- 1工智能在各个行业的渗透度都在增加,尤其是在互联网和金融行业_人工智能技术正字啊渗透到了ict产业的各个环节,比如()等各领域
- 2mysql不支持addbatch_Mysql连接数据库:PreparedStatement.addBatch()方法
- 3LeetCode:20、给定一个只包括 '(',')','{','}','[',']' 的字符串,判断字符串是否有效。_.给定一个只包括(,了,“,了,[,了的字符串,判断字符串是否有效
- 4Java 开发验证码。随机产生一个四位数的验证码,每位数可能是数字、大写字母或小写字母。_随机产生4位数的验证码
- 5转载windows的网络错误问题,备需要时查看
- 6电脑使用adb实现模拟手机点击_adb 模拟点击
- 7React父子组件传值默认值,传值类型
- 8论文解读Nerf2Mesh:基于Nerf的网格资产生成
- 9搭建SpringBoot项目——开发环境搭建开发环境搭建_springboot环境搭建
- 10stm32启动地址
Hadoop入门学习笔记——六、连接到Hive_hadoop连接hive
赞
踩
视频课程地址:https://www.bilibili.com/video/BV1WY4y197g7
课程资料链接:https://pan.baidu.com/s/15KpnWeKpvExpKmOC8xjmtQ?pwd=5ay8
六、连接到Hive
