系中某一列排好序以后,其他列必然是乱序的,那怎么办?在RDBMS中,这种情况可以通过新建一个只包含两列的附加表来实现:

索引表中其中一列为索引字段,另一列则包含一个指针指向原纪录。这样在对索引列进行查询的时候,RDBMS会先对索引表进行操作,完了再映射到原表并返回结果。
从本质上来说,这是一种牺牲空间换取时间的办法,索引建立不单耗费存储资源,而且会降低更新、删除等操作的效率。因此不是说建的索引越多就越好,具体建立何种索引,建立多少索引,则要取决于计算资源,RDBMS,业务场景等因素。
触发器机制
触发器是一种规则,当关系中删除、插入、修改一条记录的时候执行。它的应用场景很多,故几乎所有RDBMS都提供了该功能。如下代码是在MYSQL中编写的触发器,它施加于student关系的insert操作上:每次insert一条学生记录后,都会更新关系中的记录数,如果记录数超过10,则不为新的学生分配导师:
CREATE TRIGER studentinserttrigger
BEFORE INSERT ON student
FOR EACH ROW
BEGIN
DECLARE totaladvised INT DEFAULT 0;
SELECT COUNT(*) INTO totaladvised
FROM student
WHERE advisorid = NEW.advisorid;
IF (totaladvised >= 10) THEN
SET NEW.advisorid = NULL;
END IF
END;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
注意这段代码不是标准SQL代码,不必细究。触发器实现代码的语法规则取决于RDBMS,需要时再有针对性的参考手册即可。
数据库系统开发流程
所谓数据库系统(database system),就是指让用户和数据库信息之间进行有效交互的计算机系统。其典型的框架如下图所示:
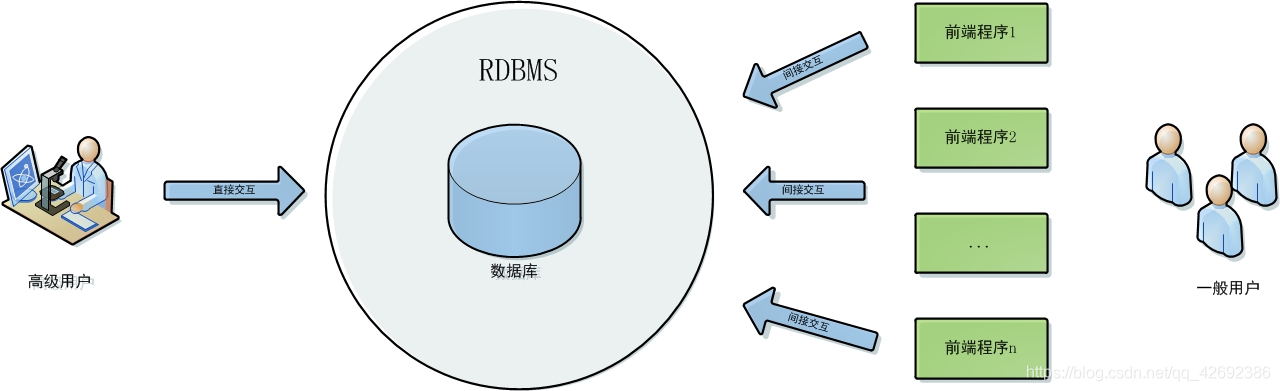
可见, 数据库系统的三大主要成分分别是:数据库,数据库管理软件RDBMS,还有前端应用程序(网站,APP等)。数据库是数据库系统的核心,负责存放所有数据。而数据库对外的所有交互,均通过RDBMS来进行。一般用户通过前端应用程序使用RDBMS,而比较专业的用户也可直接使用RDBMS操纵数据库。
举例来说,某人通过APP订购商品,那么这个APP就是前端应用程序。而当他有一个具体行为,比如付款的时候,前段应用程序就会和RDBMS通信,让RDBMS完成扣款并返回操作执行结果。
数据库系统的总体开发流程,可以总体划分为以下步骤:

-
数据库需求
需求搜集是所有环节中最重要的一步,吃透了用户需求,往往就成功了大半。这些需求将指导后面如需求建模、实现、以及前端应用程序开发等。通常来说,需求都会通过ER图来表示(参考本系列第一篇),并和各业务方讨论搜集得到,最终整理成文档。
要特别强调的一点是数据库系统开发需求阶段过程是循环迭代式的,一开始的需求集并不大,但随着项目的进展,需求会越来越多。而且不论是以上哪个阶段发生了需求变动,整个流程都需要重新走一遍,决不允许隐式变更需求。 -
数据库建模
也就是逻辑模型建模,在本系列第二篇有过详细讲解,这里不再赘述。 -
数据库实现
这一步的本质就是在空的RDBMS里实现2中创建的关系模型,一般通过使用SQL或者RDBMS提供的前端工具实现。 -