6.1. 使用Hive的Shell客户端
1、在HDFS集群、JobHistoryServer、YARN集群、metastore服务均已启动的前提下,进入hive客户端
su hadoop
cd /export/server/hive/bin
# 进入hive客户端
./hive
- 1
- 2
- 3
- 4
2、创建表
create table test(id int, name string, gender string);
- 1
3、展示当前数据库的所有表
show tables;
- 1
4、插入数据
INSERT INTO test VALUES(1, '王力红', '男'), (2, '周杰轮', '男'), (3, '林志灵', '女');
- 1
执行时会发现非常慢,查看执行日志之后发现,虽然写的是SQL代码,但是实际是一个MapReduce程序在执行。
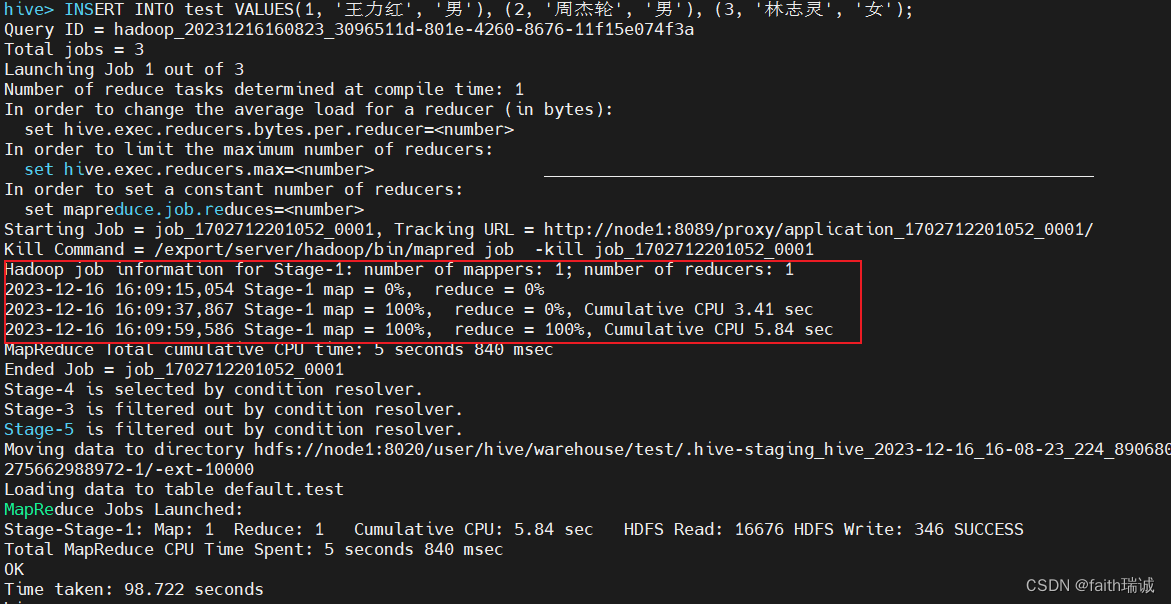
虽然这里执行很慢,但是在实际使用场景中,Hive数据都是批量(一次性几百万以上)插入的,不会一条条的插入,所以性能会更高。
5、查询数据
# 查询数据
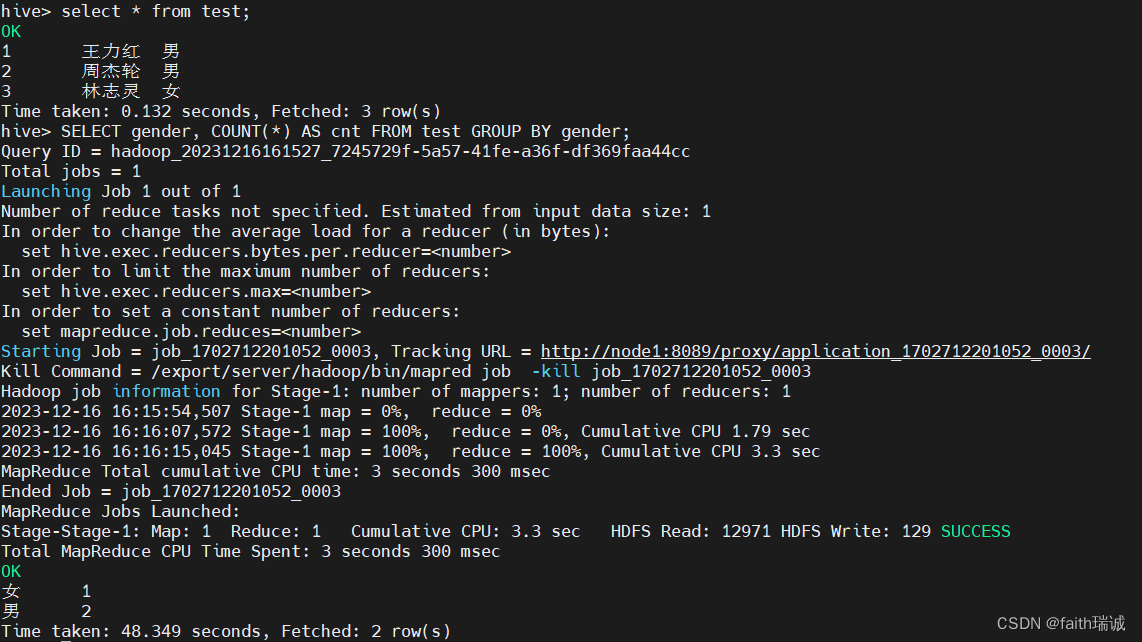
select * from test;
# 按性别统计人数
SELECT gender, COUNT(*) AS cnt FROM test GROUP BY gender;
- 1
- 2
- 3
- 4
执行之后会发现,第一条语句执行非常快,没有转换成MapReduce程序,第二条语句又会转换成MapReduce程序进行执行(慢的原因主要在于提交到YARN集群,YARN集群准备阶段慢)。
6、Hive中数据库和数据的存放路径位于HDFS文件系统的/user/hive/warehouse路径下,该路径下,每个Hive库中的表都是一个文件夹,使用fs -ls /user/hive/warehouse命令可以查看,下图test文件夹表示刚才创建的test表(一个hive库就是一个HDFS系统中的文件夹,一个表也是HDFS系统中的一个文件夹,default库下的表直接体现为/user/hive/warehouse下的文件夹,其他自定义库也是/user/hive/warehouse下的文件夹,然后其库内的表,是下一层的文件夹);

使用hadoop fs -cat /user/hive/warehouse/test/*命令查看test文件夹下所有文件的内容,可以看到刚才通过insert语句插入的数据

所以,Hive表面上看起来操作的是数据库和表,但本质上还是在操作HDFS系统中的文件。
上图中,可以看到在命令行中,没法看到test表中各列数据的分隔符(看起来数据都是紧密排列的),可以在元数据库(MySQL)中查询到对应的分隔符信息(默认分隔符是“\001”,是一个特殊字符,是ASCII码,在控制台上无法显示,在部分软件中显示为SOH),在bash shell命令行中使用mysql -u root -p命令登录MySQL;