开发前端应用程序
前端应用开发在需求搜集好了之后就开始进行,主要有网站、APP等前端形式。另外前端程序的实际实现涉及到和数据库之间交互,因此这一步的最终完成在数据库建模之后。 -
数据库部署
顾名思义,这一步就是部署数据库系统的软硬件环境。笔者这里插一个故事,以前在A公司工作时,一哥们自告奋勇到某政府秘密部门部署私有云环境。那地方很偏僻,不允许外网,U盘都不能用,只能光盘安装。而A公司的云平台部署是一件非常复杂的活,于是那哥们就在那里呆了一个多月,回来后据说是瘦了7斤…
回到正题,数据库部署往往还包含将初始数据填入数据库中的意思。对于云数据仓库,这一步就叫"数据上云"。 -
数据库使用
这一步没啥多讲的,就再讲一个有关的故事吧。同样是在A公司,有一次某政企私有云项目完成后,我们有人被派去给他们培训如何使用。结果去的人回来后说政企意见很大,认为让他们学习SQL以外的东西都不行。拒绝用Python写UDF,更拒绝MR编程接口,只要SQL和图形界面操作方式。一开始我对政企的这种行为有点看不起,但后来我想,就是因为有这群挑剔的用户,才使得A公司云产品的易用性如此强大,从而占领国内云计算的大部分市场。用户的需求才是技术的唯一试金石。 -
数据库管理和维护
严格来讲,这部分不算开发流程,属于数据库系统开发完成后的工作。接下来本文将围绕这个话题进行讲解。
数据库系统管理
数据库系统发行后,控制权便从数据库设计、实现、部署的团队移交给了数据库管理员(database administrator, DBA),并由他们来对系统进行管理。
数据库管理涵盖了确保一个已经部署的数据库系统正确运行的各种行为。为了实现这一目标,数据库管理具体包含以下范畴:

这部分工作的涉及面相当广而深,应由专业的DBA团队去完成。本文主要针对人群是数据科学家,因此仅对这些工作做一个简明的介绍。
-
数据库系统监测与维护
监测工作可以让DBA掌握数据库系统的运行情况,并针对发现的问题进行维护。比如发现存储资源不够用了,则要分配给数据库系统更多存储空间等。
同时,监测工作也可以让DBA知道关系数据库中各关系的具体使用情况,从而进行优化。比如某两个表被大群用户频繁使用,并只用来重复创建相同的报表。这时候DBA就可以考虑建议数据库开发团队反规范化设计的将这两个表合并到一起。
维护工作是指DBA在监测到了问题后,采取的修复行为。比如上面提到的分配更多存储空间,向数据系统加入新的关系(注: 数据库开发设计人员决定是否加入关系,DBA负责建议加入和具体执行),都属于维护范畴。 -
数据库安全保障
数据库安全保障工作可以说是数据库系统管理工作中的首要任务,该任务需要DBA对数据的存取过程严加控制。
具体点来说,就是要求DBA做好数据库访问人员的认证工作,并对所有用户进行权限划分。
此外,对于特别敏感的数据,还应进行加密处理。这部分功能一些商业数据库做得很好,比如Oracle。 -
数据库备份与恢复
这里简要说明一下数据库备份与恢复的原理。我们知道,数据库的数据,是存放到磁盘里的。而计算机对数据的处理过程,都是先把数据从硬盘转移到内存,处理完后再放回去。
而如果数据在内存中进行处理,还没有将数据转移回磁盘的时候,数据库挂了的话就将导致数据丢失。因此RDBMS采用恢复日志(recovery log)机制,先记录更新操作要做的事情,比如那个数据被更新,更新前后的值,更新请求的用户等,然后再做具体的更新操作。在更新日志中可以设置"检查点",之后DBA可使用它进行周期性副本备份。失效事件发生之后,DBA可以利用"检查点"进行系统恢复:回滚(Roll Back)至指定检查点状态。