# 选择hive数据库
use hive;
# 查看hive库中的表
show tables;
# 查看hive中所有的表
select * from TBLS;
- 1
- 2
- 3
- 4
- 5
- 6

可以看到刚才在hive中新建的test表及其信息。
# 查看hive中所有的库及其信息
select * from DBS;
- 1
- 2
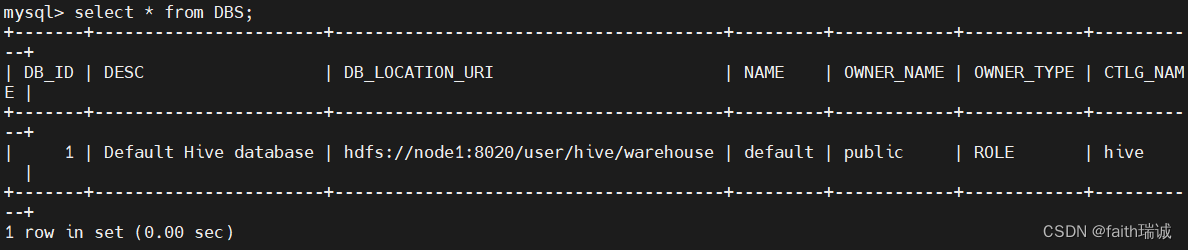
可以看到hive中的default数据库,可以看到其在HDFS中的存储位置(hdfs://node1:8020/user/hive/warehouse)。
6.2. 使用Beeline客户端连接HiveServer2操作Hive
HiveServer2是Hive内置的一个ThriftServer服务,提供Thrift端口供其它客户端链接。
可以连接ThriftServer的客户端有:
- Hive内置的 beeline客户端工具(命令行工具);
- 第三方的图形化SQL工具,如DataGrip、DBeaver、Navicat等。
Hive的客户端体系如下所示:
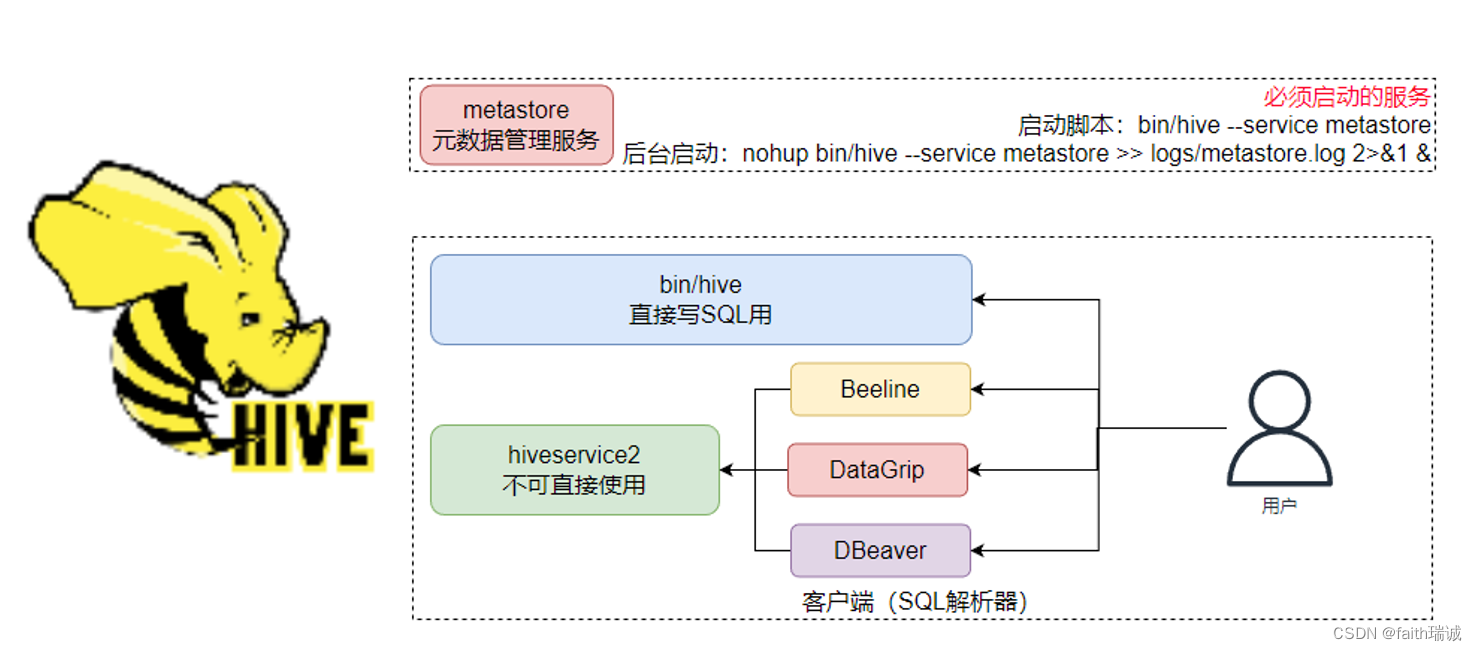