对于那种彻底性毁坏的情况,比如发生火灾、地震等,可在多个不同物理站点上保留完全镜像备份(complete mirrored backup)。这些副本需持续更新保证与数据库系统一致。 -
数据库性能优化
性能优化工作包括设置索引,逆规范化,SQL优化等等。通常有QPS(query per second)等指标来衡量数据库系统的优化效果。
这部分工作内容很多也比较杂,主要通过DBA管理RDBMS的查询优化器完成。但对于数据库的开发员和使用者来说,也多多少少要知道一点,比如写Hive语句的时候需要灵活设置分区,避免数据倾斜等。这些具体环境的优化方案,本文篇幅有限就不一一讲解了。 -
数据库标准制定
这部分工作包括数据库中字段命名规范,SQL编码规范的制定等。除了这些开发标准,还有使用标准,比如使用数据库的人需要遵守哪些有益于数据库系统健康的行为规范。
数据质量体系
数据库系统,以及接下一个系列要讲的数据仓库系统,都需要始终重视数据质量问题。用一句话概括,数据质量就是衡量数据能否真实、及时反映客观世界的指标。
具体来说,数据质量包含以下几大指标:
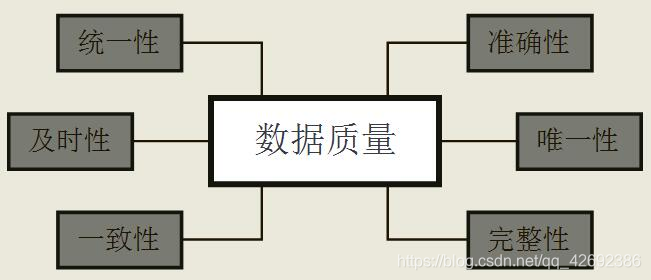
-
准确性
准确性要求数据能够正确描述客观世界。比如某用户姓名拼音mu chen错误的录入成了muc hen,就应该弹出警告语; -
唯一性
唯一性要求数据不能被重复录入,或者不能有两个几乎相同的关系。比如张三李四在不同业务环境下分别建立了近乎相同的关系,这时应将这两个关系合并; -
完整性
完整性要求进行数据搜集时,需求数据的被描述程度要高。比如一个用户的购买记录中,必然要有支付金额这个属性; -
一致性
一致性要求不同关系、或者同一关系不同字段的数据意义不发生冲突。比如某关系中昨天存货量字段+当天进货量字段-当天销售量字段不等于当天存活量,否则就可能是数据质量有问题; -
及时性
及时性要求数据库系统中的数据"保鲜"。比如当天的购买记录当天就要入库; -
统一性
统一性要求数据格式统一。比如nike这个品牌,不能有的字段描述为"耐克",而有的字段又是"奈克";
数据质量和数据具体意义有很大相关性,因此无法单凭数据库理论来保证。且由于具体业务及真实世界的复杂性,数据质量问题必然会存在,不可能完全预防得了。因此很多RDBMS或第三方公司都提供了数据质量工程服务/软件,用来识别和校正数据库系统中的各种数据质量问题。
小结
本篇作为数据库系列的终篇,主要围绕数据库系统实现所涉及到的方方面面进行讲解。想必读者看完本文后会和我一样,感受到一个完整而优秀的数据库系统实现并不简单,甚至可以说是比较繁琐。虽说实际项目中每个人只需要专门负责其中一个或者几个模块,不过笔者认为作为一名优秀的数据库开发人员,也必须对全局有一定的认识,这也是本文意义所在。
最后谈点题外话吧。笔者本人是一名数据挖掘工程师,看到很多朋友把精力完全投到研究数据挖掘算法和实现上,私以为这样做是很不科学的。因为一个优秀的数据挖掘引擎,必然架构在一个优秀的数据库/数据仓库系统之上。而一个数据挖掘工程师80%的工作都是在利用这些系统进行数据清洗、特征提取等,深入思考算法模型的时间并不多(除非您是在特别牛的平台性算法团队工作)。因此在深入学习数据挖掘算法之前,一定要有良好的数据基础知识,不能好高骛远。