6.1章节演示的便是bin/hive客户端,本章节介绍通过Beeline连接hiveservice2的方式操作Hive。
1、启动HiveServer2(在node1节点)
在启动hiveserver2服务之前,需要确保metastore服务已经启动了。
前台启动方式:./hive --service hiveserver2
后台启动方式:nohup ./hive --service hiveserver2 >> ../logs/hiveserver2.log 2>&1 &
在实际工作中,一般使用后台启动方式启动。
启动完成后,可以使用netstat -anp | grep 10000命令,查看node1服务器的10000端口(ThriftServer服务的端口号)正在被hiveserver2服务的进程(通过进程号比对可知)占用着。
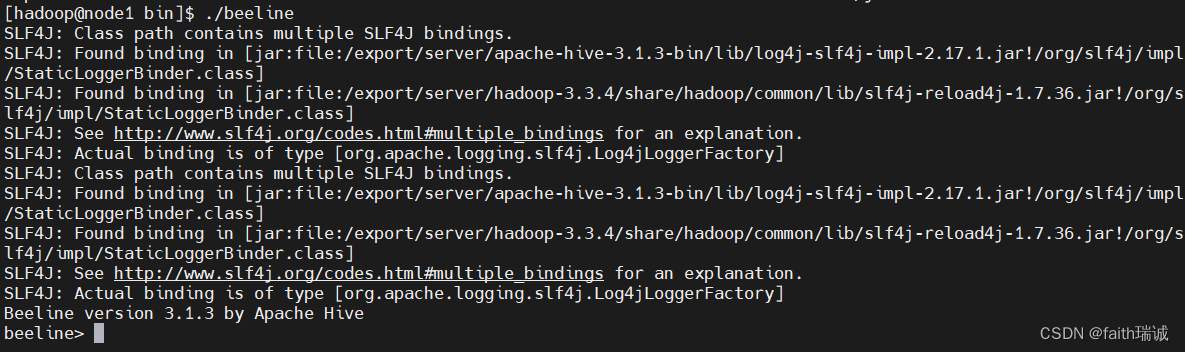
2、使用Beeline客户端连接HiveServer2服务
在$HIVE_HOME/bin目录下,有一个beeline程序,可以直接使用./beeline打开beeline命令行,如下所示:
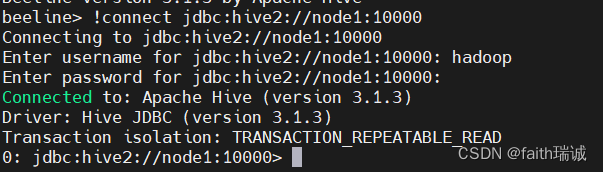
在beeline命令行中输入!connect jdbc:hive2://node1:10000连接HiveServer2服务,这个命令的含义是,告知beeline客户端,我们要发起连接,使用jdbc驱动,按照hive2协议,连接node1(这里也可以是IP地址)的10000号端口。
输入上述命令后,程序会提示输入用户名,这里需要输入启动hive的启动用户(即hadoop),然后会提示输入密码,因为没有配置,所以直接回车即可,然后就可以看到已经连接好了,具体效果如下:
3、此时,就可以在0: jdbc:hive2://node1:10000>shell中输入相关的SQL语句,操作hive了。
在显示效果上,beeline客户端要比hive的shell客户端好看一些,查询结果都是以表格的格式返回的,而hive的shell客户端则是直接文本输出。
show databases;
- 1
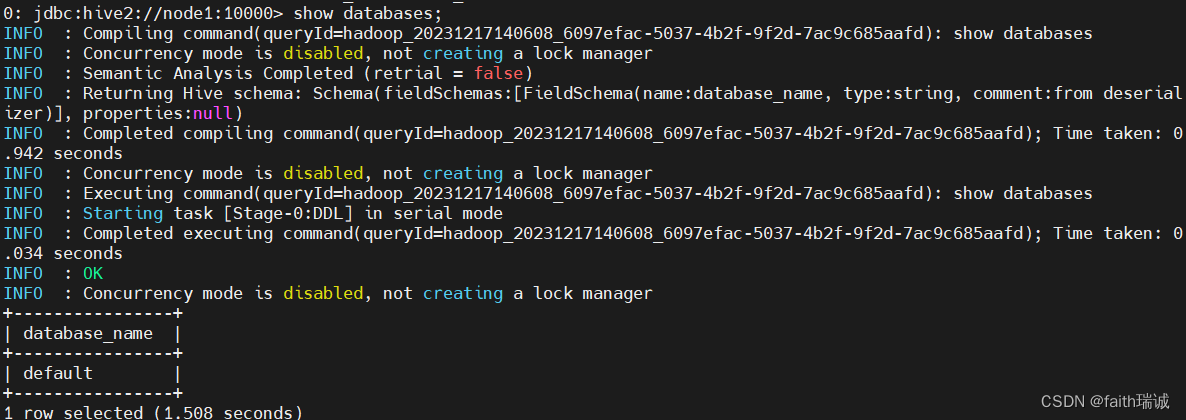
show tables;
- 1
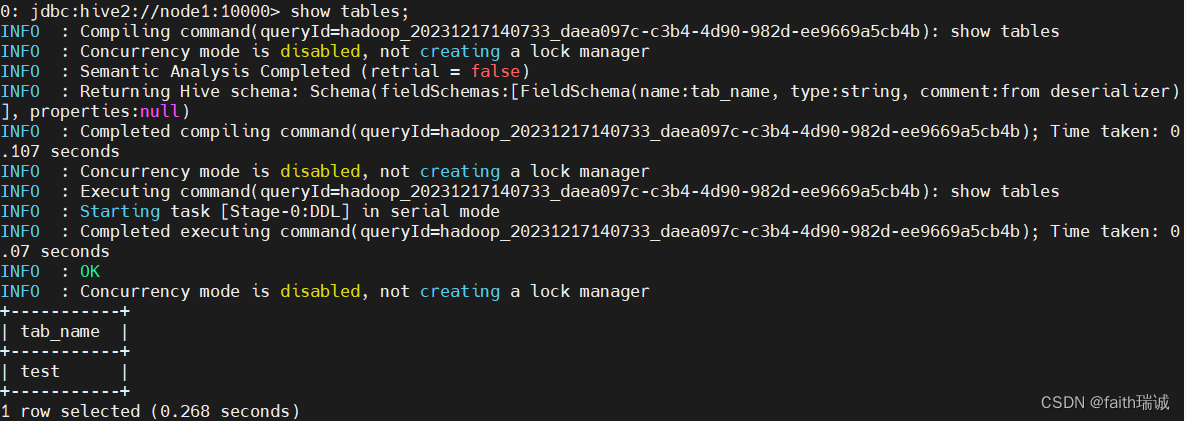
select * from test;
- 1
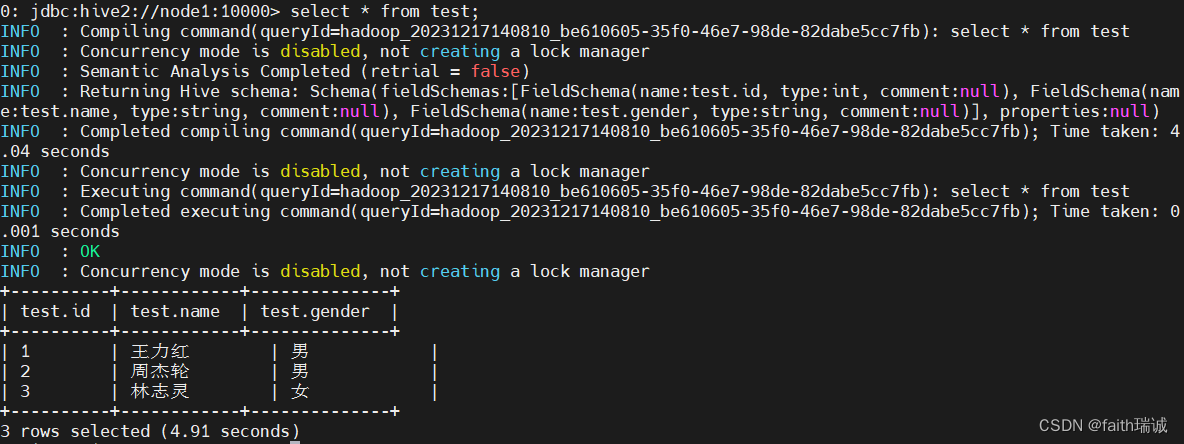
可以看到,这里虽然是查询动作,但是由于没有统计和计算,所以并没有转换成MapReduce程序。
select gender, count(*) from test group by gender;
- 1
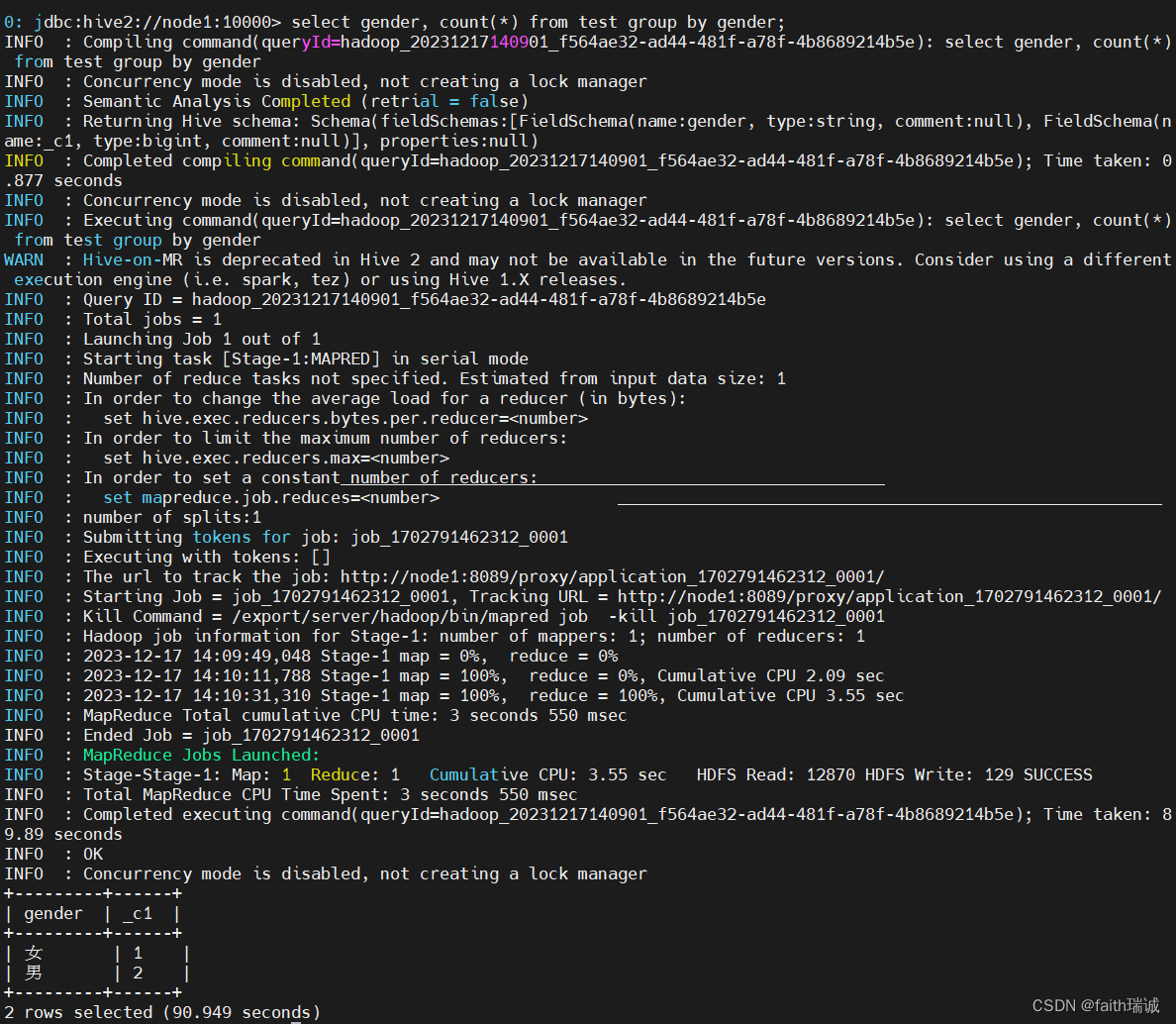
可以看到,当进行统计、计算的时候,这里将SQL转化成了MapReduce程序在运行,相应的,运行时间也会更长一点。而且,在在YARN集群的监控页面http://node1:8088/中,也可以看到执行该条SQL的MapReduce应用记录。
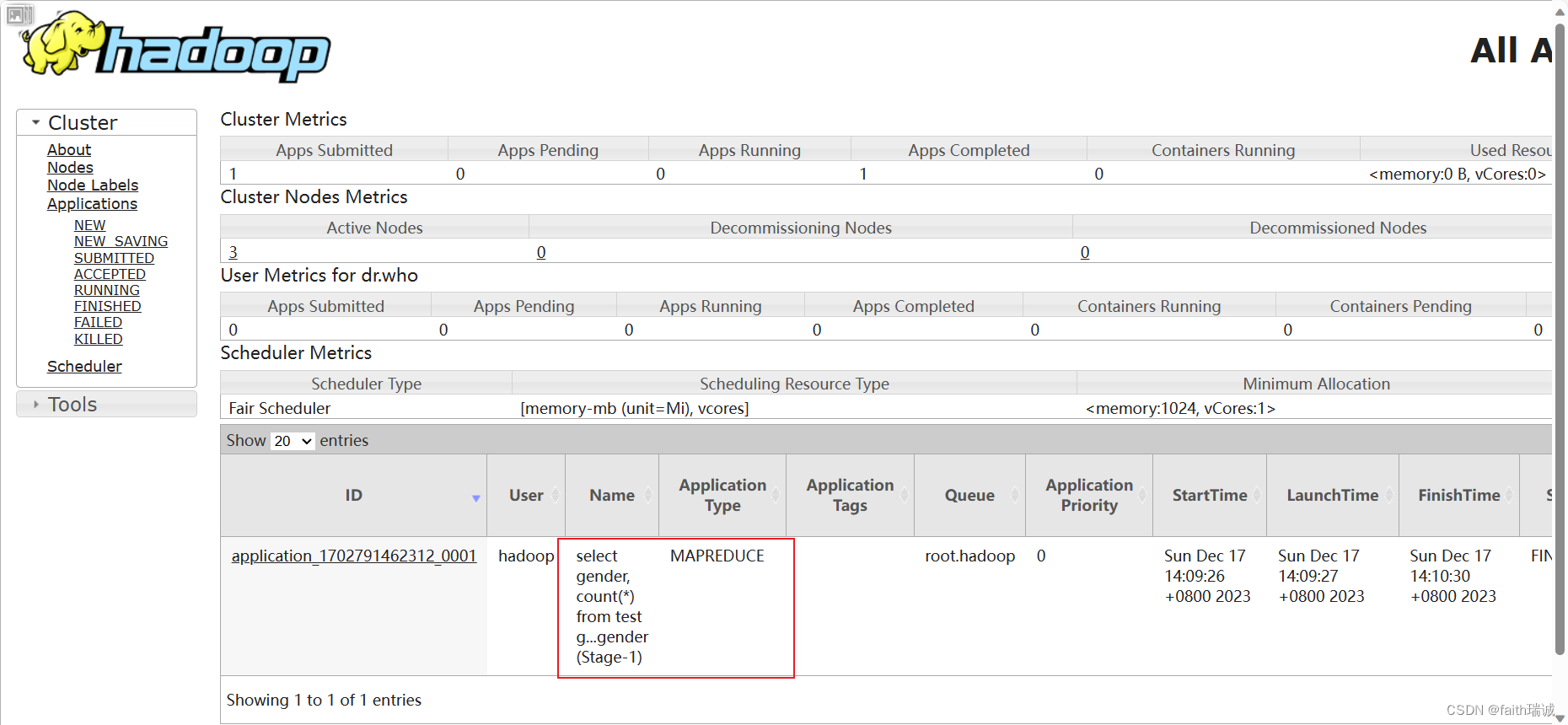
4、关闭HiveServer2
使用ps -aux | grep hiveserver2命令,查询到hiveserver2服务的进程号,然后使用kill命令杀死对应进程即可。
6.3. 使用DataGrip连接HiveServer2操作Hive
DataGrip是由JetBrains公司推出的数据库管理软件,DataGrip支持几乎所有主流的关系数据库产品,如DB2、Derby、MySQL、Oracle、SQL Server等,也支持几乎所有主流的大数据生态圈SQL软件,并且提供了简单易用的界面,开发者上手几乎不会遇到任何困难。
1、新建或打开一个工程;
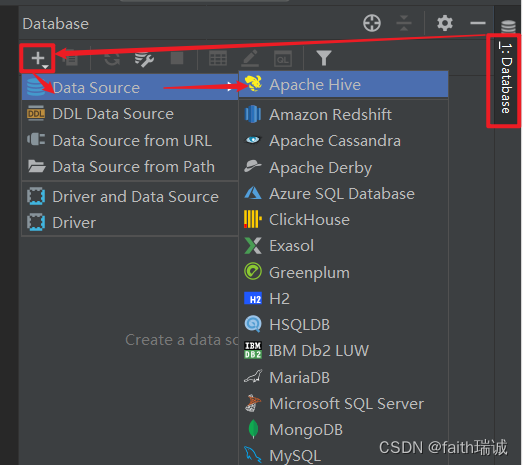
2、在左侧的“DataBase Explorer”中,点击左上角的“+”号,然后选择“DataSource-Apache Hive”,若看不到Apache Hive选项,可以在Other中寻找;
3、在打开的新建Hive连接页面中填写连接的自定义名称、Host(改为node1)、Port(改为10000)、User(改为hadoop)后,点击页面下部的“Download”链接;
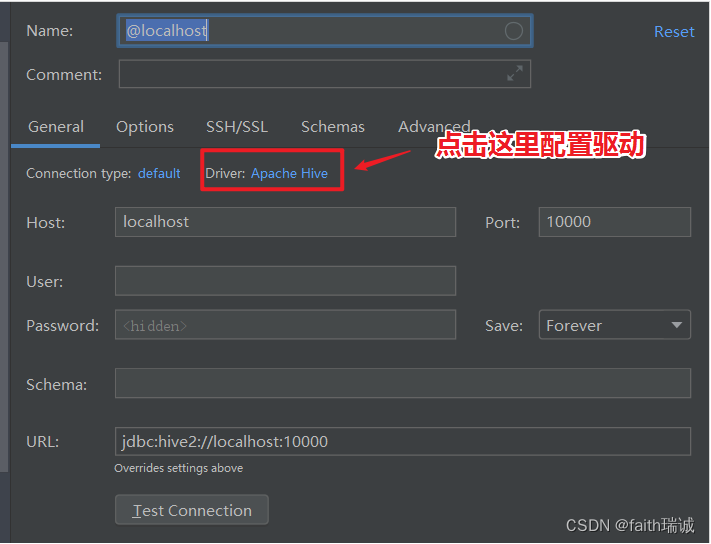
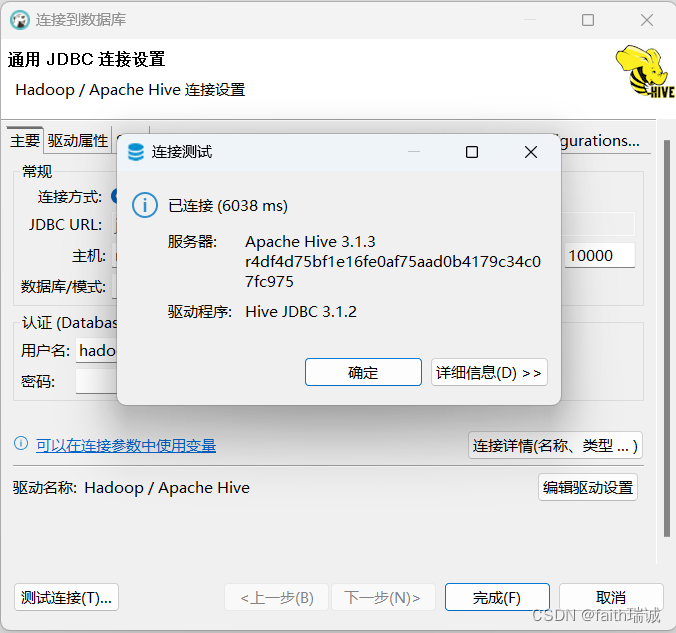
4、配置及驱动都准备好后,点击TestConnection按钮,测试连通性。
在DataGrip中,除了写SQL语句外,也可以通过图形化的方式创建库、表等操作,也可以图形化的查看数据。
6.4. 使用DBeaver连接HiveServer2操作Hive
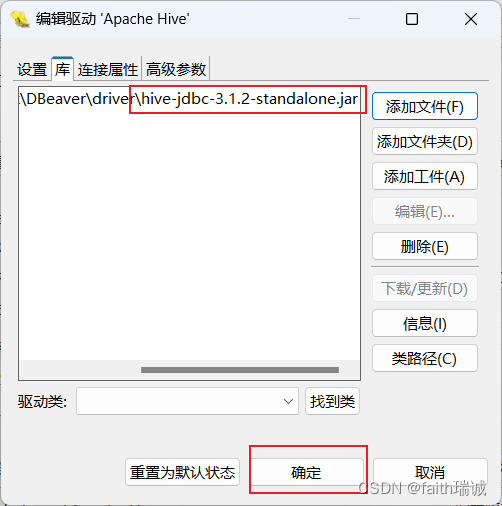
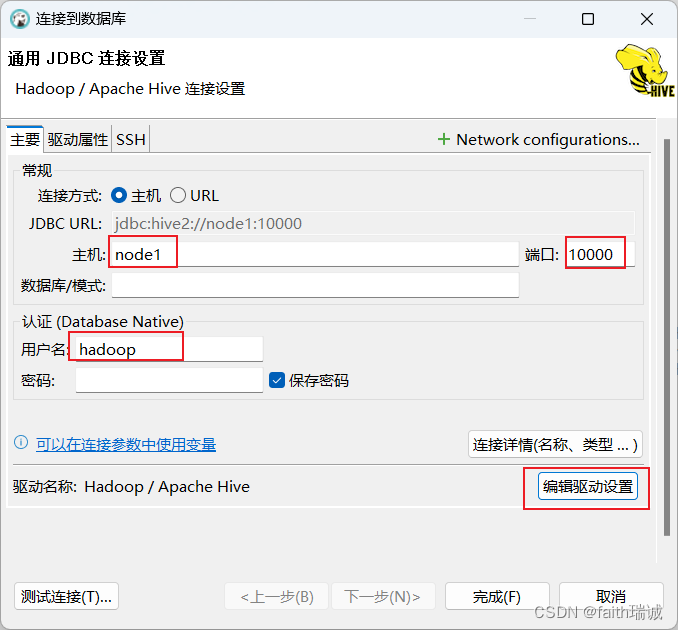
1、打开DBeaver,新建连接,选择Apache Hive(如果找不到,就在Other里面找);
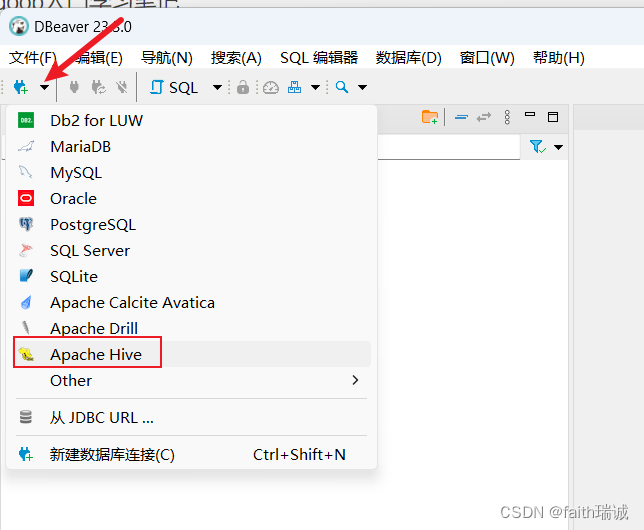
2、在弹出的新建连接窗口,填写主机(node1)、端口号(10000)、用户名(hadoop),然后点击“编辑驱动设置”按钮;
3、在驱动设置窗口,选择“库”选项卡,删除其内置的库,添加本课程资料中提供的hive-jdbc-3.1.2-standalone.jar驱动程序,然后点击“确定”按钮,再点击“测试连接”按钮,看到“已连接”代表配置成功,点击“完成”按钮;